VLA 论文精读(二十二)Multi-agent Embodied AI: Advances and Future Directions
这是一篇2025年发表在arxiv中的具身智能与Agent领域综述,就我目前读到的而言是最全面且最易懂的综述,特别是对dataset和benchmark的有非常详尽的描述,我平时都将这篇论文当作字典来查找想要的benchmark,而且作者团队是国内高校更适合中国宝宝体质。
以下是我根据文章顺序提炼的一些关键语句,平时可以用来搂一眼用:
- 由于联合行动空间扩大和规划范围延长导致问题复杂性呈指数级增长、智能体之间信息分散导致的部分可观测性、并发智能体学习过程产生的非平稳性,以及难以准确分配个体贡献;
- 具身人工智能强调现实世界的交互是学习和决策的基础;
- 在系统层面,具身人工智能架构通常由三个紧密集成的组件组成:perception 感知、cognition 认知、action 行动;
- RL 以反复试验的过程为基础,通过持续的交互智能体学会选择能够最大化长期累积奖励的行动,并利用来自环境的反馈来不断改进其行为;
- Reinforcement Learning 强化学习问题的核心通常被形式化为马尔可夫决策过程 (MDP);
- MARL 问题通常使用分散部分可观测马尔可夫决策过程 (Dec- POMDP) 框架建模;
- Hierarchical Learning 分层学习它将学习过程组织成多个抽象层次,较高层次负责设定抽象目标或意图,较低层次则专注于执行更具体、更细粒度的子任务;
- Imitation Learning 模仿学习通过观察和模仿专家行为来获得任务解决能力,利用专家演示作为直接监督;
- Generative Models 生成模型是机器学习的基础范式,其核心目标是捕捉训练数据的底层分布,以生成具有相似特征的新样本,Transformer、Diffusion Model、Mamba;
- End-to-End RL 端到端强化学习存在样本效率低和训练时间过长的问题;
- Hierarchical RL 分层强化学习将复杂任务分解为一系列更简单的子任务,从而提高学习效率和可扩展性;
- 但端到端和分层强化学习方法从根本上都依赖于精心设计的奖励函数,而这些奖励函数在现实环境中通常难以定义或不切实际;
- IL 使智能体能够直接从专家演示中获取有效策略,从而规避了显式奖励工程的需要,并促进了实践中更快的部署;
- 早期VLM将状态和目标等输入格式化为自然语言,并将其输入到预训练的生成模型中,从而无需额外训练即可进行动作推理;
- 利用预训练生成模型固有的推理和反思能力,可以在接收环境描述、状态和目标等输入后,通过迭代推理和反射过程有效地生成面向目标的计划;
- 生成模型强大的表达能力也使其能够有效地协助具身智能体进行环境感知;
- 为了应对在复杂的现实场景中设计高质量奖励函数的挑战,利用预先训练的生成模型进行奖励设计,包括奖励信号生成与奖励函数生成;
- 采用生成模型生成数据以提高样本效率是辅助策略学习的另一种重要方法;
- Multi-agent System, MAS 中,基于控制的方法仍然是在任务约束下实现高精度实时决策的基本途径;
- Asynchronous collaboration Embodied, ACE 引入了宏动作的概念,其中宏动作作为整个 MAS 的中心目标,各个智能体基于此目标做出多个异步决策,并且仅在宏动作完成后才会提供来自环境的延迟反馈;
- 生成模型已成为增强多智能体具身化系统决策能力的有力工具,引入先验知识来促进明确的任务分配,并利用其强大的信息处理能力来实现智能体间通信和观测完成,从而实现分布式决策;
- 利用预训练生成模型的先验知识和推理能力,将不同的任务明确地分配给不同的智能体,从而显著减少了每个智能体的探索空间;
- 集中式任务规划和分配会损害合作的灵活性和可扩展性,通常需要频繁召回进行调整,但生成模型出色的感知和推理能力使得部署多个基于 LLM 的智能体成为可能,这些智能体可以独立有效地执行决策和策略评估;
- 传统的强化学习方法往往无法充分捕捉人类行为固有的复杂性和多变性,但如果让人参与到决策过程中类似Human-in-loop但不给明确指令而是帮助机器人获取环境观测,则可以构建更灵活的人机协作;
写在最前面
为了方便你的阅读,以下几点的注意事项请务必了解:
- 该系列文章每个字都是我理解后自行翻译并写上去的,可能会存在笔误与理解错误,如果发现了希望读者能够在评论区指正,我会在第一时间修正错误。
- 阅读这个系列需要你有基本的 VLA、Agent相关基础知识,有时候我会直接使用英文名词,因为这些词汇实在不容易找到符合语境的翻译。
- 原文可能因为版面限制存在图像表格与段落不同步的问题,为了更方便阅读,我会在博文中重新对图像表格进行排版,并做到引用图表的文字下方就能看到被引用的图表。因此可能会出现一张图片在博客中多处位置重复出现的情况。
- 对于原文中的图像,我会在必要时对图像描述进行翻译并附上我自己的理解,但如果图像描述不值得翻译我也不会强行写上去。
Basic Information
- 论文标题:Multi-agent Embodied AI: Advances and Future Directions
- 原文链接: https://arxiv.org/abs/2505.05108
- 发表时间:2025年03月08日
- 发表平台:arxiv
- 预印版本号:[v1] Thu, 8 May 2025 10:13:53 UTC (13,753 KB)
- 作者团队:Zhaohan Feng, Ruiqi Xue, Lei Yuan, Yang Yu, Ning Ding, Meiqin Liu, Bingzhao Gao, Jian Sun, Gang Wang
- 院校机构:
- Beijing Institute of Technology;
- Nanjing University;
- Xi’an Jiaotong University;
- Zhejiang University;
- Tongji University;
- 项目链接: 【暂无】
- GitHub仓库: 【暂无】
Abstract
具身人工智能(Embodied AI)在智能时代先进技术的应用中扮演着关键角色。在智能时代,人工智能系统与物理实体相融合,使其能够感知、推理并与环境交互。通过使用传感器输入和执行器执行动作,这些系统能够根据现实世界的反馈进行学习和调整,从而能够在动态且不可预测的环境中有效地执行任务。随着深度学习(DL)、强化学习(RL)、大型语言模型(LLM)等技术的成熟,具身人工智能已成为学术界和工业界的领先领域,其应用领域涵盖机器人、医疗保健、交通运输和制造业。然而,大多数研究都集中在通常假设静态封闭环境的单智能体系统上,而现实世界的具身人工智能必须应对更为复杂的场景。在这样的环境中,智能体不仅必须与周围环境交互,还必须与其他智能体协作,这就需要复杂的机制来实现自适应、实时学习和协作解决问题。尽管人们对多智能体系统的兴趣日益浓厚,但现有研究范围仍然狭窄,通常依赖于简化模型,无法捕捉多智能体具身人工智能动态开放环境的全部复杂性。此外,尚无全面的综述系统地回顾该领域的进展。随着具身人工智能的快速发展,加深对多智能体具身人工智能的理解对于应对实际应用带来的挑战至关重要。为了填补这一空白并促进该领域的进一步发展,本文回顾了当前的研究现状,分析了关键贡献,并指出了挑战和未来方向,旨在为指导该领域的创新和进步提供见解。
1. Introduction
具身人工智能 (Embodied AI) 是人工智能 (AI)、机器人技术、认知科学交叉学科的研究领域,旨在使机器人具备感知、规划、决策、行动的能力,从而使它们能够主动与环境交互并适应环境。这一概念最初由艾伦·图灵在 20 世纪 50 年代提出,当时他探索了机器如何感知世界并做出相应的决策。在 20 世纪 80 年代,包括罗德尼·布鲁克斯在内的研究人员重新考虑了符号人工智能,认为智能应该通过与环境的主动交互而不是被动的数据学习而产生,从而为具身人工智能奠定了基础。近年来,在深度学习 (DL)、强化学习 (RL) 和其他技术的推动下,具身人工智能取得了重大进展,特别是通过应用大型预训练模型,例如大型语言模型 (LLM) 和视觉语言模型 (VLM)。这些模型增强了智能系统的感知、决策和任务规划能力,在视觉理解、自然语言处理、多模态集成任务中取得了卓越的表现。基于这些大型模型,具身人工智能在图像识别、语音交互、机器人控制方面取得了突破,提高了机器人理解和适应复杂动态环境的能力。
具身人工智能面临的主要挑战在于,智能体必须同时具备强大的感知和决策能力,以及通过与动态不断发展的环境持续交互而不断学习和适应的能力。从历史上看,以图灵机理论为代表的早期符号方法试图通过符号表示和逻辑推理来实现智能。然而,这些符号方法未能有效地处理感知与行动之间所需的动态交互。为了克服这些局限性,罗德尼·布鲁克斯提出了“perception-action loop”的概念,该概念认为智能是通过智能体与其环境的主动和持续互动而自然产生的,从而为现代具身人工智能研究奠定了基础。沿着这一思路,模仿学习 (IL) 等学习范式应运而生,它通过模仿专家演示来加速学习过程,但仍然严重依赖专家生成的数据,因此容易受到分布偏移等挑战的影响。作为一种替代方案,强化学习(尤其是深度强化学习)集成了深度神经网络,通过来自环境的交互驱动反馈来优化决策策略。此类方法擅长管理高维感官输入,在各种复杂任务中表现出强大的适应性。近年来,大规模模型的出现,尤其是 LLM 和 VLM,显著推动了具身人工智能的发展,增强了智能体在视觉理解、多模态感知和任务规划方面的能力。尽管取得了这些进展,但当前的大多数研究主要关注单智能体场景,往往忽略了多智能体交互的内在复杂性。相比之下,现实世界的具身人工智能应用通常需要多个异构智能体之间的有效协作,以完成诸如对抗未知对手或应对复杂动态挑战等任务。
多智能体设置与单智能体场景有着根本的不同,因为智能体必须同时优化各自的策略并管理多个实体之间的复杂交互。具体而言,多智能体交互带来了诸多挑战,例如由于联合行动空间扩大和规划范围延长导致问题复杂性呈指数级增长、智能体之间信息分散导致的部分可观测性、并发智能体学习过程产生的非平稳性,以及难以准确分配个体贡献。尽管单智能体具身人工智能取得了长足的进步,但在多智能体环境下的具身人工智能研究仍然处于相对初级阶段。当前的研究通常采用成功的单智能体方法,或采用强化学习和LLM 等成熟的框架。最近,专门针对具身多智能体场景的基准测试的开发已经开始,旨在支持这一不断发展的领域的系统性进步。虽然大量的文献综述已经深入探讨了相关领域,包括具身人工智能、多智能体强化学习 (MARL)和多智能体合作,但明确关注具身多智能体人工智能的综合性综述仍然有限。例如,系统总结具身 MARL 的最新进展,涵盖了社会学习、应急通信、Sim2Real 迁移、分层方法、安全考虑等主题,或者进一步扩展了这一视角,回顾了生成基础模型与具身多智能体系统 (MAS) 的集成,提出了协作架构的分类,并讨论了感知、规划、通信、反馈机制等基本组成部分。然而,这些综述主要涉及多智能体具身人工智能的特定维度,缺乏对整个领域的系统全面的概述。
