基于pytorch深度学习笔记:2.VGGNet介绍
本节再来学习一个网络结构--VGGNet。
VGGNet是牛津大学计算机视觉组(Visual Geometry Group)和谷歌DeepMind一起研究出来的深度卷积神经 网络,因而冠名为VGG。VGG是一种被广泛使用的卷积 神经网络结构,其在在2014年的ImageNet大规模视觉识 别挑战(ILSVRC-2014)中获得了亚军,不是VGG不够强, 而是对手太强,因为当年获得冠军的是GoogLeNet(我们也会在后面学到)。 通常人们说的VGG是指VGG-16(13层卷积层+3层全连接层)。虽然其屈居亚军,但是由于其规律的设计、简洁可堆叠的卷积块,且在其他数据集上都有着很好的表现, 从而被人们广泛使用,从这点上还是超过了GoogLeNet。 VGG和之前的AlexNet相比,深度更深,参数更多(1.38亿), 效果和可移植性更好。
1.VGGNet的网络架构

经典卷积神经网络的基本组成部分是下面的这个序列:
(1)带填充以保持分辨率的卷积层;
(2)非线性激活函数,如ReLU;
(3)池化层,最大池化层。
而一个VGG块与之类似,由一系列卷积层组成,后面再 加上用于空间下采样的最大池化层。 而一个VGG块与之类似,由一系列卷积层组成,后面再加 上用于空间下采样的最大池化层。
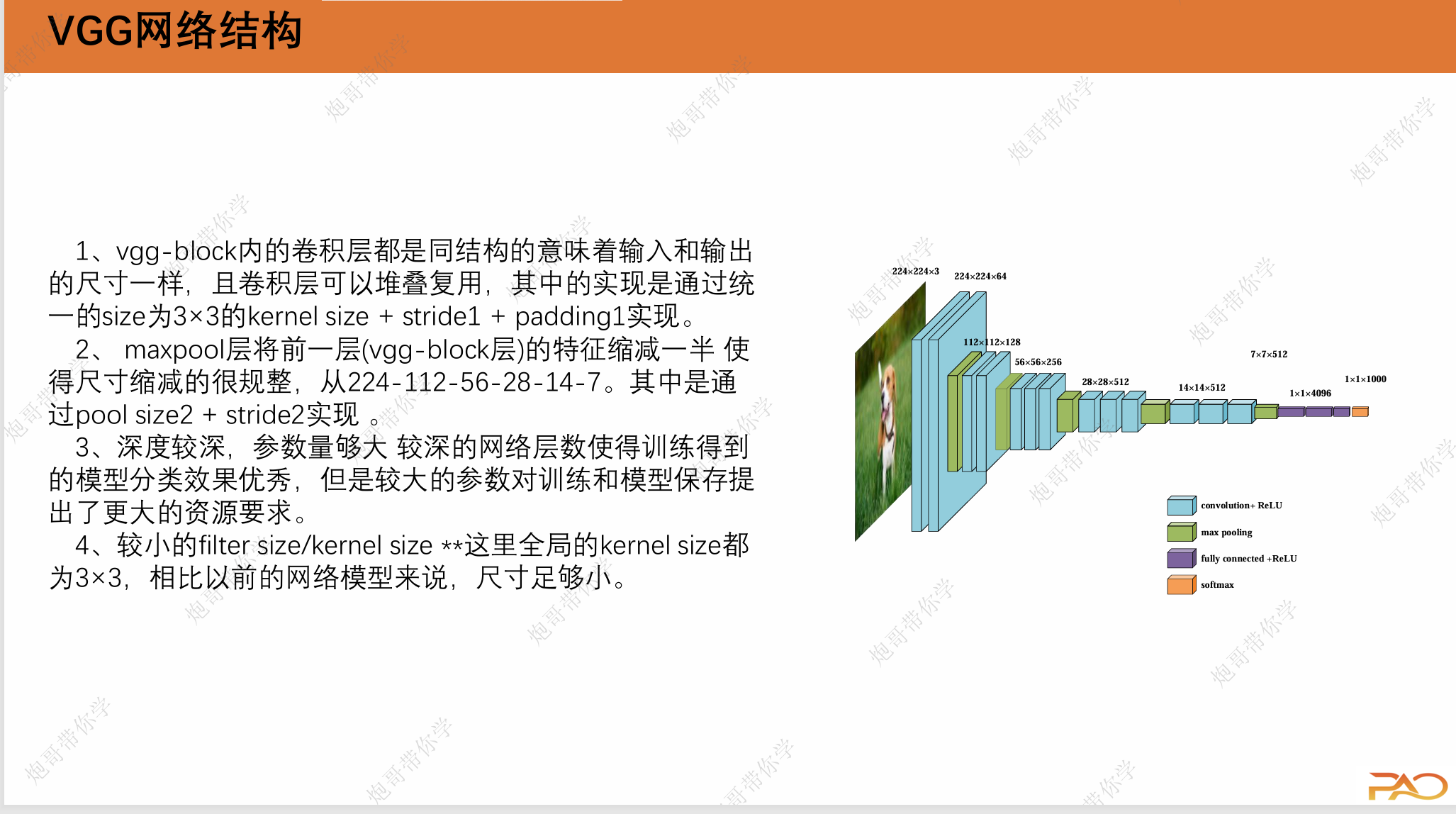
VGG特点: vgg-block内的卷积层都是同结构的,池化层都得上一层的卷积层特征缩减一半。深度较深,参数量够大,较小的filter size/kernel size
如上图所示,VGG是有不少变种的,我们这里主要讲的是VGG-16(D列对应的网络架构)
2.VGGNet的网络参数
VGG网络有一个显著的改进是将网络“打包”,一块一块的进行架构,这赋予了它简洁和可移植性强的特点。
第1个vggblock层:
(1)输入为224×224×3,卷积核数量为64个;卷 积核的尺寸大小为3×3×3;步幅为1(stride=1), 填充为1(padding=1);卷积后得到shape为 224×224×64的特征图输出。
(2)输入为224×224×64,卷积核数量为64个;卷积核的尺寸大小为3×3×64;步幅为1(stride=1), 填充为1(padding=1);卷积后得到shape为 224×224×64的特征图输出。
(3)输入为224×224×64,池化核为2×2,步幅为 2(stride=2)后得到尺寸为112×112×64的池化 层的特征图输出。
第2个vggblock层:
(1)输入为112×112×64,卷积核数量为128个; 卷积核的尺寸大小为3×3×64;步幅为1(stride= 1),填充为1(padding=1);卷积后得到shape 为112×112×128的特征图输出。
(2)输入为112×112×128,卷积核数量为128个; 卷积核的尺寸大小为3×3×128;步幅为1(stride= 1),填充为1(padding=1);卷积后得到shape 为112×112×128的特征图输出。
(3)输入为112×112×128,池化核为2×2,步幅为2(stride=2)后得到尺寸为56×56×128的池化 层的特征图输出。
第3个vggblock层:
(1)输入为56×56×128,卷积核数量为256个;卷积核 的尺寸大小为3×3×128;步幅为1(stride=1),填充 为1(padding=1);卷积后得到shape为56×56×256的 特征图输出。
(2)输入为56×56×256,卷积核数量为256个;卷积核 的尺寸大小为3×3×256;步幅为1(stride=1),填充 为1(padding=1);卷积后得到shape为56×56×256的 特征图输出。
(3)输入为56×56×256,卷积核数量为256个;卷积核 的尺寸大小为3×3×256;步幅为1(stride=1),填充 为1(padding=1);卷积后得到shape为56×56×256的 特征图输出。
