VGG16训练和测试Fashion和CIFAR10
CIFAR10 epoch=50
Test Accuracy: 91.77%
VGG网络结构
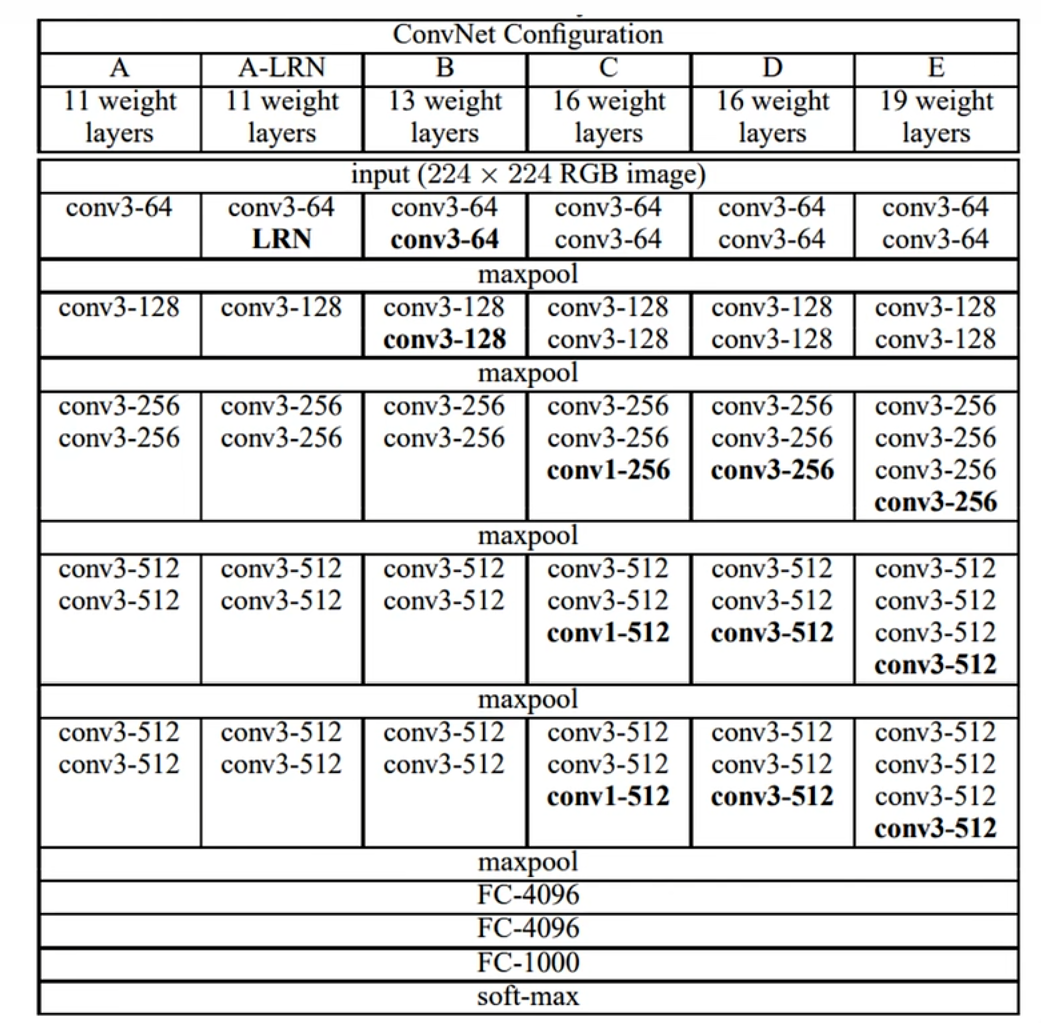
VGG16(D)网络结构 5个block+5个Maxpool+3个FC+soft-max
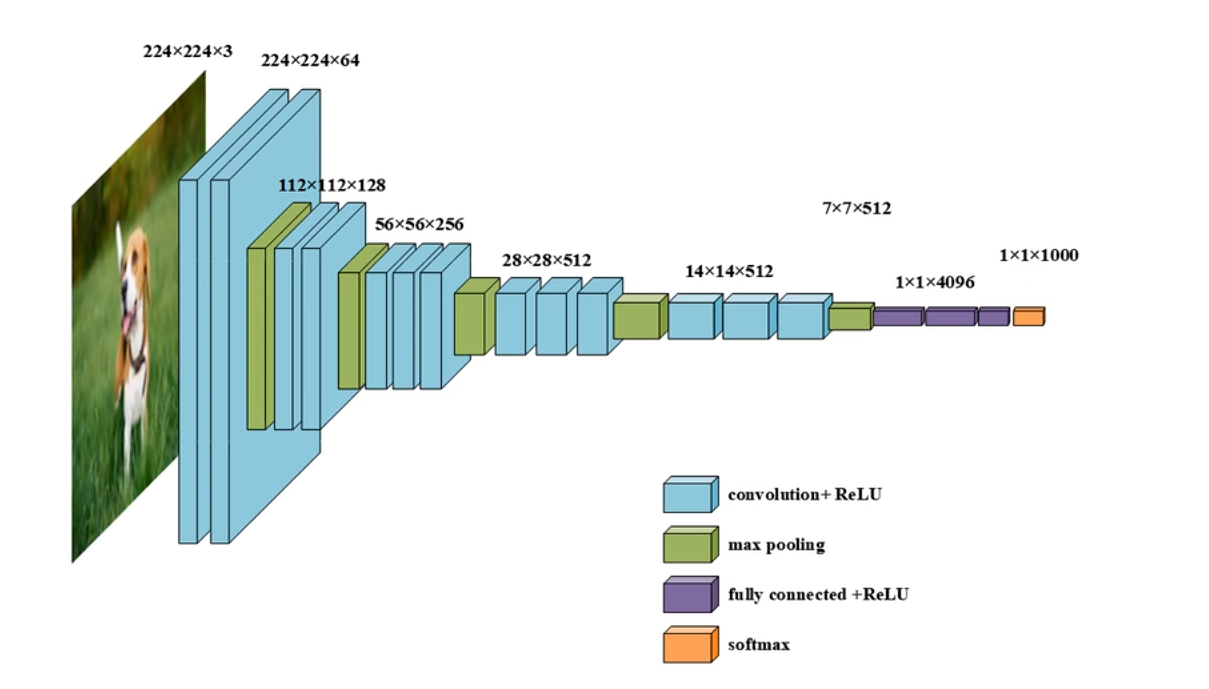
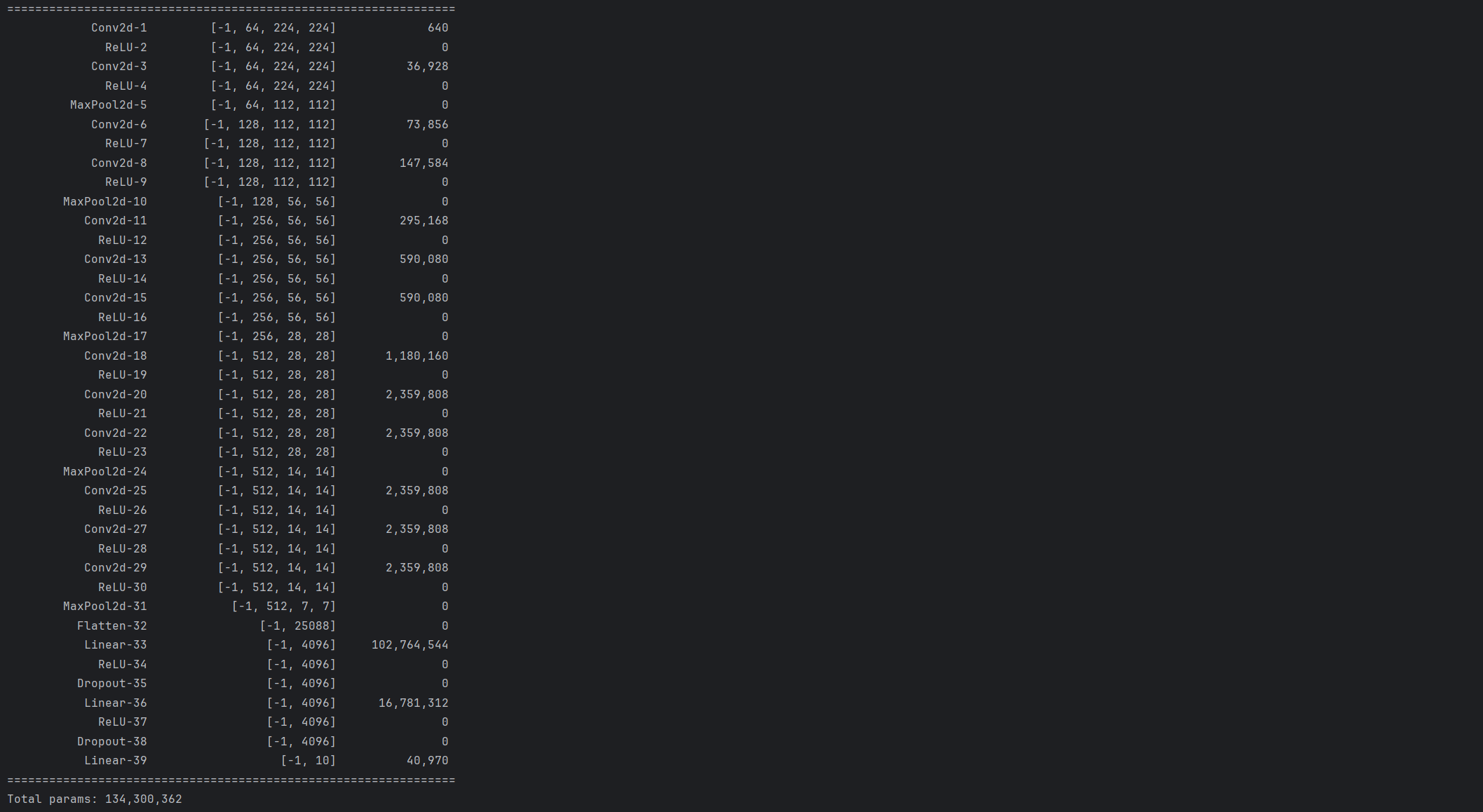
VGG网络参数(标准 ImageNet 版 VGG16)
第一个VGG Block层(两个卷积层,两个ReLu,一个池化)
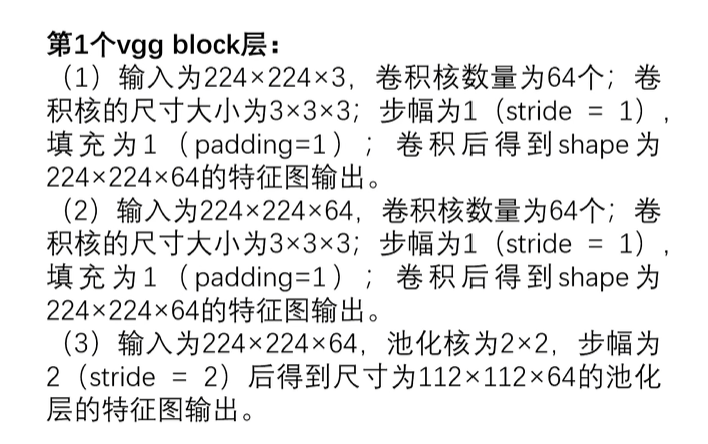
self.block1 = nn.Sequential(nn.Conv2d(in_channels=1, out_channels=64, kernel_size=3, stride=1, padding=1),nn.ReLU(inplace=True),nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2)
)第二个VGG Block层(两个卷积层,两个ReLu,一个池化)

self.block2 = nn.Sequential(nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1),nn.ReLU(inplace=True),nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2))第三个VGG Block层(三个卷积层,三个ReLu,一个池化)

self.block3 = nn.Sequential(nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=1),nn.ReLU(inplace=True),nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1),nn.ReLU(inplace=True),nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2))第四个VGG Block层(三个卷积层,三个ReLu,一个池化)