认识到多智能体具身人工智能在解决现实环境中的复杂协调任务方面的巨大潜力,本文对这一新兴研究领域的最新进展进行了系统而全面的回顾。如Fig.1所示,首先介绍基础概念,包括 MAS、RL 和相关方法。接下来讨论单智能体情境中的具身人工智能,清晰地概述核心定义、主要研究方向、代表性方法、已建立的评估基准。在此基础上讨论扩展到多智能体具身人工智能,重点介绍广泛使用的技术,并研究专为多智能体场景设计的近期突出基准。最后,总结本次回顾的主要贡献,对多智能体具身人工智能的未来发展提出了深刻的见解,旨在促进这一前景广阔且快速发展的领域的进一步研究和创新。
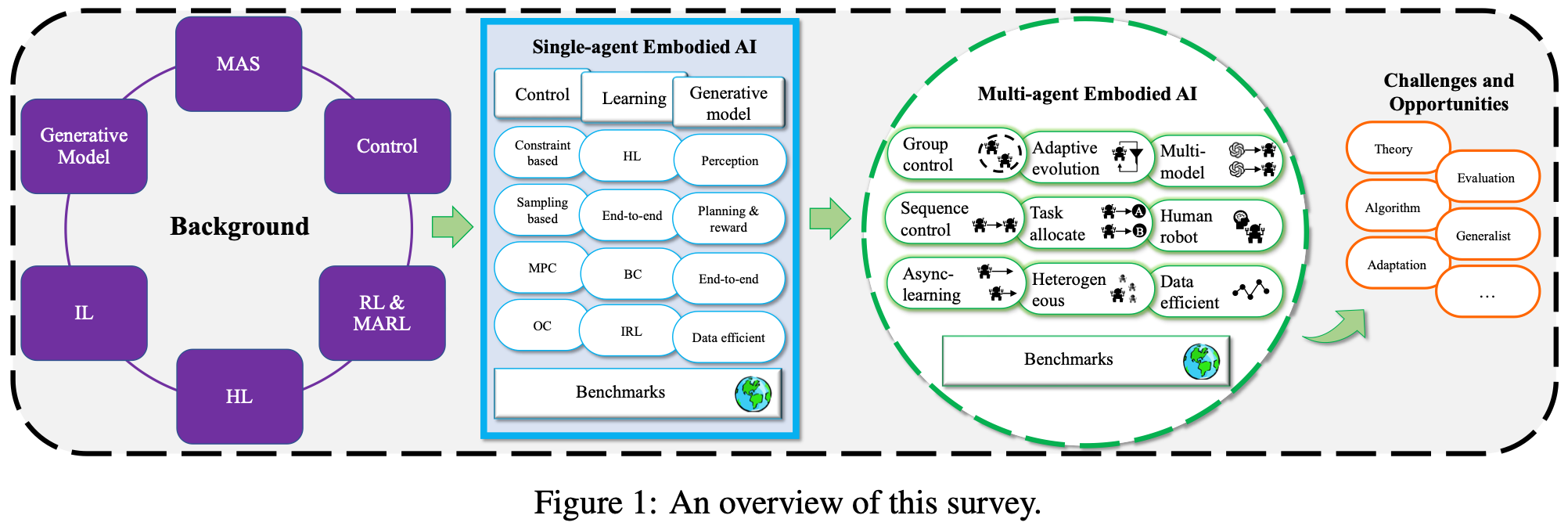
2. Preliminaries
在本节中将介绍构成具身人工智能的核心技术,首先介绍具身人工智能本身的正式定义。还将定义多智能体系统 (MAS) 的概念,并探讨一系列基本方法,包括最优控制 (OC)、强化学习 (RL)、多智能体学习 (MARL)、分层学习 (IL) 、生成模型。
2.1 Embodied AI
具身人工智能Fig.2是指一类配备有物理躯体的智能代理,使其能够通过持续的交互来感知、采取行动并适应环境。具身人工智能的概念根源可以追溯到艾伦·图灵在20世纪50年代的早期主张,即真正的智能必须源于感官和运动体验而非纯粹的符号计算。这一概念在20世纪80年代通过具身认知理论得到进一步形式化,该理论认为认知本质上是由代理的物理形态及其与世界的交互所塑造的。与依赖抽象推理或从静态数据集被动学习的传统人工智能范式相比,具身人工智能强调现实世界的交互是学习和决策的基础。
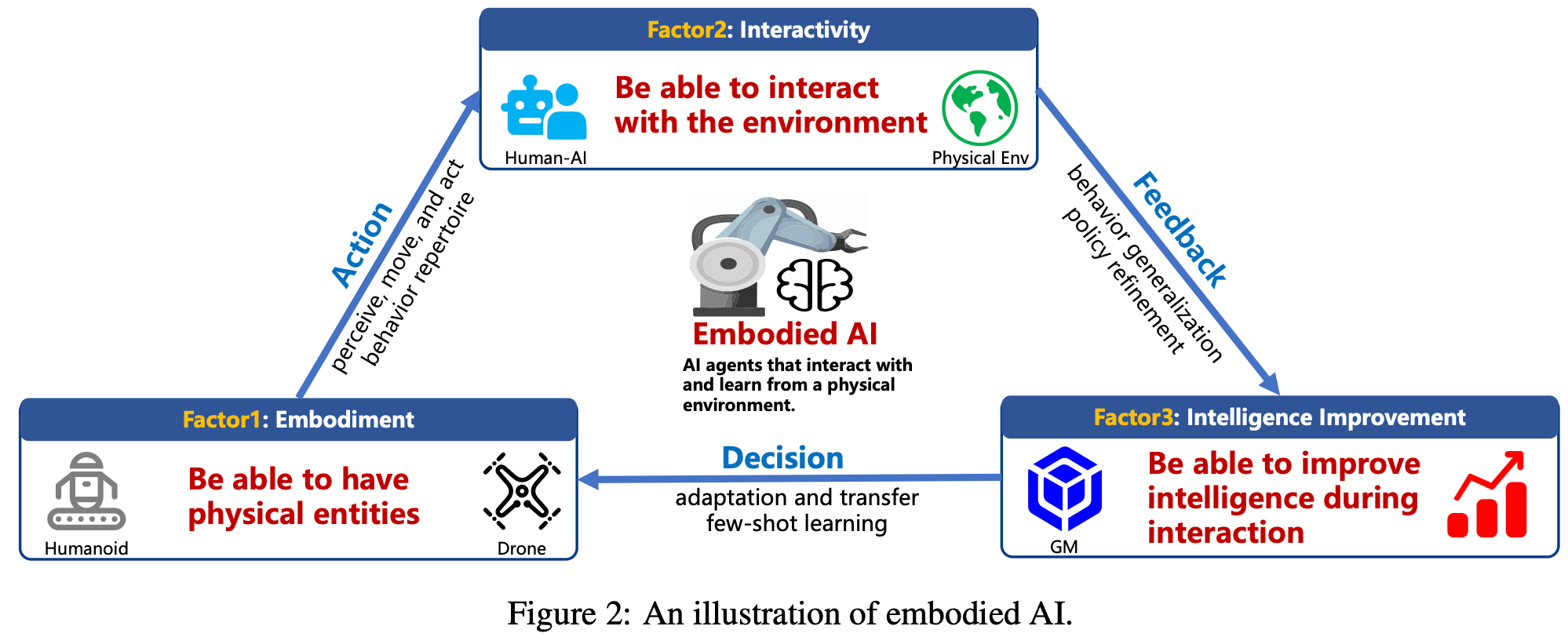
在系统层面,具身人工智能架构通常由三个紧密集成的组件组成:perception感知、cognition认知、action行动。智能体使用物理传感器从周围环境获取实时的、与情境相关的信息。这些感知数据由支持推理、解释和规划的认知模块处理。然后,由此产生的决策通过执行器转化为物理动作,执行器会修改环境并发起新的感知输入。这些过程形成一个连续的反馈回路,称为 “perception–cognition–action cycle”,这使得具身智能体能够根据环境反馈动态地调整其行为。具身人工智能范式的核心是三个基本属性,它们决定了智能如何在物理智能体中出现和发展:
Embodiment
具身人工智能植根于具备感知、移动、在现实世界中行动能力的物理代理。这些代理形态各异,包括人形机器人、四足动物、自主地面车辆、无人机。物理躯体不仅是代理与环境交互的媒介,也是约束和实现其行为能力的结构基础。躯体的形态、感觉运动保真度和驱动力共同定义了代理可能交互的范围和粒度,从而塑造了其情境智能的范围。
Interactivity
基于这一物理基础,具身智能通过与周围环境的持续闭环交互而显现。智能体以第一人称视角进行操作,参与感知、决策、行动的动态循环。每种行为不仅响应环境刺激,还会改变未来的感官输入,形成一个支持自适应学习的、反馈丰富的循环。通过这种持续的互动,智能体不断完善其策略,获得特定于任务的能力,并在不同情境中泛化行为,从而在现实世界场景中实现稳健的情境感知性能。
Intelligence Improvement
具身人工智能的发展以认知和行为的持续改进能力为特征。大规模多模态模型的集成日益推动着这一进程,这些模型赋予智能体语义理解、指令遵循、情境推理能力。这些模型促进了小样本学习、情境自适应以及跨任务的知识迁移。随着智能体与环境的交互,它会逐步调整其感知输入、决策过程和物理动作,从而立即实现任务成功,并随着时间的推移,在自主性、适应性、泛化能力方面持续提升。
生成模型LLM的最新进展进一步扩展了具身智能体的认知能力。LLM 凭借其强大的推理和泛化能力,使具身系统能够理解语言指令,将语义知识与物理经验相结合,并执行零样本或少样本自适应。这些发展加速了具身人工智能在机器人、自动驾驶、智能制造、医疗保健等现实世界领域的部署。重要的是,具身人工智能不仅仅是强大的人工智能模型与机器人平台的集成;相反,它代表了一种共同进化的范式,其中智能算法(“大脑”)、物理结构(“身体”)和动态环境共同进化,以支持自适应的具身智能。
2.2 Multi-Agent Systems
MAS 由多个自主智能体组成,每个智能体能够感知其环境、做出独立决策并相应地执行操作。与传统的集中式控制范式相比,MAS 采用分散式架构,其中智能体在本地交互的同时实现全局协调。这种分散式设计在可扩展性、容错性和适应性方面具有显著优势,尤其是在动态、部分可观测或非平稳环境中。MAS 的核心属性包括自主性、分散性、智能体间通信、本地信息访问、动态适应性。这些特性使 MAS 能够处理各种复杂的高维任务,这些任务需要并行感知、分布式规划和实时协调,在机器人、自动驾驶和智能基础设施等领域有着突出的应用。
近年来,在基于学习的方法融合和神经架构进步的推动下,MAS 研究经历了重大的范式转变。处于这一转变前沿的是 MARL,它提供了一个强大的框架,使智能体能够通过交互学习复杂的行为。诸如集中训练与分散执行 (CTDE)、参数共享、信用分配、对手建模等技术已被广泛采用,以应对非平稳性、协调性、部分可观测性等核心挑战。作为这些进步的补充,LLM 的集成为 MAS 开辟了新的能力。LLM 赋能的智能体可以访问海量预训练知识,通过自然语言进行交流,并进行高级推理和抽象,这些能力超越了传统策略驱动系统的局限性。强化学习与基础模型的融合正在重塑 MAS 的格局,为更具泛化能力、可解释性且更贴近人类的智能体架构铺平道路。
2.3 Optimal Control
OC 是现代控制理论的一个基本分支,其重点是设计控制策略以优化特定的性能指标,例如时间、能耗或成本,同时满足系统的动态和控制约束。由于OC能够实现全局最优,同时处理多个目标和约束,并在复杂系统中保持鲁棒性,因此在航空航天工程、工业自动化、经济管理和能源系统等领域得到了广泛的应用。
形式上,标准 OC 问题可以描述如下:给定一个由 x ˙ ( t ) = f ( x ( t ) , u ( t ) , t ) \dot{x}(t)=f(x(t),u(t),t) x˙(t)=f(x(t),u(t),t) 和初始状态 x ( t 0 ) = x 0 x(t_{0})=x_{0} x(t0)=x0 控制的动态系统,目标是找到一个控制输入 u ( t ) u(t) u(t),使性能指标最小化:
J = ϕ ( x ( t f ) , t f ) + ∫ t 0 t f L ( x ( t ) , u ( t ) , t ) d t J=\phi(x(t_{f}),t_{f})+\int^{t_{f}}_{t_{0}}{L(x(t),u(t),t)}dt J=ϕ(x(tf),tf)+∫t0tfL(x(t),u(t),t)dt
其中 ϕ \phi ϕ 为终端成本函数, L L L为运行代价函数。
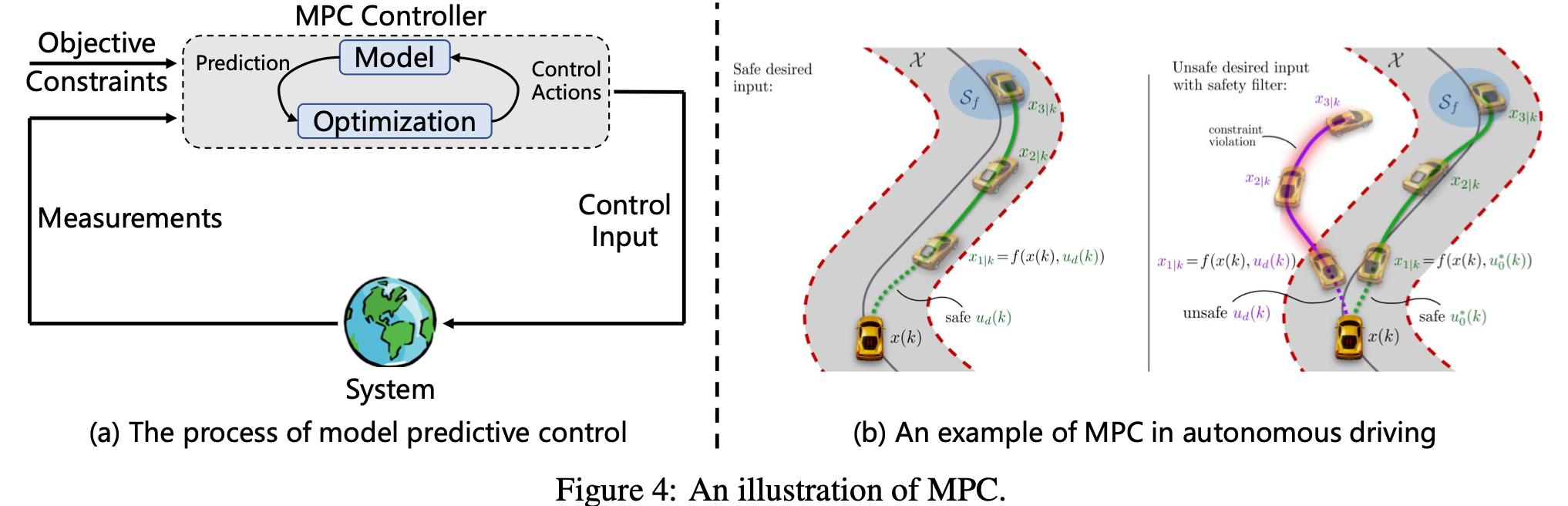
OC 中常用的方法包括变分法、Pontryagin 最大值原理、动态规划、模型预测控制 (MPC)。变分法利用 Euler–Lagrange 方程推导出最优轨迹;Pontryagin 最大值原理通过构造哈密顿函数并定义状态和共状态动力学来制定最优性的必要条件;动态规划 (DP) 通过贝尔曼最优原理解决复杂系统中的状态空间优化问题;MPC 使用滚动时域策略实时求解约束优化问题。其中,MPC 是工业界应用最广泛的方法,其核心思想是在每个时间步求解一个有限时域 OC 问题,并且只执行第一个 OC 动作,如Fig.4所示。具体而言,在 t k t_{k} tk 时刻,MPC 求解以下在线优化问题:
min u 0 , u 1 , … , u N − 1 ∑ i = 0 N − 1 L ( x i , u i ) + ϕ ( x N ) \min_{u_{0},u_{1},\dots,u_{N-1}}{\sum^{N-1}_{i=0}{L(x_{i},u_{i})+\phi(x_{N})}} u0,u1,…,uN−1mini=0∑N−1L(xi,ui)+ϕ(xN)
受系统动力学 x i + 1 = f ( x i , u i , i ) x_{i+1}=f(x_{i},u_{i},i) xi+1=f(xi,ui,i) 约束。MPC由于其高效性、实时性和鲁棒性,被广泛应用于多智能体具体化AI系统,例如机器人群体的协调控制、无人机(UAV)的编队控制等。
2.4 Reinforcement Learning
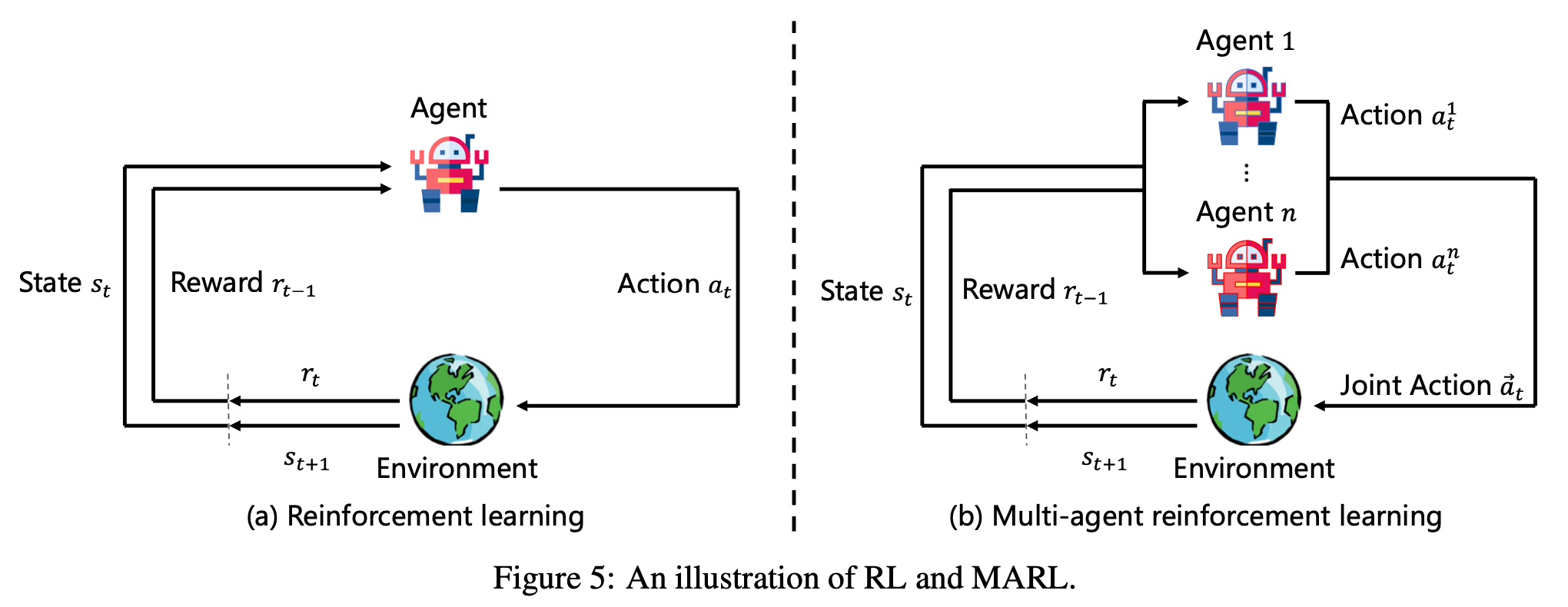
强化学习 (RL) 是机器学习的一个基本分支,专注于使智能体通过与动态环境交互做出连续决策。与需要标记数据的监督学习或揭示未标记数据中隐藏模式的无监督学习不同,RL 以反复试验的过程为基础,通过持续的交互智能体学会选择能够最大化长期累积奖励的行动,并利用来自环境的反馈来不断改进其行为。由于其从交互中学习的能力,RL 在众多领域取得了令人瞩目的成果。这些领域包括战略游戏、机器人控制、工业过程优化、个性化医疗、自动驾驶,甚至 LLM 中的对齐和指令遵循。
强化学习问题的核心通常被形式化为马尔可夫决策过程 (MDP),如Fig.5 (a) 所示。MDP 由一个元组 M = < S , A , P , R , γ > M=<S,A,P,R,\gamma> M=<S,A,P,R,γ> 定义,其中 S S S 和 A A A 分别表示状态和动作的集合; P ( s ′ ∣ s , a ) P(s'|s,a) P(s′∣s,a) 是转移概率函数; R ( s , a ) R(s,a) R(s,a)表示奖励函数; γ ∈ [ 0 , 1 ] \gamma\in[0,1] γ∈[0,1]是平衡短期和长期奖励的折扣因子。目标是学习一个策略 π ( a , s ) \pi(a,s) π(a,s),使以下预期累积回报最大化:
E π [ ∑ t = 0 ∞ γ t R ( s t , a t ) ∣ s 0 ] E_{\pi}\left[\sum^{\infty}_{t=0}{\gamma^{t}R(s_{t},a_{t})|s_{0}}\right] Eπ[t=0∑∞γtR(st,at)∣s0]
