map和set的应用总结
目录
1.map和set
2.set系列的使用
1.set和multiset的使用文档介绍
2.set类的介绍
编辑
3.迭代器的使用
3.set和multise的差别
4.map的使用
5.pair
6.这里介绍一下map的[]的使用方法
7.题目练习
下面我们借助一个题目来熟悉一下map和multimap的接口,体会一下k-v的使用方法:
编辑
1.map和set
set存储的是key值,map存储的是key-value值,它们都属于关联式容器,正常情况下map和set不支持冗余,想要插入相同的数据,需要使用multiset和multimap来进行冗余数据的插入,这里冗余指的是key值相等。
2.set系列的使用
1.set和multiset的使用文档介绍
https://legacy.cplusplus.com/reference/set/
2.set类的介绍
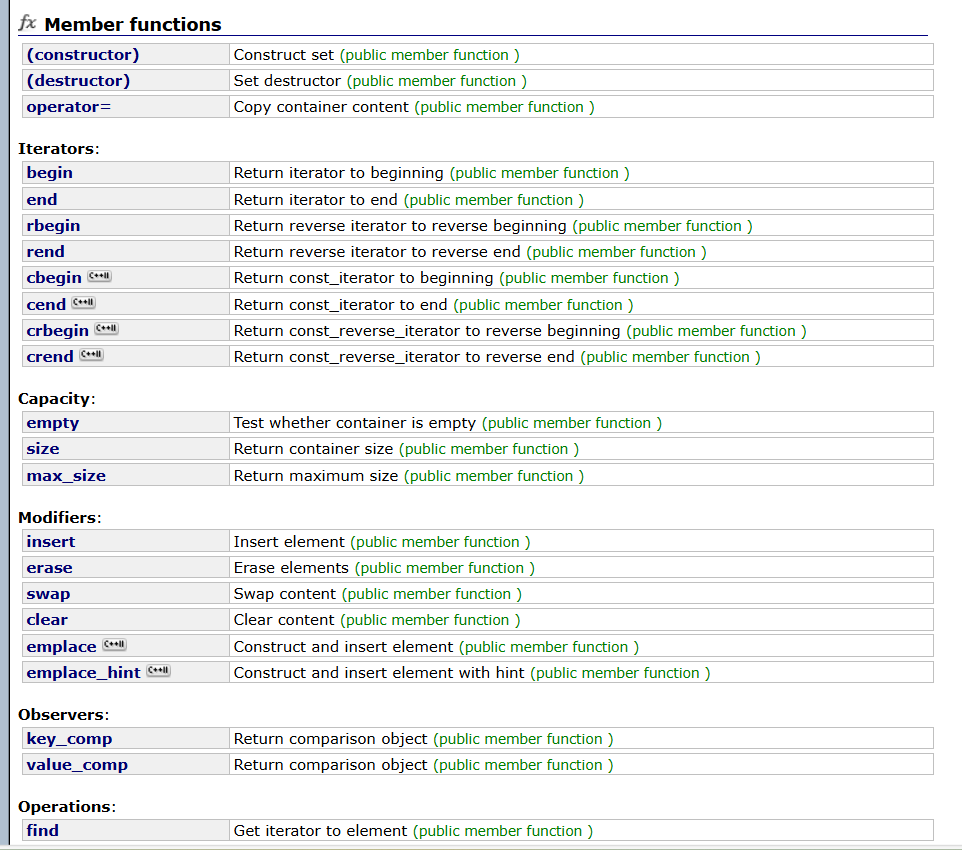
库中给出了set的一些接口,我们介绍一下,和其他容器一样,set也支持迭代器,它的迭代是中序遍历,insert是插入一个数据,这里插入之后会自动进行排序,find是在set中寻找你想要的值,找到返回迭代器,未找到返回end(),count是返回容器中有一个要寻找的值,未找到返回0.
