【C++初阶】模拟实现string(二):swap优化与写时拷贝机制
文章目录
- 前言
- 一、swap
- 1.1 算法库中的swap
- 1.2 string的成员函数swap
- 1.3 string 全局的swap
- 二、拷贝构造和赋值的简洁写法
- 2.1 拷贝构造
- 2.2 赋值
- 三、写时拷贝
- 3.1 引用计数
- 3.2 写时拷贝
- 四、编码
前言
我们之前模拟实现了 string类的一些常用接口,今天我们将继续看看 string 背后的一些实现细节,比如 swap 的不同写法、拷贝构造与赋值运算符的简洁实现,以及“写时拷贝”的相关概念。
一、swap
在学习string的过程中,我们发现:
string既自己实现了一个swap

又在全局实现了一个swap
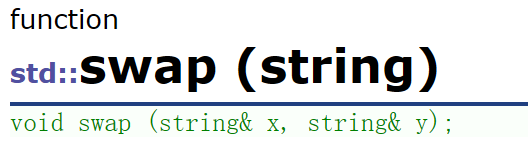
算法库中还有一个swap

我们有一个疑惑,为什么要搞这么多swap呢?
1.1 算法库中的swap
我们先看一看算法库中的swap

然后写一个代码测试一下:
void test1()
{zhangsan::string s1("hello world");zhangsan::string s2("xxxxxxxxxxxxxxxxxxxxx");//swap(s1, s2);s1.swap(s2);cout << s1 << endl;cout << s2 << endl;
}
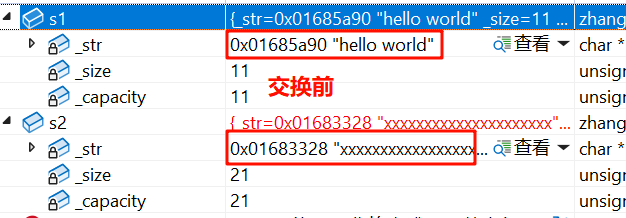
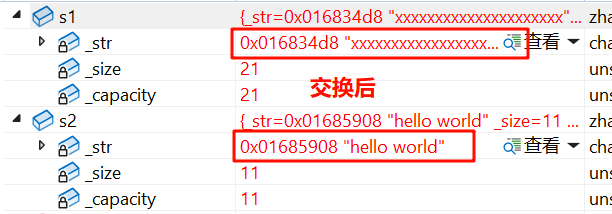
我们发现,使用算法库中的 swap ,交换前的地址和交换后的地址均不相同,说明开了新空间
简单分析一下:
如果我们用的是算法库中的swap函数来交换 s1,s2 这两个string对象,那么需要
1)先用 s1 构造一个 c,让 c 开一个和 s1 一样大的空间
2)然后让 s2 赋值给 s1:让 s1 释放旧空间,并开一个和 s2 一样大的空间
3)最后让 c 赋值给s2 :让 s2 释放旧空间,并开一个和 c 一样大的空间
4)最后出作用域,c 会析构,释放空间
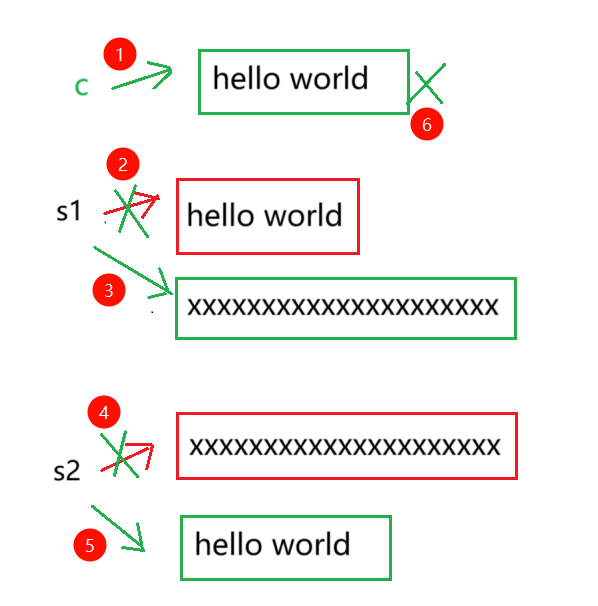
使用这个swap,我们申请了三次空间,释放了三次空间,这样的代价是很大的
1.2 string的成员函数swap
实际上,交换两个string对象不需要这么复杂,我们只需要将两个string对象的字符指针交换,_size 和 _capacity交换
