联邦学习常见模型
在联邦学习(Federated Learning, FL)中,模型的选择和设计通常取决于应用场景、数据分布和通信效率等因素。以下是一些常见的联邦学习模型,涉及了不同的优化目标、算法和应用场景。
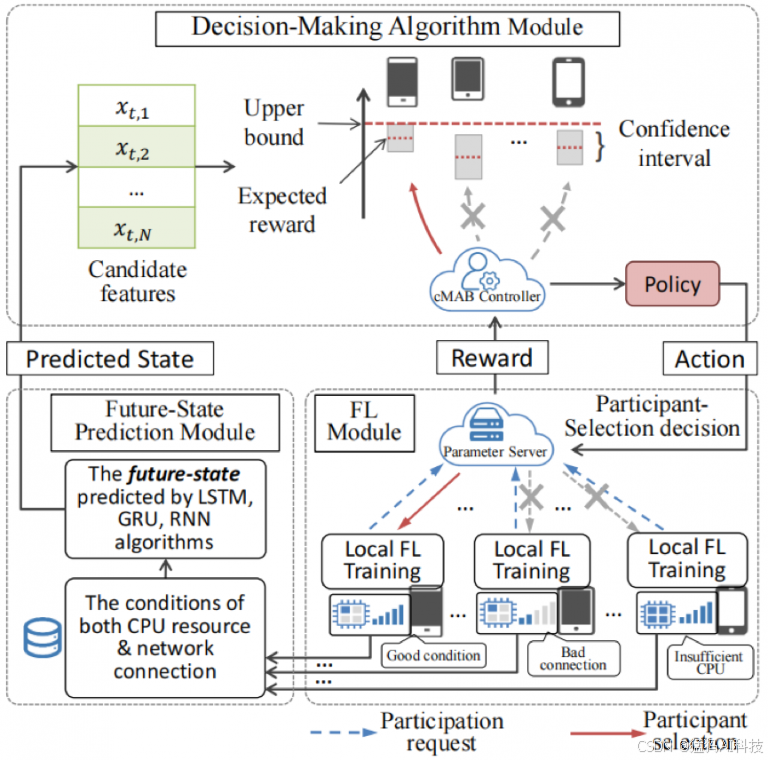
1. 联邦平均(FedAvg)
FedAvg 是联邦学习中最经典且常用的模型。它的主要思想是通过在每个参与节点上本地训练模型,然后将这些本地更新的模型权重进行平均,以生成全局模型。
工作原理:
- 每个参与节点(如移动设备)根据本地数据进行一定数量的训练。
- 训练完成后,每个节点将更新后的模型参数发送到服务器。
- 服务器收集所有节点的模型参数,并计算加权平均(通常按照每个节点的数据量加权)以生成新的全局模型。
- 然后,新的全局模型被发送回所有节点进行下一轮训练。
优缺点:
- 优点:简单高效,易于实现,是联邦学习的标准方法。
- 缺点:对于数据非独立同分布(Non-IID)问题较为敏感,训练过程中可能出现不一致的结果。
2. 联邦SGD(Federated Stochastic Gradient Descent)
联邦SGD 是基于经典的随机梯度下降(SGD)方法,但它是在分布式环境中进行的。与FedAvg相比,FedSGD更多地关注每个节点上每轮训练后的模型更新。
工作原理:
- 每个节点利用本地数据进行单次梯度更新,并将更新的梯度(而非参数)发送到服务器。
- 服务器通过合并所有节点的梯度并更新全局模型。
优缺点:
- 优点:梯度级别的合并通常比模型参数的合并具有更高的精度,适用于一些对精度要求较高的任务。
- 缺点:每轮通信频繁,尤其是在大规模数据集上可能会导致高通信开销。
3. 个性化联邦学习(Personalized Federated Learning, PFL)
传统的联邦学习方法通常使用一个统一的全局模型,但在许多应用中,不同用户或设备的数据分布不同,导致全局模型的性能下降。个性化联邦学习旨在为每个设备或用户定制一个个性化的模型。
工作原理:
- 个性化联邦学习方法通常会在全局模型的基础上,为每个设备进行微调或加上个性化的参数。
- 通过元学习(Meta-learning)或迁移学习(Transfer Learning)技术,根据每个设备的数据特征优化模型。
优缺点:
- 优点:能够解决数据非独立同分布(Non-IID)问题,提高个性化性能。
- 缺点:个性化训练可能需要更高的计算开销和更多的通信。
4. 异步联邦学习(Asynchronous Federated Learning)
在传统的联邦学习中,所有设备都同步地进行训练并上传更新,这可能会受到网络延迟和设备不一致性的影响。异步联邦学习则允许设备不需要在同一时刻进行同步更新。
工作原理:
- 每个设备在本地训练后,立即将模型更新上传到服务器,而不需要等待其他设备完成。
- 服务器根据上传的更新进行全局模型的更新,不要求每个设备都按顺序更新。
