DAY 31 文件的规范拆分和写法
@浙大疏锦行![]() https://blog.csdn.net/weixin_45655710
https://blog.csdn.net/weixin_45655710
作业:尝试针对之前的心脏病项目ipynb,将他按照今天的示例项目整理成规范的形式,思考下哪些部分可以未来复用。
各模块作用
-
config/(配置文件夹)config.py: 这个文件通常用来存放项目的全局配置信息。比如文件路径、模型参数、特征列表等不应硬编码在主代码中的变量。这样做的好处是,当需要修改参数时,只需修改这一个文件,而不用去翻阅所有代码。
-
data/(数据文件夹)- 这是存放所有与项目相关的数据的地方。
raw/: 存放原始数据 (data.csv)。这里的数据是未经任何处理的,保持其最原始的状态,这对于保证项目的可复现性至关重要。processed/: 存放经过预处理、清洗、特征工程后的数据。这些数据是准备好可以直接用于模型训练的。
-
logs/(日志文件夹)data_processing.log: 存放程序运行过程中产生的日志信息。例如,数据处理脚本运行时,可以记录每一步的开始、结束、遇到的警告或错误。这对于调试程序和监控长时间运行的任务非常有用。
-
models/(模型文件夹)- 存放训练好的机器学习模型。模型训练完成后,会被保存成文件(如
.pkl格式),以便将来可以直接加载进行预测,而无需重新训练。 lgb_model.pkl: 保存的LightGBM模型。xgb_model.pkl: 保存的XGBoost模型。
- 存放训练好的机器学习模型。模型训练完成后,会被保存成文件(如
-
notebooks/(笔记本文件夹)eda.ipynb: 存放Jupyter Notebook文件。这类文件非常适合进行探索性数据分析 (Exploratory Data Analysis, EDA)、数据可视化和快速原型设计。eda通常是分析的第一步,用来理解数据特性。
-
src/(源代码文件夹)- 这是项目的核心代码区,包含了所有实现项目功能的Python脚本。
__init__.py: 一个空文件,它的存在告诉Python,src这个目录是一个可以被导入的包 (package)。data_processing.py: 包含所有数据预处理和特征工程的函数。train.py: 包含训练模型的代码。它会加载处理好的数据,并使用特定算法来训练模型。evaluate.py: 包含评估模型性能的函数,例如计算准确率、F1分数、绘制ROC曲线等。visualize.py: 包含所有数据可视化的函数,比如绘制特征分布图、混淆矩阵等。main.py: 项目的主入口文件。它会像一个总指挥,按照顺序调用其他模块的函数,串联起整个流程:加载数据 -> 处理数据 -> 训练模型 -> 评估模型 -> 保存结果。
-
tests/(测试文件夹)test_data_processing.py: 存放单元测试或集成测试的代码。例如,可以编写测试来验证data_processing.py中的函数是否能正确处理特定情况的缺失值,或者输出的数据形状是否符合预期。这能保证代码的质量和可靠性。
-
requirements.txt(项目依赖文件)- 这是一个文本文件,记录了运行这个项目所需要的所有第三方Python库及其版本号(例如
pandas==1.5.3,scikit-learn==1.2.2)。其他人拿到这个项目后,只需在终端运行pip install -r requirements.txt就能快速安装好所有依赖,搭建起一模一样的运行环境。
- 这是一个文本文件,记录了运行这个项目所需要的所有第三方Python库及其版本号(例如
processing.py模块
import pandas as pd
from typing import Tuple, Optional # 【修改】从 typing 模块导入 Optionaldef load_data(file_path: str) -> Optional[pd.DataFrame]:# ▲▲▲ 【修改】将返回类型提示从 pd.DataFrame 改为 Optional[pd.DataFrame] ▲▲▲"""加载心脏病数据文件Args:file_path (str): 数据文件路径Returns:Optional[pd.DataFrame]: 加载的数据框,如果文件未找到则返回 None"""try:return pd.read_csv(file_path)except FileNotFoundError:print(f"❌ 错误: 文件未找到于 '{file_path}'")return Nonedef preprocess_features(data: pd.DataFrame) -> pd.DataFrame:"""对心脏病数据集的特征进行预处理对于心脏病数据集,其特征大部分是数值类型,但其中一些实际上代表类别。