PPIO 上线 Qwen3-Embedding 系列模型
今天,PPIO 已上线 Qwen3-Embedding 系列模型!
Qwen3-Embedding 系列模型是 Qwen 模型家族的新成员。该系列模型专为文本表征、检索与排序任务设计,基于 Qwen3 基础模型进行训练,充分继承了 Qwen3 在多语言文本理解能力方面的优势。
Qwen3-Embedding 系列模型并非 chat 模型,需要通过 API 调用。现在,你可以到 PPIO 官网接入 API 进行体验。
如果你是新用户,填写邀请码【JMZ5F8】注册还可以得 15 元代金券。此外,通过你的专属邀请码每成功邀请一位好友并完成实名认证,还可以额外获得30元代金券。
你还可以到 PPIO 的 B站账号观看 Embedding 模型的视频教程: https://www.bilibili.com/video/BV1FL7VzaEwe/?share_source=copy_web&vd_source=baa594f92b682489c26bd0ea4ec8cc8f
1. 什么是 Embedding 模型?
Embedding 模型是一种将离散的符号(如单词、句子、图像等)映射到连续的向量空间中的模型。在自然语言处理(NLP)领域,它通常用于将单词或句子转换为向量形式,以便计算机能够更好地处理和理解语言信息。
训练 Embedding 模型的目标是使相似的符号在向量空间中更接近,不相似的符号更远离。