合并有重叠的时间区间的极简方法
某库表有多个账户,每个账户有多个时间区间,区间之间有重叠。
| account_id | start_date | end_date |
| A | 2019-06-20 | 2019-06-29 |
| A | 2019-06-25 | 2019-07-25 |
| A | 2019-07-20 | 2019-08-26 |
| A | 2019-12-25 | 2020-01-25 |
| A | 2021-04-27 | 2021-07-27 |
| A | 2021-06-25 | 2021-07-14 |
| A | 2021-07-10 | 2021-08-14 |
| A | 2021-09-10 | 2021-11-12 |
| B | 2019-07-13 | 2020-07-14 |
| B | 2019-06-25 | 2019-08-26 |
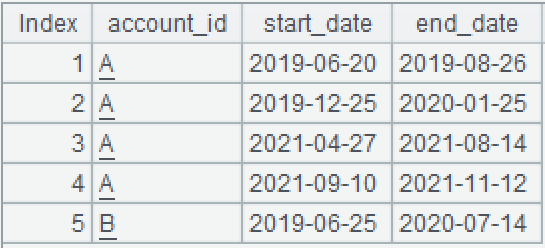
现在要合并每个账户里重叠的时间区间,生成新的区间,新区间不重叠。
| account_id | start_date | end_date |
| A | 2019-06-20 | 2019-08-26 |
| A | 2019-12-25 | 2020-01-25 |
| A | 2021-04-27 | 2021-08-14 |
| A | 2021-09-10 | 2021-11-12 |