最适合的处理方式是对这些类别特征进行独热编码。Args:data (pd.DataFrame): 原始数据框Returns:pd.DataFrame: 经过独热编码处理后的数据框"""if data is None:return Nonedata_processed = data.copy()categorical_features = ['sex', 'cp', 'fbs', 'restecg', 'exang', 'slope', 'ca', 'thal']features_to_encode = [col for col in categorical_features if col in data_processed.columns]if features_to_encode:print(f"✅ 正在对以下类别特征进行独热编码: {features_to_encode}")# ▼▼▼【核心修正】▼▼▼# 移除多余且导致错误的 prefix 参数。# get_dummies 默认就会使用原始列名作为前缀。data_processed = pd.get_dummies(data_processed, columns=features_to_encode)# ▲▲▲【核心修正】▲▲▲else:print("ℹ️ 未发现需要进行独热编码的指定类别特征。")rename_map = {'output': 'target', 'condition': 'target'}for old_name, new_name in rename_map.items():if old_name in data_processed.columns:data_processed.rename(columns={old_name: new_name}, inplace=True)print(f"✅ 已将目标列 '{old_name}' 重命名为 '{new_name}'。")return data_processeddef handle_missing_values(data: pd.DataFrame) -> pd.DataFrame:"""处理缺失值,使用中位数进行填充Args:data (pd.DataFrame): 可能包含缺失值的数据框Returns:pd.DataFrame: 处理缺失值后的数据框"""if data is None:return Nonedata_clean = data.copy()if data_clean.isnull().sum().sum() > 0:print("\nℹ️ 发现缺失值,正在使用中位数填充...")for col in data_clean.columns:if data_clean[col].isnull().any() and pd.api.types.is_numeric_dtype(data_clean[col]):median_value = data_clean[col].median()data_clean[col].fillna(median_value, inplace=True)print(f" - 列 '{col}' 的缺失值已填充。")else:print("✅ 数据集中没有缺失值。")return data_cleanif __name__ == "__main__":file_path = 'heart.csv'print(f"--- 步骤 1: 加载数据 ---")raw_data = load_data(file_path)if raw_data is not None:print(f"原始数据形状: {raw_data.shape}")print(f"\n--- 步骤 2: 处理缺失值 ---")clean_data = handle_missing_values(raw_data)print(f"\n--- 步骤 3: 特征预处理 ---")processed_data = preprocess_features(clean_data)print("\n✅ 数据预处理流程完成!")print(f"最终处理后的数据形状: {processed_data.shape}")print("最终数据预览:")print(processed_data.head())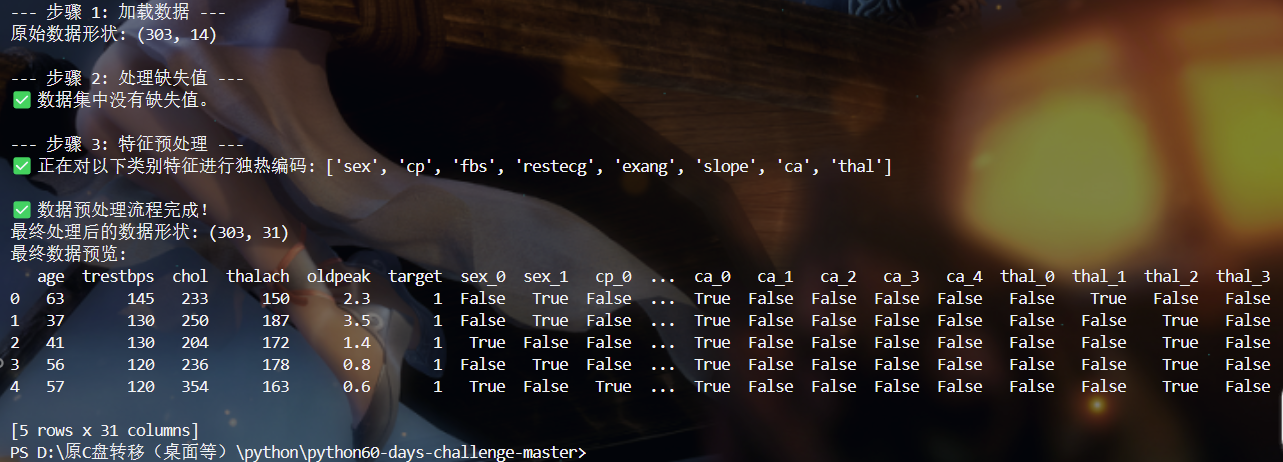
