【大模型LLM学习】MiniCPM的注意力机制学习
【大模型LLM学习】MiniCPM的注意力机制学习
- 前言
- 1 Preliminary
- 1.1 MHA
- 1.2 KV-cache
- 2 GQA
- GQA的MiniCPM实现
- 3 MLA
- MLA的MiniCPM-3-4b的实现
- TODO
前言
之前MiniCPM3-4B是最早达到gpt-3.5能力的端侧小模型,其注意力机制使用了MLA。本来想借着MiniCPM从MHA过到MLA的,但是最后发现MiniCPM3是attention结构使用的MLA,但是因为和其它框架等兼容性问题,kv-cache存储方式和MHA一样,有一些尴尬,在这记录一下学习过程。
- OpenBMB的官方文档——MiniCPM的三代注意力机制
- 苏神的空间关于从MHA到MLA的详细介绍——从MHA、MQA、GQA到MLA
- MiniCPM的1代模型代码地址——MiniCPM-2b-sft
- MiniCPM的2代模型代码地址——MiniCPM-1b-sft
- MiniCPM的3代模型代码地址——MiniCPM3-4b
- The illustrated系列(图画的都非常好)——The illustrated transformers
1 Preliminary
1.1 MHA
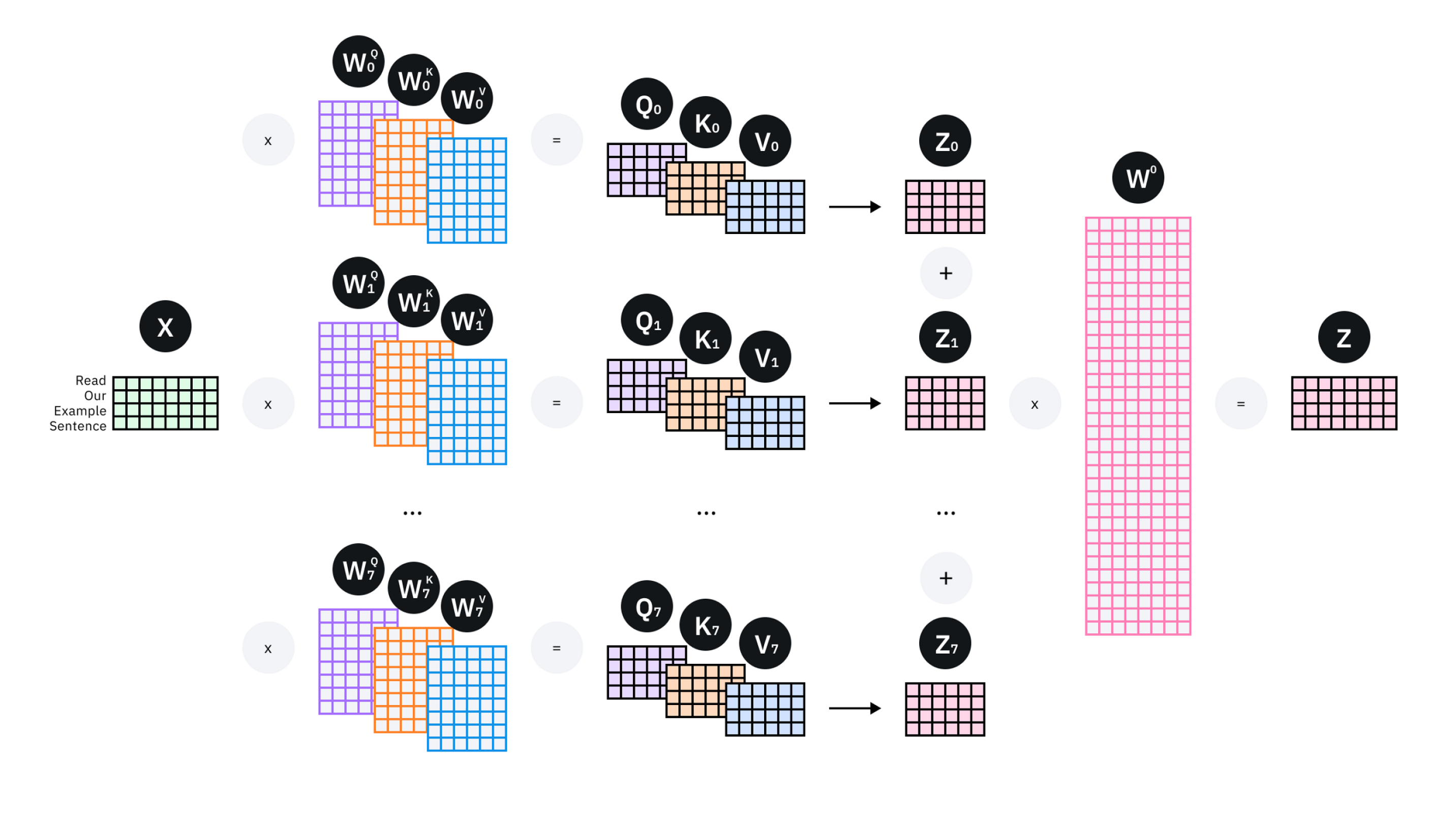
MHA是multi-head attention,前面在qwen1-LLM里面看到过,计算attention的时候把qkv矩阵从hiddensize的大小变成了num_heads个head_dim大小的小矩阵。
def _split_heads(self, tensor, num_heads, attn_head_size):new_shape = tensor.size()[:-1] + (num_heads, attn_head_size) # 前面维度不变,最后一维拆开tensor = tensor.view(new_shape)return tensorquery, key, value = mixed_x_layer.split(self.split_size, dim=2) # 分开qkv,每个的维度为(batch_size, seq_len, hidden_size)query = self._split_heads(query, self.num_heads, self.head_dim) # new_shape = tensor.size()[:-1] + (num_heads, attn_head_size),前面维度不变,最后一维hidden_size拆开
key = self._split_heads(key, self.num_heads, self.head_dim)
value = self._split_heads(value, self.num_heads, self.head_dim)
图示来看是这样的
1.2 KV-cache
为了节省计算开销和推理时KV-cache的显存开销,有篇huggingface上的介绍KV-cache非常好的blog——KV-cache介绍。
在训练的时候不存在KV-cache的概念,因为在训练时,一条样本输入模型后,直接输出了对应长度的结果,不需要解码。例如是文本生成任务,对于一条样本,如果输入是X=[x1,x2,xm],输出是Y=[y1,…,yn],实际上模型的输入是类似X+Y的形式(加上一些special token例如bos和eos),输出结果y_pred是基于attention mask这个下三角矩阵可以一次性输出的,每个token只看得到它之前的token的k和v:
- 输入数据X,长度为T:[x1,x2,xm,y1,…,yn-1]
- 预测目标Y,长度为T:(右shift一位)[x2,xm,y1,…,yn]
通常,模型的NTP loss(Next Token Prediciton)使用下面的方法计算
