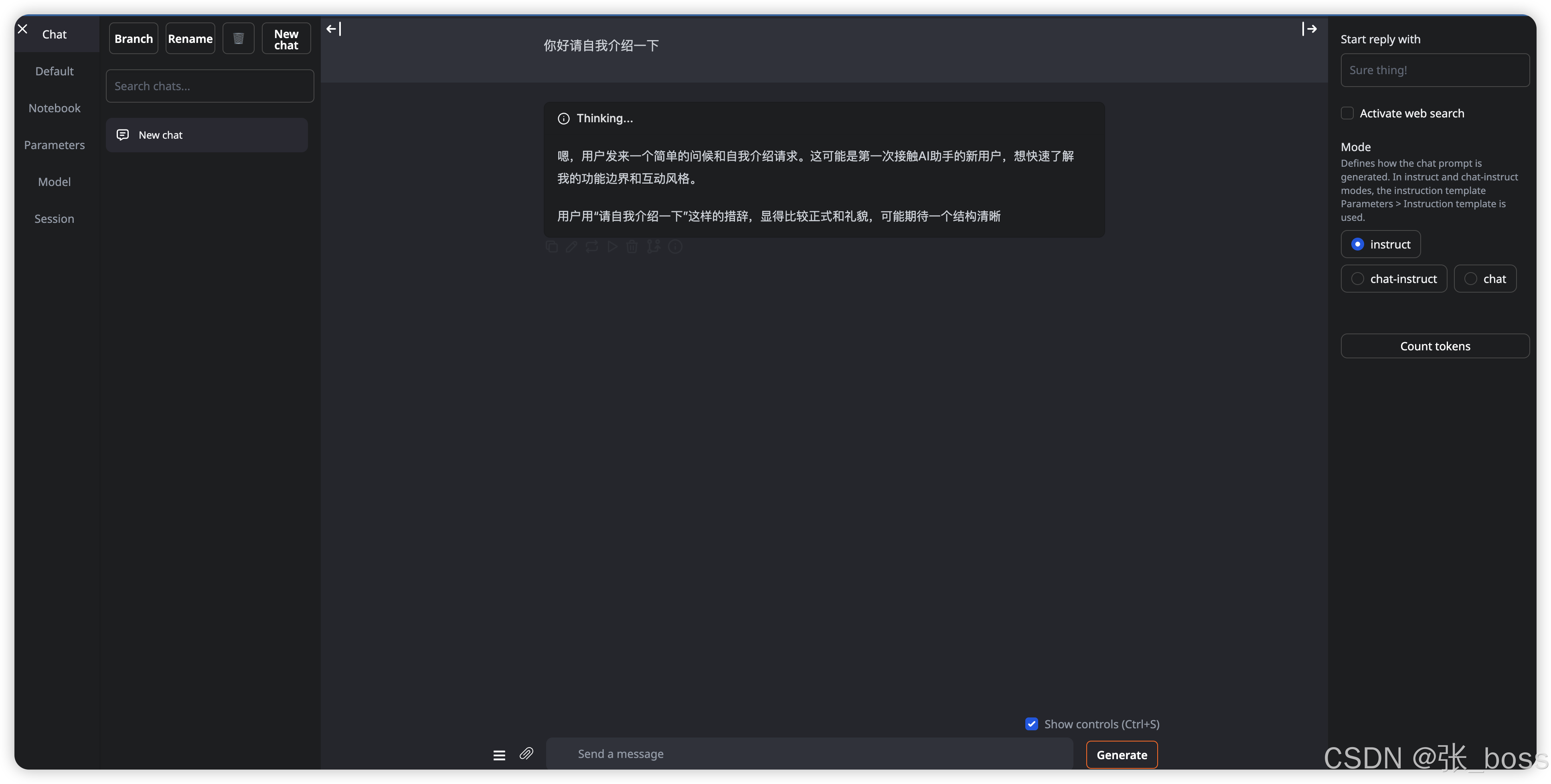
【oobabooga 本地AI模型搭建】
文本生成 Web UI
用于大型语言模型的 Gradio Web UI。
其目标是成为文本生成的AUTOMATIC1111/stable-diffusion-webui 。
尝试 Deep Reason 扩展
特征
-
在一个 UI/API 中支持多个文本生成后端,包括llama.cpp,Transformers,ExLlamaV3,ExLlamaV2,和TensorRT-LLM(后者通过其自己的Dockerfile)。
-
轻松设置:在 Windows/Linux/macOS 上为 GGUF 模型选择便携式版本(零设置,只需解压缩并运行),或者选择创建自包含
installer_files目录的一键安装程序。 -
100% 离线和私密,无需遥测、外部资源或远程更新请求。
-
使用 Jinja2 模板自动格式化提示符。您无需担心提示符的格式。
-
文件附件:上传文本文件和PDF文档,讲述其内容。
-
网络搜索:可选择使用 LLM 生成的查询搜索互联网,为对话添加上下文。
-
具有深色和浅色主题的美观用户界面。
-
instruct用于遵循指令的模式(如 ChatGPT)和chat-instruct用于chat与自定义角色交谈的模式。 -
随时编辑消息、在消息版本之间导航以及分支对话。
-
多种采样参数和生成选项,用于复杂的文本生成控制。
-
无需重新启动即可在 UI 中切换不同模型。
-
GGUF 模型的自动 GPU 层(在 NVIDIA GPU 上)。
-
在默认/笔记本选项卡中生成自由格式的文本,而不仅限于聊天轮次。
-
与 Chat 和 Completions 端点兼容的 OpenAI API,包括工具调用支持 - 参见示例。
-
扩展支持,提供大量内置和用户贡献的扩展。详情请参阅wiki和extensions 目录。
如何安装
选项 1:便携式构建(从这里开始)
无需安装 – 只需解压并运行。兼容 Windows、Linux 和 macOS 上的 GGUF (llama.cpp) 模型。
下载地址:https://github.com/oobabooga/text-generation-webui/releases
选项 2:一键安装程序
-
克隆或下载存储库。
-
运行与您的操作系统匹配的脚本:
start_linux.sh start_windows.bat 或 start_macos.sh -
当系统询问时,请选择您的 GPU 供应商。
-
安装完成后,浏览至
http://localhost:7860 -
玩得开心!
稍后要重新启动 Web UI,只需运行相同的start_脚本即可。如果需要重新安装,请删除installer_files安装期间创建的文件夹,然后再次运行该脚本。
您可以使用命令行标志,例如: ./start_linux.sh --help ,或将其添加到user_data/CMD_FLAGS.txt(例如,--api启用 API 使用)。要更新项目,请运行update_wizard_linux.sh,update_wizard_windows.bat,或update_wizard_macos.sh。
设置详细信息和有关手动安装的信息
一键安装程序
该脚本使用 Miniconda 在文件夹中设置 Conda 环境installer_files。
如果您需要在installer_files环境中手动安装某些内容,则可以使用 cmd 脚本启动交互式 shell:cmd_linux.sh,cmd_windows.bat,或cmd_macos.sh。
-
无需以管理员/root身份运行任何脚本(
