Mcu_Bsdiff_Upgrade
系统架构
概述
MCU BSDiff 升级系统通过使用二进制差分技术,提供了一种在资源受限的微控制器上进行高效固件更新的机制。系统不传输和存储完整的固件映像,而是只处理固件版本之间的差异,从而显著缩小更新包并降低带宽要求。
该架构遵循一个由两部分组成的模型:
- 主机端:在新旧固件之间创建差异补丁
- 设备端:应用补丁以更新嵌入式设备上的固件
高级架构
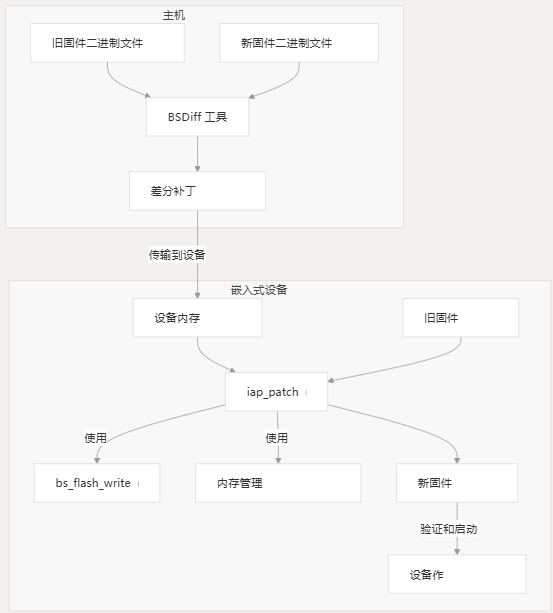
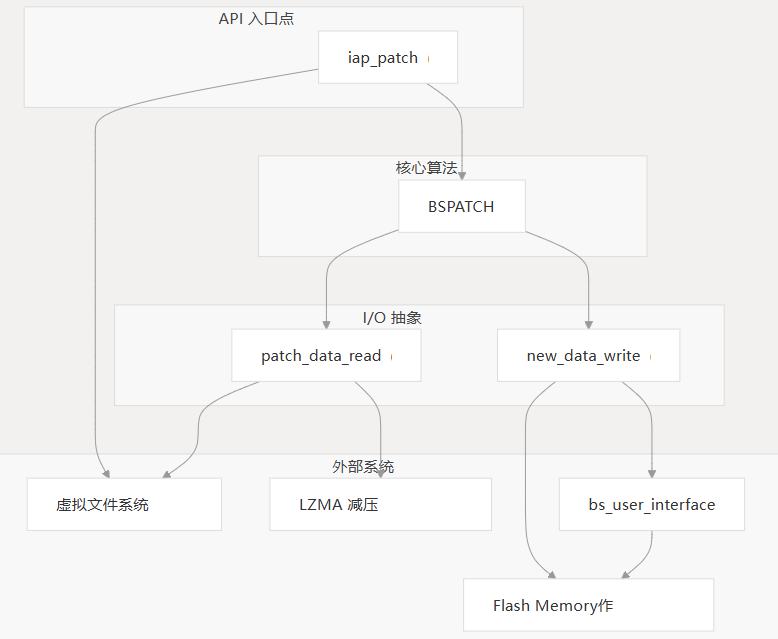
系统采用新旧固件二进制文件,使用 BSDiff 算法创建补丁,将补丁传输到设备,然后应用补丁以就地创建新的固件版本。
核心组件
该系统由几个关键组件组成,这些组件协同工作以实现差异更新机制:
- iap_patch:协调修补过程的主要入口点
- bspatch:实现二进制修补算法
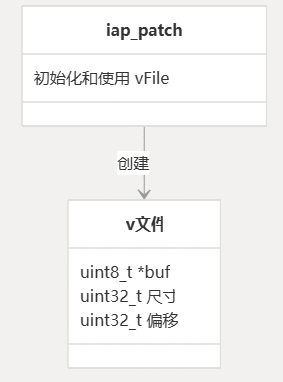
- vFile:为内存作提供虚拟文件系统抽象
- LZMA Decompression:解压缩的补丁数据
- bs_user_interface:用户提供的函数,用于特定于硬件的作
组件关系