if labels is not None:labels = labels.to(lm_logits.device)shift_logits = lm_logits[..., :-1, :].contiguous() # 训练的时候是可以一次性推理出结果的,因为有答案,相当于只基于之前的词的ground truth预测了下一个词(mask机制)shift_labels = labels[..., 1:].contiguous()loss_fct = CrossEntropyLoss()loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))
但是在推理时,没有完整的答案,不能一次得到结果,需要每次推理一个token,看看是不是结束标志<eos>,不是的话继续解码。在解码第t个token时,能看到 k ≤ t k_{\leq t} k≤t和 v ≤ t v_{\leq t} v≤t,使用 q t q_t qt和 K [ : t ] K_{[:t]} K[:t]、 V [ : t ] V_{[:t]} V[:t]相乘。
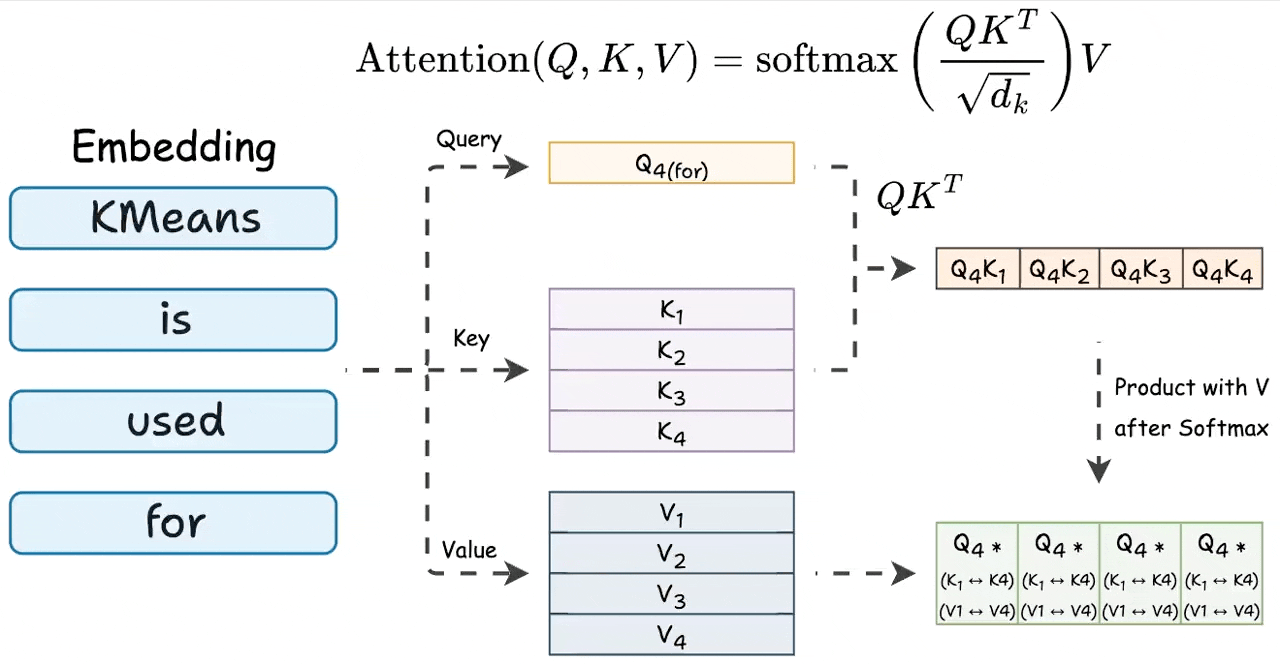
可以发现,在这个过程中,所有的之前的时间步的 k ≤ t k_{\leq t} k≤t和 v ≤ t v_{\leq t} v≤t是不会改变的,每次解码后,只会有 k k k和 v v v的增量拼接在原始的 k k k和 v v v后面。如果每次都需要计算 x W k x W_k xWk和 x W v x W_v xWv是很耗费计算资源和时间的。为了加速推理速度,KV-cache做的事情是,把这些 k k k和 v v v存起来,如果没有解码结束,下次把存起来的 k k k和 v v v读出来就行,节省计算时间,用空间换时间。
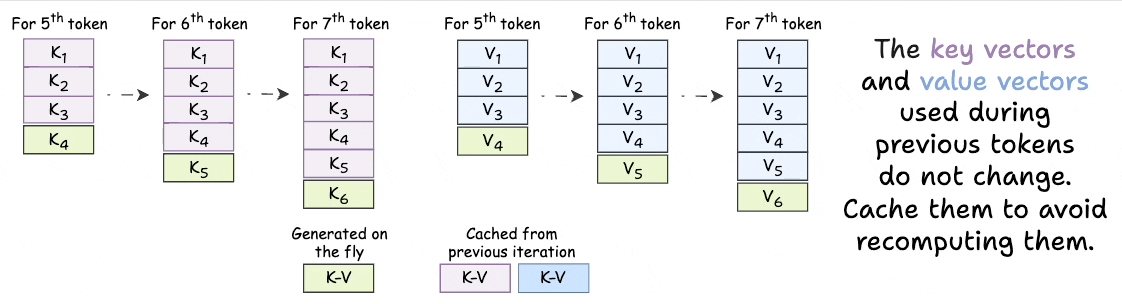
但是空间是有限的,尤其长文本推理的情况下,使用MQA、GQA和MLA等attention机制的模型通过改变attention计算方法、KV-cache的存储内容来节省空间。
2 GQA
从MiniCPM-2b-sft里面就使用了GQA (Grouped Query Attention),MHA里面有 N N N个注意力头,在GQA里面也有 N N N个注意力头,只不过GQA把 N N N个注意力头分成了 g g g个组,在每个组内的所有head,参数是一样的, g g g个组,只有 g g g个不一样的k和v。最极端的情况是MQA (Multi-Query Attention)的形式,只有一组KV,所有 N N N个注意力头参数一样。
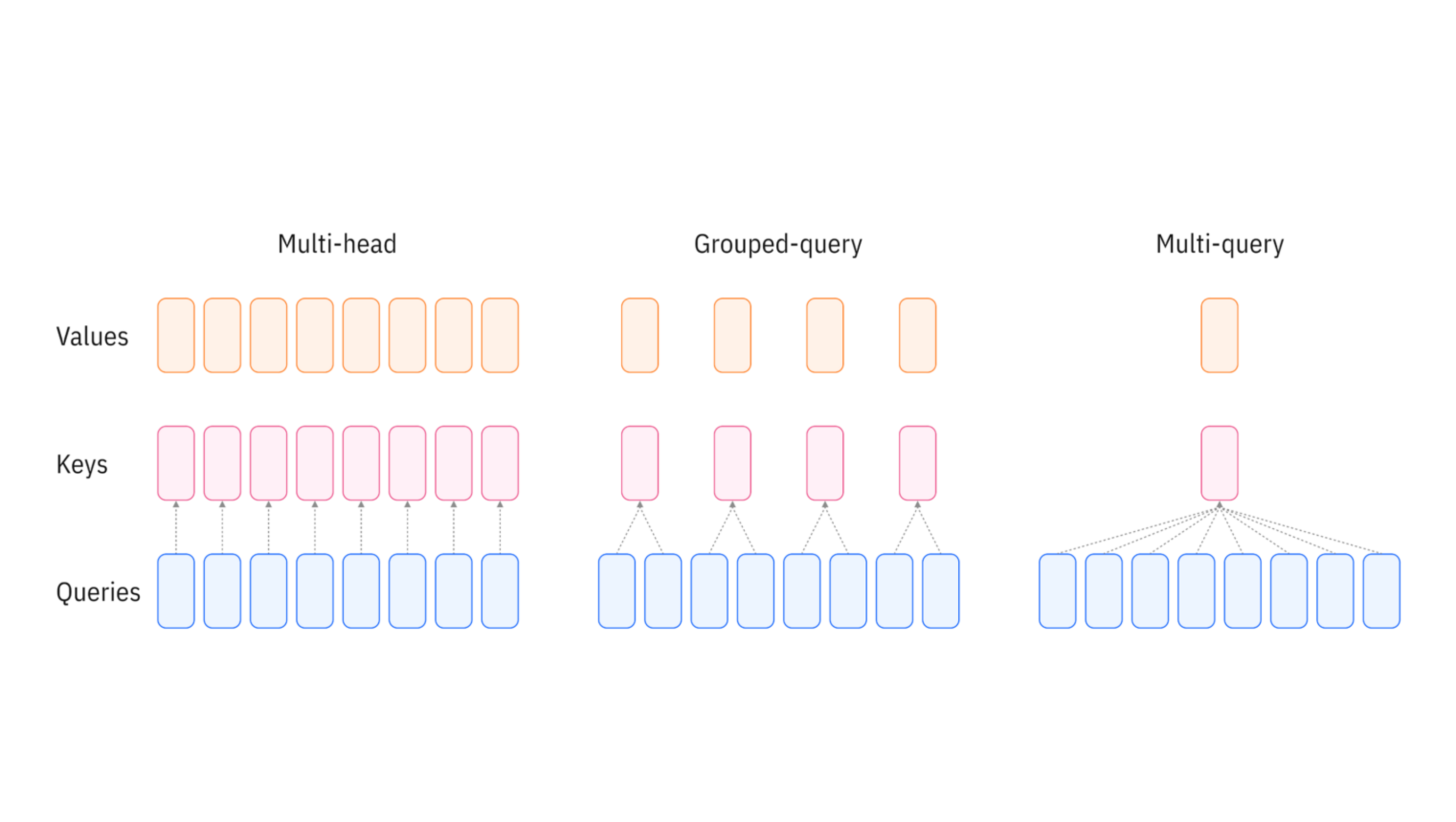
相比于MHA,GQA节省了KV的存储,只需要之前的 N / g N/g N/g的存储空间来存储KV。但是由于每个group里面参数是一样的,最后模型的效果肯定有一点下降。
GQA的MiniCPM实现
- 可以看到使用repeat_kv把k和v进行了复制,但是是在repeat之前对kv-cache进行了更新和存储,因此节省了kv-cache的存储
- 相比于MHA,除了要保存的keys和values变小了(组内共享),GQA的 W k W_k Wk和 W v W_v Wv也变小了,节省了计算开销
def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:batch, num_key_value_heads, slen, head_dim = hidden_states.shapeif n_rep == 1:return hidden_stateshidden_states = hidden_states[:, :, None, :, :].expand(batch, num_key_value_heads, n_rep, slen, head_dim) # 复制return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen, head_dim)class MiniCPMAttention(nn.Module):def __init__(self, config: MiniCPMConfig, layer_idx: Optional[int] = None):self.hidden_size = config.hidden_sizeself.num_heads = config.num_attention_heads # 24self.head_dim = self.hidden_size // self.num_headsself.num_key_value_heads = config.num_key_value_heads # 8self.num_key_value_groups = self.num_heads // self.num_key_value_heads # 3self.q_proj = nn.Linear(self.hidden_size, self.num_heads * self.head_dim, bias=config.attention_bias)self.k_proj = nn.Linear(self.hidden_size, self.num_key_value_heads * self.head_dim, bias=config.attention_bias)self.v_proj = nn.Linear(self.hidden_size, self.num_key_value_heads * self.head_dim, bias=config.attention_bias)self.o_proj = nn.Linear(self.num_heads * self.head_dim, self.hidden_size, bias=config.attention_bias)def forward()bsz, q_len, _ = hidden_states.size()query_states = self.q_proj(hidden_states)key_states = self.k_proj(hidden_states)value_states = self.v_proj(hidden_states)query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2) # [bsz, num_heads, q_len, head_dim]## KV只有num_key_value_heads个,而不是num_heads个key_states = key_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2) # [bsz, num_key_value_heads, kv_len, head_dim]value_states = value_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)kv_seq_len = key_states.shape[-2]if past_key_value is not None: # 推理时有KV的情况下kv_seq_len += past_key_value.get_usable_length(kv_seq_len, self.layer_idx)cos, sin = self.rotary_emb(value_states.to(torch.float32), seq_len=kv_seq_len)query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)# 是在repeat之前存储if past_key_value is not None:cache_kwargs = {"sin": sin, "cos": cos} # Specific to RoPE modelskey_states, value_states = past_key_value.update(key_states, value_states, self.layer_idx, cache_kwargs)key_states = repeat_kv(key_states, self.num_key_value_groups) # [bsz, num_heads, kv_len, head_dim],复制key,同一个组共享value_states = repeat_kv(value_states, self.num_key_value_groups)attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim)
