6.6 打卡
DAY 45 Tensorboard使用介绍
知识点回顾:
- tensorboard的发展历史和原理
- tensorboard的常见操作
- tensorboard在cifar上的实战:MLP和CNN模型
效果展示如下,很适合拿去组会汇报撑页数:
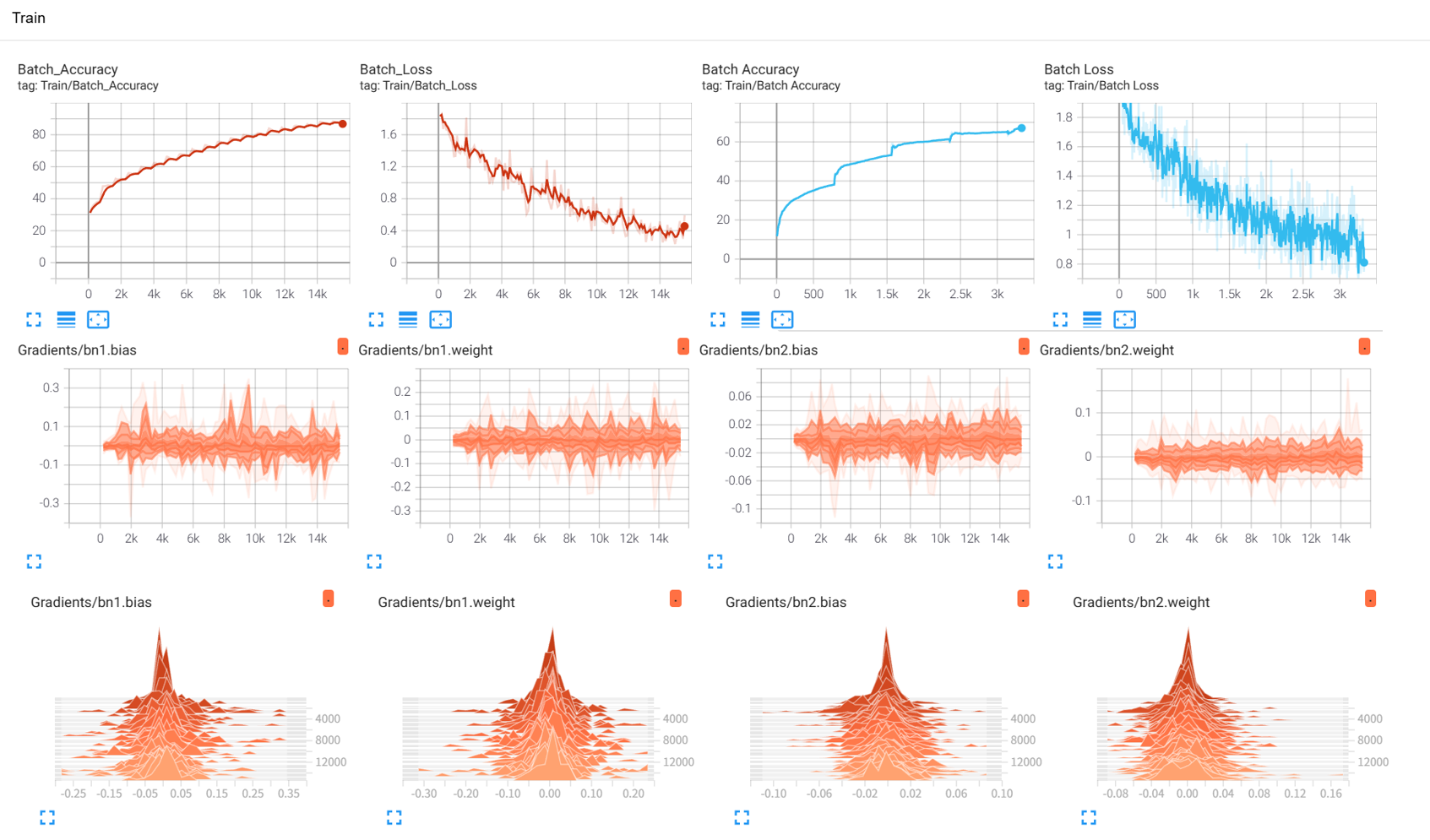
作业:对resnet18在cifar10上采用微调策略下,用tensorboard监控训练过程。
PS:
- tensorboard和torch版本存在一定的不兼容性,如果报错请新建环境尝试。
- tensorboard的代码还有有一定的记忆量,实际上深度学习的经典代码都是类似于八股文,看多了就习惯了,难度远远小于考研数学等需要思考的内容
- 实际上对目前的ai而言,你只需要先完成最简单的demo,然后让他给你加上tensorboard需要打印的部分即可。---核心是弄懂tensorboard可以打印什么信息,以及如何看可视化后的结果,把ai当成记忆大师用到的时候通过它来调取对应的代码即可。
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
import torchvision
import torchvision.transforms as transforms
import torchvision.models as models
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter # 导入SummaryWriter
import time
import os
import copy
import numpy as np# 0. 配置和超参数
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {DEVICE}")BATCH_SIZE = 128
LEARNING_RATE = 0.001
NUM_EPOCHS = 20 # 实际应用中可能需要更多轮次
MODEL_NAME = "resnet18_finetune_cifar10"
LOG_DIR = f'runs/{MODEL_NAME}_{time.strftime("%Y%m%d-%H%M%S")}'# 1. 数据准备
# ResNet18在ImageNet上预训练,输入图像通常是224x224
# CIFAR-10是32x32,需要调整
# ImageNet的均值和标准差
imagenet_mean = [0.485, 0.456, 0.406]
imagenet_std = [0.229, 0.224, 0.225]transform_train = transforms.Compose([transforms.Resize(256), # 先放大到256transforms.RandomResizedCrop(224), # 随机裁剪到224x224transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize(imagenet_mean, imagenet_std)
])transform_val = transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224), # 中心裁剪到224x224transforms.ToTensor(),transforms.Normalize(imagenet_mean, imagenet_std)
])# 下载并加载CIFAR-10数据集
train_dataset = torchvision.datasets.CIFAR10(root='./data', train=True,download=True, transform=transform_train)
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE,shuffle=True, num_workers=4)val_dataset = torchvision.datasets.CIFAR10(root='./data', train=False,download=True, transform=transform_val)
val_loader = DataLoader(val_dataset, batch_size=BATCH_SIZE,shuffle=False, num_workers=4)dataloaders = {'train': train_loader, 'val': val_loader}
dataset_sizes = {'train': len(train_dataset), 'val': len(val_dataset)}
class_names = train_dataset.classes # ['airplane', 'automobile', ..., 'truck']
num_classes = len(class_names)# 2. 模型准备
# 加载预训练的ResNet18
model_ft = models.resnet18(weights=models.ResNet18_Weights.IMAGENET1K_V1)# 冻结所有预训练层参数
for param in model_ft.parameters():param.requires_grad = False# 获取ResNet18最后一个全连接层的输入特征数
