谈谈对dubbo的广播机制的理解
目录
1、介绍
1.1、广播调用
1、工作原理
1.2、调用方式
1、@Reference 注解
2、XML 配置
3、全局配置
1.3、 广播机制的特性
2、重试机制
2.1、默认行为
2.2、自定义逻辑
1、在业务层封装重试逻辑
2、使用 @Reference
3、广播调用的实践
3.1、常用参数
1. XML 配置示例
2. 注解配置示例
3. 代码配置示例
3.2、集群策略
3.3、幂等性设计
1、原因
2、解决方案
4、使用场景
5、注意事项
前言
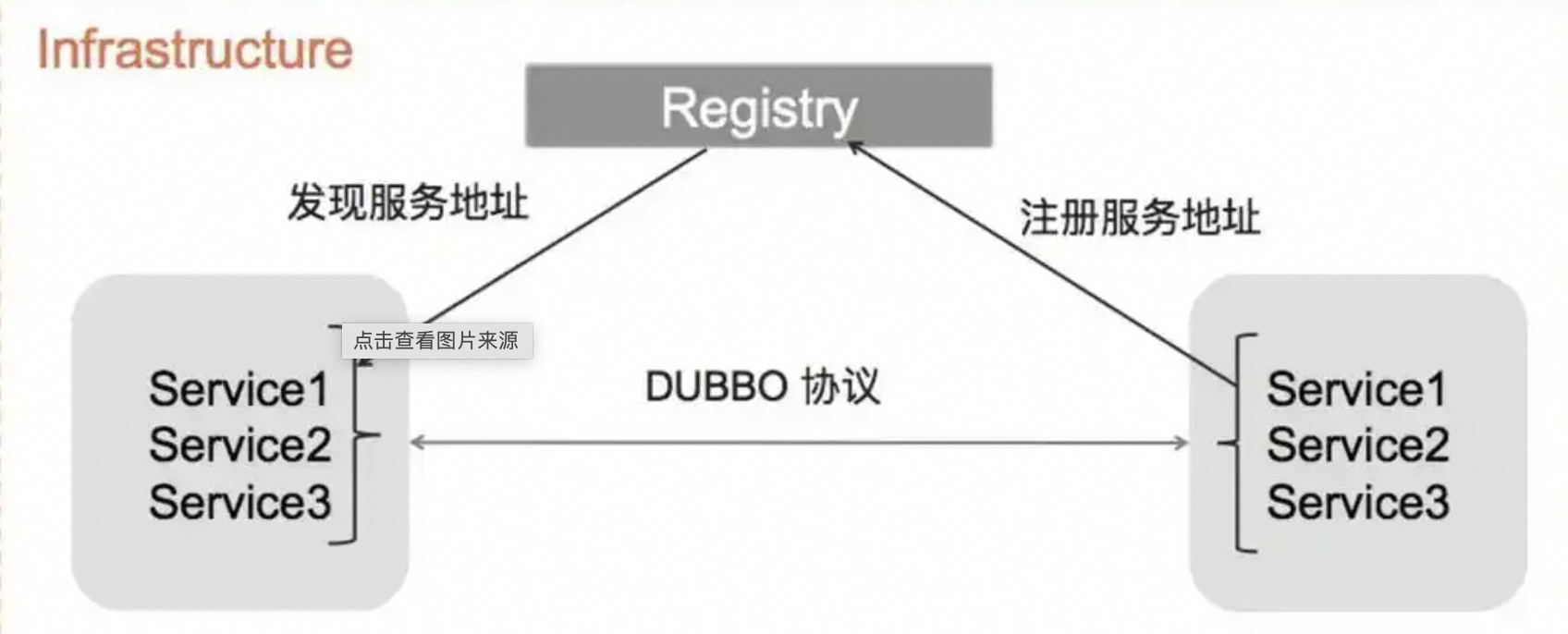
在dubbo中协议端口默认为20880,注册中心zookeeper默认端口为2181。
zookeeper类似于电话簿,dubbo类似于电话号码。
两者关系如下图所示:
在分布式系统中,服务的高可用性和容错能力是确保系统稳定性的重要因素。Dubbo 作为一个高性能的 RPC 框架,提供了多种集群容错策略,来应对分布式服务调用中的各种异常情况。
其中,Broadcast Cluster (广播集群) 是一种特殊的策略,它能够将请求广播给所有的服务提供者,并要求所有服务都必须成功执行。
关于更多dubbo的介绍:深入探讨dubbo组件的实践_dubbo 分层-CSDN博客
1、介绍
在 Apache Dubbo 中,广播调用(Broadcast) 是一种特殊的调用模式,它将请求发送到所有注册的服务提供者(Provider),每个提供者都会独立执行该调用。
这种模式常用于通知所有服务实例执行某些操作(如刷新缓存、更新配置等)。
以下是关于 Dubbo 广播调用中重试机制(retries 配置)的详细说明:
1.1、广播调用
广播调用(Broadcast) 是一种特殊的远程调用模式,其核心特点是:将请求发送到所有注册的服务提供者(Provider),每个提供者独立执行该调用。
1、工作原理
Broadcast(广播)集群容错策略在 Dubbo 中是指将请求广播给所有的服务提供者,并逐一调用它们。只有当所有的服务提供者都成功执行请求时,调用才被认为是成功的。
如果任何一个服务提供者执行失败,则整个调用会抛出异常。
具体的工作原理如下:
请求广播:
当服务消费者发起一个 RPC 请求时,Dubbo 会将这个请求广播到所有注册的服务提供者。
逐一调用:
每一个服务提供者都会接收到这个请求,并按照顺序执行请求中的操作。
返回结果:
如果所有的服务提供者都成功执行了请求,Dubbo 会返回成功的响应。如果有任何一个服务提供者执行失败,Dubbo 将抛出异常,并停止后续的调用。
这种策略确保了所有服务提供者的操作保持一致,适用于需要全局一致性的场景。
1.2、调用方式
1、@Reference 注解
通过
@Reference 注解的 cluster 属性设置为 boradcast。
代码示例:
@Reference(cluster = "broadcast", timeout = 3000)
private DemoService demoService;
2、XML 配置
代码示例:
<dubbo:reference id="demoService" interface="com.example.DemoService"cluster="broadcast"timeout="3000" />
-
行为特点:
- 请求会发送到所有服务提供者(Provider)。
- 每个 Provider 独立执行调用,互不干扰。
- 如果任何一个调用失败,Dubbo 会记录失败信息,但不会自动重试。
3、全局配置
可以通过全局配置dubbo.properties方式指定使用 Broadcast 策略:
dubbo.reference.cluster=broadcast
这种方式适用于需要全局统一使用 Broadcast 策略的场景。
1.3、 广播机制的特性
1.多实例并发调用
广播调用会将请求发送到所有注册的服务提供者(Provider),每个实例独立执行操作。
2.无顺序性
广播调用不保证执行顺序,多个实例可能同时处理同一请求。
3.无自动重试
Dubbo 默认不为广播调用的每个 Provider 提供重试机制,但业务层可能手动实现重试。
2、重试机制
2.1、默认行为
1、无自动重试:
Dubbo 的广播调用默认不支持自动重试。即使某个 Provider 调用失败(如网络异常),也不会对该 Provider 重新尝试调用。
2、失败处理策略:
广播调用的失败处理由 cluster 策略决定,默认是 failover(失败自动切换)或 failfast(快速失败)。但在广播模式下,cluster 配置被强制设置为 boradcast,因此失败处理策略被覆盖。
2.2、自定义逻辑
如果需要为广播调用的每个 Provider 添加重试机制,需要通过以下方式实现:
1、在业务层封装重试逻辑