3.迭代器的使用
这里要注意一下,set的迭代器不能修改数据,因为一旦修改数据,会导致树的结构错乱,破坏了树结构。
3.set和multise的差别
set不支持冗余数据的插入,multise支持冗余数据的插入。
4.map的使用
map和set的区别是它支持key-value的插入,我们不可以修改key值,但是可以修改value的值,它本质是加了一个变量value来帮助我们实现更多的功能,比如字典某一个字母出现的次数。它的查找效率是logN。
5.pair
map底层的红⿊树节点中的数据,使⽤pair<Key, T>存储键值对数据。
6.这里介绍一下map的[]的使用方法
map的[]里应该是key值,如果有,则返回value的值,没有则插入。
下列代码中,如果在map中未找到str,就会插入,并且value值+1。
int main()
{// 利⽤[]插⼊+修改功能,巧妙实现统计⽔果出现的次数string arr[] = { "苹果", "西⽠", "苹果", "西⽠", "苹果", "苹果", "西⽠","苹果", "⾹蕉", "苹果", "⾹蕉" };map<string, int> countMap;for (const auto& str : arr){// []先查找⽔果在不在map中// 1、不在,说明⽔果第⼀次出现,则插⼊{⽔果, 0},同时返回次数的引⽤,// 2、在,则返回⽔果对应的次数++countMap[str]++;}for (const auto& e : countMap){cout << e.first << ":" << e.second << endl;}cout << endl;return 0;
}int main()
{
map<string, string> dict;
dict.insert(make_pair("sort", "排序"));
// key不存在->插⼊ {"insert", string()}
dict["insert"];
// 插⼊+修改
dict["left"] = "左边";
// 修改
dict["left"] = "左边、剩余";
// key存在->查找
cout << dict["left"] << endl;
return 0;
}7.题目练习
下面我们借助一个题目来熟悉一下map和multimap的接口,体会一下k-v的使用方法:
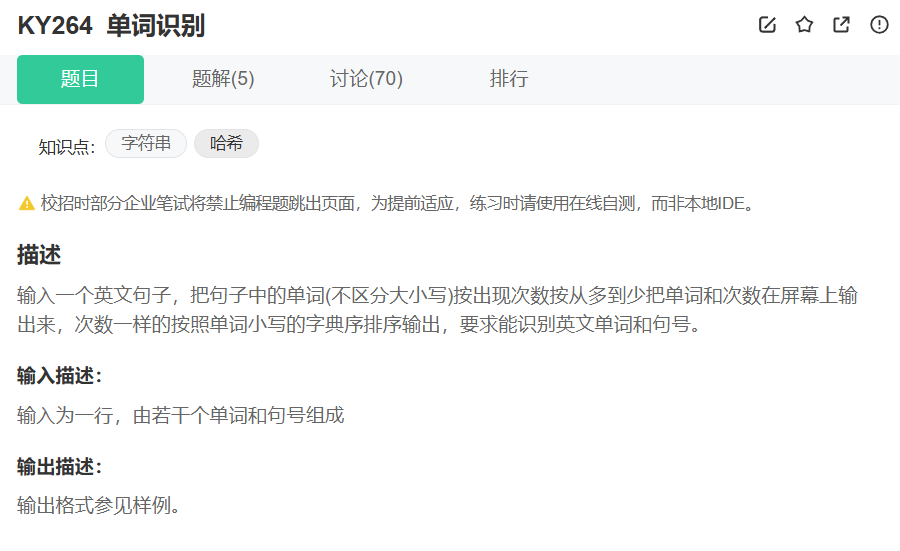
这道题目让我们打印各个单词出现的次数,我们先把这个stringd单词存到map中去,让它的字母按顺序排,然后按降序再存入map<int,string,greater<int>>中去,方便我们的打印,这样第一次存我们按照字母的顺序存入,第二次存入我们按照出现次数进行存入,既保证了次数相同字母的出现顺序,又保证了从大到小的存入。
注:二次存入的一个原因是key无法修改,只能修改v,如果我们只存入一次,第一次只会得到字母的顺序,无法得到按v的顺序,第二次存入是得到v的顺序和k的顺序。
下面我们给出相应的代码参考
#include<iostream>
#include<map>
using namespace std;
int main()
{string a;map<string, int>mup;int count = 0;while (cin >> a){if (a[0] <= 'Z' && a[0] >= 'A'){a[0] = a[0] + 32;}if (a[a.size()-1] == '.'){a.pop_back();auto it1= mup.find(a);if (it1 == mup.end()){mup.insert({ a, 1 });}else{mup[a]++;}break;}else{auto it = mup.find(a);if (it == mup.end()){mup.insert({ a, 1 });}else{mup[a]++;}}}multimap<int, string, greater<int>>mup2;for (auto e : mup){mup2.insert({ e.second,e.first });}for (auto e : mup2){cout << e.second << ":" << e.first << endl;}return 0;
}