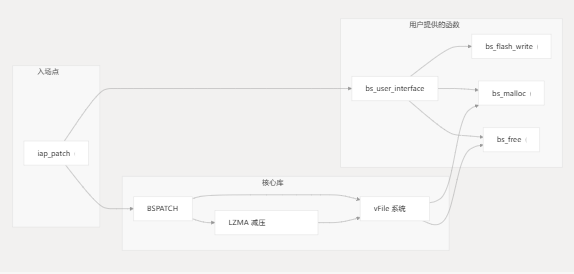
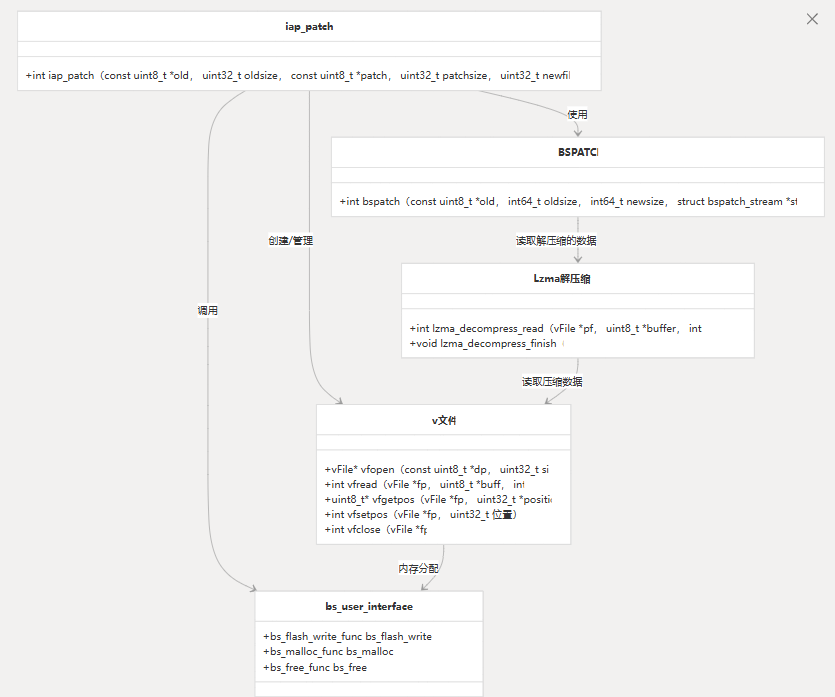
架构遵循模块化设计,其中:
- iap_patch 充当入口点并协调补丁应用程序
- BSPATCH 实现核心修补算法
- vFile 和 LZMA 解压缩提供支持功能
- bs_user_interface 通过用户实现的函数提供硬件抽象
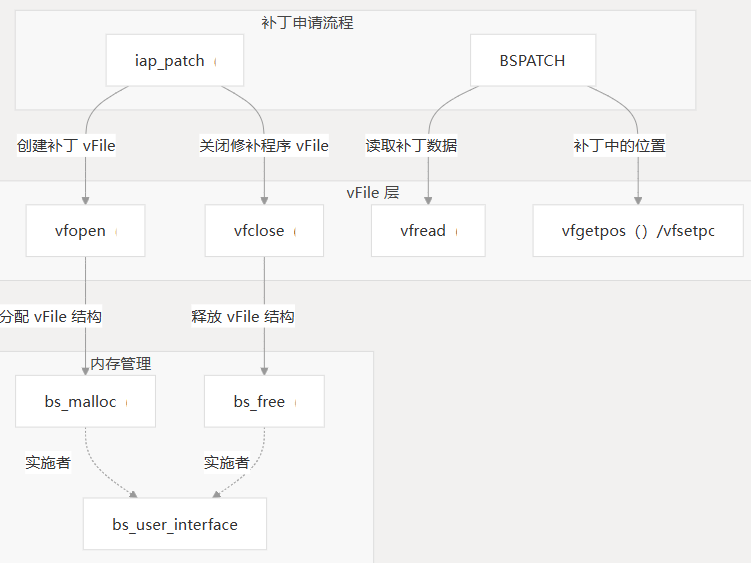
补丁申请流程
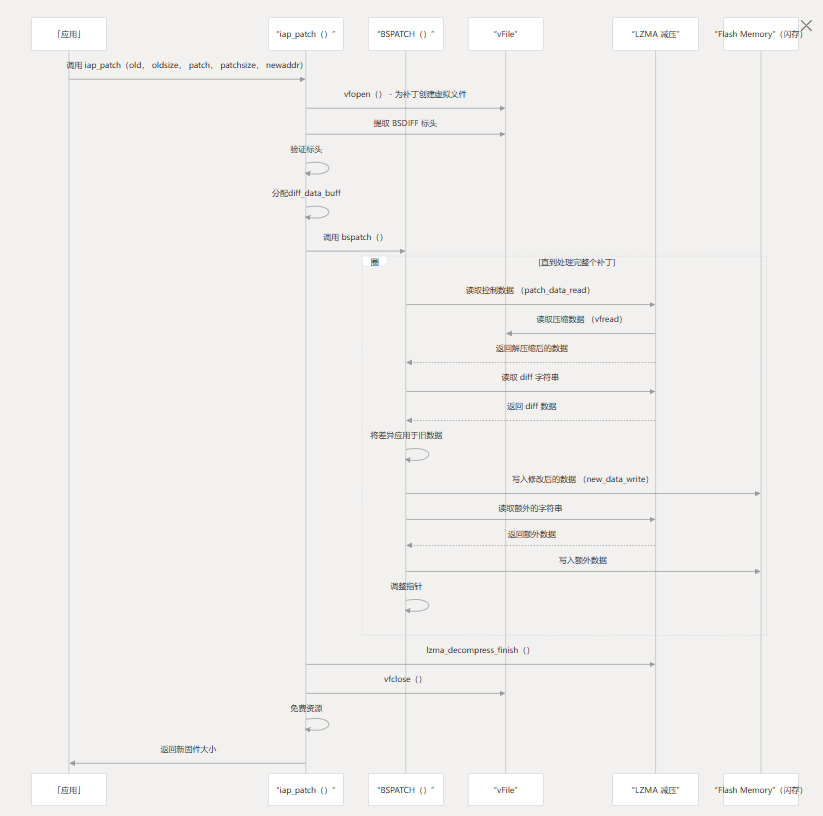
补丁应用程序过程包括几个步骤:
- 将补丁作为虚拟文件打开
- 提取并验证补丁标头
- 为解压缩缓冲区分配内存
- 读取和处理控制、差异和额外数据
- 将新固件写入闪存
- 清理资源
内存架构
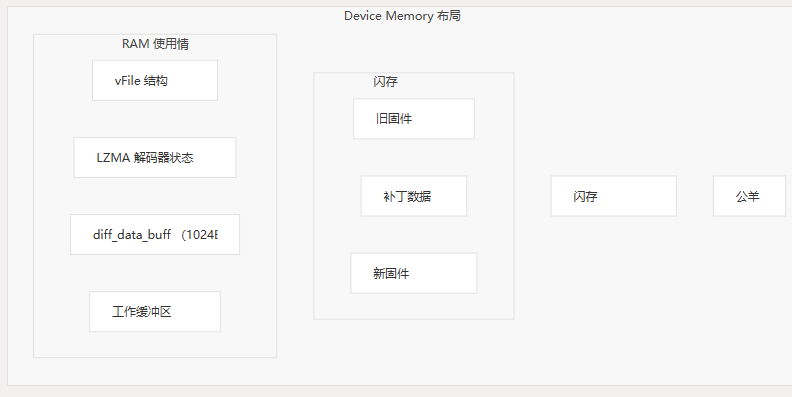
该系统设计为在嵌入式设备的内存限制内运行:
- Flash Memory:存储旧固件、补丁数据和新生成的固件
- RAM:与关键结构一起有效使用:
- vFile 结构(最小开销)
- LZMA 解码器状态
- 解压缩缓冲区 (可配置,默认 1024 字节)
- 用于修补作的工作内存
数据结构和类型