| B | 2019-06-25 | 2020-07-14 |
SQL 分组后必须立刻汇总,不方便生成时间序列,不方便进行序列间的集合计算,间接实现的代码很复杂。SPL 可以保留分组子集继续计算,提供了生成时间序列的函数、序列间集合计算的函数:Try DEMO
| A | |
| 1 | $select * from data.txt |
| 2 | =A1.group(account_id) |
| 3 | =A2.(~.(periods(start_date,end_date)).merge@u().group@i(~!=~[-1]+1) .new(A2.account_id,~1:start_date,~.m(-1):end_date)) |
| 4 | =A3.conj() |
A1:加载数据。
A2:按账户分组,但不汇总,每组是一个集合。
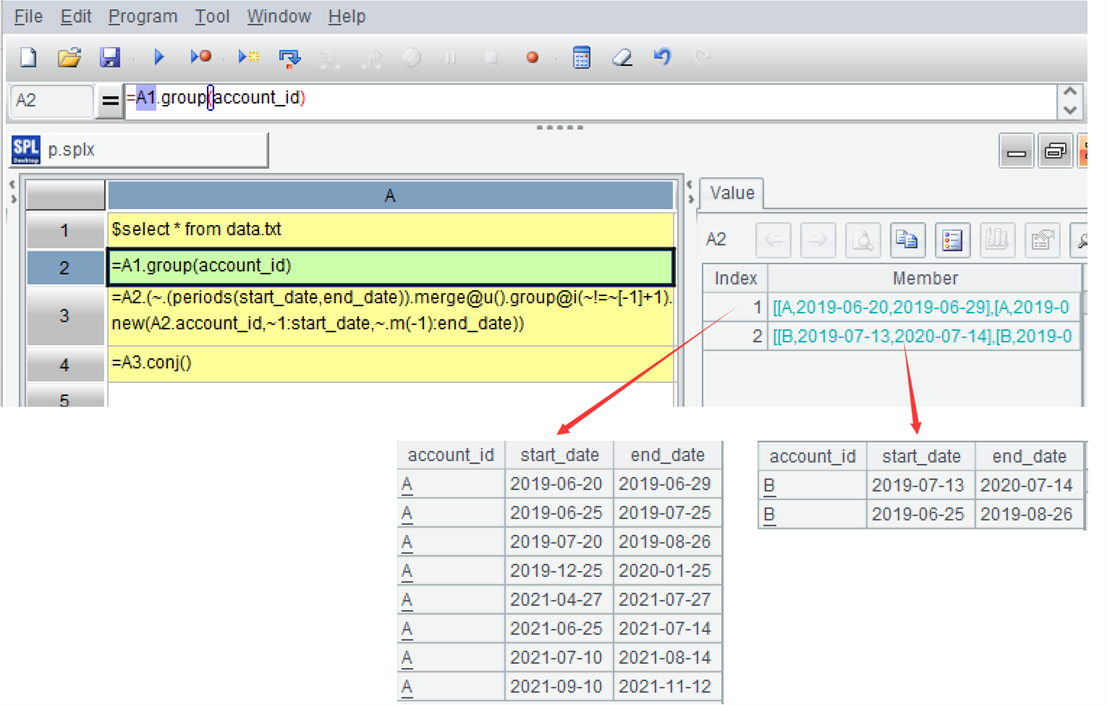
A3=A2.(~.(periods(start_date,end_date))…) 处理 A2 中的每组数据:先循环当前组的每条记录,根据起止日期生成序列,结果是个序列的集合。~ 表示当前组,函数 periods 可生成时间序列。下图是第一组的第一条记录生成的序列:
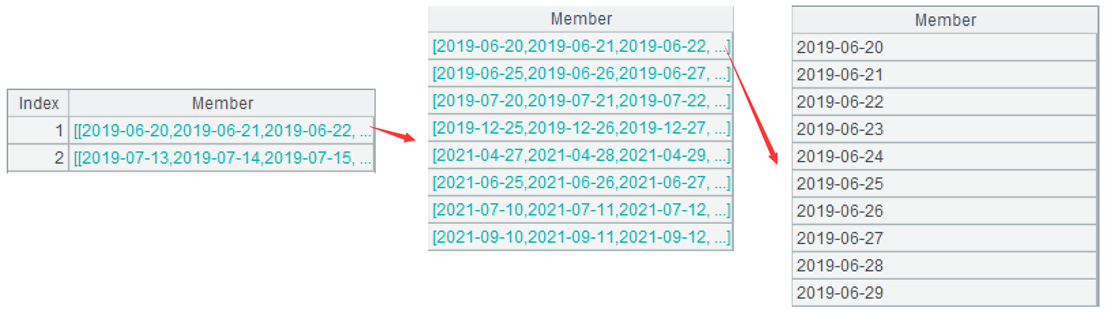
