一篇文章讲清楚mysql的聚簇索引、非聚簇索引、辅助索引
聚簇索引与非聚簇索引最大的区别就是:
聚簇索引的索引和数据是存放在一起的,都是在叶子结点;
非聚簇索引的索引和数据是分开存储的,叶子节点存放的是索引和指向数据文件的地址,通过叶子节点找到索引,再通过索引找到地址,再通过地址指向数据文件具体的数据。当然叶子节点有可能存放的是索引和主键,比如辅助索引。
这就是他们的本质区别。
聚簇索引与非聚簇索引的比较?
聚簇索引由于索引与数据是存放在一起的,所以不用回表,比非聚簇索引减少一次磁盘IO,
聚簇索引如果索引列上的值发生改变的时候,不仅要重新维护索引在树中的有序关系,而且聚簇索引的叶子节点存放了索引和数据,所以数据也需要修改。而非聚簇索引叶子结点是没有存放数据的,只需要维护索引在树中的位置,开销相比较没那么大。所以主键一般不能被修改。
非聚簇索引的结构:
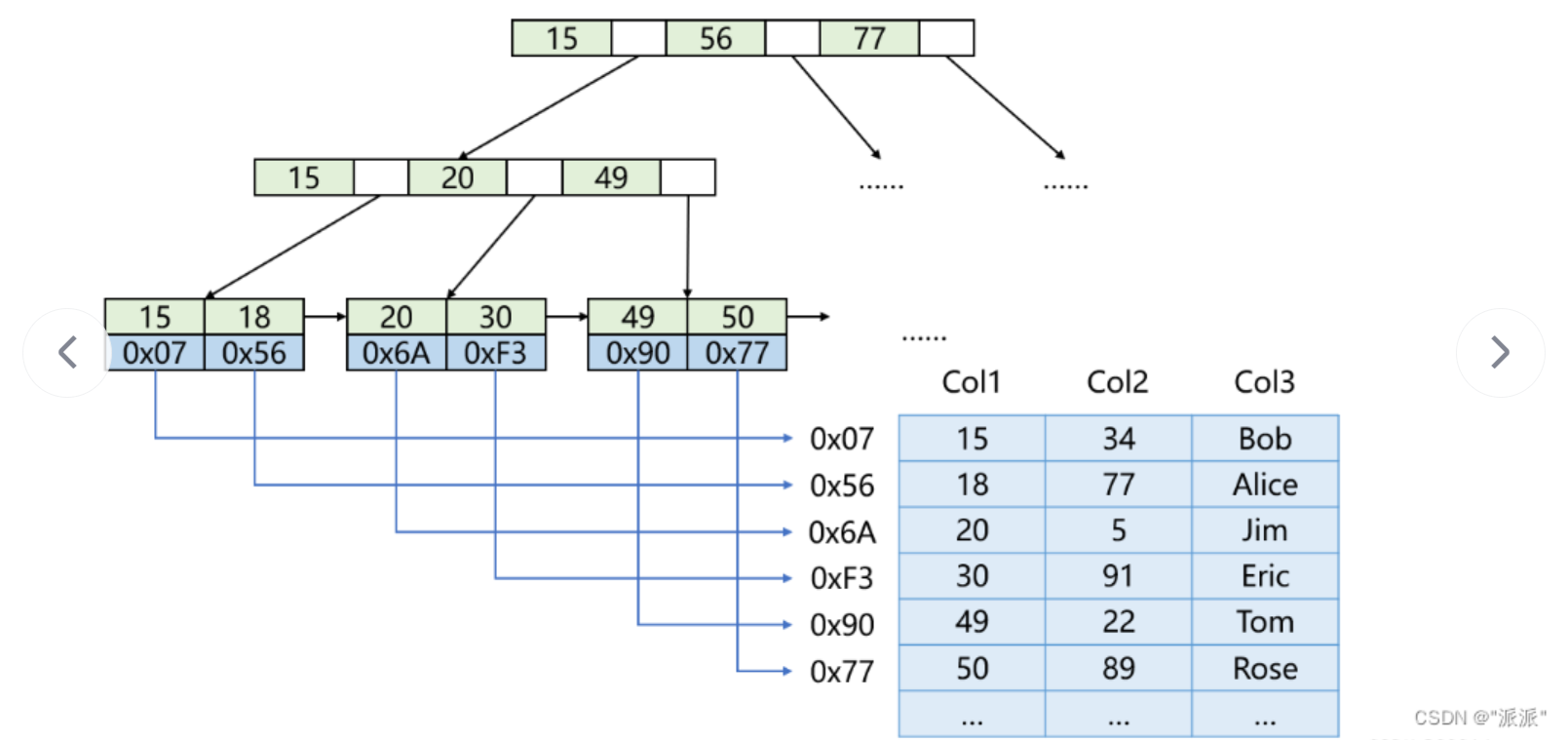
