【RAG】Milvus、Pinecone、PgVector向量数据库索引参数优化
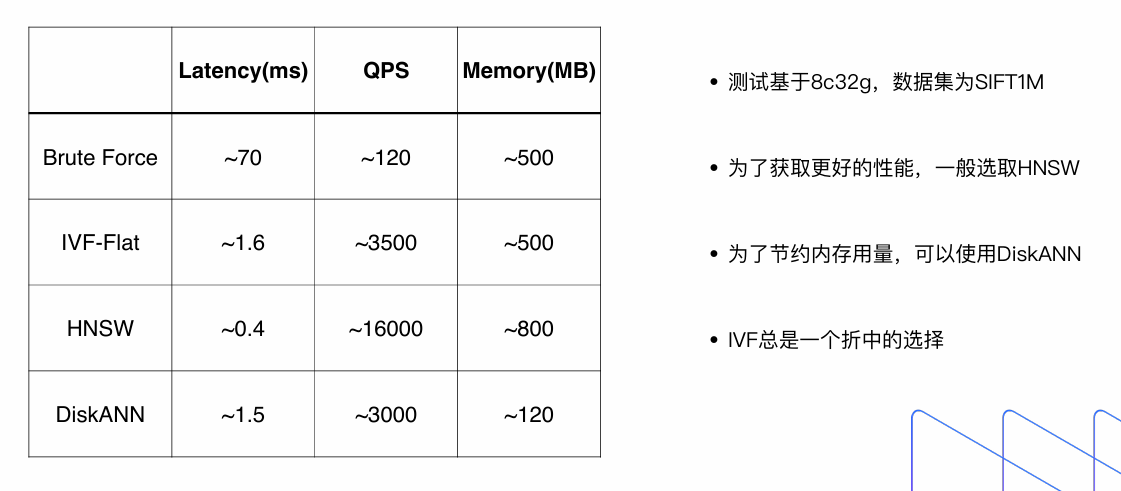
Milvus 、PgVector 索引参数优化
IVF类索引关键参数(基于聚类算法)
-
nlist (倒排列表数量):
- 决定将向量空间划分为多少个聚类中心
- 值越大搜索越精确但耗时越长
- 推荐值: 通常设置为数据量的4√n到n/1000之间
- 例如: 1百万数据量可设nlist=1000到4000
-
nprobe (搜索时探查的聚类数量):
- 决定搜索时检查多少个最近邻的聚类
- 值越大结果越精确但速度越慢
- 推荐值: 通常为nlist的1%~10%
- 例如nlist=4096时,nprobe可设为32-256
-
优化建议:
- 先固定nlist,调整nprobe找到准确率与延迟的平衡点
- 对于高准确率需求,可增大nprobe
- 对于低延迟需求,可减小nprobe
- 小数据集(<100万):
nlist=100,nprobe=10 - 大数据集(>1000万):
nlist=1000,nprobe=50
Tips:
不知道聚类中心是什么?不理解索引参数优化为什么这样调?朋友们可以看看这篇:索引的底层算法原理就明白辣: 【RAG】向量?知识库的底层原理:向量数据库の技术鉴赏 | HNSW(导航小世界)、LSH、K-means-CSDN博客
HNSW索引参数
-
M (每个节点的最大连接数):
- 影响图结构的连通性
- 值越大精度越高但内存占用越大
- 推荐值: 通常在12-48之间
-
efConstruction (构建时的搜索范围):
- 影响索引构建质量
- 值越大构建质量越好但构建时间越长
- 推荐值: 通常在100-400之间
-
efSearch (搜索时的动态候选集大小):
- 影响搜索质量和速度
- 值越大结果越精确但搜索越慢
- 推荐值: 通常在32-256之间
Pinecone 索引参数优化
Pinecone作为托管服务,参数调整相对简化,但仍有一些关键参数:
-
索引类型选择:
- 精确搜索(Flat): 100%准确但速度慢
- 近似搜索: 平衡准确率和速度
-
pod类型和数量:
- 更多pod可提高并行度和吞吐量
- 更大pod可处理更高维度和更多数据
-
metric类型:
- 根据应用场景选择合适距离度量(余弦、欧式、点积等)
通用优化策略
-
基准测试:
- 使用代表性查询集测试不同参数组合
- 记录召回率和延迟指标
-
权衡考虑:
- 召回率 vs 查询延迟
- 索引构建时间 vs 查询性能
- 内存使用 vs 搜索精度
-
数据特性考虑:
- 高维数据通常需要更大的nlist/nprobe
- 数据分布不均匀时可能需要调整聚类参数
-
硬件资源考虑:
- 更多CPU核心可支持更大的nprobe并行搜索
- 足够内存才能支持大型索引
那Chroma怎么优化?