优缺点:
- 优点:提高了训练的效率,尤其是当设备数量非常大时,可以减少同步延迟。
- 缺点:可能导致训练过程的不稳定,特别是在设备更新不均匀时,可能出现“模型漂移”问题。
5. 联邦强化学习(Federated Reinforcement Learning, FRL)
联邦强化学习是联邦学习的一个扩展,它结合了强化学习和联邦学习的思想。它通常用于多方协作的环境中,其中每个节点都在进行强化学习任务(例如智能体在环境中的互动),并共享策略或值函数的更新。
工作原理:
- 每个节点(智能体)根据自己的环境和状态进行强化学习。
- 训练结束后,每个节点将其策略或价值函数的更新发送到服务器。
- 服务器将这些更新合并,并返回给每个智能体进行新的训练。
优缺点:
- 优点:适用于多个分布式环境(如智能城市、自动驾驶等),能够通过协作提高策略优化效果。
- 缺点:强化学习通常需要长时间的训练,通信开销较大,且可能面临策略不一致问题。
6. 多任务联邦学习(Federated Multi-task Learning)
多任务联邦学习考虑到不同设备或用户可能执行不同的任务,因此在每个设备上训练针对特定任务的模型,并在全局层面进行多任务学习。
工作原理:
- 每个设备执行一个特定的任务(如分类、回归等)。
- 通过共享一些模型参数或特征,进行多任务学习,从而提高任务之间的共享学习效果。
- 服务器聚合不同设备的多任务模型。
优缺点:
- 优点:能够支持设备执行不同任务,并且通过共享学习提高模型的泛化能力。
- 缺点:多任务学习的参数共享可能会导致任务之间的干扰,尤其是在任务相关性较低时。
7. 联邦生成对抗网络(Federated GANs)
生成对抗网络(GANs)通过生成器和判别器的对抗训练生成数据,而联邦生成对抗网络(Federated GANs)则将这一概念应用到联邦学习中。
工作原理:
- 在联邦学习中,生成器和判别器的训练过程是在各个设备上本地完成的。
- 各个设备的生成器生成假数据,而判别器判断这些假数据是否真实。
- 更新后的生成器和判别器模型被上传到服务器,进行全局模型的更新。
优缺点:
- 优点:适用于需要生成高质量数据的场景,如隐私保护的数据生成。
- 缺点:训练过程可能较为复杂,且需要较强的计算能力。
8. 联邦迁移学习(Federated Transfer Learning, FTL)
联邦迁移学习结合了迁移学习和联邦学习的优势。它的目标是通过共享学习到的知识,在不同的设备之间迁移已有的知识。
工作原理:
- 每个设备在自己的本地数据上进行训练,并生成一个局部模型。
- 设备之间通过共享一些公共的特征或权重来提高模型的泛化能力。
- 迁移学习能够帮助在目标任务上进行加速训练,特别是在数据不充足的情况下。
优缺点:
- 优点:适用于数据稀缺的任务,能够有效地迁移知识。
- 缺点:需要良好的特征共享机制,否则可能导致迁移失败或负迁移。