- p.s. 除了MiniCPM系列,qwen2和qwen3使用的也是GQA,而不是MLA。
3 MLA
因为在GQA里面,每个组内的注意力头参数共享,降低了模型的表达能力。MLA (Multi-head Latent Attention)在GQA的基础上,减少KV-cache的同时,让每个注意力头的参数还不一样。MLA的操作略微有一些复杂,在看了很多博客之后发现还是先看代码更容易理解。
MLA的核心是,对矩阵进行低秩分解,存low rank的矩阵(有点类似lora),分解后的两个矩阵是比原来的大矩阵小的,计算成本比之前低,存储成本也会低如果存低秩矩阵(当然并没有直接存这两个小矩阵)。推理的时候再做一次矩阵乘法把KV恢复(这个乘法矩阵会比原始的 W k W_k Wk和 W v W_v Wv小,计算成本低)。
MLA的MiniCPM-3-4b的实现
- 相比于MHA和GQA,在dim上多了"lora_rank"、"nope_dim"和"rope_dim"这几项,其中"lora_rank"和低秩矩阵有关,"nope"的是没有rope信息的分量,"rope"的是含有rope信息的分量
- 在矩阵运算上, W q W_q Wq对应 q q q相关的有a\b两个proj矩阵, W k W_k Wk和 W v W_v Wv对应另外两个a/b的proj矩阵。
class MiniCPMAttention(nn.Module):def __init__():self.hidden_size = config.hidden_size # 2560self.num_heads = config.num_attention_heads # 40self.max_position_embeddings = config.max_position_embeddings # 32768self.q_lora_rank = config.q_lora_rank # 768self.qk_rope_head_dim = config.qk_rope_head_dim # 32self.kv_lora_rank = config.kv_lora_rank # 256self.v_head_dim = config.hidden_size // config.num_attention_heads # 2560 // 40 = 64self.qk_nope_head_dim = config.qk_nope_head_dim # 64self.q_head_dim = config.qk_nope_head_dim + config.qk_rope_head_dim # 64+32=96self.q_a_proj = nn.Linear(self.hidden_size, config.q_lora_rank, bias=config.attention_bias) # hiddensize -> q_lora_rank 2560->768self.q_a_layernorm = MiniCPMRMSNorm(config.q_lora_rank)self.q_b_proj = nn.Linear(config.q_lora_rank, self.num_heads * self.q_head_dim, bias=False) # q_lora_rank -> num_heads * q_head_dim = 768 -> 40*(64+32)self.kv_a_proj_with_mqa = nn.Linear(self.hidden_size,config.kv_lora_rank + config.qk_rope_head_dim,bias=config.attention_bias,) # kv_lora_rank = 256, qk_rope_head_dim = 32 2560 -> 256 + 