例如“苹果”和“香蕉”两个单词,一个好的文本 Embedding 模型会把它们编码成两个接近的向量。这样,AI 系统就可以通过“向量距离”来判断语义相似性。
Embedding 模型常见的应用场景包括:
-
语义搜索 / RAG:用户提问后,先用向量查找相关文本,再送入大模型回答;
-
推荐系统:将用户和物品编码成向量,进行向量匹配;
-
多模态检索:输入一段文字,返回相关图片或视频;
-
聚类 / 去重 / 相似性判断:快速找出文本之间的相似程度。
今天上线的 Qwen3-Embedding 系列模型有两个系列:Qwen3-Reranker(文本重排序) 和 Qwen3-Embedding(文本嵌入)。
PPIO 平台上线了 Qwen3-Reranker-8B 与 Qwen3-Embedding-8B,开发者可以灵活组合表征与排序模块,实现功能扩展。
此外,模型支持以下定制化特性:
-
表征维度自定义:允许用户根据实际需求调整表征维度,有效降低应用成本;
-
指令适配优化:支持用户自定义指令模板,以提升特定任务、语言或场景下的性能表现。
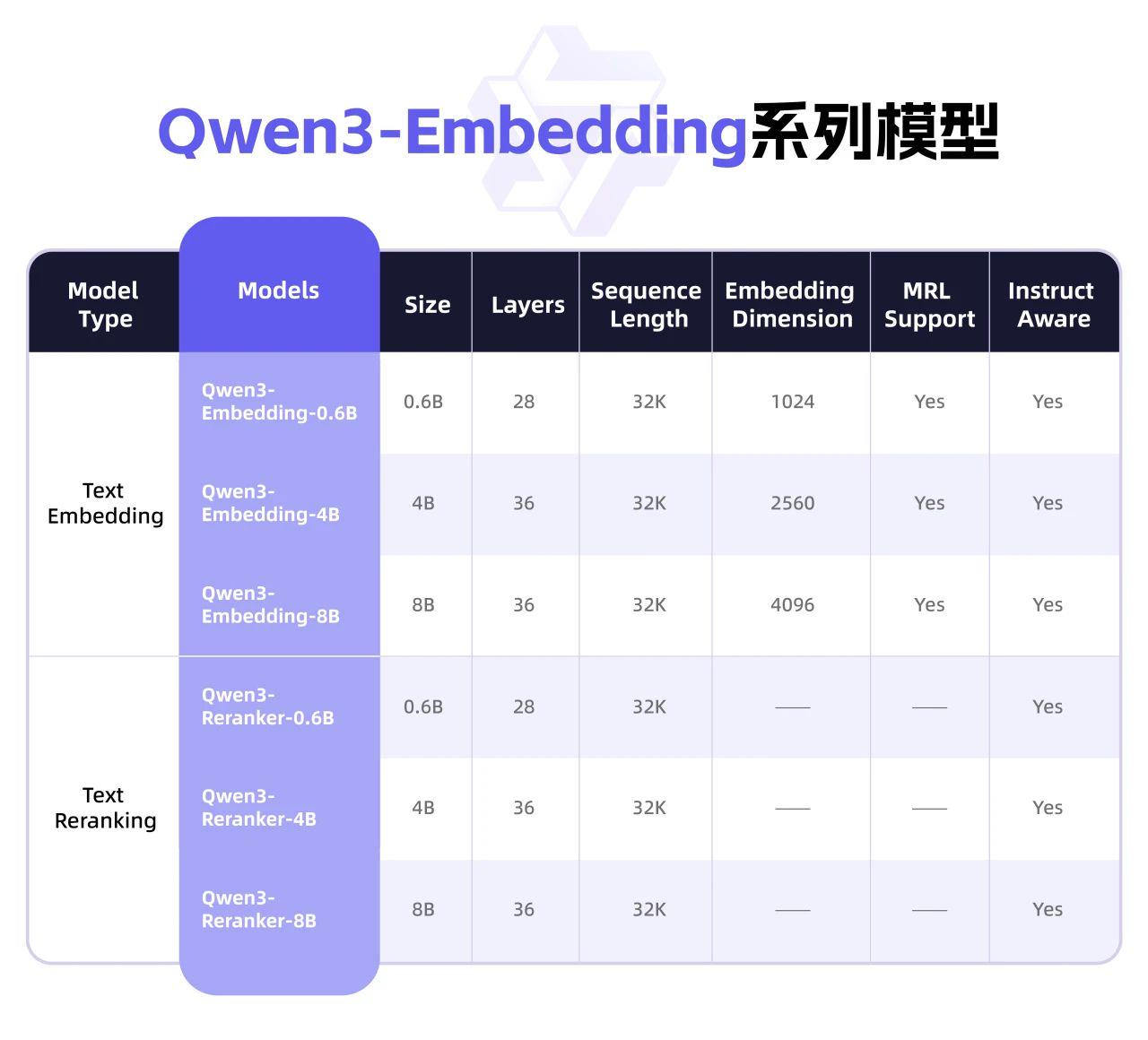
Qwen3-Embedding 系列在多个下游任务评估中达到行业领先水平。其中,8B 参数规模的 Embedding 模型在 MTEB 多语言 Leaderboard 榜单中位列第一(截至 2025 年 6 月 6 日,得分 70.58),性能超越众多商业 API 服务。此外,该系列的排序模型在各类文本检索场景中表现出色,显著提升了搜索结果的相关性。
