人工智能期末复习1
该笔记为2024.7出版的人工智能技术应用导论(第二版)课本部分的理论总结。
一、人工智能的产生与发展
概念:人工智能是通过计算机系统和模型模拟、延申和拓展人类智能的理论、方法、技术及应用系统的一门新的技术科学。
发展:1943完成最早的工作,1956年开始艰难发展60年,从2017年至2023年相关技术突飞猛进。
AI赋能
定义:通过AI技术模仿和增强人类的各种能力,为应用系统和机器赋予人的能力、智力。
1.感知能力——图像与视觉
AI在视觉方面的研究与应用主要分为数字图像处理DP、计算机视觉CV、机器视觉MV三大领域。
数字图像处理:将图像信号或视频信号转换成数字图像信号并利用计算机对其处理。包括去~噪、增强、复原、分割、变换、重建、提取特征、识别(场景、物体、动作、形态等)等。
计算机视觉:利用摄像机和计算机模仿人类视觉(眼睛和大脑),对目标分割、分类、识别、跟踪、判别、决策。它的研究目标是让计算机能通过二维图像认知三位环境信息的能力。侧重于分析。
机器视觉:用机器代替人眼做测量和判断。通过图像摄取装置将被摄取目标转换成图像信号传送给专用的图像处理系统,再将相关信息转换成数字信号。让图像系统运算这些信号抽取特征,根据判别的结果控制现场设备运行。侧重于做人做不到的工作。
图像摄取装置分为CMOS和CCD两种。
2.语言能力——自然语言处理
自然语言处理NLP:语音识别、语义理解、语音输入、语音交互、语音合成、文本生成、机器翻译、声纹特征识别。
3.记忆能力——知识表示与知识图谱
知识表示 = 结构模型 + 处理机制
知识库是基于知识的系统,具有智能性
4.推理能力——自动推理与专家系统
专家系统 = 知识库 + 推理机
5.规划能力——智能规划
规划时通常把某些复杂问题分解成较小子问题。实现问题分解有两条重要途径:
①当从一个问题状态移动到下一个状态时无需计算整个新的形态,只要考虑状态中可能变化了的部分;
②把单一困难问题分割为几个有希望较为容易解决的子问题。
6.学习能力——机器学习
机器学习ML是实现学习能力的主要方法。基于反向传播深度卷积神经元网络的机器学习又称深度学习DL。
人工智能、机器学习与深度学习
AI的分类
从AI实现智能的方式可分为计算智能、感知智能和认知智能。
计算智能:计算能力和存储能力超强的智能。如神经网络、遗传算法。
感知智能:机器能听会说人类的语言,看懂世界的智能。如智能语音、智能视觉。
认知智能:机器能主动思考并采取行动。如自动驾驶汽车、知识图谱、预训练大模型。
1.模式识别
模式识别是通过计算机采用数学知识和方法来研究模式的自动处理与判读。
2.机器学习
人工智能包括机器学习包括深度学习。
机器学习最基本的思路是使用算法解析训练数据(模型训练),从中学习到特征(得到模型),再根据模型对真实事物分类、预测、决策。
3.深度学习
这里的“深度”指的是人工神经元网络的层数,可多达上千层,并通过卷积、池化、反向传播等非线性变换方法进行分析、抽象和学习的神经网络,模拟人脑机制“分层”抽象和解释数据、提取特征、建立模型。
算法、算力、大数据
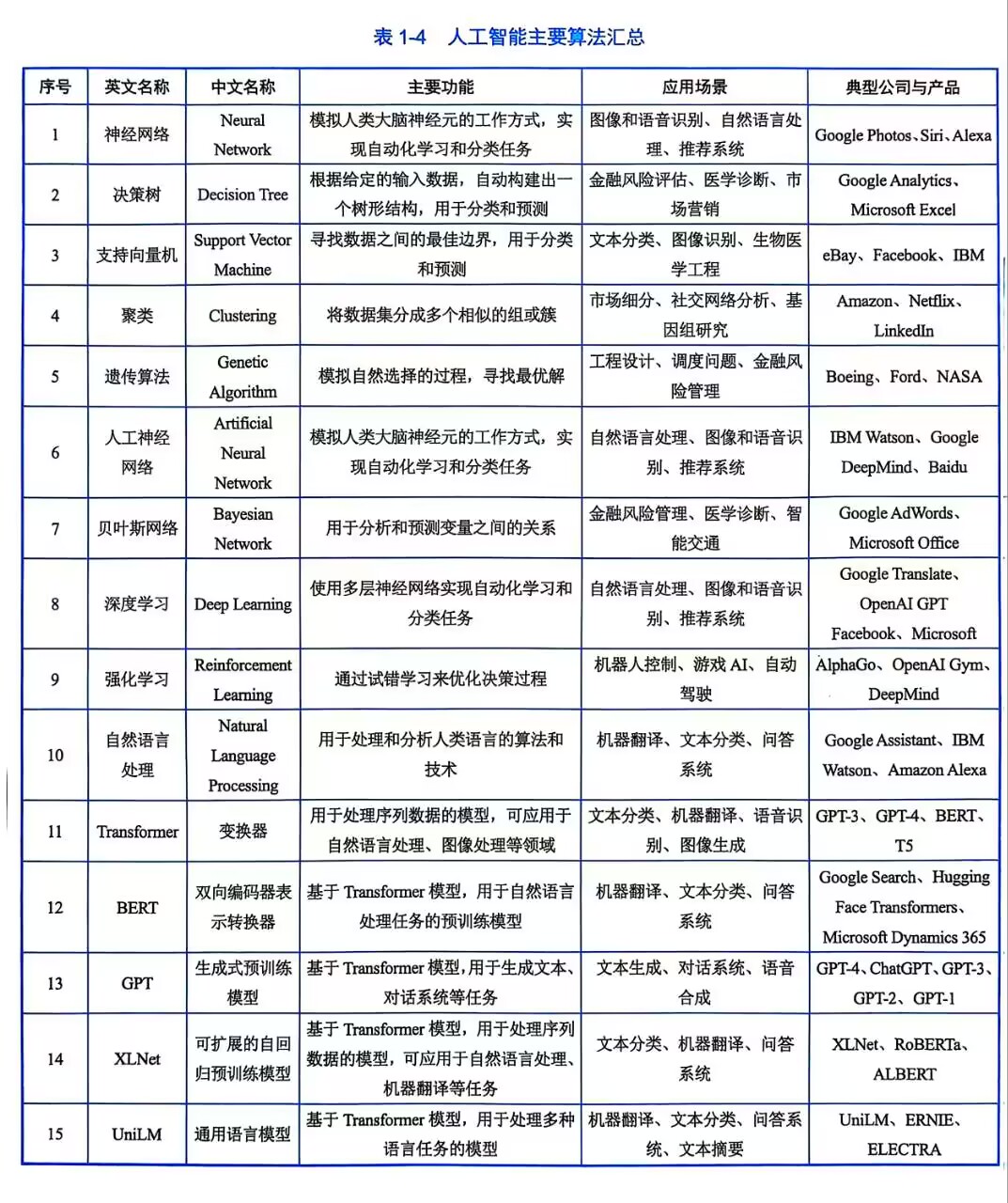
人工智能崛起的三大基石:互联网与云计算支撑下的大数据基础、计算力平台和算法引擎。
人工智能算法如下图所示。
二、AI典型应用
①科大讯飞
科大讯飞开放平台是基于云计算和互联网的、以语音综合智能服务为主的开放平台。
