大模型微调(4):使用 AutoClass 管理 Tokenizer 和 Model
1. AutoClass API 简介
在上一篇文章中,我们介绍了 HuggingFace 及其 Pipeline API 的使用。Pipeline 是对底层模型的预训练、编解码、后处理等一系列流程的封装,并暴露了简洁的 API ,供用户高效实现模型的推理、微调等功能。延续之前的内容,本篇文章我们进一步快速学习下另一组 API:AutoClass。
AutoClass 是 HuggingFace 提供的一组高级 API 对象,为用户提供了一种便捷的方式来加载各种预训练模型、分词器等核心组件,而无需手动指定具体的类名。
其核心就是下面两类组件:
- AutoModel:用于加载预训练的模型。通过
from_pretrained()方法,只需指定预训练模型的名称或路径,就能自动推断并加载相应的模型架构和权重。 - AutoTokenizer:用于加载预训练的分词器。它可以将文本转换为模型能够处理的格式,比如将文本分割成单词或词元,并转换为对应的数字表示。
特别注意:Model 要与 Tokenizer 一一对应,因为不同的模型可能使用了不同的分词器。
AutoClass 的最核心的优势,就是让用户可以更轻松地使用Hugging Face的各种预训练模型和相关工具,减少了代码量和开发时间,同时也提高了代码的可维护性和可读性。
2. 使用 AutoClass 管理 Tokenizer 和 Model
话不多说,我们现在就来演示下 AutoClass API 的用法。我们以 bert-base-chinese 这个模型为例,它是一个基于中文语料预训练好的 BERT 架构的模型,对中文有较强的理解能力。
2.1 加载模型与分词器
模型与分词器的加载非常简单,直接使用各自的 from_pretrained 方法即可。
from transformers import AutoTokenizer, AutoModel# 指定模型名称
model_name = "bert-base-chinese"# 使用AutoTokenizer加载tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name)# 使用AutoModel加载模型
# tokenizer与模型要一一对应,不同的模型可能使用不同的分词器
model = AutoModel.from_pretrained(model_name)这样我们就将 model 和 tokenizer 加载到本地了。
2.2 使用 Tokenizer 进行编解码
编码 (Encoding) 过程包含两个步骤:
- 分词:使用分词器按某种策略将文本切分为 tokens;
- 映射:将 tokens 转化为对应的 token_ids。
# Step1——分词: 将原始文本切分成tokens
sequence = "中国的首都是北京"
tokens = tokenizer.tokenize(sequence)
print(tokens)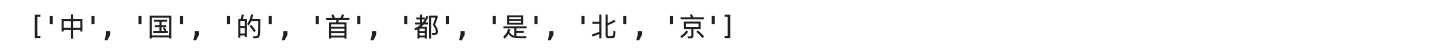
# Step2——映射: 将token转换成token_id
token_ids = tokenizer.convert_tokens_to_ids(tokens)
print(token_ids)
也可以使用 encode 方法,将上述的两个步骤合并成一步,完成端到端的处理:
# 直接使用encode方法,实现端到端的处理
token_ids_e2e = tokenizer.encode(sequence)
print(token_ids_e2e)
相信细心的你肯定已经发现了,encode 后的 token_ids,相较于之前,多了两个 101 和 102,这是什么鬼?我们再使用 decode 方法解码回去看看:
tokenizer.decode(token_ids_e2e)
原来,101 和 102 这个两个 token,分别对应的是 [CLS] 和 [SEP],这是 BERT 在预训练时就定义好的 special token。[CLS] 用于表示一个句子的开头;而 [SEP] 则代表了不同句子之间的分隔符。
因为 bert-base-chinese 这个模型也是基于 BERT 架构的,因此与沿用了 BERT tokenizer 的设计。
为了更直观地展示 special token 的作用,我们对多段文本进行编码:
# 对多段文本进行encoding
# tokenizer实现了__call__,可以直接进调用,一步完成文本编码+特殊编码补全
embedding_batch = tokenizer("中国的首都是北京", "清华大学坐落在北京")# 结构化输出编码结果
for key, value in embedding_batch.items():print(f"{key}: {value}\n")结果如下:
可以看到,当一次处理多段文本时, [SEP] 的作用就体现出来了,它可以对不同的 sentence 进行分隔。