其中期望取自策略 π \pi π 和过渡动态 P P P 生成的轨迹。虽然单智能体 RL 为自主决策提供了坚实的基础,但许多现实世界场景涉及多个智能体同时行动和学习。这促使 RL 扩展到 MARL 中,其中智能体之间的coordination 协调、competition 竞争、cooperation 合作变得至关重要。在完全合作任务中,MARL 问题通常使用分散部分可观测马尔可夫决策过程 (Dec-POMDP) 框架建模,如Fig5 (b)所示。Dec-POMDP 通过引入多个智能体和部分可观测性扩展了 MDP,形式化定义为一个元组 M = < I , S , A i , P , R , Ω i , O , n , γ > M=<I,S,A_{i},P,R,\Omega_{i},O,n,\gamma> M=<I,S,Ai,P,R,Ωi,O,n,γ>;其中 I I I 是 n n n 个智能体的集合,每个智能体 i i i 仅基于局部观察 Ω i \Omega_{i} Ωi, 并从其自己的动作空间 A i A_{i} Ai 中选择动作;全局状态根据联合动作 a a a 通过 P ( s ′ ∣ s , a ) P(s'|s,a) P(s′∣s,a) 进行转换,所有智能体获得共享奖励 R ( s , a ) R(s,a) R(s,a)。观测值通过函数 O ( s ′ , a , o ) O(s',a,o) O(s′,a,o) 生成,为每个智能体提供私密可能不完整的信息。核心挑战在于学习一组去中心化策略 [ π 1 , … , π n ] [\pi_{1},\dots,\pi_{n}] [π1,…,πn],其中每个智能体必须仅使用局部信息采取最优行动,同时它们的联合行为能够最大化团队的累积奖励。
人们已经开发出各种各样的算法策略来解决单智能体和多智能体强化学习问题。其中,主要有两类方法脱颖而出:基于价值的方法和基于策略的方法。基于价值的方法,例如深度 Q 网络 (DQN) 专注于估计动作价值函数,使智能体能够根据预测的未来奖励采取贪婪的行动;基于策略的方法,例如 DDPG 和 PPO 直接优化参数化策略。这些方法通常结合价值函数来指导学习,特别适用于高维或连续动作空间的环境。这两种范式都通过不同的架构创新扩展到多智能体环境。价值分解方法,例如 QMIX ,学习一个可以分解为各个智能体效用的全局价值函数。这种结构支持分散执行,同时支持集中训练。另一方面,基于策略的 MARL 方法,包括 MADDPG 和 MAPPO ,采用了 CTDE 框架。这些方法在训练过程中采用共享的全局评价器来提供稳定的学习信号,并支持代理之间有效的信用分配,从而增强了合作任务中的协调性。
2.5 Hierarchical Learning
分层学习是一种学习范式,它将学习过程组织成多个抽象层次,较高层次负责设定抽象目标或意图,较低层次则专注于执行更具体、更细粒度的子任务(参见Fig.6)。这种分层结构使模型能够跨不同的粒度级别运行,从而通过将复杂任务分解为更简单、更易于管理的组件,提高了解决复杂任务的效率和可扩展性。
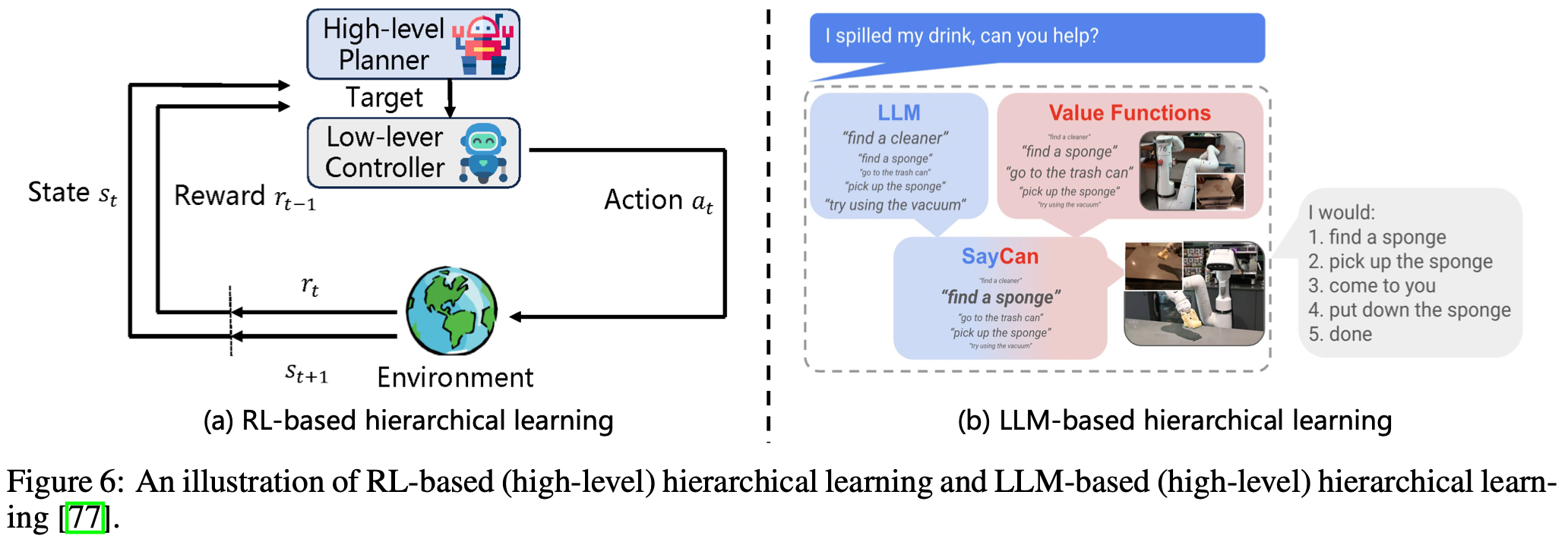
分层学习的核心过程通常包含两个阶段:低级策略学习和高级策略学习。低级策略学习旨在掌握基本子任务,通常使用传统的控制方法(例如 MPC )或端到端强化学习来实现;高级策略学习负责协调已学习到的低级技能,以实现更复杂的目标。这通常通过强化学习或使用 LLM 进行规划来实现。在基于强化学习的高级策略学习中,动作空间被定义为已学习到的低级策略的集合。然后,使用来自环境的奖励信号训练参数化的高级策略,以有效地选择和排序这些低级技能。相比之下,基于 LLM 的高级策略学习通常涉及将任务目标和可用的低级策略集作为 LLM 的输入,然后 LLM 通过组合和调用适当的低级技能来直接生成结构化计划以完成任务。
2.6 Imitation Learning
IL 也称从演示中学习,是一种机器学习范式,其中代理通过观察和模仿专家行为来获得任务解决能力。与需要手动设计奖励函数来指导学习的RL不同,IL利用专家演示作为直接监督。这种区别使得IL在奖励规范模糊、成本高昂甚至不可行的复杂高维环境中尤为有利。多年来,IL中出现了三种最突出的方法:行为克隆(BC)、逆强化学习(IRL)和生成对抗模仿学习(GAIL)。
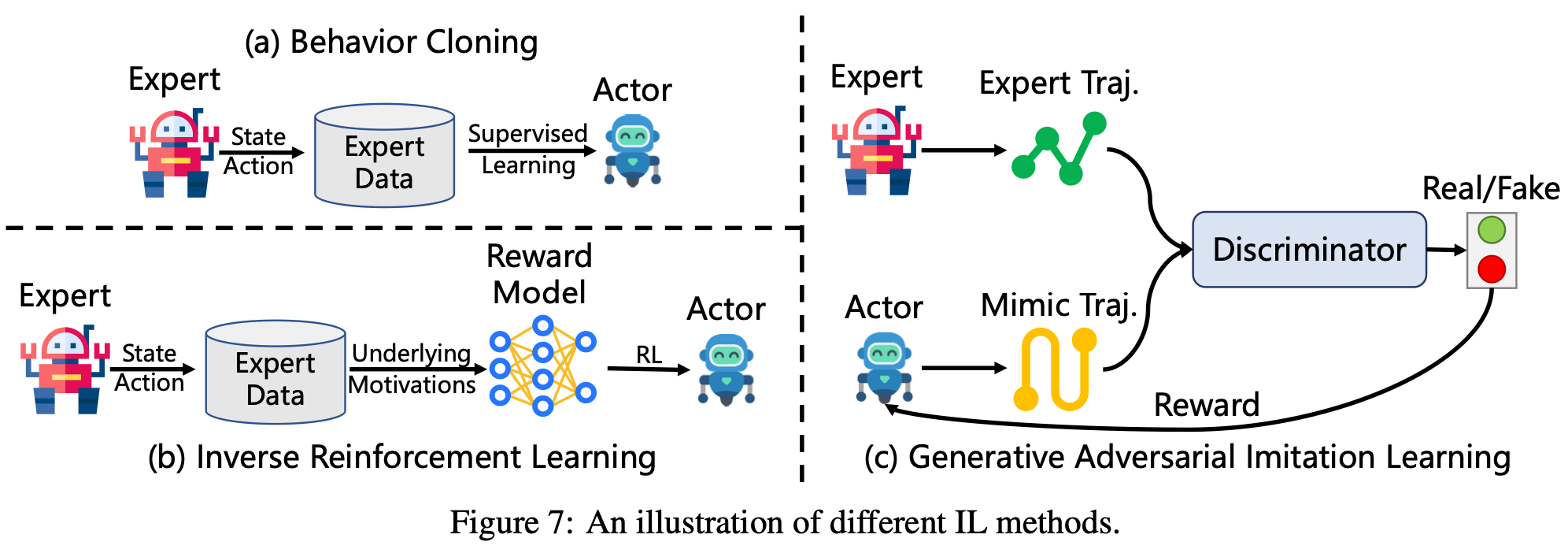
BC 是最直接、应用最广泛的技术。它将模仿任务转化为监督学习问题,旨在将观察到的状态直接映射到相应的专家动作。如Fig.7 (a) 所示,代理从专家生成的状态-动作对数据集 D = { ( s i ) , a i } i = 1 N D= \{(s_{i}),a_{i}\}^{N}_{i=1} D={(si),ai}i=1N 中进行学习,从而优化以下目标:
min θ E ( s , a ) ∼ D [ − log π θ ( a ∣ s ) ] \min_{\theta}E_{(s,a)\sim D}[-\log{\pi_{\theta}(a|s)}] θminE(s,a)∼D[−logπθ(a∣s)]
其中 θ \theta θ 表示策略 π θ \pi_{\theta} πθ 的参数,这种损失会促使学习到的策略在面对类似状态时做出与专家策略紧密匹配的动作。虽然 BC 计算效率高且易于实现,但由于协变量偏移,它容易出现误差累积,尤其是在智能体会访问训练期间未曾见过的状态的长视域任务中。
为了解决BC的一些局限性,IRL采用了一种根本不同的方法,旨在推断专家的底层奖励函数,而不是直接复制他们的行为。一旦恢复了奖励函数,就可以使用标准RL方法来推导最优策略。如Fig.7 (b)所示,这个两步过程可以提高泛化能力和策略的可解释性。形式上,一个代表性的公式是最大熵IRL目标函数
max R E τ ∼ D [ R ( τ ) ] − log Z ( R ) \max_{R}E_{\tau\sim D}[R(\tau)]-\log{Z(R)} RmaxEτ∼D[R(τ)]−logZ(R)
其中 τ = ( s 0 , a 0 , … , s T , a T ) \tau=(s_{0},a_{0},\dots,s_{T},a_{T}) τ=(s0,a0,…,sT,aT), R ( τ ) = ∑ t = 0 T R ( s t , a t ) R(\tau)=\sum^{T}_{t=0}R(s_{t},a_{t}) R(τ)=∑t=0TR(st,at), Z ( R ) = ∫ e R ( τ ) d τ Z(R)=\int{e^{R(\tau)}}d\tau Z(R)=∫eR(τ)dτ 是确保轨迹分布正则化的配分函数。通过明确地建模专家的意图,IRL 提供了更稳健且可解释的策略。然而,由于在奖励学习过程中需要重复进行 RL 迭代,因此这种好处是以额外的计算开销为代价的。
与BC和IRL不同,GAIL 引入了一个对抗性训练框架无需明确指定奖励。受生成对抗网络 (GAN) 的启发,GAIL 将模仿构建为两个组件之间的极小极大博弈:一个生成器(待学习的策略)和一个鉴别器,用于区分专家轨迹和策略生成的轨迹。如Fig.7 (c) 所示,优化目标是:
min π max D E ( s , a ) ∼ D [ log D ( s , a ) ] + E ( s , a ) ∼ D π [ log ( 1 − D ( s , a ) ) ] \min_{\pi}\max_{D}E_{(s,a)\sim D}[\log{D(s,a)}]+E_{(s,a)\sim D_{\pi}}[\log{(1-D(s,a))}] πminDmaxE(s,a)∼D[logD(s,a)]+E(s,a)∼Dπ[log(1−D(s,a))]
其中 D π D_{\pi} Dπ 表示当前策略生成的轨迹。通过这种对抗性设置,GAIL 隐式地学习到一种奖励信号,鼓励智能体做出与专家难以区分的行为。与 IRL 相比,GAIL 通过避免显式的奖励建模简化了训练流程,从而提高了样本效率。然而,这种优势是以降低可解释性为代价的,因为学习到的奖励从未被显式提取。总而言之,BC、IRL 和 GAIL 代表了更广泛的 IL 框架内的互补范式。BC 提供了简单有效的基线,IRL 通过奖励恢复提供了可解释性和泛化能力,而 GAIL 则结合了两者的优势,通过对抗性学习实现端到端的模仿。在它们之间进行选择通常取决于目标应用所需的样本效率、泛化能力、计算复杂度和可解释性之间的权衡。
2.7 Generative Models
生成模型是机器学习的基础范式,其核心目标是捕捉训练数据的底层分布,以生成具有相似特征的新样本。这些模型已广泛应用于视觉、语言和多模态学习等领域。近年来,LLM 和 VLM 等大规模生成模型的出现显著推动了该领域的发展。它们的成功很大程度上归功于强大的泛化能力、海量数据集的可用性以及可扩展的架构。这些模型的核心是几个关键的架构框架,包括 Transformer、扩散模型,以及最近的状态空间模型 (SSM),例如 Mamba。
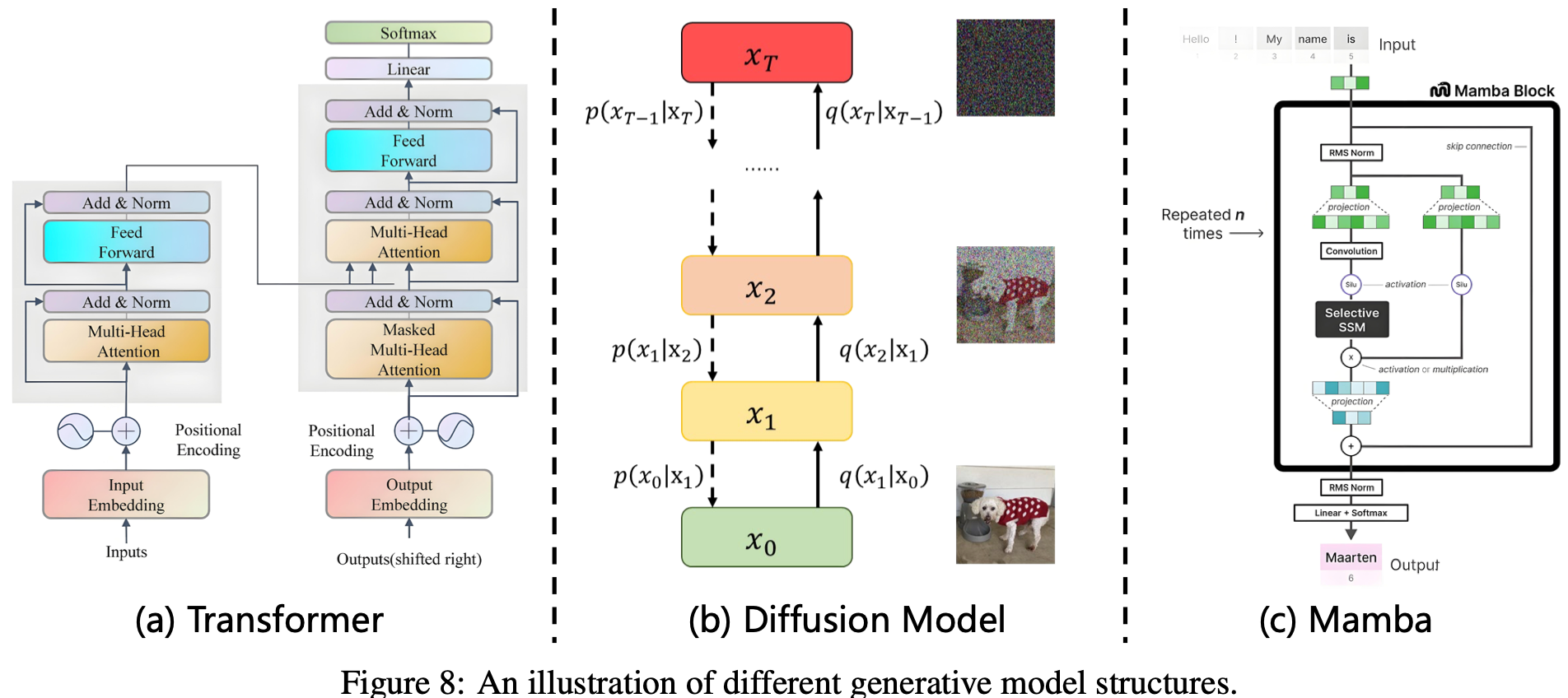
其中,Transformer 架构在序列建模的革新中发挥了关键作用。Transformer 最初是为机器翻译而提出的,它通过引入基于注意力机制的机制,使序列中的每个元素能够直接关注其他所有元素 Fig.8 (a),从而消除了对循环或卷积的需求。这种设计促进了高效的并行计算,并使模型能够捕获全局上下文依赖关系。其核心注意力机制的数学定义如下:
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q,K,V)=\text{softmax}\left(\frac{QK^{T}}{\sqrt{d_{k}}}\right)V Attention(Q,K,V)=softmax(dkQKT)V
其中 Q Q Q、 K K K、 V V V 分别代表查询、键、值; d k d_{k} dk 是键向量的维数,充当稳定梯度的缩放因子。在自注意力机制下, Q Q Q、 K K K、 V V V 是根据同一输入序列计算得出的,这使得每个 token 能够根据所有其他 token 进行语境化。这种机制是 Transformer 在各种自然语言处理和视觉任务中取得成功的基础。
与 Transformer 的离散注意力机制不同,Diffusion Model 扩散模型提供了一个概率性的、噪声驱动的生成框架。这些模型通过两个阶段运行:一个是正向扩散阶段,它会逐渐用噪声破坏数据;另一个是学习到的反向过程,它会从噪声输入中重建数据Fig.8 (b)。正向扩散过程形成一个马尔可夫链,其中在每个时间步都会添加高斯噪声:
q ( x t ∣ x t − 1 ) = N ( x t ; 1 − β t x t − 1 , β t , I ) q(x_{t}|x_{t-1})=N(x_{t};\sqrt{1-\beta_{t}}x_{t-1},\beta_{t},I) q(xt∣xt−1)=N(xt;1−βtxt−1,βt,I)
其中 β t \beta_{t} βt 表示预定义的方差表, I I I 表示单位矩阵。模型学习近似的逆过程也遵循高斯分布:
p ( x t − 1 ∣ x t ) = N ( x t − 1 ; μ θ ( x t , t ) , ∑ θ ( x t , t ) ) p(x_{t-1}|x_{t})=N(x_{t-1};\mu_{\theta}(x_{t},t),\sum_{\theta}(x_{t},t)) p(xt−1∣xt)=N(xt−1;μθ(xt,t),θ∑(xt,t))