Chroma 的自动索引机制
Chroma 的设计理念是简化使用,因此它默认采用自动索引管理,不像 Milvus/FAISS 那样需要手动调整 nlist、nprobe 等参数。它的索引层通常采用 HNSW(Hierarchical Navigable Small World) 算法,并自动优化索引构建和查询过程。
优化建议:
- 如果数据量较大(百万级以上),可以尝试调整 HNSW 参数(如
M、ef_construction、ef_search),但 Chroma 的 API 并未直接暴露这些参数,通常需要修改底层配置或等待官方支持。
结合元数据过滤
Chroma 支持元数据(metadata)索引,可以在查询时结合元数据过滤,减少搜索范围:
results = collection.query(query_embeddings=[query_embedding],n_results=10,where={"category": "technology"} # 元数据过滤
)
这样可以大幅提升检索效率。
元数据支持
1. Milvus 的元数据支持
Milvus 支持结构化元数据过滤,可以结合向量搜索进行高效检索:
- 支持的数据类型:数值(int/float)、字符串(string)、布尔值(bool)等。
- 查询方式:
- 支持
AND/OR/NOT等逻辑运算符。 - 支持范围查询(
>、<、BETWEEN)、模糊匹配(LIKE)等。
- 支持
- 示例查询(Python SDK):
results = collection.search(data=[query_vector],anns_field="vector",param={"nprobe": 10},limit=10,expr='category == "technology" AND price < 100' # 元数据过滤 ) - 优势:
- 适用于大规模数据,支持混合查询(向量+元数据)。
- 高性能,适用于推荐系统、图像检索等场景。
2. Pinecone 的元数据支持
Pinecone 提供灵活的元数据过滤,适用于低延迟搜索:
- 支持的数据类型:数值、字符串、布尔值、列表等。
- 查询方式:
- 支持
$eq(等于)、$ne(不等于)、$in(包含)、$gt(大于)等操作符。 - 支持组合查询(
$and/$or)。
- 支持
- 示例查询(Python SDK):
results = index.query(vector=query_vector,top_k=10,filter={"category": {"$eq": "technology"},"price": {"$lt": 100}} ) - 优势:
- 无服务器架构,适合云原生应用。
- 适用于推荐引擎、语义搜索等低延迟场景。
3. Chroma 的元数据支持
Chroma 也支持元数据过滤,但功能相对简单:
- 支持的数据类型:字符串、数值等基础类型。
- 查询方式:
- 支持
==、!=、in等简单操作。
- 支持
- 示例查询:
results = collection.query(query_embeddings=[query_vector],n_results=10,where={"category": "technology"} ) - 局限性:
- 不支持复杂逻辑运算(如
AND/OR组合)。 - 适合小规模数据或快速原型开发。
- 不支持复杂逻辑运算(如
对比总结
| 功能 | Chroma | Milvus | Pinecone |
|---|---|---|---|
| 元数据类型 | 基础类型 | 数值、字符串、布尔等 | 数值、字符串、列表等 |
| 查询运算符 | 简单(==、in) | 复杂(AND/OR/BETWEEN) | 丰富($eq/$gt/$in) |
| 混合查询 | ❌ | ✅(向量+元数据) | ✅(向量+元数据) |
| 适用场景 | 小规模/原型 | 大规模、高性能 | 低延迟、云原生 |
建议
- 如果需要高性能、复杂元数据查询,选择 Milvus(适合大规模数据)。
- 如果需要低延迟、云托管,选择 Pinecone(适合推荐系统、AI应用)。
- 如果只是快速原型开发或小规模数据,Chroma 足够使用。