在各种电子设备上均有应用。以及讯飞输入法、智能音箱、讯飞星火认知大模型。
②OpenAI的GPT和ChatGPT
ChatGPT又称为聊天生成式预训练大语言模型。
③人脸识别、智能商务、智能机器人、智能视频监控、智能数字人
三、常用数据集
Python基本数据类型有6种,分别是:数字、字符串、列表、元组、字典、集合。在学习本章节前需熟悉他们的相关操作。详见Python程序设计基础笔记。
对于数据的收集、整理、清洗;数据分析;图像处理相关部分详见数据分析笔记。
MNIST——手写数字数据集
每张图片包括28*28=784个像素点,用一个数字数组表示。
MNIST训练数据集中,mnist.train.images是一个形状[60000,784]的张量。此张量的每一个元素都表示某个像素的强度值,值介于0和1之间。
CTW——中文自然文本数据集
包括32285张图像和1018402个中文字符。
四、机器学习
简介
基本含义:机器学习是通过算法与模型训练,让机器从已有数据(训练数据集)中自动分析,习得规律(模型与参数),再利用规律对未知数据进行预测。
机器:包含硬件和软件的计算机系统。
所有机器学习都基于算法,算法是计算机用来解决问题的特定指令集。
机器学习处理的数据有结构化数据和非结构化数据。
结构化数据:用二维表来逻辑表达和实现的数据。
非结构化数据:数据结构不规则或不完整,没有预定义的数据模型。如文本,语音,图像,视频。
机器学习的分类
从学习形式的视角:有监督学习,半监督学习,无监督学习,强化学习。
从学习任务的视角:分类,回归,聚类,降维,异常查找。
有监督学习
利用一组带标签的数据,学习从输入到输出的映射,从这种映射关系应用到未知数据上,达到分类或回归的目的。
分类任务输出标签是离散的。例如身高,体重,性别。
回归任务输出标签是连续的。例如某一地区人的平均身高。
无监督学习
无监督学习中数据集中数据完全没有标签。依据相似样本在数据空间中一般距离较近这一假设将样本进行分类。
无监督学习可以解决关联分析,聚类问题,维度约减。
关联分析:发现不同事物之间同时出现的概率。
聚类问题:将相似的样本划分为一个簇。
维度约减:减少数据维度的同时保证不丢失有用的信息。
半监督学习
有监督学习和无监督学习相结合的一种学习方法。一般针对数据量大,但有标签的数据少,或标签数据的获取代价高。训练的时候一部分数据有标签,一部分数据没有标签。
半监督学习成本低,准确度高。
相关术语
| 术语 | 解释 | 英文 |
| 模型 | 机器学习的核心是机器学习算法在经过数据训练后参数具备了一定智能的产物,即可以使用训练好的模型对新的输入做出判断 | model |
| 学习/训练 | 模型通过执行某个机器学习算法,凭借数据提供的信息改进自身性能 | learning/training |
| 数据集 | 一组具有相似结构的数据样本的集合 | data set |
| 实例 | 对某个对象的描述,也叫样本sample | instance |
| 属性 | 对象某方面表现或特征,也叫特征feature | attribute |
| 属性值 | 属性上的取值 | attribute value |
| 特征向量 | 一个样本的全部特征构成的向量; 一个特征向量就是一个样本 | feature vector |
| 维数 | 描述样本属性参数的个数 | dimensionality |