train.py模块
# -*- coding: utf-8 -*-import sys
import os
# sys.path.append(...) # 这部分保持您原来的设置import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, confusion_matrix
import time
import joblib
from typing import Tuple, Dict, Optional# --- 数据预处理函数 (保持不变) ---
def load_data(file_path: str) -> Optional[pd.DataFrame]:try:return pd.read_csv(file_path)except FileNotFoundError:print(f"❌ 错误: 文件未找到于 '{file_path}'")return Nonedef preprocess_features(data: Optional[pd.DataFrame]) -> Optional[pd.DataFrame]:if data is None:return Nonedata_processed = data.copy()categorical_features = ['sex', 'cp', 'fbs', 'restecg', 'exang', 'slope', 'ca', 'thal']features_to_encode = [col for col in categorical_features if col in data_processed.columns]if features_to_encode:data_processed = pd.get_dummies(data_processed, columns=features_to_encode)rename_map = {'output': 'target', 'condition': 'target'}for old_name, new_name in rename_map.items():if old_name in data_processed.columns:data_processed.rename(columns={old_name: new_name}, inplace=True)return data_processeddef handle_missing_values(data: Optional[pd.DataFrame]) -> Optional[pd.DataFrame]:if data is None:return Nonedata_clean = data.copy()if data_clean.isnull().sum().sum() > 0:for col in data_clean.columns:if data_clean[col].isnull().any() and pd.api.types.is_numeric_dtype(data_clean[col]):median_value = data_clean[col].median()data_clean[col].fillna(median_value, inplace=True)return data_clean# --- train.py 模块的核心代码 ---
def prepare_data(file_path: str) -> Optional[Tuple]:"""准备训练数据"""data = load_data(file_path)data_processed = preprocess_features(data)data_clean = handle_missing_values(data_processed)# ▼▼▼【核心修正】▼▼▼# 在使用 data_clean 之前,必须先检查它是否为 Noneif data_clean is None:print("❌ 错误: 数据预处理失败,无法继续。")