推荐标注数据标注
数据标注
一、病害类型角度(精准分类)
如果要区分具体病害,先判断病斑特征:
- 若病斑是柑橘溃疡病(病斑通常呈火山口状开裂,初期黄色晕圈 ),标签可设为
citrus_canker。 - 若像是柑橘炭疽病(病斑多为圆形、褐色至黑色 ),标签设为
citrus_melanose。
二、简易分类角度(快速区分)
要是先做简单的 “病害 / 健康” 二分类,标签设为 diseased_citrus(代表带病柑橘 ),后续再细化也可。
三、结合项目需求
若你的柑橘检测模型目标是识别病害类别,选病害精准标签;若只是初步筛选带病果实,用 diseased_citrus 这类通用标签。你可根据实际要检测的病害类型,在 MaixHub 右上角 “添加标签” 处,输入对应标签名(比如确认是溃疡病就填 citrus_canker ),方便后续模型训练识别 。
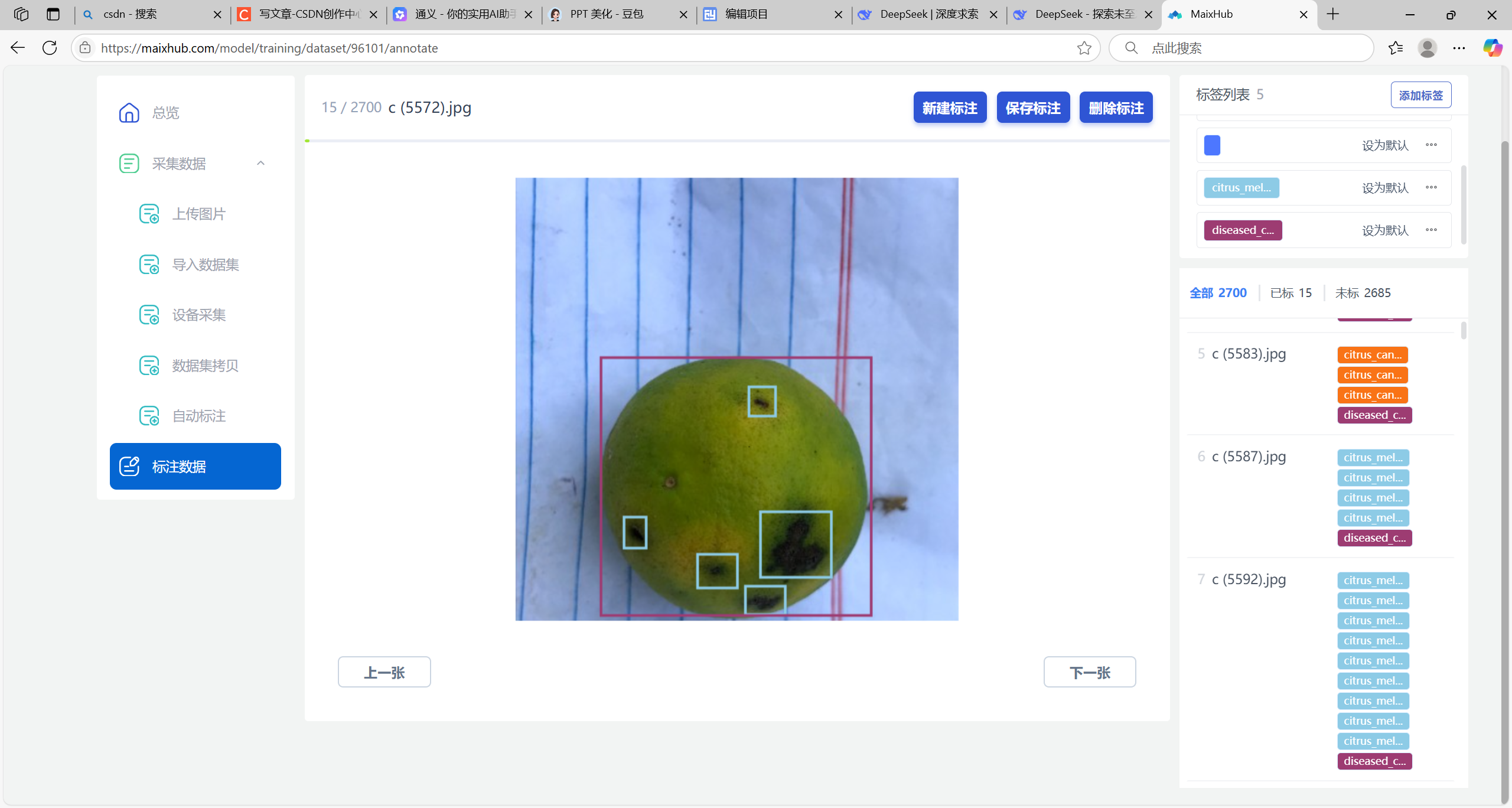
一、当前标注的 “合格项”
- 目标覆盖:
框基本包围了柑橘病斑,能让模型识别病斑位置,这是检测任务的基础。 - 标签关联:
右侧标签列表能看到关联了citrus_mel(假设是炭疽病)、diseased_c等标签,类别逻辑清晰。
二、需要优化的点(让标注更 “合格”)
1. 框的精准度
- 问题:部分框过大 / 过小(比如有些框包含太多空白,有些框没完全覆盖病斑 )。
- 优化:框尽量紧贴病斑边缘,别包含多余背景,也别漏掉病斑区域。
2. 标签一致性
- 问题:同一类病斑(比如炭疽病),标签用了
citrus_mel、diseased_c等多个,容易让模型混淆。 - 优化:统一标签名(比如全用
citrus_melanose表示炭疽病 ),一个类别只对应一个标签。
3. 类别完整性
- 问题:如果要区分 “健康柑橘” 和 “病害柑橘”,需补充健康柑橘的标注(当前只标了病害 )。
- 优化:找健康柑橘图,标
healthy_citrus标签,让模型学习对比。
三、“合格标注” 的参考标准
- 框的质量:
- 每个框完整包围目标(病斑 / 果实 ),不超出、不遗漏。
- 标签质量:
- 标签命名清晰、无歧义,同一类别标签唯一。
- 数据覆盖:
- 病害、健康、不同病害类型(如果区分 )都有标注,样本均衡。
四、优化后的标注流程建议
- 重新整理标签:
删去重复 / 歧义标签,保留citrus_canker(溃疡病 )、citrus_melanose(炭疽病 )、healthy_citrus(健康 ) 。 - 重新调整框:
每张图里的病斑,用最紧凑的框包围,保证 “框住且不多余”。 - 补充健康样本:
找健康柑橘图,标healthy_citrus,让模型能区分 “病 / 健”。
按这些优化后,标注会更规范,模型训练效果也会更好。简单说,当前标注有基础,但在框的精准度、标签一致性上还能优化,调整后就更 “合格” 啦~
我标注多少张可以开始训练模型了
一般来说,至少标注 100 - 200 张 可尝试启动训练,但效果是否理想,还和标注质量、场景复杂度有关。以下分场景给你参考:
一、基础版:“能跑通训练” 的最低要求
如果只是想 验证流程、看看模型能不能跑:
- 简单场景(比如只区分 “健康 / 炭疽病”,背景单一 ):
标注 100 张左右 即可启动训练(其中健康、病害样本尽量各占一半 )。 - 作用:能验证数据格式、训练代码是否正确,但模型泛化能力弱(遇到新图容易错 )。
二、进阶版:“有实用价值” 的标注量
如果想让模型 在实际场景能用(比如果园里检测病害 ):
- 复杂场景(病斑多样、背景有树叶 / 枝干干扰 ):
至少标注 300 - 500 张,且要覆盖:- 不同病害类型(溃疡病、炭疽病都要有 );
- 不同光照(晴天、阴天、傍晚 );
- 不同病斑数量(1 个病斑、多个病斑的柑橘 )。
- 作用:模型能学习到多样特征,实际检测时更稳定。
三、专业版:“工业级效果” 的标注量
如果要做 落地项目 / 竞赛,追求高精度:
- 标注量建议 1000 张以上,且需严格分层:
- 病害类型分层:每种病害(溃疡、炭疽等 )至少 300 张;
- 样本难度分层:包含模糊、小目标、多病害重叠的图;
- 数据增强补充:标注后用工具(如 YOLO 自带增强 )扩充到 3000 + 样本。
- 作用:模型能应对各种极端情况,达到商用级别精度。
四、关键提醒:“标注质量> 数量”
- 别盲目堆数量!如果 100 张图标注很粗糙(框不准、标签乱 ),训练出来的模型比 50 张高质量标注的还差。
- 建议先标 50 张高质量图 跑个小训练,看看模型是否能 “学会”(比如看验证集准确率 ),再决定是否继续加数据。
总结:
- 想试试水 → 100 张起步;
- 想做实用模型 → 300 - 500 张 + 高质量标注;
- 想冲高精度 → 1000 张 + 分层细化 + 数据增强。