JAVA多线程进阶
文章目录
- (一)常见的锁策略
- 1.乐观锁 vs 悲观锁
- 2.读写锁 vs 普通的互斥锁
- 3.重量级锁 vs 轻量级锁
- 4.挂起等待锁 vs 自旋锁
- 5.公平锁 vs 非公平锁
- 6.可重入锁 vs 不可重入锁
- 7.synchronized的锁策略
- (二)CAS
- 1.基于CAS能够实现“原子类”
- 2.基于CAS类能够实现“自旋锁”
- 3.ABA问题
- (三)synchronized中的锁优化机制
- 1.锁膨胀/锁升级
- 2.锁粗化
- 3.锁消除
- (四)JUC(java.util.concurrent)的常见类
- 1.Callable
- 2.ReentrantLock
- ReentrantLock和synchronized的区别
- 3.原子类
- 4.线程池
- (1)ExecutorService 和 Executors
- (2)ThreadPoolExecutor
- 5.信号量Semaphore
- 6.CountDownLatch
- 7.线程安全的集合类
- (1)多线程环境使用ArrayList
- (2)多线程环境使用队列
- (3)多线程环境使用哈希表
(一)常见的锁策略
锁策略一般只与“实现锁”的人有关系,锁策略与JAVA本身并没有关系,适用于所有锁相关的情况
1.乐观锁 vs 悲观锁
- 偏向于处理锁的态度
- 悲观锁,预期锁冲突的概率很高,做的工作会更多,更低效
- 乐观锁,预期锁冲突的概率很低,做的工作会更少,更高效
2.读写锁 vs 普通的互斥锁
-
对于普通的互斥锁来说,只能进行单个的加锁和解锁,如果对同一个对象进行加锁,就会产生互斥。但是多线程针对同一个变量进行读操作时并不会产生线程安全问题,此时都用同一个锁会产生极大的性能损耗。
-
对于读写锁来说,如果代码进行了读操作,就加读锁,如果代码进行了修改操作,就加写锁。读锁和读锁之间不存在互斥关系;但读锁和写锁、写锁和写锁之间需要互斥
-
JAVA标准库中提供了 ReentrantReaderWriteLock 类实现了读写锁
ReentrantReaderWriteLock.ReadLock 表示一个读锁,这个对象提供了 lock / unlock 方法进行加锁解释
ReentrantReaderWriteLock.WriteLock 表示一个写锁,这个对象也供了 lock / unlock 方法进行加锁解释
3.重量级锁 vs 轻量级锁
- 重量级锁加锁做的工作更多,开销更大,轻量级锁加锁做的工作少,开销更小。
- 通常情况下,认为悲观锁是重量级锁,乐观锁是轻量级锁。一般在于处理锁冲突的结果
- 在使用的锁中,如果锁是基于内核的一些功能来实现的,例如调用了操作系统提供的mutex接口,此时一般认为这是重量级锁
- 如果锁是纯用户态实现的,此时一般认为是轻量级锁
4.挂起等待锁 vs 自旋锁
- 挂起等待锁,往往通过内核的机制来实现,较重,是重量级锁的一种典型实现
- 自旋锁,往往通过用户态代码来实现,较轻,是轻量级锁的一种典型实现
5.公平锁 vs 非公平锁
-
公平锁:多个线程在等待一把锁的时候,遵守先来后到的策略
-
非公平锁:多个线程在等待一把锁的时候,不遵循先来后到,每个线程获取到锁的概率是均等的
-
操作系统中的 mutex 锁就属于非公平锁,线程之间的调度情况随机,要想实现公平锁一般来说要付出更大的代价,需要给参与竞争的线程设置优先级
6.可重入锁 vs 不可重入锁
- 可重入锁:针对一个线程进行连续加锁,不会产生死锁
- 不可重入锁:针对一个线程进行连续加锁,会产生死锁
7.synchronized的锁策略
- 既是一个乐观锁,也是一个悲观锁,会根据竞争的激烈进行自适应
- 不是读写锁,是一个普通互斥锁
