扩展数据(Concatenate)组件研究
版本:Orange3.38.1
作者:erichoo
时间:2025.5.31 10:00-2025.6.2 16:00
地点:重庆市江津区
文章目录
- 1 背景知识
- 2 功能详解
- 3 实例
- 3.1 辅数据-全变量
- 3.2 辅数据-交变量
- 3.3 主数据-列覆盖
- 3.4 主数据-非覆盖
- 4 总结
1 背景知识
数据挖掘过程中,准备样本数据是第一个难点。有时候,我们面临的难点是要素不够,这就需要横向整合多个数据来源,采用拼接的模式充分增强数据维度,Orange软件的合并数据(Merge Data)组件具备此功能;有时候,我们面临的难点是样本量不够,这就需要纵向整合多个数据来源,采用扩展的模式充分增强实例数量,本节研究的扩展数据(Concatenate)组件具备此功能。
总结来看,扩展数据组件主要应用于以下场景:
- 分段整合
即按时间维度整合历史数据,形成时序完整的数据集。例如电商平台每日生成订单日志(包括订单 ID、用户 ID、金额、时间等变量),如果需要分析月度销售情况,那么需要整合该月度内所有交易日的订单日志。分段整合场景的典型特征是多段同构,即样本的结构相同但所属时间段不同。 - 分组整合
即按业务特征整合多源数据,形成业务完整的数据集。例如零售集团旗下拥有高端品牌、大众品牌、折扣品牌 ,各品牌有各自独立的门店系统,如果需要综合分析零售集团的客户特征,那么需要整合所有品牌的客户数据。分组整合场景的典型特征是多组同构,即样本的结构相同但业务特征不同。 - 多端整合
即按应用终端整合移动端、PC端,形成终端完整的数据集。例如社交平台公司同时拥有 iOS 端、Android 端和 PC 端的登录日志,如果需要分析跨设备登录规律(如 用户在手机端晨练时登录,PC 端办公时再次登录的场景),那么就需要整合所有终端的登录样本。多端整合的典型特征是多端同构,即样本的结构相同但采集来源不同。
2 功能详解
Orange软件的Concatenate组件,具备主数据、辅数据两种应用模式。主数据模式的激活,需要设置主数据,此时输出样本变量将以主数据为准;辅数据模式在未设置主数据时自动激活,此时输出样本变量可以选择辅数据变量的交集或者并集。
需要注意的是,Merge Data组件只支持两个输入数据集(Data与ExtraData),Concatenate组件可以支持多个输入数据集,辅数据(Additional Data)可以有多个,主数据(Primary Data)只能有一个。
扩展数据组件的功能配置界面如下图:
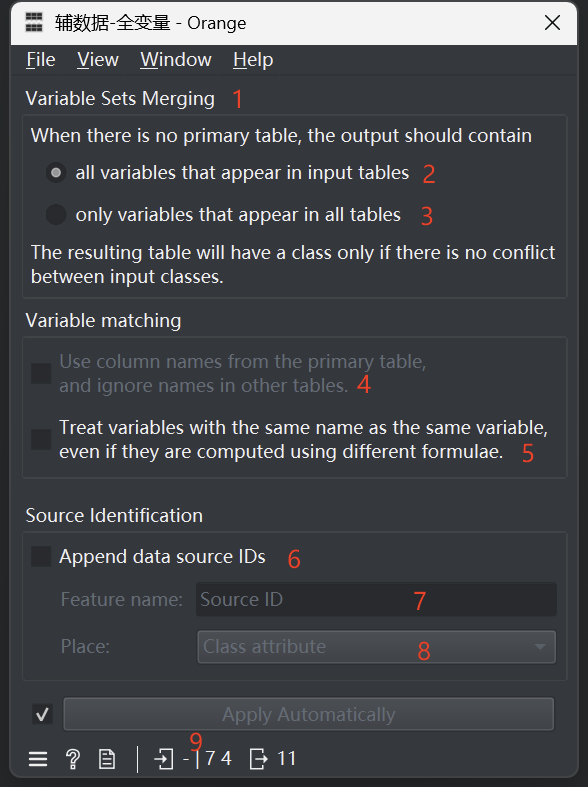
以下按照标红数字编号,依此介绍每一个组件功能:
- Variable Sets Merging
变量集合并。
此控件只在辅数据模式下可用,用于设置变量集合选择规则(并集/交集)。 - all variables that appear in input tables
并集。
输出数据集的变量为所有输入数据集变量的并集。 - only variables that appear in all tables
交集。
输出数据集的变量为所有输入数据集变量的交集。 - Use column names from the primary table, and ignore names in other tables.