return None# ▲▲▲【核心修正】▲▲▲if 'target' not in data_clean.columns:print("❌ 错误: 处理后的数据中未找到 'target' 列。")return NoneX = data_clean.drop(['target'], axis=1)y = data_clean['target']# 确保 y 中类别数量大于1才能进行分层抽样stratify_param = y if y.nunique() > 1 else NoneX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=stratify_param)return X_train, X_test, y_train, y_testdef train_model(X_train, y_train, model_params: Optional[Dict] = None) -> RandomForestClassifier:"""训练随机森林模型"""if model_params is None:model_params = {'random_state': 42}model = RandomForestClassifier(**model_params)model.fit(X_train, y_train)return modeldef evaluate_model(model, X_test, y_test) -> None:"""评估模型性能"""y_pred = model.predict(X_test)print("\n分类报告:")print(classification_report(y_test, y_pred))print("\n混淆矩阵:")print(confusion_matrix(y_test, y_pred))def save_model(model, model_path: str) -> None:"""保存模型"""os.makedirs(os.path.dirname(model_path), exist_ok=True)joblib.dump(model, model_path)print(f"\n模型已保存至: {model_path}")if __name__ == "__main__":prepared_data = prepare_data("heart.csv") # 确保 heart.csv 在同一目录if prepared_data:X_train, X_test, y_train, y_test = prepared_datastart_time = time.time()model = train_model(X_train, y_train)end_time = time.time()print(f"\n训练耗时: {end_time - start_time:.4f} 秒")evaluate_model(model, X_test, y_test)save_model(model, "models/random_forest_model.joblib")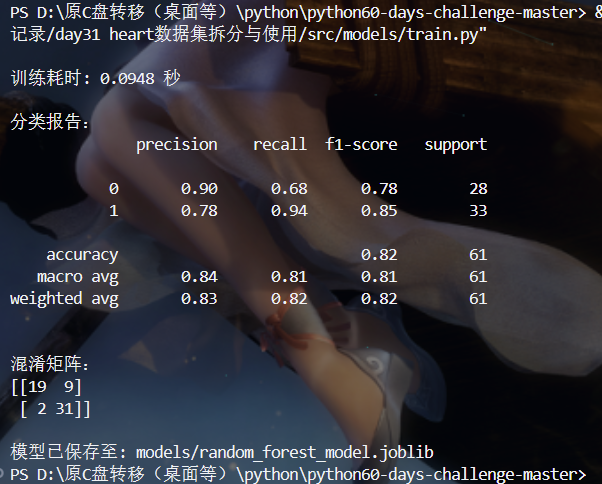
plot.py模块
import matplotlib.pyplot as plt
import seaborn as sns
import shap
import numpy as np
import pandas as pd
from typing import Any, Optional
from sklearn.metrics import confusion_matrix
from sklearn.ensemble import RandomForestClassifier
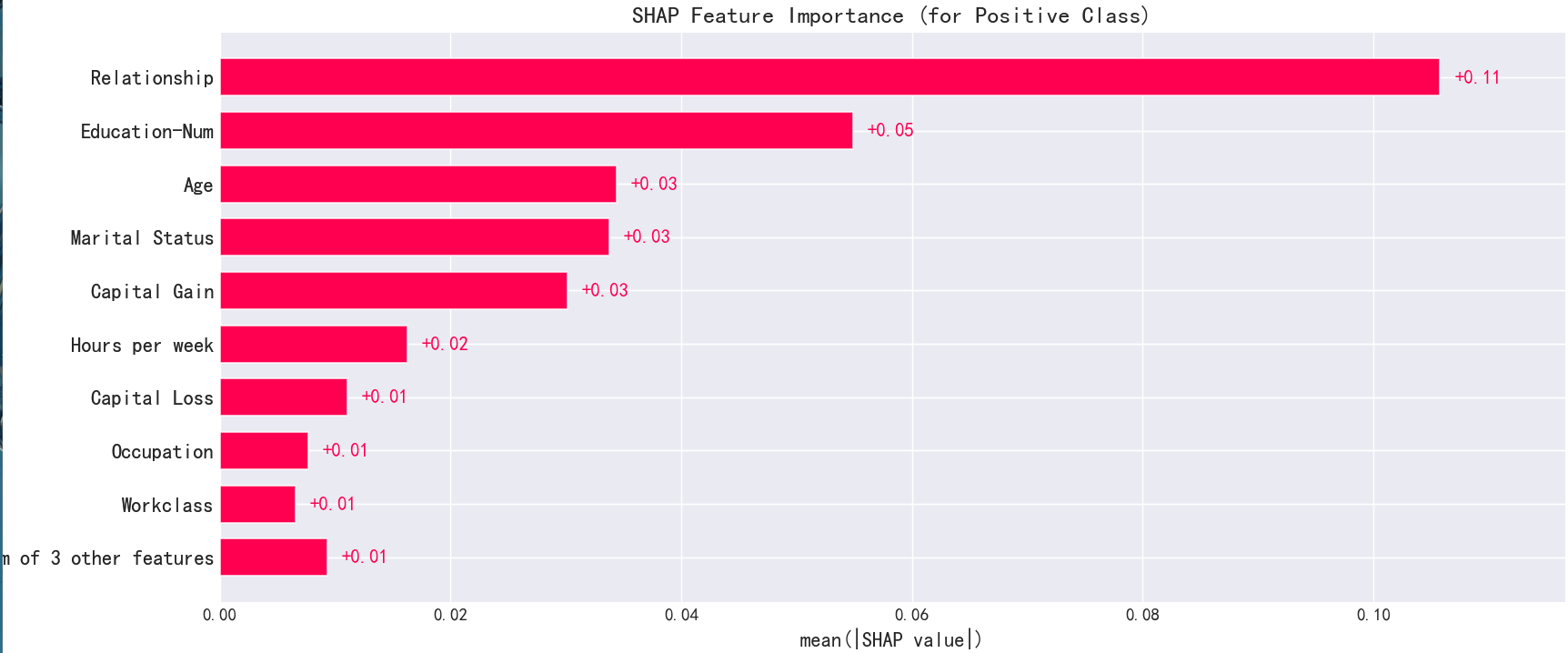