- 既是一个轻量级锁,也是一个重量级锁,同样根据竞争的激烈进行自适应
- 轻量级锁的部分基于自旋锁来实现,重量级的部分基于挂起等待锁来实现
- 非公平锁
- 可重入锁
(二)CAS
CAS(Compare and swap)的主要工作是将寄存器/某个内存中的值和另外一个内存的值进行比较,如果值相同,就把另一个寄存器/内存的值和当前这个内存进行交换,其伪代码如下所示,
boolean CAS(address, expectValue, swapValue){if (&address == expectValue){&address = swapValue;return true;//操作成功}return false;//操作失败
}
其中,address为待比较的内存地址,expectValue为预期内存中的值,swapValue希望把内存中的值修改成的新值
一个CAS涉及到下面的操作:1.比较 A 与 V 是否相等。2.如果比较相等,那就将B写入A。3.返回操作是否成功。
此处所指的CAS指的是CPU提供了一个单独的CAS指令,通过一条指令能够完成上述伪代码描述的过程,相当于是原子的,指令不可分割,保证了线程安全
通过硬件直接实现了上面的交换逻辑,通过这一条指令进行了封装
1.基于CAS能够实现“原子类”
JAVA标准库中提供了一组原子类,针对常用的int、long、int array等进行了封装,可以基于CAS的方式进行修改,并且线程安全
因为代码基于CAS实现的自增操作,因此不存在安全问题,这样的操作既能够保证线程的安全,又能比synchronized高效,因为synchronized会涉及到两个锁之间的竞争,线程之间要相互等待,而CAS则不涉及线程阻塞等待的问题。
当多个线程同时对某个资源进行ACS操作的时候,是能有一个线程操作成功,但是并不会阻塞其他线程,其他线程只会获得操作失败的信号,CAS可以视为一种乐观锁,下面是基于CAS实现的两个线程进行自增的操作,得到的结果是100000,保证了线程的安全。
import java.util.concurrent.atomic.AtomicInteger;public class Demo {public static void main(String[] args) throws InterruptedException {AtomicInteger num = new AtomicInteger(0);Thread t1 = new Thread(()->{for(int i = 0;i < 50000;i++){//相当于num++;num.getAndIncrement();}});Thread t2 = new Thread(()->{for(int i = 0;i < 50000;i++){//相当于num++;num.getAndIncrement();}});t1.start();t2.start();t1.join();t2.join();//得到原子类内部的数值System.out.println(num.get());}
}下面是实现原子类的伪代码,此处的 oldValue 在实际实现中是直接用寄存器存储的内容 ,value 是内存中的原始数据,CAS(value,oldValue,oldValue+1) 操作理解为,判定内存中的值和寄存器中的值是否一致,如果一致,就把内存中的value值设置为 oldValue+1,返回 true,循环结束;如果判定失败,就返回 false 将寄存器中的值跟新为内存中的值,再循环进行CAS判定,直到判定成功