self.block4 = nn.Sequential(nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, stride=1, padding=1),nn.ReLU(inplace=True),nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),nn.ReLU(inplace=True),nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2))第五个VGG Block层(三个卷积层,三个ReLu,一个池化)
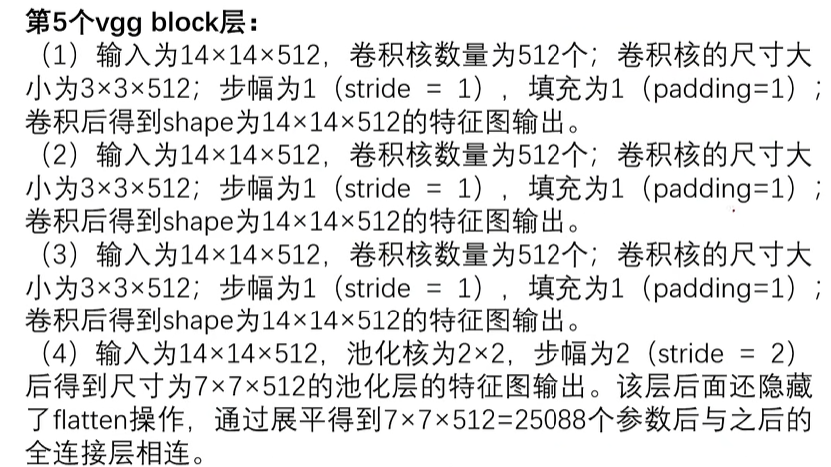
self.block5 = nn.Sequential(nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),nn.ReLU(inplace=True),nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),nn.ReLU(inplace=True),nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2))线性分类器层(flatten,linear,Relu,Dropout)

self.classifier = nn.Sequential(nn.Flatten(),nn.Linear(in_features=7*7*512, out_features=4096),nn.ReLU(inplace=True),nn.Dropout(),nn.Linear(in_features=4096, out_features=4096),nn.ReLU(inplace=True),nn.Dropout(),nn.Linear(in_features=4096, out_features=10),)前向传播代码
def forward(self, x):x = self.block1(x)x = self.block2(x)x = self.block3(x)x = self.block4(x)x = self.block5(x)x = self.classifier(x)return xkaiming初始化权重函数