from sklearn.model_selection import train_test_splitdef plot_feature_importance_shap(model: Any, X_test: pd.DataFrame, save_path: Optional[str] = None) -> None:"""绘制SHAP特征重要性图 (使用现代SHAP API,最稳健)Args:model: 训练好的树模型X_test: 测试数据 (Pandas DataFrame)save_path: 图片保存路径,可以为 None"""print("--- 正在计算SHAP值并绘图 (使用现代API) ---")# ▼▼▼【核心修正:使用新的SHAP API流程】▼▼▼# 1. 创建解释器 (保持不变)explainer = shap.TreeExplainer(model)# 2. 计算SHAP值,得到一个 Explanation 对象,而不是原始的numpy数组shap_explanation = explainer(X_test)# 3. 使用新的 shap.plots.bar() 函数绘图# 对于二分类,我们选择对类别 1 (正类) 的SHAP值进行可视化# shap_explanation[:, :, 1] 是一个智能切片,获取所有样本、所有特征、针对类别1的SHAP值plt.figure()shap.plots.bar(shap_explanation[:, :, 1], show=False)# ▲▲▲【核心修正:使用新的SHAP API流程】▲▲▲# 优化标题plt.title("SHAP Feature Importance (for Positive Class)", fontsize=15)if save_path:plt.savefig(save_path, bbox_inches='tight')print(f"特征重要性图已保存至: {save_path}")plt.show()# --- 其他函数保持不变 ---
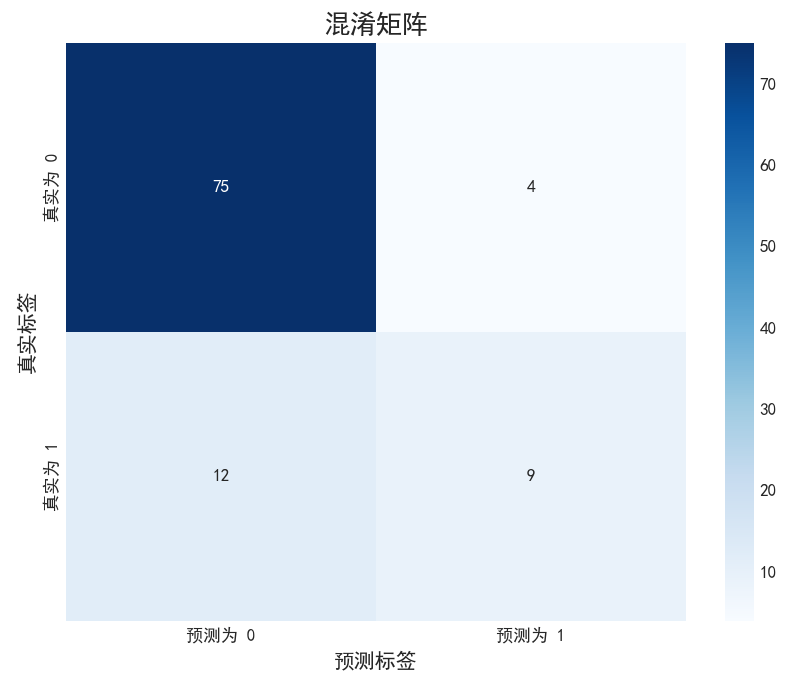
def plot_confusion_matrix(y_true: Any, y_pred: Any, save_path: Optional[str] = None) -> None:print("--- 正在绘制混淆矩阵 ---")plt.figure(figsize=(8, 6))cm = confusion_matrix(y_true, y_pred)sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', xticklabels=['预测为 0', '预测为 1'], yticklabels=['真实为 0', '真实为 1'])plt.title('混淆矩阵', fontsize=15)plt.ylabel('真实标签', fontsize=12)plt.xlabel('预测标签', fontsize=12)if save_path:plt.savefig(save_path)print(f"混淆矩阵图已保存至: {save_path}")plt.show()def set_plot_style():try:plt.style.use('seaborn-v0_8-darkgrid')except OSError:print("警告:'seaborn-v0_8-darkgrid' 样式不可用,使用默认样式。")plt.rcParams['font.sans-serif'] = ['SimHei']plt.rcParams['axes.unicode_minus'] = Falseif __name__ == "__main__":set_plot_style()print("可视化模块加载成功!") print("\n--- 开始运行功能测试示例 ---")# 1. 创建模拟数据X_mock, y_mock = shap.datasets.adult()X_mock = X_mock.iloc[:500]y_mock = y_mock[:500]X_train, X_test, y_train, y_test = train_test_split(X_mock, y_mock, test_size=0.2, random_state=42)# 2. 训练示例模型print("正在训练示例模型...")model = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=42)model.fit(X_train, y_train)print("✅ 示例模型训练完成。")# 3. 进行预测y_pred = model.predict(X_test)# 4. 调用绘图函数 (使用更新后的函数)plot_feature_importance_shap(model, X_test)# 5. 测试混淆矩阵图plot_confusion_matrix(y_test, y_pred)print("\n--- 功能测试示例结束 ---")