| 训练数据 | 训练过程使用的数据 | training data |
| 训练样本 | 训练过程使用的数据样本 | training sample |
| 训练集 | 训练样本组成的集合 | training set |
| 验证样本 | 用来调整模型参数的样本 | validation sample |
| 验证集 | 验证样本组成的集合 | validation set |
| 测试 | 得到模型后用模型进行预测的过程 | testing |
| 测试样本 | 被预测的样本 | testing sample |
| 测试集 | 测试样本组成的集合 | testing set |
| 泛化 | 泛化能力:学得的模型适用于新样本的能力 | generalization |
| 过拟合 | 模型过度学习,学习了过多只属于训练数据的特点,使泛化能力下降 | overfitting |
| 欠拟合 | 模型学习不足,没有学习到训练数据中的一般规律,使泛化能力不足 | underfitting |
分类算法的验证
| 实际为1 | 实际为0 | |
| 预测为1 | TP | FP |
| 预测为0 | FN | TN |
可以理解为预测与实际相符为T,不符为F;预测为1为P,预测为0为N。
精确率precision:分类算法预测的正样本中预测正确的比例,取值范围为[0,1],取值越大,预测能力越好。
准确率accuracy:分类算法正确分类的样本数和总样本数之比。
召回率recall:分类算法预测正确的正样本占所有正样本的比例。
scikit-learn中基本概括classification分类、clustering聚类、regression回归、dimensionality reduction降维中的大部分内容。它的安装需要建立在Numpy、SciPy安装成功的基础上。
过拟合和欠拟合的判断标准
| 训练集中表现 | 测试集中表现 | 结论 |
| 布豪 | 布豪 | 欠拟合 |
| 好 | 布豪 | 过拟合 |
| 好 | 好 | 适度拟合 |
☆分类
分类classification是在已有数据的基础上建立一个分类函数或构造一个分类模型,即分类器classifier。
分类任务的目标是从已经标记的数据中学习如何预测未标记数据的类别。用于预测离散的数据。
一般步骤:数据分割、训练、验证、应用。
机器学习任务的常用算法有:
| 算法 | 二分类 | 多类别分类 | 多标签分类 |
| K近邻分类算法 | V | V | |
| 决策树分类算法 | V | V | V |
| 贝叶斯分类算法 | V | V | |
| 支持向量机分类算法 | V |
K近邻分类算法
K-Nearest-Neighbors Classification, KNNC
算法描述
1、计算已知类别数据集中的点与当前点距离
2、按照距离递增次序排序
3、选取与当前点距离最小的K个点
4、确定前K个点所在类别的出现概率
5、返回前K个点出现频率最高的类别作为当前点的预测分类
基本要素
K值的选择、距离度量、分类决策规则
K值较小过拟合,K值较大欠拟合。
通过计算样本距离作为各个样本间的非相似性指标,距离一般用欧式距离或曼哈顿距离。
算法决策规则:多数表决,即由输入样本的前K个最近邻的训练样本中的多数类决定输入样本的类别。
决策树分类算法
Decision Tree Classification
算法描述
1、自上而下生成决策树