class AtomicInteger{private int value;public int getAndIncrement(){int oldValue = value;//两行代码之间可能有其他线程修改了value的值while( CAS(value,oldValue,oldValue+1) != true){oldValue = value;}return oldValue;}
}
两个线程分别进行自增操作,其中一种情况的流程如下,
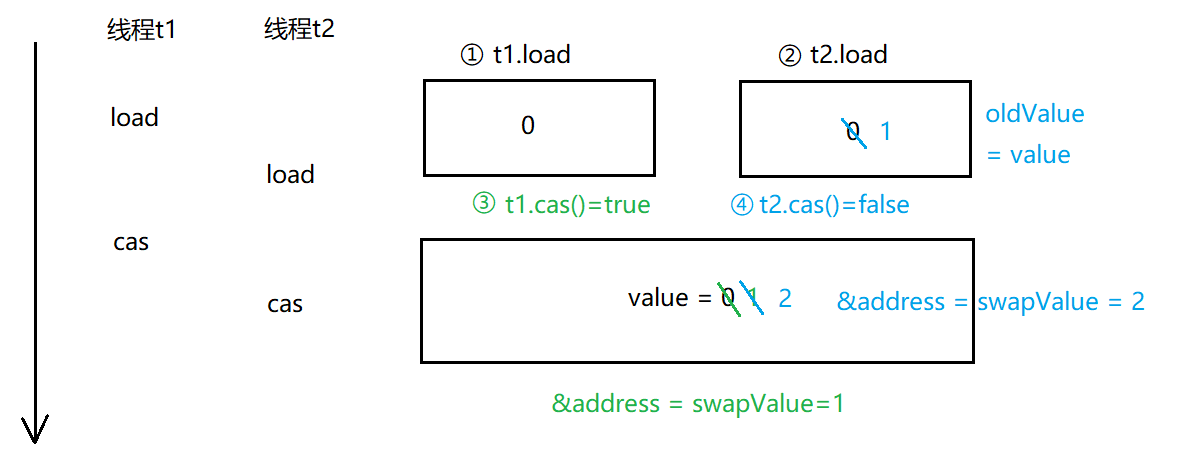
2.基于CAS类能够实现“自旋锁”
自旋锁伪代码
public class SpinLock{private Thread owner = null;public void lock(){//通过CSA 看当前锁是否被某个线程持有//如果这个锁已经被别的线程持有,那么就自旋等待//如果这个锁没有被别的线程持有,那么就把 owner 设置成当前尝试加锁的线程while(!CAS(this.owner,null,Thread.currentThread())){}}public void unlock(){this.owner = null;}
}
Thread owner记录当前锁被哪个线程持有了,null表示当前未加锁。CAS会比较当前的 owner 是否是 null,如果是 null就改成当前线程,当前线程就拿到了锁,如果不是null就返回 false 进入下次循环,下次循环再进行CAS判定。如果当前锁一直被别人持有,当前加锁的线程就会再while循环处反复,也就是忙等,自旋锁是一个轻量级锁,也可以视为一个乐观锁,认为当前锁虽然没有拿到,但是预期很快就能拿到,短暂的自旋并不会产生大量的CPU损耗
3.ABA问题
CAS的关键是先比较,再交换,在比较的过程中,当前值和旧值是相同时,就认为中间没有发生过改变,但是可能存在中间发生了改变,但多次改变后值不变的情况。
一个典型的ABA问题的例子,如下图所示,在银行进行取钱时,连续点击了两次取钱100的操作,即线程t1、t2,如果没有 t3 线程那么 t2 线程会判断为 false ,从而取消第二次的重复操作。若在 t2 线程 CAS 操作前 t3 线程对数据进行了 +100 的操作,此时t2线程会判定为true,本来第二次误操作就会执行成功。
9
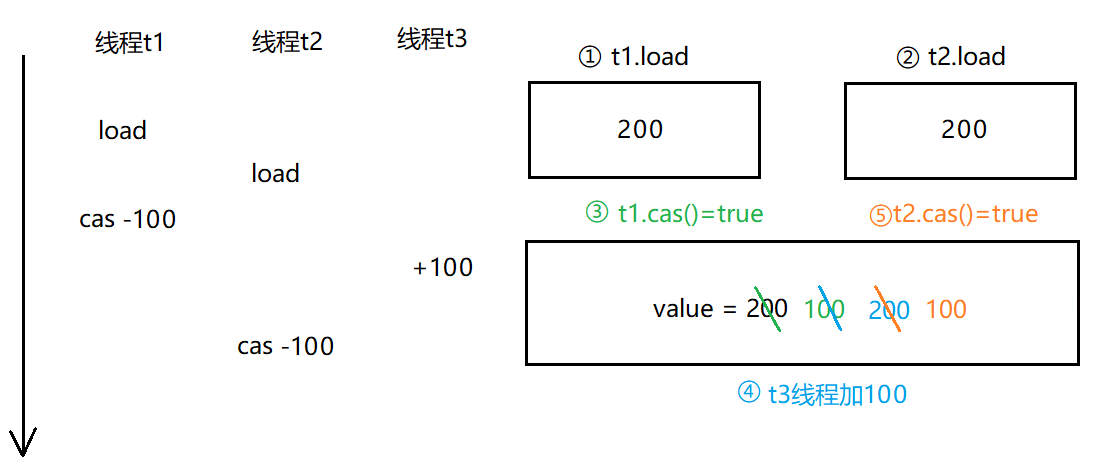
对于ABA问题的解决,可以引入一个“版本号”,版本号只能变大,不能变小,修改变量的时候,就不再比较变量的值本身,而是比较版本号,每次对value进行修改的时候,都要对版本进行加一,每次修改前也要检查版本是否相同。也可使用时间戳,与设置版本号的方式类似
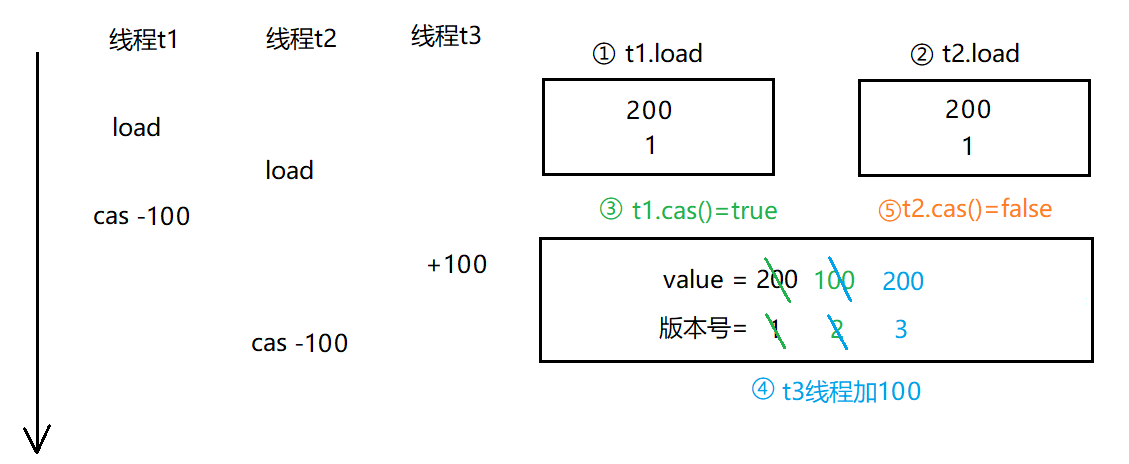
这种基于版本号进行多线程的控制,也是一种乐观锁的体间,常见于数据库管理,版本管理工具(SVN,通过版本号进行多人协同)
(三)synchronized中的锁优化机制
1.锁膨胀/锁升级
锁膨胀/体现了synchronized能够“自适应”的能力,锁膨胀的过程如下,进行加锁的类型会随着加锁而改变状态
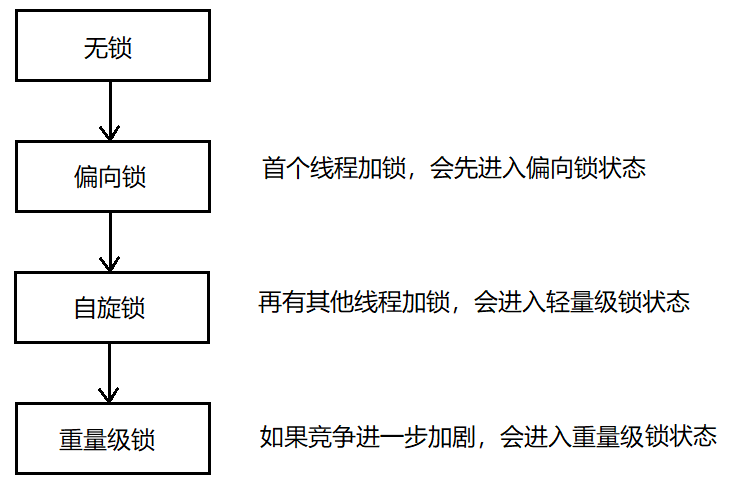
偏向锁并不是真正的加锁,只是做了一个标记,如果后续没有线程来竞争这个锁,就不必真的加锁,从而避免了加锁解锁的开销
2.锁粗化
粗细指的是锁的粒度(加锁的范围大小)。锁粒度较细,那么多个线程之间的并发性就越高;如果锁粒度较粗,那么加锁解锁的开销就会比较小。编译器自身自带一个优化,及自身进行判定,对粒度太细的锁进行粗化,如果两次加锁之间的间隔较大(中间的代码多)一般不会进行优化,如果两次加锁之间的间隔较小(中间的代码少)就可能触发这个优化。
3.锁消除