start_,,update_wizard_或)。cmd_ -
要安装扩展程序所需的组件,您可以使用
extensions_reqs适用于您操作系统的脚本。最后,此脚本将安装项目的主要组件,以确保在发生版本冲突时,这些组件优先安装。 -
有关 AMD 和 WSL 设置的更多说明,请查阅文档。
-
对于自动安装,您可以使用
GPU_CHOICE,,LAUNCH_AFTER_INSTALL和INSTALL_EXTENSIONS环境变量。例如:GPU_CHOICE=A LAUNCH_AFTER_INSTALL=FALSE INSTALL_EXTENSIONS=TRUE ./start_linux.sh。
使用 Conda 手动安装
如果您有使用命令行的经验,推荐使用。
0.安装Conda
https://docs.conda.io/en/latest/miniconda.html
在 Linux 或 WSL 上,可以使用这两个命令自动安装(源):
curl -sL "https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh" > "Miniconda3.sh"
bash Miniconda3.sh
1.创建新的conda环境
conda create -n textgen python=3.11
conda activate textgen2.安装Pytorch
| 系统 | 图形处理器 | 命令 |
| Linux/WSL | 英伟达 |
|
| Linux/WSL | 仅限 CPU |
|
| Linux | AMD |
|
| MacOS + MPS | 任何 |
|
| 视窗 | 英伟达 |
|
| 视窗 | 仅限 CPU |
|
最新的命令可以在这里找到:https://pytorch.org/get-started/locally/。
如果您需要nvcc手动编译某些库,您还需要安装这个:
conda install -y -c "nvidia/label/cuda-12.4.1" cuda
3.安装Web UI
git clone https://github.com/oobabooga/text-generation-webui
cd text-generation-webui
pip install -r <requirements file according to table below>
要使用的要求文件:
| 图形处理器 | 中央处理器 | 要使用的需求文件 |
| 英伟达 | 拥有 AVX2 |
|
| 英伟达 | 没有 AVX2 |
|
| AMD | 拥有 AVX2 |
|
| AMD | 没有 AVX2 |
|
| 仅限 CPU | 拥有 AVX2 |
|
| 仅限 CPU | 没有 AVX2 |
|
| 苹果 | 英特尔 |
|
| 苹果 | 苹果硅片 |
|
启动 Web UI
conda activate textgen
cd text-generation-webui
python server.py
然后浏览至
http://localhost:7860/?__theme=dark
手动安装
requirements*.txt以上包含通过 GitHub Actions 预编译的各种轮子。如果您希望手动编译,或者由于没有适合您硬件的轮子而需要手动编译,您可以requirements_nowheels.txt手动使用并安装所需的加载器。
替代方案:Docker
For NVIDIA GPU:
ln -s docker/{nvidia/Dockerfile,nvidia/docker-compose.yml,.dockerignore} .