# ===== Kaiming 初始化函数 =====
def init_weights(m):if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')if m.bias is not None:nn.init.constant_(m.bias, 0)elif isinstance(m, nn.Linear):nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')nn.init.constant_(m.bias, 0)主函数代码
if __name__ == '__main__':device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")model = VGG16().to(device)print(summary(model, (1, 224, 224)))完整代码
import torch
import torch.nn as nn
from torchsummary import summaryclass VGG16(nn.Module):def __init__(self):super().__init__()self.block1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=3, stride=1, padding=1),nn.ReLU(inplace=True),nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(2, 2))self.block2 = nn.Sequential(nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1),nn.ReLU(inplace=True),nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(2, 2))self.block3 = nn.Sequential(nn.Conv2d(128, 256, kernel_size=3, stride=1, padding=1),nn.ReLU(inplace=True),nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1),nn.ReLU(inplace=True),nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(2, 2))self.block4 = nn.Sequential(nn.Conv2d(256, 512, kernel_size=3, stride=1, padding=1),nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(2, 2))self.block5 = nn.Sequential(nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(2, 2))self.classifier = nn.Sequential(nn.Flatten(),nn.Linear(7*7*512, 4096),nn.ReLU(inplace=True),nn.Dropout(),nn.Linear(4096, 4096),nn.ReLU(inplace=True),nn.Dropout(),nn.Linear(4096, 10),)def forward(self, x):x = self.block1(x)x = self.block2(x)x = self.block3(x)x = self.block4(x)x = self.block5(x)x = self.classifier(x)return x# ===== Kaiming 初始化函数 =====
def init_weights(m):if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')if m.bias is not None:nn.init.constant_(m.bias, 0)elif isinstance(m, nn.Linear):nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')nn.init.constant_(m.bias, 0)if __name__ == '__main__':device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")model = VGG16().to(device)# 应用 Kaiming 初始化model.apply(init_weights)# 打印模型结构summary(model, (1, 224, 224))
运行结果:Total params: 134,300,362
VGG网络参数(适用于CIFAR10的 VGG16)
前面的网络参数太大,一般适用于ImageNet数据集,而CIFAR10数据集只有32*32*3,因此可以重新设计模型参数,并且可以加入BatchNorm,提高收敛速度和稳定性。