32self.kv_a_layernorm = MiniCPMRMSNorm(config.kv_lora_rank)self.kv_b_proj = nn.Linear(config.kv_lora_rank,self.num_heads* (self.q_head_dim - self.qk_rope_head_dim + self.v_head_dim),bias=False,) # kv_lora_rank -> num_heads * (q_head_dim - qk_rope_head_dim + v_head_dim) = 40*(96-32+64) = 40 * 128 = 5120self.o_proj = nn.Linear(self.num_heads * self.v_head_dim,self.hidden_size,bias=config.attention_bias,) # num_heads * v_head_dim -> hiddensize 40*64 -> 2560
- 在MLA的实现上,对于 q q q的计算,使用2个低秩小矩阵的乘法,节约计算成本【假设原始是 x ⋅ W q x \cdot W_q x⋅Wq, x x x大小是 ( 1 , d ) (1,d) (1,d), W q W_q Wq大小是 ( d , D ) (d,D) (d,D),计算复杂度是 O ( d ⋅ D ) O(d⋅D) O(d⋅D);令 U V = W q UV=W_q UV=Wq,其中 U U U的大小为 ( d , r ) (d,r) (d,r), V V V的大小是 ( r , D ) (r,D) (r,D), x U V xUV xUV的计算复杂度是 O ( d ⋅ r + r ⋅ D ) O(d\cdot r+r \cdot D) O(d⋅r+r⋅D), r r r是低秩的情况下】
- 同时,因为MLA里面要存储低秩的K,和ROPE的实现有一些冲突,直接实现起来要么需要存原始的K,要么推理时需要大的计算量,所以实现上,单独把ROPE的信息作为一个分量来进行单独的存储和计算,和K对应的q里面会有一份不带有ROPE信息的q_nope,以及后续会加上rope信息的q_pe,所以会看到这里面q做了split。
def forward(self,hidden_states: torch.Tensor,attention_mask: Optional[torch.Tensor] = None,position_ids: Optional[torch.LongTensor] = None,past_key_value: Optional[Cache] = None,output_attentions: bool = False,use_cache: bool = False,**kwargs,) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:bsz, q_len, _ = hidden_states.size() # hidden_size=2560# q使用2个小矩阵乘法,而不是直接和大矩阵相乘,节约计算成本q = self.q_b_proj(self.q_a_layernorm(self.q_a_proj(hidden_states))) # hiddensize -> q_lora_rank -> num_heads * q_head_dim = 40*(64+32)q = q.view(bsz, q_len, self.num_heads, self.q_head_dim).transpose(1, 2)q_nope, q_pe = torch.split(q, [self.qk_nope_head_dim, self.qk_rope_head_dim], dim=-1) # q的大小为40*96;qk_nope_head_dim=64, qk_rope_head_dim=32;q沿着最后一个维度拆分成两部分,所以q_nope=40*64,q_pe=40*32- 接着的部分,首先计算出一个compressed_kv,注意它的维度上没有num_heads这个维度,看上去是对于所有head都是共用的一个向量