系统中的关键数据结构:

这些数据结构用于以下目的:
- image_header_t:包含有关补丁和固件版本的元数据
- vFile:为内存作提供虚拟文件抽象
- bspatch_stream:定义用于读取和写入补丁数据的接口
- bs_user_interface:定义用户为硬件作提供的函数
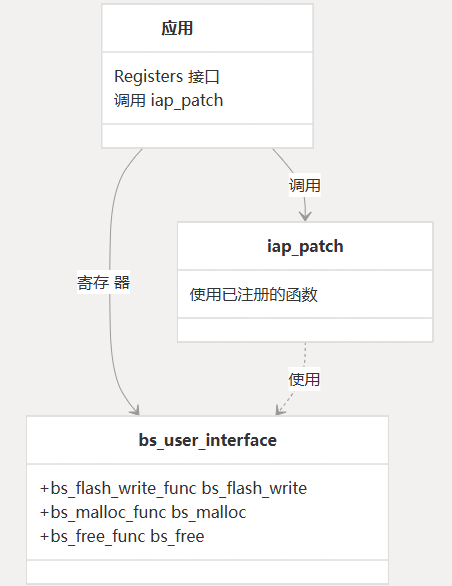
用户界面集成
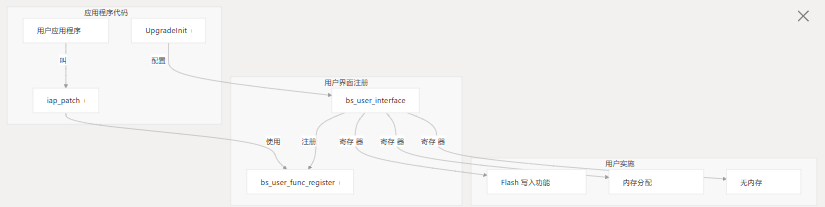
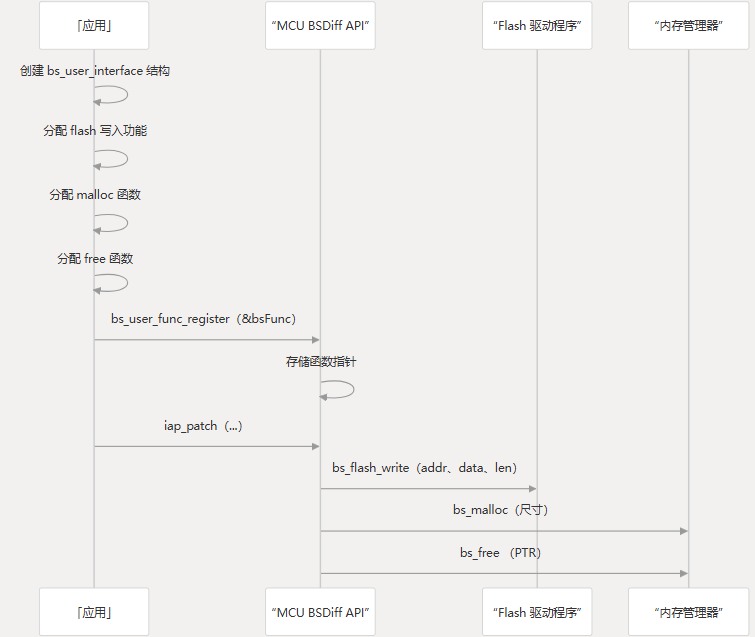
要集成系统,用户必须:
- 实现特定于硬件的功能(闪存写入、内存分配/释放)
- 创建结构并注册这些函数
bs_user_interface - 使用适当的参数调用 app 补丁
iap_patch()
注册码示例:
void UpgradeInit(void)
{bs_user_interface bsFunc;bsFunc.bs_flash_write = xmq25qxxWrite;bsFunc.bs_malloc = (bs_malloc_func)pvPortMalloc;bsFunc.bs_free = vPortFree;bs_user_func_register(&bsFunc);