Qwen3-Embedding 系列支持超过 100 种语言,涵盖主流自然语言及多种编程语言。该系列模型具备强大的多语言、跨语言及代码检索能力,能够有效应对多语言场景下的数据处理需求。
2. 在 Cherry Studio 接入 PPIO 的 Qwen3-Embedding
由于 Qwen3-Embedding 系列模型并非 chat 模型,需要通过 API 调用。我们以 Cherry Studio 为例进行接入。
(1)获取并保存【 API key 】、【 Base URL 】和【模型名称】
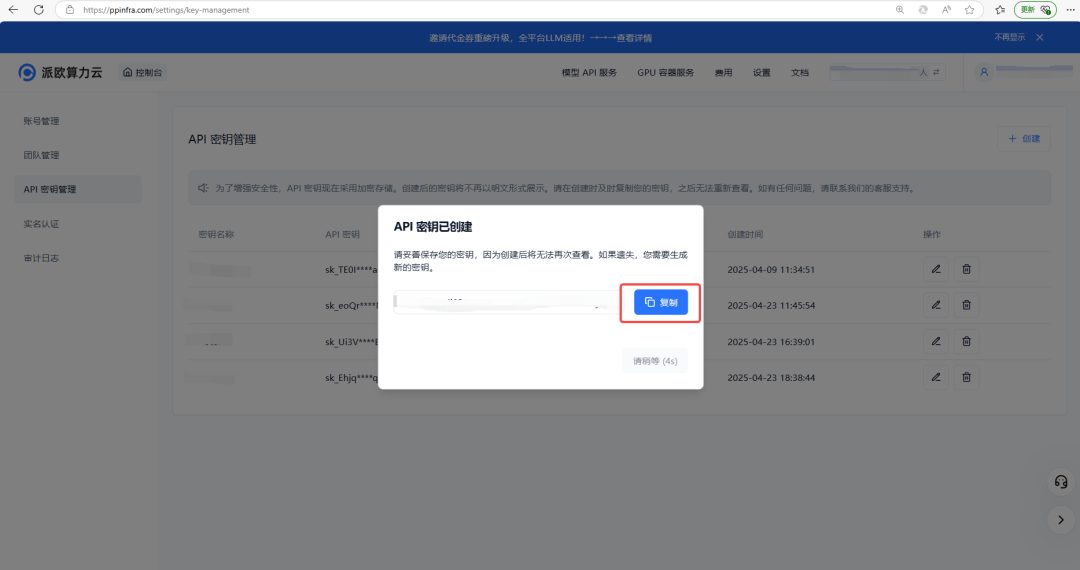
