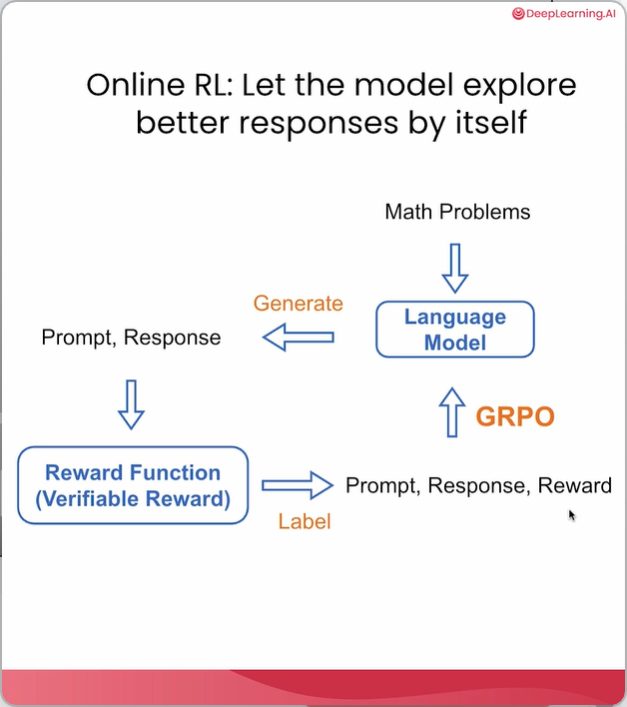
大模型后训练——Online-RL实践
大型语言模型在能够执行指令和回答问题之前,需要经历预训练(Pre-training)和后训练(Post-training)两个核心阶段。
- 预训练阶段,模型通过学习从海量未标注的文本中预测下一个词或token来掌握基础知识。而在后训练阶段,模型则着重学习实际应用中的关键能力,包括准确理解并执行指令、熟练运用工具,以及进行复杂的逻辑推理。
- 后训练是将在海量无标签文本上训练的原始的通用语言模型转变为能够理解并执行特定指令的智能助手的过程。无论是想打造一个更安全的 AI 助手、调整模型的语言风格,还是提升特定任务的精确度,后训练都不可或缺。
后训练是大语言模型训练中发展最迅速的研究方向之一。
而在本课程中,就可以学习到三种常见的后训练方法——监督微调(SFT)、直接偏好优化(DPO)和在线强化学习(Online RL)——以及如何有效使用它们。
学习地址:Online-RL实践。
import torch
from transformers import TrainingArguments, AutoTokenizer, AutoModelForCausalLM
from trl import GRPOTrainer, GRPOConfig
from datasets import load_dataset, Dataset
from helper import generate_responses, test_model_with_questions, load_model_and_tokenizer
import re
import pandas as pd
from tqdm import tqdm这段代码是 Python 语言,主要用于自然语言处理任务,通常与基于 Transformer 架构的模型,具体解释如下:
import torch:导入 PyTorch 库,这是一个广泛用于深度学习的框架,在自然语言处理中用于张量计算、构建神经网络模型等。from transformers import TrainingArguments, AutoTokenizer, AutoModelForCausalLM:从 Hugging Face 的transformers库中导入几个关键类。TrainingArguments用于配置模型训练的参数,如训练轮数、学习率等;AutoTokenizer用于自动选择并加载适合特定预训练模型的分词器,将文本转换为模型可处理的输入格式;AutoModelForCausalLM用于自动加载适合因果语言模型(如 GPT 系列类似的自回归语言模型)的预训练模型。from trl import GRPOTrainer, GRPOConfig:从trl(可能是一个与 Transformer 相关的特定库,可能用于强化学习与语言模型结合等场景)库中导入GRPOTrainer和GRPOConfig,GRPOTrainer可能是用于基于某种特定优化算法(如近端策略优化相关)的训练器,GRPOConfig用于配置该训练器的参数。from datasets import load_dataset, Dataset:从datasets库中导入load_dataset和Dataset。load_dataset用于加载各种公开数据集,Dataset类可能用于表示和操作数据集。from helper import generate_responses, test_model_with_questions, load_model_and_tokenizer:从自定义的helper模块中导入generate_responses(用于生成模型对输入的回应)、test_model_with_questions(用于使用问题测试模型性能)和load_model_and_tokenizer(用于加载模型和分词器)函数。import re:导入 Python 的re库,用于正则表达式操作,在自然语言处理中常用来处理文本匹配、清洗等任务。import pandas as pd:导入pandas库,以pd作为别名,常用于数据处理和分析,例如处理数据集、读取和写入表格数据等。from tqdm import tqdm:从tqdm库中导入tqdm,tqdm用于创建进度条,在循环处理数据时可直观展示处理进度。
USE_GPU = TrueSYSTEM_PROMPT = ("You are a helpful assistant that solves problems step-by-step. ""Always include the final numeric answer inside \\boxed{}."