}完整的系统更新流程
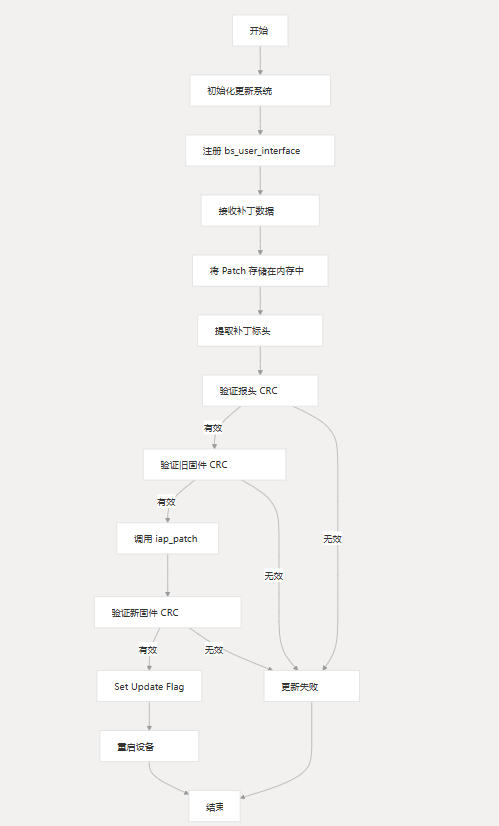
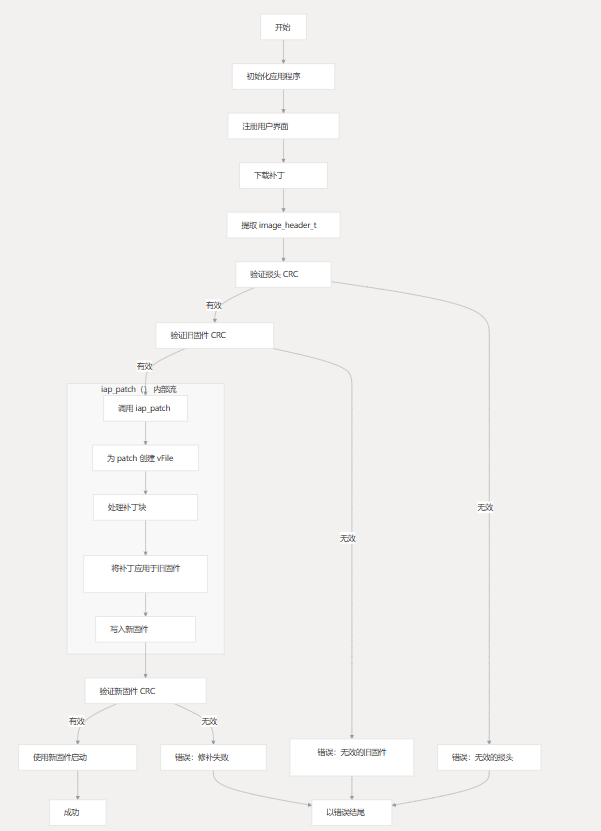
完整的固件更新过程包括:
- 初始化更新系统并注册用户功能
- 接收和存储补丁数据
- 提取并验证补丁标头
- 验证旧固件的 CRC
- 使用 应用补丁
iap_patch() - 验证新生成固件的 CRC
- 设置更新标志并重新启动设备
内存约束和优化
该系统设计为在嵌入式微控制器典型的严格内存限制下运行:
| 资源 | 典型要求 | 笔记 |
|---|---|---|
| ram | ≥10KB | 用于减压和工作缓冲区 |
| 只读存储器 | ~5KB | 对于库代码 |
| 堆 | 建议 ≥20KB | 可以通过修改缓冲区大小来减小 |
关键优化策略:
- 使用虚拟文件抽象来最小化内存副本
- 增量解压缩以块的形式处理数据
- 可配置的缓冲区大小,以适应不同的内存限制
- 直接写入闪存以避免大内存缓冲区
结论
MCU BSDiff 升级系统架构通过精心设计的二进制差分算法、内存高效的数据结构和硬件抽象层的组合,在资源受限的微控制器上实现高效的固件更新。
