GPU训练和call方法
知识点回归:
- CPU性能的查看:看架构代际、核心数、线程数
- GPU性能的查看:看显存、看级别、看架构代际
- GPU训练的方法:数据和模型移动到GPU device上
- 类的call方法:为什么定义前向传播时可以直接写作self.fc1(x)
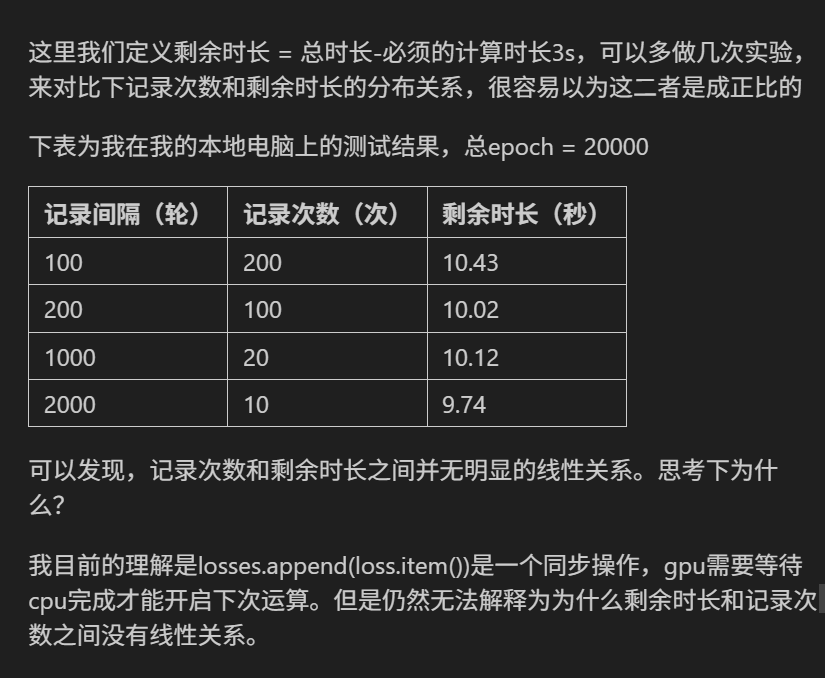
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import numpy as np# 仍然用4特征,3分类的鸢尾花数据集作为我们今天的数据集
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data # 特征数据
y = iris.target # 标签数据
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# # 打印下尺寸
# print(X_train.shape)
# print(y_train.shape)
# print(X_test.shape)
# print(y_test.shape)# 归一化数据,神经网络对于输入数据的尺寸敏感,归一化是最常见的处理方式
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test) #确保训练集和测试集是相同的缩放# 将数据转换为 PyTorch 张量,因为 PyTorch 使用张量进行训练
# y_train和y_test是整数,所以需要转化为long类型,如果是float32,会输出1.0 0.0
X_train = torch.FloatTensor(X_train)
y_train = torch.LongTensor(y_train)
X_test = torch.FloatTensor(X_test)
y_test = torch.LongTensor(y_test)class MLP(nn.Module): # 定义一个多层感知机(MLP)模型,继承父类nn.Moduledef __init__(self): # 初始化函数super(MLP, self).__init__() # 调用父类的初始化函数# 前三行是八股文,后面的是自定义的self.fc1 = nn.Linear(4, 10) # 输入层到隐藏层self.relu = nn.ReLU()self.fc2 = nn.Linear(10, 3) # 隐藏层到输出层
# 输出层不需要激活函数,因为后面会用到交叉熵函数cross_entropy,交叉熵函数内部有softmax函数,会把输出转化为概率def forward(self, x):out = self.fc1(x)out = self.relu(out)out = self.fc2(out)return out# 实例化模型
model = MLP()# 分类问题使用交叉熵损失函数
criterion = nn.CrossEntropyLoss()# 使用随机梯度下降优化器
optimizer = optim.SGD(model.parameters(), lr=0.01)# # 使用自适应学习率的化器
# optimizer = optim.Adam(model.parameters(), lr=0.001)# 训练模型
num_epochs = 20000 # 训练的轮数# 用于存储每个 epoch 的损失值
losses = []import time
start_time = time.time() # 记录开始时间for epoch in range(num_epochs): # range是从0开始,所以epoch是从0开始# 前向传播outputs = model.forward(X_train) # 显式调用forward函数# outputs = model(X_train) # 常见写法隐式调用forward函数,其实是用了model类的__call__方法loss = criterion(outputs, y_train) # output是模型预测值,y_train是真实标签# 反向传播和优化optimizer.zero_grad() #梯度清零,因为PyTorch会累积梯度,所以每次迭代需要清零,梯度累计是那种小的bitchsize模拟大的bitchsizeloss.backward() # 反向传播计算梯度optimizer.step() # 更新参数# 记录损失值losses.append(loss.item())# 打印训练信息if (epoch + 1) % 100 == 0: # range是从0开始,所以epoch+1是从当前epoch开始,每100个epoch打印一次print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')time_all = time.time() - start_time # 计算训练时间
print(f'Training time: {time_all:.2f} seconds')
import matplotlib.pyplot as plt
# 可视化损失曲线
plt.plot(range(num_epochs), losses)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training Loss over Epochs')
plt.show()CPU性能的查看
# pip install wmi -i https://pypi.tuna.tsinghua.edu.cn/simple
# 这是Windows专用的库,Linux和MacOS不支持,其他系统自行询问大模型
# 我想查看一下CPU的型号和核心数
import wmic = wmi.WMI()
processors = c.Win32_Processor()for processor in processors:print(f"CPU 型号: {processor.Name}")print(f"核心数: {processor.NumberOfCores}")print(f"线程数: {processor.NumberOfLogicalProcessors}")GPU训练
要让模型在 GPU 上训练,主要是将模型和数据迁移到 GPU 设备上。
在 PyTorch 里,.to(device) 方法的作用是把张量或者模型转移到指定的计算设备(像 CPU 或者 GPU)上。
- 对于张量(Tensor):调用 .to(device) 之后,会返回一个在新设备上的新张量。
- 对于模型(nn.Module):调用 .to(device) 会直接对模型进行修改,让其所有参数和缓冲区都移到新设备上。
在进行计算时,所有输入张量和模型必须处于同一个设备。要是它们不在同一设备上,就会引发运行时错误。并非所有 PyTorch 对象都有 .to(device) 方法,只有继承自 torch.nn.Module 的模型以及 torch.Tensor 对象才有此方法。
RuntimeError: Tensor for argument #1 'input' is on CPU, but expected it to be on GPU
这个常见错误就是输入张量和模型处于不同的设备。
如何衡量GPU的性能好坏呢?