)这里设置启用GPU,并且设置了系统提示词。
def reward_func(completions, ground_truth, **kwargs):# Regular expression to capture content inside \boxed{}matches = [re.search(r"\\boxed\{(.*?)\}", completion[0]['content']) for completion in completions]contents = [match.group(1) if match else "" for match in matches]# Reward 1 if the content is the same as the ground truth, 0 otherwisereturn [1.0 if c == gt else 0.0 for c, gt in zip(contents, ground_truth)]这是一个名为reward_func的 Python 函数,其功能是根据完成内容与真实值的匹配情况给予奖励分数。具体解释如下:
- 函数定义及参数:
def reward_func(completions, ground_truth, **kwargs),该函数接受三个参数,completions可能是一系列完成的内容,ground_truth是真实值,**kwargs用于接收可能的其他关键字参数。 - 正则表达式匹配:
matches = [re.search(r"\\boxed\{(.*?)\}", completion[0]['content']) for completion in completions],使用正则表达式在completions每个元素的content字段中查找\boxed{}内的内容,re.search函数用于在字符串中搜索匹配的模式,r"\\boxed\{(.*?)\}"这个正则表达式中,\\boxed匹配\boxed字符串,\{(.*?)\}用于捕获花括号内的任意内容,(.*?)是非贪婪模式的捕获组。这里使用列表推导式对completions中的每个元素进行匹配操作。 - 提取内容:
contents = [match.group(1) if match else "" for match in matches],对于上一步得到的匹配结果matches,如果匹配成功(match不为None),则提取捕获组中的内容(即\boxed{}内的内容),否则返回空字符串,同样使用列表推导式生成一个包含提取内容的列表contents。 - 给予奖励分数:
return [1.0 if c == gt else 0.0 for c, gt in zip(contents, ground_truth)],将提取的内容contents与真实值ground_truth进行逐个比较,如果提取内容与真实值相同,则给予奖励分数 1.0,否则给予 0.0,最终以列表形式返回这些奖励分数。
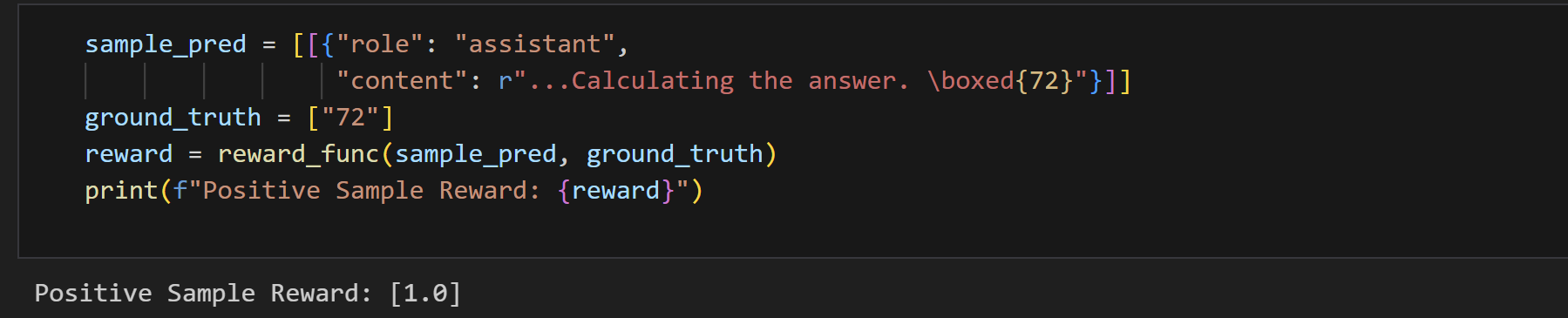
sample_pred = [[{"role": "assistant", "content": r"...Calculating the answer. \boxed{72}"}]]
ground_truth = ["72"]
reward = reward_func(sample_pred, ground_truth)