其中 μ θ \mu_{\theta} μθ 和 ∑ θ \sum_{\theta} ∑θ 由神经网络参数化,通常基于 U-Net 架构。通过对纯高斯噪声进行迭代去噪,扩散模型可以生成高保真输出,使其在图像生成、音频合成和其他结构化数据领域非常有效。
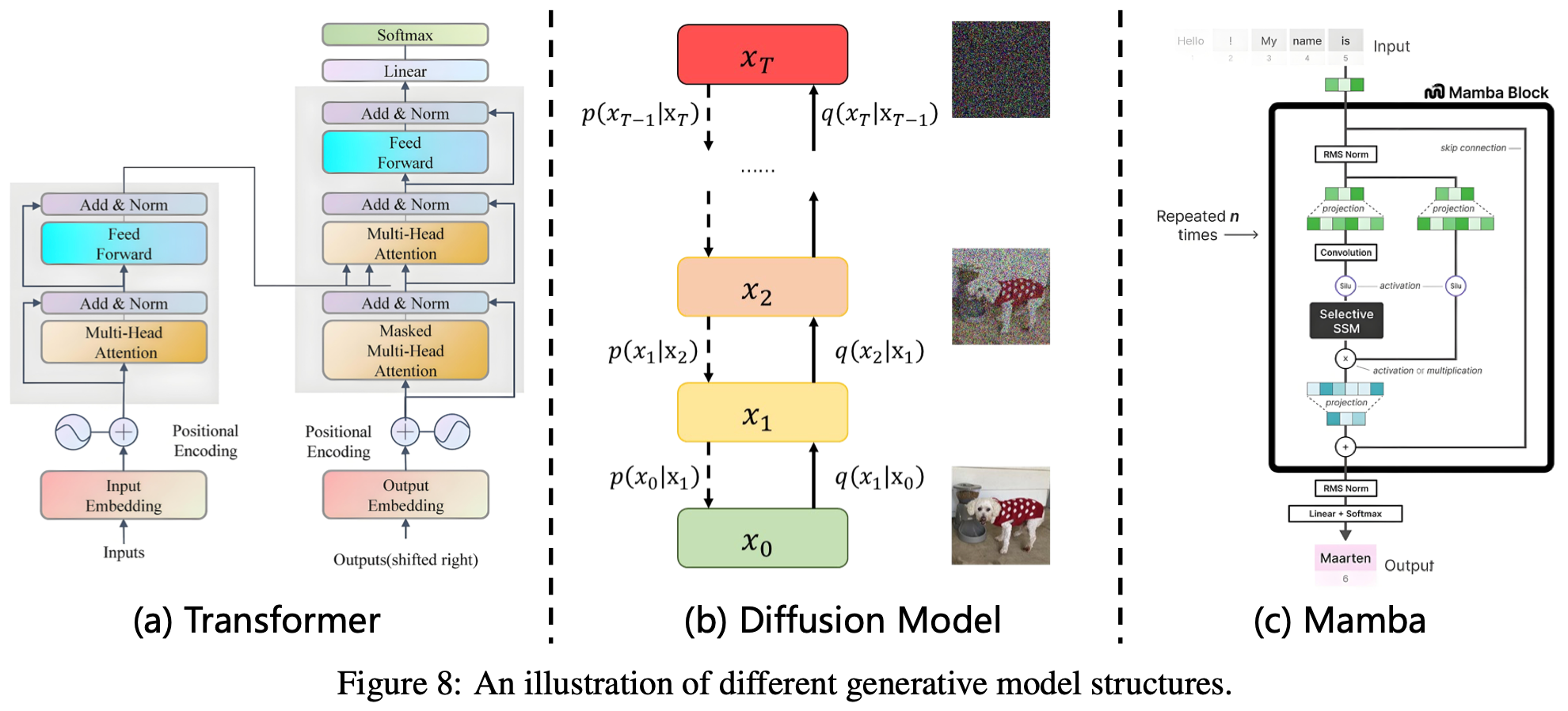
虽然 Transformer 和扩散模型取得了显著的成功,但这两种架构在扩展到长序列或复杂的生成过程时都遇到了限制。为了应对这些挑战,Mamba 架构引入了一种基于连续时间 SSM 的新方法,在长序列处理中提供了线性时间复杂度和更高的效率 Fig.8 (c)。Mamba 使用以下微分方程表示序列数据:
h ˙ ( t ) = A ( t ) h ( t ) + B ( t ) x ( t ) , y ( t ) = C ( t ) h ( t ) + D ( t ) x ( t ) \dot{h}(t)=A(t)h(t)+B(t)x(t),\quad y(t)=C(t)h(t)+D(t)x(t) h˙(t)=A(t)h(t)+B(t)x(t),y(t)=C(t)h(t)+D(t)x(t)
其中 h ( t ) h(t) h(t) 为隐藏状态; x t x_{t} xt 和 y ( t ) y(t) y(t) 分别表示输入和输出信号; A ( t ) A(t) A(t)、 B ( t ) B(t) B(t)、 C ( t ) C(t) C(t) 和 D ( t ) D(t) D(t) 是可学习的、与时间相关的系统参数。在大多数实际场景中, D ( t ) D(t) D(t) 设置为零,引入跳过连接以改善梯度流。通过离散化连续系统并引入选择性扫描机制,Mamba 实现了卓越的推理效率和可扩展性。这些特性使其成为涉及远程依赖和实时计算的任务的引人注目的替代方案。总而言之,Transformer、扩散模型、像 Mamba 这样的 SSM 代表了生成建模的三大架构方向。这些范例各自在表达力、效率和适用性方面提供了独特的优势,理解它们的设计原理对于下一代生成系统的开发至关重要。
3. Single-Agent Embodied AI
具身人工智能的主流研究主要集中于单智能体设置,即单个智能体在静态环境中运行以完成各种任务。在此背景下,现有方法大致可分为经典方法和基于现代学习的技术。早期的研究主要依赖于知识驱动、针对特定任务的规划和控制策略。然而,随着智能体越来越多地部署在动态和非结构化的环境中,手动设计针对每种场景的定制规划器和控制器已变得不可行。因此,基于学习的方法具有固有的适应性,并且在各种任务中具有强大的泛化能力,已成为在复杂动态环境中赋予具身智能体的主流范式。近年来,生成模型的进步进一步增强了具身智能体的潜力,使其能够表现出更具适应性、适用范围更广的行为。
3.1 Classic Control and Planning
为了在物理世界中完成长远任务,具身智能体必须有效地规划和控制其运动,并生成基于感知和特定任务输入的轨迹。经典的规划方法大致可分为基于约束、基于采样、基于优化的方法。基于约束的方法将任务目标和环境条件编码为逻辑约束,将规划领域转化为符号表示,并采用符号搜索等约束求解技术来识别可行的解决方案。然而,这些方法通常侧重于可行性而非解决方案的质量,往往忽略了最优性。此外,当感知输入为高维或结构复杂时,约束求解的复杂性会显著增加。基于采样的方法通过随机采样技术逐步探索可行解空间来解决这些限制,例如快速探索随机树 (RRT) 及其变体,逐步构建树或图结构以发现可行的运动轨迹。
为了进一步优化可行域内的运动规划,基于优化的方法将任务目标和性能指标明确建模为目标函数,同时将可行性条件表示为硬约束。然后利用高级优化技术在受限的解空间内搜索最优解。代表性的基于优化的方法包括多项式轨迹规划、MPC 和OC。其中,多项式轨迹规划通常计算成本相对较低,能够确保实时响应和平滑的轨迹生成,特别适合复杂场景下的自主导航任务。相比之下,MPC和OC方法更适合需要时间最优机动的高度受限场景,例如无人机操作期间的防撞。如Fig.9所示,文献引入了一个积极的、包含碰撞的运动规划框架,该框架策略性地利用碰撞来提高受限环境中的导航效率。该方法集成了一个增强型包含碰撞的快速探索随机树 (ICRRT) 用于生成可变形运动原语,以及一个由滚动时域决策 (RHD) 策略指导的轨迹优化方法,用于自主处理碰撞。实验结果证明了该方法的有效性,与传统的无碰撞方法相比,任务完成时间显著缩短(约 58.2%),凸显了其在实际应用中的巨大潜力。
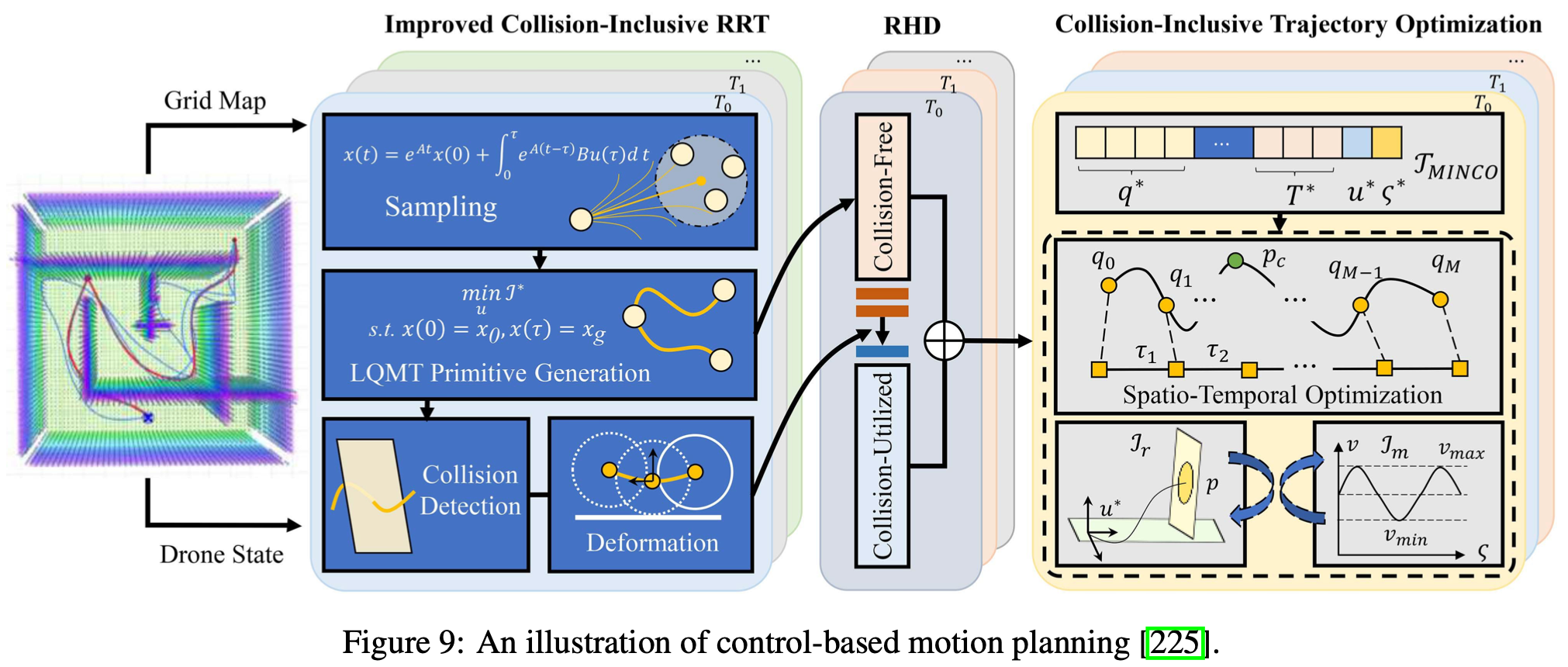
3.2 Learning based Methods
传统的控制和规划方法因其能够提供高精度解决方案而长期被用于受约束的实时决策。然而,这些方法通常计算量大,限制了可扩展性、响应能力,尤其是在高维、非线性或非平稳系统中。此外,它们通常对未见过的场景或动态变化的环境表现出较差的泛化能力。为了克服这些限制,基于学习的决策范式越来越受到关注,旨在通过直接从交互式数据中学习来提供具有改进的鲁棒性和泛化能力的实时性能。end-to-end 端到端 RL 已成为一种突出的方法,因为它能够通过与环境的交互实现直接的策略优化。然而,在具有复杂目标或大型状态动作空间的任务中,由于探索空间过大,端到端 RL 存在样本效率低和训练时间过长的问题。为了缓解这一问题,Hierarchical RL 分层强化学习应运而生,Hierarchical RL将复杂任务分解为一系列更简单的子任务,从而提高学习效率和可扩展性。尽管取得了这些进展,但端到端和分层强化学习方法从根本上都依赖于精心设计的奖励函数,而这些奖励函数在现实环境中通常难以定义或不切实际。在这种情况下,IL 提供了一种极具吸引力的替代方案,它使智能体能够直接从专家演示中获取有效策略,从而规避了显式奖励工程的需要,并促进了实践中更快的部署。
End-to-end learning
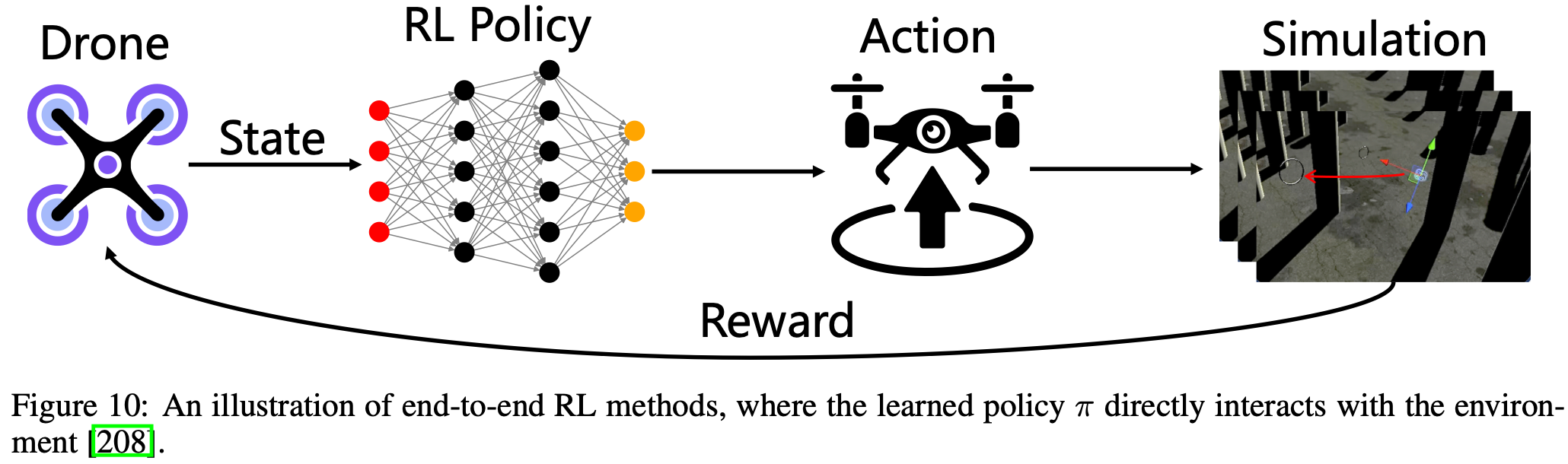
在复杂的环境中,OC 问题通常表现出非凸性,这使得经典的规划和控制方法难以在合理的计算时间内找到可行的解决方案。解决此问题的一种自然方法是以端到端的方式优化整个系统,利用强化学习技术通过神经网络将感知信息直接映射到行动决策。这些方法通过最大化 (3) 中定义的预期累积奖励来优化策略,从而确保稳定且高频的控制输出Fig.10。因此,端到端学习被广泛认为是实现具身人工智能的终极途径,因为它消除了手动分解、对齐和调整单个模块的必要性,使智能体能够将原始感知输入直接转化为有效的动作。事实上,端到端强化学习已经在配备多模态输入的各种机器人平台上取得了令人瞩目的表现,包括无人机、自动驾驶汽车、机械臂、足式机器人。
Hierarchical learning
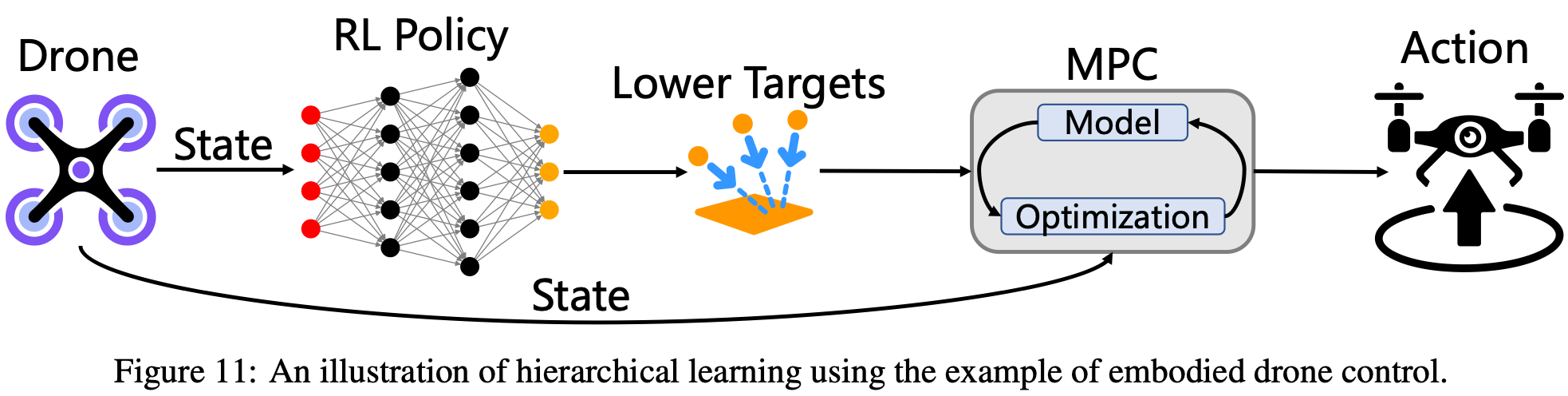
在处理目标复杂或状态-动作空间较大的任务时,端到端强化学习 (RL) 常常面临样本效率低和训练时间延长等挑战,因为探索空间过大。为了解决这个问题,研究人员经常采用将强化学习与经典控制方法相结合的分层框架。在这样的框架中,强化学习通常负责高级规划或策略生成,而鲁棒的低级控制器(例如模型预测控制 (MPC) 或比例积分微分 (PID) 控制器)则执行精确可靠的动作指令。这种分层方法使具身智能体能够有效地解决具有挑战性的非结构化问题。例如,仅凭经典方法,引导无人机在最短时间内通过动态摆动的闸门尤其困难Fig.11,因为闸门的位置会随着时间推移而变化,因此定义一个固定的优化目标并不切实际。相反,强化学习可以学习确定中间目标状态和 MPC 规划范围的策略,利用由遍历成功率和时间塑造的奖励信号来生成高效的轨迹。此外,当门控动态未知时,可学习的混合系数可以动态调整控制策略,基于实时状态信息实现追踪行为和通过行为之间的平滑过渡,从而增强轨迹的连续性。此外,精心构建的层次化设计可以自然地扩展此框架,以支持复杂具身场景中的多智能体协作任务。
Learning from demonstrations
与有机认知方法不同,强化学习(RL)等基于学习的方法需要通过反复试验与环境交互来收集大量数据,这在现实世界的具身化环境中成本高昂。此外,强化学习通常严重依赖精心设计的目标函数或奖励信号,由于灵活性和适应性的必要性,在复杂且非结构化的环境中准确指定这些函数或奖励信号变得具有挑战性。在这些情况下,从专家演示中学习(通常称为 IL)是一种更实用的替代方案。例如,使用经典的 IL 方法 BC 成功地将绘画策略从模拟器迁移到现实世界的机械臂,展示了高水平的绘画和书法技巧,如Fig.12 所示。除此之外,一系列更先进的 IL 技术已被引入,以进一步增强具身智能,提高泛化能力和鲁棒性,包括交互式 IL、约束 IL、IRL。

3.3 Generative Model Based Methods
传统的学习方法尽管取得了进展,但往往受限于表征能力,不足以处理多目标或多任务决策等复杂场景。这些方法通常存在学习性能不佳、外部先验知识利用效率低以及样本效率低等问题。为了应对这些挑战,研究人员开始探索利用表征能力更强的生成模型,以实现更高效、更灵活的具身智能。生成模型最直接的应用是充当端到端控制器,直接输出可执行动作,从而将其内部先验和预训练知识迁移到具身系统中。然而,许多具身智能任务涉及细粒度的低级行为,生成模型通常难以理解和有效控制这些行为。受分层学习原理的启发,越来越多的研究采用生成模型来生成高级计划,同时依赖传统的控制或基于学习的方法来执行低级技能。除了直接决策之外,生成模型也被广泛用于支持学习过程。其应用包括整合感知信息以实现感知、生成奖励函数、合成数据以提高样本效率。
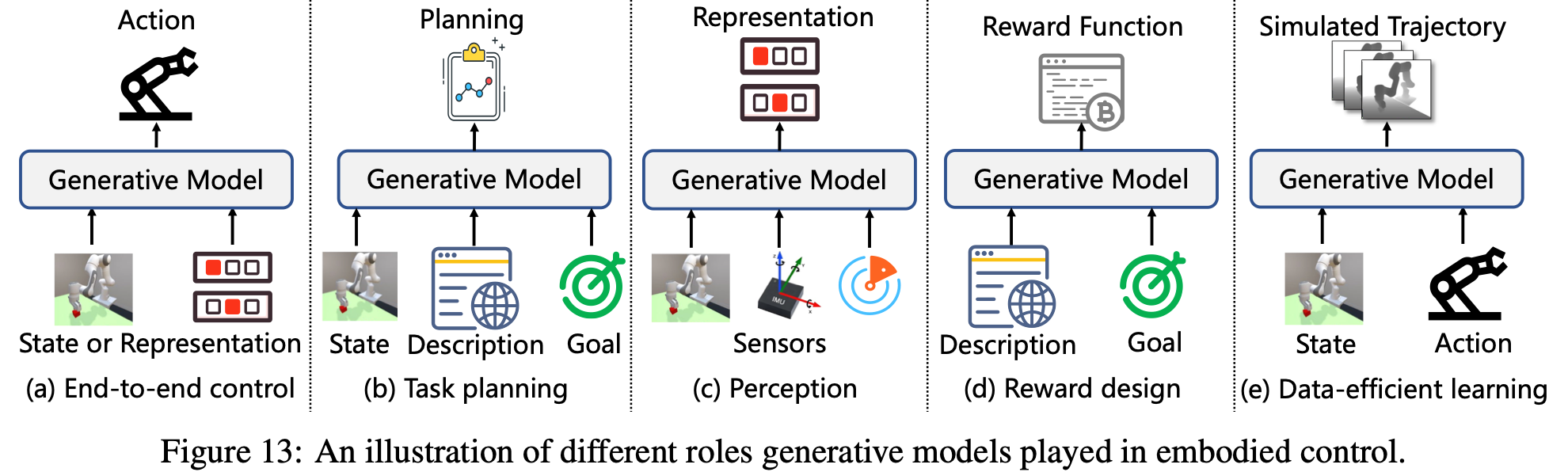
End-to-end control
为了在决策过程中加强对先验知识的利用和对复杂、多模态观察的处理,越来越多的研究探索使用生成模型作为直接决策者,特别是大型 VLM,如Fig.13 (a)所示。早期的方法通常涉及将状态和目标等输入格式化为自然语言,并将其输入到预训练的生成模型中,从而无需额外训练即可进行动作推理。然而,由于预训练期间涵盖的场景范围有限,这些模型通常难以推广到广泛的现实世界决策任务。因此,更多的研究集中于使用领域特定数据对生成模型进行微调,或将它们与其他网络集成,以实现领域知识和生成能力的更有效地融合。
Task planning
由于生成模型在理解许多任务的低级控制方面能力有限,以及进行特定领域微调所需的大量资源和成本,直接采用预训练生成模型进行高级任务规划是一种更简单、适用范围更广的方法,利用预训练生成模型固有的推理和反思能力,这些模型可以在接收环境描述、状态和目标等输入后,通过迭代推理和反射过程有效地生成面向目标的计划,如Fig.13 (b)所示。例如,对于“倒一杯水并放在桌子上”这样的高级任务,LLM 可以将其分解为清晰的可操作步骤序列:(S1) 从桌子上拿起杯子;(S2) 找到饮水机;(S3) 将杯子对准饮水机的出水口;(S4) 启动饮水机并等待杯子装满;(S5) 将装满的杯子放回桌子上。同时,近年来,具身人工智能规划的安全性也越来越受到关注。
Perception