通过仅处理固件版本之间的差异并使用压缩技术,该系统显著减少了更新期间需要传输和临时存储的数据量,使其成为带宽和内存资源有限的嵌入式应用程序的理想选择。
安装和设置
先决条件
在集成 MCU BSDiff 升级系统之前,请确保您的目标平台满足以下要求:
- 具有至少 10KB 可用 RAM 的 MCU
- 大约 5KB 的 ROM/Flash 用于库代码
- 功能性 flash 写入作
- 内存分配和释放功能
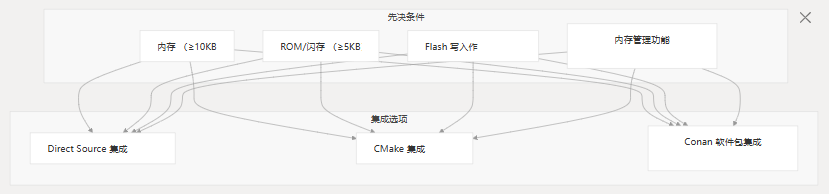
安装方法
MCU BSDiff 升级库可以通过三种不同的方法集成到您的项目中:
方法 1:Direct Source 集成
最简单的方法是直接在项目中包含源文件:
-
将以下目录复制到您的项目中:
bsdiff/- 核心差分修补算法lib/- 效用函数lzma/- LZMA 压缩/解压缩user/- 用户界面层
-
将复制的目录添加到您的包含路径中。
-
将所有 .c 文件添加到您的构建系统中。
方法 2:CMake 集成
如果您的项目使用 CMake:
- 将整个存储库复制到您的项目中,或将其添加为子模块。
- 在项目的CMakeLists.txt中,添加:
add_subdirectory(path/to/mcu_bsdiff_upgrade)