2、每个属性有不同属性值
3、根据不同属性值划分可得到不同结果
决策树是一种树形结构,每个内部节点表示一个属性的条件判断,每个分支代表一个条件输出,每个叶节点代表一种类别。
实现原理
将原始数据基于最优划分属性来划分数据集,第一次划分之后,可以采用递归原则处理数据集。
递归结束条件:程序遍历完所有划分数据集的属性,或者每个分支下的所有样本都具有相同分类。
流程
1、创建数据集
2、计算数据集中所有属性的信息增益
3、选择信息增益最大的属性为最好的分类属性
4、根据3得到的分类属性分割数据集,直到分类结束
5、返回3递归,不断分割数据集,直到分类结束
6、使用决策树分类,返回分类结果
贝叶斯分类算法
Beyes Classification, BC
算法描述
利用概率统计知识进行分类的算法。
支持向量机分类算法
Support Vector Machine Classification, SVMC
主要思想
建立一个最优决策平面,使得该平面最近的两类样本之间的距离最大化。
有良好的泛化能力。
人工神经网络
Artificial Neural Network, ANN
有良好的鲁棒性、自组织自适应性、并行处理、分布存储和高度容错等特性。
☆回归
回归属于有监督学习,用于预测连续的数据。
步骤
数据分割、训练、验证、应用。
线性回归
linear regression
显示自变量与因变量之间的线性关系。
找一条直线,并让直线尽可能拟合图中数据点。
逻辑回归
logistics regression
是一种广义线性模型generalized linear model
适用条件
1、因变量为二分类变量或某事件的发生率,是数值类变量。不能有重复计数现象。
2、残差和因变量都要服从二项分布。二项分布对应的是分类变量->不是正态分布->不能用最小二乘法->能用最大拟然法解决方程估计和检验问题。
3、自变量和逻辑概率是线性关系。
4、各观测对象间相互独立。
主要算法
K近邻回归:K-Nearest-Neighbors Regression, KNNR通过找出某个样本的K个最近的邻居,将这些邻居的预测属性的平均值赋给该样本,得到该样本的预测值。
它的一个改进算法将不同距离的邻居对该样本产生的影响给予不同权值,如权值与距离成反比。
决策树回归算法:与分类树思路类似,但叶节点的数据类型不是离散型而是连续型。
使用条件
属性值是连续分布的,依旧可以划分群落,每个群落内部是相似的连续分布,群落之间分布不同。
一句话概括为”物以类聚“。
支持向量回归算法:Support Vector Regression, SVR。是基于支持向量分类的方法的扩展。
☆聚类
含义:将对象的集合分成由类似对象组成的多个类的过程是聚类clustering。
聚类生成的簇是一组数据对象的集合。
聚类是无监督的机器学习。
聚类的方法:距离相似度度量、密度相似度度量、连通性相似度度量、概念相似度度量。
K-均值聚类
K-means
步骤
1、从N个数据中随机选取K个数据作为中心点
2、对剩余的每个数据测量其到每个中心点的聚类,并把它归到最近的中心点的类。
3、重新计算已得到的各个类的中心点。
4、迭代2、3直到心的中心点与原中心点相等或小于指定阈值即结束。
分类、回归、聚类
| 分类 | 回归 | 聚类 | |
| 类型 | 监督学习 | 监督学习 | 无监督学习 |
