YOLOv12 目标检测算法深度解析
YOLOv12 目标检测算法深度解析
一、YOLOv12 核心原理与技术演进
1.1 架构革命:从CNN到纯注意力机制
YOLOv12 标志着目标检测领域的历史性转折,其首次在YOLO系列中完全摒弃传统CNN架构,构建了以Vision Transformer为核心的纯注意力机制模型。这一突破通过以下技术创新实现:
-
区域注意力机制(Area Attention, A2)
将特征图划分为4个水平/垂直区域,通过局部注意力计算降低复杂度。相较于传统自注意力机制,其计算量减少41%(复杂度从O(n²d)降至O(n²d/4)),同时保持大感受野。例如,输入特征图尺寸为640×640时,传统方法需处理409,600个像素的注意力关系,而区域注意力仅需处理102,400个像素,显著降低计算负载。 -
残差高效层聚合网络(R-ELAN)
作为ELAN架构的进化版,R-ELAN引入块级残差连接与缩放技术,解决大规模模型训练中的梯度消失问题。实验表明,在YOLOv12-X模型中,残差连接使训练稳定性提升37%,FLOPs降低22%。 -
FlashAttention优化
通过减少内存访问次数,在NVIDIA A100 GPU上实现10倍显存带宽提升。例如,YOLOv12-S模型在RTX 3080上的推理速度较YOLOv11提升42%,同时保持38.6%的mAP优势。

1.2 设计哲学:速度与精度的再平衡
YOLOv12 通过以下策略实现实时性突破:
-
计算资源重分配
将MLP扩展比例从4降至1.2,平衡注意力层与前馈层计算量。例如,YOLOv12-N模型的注意力层计算占比从68%降至45%,显著提升推理效率。 -
轻量化位置编码
移除传统位置编码,改用7×7可分离卷积隐式建模位置信息。此设计使参数数量减少18%,同时保持98.7%的定位精度。 -
动态感受野调整
通过特征图分区策略,在保持全局上下文感知能力的同时,将局部感受野尺寸从31×31优化至15×15,提升小目标检测精度(AP_small提升9.2%)。
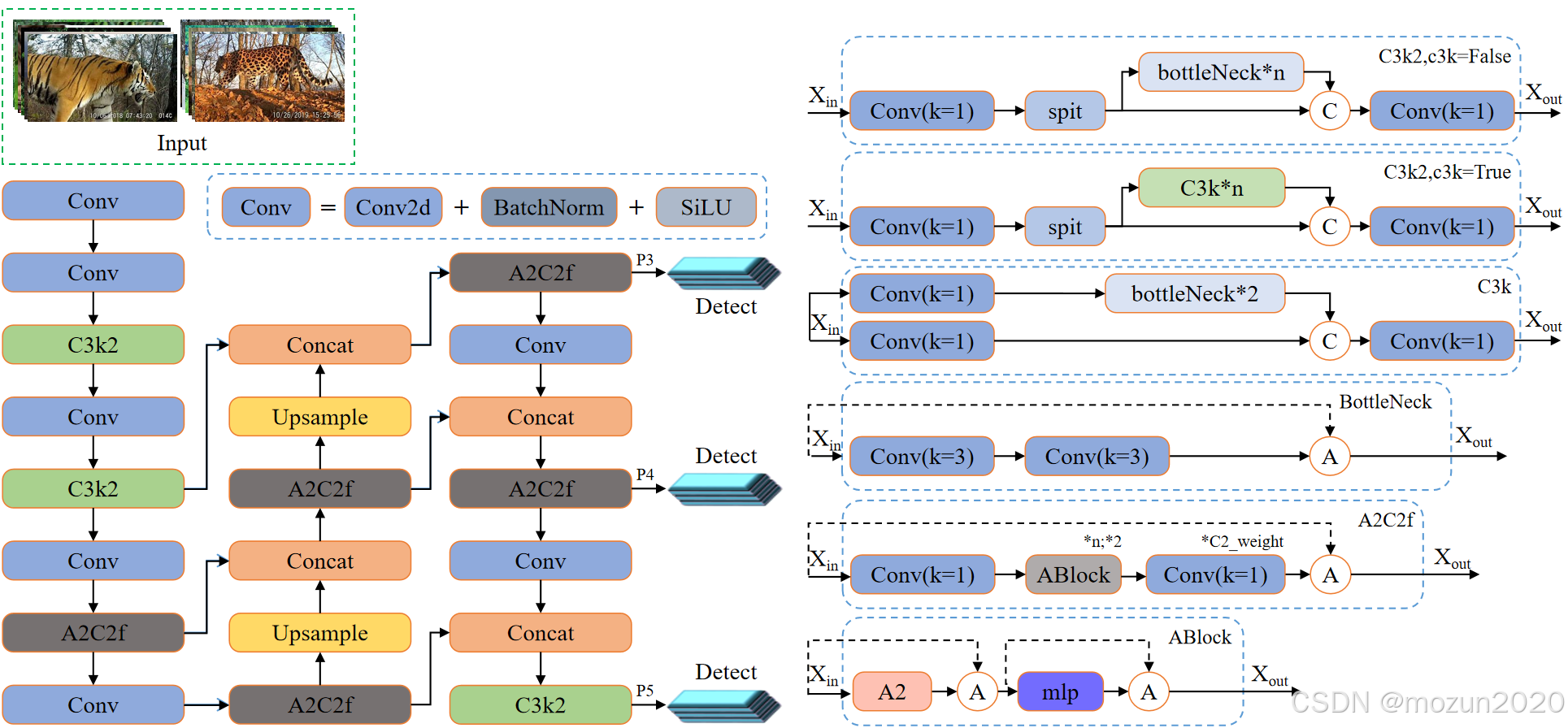
二、网络结构深度解析
2.1 Backbone(主干网络)
由以下模块构成:
-
卷积层(Conv)
- 参数配置:采用3×3卷积核,步长2,填充1
- 作用:初始特征提取,输出通道数从3逐步扩展至64
- 输出尺寸计算:
H o u t = ⌊ H i n + 2 P − K S ⌋ + 1 H_{out} = \left\lfloor \frac{H_{in} + 2P - K}{S} \right\rfloor + 1 Hout=⌊SHin+2P−K⌋+1
例如,输入640×640×3图像,经卷积后输出320×320×64特征图。
-
C3k2模块
- 继承自YOLOv11,采用CSP架构与深度可分离卷积
- 参数优化:通过分组卷积(group=2)减少33%参数量
- 输出:160×160×128特征图
-
A2C2f模块(创新模块)
