ForCenNet:文档图矫正迎来新SOTA(2025)
文档图像校正,就是要把一张拍“歪”了的文档图片,通过算法恢复成一张像扫描仪扫出来一样平整的图片。这项技术是文档智能分析流程中的关键预处理步骤。
然而,许多现有方法在预测整个图像的变形场时,对所有像素“一视同仁”,没有充分利用文档图像的结构先验。实际上,文本行和表格边框这些前景元素,它们在理想状态下本应是直线。这些元素的弯曲程度和方向,直接揭示了文档的几何畸变信息。忽略这些关键线索,就像在没有参照物的情况下凭空想象如何把一张纸铺平,效果自然受限。
一. 论文和代码
论文:https://arxiv.org/pdf/2507.19804v1
代码:https://arxiv.org/pdf/2507.19804v1
二. 原理简介
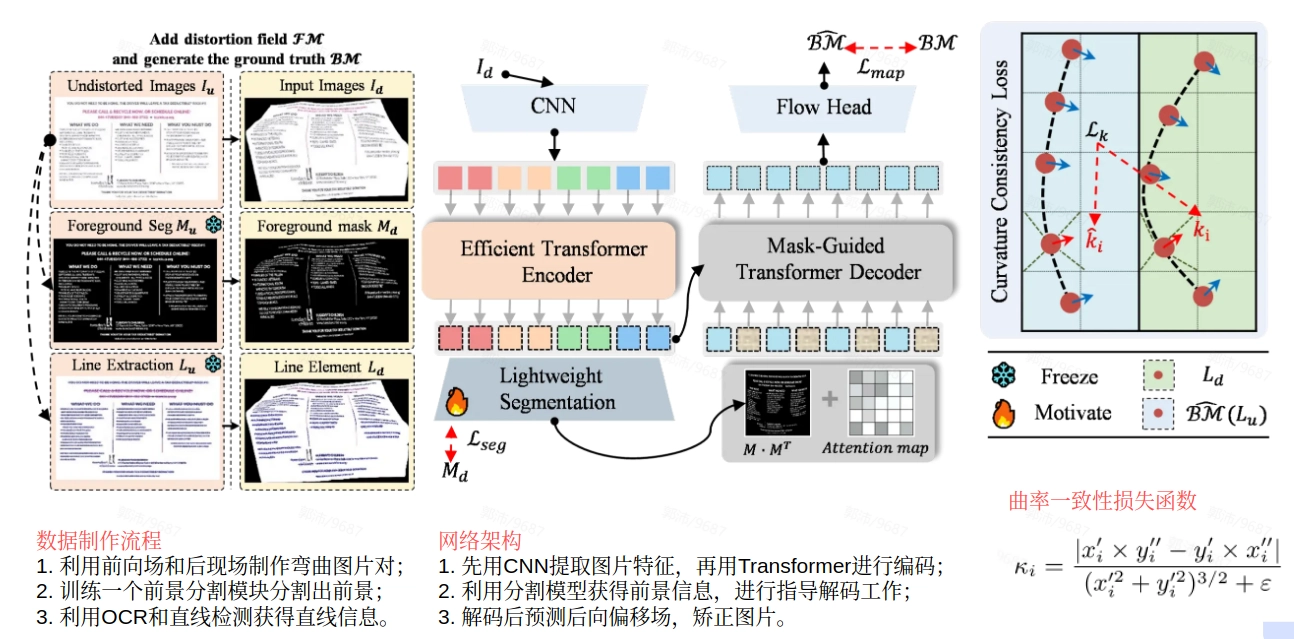
1. 以前景为中心的标签生成(Foreground-Centric Label Generation)
为了让模型学会关注前景,首先需要为它提供精确的“学习资料”。研究者提出了一种方法,从平整、无畸变的原始文档图像中,自动提取出详细的前景元素(包括文本行、表格线等)作为监督标签。这样,模型在训练时就能明确知道需要重点关注哪些区域。
2. 以前景为中心的掩码机制(Foreground-Centric Mask Mechanism)
在模型内部,研究者引入了一个前景掩码(Foreground Mask)。这个掩码的作用类似于给模型戴上了一副“特殊眼镜”,让它能够清晰地区分出包含文字和线条的可读区域与空白的背景区域。通过这种方式,模型可以将更多的计算资源和注意力集中在对校正起决定性作用的前景上。
3. 曲率一致性损失(Curvature Consistency Loss)