public void broadcastWithRetry() {List<Invoker<DemoService>> invokers = registry.getInvokers();for (Invoker<DemoService> invoker : invokers) {int retries = 3;while (retries > 0) {try {invoker.invoke(new RpcInvocation("sayHello", new Object[] { "world" }));break; // 成功则跳出循环} catch (Exception e) {retries--;if (retries == 0) {// 记录失败日志或抛出异常log.error("Broadcast call failed after retries: {}", e.getMessage());}}}}
}
2、使用 @Reference
retries 参数(不推荐)。
限制:@Reference 的 retries 参数仅对单个调用生效,无法直接应用于广播调用。
替代方案:结合 retries 和自定义负载均衡策略,但需要谨慎处理。
3、广播调用的实践
3.1、常用参数
如下图所示:

1. XML 配置示例
1、服务提供者配置
<!-- dubbo.xml -->
<dubbo:service interface="com.example.DemoService"ref="demoServiceImpl"timeout="3000" <!-- 超时时间(毫秒) -->retries="2" <!-- 失败重试次数(仅在 cluster=failover 时生效) -->loadbalance="roundrobin" <!-- 负载均衡策略 -->cluster="failover" <!-- 集群容错策略 -->
/>
2、服务消费者配置
<!-- dubbo.xml -->
<dubbo:reference id="demoService"interface="com.example.DemoService"timeout="5000" <!-- 超时时间(毫秒) -->retries="1" <!-- 失败重试次数 -->loadbalance="random" <!-- 负载均衡策略 -->cluster="failfast" <!-- 集群容错策略 -->
/>
3、全局配置(默认值)
<!-- dubbo.xml -->
<dubbo:provider timeout="2000"retries="0"loadbalance="random"cluster="failover"
/>
<dubbo:consumer timeout="1000"retries="0"loadbalance="random"cluster="failover"
/>
2. 注解配置示例
1、服务提供者
@Service(timeout = 3000, retries = 2, loadbalance = "roundrobin", cluster = "failover")
public class DemoServiceImpl implements DemoService {@Overridepublic String sayHello(String name) {return "Hello, " + name;}
}
2、服务消费者
@Reference(timeout = 5000, retries = 1, loadbalance = "random", cluster = "failfast")
private DemoService demoService;
3. 代码配置示例
1、服务提供者
ServiceConfig<DemoService> service = new ServiceConfig<>();
service.setInterface(DemoService.class);
service.setRef(new DemoServiceImpl());
service.setTimeout(3000); // 超时时间
service.setRetries(2); // 重试次数
service.setLoadbalance("roundrobin"); // 负载均衡
service.setCluster("failover"); // 集群策略
service.export();
2、服务消费者
ReferenceConfig<DemoService> reference = new ReferenceConfig<>();
reference.setInterface(DemoService.class);
reference.setTimeout(5000); // 超时时间
reference.setRetries(1); // 重试次数
reference.setLoadbalance("random"); // 负载均衡
reference.setCluster("failfast"); // 集群策略
DemoService demoService = reference.get();
3.2、集群策略
超时时间单位:
timeout的单位是 毫秒(ms),需根据业务需求合理设置。
1、负载均衡策略:
random:随机选择(默认)。