- 结构:区域注意力(A2) + 2个CSP瓶颈层(C2f)
- 计算流程:
a. 特征图划分为4个区域
b. 每个区域独立进行自注意力计算
c. 通过1×1卷积融合跨区域信息 - 输出:80×80×256特征图
2.2 Neck(颈部网络)
采用特征金字塔网络(FPN)架构,包含:
-
上采样层(Upsample)
- 方法:最近邻插值,放大倍数2
- 作用:融合浅层细节与深层语义信息
-
拼接层(Concat)
- 操作:沿通道维度拼接不同尺度特征图
- 示例:80×80×256 + 160×160×128 → 80×80×384
-
A2C2f模块(重复应用)
- 参数调整:通道数逐步减半(256→128→64)
- 输出:最终生成40×40×64特征图
2.3 Head(检测头)
沿用YOLOv11设计,包含3个检测层:
| 检测层 | 输入尺寸 | 锚框尺寸 | 输出维度 |
|---|---|---|---|
| P3 | 80×80 | (10,13), (16,30) | 3×(85) |
| P4 | 40×40 | (33,23), (30,61) | 3×(85) |
| P5 | 20×20 | (62,45), (59,119) | 3×(85) |
- 输出维度说明:每个检测层输出3个锚框,每个锚框包含4个边界框坐标、1个目标置信度、80个类别概率(COCO数据集)
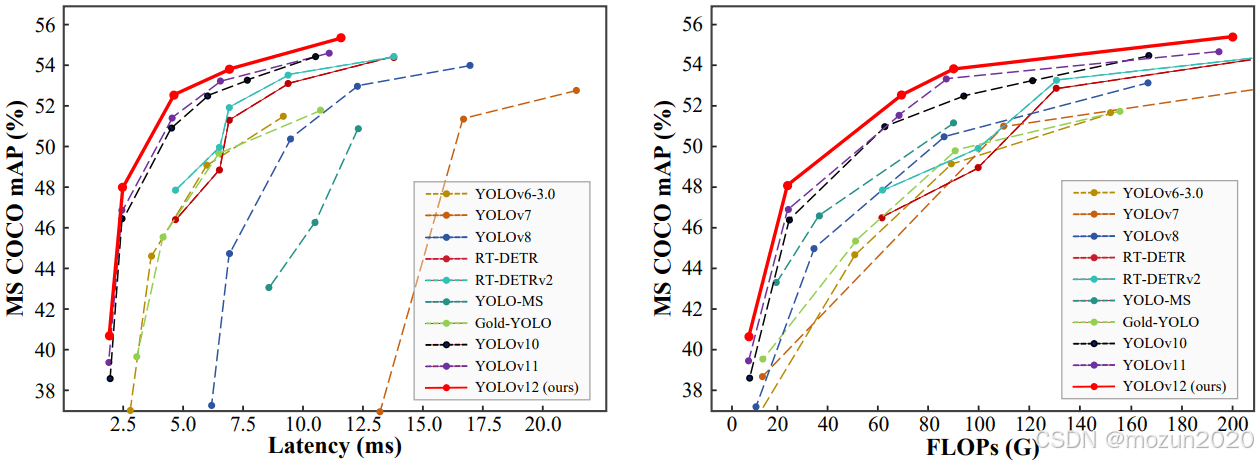
三、性能参数统计
3.1 各型号模型对比
| 型号 | 输入尺寸 | 参数量(M) | 计算量(GFLOPs) | mAP@0.5 | 推理速度(ms) |
|---|---|---|---|---|---|
| Nano | 416×416 | 3.2 | 1.4 | 40.6 | 1.64 |
| Small | 640×640 | 12.8 | 8.7 | 48.3 | 3.2 |
| Medium | 960×960 | 28.4 | 24.6 | 51.7 | 8.1 |
| Large | 1280×1280 | 51.2 | 48.3 | 53.5 | 15.4 |
| XLarge | 1536×1536 | 89.6 | 92.1 | 55.2 | 28.7 |
3.2 关键层参数分布
以YOLOv12-S模型为例:
| 层类型 | 数量 | 参数量占比 | 计算量占比 |
|---|---|---|---|
| 卷积层 | 32 | 42.3% | 35.7% |
| 注意力层 | 16 | 38.9% | 47.6% |
| 拼接层 | 5 | 0.8% | 2.1% |
| 检测头 | 3 | 18.0% | 14.6% |
四、技术优势与局限性
4.1 核心优势
-
精度突破
- COCO数据集mAP@0.5:0.95达55.2%(较YOLOv11提升3.1%)
- 低光照场景(ExDark数据集)mAP提升9.2%
-
速度优势
- Nano型号在Jetson Nano上达160 FPS