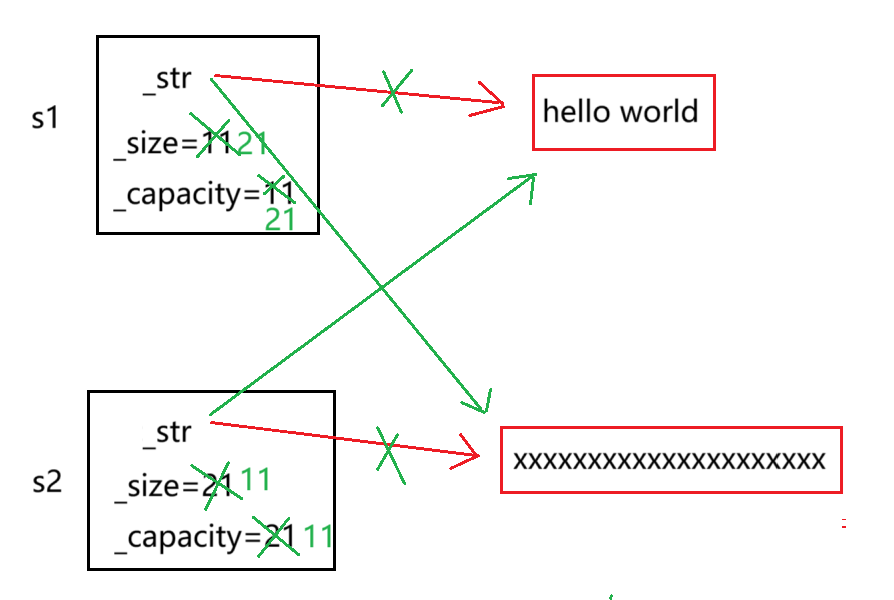
我们可以自己试着实现一个string 成员函数的 swap:
void swap(string& s)
{//交换内置类型调用算法库中的swap即可std::swap(_str, s._str);std::swap(_size, s._size);std::swap(_capacity, s._capacity);
}
细节:
如果直接写swap 默认会优先调用我们自己写的swap,即zhangsan这个命名空间的swap,所以我们需要指定命名空间std,调用算法库中的swap
再测试一下:
void test1()
{zhangsan::string s1("hello world");zhangsan::string s2("xxxxxxxxxxxxxxxxxxxxx");//swap(s1, s2);s1.swap(s2);cout << s1 << endl;cout << s2 << endl;
}
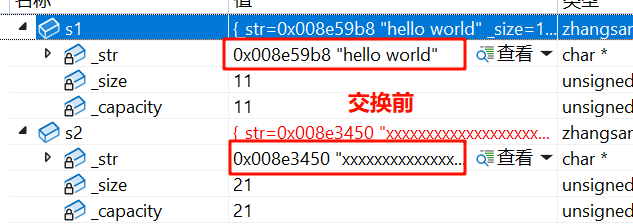
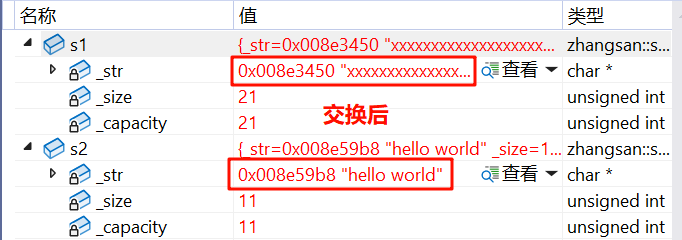
我们发现 swap 交换前后地址没变,说明并没有开新空间,只是交换了指针
总结: 使用算法库中的swap交换 string对象 代价大,使用string成员函数中的swap 代价小
1.3 string 全局的swap
我们现在已经了解了算法库中的swap和string成员函数中的swap的差异,但是string在全局还有一个 swap,这个swap设计出来又有什么意义呢?
//string全局的swap
void swap(string& s1, string& s2)
{s1.swap(s2);
}
string全局的swap其实是对成员函数的封装,是普通函数,而算法库中的swap是函数模版。
我们之前学过,如果既写了函数模版,又写了普通函数,如果传的参数和普通函数的参数类型匹配,编译器会优先调用普通函数。
也就是说string实现全局的swap后,无论我们是通过 对象.swap的方式调用成员函数的swap,还是直接调用swap函数,都不会调用算法库中的swap
补充说明一下:
C++11提供的右值引用和移动语义后,即使string不提供全局的swap,也不会调用算法库中的swap,而是调用string成员函数中深拷贝的swap