roundrobin:轮询。
leastactive:最少活跃调用者优先。
consistenthash:一致性哈希(需额外配置)。
2、集群策略:
failover:失败自动切换(重试其他节点)。
failfast:快速失败(立即抛出异常)。
failsafe:失败安全(忽略异常,返回空结果)。
failback:失败自动恢复(异步重试)。
forking:并行调用多个节点(需配置 forks)。
3.3、幂等性设计
1、原因
1.网络不可靠导致请求重复
- 场景:消费者(Consumer)发送广播请求后,部分 Provider 因网络问题未收到响应,Consumer 可能重发请求。
- 问题:若接口非幂等,重复请求会导致重复操作(如多次写入数据库、多次触发任务)。
2.服务实例重启或故障恢复
- 场景:某个 Provider 在处理广播请求时发生故障,重启后可能重新处理未完成的请求。
- 问题:若接口非幂等,重启后重复执行可能导致数据不一致。
3.广播调用的重试逻辑
- 场景:业务层为广播调用添加重试逻辑(如失败后重试特定 Provider)。
- 问题:若接口非幂等,重试会导致重复操作。
4.多线程并发执行
- 场景:多个线程并发调用广播接口,或多个广播请求同时触发。
- 问题:若接口非幂等,可能导致资源竞争或数据冲突。
2、解决方案
1、唯一标识符(Request ID):
为每个广播请求分配唯一 ID,服务端通过检查 ID 判断是否已处理过该请求。
public void refreshCache(String requestId) {if (cacheService.isProcessed(requestId)) {return; // 已处理,直接返回}// 执行刷新缓存逻辑cacheService.markAsProcessed(requestId);
}
2、状态检查与更新:
在操作前检查目标状态,避免重复修改。
public void updateStatus(String resourceId, String newStatus) {String currentStatus = db.getStatus(resourceId);if (currentStatus.equals(newStatus)) {return; // 状态一致,无需更新}db.updateStatus(resourceId, newStatus);
}
3、去重表(Deduplication Table):
使用数据库表记录已处理的请求 ID,防止重复处理。
CREATE TABLE deduplication (request_id VARCHAR(36) PRIMARY KEY,processed_at TIMESTAMP
);
举例:客户端与服务端协作
1.客户端:生成唯一请求 ID 并传递给服务端。
String requestId = UUID.randomUUID().toString();
demoService.broadcastRefreshCache(requestId);
2.服务端:基于请求 ID 实现幂等性校验。
@Service
public class CacheServiceImpl implements CacheService {private final Set<String> processedRequests = new HashSet<>();@Overridepublic void refreshCache(String requestId) {if (processedRequests.contains(requestId)) {return;}// 执行刷新逻辑processedRequests.add(requestId);}
}
经过上面的示例,可以得出:

4、使用场景
1、通知所有服务实例
例如,更新分布式缓存、关闭资源、触发定时任务等。
2、配置同步
在分布式系统中,有时需要将某些配置信息同步到所有节点。例如,在分布式缓存或数据库集群中,更新配置时需要确保所有节点都接收到并执行这个更新操作。
3、全局状态更新
当系统中的全局状态需要在多个服务提供者之间保持一致时,Broadcast 策略能够确保所有服务提供者都执行了相同的操作。
4、多节点数据一致性
在某些场景下,多个服务节点的数据需要保持一致,例如在分布式文件系统中,删除某个文件时需要确保所有节点都删除该文件。
5、注意事项
- 性能开销:
广播调用会向所有 Provider 发送请求,可能导致性能下降。需合理控制调用频率。 - 幂等性要求:
由于调用可能重复或失败,服务接口必须设计为幂等的(Idempotent)。 - 失败容忍:
广播调用不保证所有 Provider 成功执行,需在业务层处理部分失败的情况。
总结
- 广播调用(
boradcast)是 Dubbo 的特殊调用模式,用于通知所有服务实例。 - 默认不支持重试:广播调用的每个 Provider 调用失败时,Dubbo 不会自动重试。
- 自定义重试:需在业务层显式实现重试逻辑,或结合负载均衡策略。
- 适用场景:适用于需要通知所有服务实例的场景,但需注意性能和幂等性。