print(f"Positive Sample Reward: {reward}")这段代码主要进行预测结果与真实值的比较并计算奖励值。具体解释如下:
sample_pred = [[{"role": "assistant", "content": r"...Calculating the answer. \boxed{72}"}]]:定义了一个名为sample_pred的变量,它是一个嵌套列表,最内层是一个字典,字典中有两个键值对,"role" 对应的值为 "assistant" ,"content" 对应的值为一个字符串,该字符串里包含文本及一个表示数学框的内容。ground_truth = ["72"]:定义了一个名为ground_truth的列表,其中包含一个元素 "72" ,代表真实值。reward = reward_func(sample_pred, ground_truth):调用名为reward_func的函数,将sample_pred和ground_truth作为参数传入,函数返回的结果赋值给reward变量,这个函数可能用于计算预测值与真实值匹配程度的奖励分数。print(f"Positive Sample Reward: {reward}"):使用格式化字符串输出,打印出 “Positive Sample Reward:” 加上reward的值,即展示这个正样本的奖励分数。
结果如下图所示:
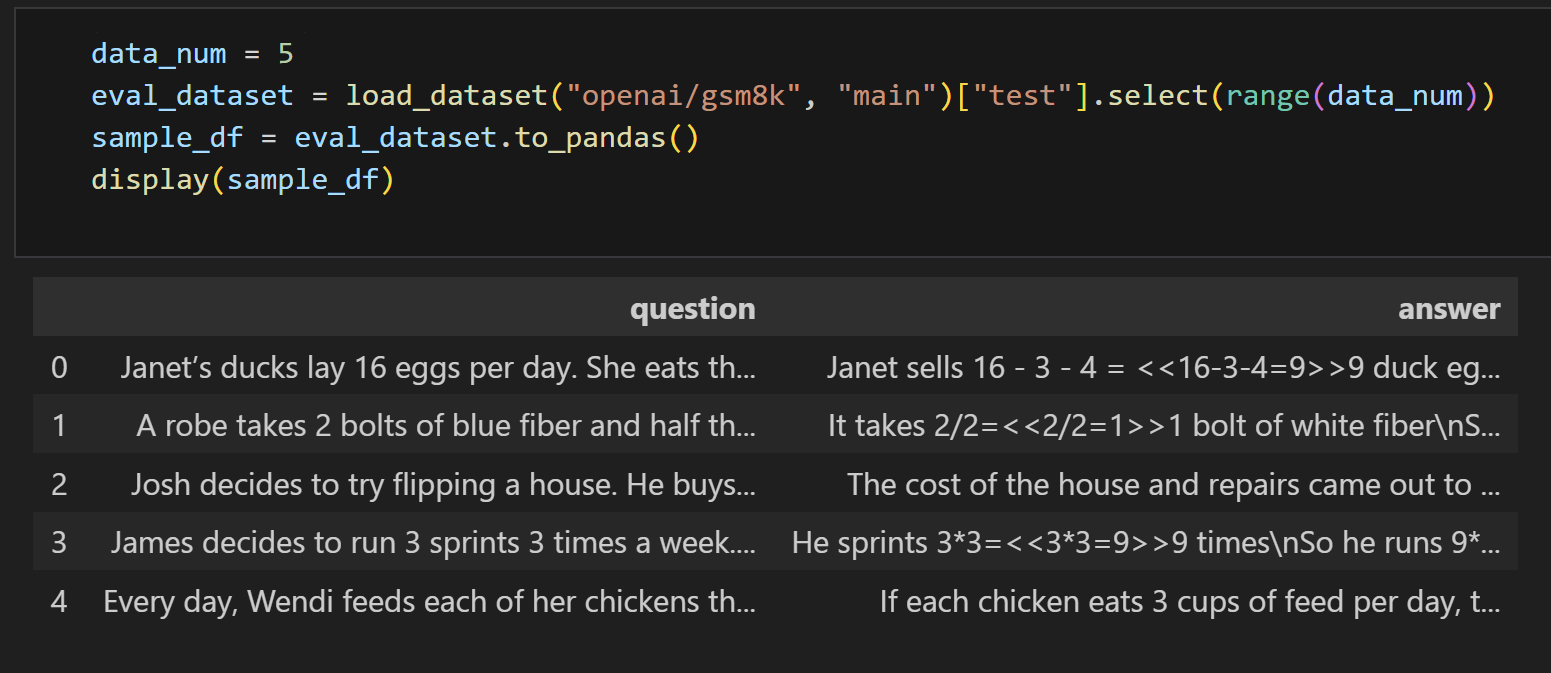
data_num = 5
eval_dataset = load_dataset("openai/gsm8k", "main")["test"].select(range(data_num))
sample_df = eval_dataset.to_pandas()
display(sample_df)这段代码实现了以下功能:
- 定义变量
data_num并赋值为5,这代表后续操作的数据数量。 - 使用
load_dataset函数从openai/gsm8k数据集中加载test子集,然后通过select方法选取前5条数据,将结果赋值给eval_dataset。这里openai/gsm8k是一个公开数据集,用于某些自然语言处理任务。 - 将
eval_dataset转换为pandas中的DataFrame格式,赋值给sample_df。pandas是一个用于数据处理和分析的库,DataFrame是其常用的数据结构。 - 使用
display函数展示sample_df的内容,在支持该函数的环境(如 Jupyter Notebook)中会以表格形式呈现数据。
def post_processing(example):match = re.search(r"####\s*(-?\d+)", example["answer"])example["ground_truth"] = match.group(1) if match else Noneexample["prompt"] = [{"role": "system", "content": SYSTEM_PROMPT},{"role": "user", "content": example["question"]}]return example
eval_dataset = eval_dataset.map(post_processing).remove_columns(["question", "answer"])这是一段 Python 代码,用于对评估数据集进行后处理。具体解释如下:
def post_processing(example):定义了一个名为post_processing的函数,该函数接受一个参数example。match = re.search(r"####\s*(-?\d+)", example["answer"]):使用正则表达式re.search在example字典的answer键对应的值中查找模式。该模式####\s*(-?\d+)表示匹配以####开头,后面跟着零个或多个空白字符,再跟着一个带符号或不带符号的整数。re.search函数返回第一个匹配的对象,如果没有找到则返回None。example["ground_truth"] = match.group(1) if match else None:如果找到了匹配项(match不为None),则将匹配到的整数部分(通过match.group(1)获取)赋值给example字典的ground_truth键;如果没有找到匹配项,则将None赋值给example["ground_truth"]。example["prompt"] = [{"role": "system", "content": SYSTEM_PROMPT}, {"role": "user", "content": example["question"]}]:为example字典创建一个新的键prompt,其值是一个包含两个字典的列表。第一个字典表示系统角色,其内容为SYSTEM_PROMPT(这里SYSTEM_PROMPT应该是在代码其他地方定义的一个变量);第二个字典表示用户角色,其内容为example字典中question键对应的值。return example:返回经过处理后的example字典。eval_dataset = eval_dataset.map(post_processing).remove_columns(["question", "answer"]):对eval_dataset数据集应用post_processing函数,即对数据集中的每个元素执行上述后处理操作。然后,从处理后的数据集移除question和answer列。最终得到的新数据集eval_dataset只包含经过后处理添加的ground_truth和prompt等列,而不再包含原始的question和answer列。
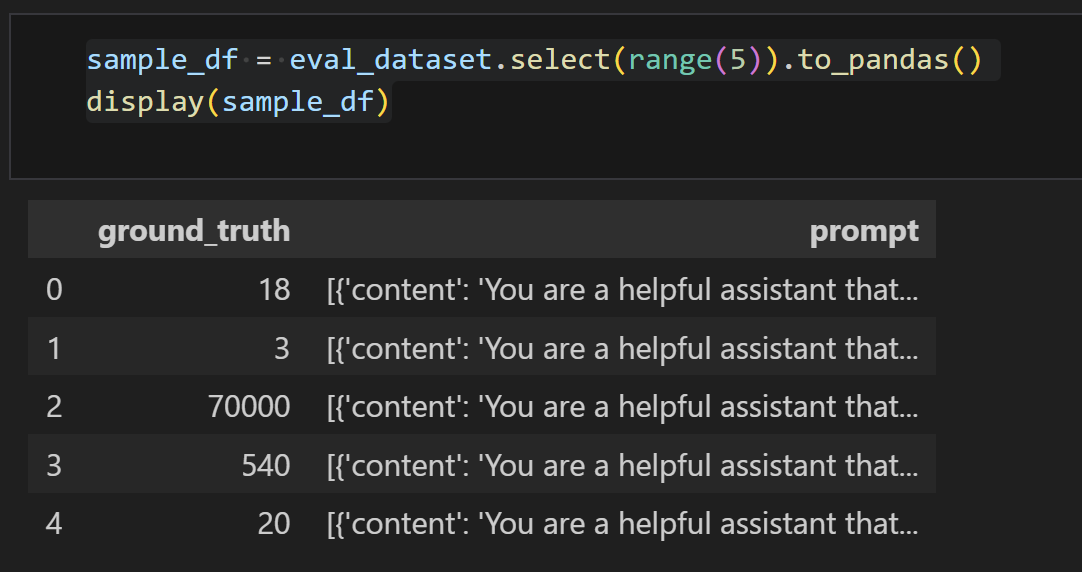
sample_df = eval_dataset.select(range(5)).to_pandas()
display(sample_df)这段代码的含义如下:
eval_dataset.select(range(5)):从名为eval_dataset的数据集中选取前 5 个元素。这里range(5)生成一个包含 0 到 4 的整数序列,select方法依据这个序列选取相应元素。.to_pandas():将选取的数据集转换为pandas库中的DataFrame格式,方便后续使用pandas提供的各种数据处理和分析功能。display(sample_df):展示名为sample_df的DataFrame数据,通常在 Jupyter Notebook 等环境中使用,能以友好的表格形式呈现数据。
model, tokenizer = load_model_and_tokenizer("./Qwen2.5-0.5B-Instruct", USE_GPU)