注册并登录 PPIO,然后打开 API 密钥管理页面,点击【创建】按钮,输入自定义密钥名称,生成 API 密钥。
❗️❗️❗️注意:密钥在服务端是加密存储,请在生成时保存好密钥(比如记录在备忘录里);若遗失密钥,可以在控制台上删除并创建一个新的密钥。
然后到模型广场获取模型名和 Base URL,固定地址为:https://api.ppinfra.com/v3/openai

(2)在 Cherry Studio 中集成 API
下载并安装 Cherry Studio,官网:https://cherry-ai.com/download
打开 Cherry Studio,点击设置,选择【PPIO派欧云】,输入官网生成的API密钥。
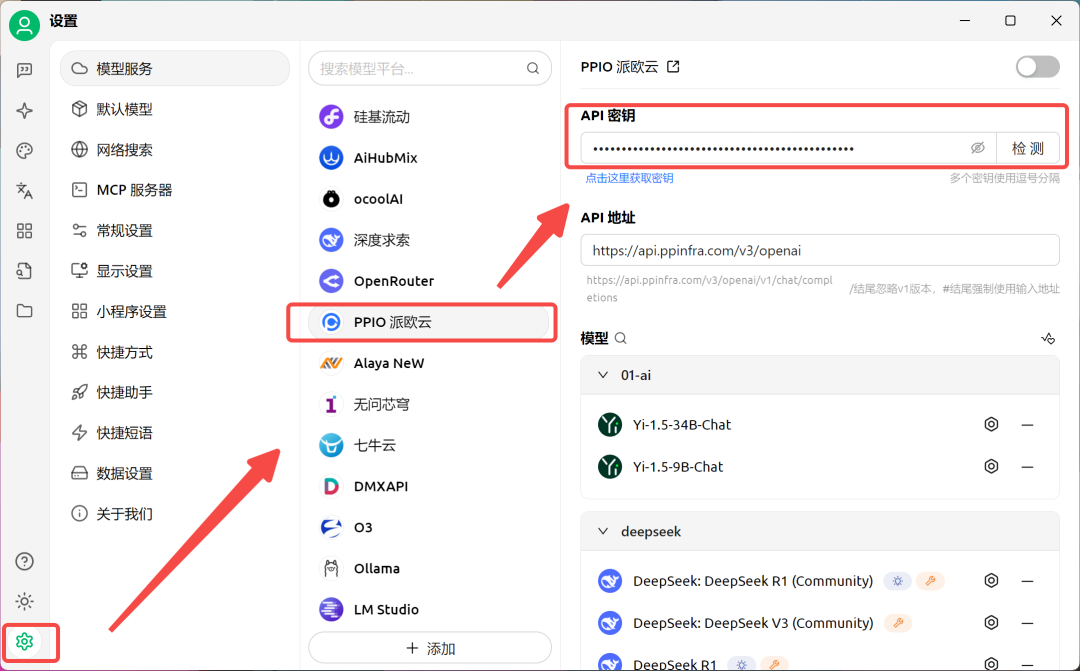
