28-Oracle 23ai Fast Ingest(Memoptimized Rowstore)高频写入
大家都是如何解决百万级TPS的高频写入场景的,当企业有了5G工厂(比如汽车主机厂、配件的产线,整条产线上的作业台和AGV小车),有了各种数采各式sensor数据(不大不小),大量高频写入的时候,是优选写入而后再校准,允许部分的不精准;还是保持ACID接收写入速率。
可以允许ACID中哪一个有缺失,还是成年人的世界,快、准,咱都要,是否有更好的平衡呢?
一、23ai 实现百万级TPS的高频写入
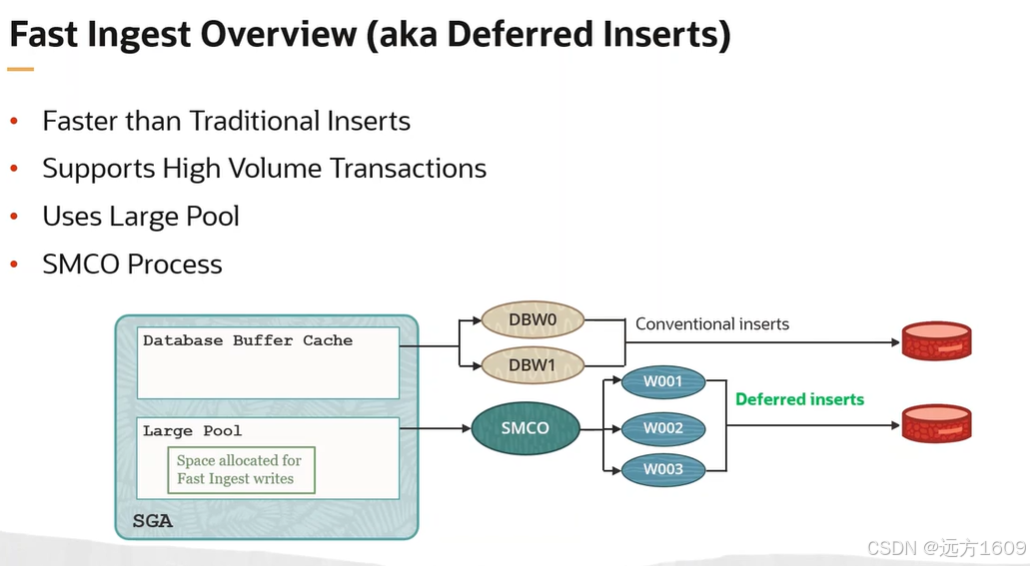
Oracle 23ai的Fast Ingest(官方名称为 Memoptimized Rowstore)是专为IoT、金融交易等高并发写入场景设计的核心技术。其核心架构分为三层:
- 内存缓冲池(Memoptimized Pool)
- 在SGA中开辟独立内存区域
- 写入时数据暂存于缓冲池,延迟写入避免直接触发磁盘I/O
- 异步批量刷盘机制
- - 由后台进程SMCO(Space Management Coordinator)和W001~W00x工作进程负责
- 哈希索引加速定位
- 通过内存哈希表快速定位缓冲数据,规避B+树锁竞争。
技术突破:相比直接写入数据文件,Fast Ingest将事务提交延迟从毫秒级降至微秒级,TPS提升10倍以上
二、行业对比:其他解决方案
| 数据库 | 技术方案 | 局限性 |
| Elasticsearch | Translog + Refresh Interval | 数据可见延迟高 |
| ClickHouse | 内存分区表 + 异步合并 | 不支持ACID事务 |
| Redis | 纯内存架构 | 数据持久化风险 |
| Oracle 23ai | Memoptimized Pool | 需预留专用内存 |
Oracle在保证ACID事务的前提下实现高频写入,而其他方案往往牺牲事务一致性或实时可见性
三、版本演进:从Oracle 19c到23ai的升级之路
- Oracle 19c:
- 仅支持基础异步写入
- 首次引入Fast Ingest,但依赖LARGE POOL且无专用内存结构
- Oracle 21c:增强MEMOPTIMIZE FOR WRITE语法,支持表级启用
- Oracle 23ai:
- 独立Memoptimized Pool区域
- 支持AI Vector Search协同处理时序数据
- 写入性能较19c提升40%,CPU开销降低25%
四、实践验证:测试Fast Ingest性能
步骤1:启用Memoptimized Pool
--要在CDB中设置,PDB中无法设置,RAC中所有节点要一致。
show parameter MEMOPTIMIZE;
SYS@FREE> show parameter MEMOPTIMIZE;NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
memoptimize_pool_size big integer 0
memoptimize_write_area_size big integer 0
memoptimize_writes string HINT
SYS@FREE>
--MEMOPTIMIZE 参数 ON/Hint(默认),是个静态参数SPFILE
alter system set memoptimize_writes = on SCOPE=spfile;
SYS@FREE> alter system set memoptimize_writes = on SCOPE=spfile;System altered.
--ALTER SYSTEM SET vector_memory_size=500M SCOPE=spfile; -- 为AI向量预留内存
--ALTER SYSTEM SET memoptimize_pool_size=2G SCOPE=spfile; --这个和FAST INGEST无关
--设置area大小
ALTER SYSTEM SET MEMOPTIMIZE_WRITE_AREA_SIEZE=2G SCOPE=BOTH;
SYS@CDB$ROOT> alter system set memoptimize_write_area_size=2g scope=both;System altered.