num_ftrs = model_ft.fc.in_features# 替换最后一个全连接层以适应CIFAR-10的10个类别
# 新的层默认 requires_grad=True
model_ft.fc = nn.Linear(num_ftrs, num_classes)model_ft = model_ft.to(DEVICE)# 3. 损失函数和优化器
criterion = nn.CrossEntropyLoss()# 只优化新添加的分类头(model_ft.fc)的参数
# 如果想优化所有层,传入 model_ft.parameters()
optimizer_ft = optim.Adam(model_ft.fc.parameters(), lr=LEARNING_RATE)# 学习率衰减(可选,但推荐)
# 每7个epoch,学习率乘以0.1
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)# 4. TensorBoard设置
writer = SummaryWriter(LOG_DIR)# 可选:将一些样本图像写入TensorBoard
dataiter = iter(train_loader)
images, labels = next(dataiter)
img_grid = torchvision.utils.make_grid(images[:16], nrow=4) # 取前16张图,每行4张
writer.add_image('cifar10_sample_images', img_grid)# 可选:将模型图写入TensorBoard (确保输入和模型都在同一设备)
# 注意:如果模型很大或者输入复杂,这步可能比较慢或出错
try:dummy_input = images[:1].to(DEVICE) # 取一个batch的第一个样本作为dummy inputwriter.add_graph(model_ft, dummy_input)
except Exception as e:print(f"Could not add graph to TensorBoard: {e}")# 5. 训练和验证函数
def train_model(model, criterion, optimizer, scheduler, num_epochs=25):since = time.time()best_model_wts = copy.deepcopy(model.state_dict())best_acc = 0.0global_step_train = 0for epoch in range(num_epochs):print(f'Epoch {epoch+1}/{num_epochs}')print('-' * 10)# 每个epoch都有训练和验证阶段for phase in ['train', 'val']:if phase == 'train':model.train() # 设置模型为训练模式else:model.eval() # 设置模型为评估模式running_loss = 0.0running_corrects = 0# 迭代数据for batch_idx, (inputs, labels) in enumerate(dataloaders[phase]):inputs = inputs.to(DEVICE)labels = labels.to(DEVICE)# 清零参数梯度optimizer.zero_grad()# 前向传播# 只在训练阶段跟踪历史with torch.set_grad_enabled(phase == 'train'):outputs = model(inputs)_, preds = torch.max(outputs, 1)loss = criterion(outputs, labels)# 只在训练阶段进行反向传播和优化if phase == 'train':loss.backward()optimizer.step()# TensorBoard: 记录每个batch的训练损失writer.add_scalar('Loss/train_batch', loss.item(), global_step_train)global_step_train += 1# 统计running_loss += loss.item() * inputs.size(0)running_corrects += torch.sum(preds == labels.data)if phase == 'train':scheduler.step() # 更新学习率epoch_loss = running_loss / dataset_sizes[phase]epoch_acc = running_corrects.double() / dataset_sizes[phase]print(f'{phase} Loss: {epoch_loss:.4f} Acc: {epoch_acc:.4f}')# TensorBoard: 记录每个epoch的损失和准确率if phase == 'train':writer.add_scalar('Loss/train_epoch', epoch_loss, epoch)writer.add_scalar('Accuracy/train_epoch', epoch_acc, epoch)writer.add_scalar('LearningRate', optimizer.param_groups[0]['lr'], epoch) # 记录学习率else: # phase == 