点击【添加】,填入所需模型名称。
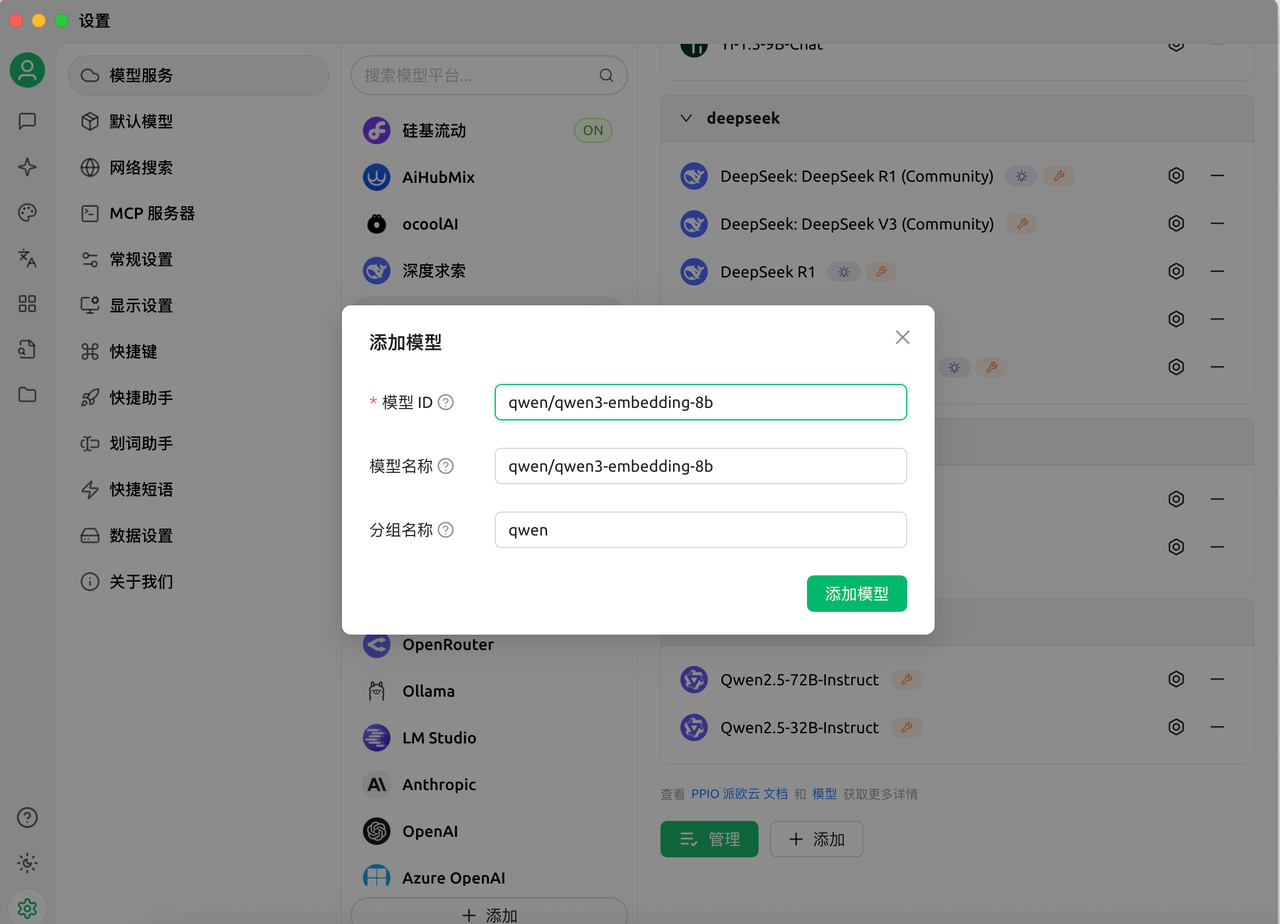
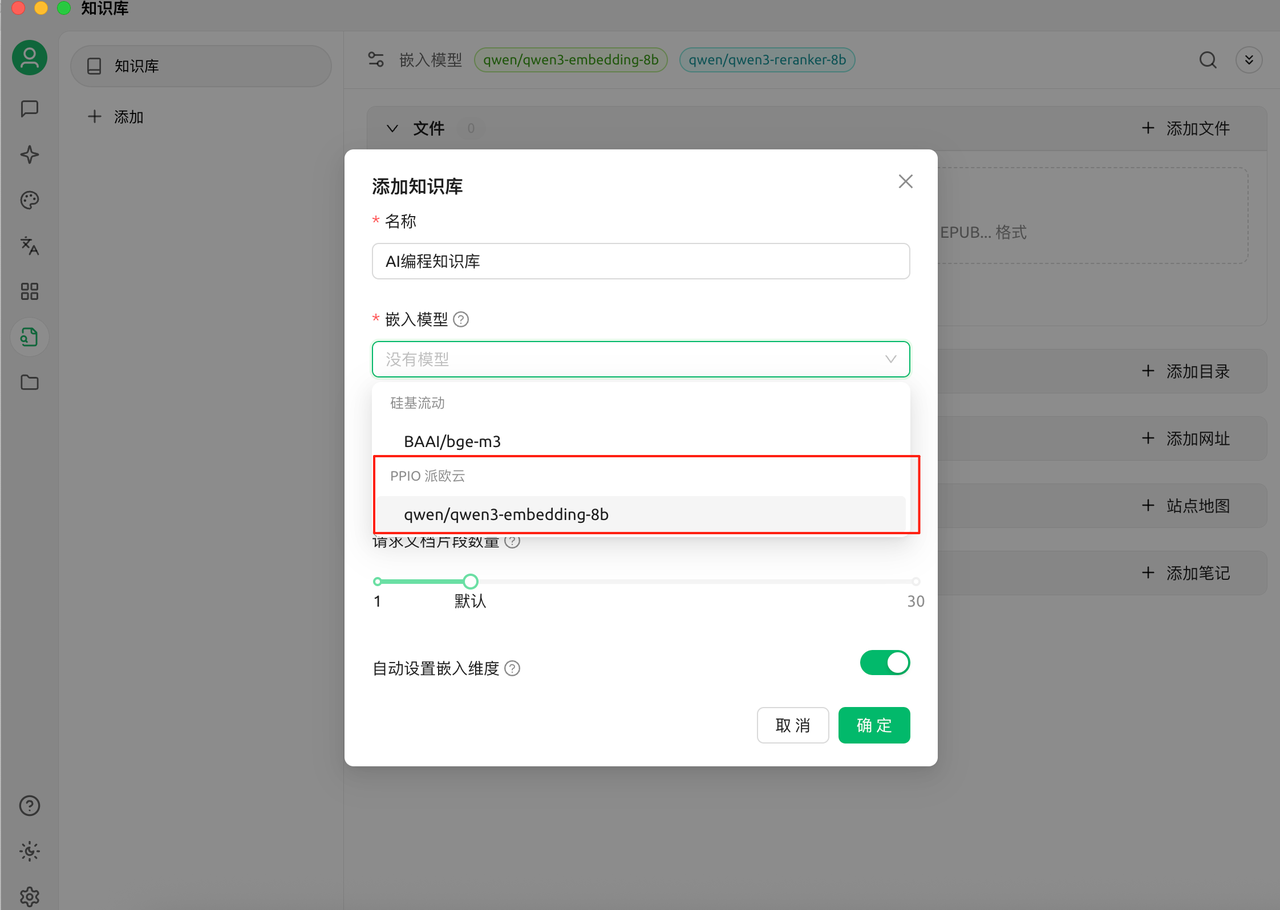
在导航栏左侧点击知识库并添加,自定义名称后,下拉嵌入模型,会看到刚刚添加的 Qwen3-Embedding-8B 模型,将其添加。
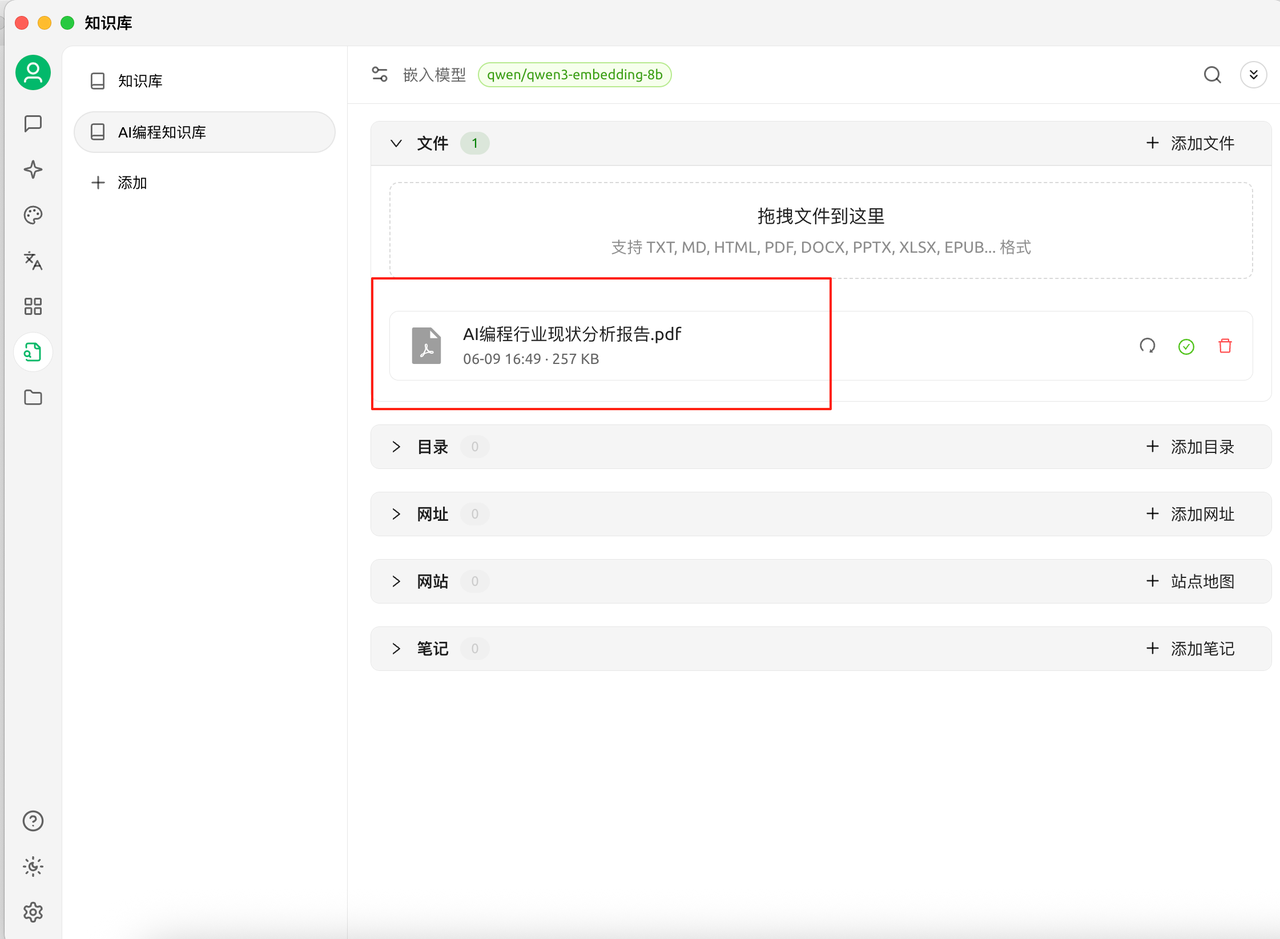
然后上传本地文档,这样一个本地知识库就搭建好了。
回到对话页面,选择刚刚构建的知识库,并点击 @ 添加一个模型。
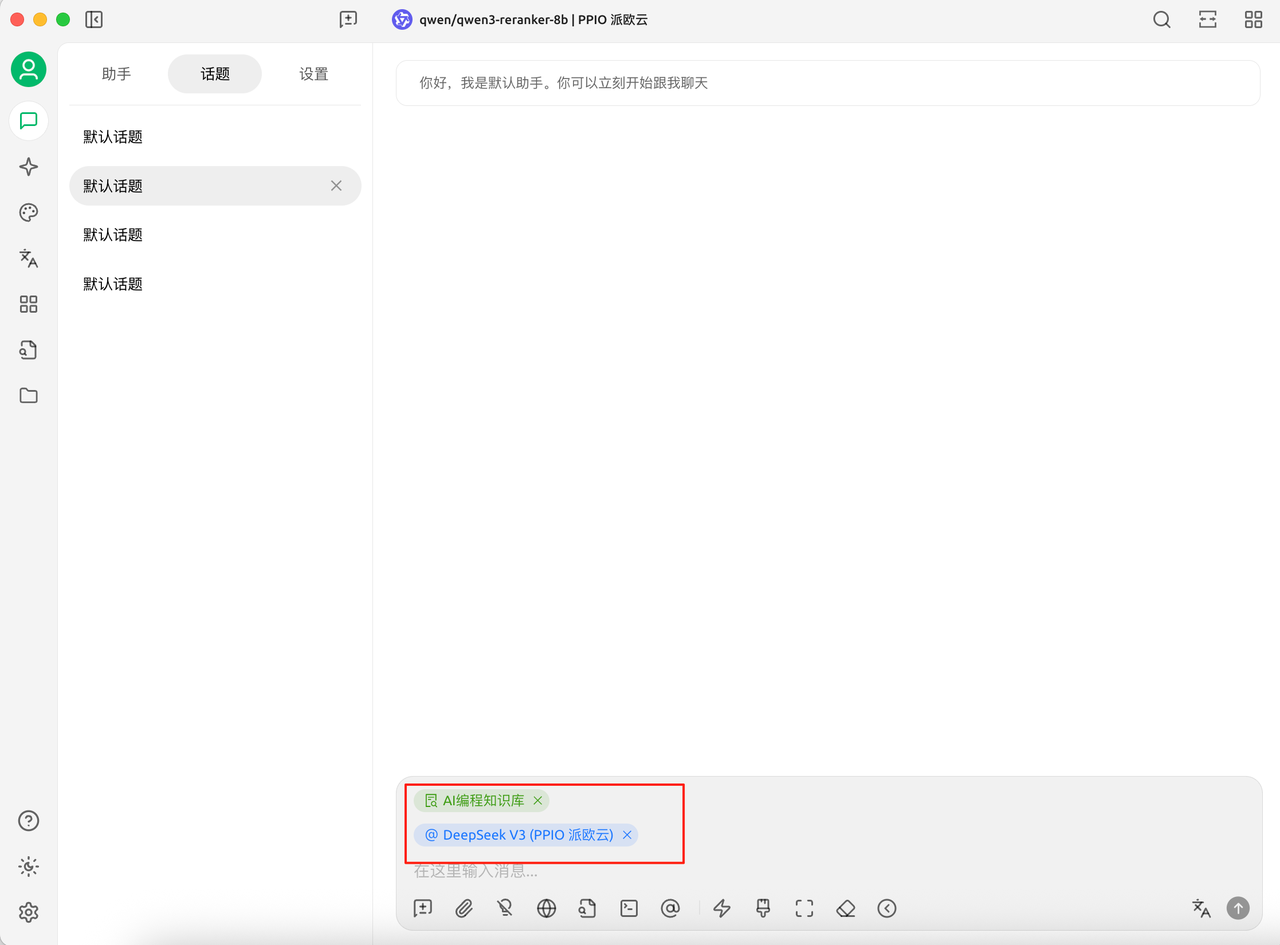
输入问题,就可以通过本地知识库进行回答了。