除了决策之外,生成模型强大的表达能力也使其能够有效地协助具身智能体进行环境感知。例如,HPT 利用 Transformer 架构强大的序列处理能力,融合从图像、IMU 传感器和雷达等各种来源跨多个时间步收集的传感数据,生成高效的观测表征,如Fig.13 (c) 所示。类似地,许多方法利用 Transformer、扩散模型、Mamba 架构进行感知融合。此外,利用预训练的 VLM 对多模态感知数据进行语义理解,为支持具身智能体执行感知任务提供了另一种有效方法。
Reward design
为了应对在复杂的现实场景中设计高质量奖励函数的挑战,利用预先训练的生成模型进行奖励设计也成为一种有效的方法,可以帮助具身智能体学习感知之外的策略。奖励设计方法大致可以分为奖励信号生成和奖励函数生成。在奖励信号生成方法中,生成模型在每个决策步骤接收状态、动作和目标信息,实时产生奖励信号。虽然这种方法提供了灵活性并允许动态适应环境变化,但由于在训练期间频繁调用生成模型,因此会产生大量的计算成本;奖励函数生成方法只需要在训练前对生成模型进行几次预训练调用,即可根据任务描述和目标生成奖励函数,如Fig.13 (d) 所示。在训练过程中,每一步都采用奖励函数而不是生成模型,从而显著减少计算开销。
Data-efficient learning
此外,由于真实物理环境中的交互成本高昂,且机器人操作中的错误可能导致物理损坏或系统故障,因此采用生成模型生成数据以提高样本效率是辅助策略学习的另一种重要方法。基于 Transformer 模型和扩散模型等生成模型架构学习世界模型,并通过这些世界模型生成数据,是提高样本效率的主流方法,如Fig.13 (e)所示。在高级语言抽象环境中,一些方法直接使用预训练的生成模型作为未来轨迹预测的世界模型。另一类方法不是学习显式的世界模型,而是利用生成模型创建多样化的模拟环境,通过智能体与模拟环境的交互生成额外数据。
3.4 Benchmarks
尽管具身智能体是为现实世界中的交互任务而设计的,但基准测试在标准化性能测量、引导研究重点和降低现实世界测试成本方面仍然发挥着至关重要的作用。近年来,具身人工智能基准测试的开发取得了长足的进步。Table.2中总结了几个具有代表性的示例,并在Fig.14中进行了展示。列出的基准测试包括:


- ALFRED:该基准旨在评估具身智能体通过一系列物理交互来理解和执行自由形式自然语言指令的能力。该基准基于 AI2-THOR 模拟器构建,包含 120 个视觉和功能各异的家庭场景,智能体在这些场景中被赋予完成涉及导航、物体操控和不可逆状态改变的目标的任务。这些任务涵盖七大类家庭活动,并涉及 58 种不同的物体类型。为了支持学习和评估,该数据集提供了 25,743 条人工编写的指令和 8,055 条专家演示。智能体通过以自我为中心的 RGB-D 输入感知环境,并使用一组预定义的 13 个离散低级动作来采取行动。交互目标通过像素级掩码定义,用于指导对象级行为。任务性能主要基于目标完成情况进行评估,基准包含支持可重复研究所需的所有代码、注释和环境资产;
- RoboTHOR:是一个面向具身人工智能的“sim-2-real”平台,提供配对的模拟和物理环境,旨在实现跨领域一致性评估。它包含 75 个训练和验证场景,以及 24 个测试场景(其中 14 个用于测试开发,10 个用于测试标准),所有场景均基于支持灵活重新配置和扩展的模块化资产库构建。代理通过统一的 AI2-THOR API 与环境交互,并可远程部署在 LoCoBot 机器人上,其噪声动态与模拟中的动态非常匹配。该基准测试以语义导航任务为中心,使用虚拟和物理环境中的成功率、声压级 (SPL) 和路径效率来评估性能。为了促进可重复研究,所有代码、资产和远程访问基础设施均已公开发布;
- RobustNav:是一个面向具身人工智能的“sim-2-real”平台,提供配对的模拟和物理环境,旨在实现跨领域一致性评估。它包含 75 个训练和验证场景,以及 24 个测试场景(其中 14 个用于测试开发,10 个用于测试标准),所有场景均基于支持灵活重新配置和扩展的模块化资产库构建。代理通过统一的 AI2-THOR API 与环境交互,并可远程部署在 LoCoBot 机器人上,其噪声动态与模拟中的动态非常匹配。该基准测试以语义导航任务为中心,使用虚拟和物理环境中的成功率、声压级 (SPL) 和路径效率来评估性能。为了促进可重复研究,所有代码、资产和远程访问基础设施均已公开发布;
- Behavior:是评估具身人工智能代理在虚拟交互环境中日常家务活动中表现的基准。它使用基于谓词逻辑的语言定义了100个现实、多样且复杂的家务,并支持iGibson 2.0中无限的场景无关实例。该基准包含500个真人VR演示,并提供评估指标,例如成功率、任务效率和以人为本的表现。所有代码、任务定义和数据均公开可用,以促进具身人工智能领域的可重复研究;
- ManiSkill2:是通用机器人操作的统一基准,包含 20 个任务系列,涵盖固定和移动平台、单臂和双臂设置以及刚体和软体交互。它包含 2000 多个对象模型和超过 400 万个演示帧。该套件支持点云、RGB-D 和基于状态的输入,并在关节和末端执行器级别进行控制。ManiSkill2 基于 SAPIEN 引擎构建,并通过 OpenAI Gym 进行接口,具有异步渲染和基于 Warp MPM 的软体模拟器,可实现高通量数据收集。开源代码库和在线挑战平台支持跨感知-规划-执行流程、强化学习和学习集成方法的可重复评估;
- EgoCOT & EgoVQA:提供2900小时以自我为中心的人与物体交互视频片段,并附带385万条机器生成、语义过滤和人工验证的思维链规划指令。EgoVQA则提供2亿个视频-问答对,这些视频-问答对由Ego4D语料库自动生成并经过CLIP过滤。这两个数据集共同构建了一个统一的大规模基准,用于在现实第一人称场景中对具身规划、控制和视觉问答进行端到端评估;
- HumanoidBench:是一个针对人形机器人的高维模拟基准,包含 27 项任务,包括 15 项全身操控任务(例如,卡车卸货、接球投篮)和 12 项运动任务(例如,跑步、迷宫导航)。该基准使用配备双影子手的 Unitree H1 人形机器人,产生 61 维的动作空间和 151 维的观察空间。它基于 MuJoCo [176] 构建,能够对平面和分层强化学习方法的成功率、效率和鲁棒性进行标准化评估。其开源代码库和统一的接口支持在复杂的人形机器人控制和学习中进行可重复的研究;
- Open X-Embodiment:该基准测试汇集了从 22 个不同的机器人实例中收集的超过一百万条真实机器人轨迹,涵盖总共 60 个数据集。所有轨迹都被转换为统一的 RLDS 格式,以确保跨平台的一致性和互操作性。为了支持广泛的应用和可重复的研究,该基准测试提供了标准化的 API、一套开源工具和预训练的 RT-X 模型检查点,从而能够跨不同的实例和任务领域高效地训练、评估和比较通用机器人策略;
- OpenEQA:是首个具身问答开放词汇基准,包含 1600 多个基于 180 多个真实世界扫描环境的人工编写问题。它支持两种评估范式——情景记忆和主动探索——其中代理通过 RGB-D 输入感知环境,并必须推理空间、语义或时间线索。代理性能使用自动化的 LLM-Match 协议进行评估,该协议能够对复杂 3D 环境中开放式、语言驱动的理解进行一致且可重复的评估;
- EAI:是用于评估具身环境中LLM驱动决策的标准化基准。它使用线性时序逻辑将任务目标形式化,并将决策过程构建为四个核心模块:目标解释、子目标分解、动作排序和转换建模。每个模块都使用语法正确性、幻觉频率、步骤完整性和排序准确性等细粒度指标进行评估。该基准基于BEHAVIOR和VirtualHome实现,并结合了自动化子任务检查器以及基于PDDL的规划器,从而能够对18个LLM进行系统性评估和可重复性比较,以将自然语言指令转换为可执行计划;
- ReALFRED:是一个逼真的具身指令遵循基准,旨在弥合模拟与现实世界复杂性之间的差距。它包含 150 个多房间 3D 扫描交互式环境,以及 30,696 条人工注释的自然语言指令和规划器生成的专家演示,涵盖七个家庭任务类别。评估基于任务成功率和执行效率的标准化指标,涵盖正确性和行为质量。为了支持可重复的研究,ReALFRED 提供了开源代码和完整的数据集,用于研究现实环境中的视觉和语言条件决策;
- PhysBench:是一项大规模基准测试,旨在评估视觉语言模型 (VLM) 对现实场景中物理概念的理解能力。它包含 10,002 个多选题实例,涵盖视频、图像和文本模态,涵盖四个核心领域:物理对象属性、对象关系、场景理解和物理动力学。这些领域进一步细分为 19 个细粒度的子任务类型,从而能够对模型在物理推理各个方面的能力进行详细评估。该数据集由真实世界视频记录、网络媒体和高保真物理模拟组合而成。为了确保评估的公平性和可重复性,PhysBench 提供了一个在线平台,其中包含未公开的测试答案,允许对 75 个具有代表性的视觉语言模型 (VLM) 进行标准化比较;
4. Multi-agent Embodied AI
现实世界中的具身任务通常涉及多个智能体或人机协作与竞争。在共享环境中,智能体之间的动态交互会产生个体无法独自完成的群体层面的突发行为。因此,将为单智能体环境设计的方法直接迁移到MAS通常效率低下。MAS的研究主要侧重于实现有效的协作。本文将从与第三节中单智能体环境相同的三个方面回顾多智能体协作的最新进展:控制与规划方法、基于学习的方法和基于生成模型的方法,典型方法列于Table.3。

4.1 Multi-agent Control and Planning
在MAS中,基于控制的方法仍然是在任务约束下实现高精度实时决策的基本途径。早期方法将MAS建模为单个智能体,并执行集中控制和规划。然而,这些方法面临着巨大的可扩展性挑战。为了解决这个问题,一些方法采用分布式策略,独立控制MAS中的每个智能体,使其更适合大规模智能体系统。然而,这种分散式方法往往难以解决智能体之间的冲突。为了克服这些局限性,EMAPF提出了一个分组多智能体控制框架。它根据智能体的空间接近度动态地对其进行聚类,在每个组内应用集中控制,同时确保组间控制保持独立,如Fig.15所示。这使得大型空中机器人团队能够高效协调。
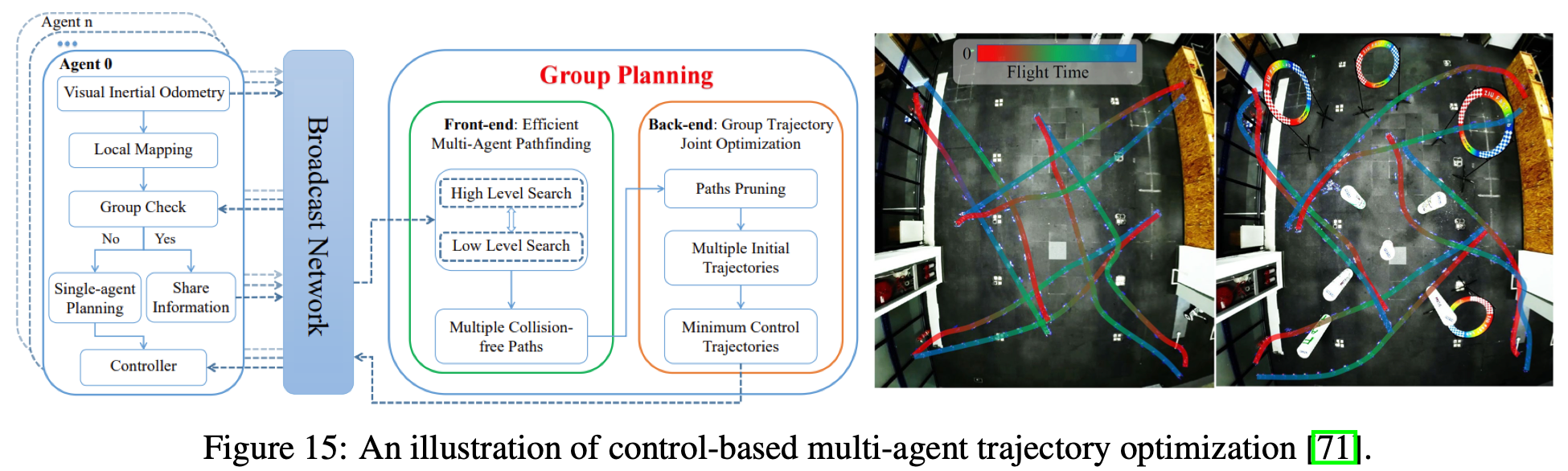
4.2 Learning for Multi-agent Interaction
与单智能体场景类似,MAS 中基于控制的方法仍然面临着计算开销高和泛化能力有限等挑战。因此,基于学习的方法在多智能体具身化人工智能中仍然至关重要。然而,与单智能体环境不同,MAS 中基于学习的方法还必须应对一些独特的挑战,包括异步决策、异构智能体、开放的多智能体环境。
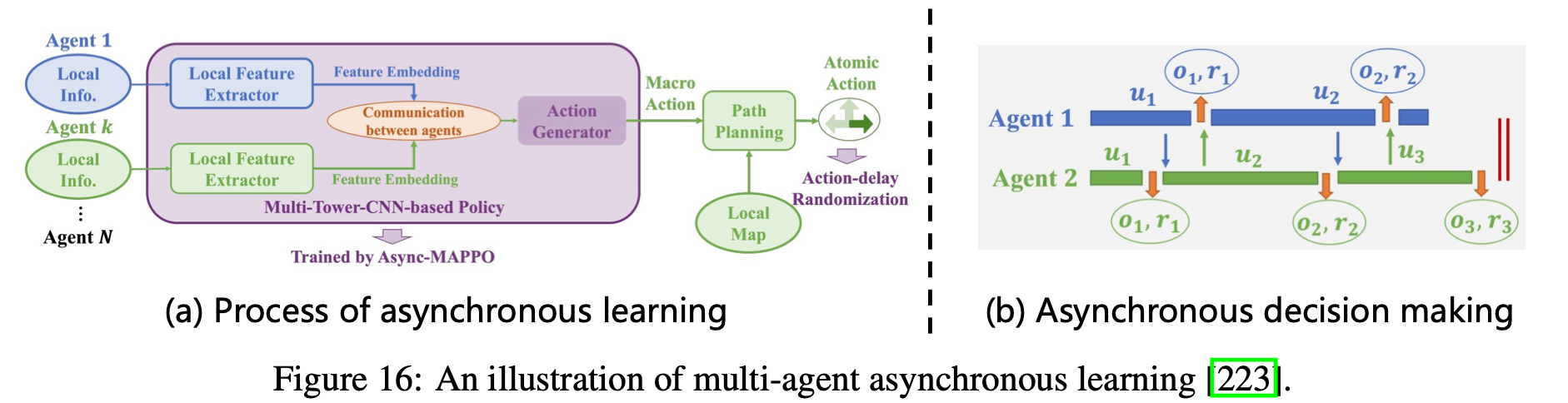
Asynchronous collaboration