对于不必要加锁的代码,JVM 虚拟机如果检测不到某段代码被共享和竞争的可能性,就会将这段代码所属的同步锁消除掉。例如 StringBuffer 的 append() 方法,或 Vector 的 add() 方法,这两个类在标准库中已经进行了加锁操作,因此在很多情况下是可以进行锁消除的,
(四)JUC(java.util.concurrent)的常见类
1.Callable
Callable 是一个 interface也是一种创建线程的方式,对比Runnablle来说,Runnablle不太适用于让线程计算并返回一个结果,例如下面的例子从1加到1000,主线程 wait() 等待线程 t,线程 t 结束后通过notify()唤醒线程。
class Result{public int sum=0;public Object lock = new Object();
}
public class Demo {public static void main(String[] args) throws InterruptedException {Result result = new Result();Thread t = new Thread(){@Overridepublic void run(){int sum = 0;for(int i=0;i<=1000;i++){sum=sum+i;}synchronized (result.lock){result.sum = sum;result.lock.notify();}}};t.start();synchronized (result.lock){while (result.sum == 0){result.lock.wait();}}System.out.println(result.sum);}
}
使用Callable能够很好的接收返回值
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;public class Demo {public static void main(String[] args) {//通过Callable来描述一个任务,泛型参数表示返回值的类型Callable<Integer> callable = new Callable<Integer>() {//重写callable中的run方法@Overridepublic Integer call() throws Exception {int sum = 0;for(int i=0;i<=1000;i++){sum += i;}return sum;}};//为了让线程执行 callable 中的任务,需要创建一个辅助的类对Callable进行封装,线程通过该类获取任务FutureTask<Integer> task = new FutureTask<Integer>(callable);//创建线程,用来执行任务Thread t =new Thread(task);t.start();//如果线程任务没有执行完成,get就会陷入阻塞//会一直阻塞到任务完成,得出计算结果try {System.out.println(task.get());} catch (InterruptedException e) {e.printStackTrace();} catch (ExecutionException e) {e.printStackTrace();}}
}
2.ReentrantLock
ReentrantLock的用法包括下面几种:lock()进行加锁,unlock()进行解锁,trylock(超时时间)加锁,如果获取不到锁,等待一段时间后就放弃加锁。