以RTX 3090 Ti, RTX 3080, RTX 3070 Ti, RTX 3070, RTX 4070等为例
-
通过“代” 前两位数字代表“代”: 40xx (第40代), 30xx (第30代), 20xx (第20代)。“代”通常指的是其底层的架构 (Architecture)。每一代新架构的发布,通常会带来工艺制程的进步和其他改进。也就是新一代架构的目标是在能效比和绝对性能上超越前一代同型号的产品。
-
通过级别 后面的数字代表“级别”,
- xx90: 通常是该代的消费级旗舰或次旗舰,性能最强,显存最大 (如 RTX 4090, RTX 3090)。
- xx80: 高端型号,性能强劲,显存较多 (如 RTX 4080, RTX 3080)。
- xx70: 中高端,甜点级,性能和价格平衡较好 (如 RTX 4070, RTX 3070)。
- xx60: 主流中端,性价比较高,适合入门或预算有限 (如 RTX 4060, RTX 3060)。
- xx50: 入门级,深度学习能力有限。
-
通过后缀 Ti 通常是同型号的增强版,性能介于原型号和更高一级型号之间 (如 RTX 4070 Ti 强于 RTX 4070,小于4080)。
-
通过显存容量 VRAM (最重要!!) 他是GPU 自身的独立高速内存,用于存储模型参数、激活值、输入数据批次等。单位通常是 GB(例如 8GB, 12GB, 24GB, 48GB)。如果显存不足,可能无法加载模型,或者被迫使用很小的批量大小,从而影响训练速度和效果
- 训练阶段:小批量梯度是对真实梯度的一个有噪声的估计。批量越小,梯度的方差越大(噪声越大)。显存小只能够使用小批量梯度。
- 推理阶段:有些模型本身就非常庞大(例如大型语言模型、高分辨率图像的复杂 CNN 网络)。即使你将批量大小减到 1,模型参数本身占用的显存可能就已经超出了你的 GPU 显存上限。
__call__方法
在 Python 中,call 方法是一个特殊的魔术方法(双下划线方法),它允许类的实例像函数一样被调用。这种特性使得对象可以表现得像函数,同时保留对象的内部状态。
# 我们来看下昨天代码中你的定义函数的部分
class MLP(nn.Module): # 定义一个多层感知机(MLP)模型,继承父类nn.Moduledef __init__(self): # 初始化函数super(MLP, self).__init__() # 调用父类的初始化函数# 前三行是八股文,后面的是自定义的self.fc1 = nn.Linear(4, 10) # 输入层到隐藏层self.relu = nn.ReLU()self.fc2 = nn.Linear(10, 3) # 隐藏层到输出层
# 输出层不需要激活函数,因为后面会用到交叉熵函数cross_entropy,交叉熵函数内部有softmax函数,会把输出转化为概率def forward(self, x):out = self.fc1(x)out = self.relu(out)out = self.fc2(out)return out可以注意到,self.fc1 = nn.Linear(4, 10) 此时,是实例化了一个nn.Linear(4, 10)对象,并把这个对象赋值给了MLP的初始化函数中的self.fc1变量。
那为什么下面的前向传播中却可以out = self.fc1(x) 呢?,self.fc1是一个实例化的对象,为什么具备了函数一样的用法,这是因为nn.Linear继承了nn.Module类,nn.Module类中定义了__call__方法。(可以ctrl不断进入来查看)
在 Python 中,任何定义了 call 方法的类,其实例都可以像函数一样被调用。
当调用 self.fc1(x) 时,实际上执行的是:
- self.fc1.call(x)(Python 的隐式调用)
- 而 nn.Module 的 call 方法会调用子类的 forward 方法(即 self.fc1.forward(x))。这个方法就是个前向计算方法。
relu是torch.relu()这个函数为了保持写法一致,又封装成了nn.ReLU()这个类。来保证接口的一致性
PyTorch 官方强烈建议使用 self.fc1(x),因为它会触发完整的前向传播流程(包括钩子函数)这是 PyTorch 的核心设计模式,几乎所有组件(如 nn.Conv2d、nn.ReLU、甚至整个模型)都可以这样调用。
我们来介绍一下call方法是什么
# 不带参数的call方法
class Counter:def __init__(self):self.count = 0def __call__(self):self.count += 1return self.count# 使用示例
counter = Counter()
print(counter()) # 输出: 1
print(counter()) # 输出: 2
print(counter.count) # 输出: 21 2 2
类名后跟(),表示创建类的实例(对象),仅在第一次创建对象时发生。
call方法无参数的情况下,在实例化之后,每次调用实例时触发 call 方法
# 带参数的call方法
class Adder:def __call__(self, a, b):print("唱跳篮球rap")return a + badder = Adder()
print(adder(3, 5)) # 输出: 8唱跳篮球rap 8
@浙大疏锦行