这里还有几个需要理解的关键参数:
- input_ids: 即编码后的 token_ids 列表。
- token_type_ids: 标识了 token_id 所归属的句子编号,从 0 开始计数。在本例中,“中国”属于第一个句子,而“清华大学”属于第二个机制。
- attention_mask: 指示哪些token需要被关注,这也 transformer 模型的注意力机制有关。经过一段时间的训练后,self-attention机制会自动更新 attention_mask。
2.3 添加新 Token
除了使用分词器 vocab 当中已存在的 token 之外,我们还可以向其中添加自定义的 token,常用于模型微调的场景中。我们来具体看下。
首先查看下默认词表长度(token 数量):
len(tokenizer.vocab.keys())![]()
接着概览下词表的内容:
from itertools import islice# 使用 islice 查看词表部分内容
for key, value in islice(tokenizer.vocab.items(), 10):print(f"{key}: {value}")
下面,我们新增两个自定义的 token:"天安门"、"颐和园"。
new_tokens = ["天安门", "颐和园"]# 通过set的集合作差,确认token是否已存在
new_tokens = set(new_tokens) - set(tokenizer.vocab.keys())
print(new_tokens)
这里的一个最佳实践是:在添加新 token 前,可以先通过 set 的差集方法,校验下 token 是否已经存在了。
然后,我们就可以调用 add_tokens 方法添加新的 token。
tokenizer.add_tokens(list(new_tokens))
# 新增加了2个token,词表总数由 21128 增加到 21130
len(tokenizer.vocab.keys())添加了2个新 token 后,总数变成了 21130。

我们还可以添加新的 special token,但是该操作存在一定的风险,需要谨慎使用:
# 定义新的特殊token
new_special_token = {"sep_token": "NEW_SPECIAL_TOKEN"}# 添加新的special token
tokenizer.add_special_tokens(new_special_token)# 新增加了1个special token,词表总数增加到 21131
len(tokenizer.vocab.keys())
3. 分词器与模型文件概览
对 tokenizer 和 model 进行了自定义的微调后,我们就可以通过 save_pretrained 方法,将最新的分词器和模型保存到本地。
# 将Tokenizer模型保存到本地
tokenizer.save_pretrained("./models/new-bert-base-chinese")# 将模型保存到本地
model.save_pretrained("./models/new-bert-base-chinese")
我们可以大致过一下这些文件的内容。
3.1 Tokenizer 核心文件
tokenizer.json
Tokenizer 的元数据文件,记录了分词器的核心属性配置

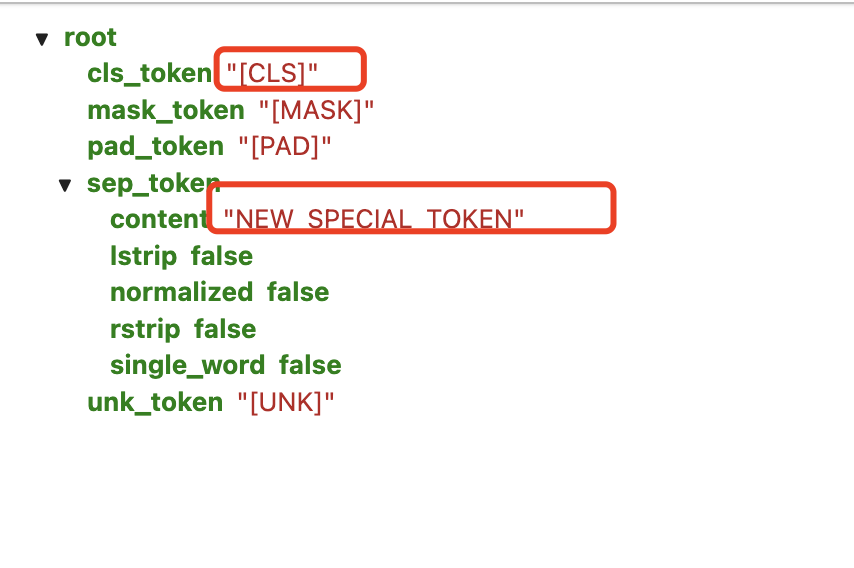
special_tokens_map.json
特殊 token 映射关系配置文件,我们前面所说的 [CLS] 和 [SEP] 就是在这里定义的。
tokenizer_config.json
Tokenizer 基础配置文件,存储构建 Tokenizer 需要的参数,如 Tokenizer 类型、模型最多长度等。

vocab.txt
词表文件,模型预训练时所有支持的 token 都在里面。

added_tokens.json
单独存放新增 tokens ,我们刚才手动添加的 token 就保存在这个文件里面。

3.2 Model 核心文件
说完了分词器相关的文件,最后我们再来看下模型的文件。
config.json
模型配置文件,存储模型的结构参数,如基础类型、Transformer 层数、特征空间维度等。
pytorch_model.bin
有时也称为 state dictionary,是模型最核心的二进制文件,存储了模型的所有权重参数。
如果模型底层是采用 PyTorch 框架训练,则通常保存为 pytorch_model.bin 格式;否则,如果采用 TensorFlow 框架,则大多为 model.safetensors 格式。