ReentrantLock将加锁和解锁操作分开,可能会导致遗漏而出现死锁问题,例如在 lock() 和 unlock()之间抛出了异常从而导致没有执行到 unlock(),下面的代码保证了不管是否异常都能够执行到unlock()
ReentrantLock lock = new ReentrantLock();
---------------------------------------lock.lock();
try{//working
}finally{lock.unlock();
}
ReentrantLock和synchronized的区别
- synchronized 是关键字,其逻辑基于JVM内部实现(C++);ReentrantLock 是一个标准库中的类,其逻辑基于Java代码实现
- synchronized 不需要手动释放锁,代码块结束锁自动释放;ReentrantLock 必须要手动释放锁,防止忘记释放引起死锁问题
- synchronized 竞争锁失败时会阻塞等待;ReentrantLock 可以使用 trylock(超时时间)的方式,在等待一段时间失败后直接返回
- synchronized 是一个非公平锁;ReentrantLock 提供了公平锁和非公平锁两个版本,可以通过参数进行指定
- 基于synchronized 衍生出来的等待机制是 wait() 和 notify()功能相对有限;基于ReentrantLock 衍生出来的等待机制是Condition类,功能要更丰富一些
3.原子类
原子类的内部基于CAS机制实现,性能比加锁实现i++高很多,常用的原子类有如下几个:
| 类名 | 说明 |
|---|---|
| AtomicBoolean | 布尔型原子类 |
| AtomicInteger | 整型原子类 |
| AtomicLong | 长整型原子类 |
| AtomicIntegerArray | 长整型原子类 |
| AtomicLong | 整型数组原子类 |
| AtomicReference | 引用类型原子类 |
| AtomicStampedReference | 原子更新带有版本号的引用类型 |
以AtomicInteger举例,常见的方法有
addAndGet(int delta); i += delta
decrementAndGet(); --i
getAndDecrement(); i--
incrementAndGet(); ++i
getAndIncrement(); i++
4.线程池
(1)ExecutorService 和 Executors
ExecutorService 表示一个线程实例,Executors是一个工厂类,能给个创建出几种不同风格的线程池。通过ExecutorService 中的 submit 方法能够向线程池中提交若干个任务
ExecutorService pool = Executors.newFixedThreadPool(10);
pool.submit(new Runnable() {@Overridepublic void run() {System.out.println("hello");}
});
Executors创建线程的几种方式
| 方法 | 说明 |
|---|---|
| newFixedThreadPool | 创建固定线程数的线程池 |
| newCachedThreadPool | 创建线程数目动态增长的线程池 |
| newSingleThreadExecutor | 创建只包含单个线程的线程池 |
| newScheduledThreadPool | 设定延迟时间后执行命令,或定期执行命令,是进阶版的Timer |
(2)ThreadPoolExecutor