在多智能体具身智能中,诸如通信延迟和跨智能体硬件异构性等挑战常常会扰乱来自真实环境的同步交互和反馈,这使得在异步决策下进行有效的策略学习成为一项重大挑战。为了解决这个问题,ACE 引入了宏动作的概念,其中宏动作作为整个 MAS 的中心目标。然后,各个智能体基于此目标做出多个异步决策,并且仅在宏动作完成后才会提供来自环境的延迟反馈。为了促进这种设置下的策略学习,ACE 采用了基于宏动作的 MAPPO 算法,如Fig.16所示。这种方法已被证明是有效的,并启发了其他一些应对异步决策挑战的研究。
Heterogeneous collaboration
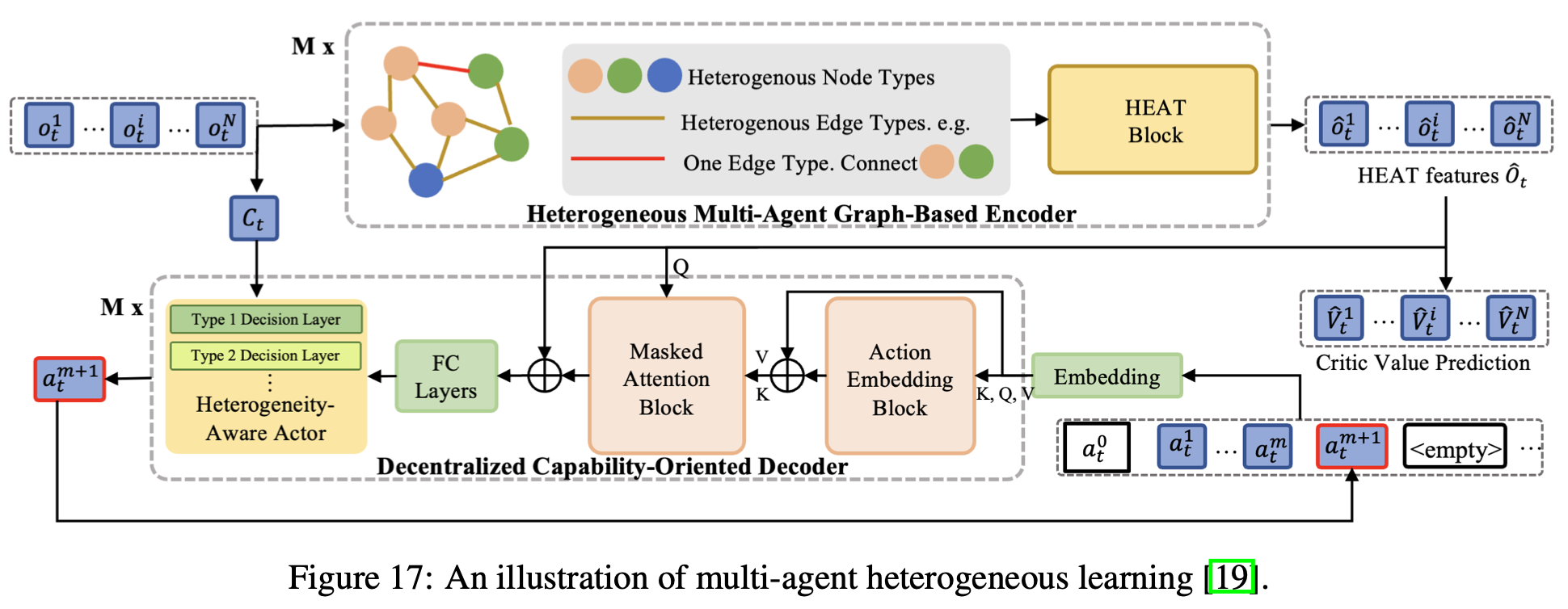
除了决策时机的差异之外,具身MAS的另一个关键区别是智能体异质性。这指的是智能体在感知能力、行动空间、任务目标、物理属性、通信能力、决策模型方面的差异。例如,在协同制造场景中,自动驾驶汽车可能负责运输货物,而机械臂则负责分拣任务。这两类智能体在观测空间、行动空间和任务目标上存在显著差异,使其成为异质智能体的典型例子。为了应对观测和行动空间差异带来的挑战,HetGPPO 和 COMAT 等方法建议为不同类型的智能体使用单独的观测网络和策略网络,这些网络通过基于图的通信连接,从而实现有效的信息交换,如Fig.17 中 COMAT 的架构所示。另一种方法侧重于调整学习算法本身,例如通过在异质智能体之间分解优势函数,以促进更有效的信用分配。
Self-evolution in open environments
与定义明确的模拟场景不同,现实世界的具身任务通常发生在开放环境中,其中任务目标、环境因素(例如状态、动作和奖励函数)、协作模式(例如队友和对手)等关键要素会不断且不可预测地发展。为了应对 MARL 中的这些挑战,研究人员提出了稳健训练和持续协调等方法,并取得了有希望的结果。然而,具身场景中开放环境的不可预测性带来了更大的困难,需要超越传统 MARL 技术的专业方法。最近一些文章利用生成模型强大泛化能力的创新解决方案。例如,当协作者的数量动态变化时,图神经网络 (GNN) 和 Transformer 等可扩展架构可以有效地编码交互信息,如Fig.18 所示。通过将这些架构与分布式策略网络相结合,智能体可以无缝适应团队规模的波动,确保稳健的协调。此外,通过结合自我博弈和其他自我反思和策略演进机制,MAS 可以在动态开放的环境中持续提升协作绩效。

4.3 Generative Models based Multi-agent Interaction
尽管针对异步决策、异构智能体、开放环境设计的算法在多智能体具身化人工智能中已经取得了基于学习的进步,但由于å合作行为的多样性以及观测数据的部分或缺失性质,挑战依然存在,导致探索效率低下和学习复杂度增加。为了解决这些问题,生成模型已成为增强多智能体具身化系统决策能力的有力工具。它们可以引入先验知识来促进明确的任务分配,并利用其强大的信息处理能力来实现智能体间通信和观测完成,从而实现分布式决策。此外,多智能体系统不仅可能涉及自主智能体,还可能涉及人类。通过利用生成模型的语言理解和生成能力,可以显著改善人机交互和协作,这标志着该领域一个独特而关键的应用。最后,多智能体环境中显著更大的探索空间使得样本效率的挑战比单智能体场景更加突出。因此,基于生成模型的数据增强技术对于提高多智能体体现人工智能中的数据效率至关重要。
Multi-agent task allocation
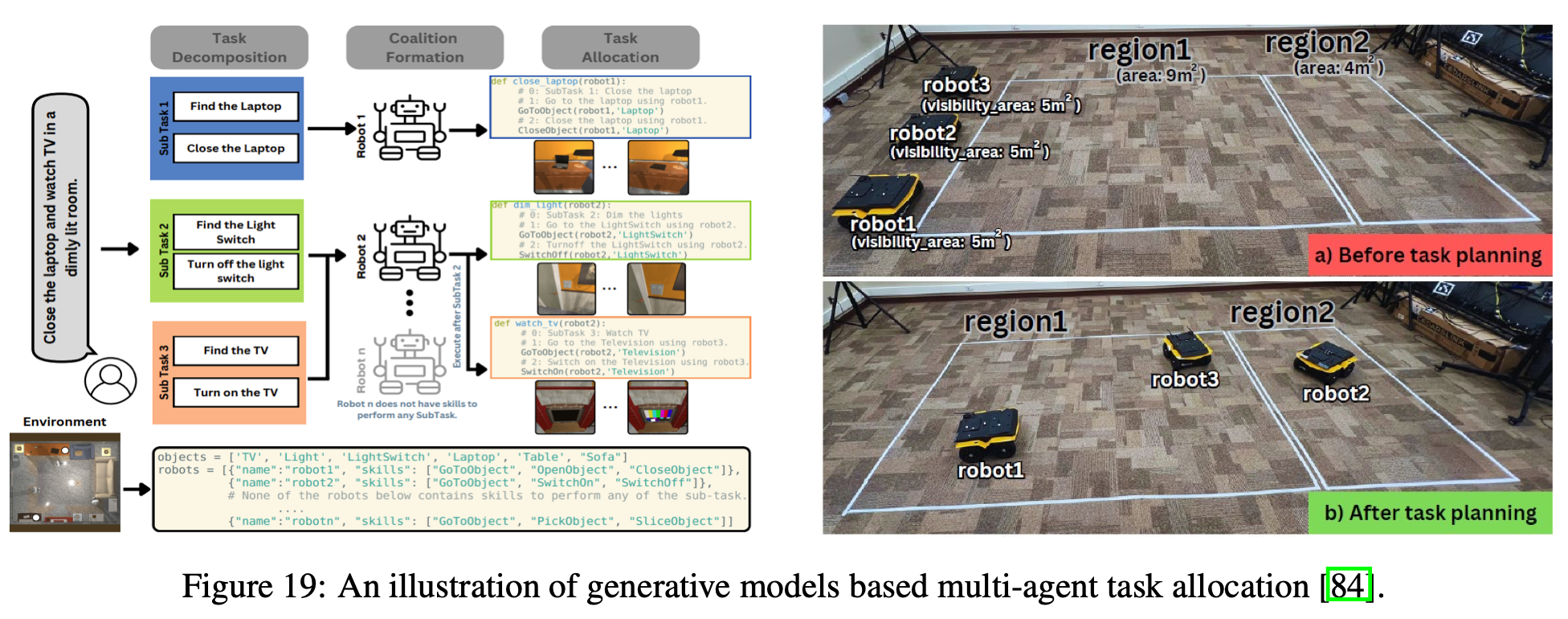
为了应对多智能体具身人工智能中多样化协作行为带来的挑战,越来越多的研究开始利用预训练生成模型的先验知识和推理能力,将不同的任务明确地分配给不同的智能体,从而显著减少了每个智能体的探索空间。例如,SMART-LLM 利用预训练语言模型,首先将给定任务分解为多个并行的子任务,然后根据智能体的能力对其进行分组;随后,任务被相应地分配给各个组,例如,可以在不同的机器人吸尘器之间划分清洁区域,如Fig.19 所示。这种任务分解和分配的范式已成为多智能体具身人工智能中的主流规划策略。在此基础上,一系列研究将任务分配和执行整合在一起。这些方法首先使用生成模型进行任务分配,然后继续使用相同或相似的模型执行任务,并根据执行结果调整分配,以形成更完整的工作流程。然而,上述方法通常仅关注基于生成推理的任务分配,往往忽略了子任务之间的依赖关系。例如,在“从封闭的盒子中取出扳手”的任务中,必须先完成“打开盒子”的子任务,然后才能“从盒子中取出扳手”。为了更好地捕捉这种依赖关系,最近的研究开始探索使用子任务依赖图来增强任务分配。除了显式的任务分解外,另一项研究采用集中式生成模型来生成全局决策。然后,通过让每个代理模仿集中式模型生成的行为,将这些决策隐式地分配给各个代理,从而实现隐式任务分配。
Multi-agent distributed decision making
使用生成模型进行多智能体具体化任务分解和规划,可以利用预训练过程中获得的先验知识和推理能力,满足现实世界协作任务的需求。然而,集中式任务规划和分配会损害合作的灵活性和可扩展性,通常需要频繁召回进行调整。因此,探索多个生成模型之间的协调至关重要。与 MARL 中经常在复杂任务中失败的独立方法不同,生成模型出色的感知和推理能力使得部署多个基于 LLM 的智能体成为可能,这些智能体可以独立有效地执行决策和策略评估。例如,为每个智能体配备了自己预先训练的生成模型。这些模型利用其强大的信息处理能力与其他智能体通信,以完成缺失的观察或请求协助,从而促进分散协作,如Fig.20 所示。然而,诸如信用分配和策略冲突等挑战仍然阻碍着完全分布式协作架构的有效性。因此,与 MARL 中的实践类似,一些研究开始加入一个额外的集中式生成模型来评估分布式生成模型所做的决策,从而增强其整体决策能力。此外,通过引入一个基于 LLM 的共享全局反射器来评估协作过程中每个人的贡献,还可以实现多 LLM 合作中的有效信用分配。通过适当设计的系统拓扑和分层协作框架,基于生成模型的分布式决策能够扩展到包含多达数千个智能体的大规模系统。
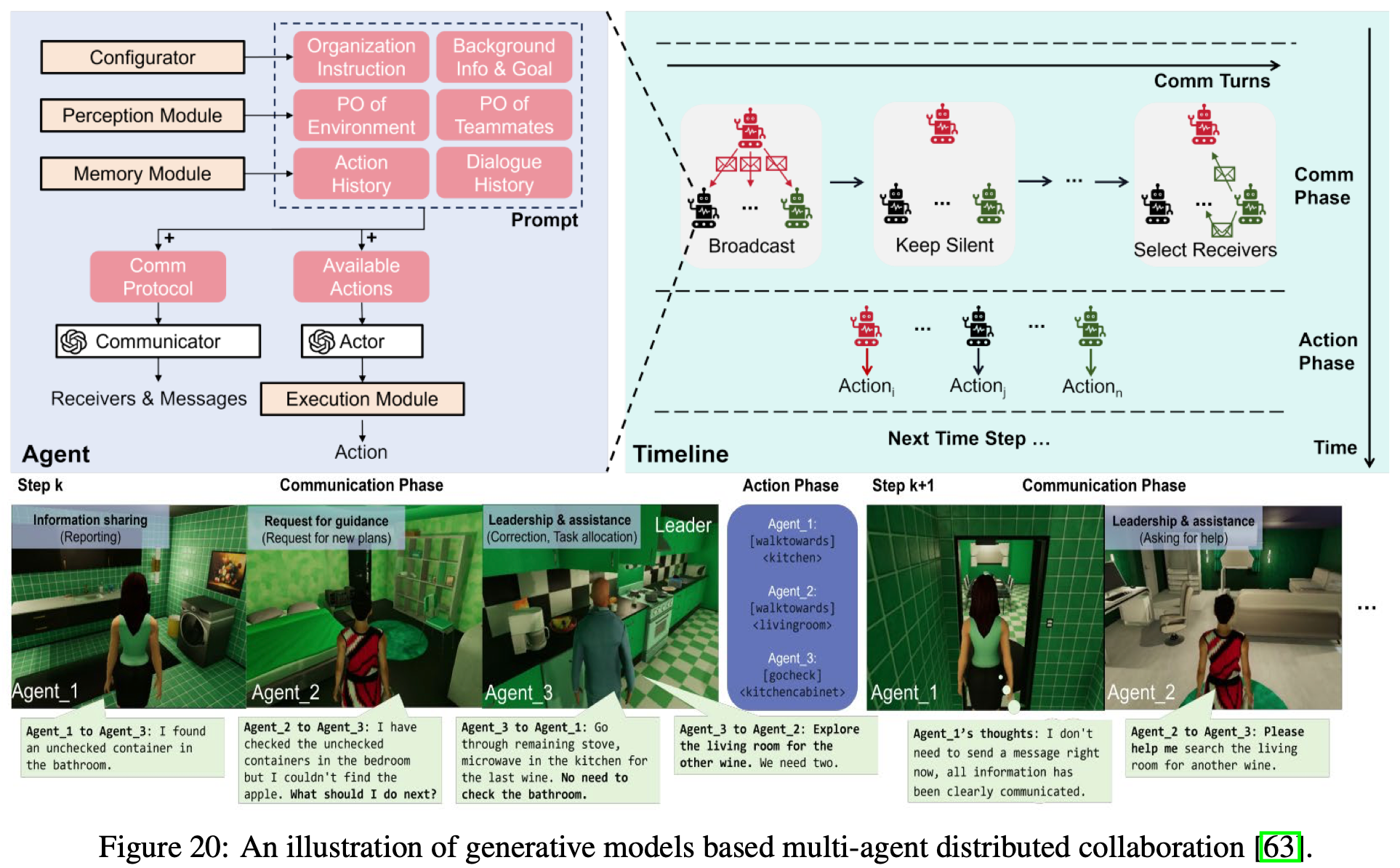
与传统的集中式或分散式具身协作框架相比,生成模型具有独特的优势:它们允许智能体之间进行协商。与智能体每一步都进行一次规划的传统协作流程不同,多个 LLM 能够在每个规划阶段进行迭代协商,旨在共同确定最佳行动方案。除了传统的协调之外,多 LLM 协商使具身 MAS 能够动态地选择和发展其成员资格、组织框架和领导角色,从而增强其在开放环境中处理复杂任务的能力。
Human-AI coordination
人类与人工智能体(机器人)之间的高效协作长期以来一直是人工智能研究的关键目标。人机协调与人机交互 (HAI) 和人机交互 (HRI) 等研究领域密切相关,致力于增强人类与人工智能体之间的团队合作,以有效地完成复杂任务。合作型多任务学习 (MARL) 以其强大的问题解决能力而受到认可,为改善不同用户群体之间的人机协作提供了有希望的途径。然而,传统的强化学习方法往往无法充分捕捉人类行为固有的复杂性和多变性。最近,随着多模态大规模模型(尤其是 LLM)的兴起,这些模型本质上涉及人在环的训练过程,研究人员已经开始利用这些模型中嵌入的广泛知识来设计复杂且自适应的人机协作策略,如Fig.21 所示。
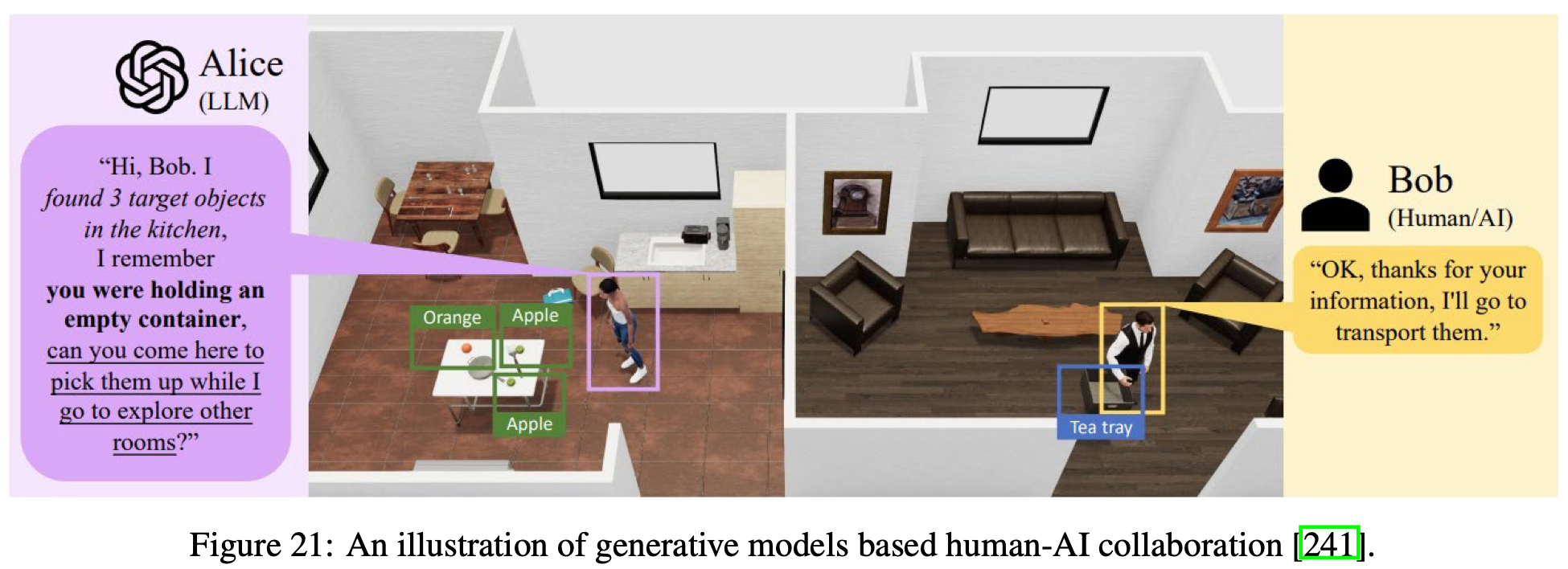
在基于多 LLM 的代理场景中,可以通过用人类参与者代替沟通伙伴或团队领导来部分促进人类与人工智能代理之间的协作。然而,这种方法往往没有充分利用人类在协作过程中的优势。鉴于人类卓越的理解、推理、适应能力,最近的方法强调人类的积极参与,以解决基于 LLM 的代理固有的局限性。例如,在导航任务中,遇到不确定性的代理可以通过自然语言查询主动向人类寻求缺失的感知或决策信息,从而使人类无需直接参与详细的任务规划或执行即可提供指导。此外,基于 LLM 的代理可以根据言语和行为线索主动推断人类的意图,从而无需明确的沟通请求,即可促进更直观、灵活和有效的人机协作。此外,这些代理可以随着时间的推移自主地调整和改进其协作行为,通过交互进行演变,而无需明确的人类指令,从而支持持续有效的长期人机协作。
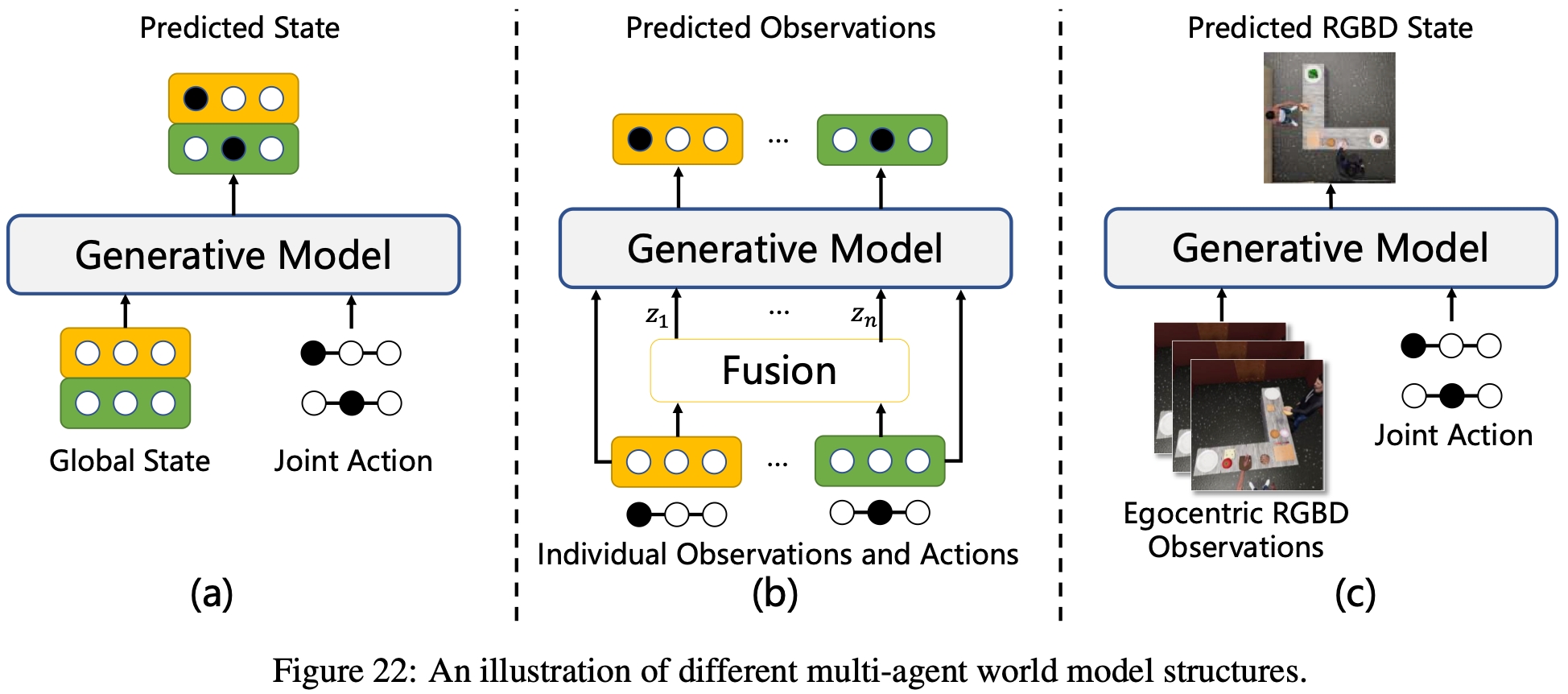
Data-efficient multi-agent learning
由于基于模型的方法样本效率高,将世界模型应用于多智能体协作学习一直是一个重要的课题。然而,在利用世界模型提高多智能体协作效率的过程中,对智能体之间的交互进行建模并从局部观察中推断全局状态仍然是一个关键难点。早期的工作尝试同时对两个协作机器人的动态进行建模,并取得了一些成功,如Fig.22 (a) 所示。然而,随着协作智能体数量的增加,这种方法很快变得效率低下。通过使用 VAE 和 Transformer 等生成模型进行局部观察融合、全局、局部建模的解耦以及自回归轨迹预测,现在可以使用世界模型对 MAS 的动态协作进行建模,如Fig.22 (b)所示。一种方法是通过构建一个生成世界模型来应对城市交通背景下的这些挑战,该模型可以在物理和社会约束下模拟大规模异构智能体,并利用目的地和个性条件动态来促进现实且安全的多智能体行为。作为补充,另一项工作侧重于以自我为中心的RGBD观测进行操作的物理实体化智能体,引入基于扩散的重建过程来建立环境的共享表征,并结合意图推断来促进无需直接通信的隐式协调,如Fig.22 (c)所示。
4.4 Benchmarks
与单智能体具身智能的快速发展相比,多智能体具身智能的进展相对有限,尤其是在标准化基准的制定方面。该领域现有的基准通常针对高度专业化的任务或定义狭窄的场景,限制了其更广泛的适用性和普遍性。为了解决这一问题,本文对当前的多智能体具身智能基准进行了全面而系统的回顾(见Table.4和Fig.23)。通过详细的分析和结构化的比较,旨在为研究人员提供最新的研究进展概述,突出现有基准中的关键差距,并促进开发更稳健、更通用、更广泛适用的评估框架,以支持该领域的未来研究。
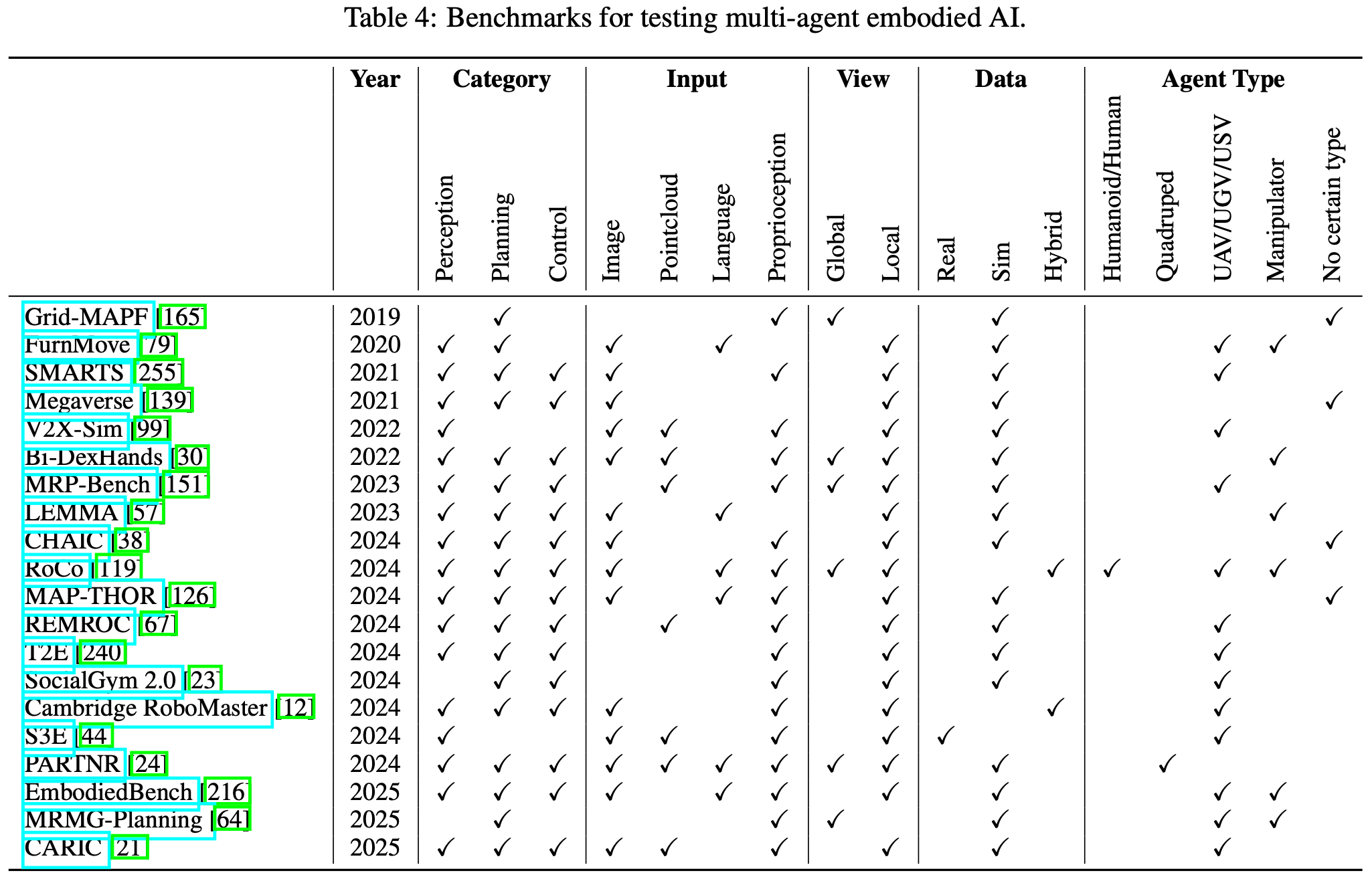

- Grid-MAPF:是一个全面的 MAPF 基准测试,包含 24 张不同的网格地图,涵盖城市布局、游戏环境和仓库式网格,每张地图提供 25 个场景。它使用随机、聚类或指定方法系统地生成源-目标对,并支持渐进式代理扩展,以测试求解器在不断增加的难度下的性能。Grid-MAPF 形式化了各种冲突类型(例如,顶点、边、交换),并支持多种目标函数,例如最大完成时间和成本总和,从而能够对 MAPF 算法进行标准化且可重复的比较;
- FurnMove:是一个模拟基准测试,旨在评估交互式家具重新布置,要求智能体感知、导航和操纵多个物体,以实现目标房间布局。它基于 Habitat 2.0 构建,提供包含各种家具类型和空间配置的多样化 3D 环境。任务被设计为以对象为中心的多步骤转换,以达到预定的目标状态。该基准测试定义了不同难度级别的结构化场景,并引入了全面的评估指标,包括布局精度、运动效率和碰撞计数,使其成为在视觉复杂环境中进行具身规划和控制的强大测试平台;