| 应用举例 | 判断一个人是否患有癌症 | 输入一个人的数据,判断他20年后的经济能力 | 电商平台将客户分为不同群体分别推荐货物 |
| 输入 | 针对离散值 | 针对连续值 | 离散值、连续值都可 |
| 输出 | 通过产生的几个函数划分为几个集合 | 通过产生的几个函数产生连续的结果 | 产生几个集合,集合中的元素彼此相似 |
五、神经网络
人工神经元网络Aritificial Neural Network, ANN,简称人工神经网络或神经网络。神经网络是一种运算模型,包括:
1、节点(神经元)
2、激活函数(激励函数)Activation Function
3、权重(权值)Weight
基本特征:非线性、非局限性、非常定性、非凸性
人工神经元相当于一个多输入,单输出的非线性阈值器件。
神经元的计算过程称为激活Activation。
常用的激活函数有:逻辑函数Sigmoid、双曲正弦函数Tanh、线性整流函数Rectified Linear Unit, ReLU。 逻辑函数是最常用的。
人工神经元特点
1、多输入、单输出元件
2、具有非线性的输入、输出特性
3、具有可塑性,其可塑性变化部分主要是权值变化
4、神经元的输出响应式各个输入值的综合作用结果
5、输入分为兴奋型(正值)和抑制型(负值)
输入层对应样本特征,输出层对应输出结果,中间零到多层的隐藏层。
通常把需要计算的层称为”计算层“。
一个神经网络的搭建需要满足:输入和输出,权重和阈值,多层网络结构。
神经网络运作过程
1、确认输入和输出
2、找到一种或多种算法,可以从输入得到输出
3、采用一组已知答案的数据集,用来训练模型,估算权重和阈值
4、一旦新的数据产生,输入模型,可得到结果,同时对权重和阈值进行校正
整个运作过程需要海量计算,一般CPU不能满足计算需求,需定制GPU和TPU或专用FPGA。
Graphics Processing Unit、Tensor Processing Unit、Field-Programmable Gate Array
神经网络分类
1、按性能:连续型网络和离散型网络,或确定型和随机型网络
2、按学习方法:有监督学习网络、半监督学习网络、无监督学习网络
3、按拓扑结构:前馈网络和反馈网络。
tips:拓扑:研究几何图形或空间在连续变形下保持不变的性质。
前馈网络有自适应线性神经网络(AdaptiveLinear简称Adaline)、单层感知器、多层感知器、BP。
神经网络主要特点
并行处理的结构、可塑性的网络连接、分布式的存储记忆、全方位的互连、群体的集合运算、强大的非线性处理能力。
神经网络优缺点
优点:能够处理复杂线性问题、能发现不同输入间的依赖关系、允许增量式训练。
缺点:黑盒方法,训练数据量的大小及问题相适应的神经网络规模方面没有明确规则可遵循。
感知器组成部分
输入权值、激活函数(用到阶跃函数)、输出
神经网络可视化工具——PlayGround
前馈神经网络
模型
前馈神经网络Feed Forward Neural Network简称前馈网络,是一种单向多层结构网络,其中每一层包含若干神经元,同一层的神经元之间没有互相连接,层间信息的传送只沿一个方向进行。
各神经元从输入层开始,接收前一级输入,输出到下一级,直至输出层。整个网络中无反馈,可以用有向无环图表示。
前馈网络具有复杂的非线性映射能力,但前馈网络的输出仅仅由当前输入和权值矩阵决定,而与网络先前的输出状态无关。前馈网络中,无论是离散型还是连续性,一般不考虑输出和输入在时间上的滞后性,只表达二者间映射关系。