这是ForCenNet最巧妙的设计之一。对于弯曲的文本行或表格线,其“弯曲的程度”(即曲率)蕴含了丰富的几何畸变信息。研究者设计了一种新的损失函数,它直接对前景线条的曲率进行监督。该损失函数要求模型预测的变形场,在作用于弯曲的前景线后,能使其曲率尽可能变为零(即恢复成直线)。这相当于给了模型一个非常直观的几何约束,帮助它更精准地理解和还原复杂的空间扭曲。
三. 实验细节
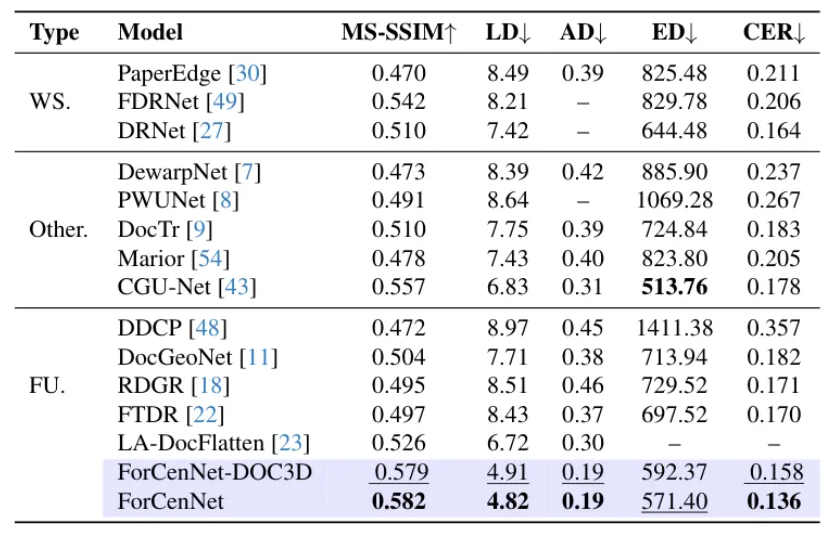
ForCenNet在四个主流的真实世界文档校正基准数据集(DocUNet, DIR300, WarpDoc, DocReal)上进行了广泛的实验,并与现有SOTA方法进行了对比。
如下表所示,无论是在DocUNet还是DIR300数据集上,ForCenNet在所有关键指标(如MS-SSIM, LD)上都取得了当前最佳(SOTA)成绩,显著超越了之前的方法。
四. 总结
- 提出了一个新颖的视角:强调了在文档图像校正中,应将前景元素作为核心驱动力。
- 设计了ForCenNet:一个完整、高效的以前景为中心的网络,其包含的标签生成、掩码机制和曲率一致性损失等模块均被证明行之有效。
- 树立了新的性能标杆:在四个真实世界基准测试中取得了全面的SOTA性能,为后续研究提供了强有力的基线。
- 开源社区贡献:作者开源了代码和相关资源,便于社区复现和在此基础上进行新的探索。
五. 博主点评
ForCenNet的成功,不仅为文档图像校正技术的发展提供了新的思路,也再次证明了在复杂的视觉任务中,深入挖掘和利用场景的内在结构先验是通往更高性能的关键。
在开源的矫正算法中表现亮眼,实际效果待测。
博主一直专注文档矫正,欢迎技术交流!WeChat:guopeiAI