Executors本质上是对ThreadPoolExecutor的封装,ThreadPoolExecutor提供了更多的可选参数,库进一步细化线程池行为的设定,其构造方法如下
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory,RejectedExecutionHandler handler)
- int corePoolSize 表示核心线程数,int maximumPoolSize 表示最大线程数,包括核心线程和非核心线程。
- long keepAliveTime 表述了非核心线程的存活时间
- TimeUnit unit 表示keepAliveTime的时间单位
- BlockingQueue workQueue 任务队列,线程池会提供一个submit方法将任务放入到线程池任务队列中
- ThreadFactory threadFactory 线程工厂,描述线程是怎么创建出来的
- RejectedExecutionHandler handler,拒绝策略,当任务队列满了设定的 具体策略,包括忽略最新任务、阻塞等待、丢弃最旧任务等方式
5.信号量Semaphore
锁是信号量的一种情况,叫做“二元信号量”,涉及两个操作 :P 操作申请资源,V 操作释放资源
锁可以视为一个“二元信号量”,其可用资源只有一个,计数器的取值非0即1。如下例所示,acquire()方法用来申请资源,release()用来释放资源,当申请资源超过资源总数量时会出现阻塞。
import java.util.concurrent.Semaphore;public class Demo30 {public static void main(String[] args) throws InterruptedException {//初始化可用资源的数量为4Semaphore semaphore = new Semaphore(4);//申请操作,P操作semaphore.acquire();System.out.println("申请第1个资源");semaphore.acquire();System.out.println("申请第2个资源");semaphore.acquire();System.out.println("申请第3个资源");semaphore.acquire();System.out.println("申请第4个资源");semaphore.acquire();System.out.println("申请第5个资源");//释放操作,V操作semaphore.release();}
}
6.CountDownLatch
对于一个文件来说,为提高下载效率可以将文件进行拆分,通过多个线程来下载其中的一个部分,有的资源下载的快,有的下载的慢,需要所有的进程都下载完毕,整个文件才算下载完成,CountDownLatch就是起到了这样一个判断终点线的作用
涉及两个方法:countDown() 给每个线程里面去调用,表示到达终点了;await() 给等待线程去调用,当所有的任务都到达终点了,await就从阻塞中返回,表示任务完成
如下例所示,当调用countDown的次数和个数一致的时候,就会产生await返回的情况