- SMARTS:SMARTS 是一款可扩展的仿真平台和基准测试套件,专为自动驾驶中的 MARL 设计。它通过模块化架构实现多样化且逼真的交互场景,并整合了来自可扩展“社交代理动物园”的异构社交代理。SMARTS 通过“气泡”为本地代理交互提供细粒度的仿真控制,支持分布式多代理训练,并与主流 MARL 库保持兼容。该基准测试涵盖双合并和无保护交叉路口等具有挑战性的驾驶任务,并提供一套全面的评估指标,涵盖安全性、敏捷性、协作性和博弈论行为,使其成为基于 MARL 的复杂驾驶研究的强大测试平台;
- Megaverse:是一个包含八项任务的具身人工智能基准测试。它以程序生成的3D环境为特色,旨在评估各种智能体能力,包括迷宫导航、障碍物穿越、探索、解谜、对象操控和基于记忆的推理。该平台通过GPU加速的批量执行实现了每秒超过100万次观测的高吞吐量模拟。它还支持多智能体团队,并允许无限次随机实例化任务,从而提升泛化能力和鲁棒性。作为一个开源基准测试,Megaverse有助于对导航、探索、规划和操控方面的具身人工智能方法进行可重复的评估;
- V2X-Sim:是自动驾驶中多智能体协同感知的综合基准测试,支持真实的车对车和车对基础设施通信场景。它基于CARLA-SUMO联合仿真,提供来自车辆和路侧单元的多模态传感器数据,包括RGB、激光雷达、GPS和语义标签。V2X-Sim评估了不同融合策略下的协同3D物体检测、跟踪和鸟瞰图语义分割。凭借丰富的注释、空间多样性和对中间特征共享的支持,V2X-Sim提供了一个严格的测试平台,用于评估遮挡、传感器噪声和通信限制下的感知鲁棒性;
- Bi-Dexhands:是基于 Isaac Gym 构建的统一基准测试,通过并行运行数千个环境,在单个 NVIDIA RTX 3090 上实现了超过 30,000 FPS,从而实现了高效的强化学习。它包含 20 个受精细运动子测试启发的双手操作任务,在一致的基准测试中支持单智能体、多智能体、离线、多任务和元强化学习设置。与之前的基准测试不同,Bi-DexHands 将每个关节、手指和手视为真正的异构智能体,并利用来自 YCB 和 SAPIEN 数据集的各种日常物体来评估任务泛化能力。该平台还提供丰富的多模态观测数据,包括接触力、RGB 图像、RGB-D 图像和点云,并将任务难度与人类运动发育里程碑相结合,从而可以直接比较机器人性能和婴儿的灵活性;
- MRP-Bench:是一个用于评估全栈多机器人导航系统的开源基准测试,它集成了集中式和分散式 MAPF 算法以及来自内部物流和家居领域的真实 3D 环境中的任务分配方法。它基于 ROS2、Gazebo、Nav2 软件包和机器人中间件框架构建,支持对规划和协调方法进行端到端评估。MRP-Bench 提供模块化接口、可配置场景和标准化评估指标,包括成功率、规划时间、完工时间和执行质量,从而能够在混乱、动态和复杂条件下直接比较多机器人解决方案;
- LEMMA:是一个针对多机器人操作的语言条件基准测试,包含八个程序生成的长视野桌面任务。每个相关任务都需要真正的协作,因为成功完成取决于两个异构机械臂在最少的高级或众包自然语言指令下操作。为了支持学习和评估,该基准测试提供了 6,400 个专家演示及其相应的语言命令,以及丰富的多模态观测数据,如 RGB-D 图像和融合点云。这些任务的结构强制执行强大的时间依赖性,并需要独占的多智能体参与,反映了现实世界协作操作的复杂性。评估基于严格的 100 秒时间限制下的标准化成功率指标,从而能够全面评估智能体在语言引导规划、任务分配和细粒度协调方面的能力;
- CHAIC:引入了首个以可访问性为重点的具身社会智能大规模基准测试。它模拟了辅助智能体与四种身体受限的人类伙伴(包括轮椅使用者、儿童、体弱成人和骑自行车者)之间的互动。这些互动通过八项在室内和室外环境中设置的长期任务进行,其中许多任务涉及紧急情况。为了成功地协助伙伴,智能体必须基于以自我为中心的RGB-D观察推断个人目标和身体限制,并基于现实物理生成用户自适应的合作计划。该基准测试使用诸如运输成功率、效率提升和目标推理准确率等指标来评估性能,从而能够对具有社会意识的具身协作进行严格评估;
- RoCo:是一个由六项任务组成的多机器人操作评估基准。它专门用于探索协作的关键维度,包括将任务分解为并行或顺序子任务、代理之间观察的对称性以及不同程度的工作空间重叠。该环境基于 MuJoCo 构建,并附带纯文本数据集。RoCo 中的任务涉及日常家居用品,要求代理展示零样本自适应、反馈驱动的重新规划和基于语言的任务推理能力。RoCo 中的评估基于成功率、环境步骤效率和重新规划尝试次数等指标,从而可以对高级协调和低级运动规划性能进行严格评估;
- MAP-THOR:是一个基准测试包含 45 个长期、语言指导的多智能体任务,这些任务位于部分可观测性的 AI2-THOR 模拟器中。为了评估空间泛化能力,每个任务在五个不同的平面图中实例化。该基准测试还根据项目类型、数量和目标位置的明确性将任务分为四个级别。这些级别涵盖了从完全指定的指令到完全隐含的目标,逐步提高了在语言模糊性面前对规划器鲁棒性的要求。为了支持一致和全面的评估,该基准测试采用了标准化指标,例如成功率、传输率、覆盖率、平衡性和平均决策步骤。这些指标共同实现了对多智能体规划方法进行严格的端到端比较,而无需依赖特权模拟器信息;
- REMROC:是一个模块化的开源基准测试,旨在评估在与人类共享的现实非结构化环境中的多机器人协调算法。它基于 ROS2、Gazebo Ignition 和 Navigation2 构建,支持异构机器人平台、可配置且人员密度各异的环境以及集成的人体运动模型。为了实现系统性评估,该基准测试记录了多种性能指标,包括目标到达时间和路径效率,使研究人员能够量化人类存在对协调有效性的影响;
- T2E:是一个二维模拟基准测试,其中异构捕获机器人和目标机器人必须协同工作以捕获对手,而不是简单地追击他们。这是通过将智能体间合作与环境约束相结合来实现的。捕获过程使用绝对安全区 (ASZ) 指标进行形式化,该指标衡量空间限制的程度。该基准测试包含基于真实世界地图的开源环境,并通过统一的 TrapNet 架构提供定制的 MARL 基线。它支持完全合作和竞争两种评估设置。标准化指标(包括完成时间、成功率、路径长度和 ASZ 区域变化)用于严格评估复杂空间布局中的协作行为;
- SocialGym 2.0:是一个多智能体社交导航基准测试,用于训练和评估具有个体运动-动态约束的自主机器人。它支持多种环境,包括开放空间和几何受限区域,例如门口、走廊、交叉路口和环岛。该模拟器将 PettingZoo 与 ROS 消息传递功能集成,允许完全自定义观察和奖励功能。SocialGym2.0 包含一系列社交小游戏以及逼真的建筑布局。它定义了成功率、碰撞率和停止时间等评估指标,用于严格评估策略在各种社交互动场景中的表现;
- Cambridge RoboMaster:通过为** DJI Robo-Master S1 平台**加装先进的板载计算能力(例如 NVIDIA Jetson Orin)、定制的 ROS2 驱动程序以及使用 CAN 和 WiFi 的双网络通信功能,为 MAS 提供了一个灵活且低成本的研究测试平台。该平台通过与 VMAS 框架集成,支持从模拟到现实的无缝传输,允许零样本部署传统的基于模型的控制器和由 GNN 驱动的去中心化 MARL 策略。这种软硬件集成使得在受控但现实的条件下进行真实世界实验成为可能。该测试平台支持各种具身多智能体任务,包括轨迹跟踪、视觉 SLAM 和协作导航,从而促进对具身系统中的协调策略和策略泛化进行可重复、可扩展且基于物理基础的评估;
- S3E:是协作式 SLAM (C-SLAM) 的大规模基准测试。它包含同步 360 度激光雷达 (LiDAR)、高分辨率立体图像、高频惯性测量单元 (IMU) 以及从三个移动平台收集的新型超宽带 (UWB) 测距数据。该数据集涵盖 18 个室内和室外序列,总大小超过 263 GB。为了支持系统性评估,S3E 定义了四种代表性轨迹模式:同心圆、相交圆、相交曲线和射线。这些模式测试了 C-SLAM 方法在不同空间重叠程度下处理环内和环间闭合的能力;
- PARTNR:是一个由自然语言驱动的具身人机协作的大规模基准测试。它包括 100,000 个程序生成的任务,分布在 60 个不同的多房间房屋中,包含 5,819 个独特物体。所有包含的任务分为四类:无约束、空间、时间和异构,旨在评估现实物理条件下的长期规划和跨智能体协调。每条指令都与一个自动生成的基于模拟的评估函数配对,从而可以对任务完成情况进行严格评估。该基准测试使用半自动化流程构建,该流程集成了基于 LLM 的任务生成、评估综合、在环仿真过滤和人工验证。这种设计使 PARTNR 达到了前所未有的规模和多样性。它还凸显了当前基于 LLM 的规划器与人类合作者在复杂的多智能体具身任务中的表现差距;
- EmbodiedBench:提供了一套涵盖四种具身环境的 1,128 个测试实例的综合套件。这些环境包括家庭场景(EB-ALFRED 和 EB-Habitat)以及低级控制域(EB-Navigation 和 EB-Manipulation)。这些任务涵盖高级和低级操作层次,并被组织成六个面向能力的子集:基础、常识、复杂指令、空间感知、视觉感知和长视域推理。该基准测试支持对 19 个最先进的专有和开源多模态大型语言模型 (MLLM) 进行细粒度、多模态评估,从而能够对各种具身人工智能挑战进行系统性评估;
- MRMG-Planning:将连续空间中的多模态、多机器人、多目标路径规划问题形式化。该基准测试包含 21 种不同的场景,从简单的验证任务到涉及多达五个异构机器人和 74 个连续目标的复杂情况。MRMG-Planning 通过建模模式转换来支持动态环境变化,这些转换会修改机器人任务分配和场景几何形状(例如在物体交接期间)。每个场景都在复合配置空间中实例化,并与两个基于 RRT* 和 PRM* 的基线规划器配对,这两个规划器都是渐近最优和概率完备的。该设计能够在不同的机器人数量、目标序列和成本公式下对端到端规划性能进行严格的评估;
- CARIC:为异构多无人机巡检提供基准,其中配备激光雷达的探测人员和仅使用相机的摄影师必须协作绘制未知结构图,同时仅使用边界框约束,并捕获高质量的结构图像。CARIC 考虑了运动学、通信和传感能力方面的现实限制。它涵盖了各种巡检场景,例如建筑物、起重机和飞机,并定义了丰富的评估指标,将巡检得分分解为可见性、运动模糊和空间分辨率等部分。这些指标能够系统地评估严格约束条件下的任务分配和规划,并支持对 CDC 2023 和 IROS 2024 中演示的真实空中巡检任务进行可重复的比较;
5. The Challenges and Future Works
尽管具身人工智能取得了快速进展,多智能体具身人工智能也取得了初步发展,但它仍面临着若干挑战,并呈现出令人兴奋的未来方向。
Theory for complex Embodied AI interaction