可以看到索引和数据是分开存储的。(这种叶子结点存放的是索引和地址,下面会说辅助索引,叶子节点存放的是索引和主键)
聚簇索引:
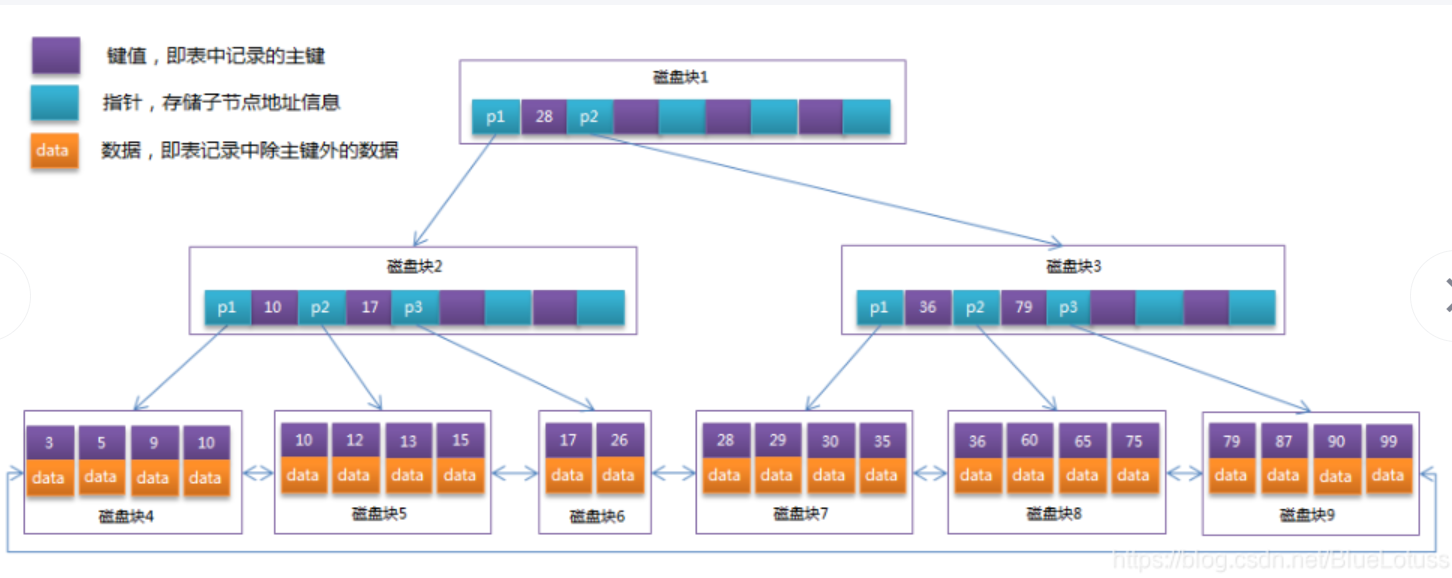
索引和数据是存储在一起的。
辅助索引其实就是普通字段上建立的索引,比如name字段建立的索引。
辅助索引的结构是属于非聚簇索引结构,叶子节点存放的是索引和对应的主键id
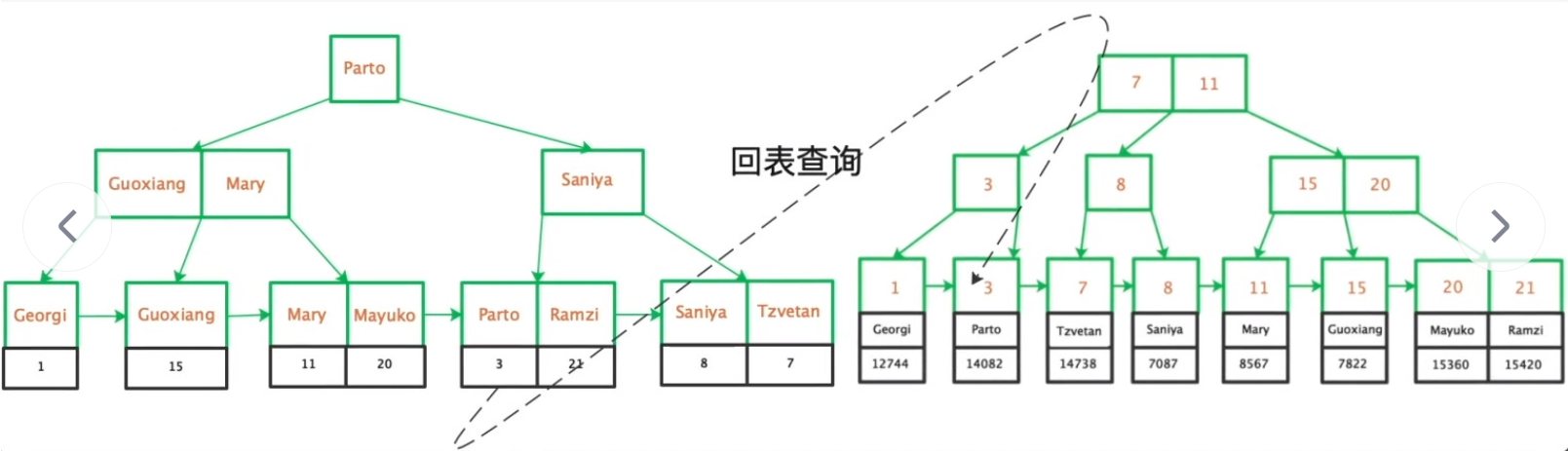
辅助索引在查找数据的时候不一定就要回表,如果是覆盖索引的话那么就不需要回表操作了。
说到覆盖索引,那么我们顺便普及一下覆盖索引是什么?
覆盖索引就是建立的索引包含或者覆盖查询的字段。
查询的时候select的字段也是索引字段,那么在找到索引之后直接读出来就可以了,就不用回表查询了,但是如果select的字段有其他额外的字段,那么就必须回表操作了。