swift多卡并行训练微调qwen3-8B
基础环境:docker-ubuntu, nvidia-ciotainer-toolkit
脚本:
DDP :
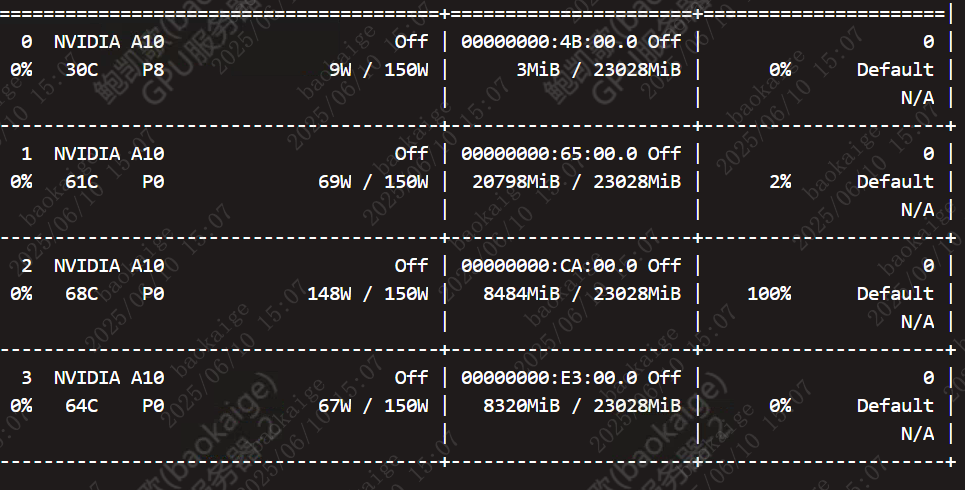
存在负载不均衡的情况。
视同device_map同样存在这个情况。
时间:
 很长,如果换成单卡,爆显存。
很长,如果换成单卡,爆显存。
多卡的话,卡之间的分配不太均匀。
可以考虑使用deepspeed尝试能不能使卡间均匀。。ZeRO2将对优化器状态、模型梯度进行分片。ZeRO3在ZeRO2基础上,对模型参数进行分片,更加节约显存,但训练速度更慢。参考这里。
可以在加个:
PYTORCH_CUDA_ALLOC_CONF='expandable_segments:True' \
PPO训练脚本:
PYTORCH_CUDA_ALLOC_CONF='expandable_segments:True' \
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 \
NPROC_PER_NODE=$nproc_per_node \
swift rlhf \--rlhf_type ppo \--model LLM-Research/Meta-Llama-3.1-8B-Instruct \--reward_model 'AI-ModelScope/Skywork-Reward-Llama-3.1-8B-v0.2' \--train_type full \--dataset 'AI-ModelScope/alpaca-gpt4-data-zh#20000' 'AI-ModelScope/alpaca-gpt4-data-en#20000' \--torch_dtype bfloat16 \--num_train_epochs 1 \--per_device_train_batch_size 1 \--per_device_eval_batch_size 1 \--learning_rate 1e-6 \--gradient_accumulation_steps $(expr 16 / $nproc_per_node) \--eval_steps 100 \--save_steps 100 \--save_total_limit 2 \--logging_steps 5 \--max_length 2048 \--output_dir output \--warmup_ratio 0.05 \--dataloader_num_workers 4 \--deepspeed zero3 \--response_length 512 \--temperature 0.7 \--dataset_num_proc 4 \--save_only_model true