# Store predictions and ground truths
all_preds = []
all_labels = []for example in tqdm(eval_dataset):input_prompt = example["prompt"]ground_truth = example["ground_truth"]# Run the model to generate an answerwith torch.no_grad():response = generate_responses(model, tokenizer, full_message = input_prompt) all_preds.append([{"role": "assistant", "content": response}])all_labels.append(ground_truth)print(response)print("Ground truth: ", ground_truth)# 3. Evaluate using reward_func
rewards = reward_func(all_preds, all_labels)# 4. Report accuracy
accuracy = sum(rewards) / len(rewards)
print(f"Evaluation Accuracy: {accuracy:.2%}")
del model, tokenizer这段代码的主要功能是对模型预测结果进行存储、评估,并计算准确率。具体解释如下:
- 初始化列表:
all_preds = []:创建一个空列表,用于存储模型的所有预测结果。all_labels = []:创建一个空列表,用于存储所有的真实标签(即正确答案)。
- 遍历评估数据集:
for example in tqdm(eval_dataset)::使用tqdm对评估数据集eval_dataset中的每个样本进行遍历,tqdm通常用于显示进度条。input_prompt = example["prompt"]:从当前样本中提取输入提示信息。ground_truth = example["ground_truth"]:从当前样本中提取真实标签。with torch.no_grad()::这是一个上下文管理器,在其内部的代码执行时,不会计算梯度,通常用于推理阶段以节省内存和计算资源。response = generate_responses(model, tokenizer, full_message = input_prompt):调用generate_responses函数,传入模型model、分词器tokenizer以及输入提示input_prompt,生成模型的回答response。all_preds.append([{"role": "assistant", "content": response}]):将模型的预测结果以特定格式(包含角色和内容的字典形式)添加到all_preds列表中。all_labels.append(ground_truth):将当前样本的真实标签添加到all_labels列表中。print(response):打印模型生成的回答。print("Ground truth: ", ground_truth):打印真实标签。
- 评估:
rewards = reward_func(all_preds, all_labels):调用reward_func函数,传入存储所有预测结果的all_preds和所有真实标签的all_labels,该函数返回每个预测结果对应的奖励分数(用于评估预测与真实标签的匹配程度)。
- 计算并报告准确率:
accuracy = sum(rewards) / len(rewards):计算平均奖励分数,即准确率,通过将所有奖励分数相加后除以奖励分数的总数得到。print(f"Evaluation Accuracy: {accuracy:.2%}"):以百分比形式打印评估准确率,保留两位小数。
- 释放资源:
del model, tokenizer:删除模型model和分词器tokenizer,以释放内存资源。
dataset = load_dataset("openai/gsm8k", "main")
train_dataset = dataset["train"]# Apply to dataset
train_dataset = train_dataset.map(post_processing)
train_dataset = train_dataset.remove_columns(["question", "answer"])
print(train_dataset[0])这是一段 Python 代码,用于加载和处理数据集。具体含义如下:
dataset = load_dataset("openai/gsm8k", "main"):使用load_dataset函数加载名为 “openai/gsm8k” 的数据集,指定加载的配置为 “main”,并将加载后的数据集赋值给变量dataset。train_dataset = dataset["train"]:从已加载的dataset中提取名为 “train” 的子集,这通常是训练数据集,并将其赋值给train_dataset。train_dataset = train_dataset.map(post_processing):对train_dataset中的每一个样本应用post_processing函数,作用是对数据进行后处理操作,处理后的结果重新赋值给train_dataset。train_dataset = train_dataset.remove_columns(["question", "answer"]):从train_dataset中移除名为 “question” 和 “answer” 的列,移除后的数据集重新赋值给train_dataset。print(train_dataset[0]):打印train_dataset中的第一个样本,展示经过上述处理后的数据形式。
处理后的数据形式如下:

train_dataset = train_dataset.select(range(100))config = GRPOConfig(per_device_train_batch_size=1,gradient_accumulation_steps=8,num_generations=4, num_train_epochs=1,learning_rate=5e-6,logging_steps=5,
)第一句 “train_dataset = train_dataset.select (range (100))”,意思是从名为 “train_dataset” 的数据集中选取索引在 0 到 99(共 100 个)的数据项,然后重新赋值给 “train_dataset”,即对原数据集进行了筛选。(这里由于本地资源有限,如果资源足够可去掉这一行)