'val'writer.add_scalar('Loss/validation_epoch', epoch_loss, epoch)writer.add_scalar('Accuracy/validation_epoch', epoch_acc, epoch)# 深度拷贝模型权重,如果验证集准确率更高if phase == 'val' and epoch_acc > best_acc:best_acc = epoch_accbest_model_wts = copy.deepcopy(model.state_dict())# 保存最佳模型torch.save(model.state_dict(), os.path.join(LOG_DIR, f'{MODEL_NAME}_best.pth'))print(f"Saved best model with acc: {best_acc:.4f}")print()time_elapsed = time.time() - sinceprint(f'Training complete in {time_elapsed // 60:.0f}m {time_elapsed % 60:.0f}s')print(f'Best val Acc: {best_acc:4f}')# 加载最佳模型权重model.load_state_dict(best_model_wts)return model# 6. 开始训练
print("Starting training...")
model_ft = train_model(model_ft, criterion, optimizer_ft, exp_lr_scheduler, num_epochs=NUM_EPOCHS)# 7. 关闭TensorBoard writer
writer.close()
print(f"TensorBoard logs saved to: {LOG_DIR}")
print(f"To view TensorBoard, run: tensorboard --logdir={os.path.abspath('runs')}")# (可选) 保存最终模型
final_model_path = os.path.join(LOG_DIR, f'{MODEL_NAME}_final.pth')
torch.save(model_ft.state_dict(), final_model_path)
print(f"Final model saved to {final_model_path}")# (可选) 可视化一些预测结果
def visualize_model(model, num_images=6):was_training = model.trainingmodel.eval()images_so_far = 0fig = plt.figure(figsize=(15, 15))with torch.no_grad():for i, (inputs, labels) in enumerate(dataloaders['val']):inputs = inputs.to(DEVICE)labels = labels.to(DEVICE)outputs = model(inputs)_, preds = torch.max(outputs, 1)for j in range(inputs.size()[0]):images_so_far += 1ax = plt.subplot(num_images//2, 2, images_so_far)ax.axis('off')ax.set_title(f'predicted: {class_names[preds[j]]}\ntrue: {class_names[labels[j]]}')# 反归一化并显示图像img = inputs.cpu().data[j].numpy().transpose((1, 2, 0))mean = np.array(imagenet_mean)std = np.array(imagenet_std)img = std * img + meanimg = np.clip(img, 0, 1)ax.imshow(img)if images_so_far == num_images:model.train(mode=was_training)# 将图像保存到TensorBoard日志目录plt.savefig(os.path.join(LOG_DIR, 'predictions_sample.png'))print(f"Predictions sample image saved to {os.path.join(LOG_DIR, 'predictions_sample.png')}")# 也可以将这个图添加到TensorBoardtry:writer_final = SummaryWriter(LOG_DIR) # 重新打开writer或使用全局的writer_final.add_figure('predictions', fig, global_step=NUM_EPOCHS)writer_final.close()except Exception as e_fig:print(f"Could not add figure to TensorBoard: {e_fig}")returnmodel.train(mode=was_training)# 如果需要可视化,取消注释以下行并确保matplotlib已安装
# import matplotlib.pyplot as plt
# visualize_model(model_ft)