import java.util.concurrent.CountDownLatch;public class Demo31 {public static void main(String[] args) throws InterruptedException {//表示一共用几个线程参与CountDownLatch latch = new CountDownLatch(10);for(int i = 0;i<10;i++){Thread t = new Thread(()->{try {Thread.sleep(3000);System.out.println(Thread.currentThread().getName() + "到达终点");latch.countDown();} catch (InterruptedException e) {e.printStackTrace();}});t.start();}//需要等到所有的线程结束//当线程执行完的时候,await就阻塞,所有的线程都执行完了,await才返回latch.await();System.out.println("比赛结束");}
}
7.线程安全的集合类
(1)多线程环境使用ArrayList
- 自己使用同步机制( synchronized 或者 ReentrantLock )
- Collections.synchronizedList( new ArrayList);
synchronizedList是标准库中提供的一个基于synchronized进行线程同步的List,synchronizedList 的关键操作上都带有synchronized - 使用CopyOnWriteArrayList
写时拷贝,在修改的时候会创建出副本,对于一个ArrayList{1,2,3,4},如果是多线程读,则不会产生线程安全问题,如果多线程写,则会把ArrayList给复制一份,优先修改副本,这样在修改的同时,对读操作是没有任何影响的,即读的时候先读旧的版本,避免了读到未修改完成的中间状态
(2)多线程环境使用队列
| 队列 | 说明 |
|---|---|
| ArrayBlockingQueue | 基于数组实现的阻塞队列 |
| LinkedBlockingQueue | 基于链表实现的阻塞队列 |
| PriorityBlockingQueue | 基于堆实现的阻塞队列 |
| TransferQueue | 只包含一个元素的阻塞队列 |
(3)多线程环境使用哈希表
- HashMap本身是线程不安全的,而HashTable 通过给方法直接加锁来保证线程的安全,针对this来进行加锁(针对对象进行加锁),因此当有多个线程访问这个Hashtable的时候,会导致锁竞争的概率非常大,效率较低
public synchronized V get(Object key)
public synchronized V put(K key, V value)
...
- ConcurrentHashMap 操作元素的时候,是针对这个元素所在的链表头结点来进行加锁的(锁桶),如果两个线程针对两个不同链表上的元素进行操作,没有线程安全问题不必要加锁。由于Hash表中,链表的数目非常多,每个链表的长度是相对短的,因此可以保证冲突的概率非常小了


- ConcurrentHashMap的优点
- ConcurrentHashMap减少了锁冲突,即锁加在每个链表的头结点上。
- ConcurrentHashMap只是针对写操作加锁了,读操作没有加锁,只是使用volatie。
- ConcurrentHashMap更广泛的使用了CAS,进一步提高了效率。
- .ConcurrentHashMap针对扩容进行了巧妙的化整为零。如果链表过长,就会影响Hash表的效率,扩容就需要创建一个更大的数组,把之前的元素给搬运过去,效率低,对于HashTable来说,只要这次put触发了扩容就一口气搬完,导致这次put非常卡顿。而ConcurrentHashMap每次操作只搬运一点点,通过多从操作完成整个搬运过程,同时维护一个新的 HashMap 和一个旧的 HashMap ,查找的时候既要查找旧的也查找新的,插入的时候只插入新的,直到搬运完毕才销毁旧的
代码如下(示例):