主数据列名为准。
此控件只在主数据模式下可用。如果选中,那么所有辅助数据集按照列位置认定变量名称;如果不选中,那么所有辅助数据集按照列名称认定变量名称,名称不一致者值为缺失。 - Treat variables with the same name as the same variable, even if they are computed using different formulae.
忽略计算函数。
如果选中,那么同名称的变量只取值而忽略计算函数;否则,名称相同但计算函数不同的变量将被认定为不同变量。 - Append data source IDs
附加数据来源编号。
如果选中,则在输出数据集中增加一个变量,描述每一个样本的数据源。 - Feature name
如果子控件6选中,则此处可以设置数据源变量的名称。 - Place
变量位置。
如果子控件6选中,则此处可以设置数据源变量的类型,包括Class、Attribute、Meta三类,分别代表分类属性、一般属性、元属性。 - 输入数据集概况
通过竖线分割的两段,来描述输入数据集,前段表示主数据,后段表示辅数据。例如“- | 7 4” 表示输入主数据未设置、第一个辅数据包括7个实例、第二个辅数据包括4个实例;又如“1 | 3 5” 表示输入主数据包含1个实例、第一个辅数据包括3个实例、第二个辅数据包括5个实例。鼠标停留后,会显示每一个输入数据集的详情。
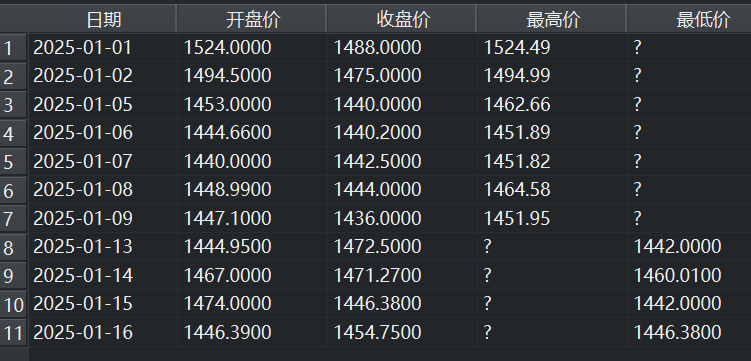
3 实例
本实例以股价数据为例,展示分段数据整合的场景,并尽量覆盖Concatenate组件的主要功能。ows文件如下图所示:
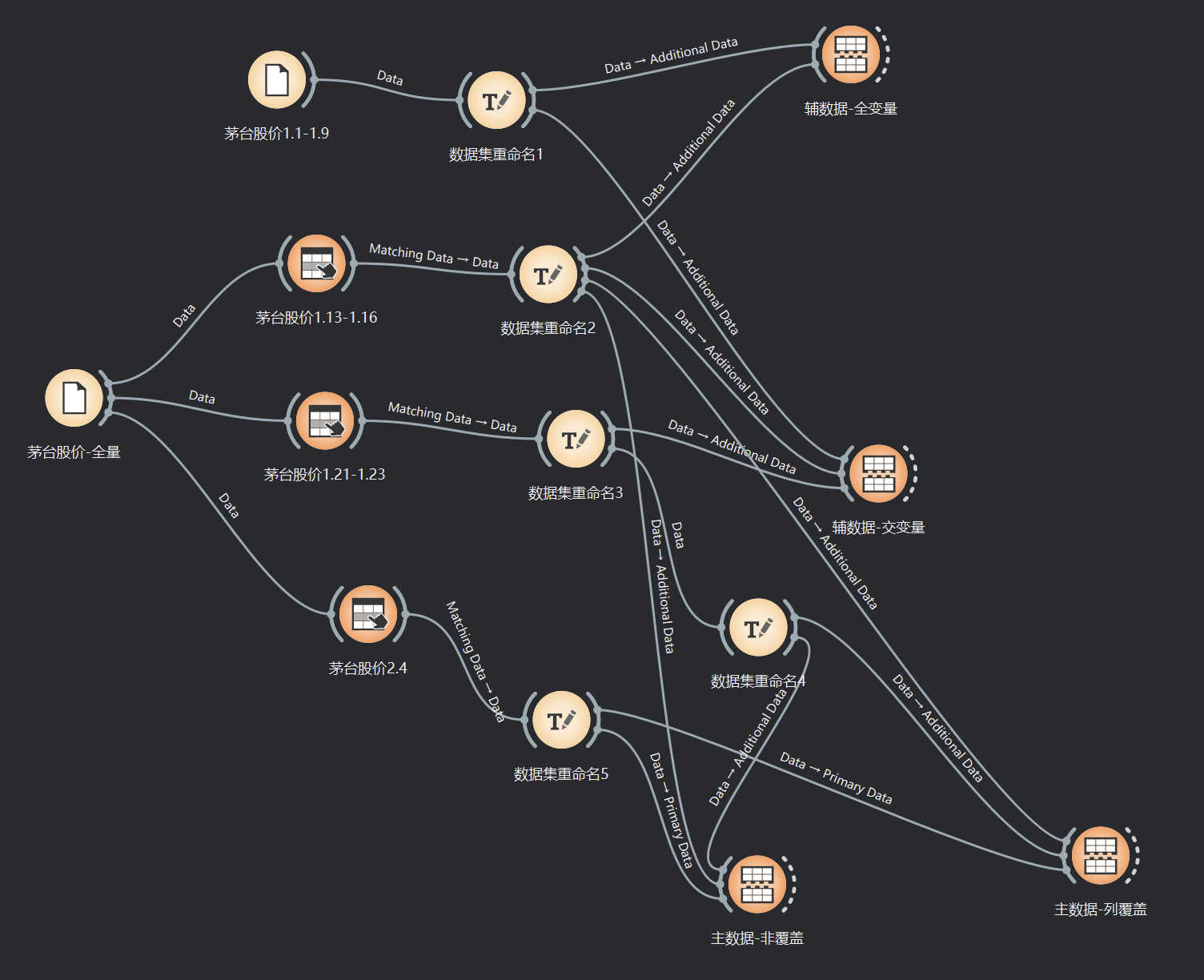
该实例通过数据集重命名1-5组件,确定了五个不同时间段的数据集gzmt1-5,各数据集截图如下。
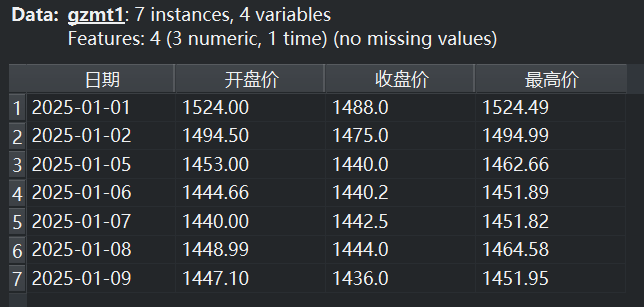 | 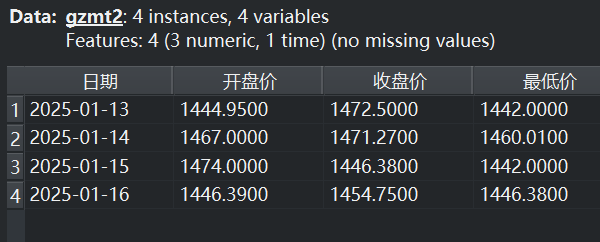 |
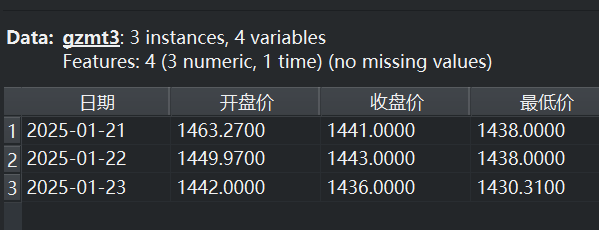 | 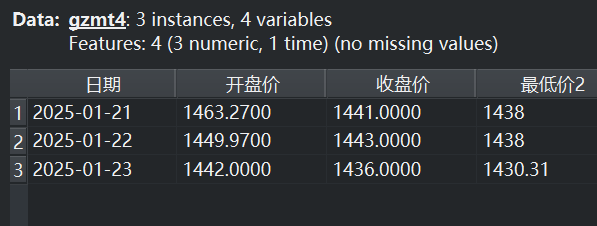 |