基于马尔可夫博弈提供的理论基础,MARL 引入了各种框架,用于有效地建模复杂环境中智能体之间的合作。价值分解等方法(例如 VDN、QMIX)通过将联合目标分解为各个效用,提高了可扩展性,而反事实推理方法(例如 COMA)则显著提高了对各个智能体贡献的归因准确性。迁移学习和网络化 MARL 的进步缓解了智能体异质性和环境非平稳性带来的挑战。此外,控制理论与博弈论的融合促进了有效的协调策略,例如共识协议和分布式任务分配方法。然而,具身多智能体 AI 带来了独特的理论挑战,包括异步感知、动作延迟、可观测性有限、通信限制、严重的异质性,使理论构建和实际实施都变得复杂。此外,虽然大型生成模型(尤其是LLM)在促进规划和智能体间通信方面具有巨大潜力,但其理论特征(例如稳定性、泛化能力、可解释性)仍未得到充分理解。为了突破这些局限性,未来的研究应探索专门针对具身化多智能体系统(MAS)的新理论范式,利用因果推理等方法来揭示智能体间的依赖关系,利用复杂系统理论来理解涌现行为,以及利用可适应现实世界复杂性的层次化、仿生协调框架。
New algorithm design
近期发展巩固了 MARL 作为合作和竞争多智能体场景基础框架的地位。一些著名算法,包括采用单调值分解的 QMIX 和基于近端策略优化的 MAPPO,已在 SMAC 和谷歌研究足球 (GRF) 等基准环境中展现出令人信服的结果。然而,这些成功主要依赖于 CTDE 范式,该范式假设了理想条件和对智能体动作的无限制访问,而这些条件在具体场景中很少能实现。物理部署引入了显著的复杂性,例如传感器噪声、驱动受限、反馈延迟、可观测性受限。此外,现有的多智能体学习框架通常难以在训练分布之外进行泛化,并且在处理异构团队时可扩展性有限。具身多智能体任务涉及多模态感知数据、多样化能力和动态交互,因此需要超越传统范式(例如 CTDE、DTDE(分散式训练和执行)或 CTCE(集中式训练和执行))的替代算法框架。未来有希望的方向包括分层协调结构、智能体分组机制以及结构化先验或经典控制理论的集成,以实现具身多智能体系统 (MAS) 的可扩展且稳健的性能。
Effective and efficient learning
大多数多智能体学习方法都是在模拟或游戏环境中开发出来的,得益于低成本、高度可重复的场景,这些场景允许通过频繁的交互采样进行广泛的策略优化。然而,具身多智能体任务的复杂性呈指数级增长,由于状态和策略空间庞大,严重降低了样本效率,并使联合探索变得复杂。这些挑战在现实世界中更加突出,因为每次交互都会耗费大量时间、财务成本、硬件磨损。尽管单智能体具身学习的最新进展提高了样本效率,例如从 LLM 等大型多模态模型中提取知识、采用基于世界模型的模拟进行策略部署以及利用离线数据驱动的策略校准,但由于复杂的交互和非平稳动态,这些策略在多智能体环境中往往举步维艰。为了克服这些障碍,需要开发能够精确模拟交互动态的专用多智能体世界模型、基于结构化先验知识的探索策略、通过IL进行快速初始化,以及通过元学习来提升泛化能力。此外,开发支持有效多任务和模拟到现实迁移的稳健方法对于现实世界的应用至关重要。
Large generative models assisted learning
GPT-4、PaLM、CLIP、SAM 和 Gemini 等大规模预训练模型的最新进展,通过提供强大的表征、感知和推理能力,显著重塑了语言、视觉和多模态学习格局。这些基于海量多样化数据集训练的基础模型,提供了丰富的先验知识和强大的跨模态对齐能力,为增强具身人工智能 (embodied AI) 开辟了充满希望的途径。利用这些模型,智能体可以获得更深入的语义理解、更卓越的泛化能力和更具自适应性的交互。然而,将这些基础模型直接部署到具身多智能体场景中仍然具有挑战性,因为它们通常源自静态的单智能体环境,并且缺乏动态交互所必需的归纳偏差,这些交互涉及异步通信、部分可观测性、紧耦合策略、非平稳性。此外,具身多智能体系统 (MAS) 通常涉及高维输入、广泛的动作空间、稀疏反馈,从而限制了其适应性和效率。近期单智能体具身学习的洞见提供了宝贵的可迁移知识,例如少样本自适应、多模态联合预训练、模拟驱动的数据增强。未来的研究应侧重于开发可扩展的多智能体预训练范式,将基础模型与强化学习和基于图的协调方法相结合,并增强从模拟到现实的迁移,从而为复杂、开放环境中的多智能体具身人工智能构建稳健且可泛化的框架。
General multi-agent Embodied AI framework
多智能体具身人工智能的最新进展主要侧重于解决受限场景下的特定任务。虽然进展显著,但这种侧重严重限制了策略的泛化能力和可扩展性。SMAC 和 GRF 等基准测试推动了 MARL 的进展,但现有方法仍在应对多变的任务目标、环境动态和智能体团队组成。像 Gato 和 RT-X 这样的单智能体通才模型展示了统一架构在视觉、语言和控制领域广泛推广的潜力。将通才原则扩展到多智能体设置会引入额外的复杂性,包括固有的非平稳性、复杂的智能体交互、多重均衡。此外,当前的架构通常假设团队规模固定且智能体同质化,从而限制了可扩展性和适应性。近期的创新,例如多智能体 Transformer (MAT) ,通过置换不变表征解决了可扩展性问题,但仍存在诸多挑战,尤其是在将多模态知识(例如,物理体现、社会推理、语言交互)集成到统一框架中方面。未来的发展将需要均衡感知的训练方法、模块化和可扩展的架构,以及鲁棒的多模态表征学习技术,从而实现在动态多智能体环境中的可靠协调和泛化。
Adaptation to open environments
与具身人工智能中通常假设的稳定封闭设置不同,开放环境场景对多智能体具身系统提出了重大挑战,因为它们本身具有动态、不确定、非平稳的特性。在这种环境中运行的智能体经常会遇到不可预测的感官输入、不断变化的奖励结构、不断发展的任务以及频繁变化的智能体群体。例如,场景可能包括嘈杂的观测、延迟或中断的反馈,以及从导航和探索到合作或竞争交互的任务转换。此外,团队组成很少是固定的,队友和对手的变化难以预测,这进一步增加了协调的复杂性。由于行为的多样性和不可预测性,人类的参与引入了额外的不确定性。这种多变性破坏了关于训练和部署环境之间一致性的假设,揭示了在稳定条件下优化的策略的脆弱性。因此,要在开放环境中实现高效性能,智能体需要具备强大的策略,能够抵御感知和环境干扰;具备持续学习能力,能够在不损害先前技能的情况下整合新经验;具备情境推理能力,能够与新型智能体进行动态交互解释和协调。策略重用、隐变量建模、元学习等能够快速调整策略的方法,对于快速推广到前所未见的情况至关重要。尽管在强大的多智能体学习 (MARL)、终身学习和情境感知决策方面的最新进展令人鼓舞,但仍存在一些关键挑战尚未解决。未来的研究应优先考虑对开放环境动态进行精确建模,预测异构智能体和人类行为,并实现实时算法自适应。
Evaluation and verification
建立严谨而全面的评估框架对于推进多智能体具身人工智能至关重要,但同时也极具挑战性。包括 CHAIC 在内的近期平台(更多基准测试见Table.4)提供了宝贵的资源,但往往存在表征复杂性有限和生态效度不足的问题。当前的基准测试主要侧重于单模态任务,忽略了现实感知和决策所必需的基本多模态信号(视觉、语言、音频、视频)。此外,基准测试通常涉及小规模、同质的 MAS,无法充分代表由无人机、机械臂、自动驾驶汽车和四足机器人等多种具身构成的异构 MAS 中遇到的复杂性。此外,理想化的假设(例如忽略部分可观测性、通信延迟、对抗行为和异步执行)扩大了模拟与现实的差距,削弱了策略的鲁棒性和可迁移性。为了突破这些局限性,未来的研究应致力于开发类似于 Gym、MuJoCo 或 PyMARL 的通用、模块化、可扩展的评估框架,并融入多模态交互、异构协调和可重复性特性。物理测试平台,包括机器人足球平台(例如 RoboCup)和无人机群竞技场,对于验证现实世界的可行性和弥合模拟与现实的差异也至关重要。此外,标准化和可解释的评估指标的缺乏仍未解决,因为现有的衡量标准(例如协调性得分、基于网络的指标)往往缺乏一致性和普遍性。因此,开发具有明确任务定义、全面评估标准(鲁棒性、可扩展性、能效、行为多样性)、开放访问排行榜和形式化验证方法的统一基准至关重要,尤其对于安全关键型应用而言。
Applications and implementations
多智能体人工智能在机器人、教育、医疗保健、军事行动、交互式模拟、智慧城市基础设施等多个领域都拥有巨大的发展前景。在机器人领域,尤其是在工业制造、仓储物流、自动驾驶领域,成功的部署需要强大的实时协调、可靠的防撞和自适应平台,这强调了算法的泛化能力。涉及虚拟智能体团队的教育应用需要可控的、符合社会规范的行为,因此对先进的自然语言处理和情感计算能力提出了很高的要求。在医疗保健领域,将机器人智能体整合到医疗团队中,凸显了可靠决策、强大隐私保护和严格遵守伦理标准的必要性。协同无人机群等军事应用进一步凸显了这些挑战,强调了对抗条件下的策略稳健性,以及人类监督在降低与自主相关的伦理和操作风险方面的关键作用。以 OpenAI Five 和 AlphaStar 等平台为代表的交互式模拟和竞技游戏环境,提供了宝贵的基准测试,但由于计算要求高,且难以将学习到的策略迁移到现实世界,也面临诸多限制。智慧城市场景,包括交通管理和电网优化,涉及众多自主智能体之间的广泛交互,需要高度可靠、高效、安全且能产生直接社会影响的解决方案。应对这些多元而又相互关联的挑战,需要整合专家领域知识、严格的验证程序和全面的安全框架,从而实现多智能体具身人工智能系统在现实世界的实际部署。
Other future directions
虽然前面讨论的部分强调了多智能体具身人工智能面临的重大挑战,但还有一些其他基本问题值得深入研究。首先,多模态感知和协作学习仍未得到充分探索,当前的研究通常侧重于孤立的感官模态,很少有效地整合视觉、听觉、语言输入。因此,未来的研究应优先开发鲁棒的跨模态融合方法和高效的通信协议,以处理模态差异、信息不一致、延迟问题。其次,社会学习为涌现集体智慧提供了一条有希望的途径。尽管诸如IL和策略提炼之类的方法使智能体群体能够表现出超越个体能力的协调性,但稳定的涌现行为所需的理论基础和条件仍然未被充分理解。最后,随着MAS的自主性日益增强,解决安全和伦理问题变得至关重要,尤其是在敏感或高风险环境中。必须制定明确的安全约束、清晰的道德准则和透明的解释机制,以确保公平、负责和可解释的决策,从而最大限度地减少由复杂代理交互引起的意外风险,并确保值得信赖的人工智能部署。
6. Conclusion
具身人工智能使智能体能够感知、知觉并与网络空间和物理世界中的各种实体进行有效交互,这标志着我们朝着实现通用人工智能迈出了重要一步。为了系统地理解这一快速发展的领域,本综述全面回顾了具身人工智能的最新发展,弥合了从单智能体到多智能体场景的差距,并进一步探讨了关键挑战和未来发展方向。具体而言,我们首先介绍具身人工智能的基本概念。然后,我们系统地研究了关键方法,包括经典的控制和规划方法、基于学习的技术以及基于生成模型的框架。此外,我们还仔细讨论了在单智能体和多智能体环境下用于评估具身人工智能的广泛采用的基准。最后,我们强调了这一新兴研究领域面临的重大挑战,并探索了未来发展方向。通过对最新进展的比较分析,本综述旨在为研究人员提供一个清晰、综合的视角,从而促进多智能体具身人工智能的持续创新。