二、拷贝构造和赋值的简洁写法
传统写法和简洁写法没有效率的提升,只是简洁一点,本质是复用
2.1 拷贝构造
string 拷贝构造的传统写法:
传统写法是自己开空间,自己拷贝数据
//s2(s1)
string(const string& s)
{_str = new char[s._capacity + 1];strcpy(_str, s._str);_size = s._size;_capacity = s._capacity;
}
string 拷贝构造的简洁写法:
//s2(s1)
string(const string& s)
{string tmp(s._str);swap(tmp);
}
先用 s1 的 _str 构造一个 tmp 对象,再让 s2 和 tmp 交换

2.2 赋值
string赋值运算符重载的传统写法:
// s1 = s3
string& operator=(const string& s)
{if (this != &s) // 防止出现自己给自己赋值的情况{delete[] _str;_str = new char[s._capacity + 1];strcpy(_str, s._str);_capacity = s._capacity;_size = s._size;}return *this;
}
string赋值运算符重载的简洁写法:
// s1 = s3
string& operator=(const string& s)
{if (this != &s) // 防止出现自己给自己赋值的情况{string tmp(s._str);swap(tmp);}return *this;
}
先用 s3 的 _str 构造一个 tmp,再让 s1 和 tmp 交换。传统写法中,我们需要手动释放s1的空间,但在现代写法中,由于tmp是局部变量,出作用域就调用析构函数,相当于把之前s1的空间销毁了。
这个写法还可以进一步改进:
//s1 = s3
string& operator=(string s)
{swap(s);return *this;
}
直接传值传参,调用拷贝构造,让 s 和 s3 有一样大的空间和一样的值,然后让 this 指向的对象和 s 进行交换
三、写时拷贝
先看一个场景:
s2(s1),用 s1 拷贝构造 s2,使用的是深拷贝,但是可能过一会其中一个就要销毁,我们觉得代价太大了,但是如果使用浅拷贝,会有两个问题 1.会析构两次 2.如果修改了其中一个,另一个也会修改。我们可以利用引用计数和写时拷贝解决这个两个问题
3.1 引用计数
引用计数就是在s1指向这块空间的时候,额外开辟一块空间,这个空间存储一个整型值,这个整型值叫引用计数。引用计数是来记录有多少个对象指向这块空间,析构的时候就 --引用计数 ,当减到0 就释放 s1 指向的这块空间。

通过引用计数,解决了多个对象指向同一块空间,析构多次的问题
3.2 写时拷贝
写时拷贝是在浅拷贝的基础上增加了引用计数的方式来实现的。写时拷贝可以解决使用浅拷贝的另一个问题,即如果修改了其中一个对象,其它的对象也会修改。
- 当只有一个对象指向这块空间的时候,修改这个对象就直接在这块空间修改
- 如果有多个对象指向这块空间,那么哪个对象要修改的时候,哪个对象就进行深拷贝,并且引用计数–
举个例子:
s2(s1) ,假如我们现在要把s1下标为0对应位置的字符改为字符 x

写时拷贝就是谁写谁进行深拷贝
如果想了解更多关于写时拷贝的知识,可以看下面两篇大佬写的文章
https://coolshell.cn/articles/1443.html
https://coolshell.cn/articles/12199.html
四、编码
我们之前在string的基本介绍和使用中中提到过string类是一个模版,原模版叫basic_string,除了有string外,C11还新增了u16string 和 u32string,也是字符数组,
- u16string:每个字符是16位的char,占两个字节
- u32string:每个字符是4个字节
由于这涉及到编码,所以我们简单学习一下编码相关的知识
编码:一些比特位的值 <-----映射-----> 文字符号
1)字符存储到计算机中,需要将字符对应的码值(整数)找出来。
比如 ‘a’
存储:‘a’ —> 码值97 —> 对应的二进制 ----> 存储
读取:对应的二进制 ----> 码值97 —> ‘a’ —> 显示
2)字符和码值的对应关系是通过字符编码表决定的(规定好的)

UTF-16、UTF-32和UTF-8
- UTF-16 :以两个字节为一个单位
- UTF-32 :以四个字节为一个单位
- UTF-8 :以一个字节为单位,是一种变长编码,兼容ASCII
除了 string、u16string 和 u32string 之外,标准库还提供了 wstring,它使用 wchar_t 作为字符类型。wchar_t 通常是 2 个字节