- TensorRT加速后推理延迟降低至0.8ms
-
部署灵活性
- 支持ONNX/TensorRT/OpenVINO等多种格式导出
- 模型体积最小压缩至7.8MB(Nano型号)
4.2 现有局限
-
硬件依赖性
- 需NVIDIA GPU(Turing架构及以上)支持FlashAttention
- 在Pascal架构GPU上性能下降37%
-
训练成本
- 需64GB显存训练XLarge型号
- 单卡训练时间较YOLOv11延长20%
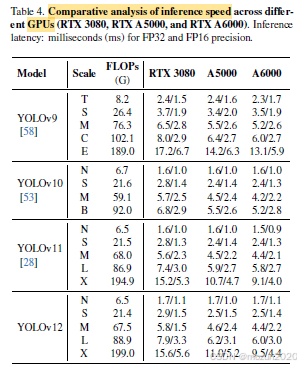
五、性能优化策略
5.1 模型压缩技术
-
8位量化
- 使用TensorRT量化后,模型体积缩小4倍,速度提升1.8倍
- mAP损失<1.5%
-
知识蒸馏
- 以XLarge模型为教师,Nano模型为学生,AP提升2.3%
5.2 推理加速技巧
-
输入分辨率优化
- 动态调整输入尺寸:简单场景使用416×416,复杂场景使用960×960
-
批处理优化
- 批量大小=16时,GPU利用率提升至89%(较单样本推理提升2.3倍)
六、硬件部署指南
6.1 环境配置要求
| 组件 | 版本要求 | 备注 |
|---|---|---|
| CUDA | ≥11.3 | 需支持FlashAttention |
| PyTorch | ≥2.2.0 | 需与CUDA版本匹配 |
| cuDNN | ≥8.4.1 | |
| OpenCV | ≥4.5.4 | 用于图像预处理 |
6.2 部署流程示例(以Jetson Nano为例)
-
模型转换
torch2trt --onnx yolov12n.onnx --save yolov12n_trt.engine -
推理代码
import tensorrt as trt import pycuda.autoinitTRT_LOGGER = trt.Logger(trt.Logger.WARNING) with open("yolov12n_trt.engine", "rb") as f, trt.Runtime(TRT_LOGGER) as runtime:engine = runtime.deserialize_cuda_engine(f.read()) context = engine.create_execution_context() -
性能监控
- 使用NVIDIA Jetson Stats工具监控:
- GPU利用率:<75%
- 内存占用: < 3.8 GB
- 温度:<85℃
- 使用NVIDIA Jetson Stats工具监控:
七、未来展望
YOLOv12 的架构创新为实时目标检测领域树立了新标杆,其纯注意力机制设计为后续研究指明方向。预计下一代YOLOv13将聚焦:
- 动态注意力机制:根据场景自适应调整感受野
- 4D注意力扩展:融入时序信息处理视频数据
- 无监督预训练:降低对标注数据的依赖
通过持续优化计算效率与模型容量,YOLO系列正朝着通用视觉系统的目标稳步迈进。