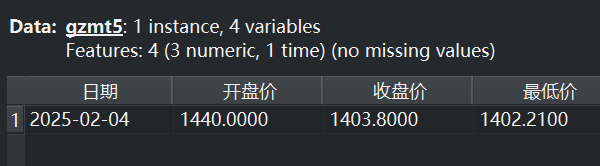 |
3.1 辅数据-全变量
组件配置如下图:
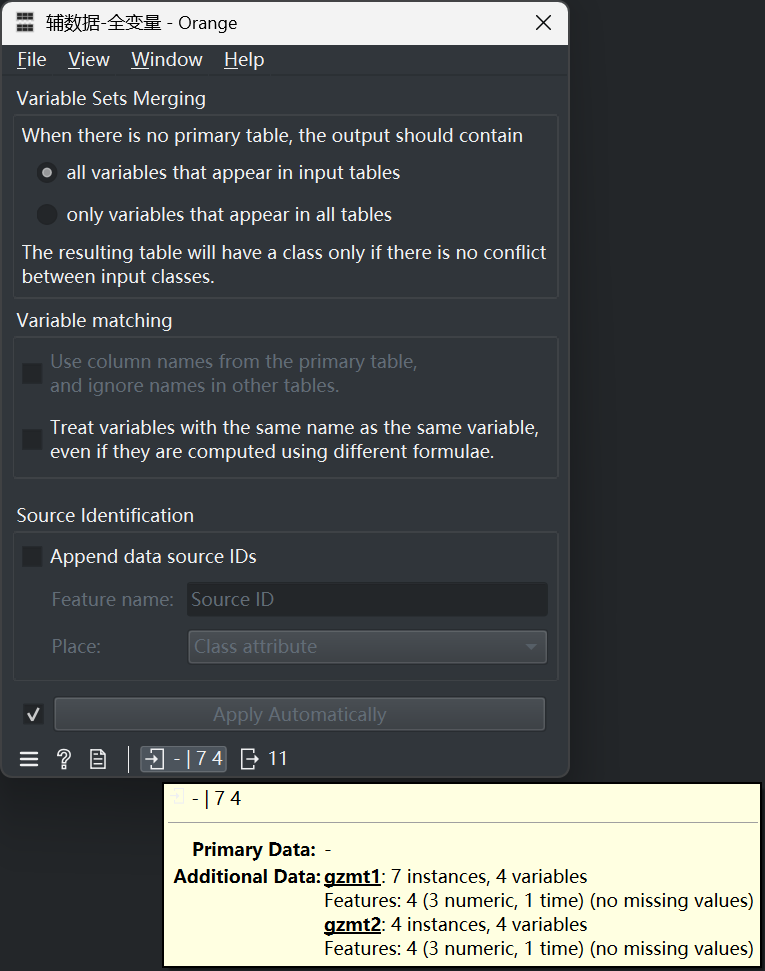
从上图中可以看出,输入数据集中,无主数据,有两个辅数据(gzmt1和gzmt2);选中了辅数据的并集模式(all variables that appear in input tables);未选择附加数据源(Append data source IDs)。这种配置下,得到的输出数据集如下:
从变量集合来看,的确取到了输入数据集的并集,所有输入数据集的独有部分全部涵盖。
3.2 辅数据-交变量
组件配置如下图:
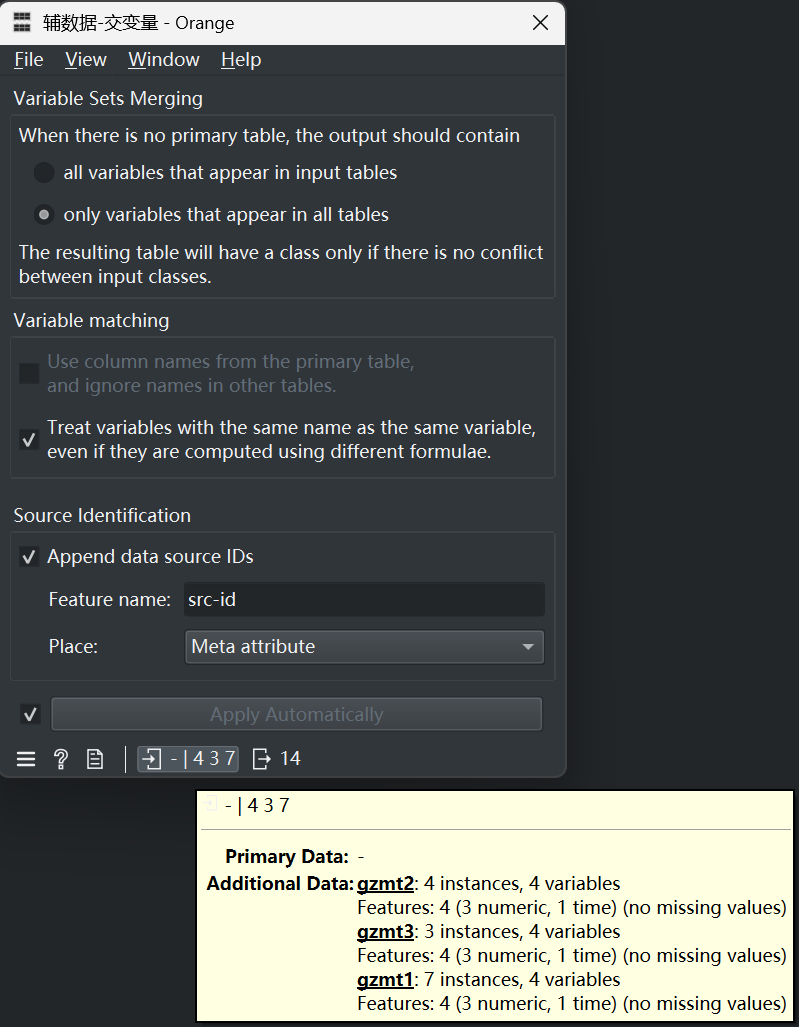
从上图中可以看出,输入数据集中,无主数据,有三个辅数据(gzmt1、gzmt2、gzmt3);选中了辅数据的交集模式(only variables that appear in all tables);选中了附加数据源(Append data source IDs),并命名该变量为“src-id”,类型选择为Meta。这种配置下,得到的输出数据集如下:
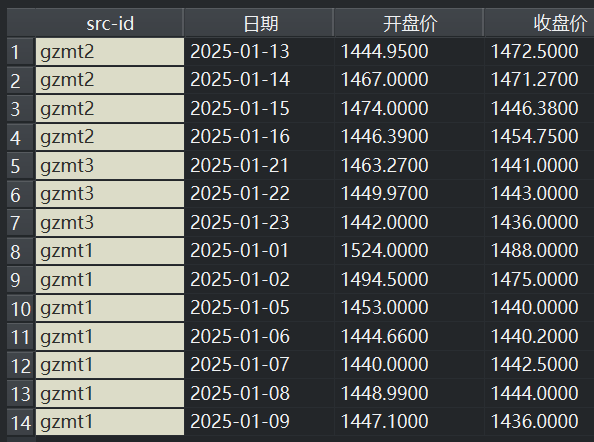
从变量集合来看,的确取到了所有输入数据集的公有部分,所有输入数据集的独有部分全部丢弃,增加了变量“src-id”,其值为输入数据集名称。
3.3 主数据-列覆盖
组件配置如下图:
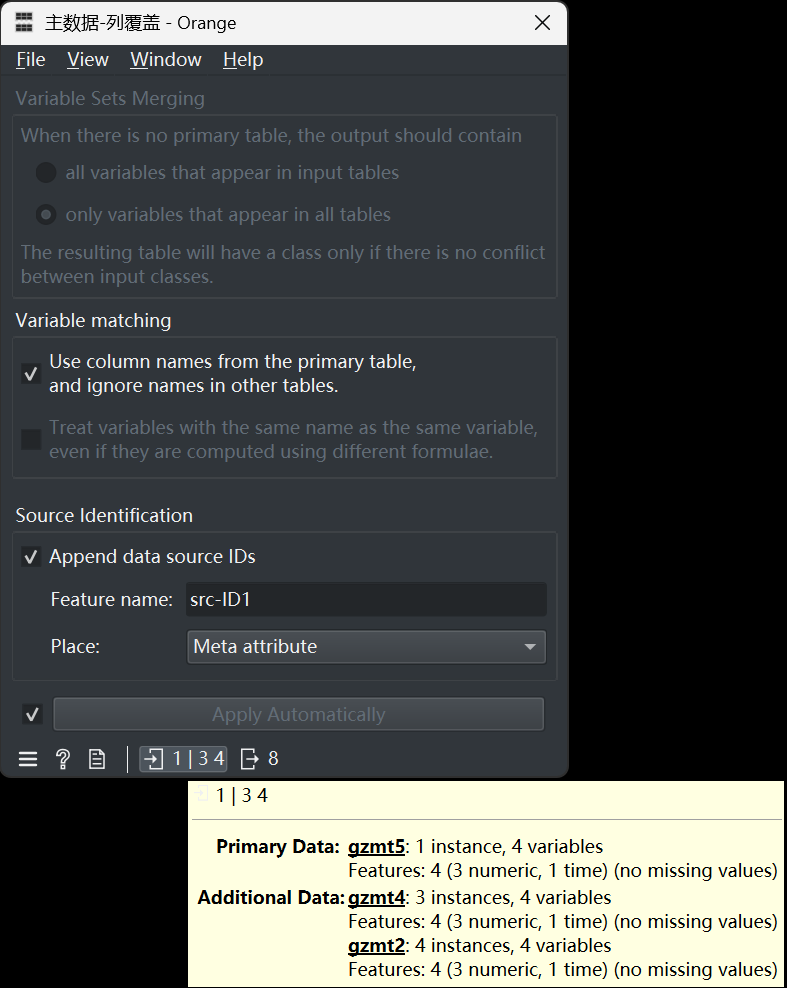
从上图中可以看出,输入数据集中,有主数据(gzmt5),有两个辅数据(gzmt2、gzmt4);选中了主数据列名为准(Use column names from the primary table, and ignore names in other tables.);选中了附加数据源(Append data source IDs),并命名该变量为“src-ID1”,类型选择为Meta。这种配置下,得到的输出数据集如下:
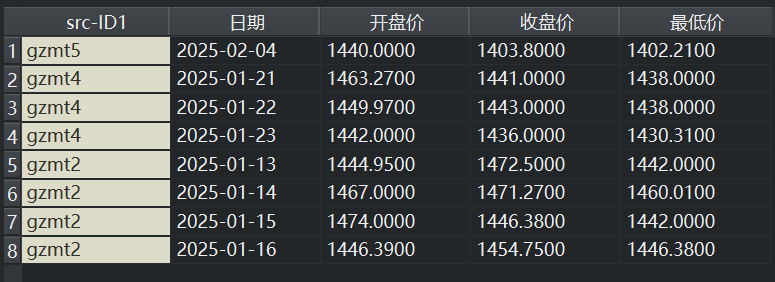 从上图可以看出,虽然输入辅数据gzmt4独有“最低价2”变量,但还是以主数据gzmt5的列名称为准,按照位置匹配了值,将“最低价2”变量的值赋给了“最低价”变量。
从上图可以看出,虽然输入辅数据gzmt4独有“最低价2”变量,但还是以主数据gzmt5的列名称为准,按照位置匹配了值,将“最低价2”变量的值赋给了“最低价”变量。
3.4 主数据-非覆盖
组件配置如下图:
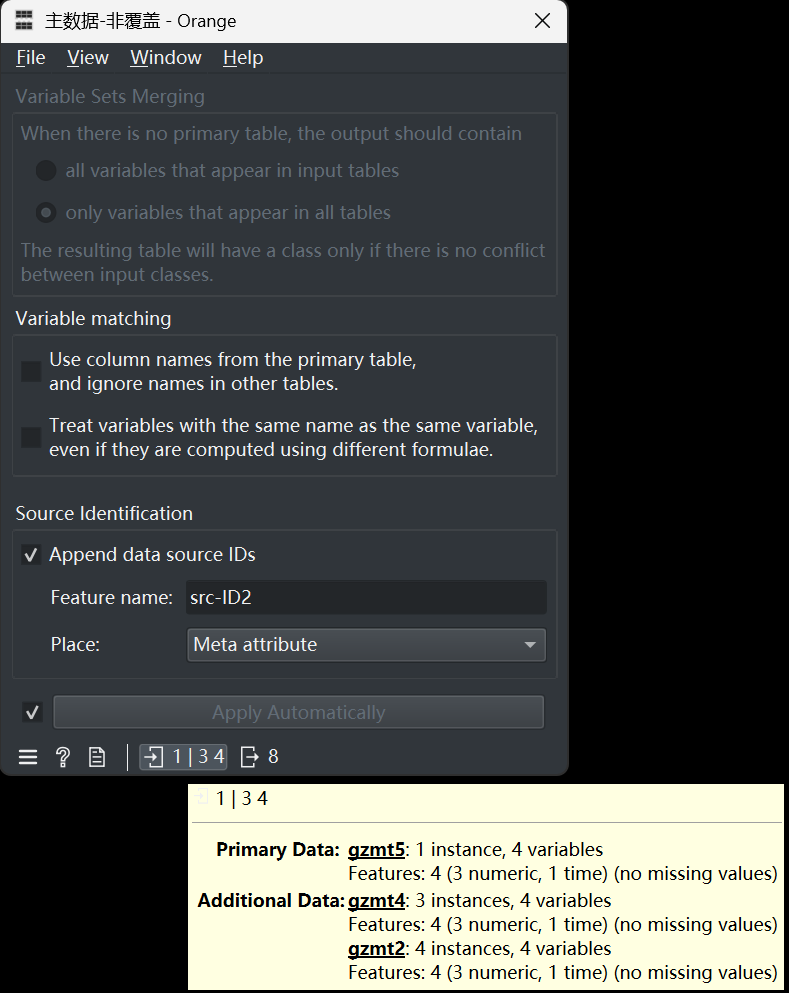
从上图中可以看出,输入数据集中,有主数据(gzmt5),有两个辅数据(gzmt2、gzmt4);未选中主数据列名为准(Use column names from the primary table, and ignore names in other tables.);选中了附加数据源(Append data source IDs),并命名该变量为“src-ID2”,类型选择为Meta。这种配置下,得到的输出数据集如下:
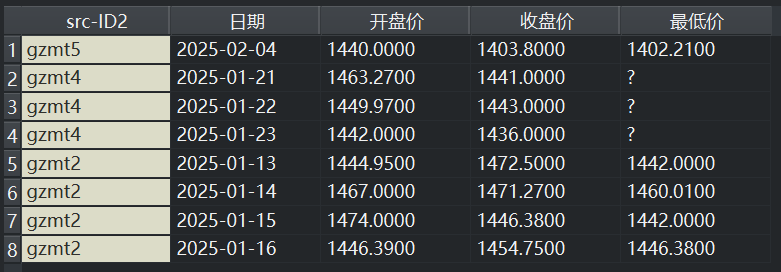
从上图可以看出,输入辅数据gzmt4独有“最低价2”变量未匹配主数据gzmt5的“最低价”变量,而是赋予了缺失值。
4 总结
本文聚焦 Orange软件的 Concatenate 组件,介绍其在数据挖掘中用于纵向整合数据、增强实例数量的功能,适用于分段、分组、多端等多源同构数据整合场景。该组件有主数据和辅数据两种模式,辅数据模式下可选择变量并集或交集,主数据模式下能按主数据列名或位置匹配变量,文中通过股价数据实例展示了不同配置下的输出效果。
示例ows文件已经传入gitee,路径地址为:
https://gitee.com/erichoocq/ai-erichoo-open/tree/master/Orange/samples
文件名称为:
test_concatenate.ows
参考数据的路径地址为:
https://gitee.com/erichoocq/ai-erichoo-open/tree/master/Orange/samples/data
文件名称为:
gzmt_SH600519.csv
guizhou_moutai_stock_data.csv