接下来是对 “GRPOConfig” 类进行实例化并配置参数:
- “per_device_train_batch_size=1” 表示在每个设备上进行训练时,每个批次的样本数量为 1。例如在使用 GPU 训练时,每次送入 GPU 进行计算的样本数量是 1 个。
- “gradient_accumulation_steps=8” 指梯度累积步数为 8。在训练过程中,不是每次前向传播后都立即更新模型参数,而是将多次(这里是 8 次)前向传播产生的梯度累积起来,然后再进行一次参数更新。
- “num_generations=4” 表示遗传算法中的代数为 4,即在模拟遗传进化过程中,要进行 4 代的迭代。
- “num_train_epochs=1” 说明整个训练数据集要被完整遍历训练的次数为 1 次。
- “learning_rate=5e-6” 表明学习率为 5 乘以 10 的负 6 次方,学习率控制着每次参数更新的步长,这个值较小意味着模型参数更新的幅度较小。
- “logging_steps=5” 意味着每训练 5 步就记录一次日志信息,方便监控训练过程中的各项指标变化。
model, tokenizer = load_model_and_tokenizer("./Qwen2.5-0.5B-Instruct", USE_GPU)grpo_trainer = GRPOTrainer(model=model,args=config,reward_funcs=reward_func,train_dataset=train_dataset
)grpo_trainer.train()这段代码实现了加载模型和分词器,并使用特定训练器对模型进行训练的功能。具体解释如下:
model, tokenizer = load_model_and_tokenizer("./Qwen2.5 - 0.5B - Instruct", USE_GPU):调用load_model_and_tokenizer函数,从路径"./Qwen2.5 - 0.5B - Instruct"加载模型和分词器,USE_GPU一个用于指定是否使用 GPU 的参数,函数返回加载后的模型model和分词器tokenizer。grpo_trainer = GRPOTrainer(:创建一个GRPOTrainer类的实例grpo_trainer。model=model:将前面加载的模型传入训练器。args=config:将配置参数config传入训练器,config中可能包含如训练轮数、学习率等训练相关的设置。reward_funcs=reward_func:将奖励函数reward_func传入训练器,在强化学习等训练场景中,奖励函数用于衡量模型输出的好坏,引导模型学习。train_dataset=train_dataset:将训练数据集train_dataset传入训练器,用于模型的训练。
grpo_trainer.train():调用训练器grpo_trainer的train方法,启动模型训练过程,按照GRPOTrainer类中定义的训练逻辑对模型进行训练。
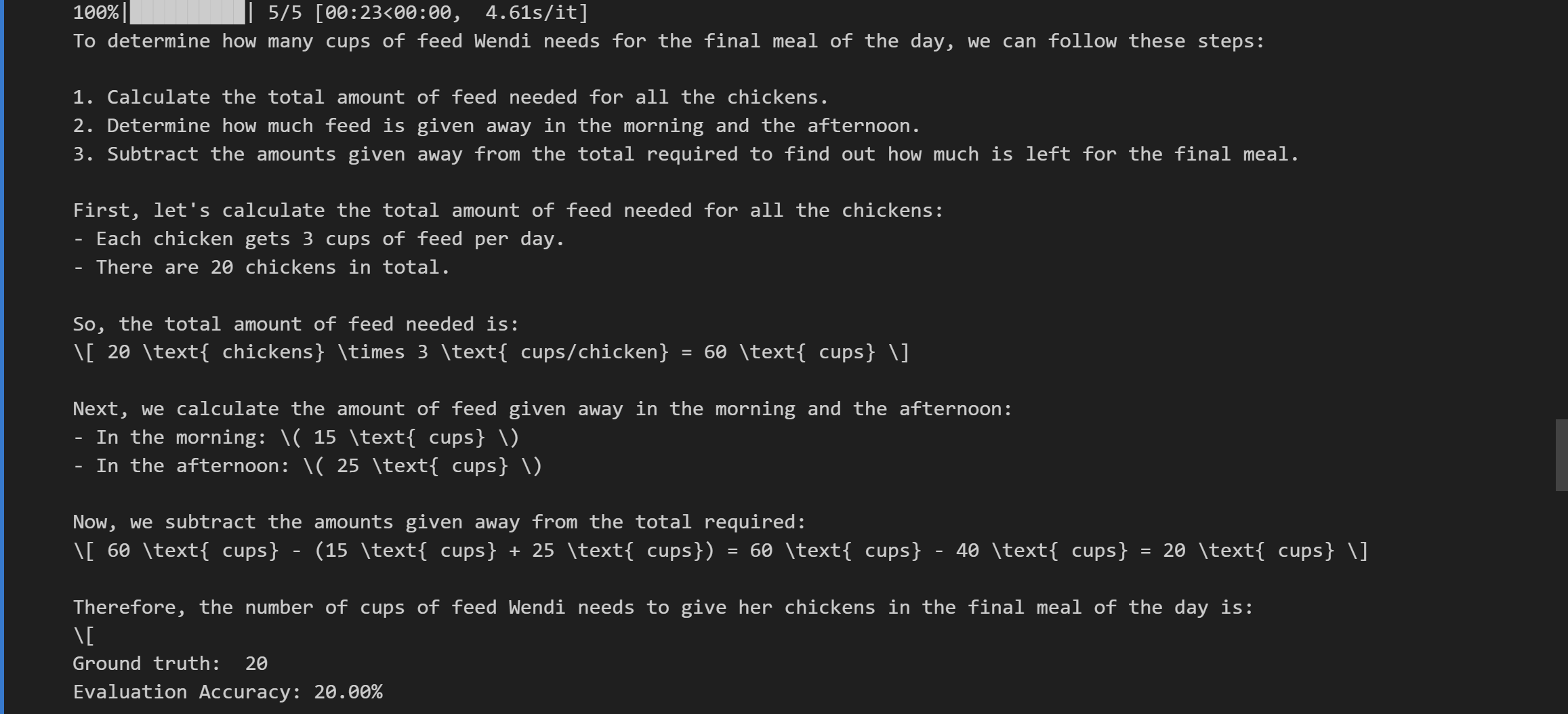
model = grpo_trainer.model# Store predictions and ground truths
all_preds = []
