论文略读: LAYERWISE RECURRENT ROUTER FOR MIXTURE-OF-EXPERTS
ICLR 2025 3668
大型语言模型(LLMs)的扩展极大地提升了其在各类任务中的表现,但这一增长也需要高效的计算策略来匹配。**专家混合架构(Mixture-of-Experts,MoE)**在不显著增加训练成本的前提下扩展模型规模方面表现突出。然而,尽管MoE具备优势,当前的MoE模型在参数效率上却常常存在问题。例如,一个具有 520亿 参数的预训练MoE模型,其性能可能仅与一个标准的 6.7亿 参数模型相当。
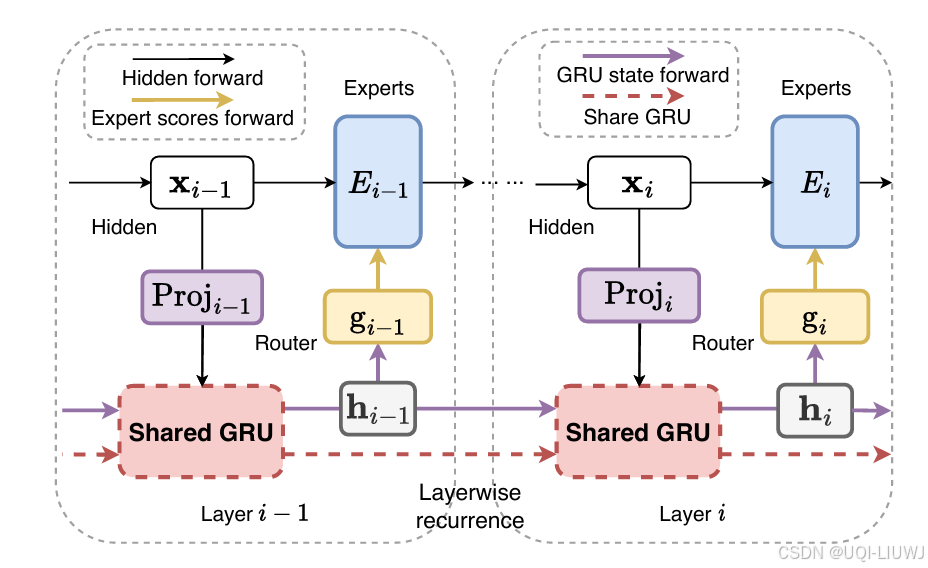
在MoE中,路由器(router) 是核心组件,但目前的做法是在各层独立地对token进行分配,未能利用历史路由信息,这可能导致次优的token–专家匹配,进而引发参数利用效率低下的问题。
为了解决这一问题,我们提出了一种新的架构:用于MoE的层间循环路由器(Layerwise Recurrent Router for Mixture-of-Experts,简称RMoE)。RMoE引入了门控循环单元(GRU),在连续层之间建立路由决策的依赖关系。这种“层间循环”机制可以高效地并行计算,且只带来可接受的计算成本。
我们的大量实证评估表明,基于RMoE的语言模型在多个基准模型上都实现了稳定且显著的性能提升。此外,RMoE还引入了一种新颖的计算阶段,该阶段与现有方法正交,从而可以无缝地集成到各种现有的MoE架构中。
分析表明,RMoE的性能提升主要得益于其跨层信息共享机制,这不仅改善了专家选择的准确性,还提升了专家间的多样性。