SHUTDOWN IMMEDIATE;
STARTUP;
--V$MEMOPTIMIZE_WRITE_AREA;
SYS@FREE> SELECT * FROM V$MEMOPTIMIZE_WRITE_AREA;TOTAL_SIZE USED_SPACE FREE_SPACE NUM_WRITES NUM_WRITERS CON_ID
---------- ---------- ---------- ---------- ----------- ----------0 0 0 0 0 10 0 0 0 0 20 0 0 0 0 3步骤2:创建支持Fast Ingest的表
CREATE TABLE TEST_FAST_INGEST (id NUMBER PRIMARY KEY,source varchar2(100)
) MEMOPTIMIZE FOR WRITE;
--Table TEST_FAST_INGEST created.
--或者将原有的表alter修成MEMOPTIMIZE FOR WRITE--查询表的是否是MEMOPTIMIZE
SELECT TABLE_NAME,MEMOPTIMIZE_WRITE FROM USER_TABLES WHERE TABLE_NAME = 'TEST_FAST_INGEST';
SYS@CDB$ROOT> SELECT TABLE_NAME,MEMOPTIMIZE_WRITE FROM USER_TABLES WHERE TABLE_NAME = 'TEST_FAST_INGEST';TABLE_NAME MEMOPTIMIZE_WRITE
___________________ ____________________
TEST_FAST_INGEST ENABLED步骤3:手动关闭后插入100w条数据
--USE HINT 写入一条
INSERT /*+ MEMOPTIMIZE_WRITE */ INTO TEST_FAST_INGEST VALUES (1,'TEST1')
--ALTER SESSION INSERT
ALTER SESSION SET MEMOPTIMIZE_WRITES=ON;
INSERT INTO TEST_FAST_INGEST VALUES (2,'TEST2');--可以手工关闭 DISABLE MEMOPTIMIZE_WRITE FOR TABLE
ALTER TABLE test_fast_ingest NO MEMOPTIMIZE FOR WRITE;SYS@CDB$ROOT> ALTER TABLE test_fast_ingest NO MEMOPTIMIZE FOR WRITE;Table TEST_FAST_INGEST altered.Elapsed: 00:00:00.049
SYS@CDB$ROOT> INSERT /*+ MEMOPTIMIZE_WRITE */ INTO TEST_FAST_INGEST (id, source)2 SELECT3 ROWNUM AS id,4 'SRC_' || TRUNC(DBMS_RANDOM.VALUE(1, 100)) AS source -- 生成 SRC_1 到 SRC_99 的随机源5 FROM DUAL6* CONNECT BY LEVEL <= 1000000;1,000,000 rows inserted.Elapsed: 00:00:09.838
SYS@CDB$ROOT> SELECT * FROM V$MEMOPTIMIZE_WRITE_AREA;TOTAL_SIZE USED_SPACE FREE_SPACE NUM_WRITES NUM_WRITERS CON_ID
_____________ _____________ _____________ _____________ ______________ _________282066944 0 282066944 0 1 3Elapsed: 00:00:00.019
-- 重新启用主键约束
ALTER TABLE TEST_FAST_INGEST MODIFY PRIMARY KEY ENABLE;步骤3、开启后插入100w条数据,查看AREA区域使用
-- 禁用约束加速写入(完成后需重新启用)
ALTER TABLE TEST_FAST_INGEST MODIFY PRIMARY KEY DISABLE;
-- 使用 CONNECT BY 语法批量生成
INSERT /*+ MEMOPTIMIZE_WRITE */ INTO TEST_FAST_INGEST (id, source)
SELECT ROWNUM AS id,'SRC_' || TRUNC(DBMS_RANDOM.VALUE(1, 100)) AS source -- 生成 SRC_1 到 SRC_99 的随机源
FROM DUAL
CONNECT BY LEVEL <= 1000000;--查看AREA使用
SYS@CDB$ROOT> SELECT * FROM V$MEMOPTIMIZE_WRITE_AREA;TOTAL_SIZE USED_SPACE FREE_SPACE NUM_WRITES NUM_WRITERS CON_ID
_____________ _____________ _____________ _____________ ______________ _________282066944 1048576 281018368 0 1 3-- 重新启用主键约束
SYS@CDB$ROOT>
ALTER TABLE TEST_FAST_INGEST MODIFY PRIMARY KEY ENABLE;
--Table TEST_FAST_INGEST altered.4、数据落盘
--数据写入的规则和设置使用DBMS_MEMOPTIMIZE Package的PL/SQL获得HWM高低水位线中的序列上、下限,DBMS_MEMOPTIMIZE WRITE_END Procedure将large pool中的当前会话数据全部落盘DBMS_MEMOPTIMIZE_ADMIN
将large pool中的当前LARGE POOL中的数据全部落盘包含所有的会话
五、应用场景:
工业物联网(IoT)、5G工厂
- 万级传感器毫秒级数据采集
智能驾驶
- 轨迹数据、ETC 高并发写入
六、技术平衡之道
Oracle 23ai通过Memoptimized Rowstore重新定义了高频数据写入,在ACID事务与极致性能间取得平衡。结合其新增的AI Vector Search,更可构建“写入-分析-决策”一体化架构。在设计IoT、实时分析系统时优先评估此特性。同样极致的性能风险性也需谨慎考虑。
Fast Ingest本质是用部分实时性换取吞吐量的工程妥协,其价值在IoT等场景不可替代,
需通过三层防御降低风险:
- 架构层:Active Data Guard + 流处理前置缓冲
- 开发层:写入前强制业务校验(避免主键冲突)
- 运维层:实时监控内存使用率