all_labels = []for example in tqdm(eval_dataset):input_prompt = example["prompt"]ground_truth = example["ground_truth"]# Run the model to generate an answerwith torch.no_grad():response = generate_responses(model, tokenizer, full_message = input_prompt) all_preds.append([{"role": "assistant", "content": response}])all_labels.append(ground_truth)print(response)print("Ground truth: ", ground_truth)# 3. Evaluate using reward_func
rewards = reward_func(all_preds, all_labels)# 4. Report accuracy
accuracy = sum(rewards) / len(rewards)
print(f"Evaluation Accuracy: {accuracy:.2%}")这段代码实现了对模型预测结果的评估过程,具体解释如下:
model = grpo_trainer.model:将grpo_trainer中的模型赋值给变量model,后续将使用这个模型进行预测。all_preds = []和all_labels = []:创建两个空列表,分别用于存储模型的所有预测结果和对应的真实标签。for example in tqdm(eval_dataset)::使用for循环遍历评估数据集eval_dataset,tqdm用于在循环过程中显示进度条。input_prompt = example["prompt"]和ground_truth = example["ground_truth"]:从数据集中取出每个样本的输入提示prompt和真实标签ground_truth。with torch.no_grad()::在这个代码块内,模型的计算过程不会记录梯度,以减少内存使用和加快计算速度。response = generate_responses(model, tokenizer, full_message = input_prompt):使用model和tokenizer根据输入提示input_prompt生成模型的响应response。all_preds.append([{"role": "assistant", "content": response}]):将生成的响应以特定格式添加到预测结果列表all_preds中。all_labels.append(ground_truth):将真实标签添加到真实标签列表all_labels中。print(response)和print("Ground truth: ", ground_truth):打印模型的预测响应和对应的真实标签。rewards = reward_func(all_preds, all_labels):使用reward_func函数,根据所有预测结果和真实标签计算奖励值。accuracy = sum(rewards) / len(rewards):计算奖励值的平均值作为准确率。print(f"Evaluation Accuracy: {accuracy:.2%}"):以百分比形式打印评估准确率,保留两位小数。