- compressed_kv会分出来不使用rope的部分,以及使用rope的部分k_pe
- 接着最核心的是,把compressed_kv通过投影矩阵kv_b_proj映射后,又有num_heads的维度了,后面split拆分后可以看到,每个注意力头是有自己的K和V的,和MHA一样的效果
compressed_kv = self.kv_a_proj_with_mqa(hidden_states) # (bsz,q_len,2560)->(bsz,q_len,256+32)compressed_kv, k_pe = torch.split(compressed_kv, [self.kv_lora_rank, self.qk_rope_head_dim], dim=-1) # kv_lora_rank=256, qk_rope_head_dim=32,split后,compressed_kv=256,k_pe=32;拆分出来要使用rope和不使用rope的分量k_pe = k_pe.view(bsz, q_len, 1, self.qk_rope_head_dim).transpose(1, 2) # (bsz, 1, q_len, 32)kv = (self.kv_b_proj(self.kv_a_layernorm(compressed_kv)) # 256-> 40*128 -> 5120.view(bsz, q_len, self.num_heads, self.qk_nope_head_dim + self.v_head_dim) # 40*(64+64) = 40*128.transpose(1, 2) # (num_heads, bsz, q_len, (self.qk_nope_head_dim + self.v_head_dim)) = (40,bsz, q_len, 128))k_nope, value_states = torch.split(kv, [self.qk_nope_head_dim, self.v_head_dim], dim=-1) # k_nope=40*bsz*q_len*64,value_states=40*bsz*q_len*64
- 加入ROPE信息, q q q里面的是q_pe分量, k k k里面的是k_pe分量
- 【bug】尴尬的地方来了,目前官方的实现里面可能是为了兼容的原因,KV-cache存的是恢复后的K和V,不是存的compressed_kv
kv_seq_len = value_states.shape[-2]if past_key_value is not None:kv_seq_len += past_key_value.get_usable_length(kv_seq_len, self.layer_idx)cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len) # 初始化的时候,这个函数里面的dim是32;这里只是用value_states的dtypeq_pe, k_pe = apply_rotary_pos_emb(q_pe, k_pe, cos, sin, position_ids) # q_pe的维度为32,k_pe的维度为32query_states = k_pe.new_empty(bsz, self.num_heads, q_len, self.q_head_dim) # num_heads=40, q_head_dim=96query_states[:, :, :, : self.qk_nope_head_dim] = q_nope # q的前64维是没有rope信息query_states[:, :, :, self.qk_nope_head_dim :] = q_pe # q的后32维是有rope信息key_states = k_pe.new_empty(bsz, self.num_heads, q_len, self.q_head_dim) # num_heads=40, q_head_dim=96key_states[:, :, :, : self.qk_nope_head_dim] = k_nope # k的前64维是没有rope信息key_states[:, :, :, self.qk_nope_head_dim :] = k_pe # k的后32维是有rope信息if past_key_value is not None:cache_kwargs = {"sin": sin, "cos": cos} # Specific to RoPE modelskey_states, value_states = past_key_value.update(key_states, value_states, self.layer_idx, cache_kwargs) # past_key_value是一个Cache对象,update函数会把past_key_value的key和value更新为当前的key和valueattn_weights = (torch.matmul(query_states, key_states.transpose(2, 3)) * self.softmax_scale) # (bsz, num_heads, q_len, q_head_dim) @ (bsz, num_heads, q_head_dim, kv_seq_len) -> (bsz, num_heads, q_len, kv_seq_len)
- 所以minicpm3在结构上是MLA,但是推理阶段目前没有做减少存储/加速的处理
DeepSeek V3里面的MLA,可以看到在存KV的时候存的是压缩之后的
compressed_kv = self.kv_a_proj_with_mqa(hidden_states)k_pass, k_rot = torch.split(compressed_kv, [self.kv_lora_rank, self.qk_rope_head_dim], dim=-1)k_pass = self.kv_b_proj(self.kv_a_layernorm(k_pass)).view(key_shape).transpose(1, 2)k_pass, value_states = torch.split(k_pass, [self.qk_nope_head_dim, self.v_head_dim], dim=-1)k_rot = k_rot.view(batch_size, 1, seq_length, self.qk_rope_head_dim)cos, sin = position_embeddingsif self.config.rope_interleave: # support using interleaved weights for efficiencyq_rot, k_rot = apply_rotary_pos_emb_interleave(q_rot, k_rot, cos, sin)else:q_rot, k_rot = apply_rotary_pos_emb(q_rot, k_rot, cos, sin)k_rot = k_rot.expand(*k_pass.shape[:-1], -1)query_states = torch.cat((q_pass, q_rot), dim=-1)key_states = torch.cat((k_pass, k_rot), dim=-1)if past_key_value is not None:# sin and cos are specific to RoPE models; cache_position needed for the static cachecache_kwargs = {"sin": sin, "cos": cos, "cache_position": cache_position}key_states, value_states = past_key_value.update(key_states, value_states, self.layer_idx, cache_kwargs)
TODO
- 完整的MLA机制学习,可能涉及attention和flashattention的底层实现原理