For AMD GPU:
ln -s docker/{amd/Dockerfile,amd/docker-compose.yml,.dockerignore} .
For Intel GPU:
ln -s docker/{intel/Dockerfile,amd/docker-compose.yml,.dockerignore} .
For CPU only
ln -s docker/{cpu/Dockerfile,cpu/docker-compose.yml,.dockerignore} .
cp docker/.env.example .env
#Create logs/cache dir :
mkdir -p user_data/logs user_data/cache
# Edit .env and set:
# TORCH_CUDA_ARCH_LIST based on your GPU model
# APP_RUNTIME_GID your host user's group id (run `id -g` in a terminal)
# BUILD_EXTENIONS optionally add comma separated list of extensions to build
# Edit user_data/CMD_FLAGS.txt and add in it the options you want to execute (like --listen --cpu)
#
docker compose up --build您需要安装 Docker Compose v2.17 或更高版本。请参阅本指南以获取说明。 如需更多 docker 文件,请查看此存储库。 更新要求 时不时地requirements*.txt会发生变化。要更新,请使用以下命令:
conda activate textgen
cd text-generation-webui
pip install -r --upgrade
命令行标志列表
usage: server.py [-h] [--multi-user] [--character CHARACTER] [--model MODEL] [--lora LORA [LORA ...]] [--model-dir MODEL_DIR] [--lora-dir LORA_DIR] [--model-menu] [--settings SETTINGS][--extensions EXTENSIONS [EXTENSIONS ...]] [--verbose] [--idle-timeout IDLE_TIMEOUT] [--loader LOADER] [--cpu] [--cpu-memory CPU_MEMORY] [--disk] [--disk-cache-dir DISK_CACHE_DIR][--load-in-8bit] [--bf16] [--no-cache] [--trust-remote-code] [--force-safetensors] [--no_use_fast] [--use_flash_attention_2] [--use_eager_attention] [--torch-compile] [--load-in-4bit][--use_double_quant] [--compute_dtype COMPUTE_DTYPE] [--quant_type