(4)输入为56×56×256,池化核为2×2,步幅为2 (stride=2)后得到尺寸为28×28×256的池化层的特征图输出。
第4个vggblock层:
(1)输入为28×28×256,卷积核数量为512个;卷积核 的尺寸大小为3×3×256;步幅为1(stride=1),填充为 1(padding=1);卷积后得到shape为28×28×512的特 征图输出。
(2)输入为28×28×512,卷积核数量为512个;卷积核 的尺寸大小为3×3×512;步幅为1(stride=1),填充为 1(padding=1);卷积后得到shape为28×28×512的特 征图输出。
(3)输入为28×28×512,卷积核数量为512个;卷积核 的尺寸大小为3×3×512;步幅为1(stride=1),填充为 1(padding=1);卷积后得到shape为28×28×512的特 征图输出。
(4)输入为28×28×512,池化核为2×2,步幅为2 (stride=2)后得到尺寸为14×14×512的池化层的特征图输出。
第5个vggblock层:
(1)输入为14×14×512,卷积核数量为512个;卷积核的尺寸大 小为3×3×512;步幅为1(stride=1),填充为1(padding=1); 卷积后得到shape为14×14×512的特征图输出。
(2)输入为14×14×512,卷积核数量为512个;卷积核的尺寸大 小为3×3×512;步幅为1(stride=1),填充为1(padding=1); 卷积后得到shape为14×14×512的特征图输出。
(3)输入为14×14×512,卷积核数量为512个;卷积核的尺寸大 小为3×3×512;步幅为1(stride=1),填充为1(padding=1); 卷积后得到shape为14×14×512的特征图输出。
(4)输入为14×14×512,池化核为2×2,步幅为2(stride=2) 后得到尺寸为7×7×512的池化层的特征图输出。该层后面还隐藏 了flatten操作,通过展平得到7×7×512=25088个参数后与之后的 全连接层相连。 第1~3层全连接层:第1~3层神经元个数分别为4096,4096, 1000。其中前两层在使用relu后还使用了Dropout对神经元随机失活,最后一层全连接层用softmax输出1000个分类
3.VGGNet的基于pytorch代码实现
import torch
from torch import nn
from torchsummary import summaryclass VGG16(nn.Module):def __init__(self):super(VGG16, self).__init__()self.block1 = nn.Sequential(nn.Conv2d(in_channels=1, out_channels=64, kernel_size=3, padding=1),nn.ReLU(),nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, padding=1),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2))self.block2 = nn.Sequential(nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, padding=1),nn.ReLU(),nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, padding=1),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2))self.block3 = nn.Sequential(nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, padding=1),nn.ReLU(),nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, padding=1),nn.ReLU(),nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, padding=1),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2))self.block4 = nn.Sequential(nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, padding=1),nn.ReLU(),nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, padding=1),nn.ReLU(),nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, padding=1),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2))self.block5 = nn.Sequential(nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, padding=1),nn.ReLU(),nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, padding=1),nn.ReLU(),nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, padding=1),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2))self.block6 = nn.Sequential(nn.Flatten(),nn.Linear(7*7*512, 256),nn.ReLU(),nn.Linear(256, 128),nn.ReLU(),nn.Linear(128, 10),)for m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, nonlinearity='relu')if m.bias is not None:nn.init.constant_(m.bias, 0)elif isinstance(m, nn.Linear):nn.init.normal_(m.weight, 0, 0.01)if m.bias is not None:nn.init.constant_(m.bias, 0)def forward(self, x):x = self.block1(x)x = self.block2(x)x = self.block3(x)x = self.block4(x)x = self.block5(x)x = self.block6(x)return xif __name__=="__main__":device = torch.device("cuda" if torch.cuda.is_available() else "cpu")model = VGG16().to(device)print(summary(model, (1, 224, 224)))4.VGGNet总结
VGGNet通过在传统卷积神经网络模型(AlexNet)上的拓展, 发现除了较为复杂的模型结构的设计(如GoogLeNet)外,深度对于提高模型准确率很重要,VGG和之前的AlexNet相比,深度更深,参数更多(1.38亿),效果和可移植性更好,且模型设计的简 洁而规律,从而被广泛使用。 还有一些特点总结如下:
1、小尺寸的filter(3×3)不仅使参数更少,效果也并不弱于大尺寸 filter如5×5
2、块的使用导致网络定义的非常简洁。使用块可以有效地设计 复杂的网络。
3、AlexNet中的局部响应归一化作用不大。