基本BP算法包括信号的正向传播和误差反传两个过程。
常见前馈神经网络有感知器网络、BP网络、RBF网络
反向传播神经网络
BP网络按照误差逆向传播算法训练的多层前馈神经网络。
基本思想是梯度下降法,利用梯度搜索技术,让网络的实际输出值和期望输出值误差均方差最小。
BP网络是在输入层和输出层之间加入若干层(1层及以上)神经元,中间层(隐层)与外界没有直接联系,但其状态的改变能影响输入与输出之间的关系,每一层可以有若干节点。
BP网络实际上是多层感知器。
BP算法属于有监督学习。
反馈神经网络模型
Feedback Neural Network是一种反馈动力学系统(状态随时间变化的系统)。
离散Hopfield神经网络
Hopfield神经网络是一种循环神经网络
连续Hopfield神经网络
连续Hopfield神经网络是一种单层反馈非线性是网络,每一个神经元的输出均反馈至所有神经元的输入。
循环神经网络
循环神经网路Recurrent Neural Network, RNN,是一类以序列数据为输入,在序列的演进方向递归且所有节点(循环单元)按链式连接的递归神经网络Recursive Neural Network。
卷积神经网络
Convolutional Neural Network, CNN是一种前馈神经网络,对于大型图像处理有出色表现。
卷积convolution的本质是两个序列/函数的平移与加权叠加。
卷积神经网络本质上是一个多层感知机,采用了局部连接和共享权值的方式,使得神经网路易于优化,降低过拟合风险。
卷积神经网络主要功能是特征提取和降维。
特征提取:使用计算机提取图像信息,决定每个图像的点是否属于一个图像特征。特征提取的结果是把图像上的点分为不同子集,这些子集往往属于鼓励的点、连续曲线或连续区域。
降维:通过线性或非线性映射,将样本从高维度空间映射到低维度空间,从而获得高维度数据的一个有意义的低维度表示过程。
卷积神经网路是一种特殊的深层神经网络模型,特征体现在它的神经元的连接是非全连接的,同一层的某些神经元之间的连接的权重是共享的(相同的)。
卷积神经网络是一种多层的有监督学习神经网络。其隐藏层中的卷积层和池化层是实现卷积神经网络特征提取和降维功能的核心模块。
通过梯度下降法最小化损失函数对网络中的权重参数逐层反向调节,通过频繁的迭代训练提高网络精度。
一般结构:输入层->卷积层->池化层->(重复卷积层与池化层)->可以是多层的全连接层->输出结果。层的大小一般为2的整数倍。卷积层使用较小的卷积核,如3X3,最大5X5。卷积层用来特征提取,池化层用来降维。
卷积神经网络的结构——LeNet-5
共有7层(不包括输入层),分别是2个卷积层,2个下抽样层,3个全连接层。其中的C5是卷积层,但使用全连接。
输入层
C1卷积层
S2池化层(下采样层)
C3卷积层
S4池化层
C5卷积层
F6全连接层
输出层(全连接层)
六、深度学习
TensorFlow深度学习框架
流程:准备数据、定义模型、训练模型、评估模型、使用模型、保存模型。
实践中的数据类型包括结构化数据、图片数据、文本数据、时间序列数据。
层次结构从低到高的5层
硬件层:支持CPU、GPU、TPU
内核层:C++实现内核,内核可跨平台分布运行
低阶API:为Python实现的操作符
中阶API:为Python实现的模型组件
高阶API:为Python实现的模型成品