QUANT_TYPE] [--flash-attn] [--threads THREADS] [--threads-batch THREADS_BATCH] [--batch-size BATCH_SIZE] [--no-mmap][--mlock] [--gpu-layers N] [--tensor-split TENSOR_SPLIT] [--numa] [--no-kv-offload] [--row-split] [--extra-flags EXTRA_FLAGS] [--streaming-llm] [--ctx-size N] [--cache-type N][--model-draft MODEL_DRAFT] [--draft-max DRAFT_MAX] [--gpu-layers-draft GPU_LAYERS_DRAFT] [--device-draft DEVICE_DRAFT] [--ctx-size-draft CTX_SIZE_DRAFT] [--gpu-split GPU_SPLIT][--autosplit] [--cfg-cache] [--no_flash_attn] [--no_xformers] [--no_sdpa] [--num_experts_per_token N] [--enable_tp] [--cpp-runner] [--deepspeed] [--nvme-offload-dir NVME_OFFLOAD_DIR][--local_rank LOCAL_RANK] [--alpha_value ALPHA_VALUE] [--rope_freq_base ROPE_FREQ_BASE] [--compress_pos_emb COMPRESS_POS_EMB] [--listen] [--listen-port LISTEN_PORT][--listen-host LISTEN_HOST] [--share] [--auto-launch] [--gradio-auth GRADIO_AUTH] [--gradio-auth-path GRADIO_AUTH_PATH] [--ssl-keyfile SSL_KEYFILE] [--ssl-certfile SSL_CERTFILE][--subpath SUBPATH] [--old-colors] [--portable] [--api] [--public-api] [--public-api-id PUBLIC_API_ID] [--api-port API_PORT] [--api-key API_KEY] [--admin-key ADMIN_KEY][--api-enable-ipv6] [--api-disable-ipv4] [--nowebui]文档
https://github.com/oobabooga/text-generation-webui/wiki
下载模型
模型应该放在文件夹中text-generation-webui/user_data/models。它们通常从Hugging Face下载。
#GGUF 模型是单个文件,应直接放入user_data/models。例如:
text-generation-webui
└── user_data└── models└── llama-2-13b-chat.Q4_K_M.gguf
#其余模型类型(例如 16 位 Transformers 模型和 EXL2 模型)由多个文件组成,必须放在子文件夹中。例如:
text-generation-webui
└── user_data└── models└── lmsys_vicuna-33b-v1.3├── config.json├── generation_config.json├── pytorch_model-00001-of-00007.bin├── pytorch_model-00002-of-00007.bin├── pytorch_model-00003-of-00007.bin├── pytorch_model-00004-of-00007.bin├── pytorch_model-00005-of-00007.bin├── pytorch_model-00006-of-00007.bin├── pytorch_model-00007-of-00007.bin├── pytorch_model.bin.index.json├── special_tokens_map.json├── tokenizer_config.json└── tokenizer.model
#在这两种情况下,您都可以使用 UI 的“模型”选项卡自动从 Hugging Face 下载模型。您也可以通过命令行下载:
python download-model.py organization/model
运行python download-model.py --help即可查看所有选项。Google Colab 笔记本 https://colab.research.google.com/github/oobabooga/text-generation-webui/blob/main/Colab-TextGen-GPU.ipynb
社区 https://www.reddit.com/r/Oobabooga/
案例
MAC 下载客户端
1.下载后文件文.ZIP
2.需要解压文件
下载模型
https://huggingface.co/models
 选择所需要的模型
选择所需要的模型

-
使用此模型
-
浏览量
3.根据电脑配置和需求进行下载
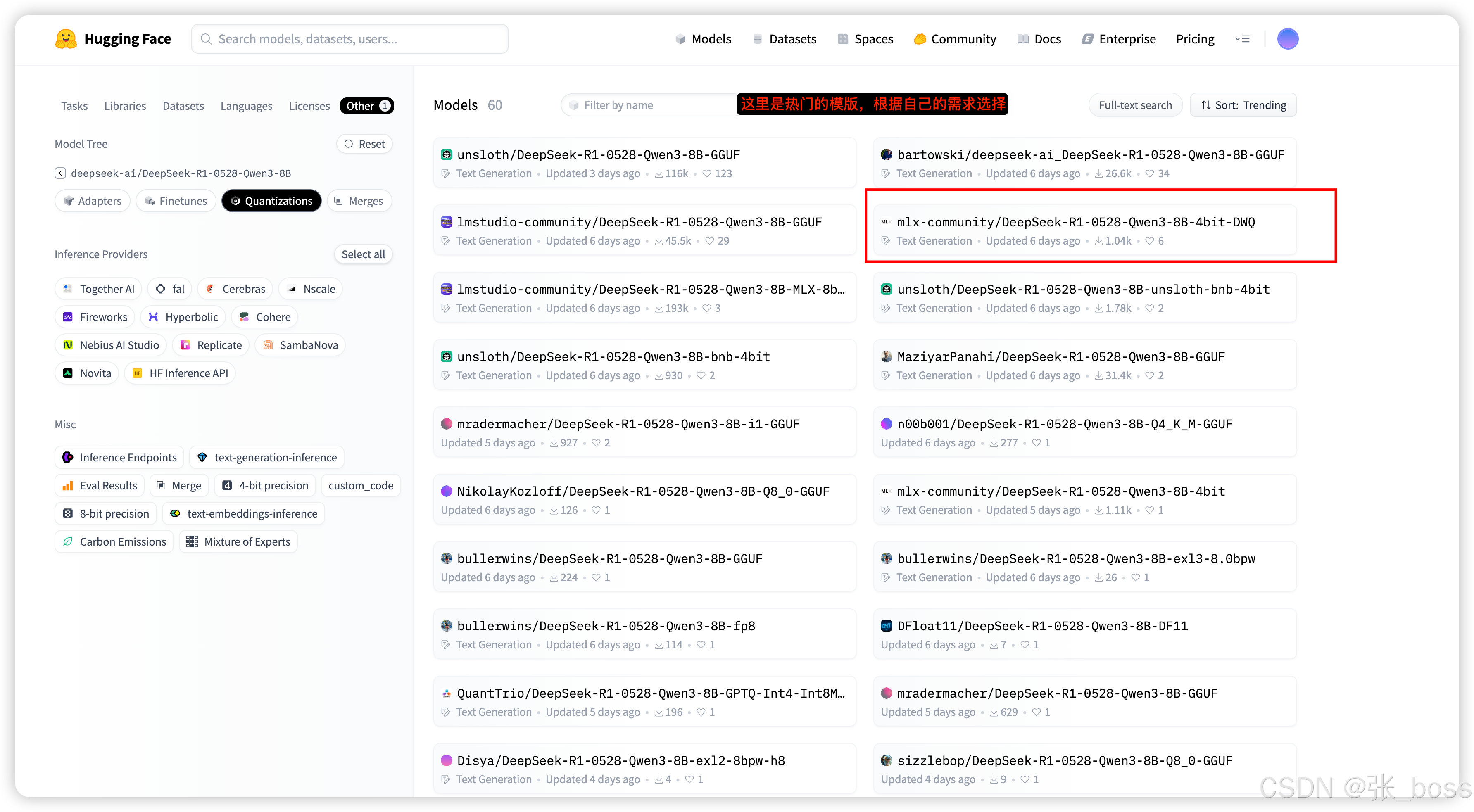
选择文件版本
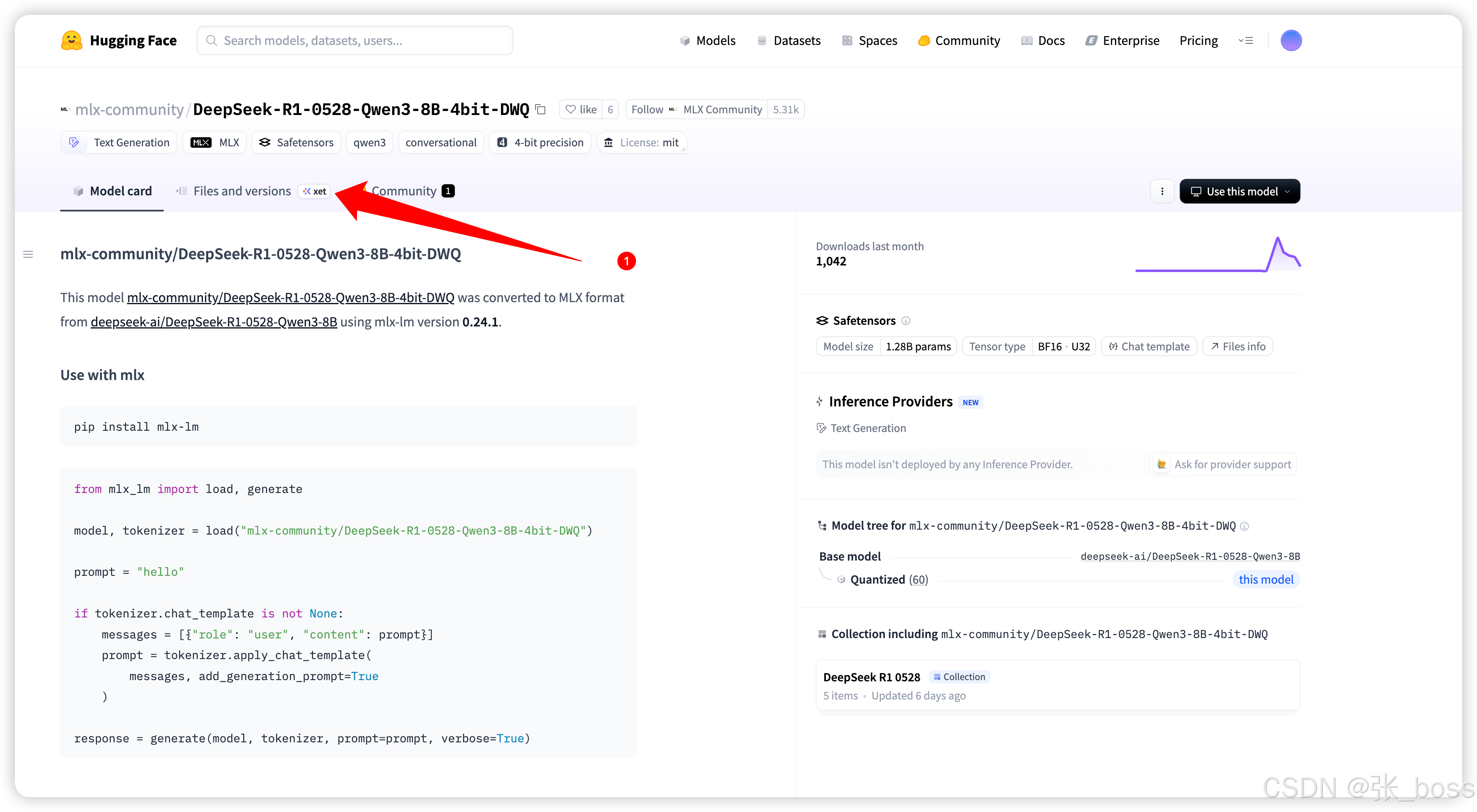
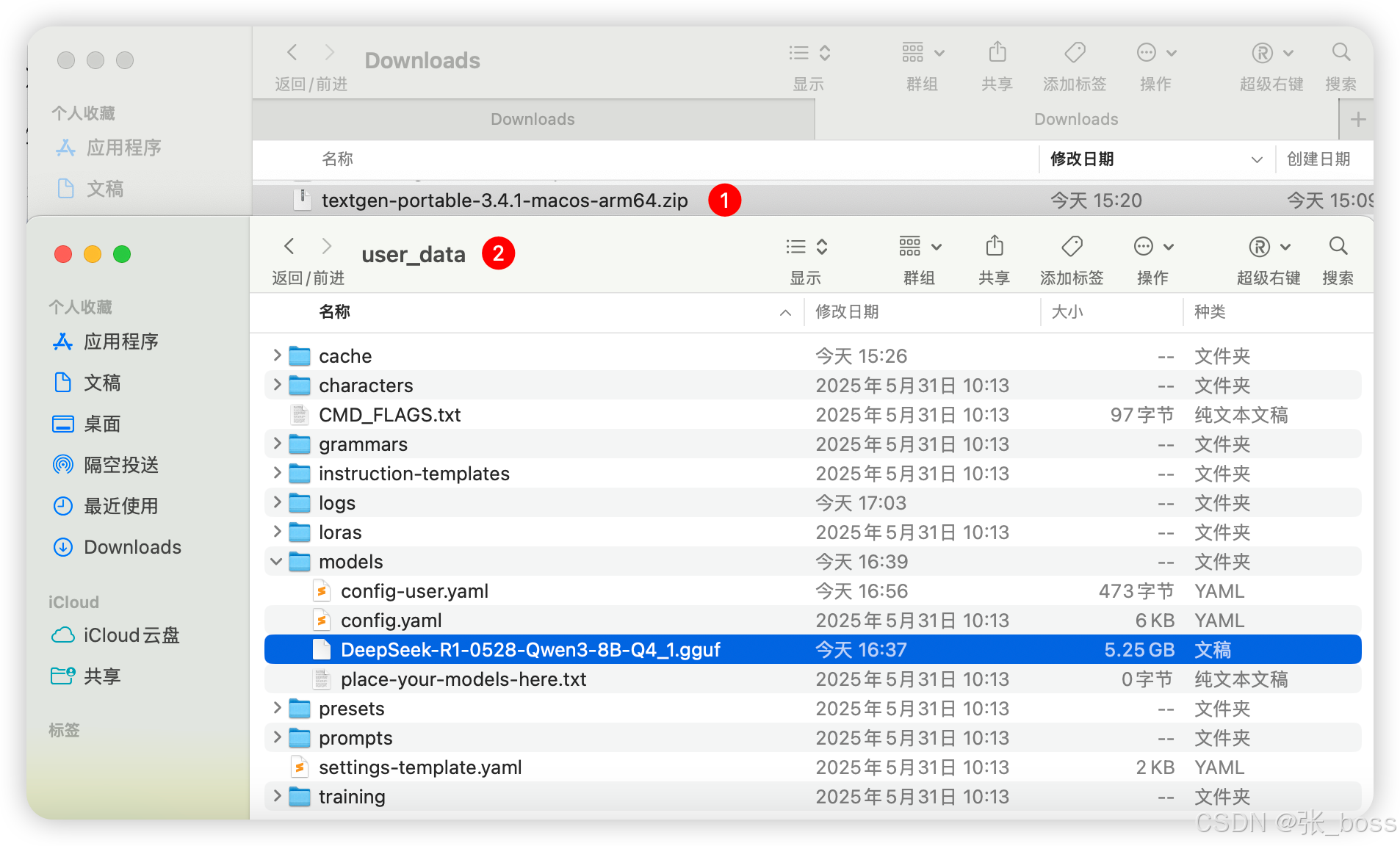
下载
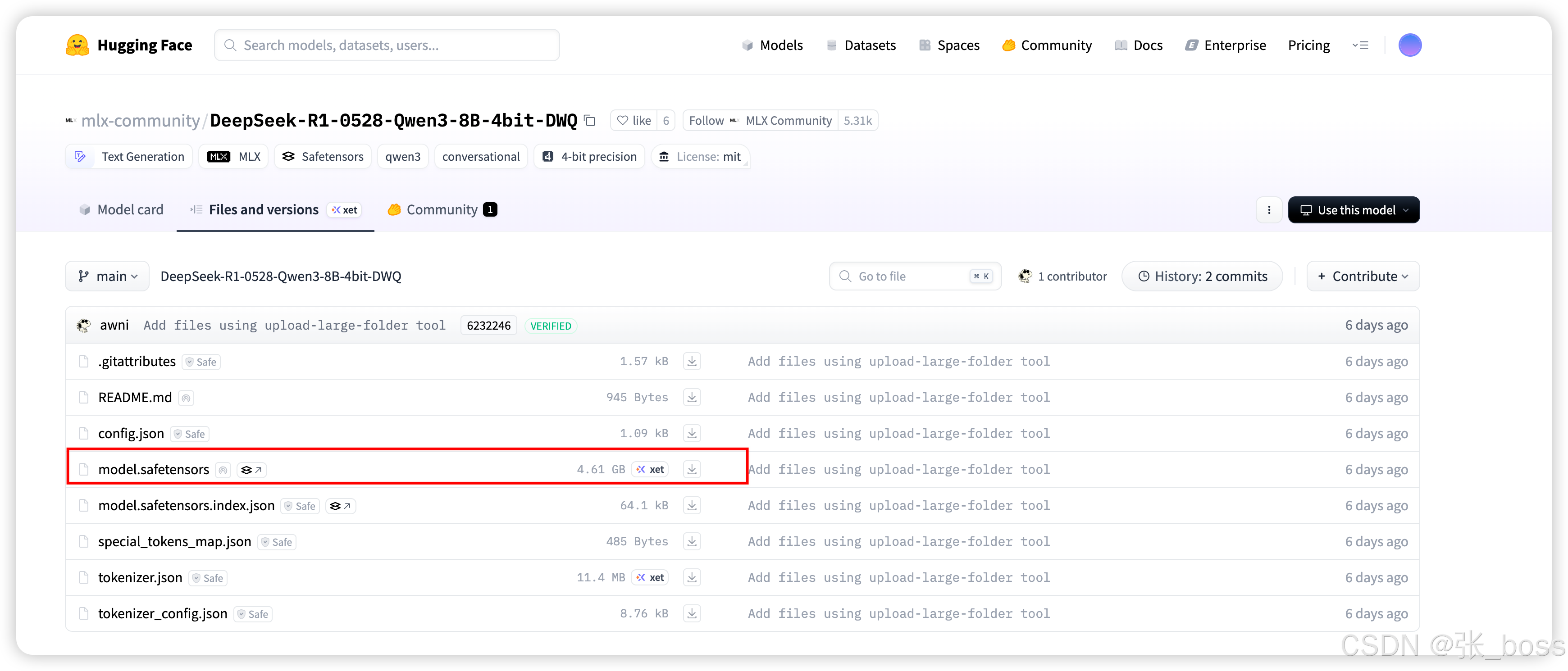
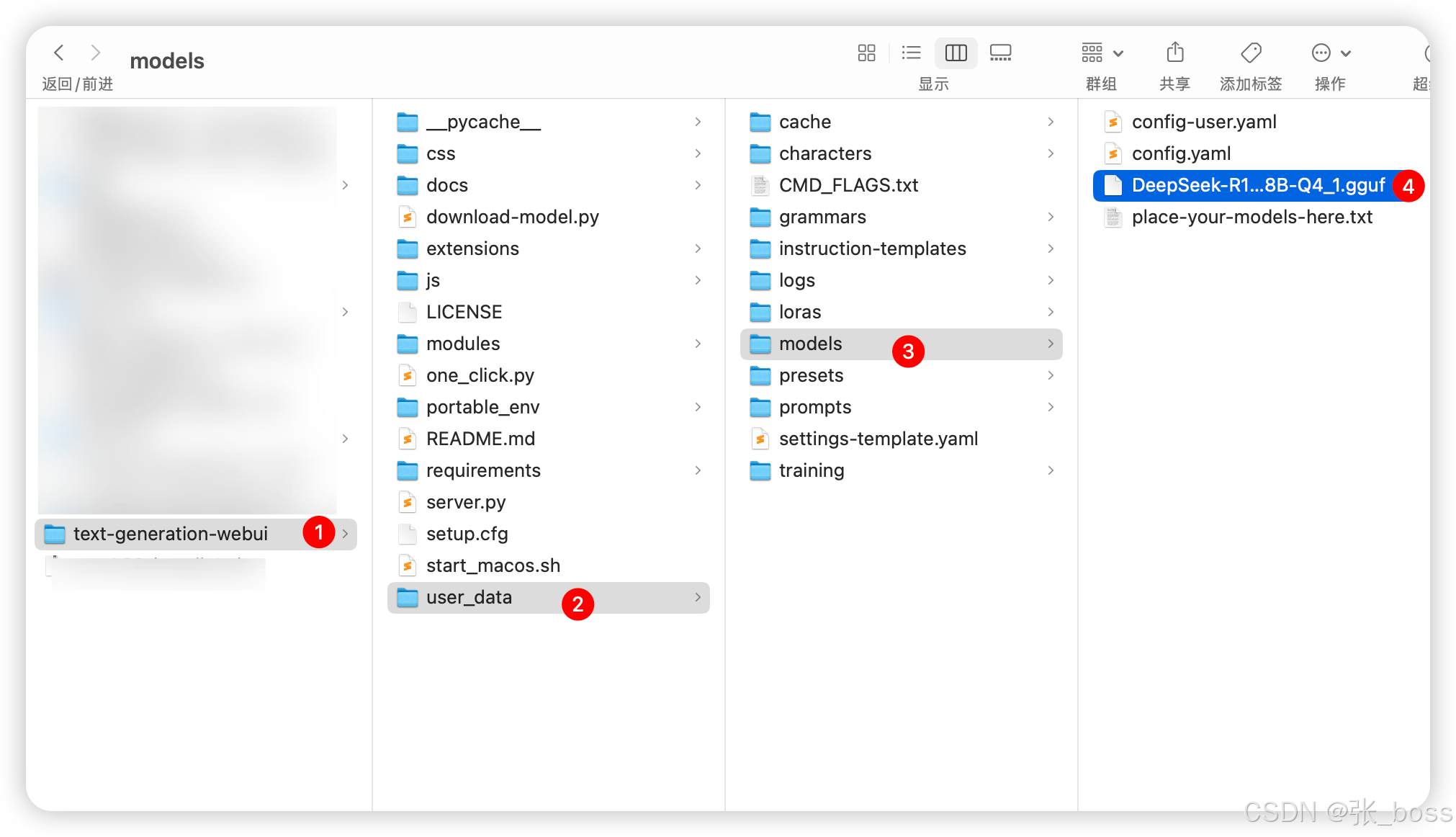
将下载好的模型放到指定文件夹 (放错了不生效)
这里的文件夹就是前面 ZIP 解压出来的文件
#启动 通过终端启动
➜ /Users/dw.zhang/Desktop/text-generation-webui
#表示text-generation-webui 文件在/Users:用户名:dw.zhang 桌面:Desktop的桌面
➜ text-generation-webui ./start_macos.sh
# ./start_macos.sh 表示启动
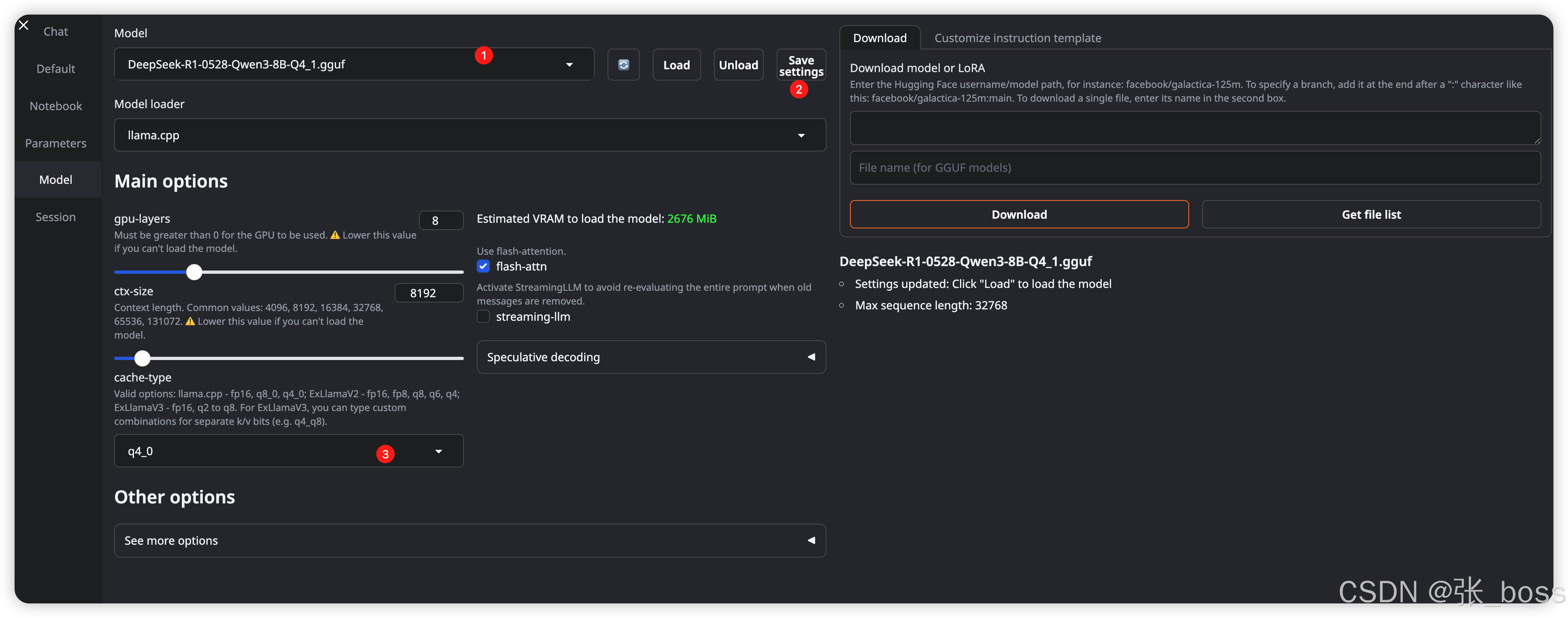
配置Mode(模型)
-
选择我们下载好的模型保存
-
cache-type 选择模型对应的版本
3.Chat
这个自定义配置
配置完后重启服务就完成了,愉快的玩耍吧