…merge@u() 继续处理:对序列的集合求并集,生成一个不重叠的日期序列。函数 merge 用于有序数据归并,@u 表示归并时求并集。下图是第一组求并集的结果,可以看到前 2 条记录重叠的日期已经合并。
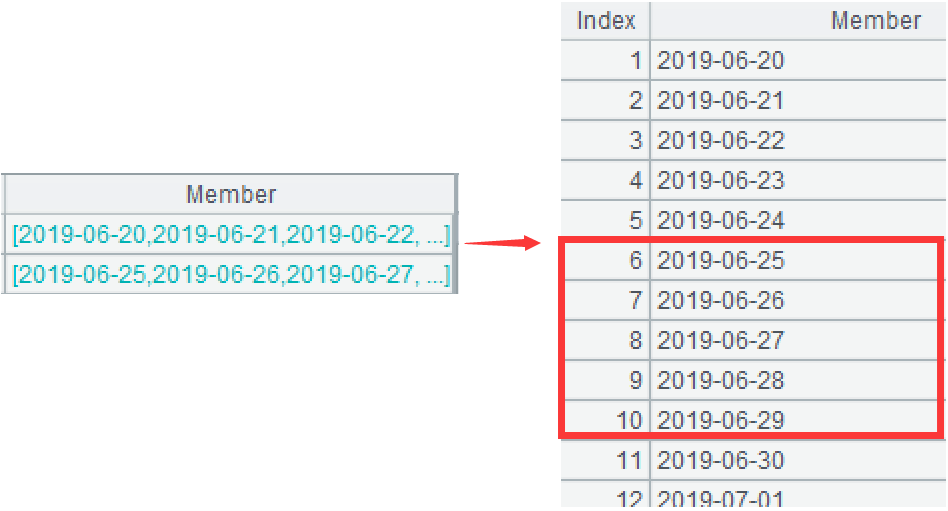
...group@i(~!=~[-1]+1)继续处理:对有序的日期序列分组,当当前成员不等于上一个成员 +1 天时新分一组,也就是将日期连续的日期分到同一组。选项 @i 表示对有序数据进行条件分组,[-1] 表示上一个成员。对第一组有序分组后,生成了四个小组,下图是前两个小组,可以看到小组之间日期不连续。
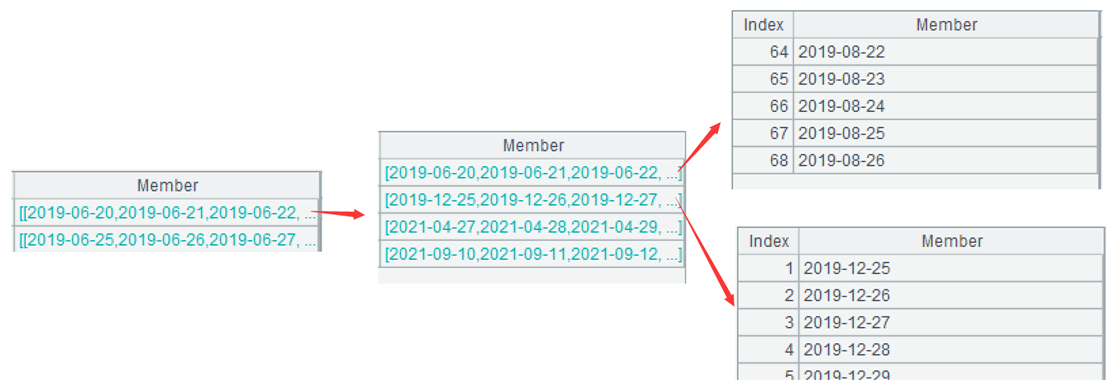
…new(A2.account_id,~1:start_date,~.m(-1):end_date)最后的处理:用小组生成新二维表,每个小组对应一条记录,account_id 取自 A2 中当前组的第一条记录,完整代码 A2.~(1).account_id,简写做 A2.account_id;start_date 取自当前小组的第一个成员;end_date 取自当前小组的最后一个成员。函数 m 可按位置取成员,~.m(1) 表示第一个成员,简写做 ~(1) 或 ~1,~.m(-1) 表示最后一个成员。下图是第一组生成的二维表。
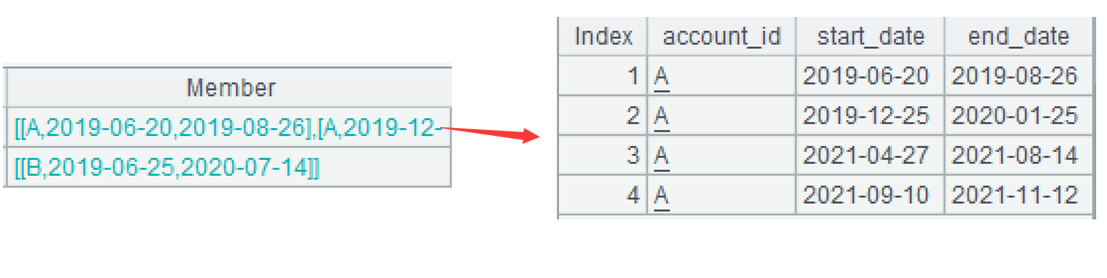
A4=A3.conj() 合并 A3 中各组的成员。
esProc SPL是开源免费的,点击下载试用~