target_link_libraries(your_target PRIVATE bsdiff_upgrade)该库的 CMakeLists.txt 可自动处理所有源文件并包含
方法 3:Conan 包集成
对于使用 Conan 包管理器的项目:
-
将库添加为 conanfile.txt 中的依赖项:
[requires] bsdiff_upgrade/1.0.3@xian/stable -
运行 以获取包。
conan install -
使用 Conan 生成的 find_package 配置链接到 CMakeLists.txt 中的库。
集成流程
下图说明了将 MCU BSDiff 升级库集成到项目中的步骤:
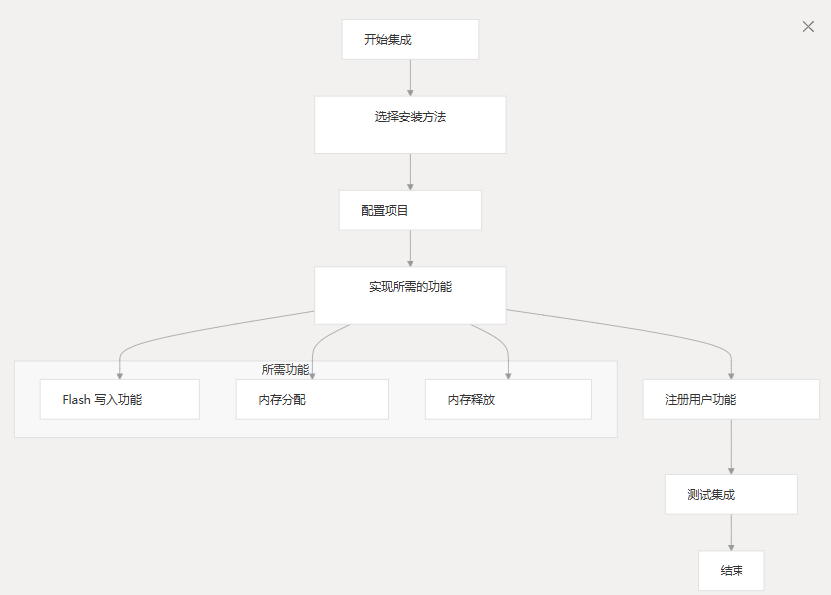
所需的用户功能
该库要求您实现并注册以下函数:
| 函数类型 | 描述 | 目的 |
|---|---|---|
| bs_flash_write | 将数据写入闪存 | 将新固件数据写入目标 flash 地址 |
| bs_malloc | 分配内存 | 为修补过程提供工作内存 |
| bs_free | 释放分配的内存 | 使用后释放工作内存 |
这些函数是通过 structure 和 function 注册的。bs_user_interfacebs_user_func_register

设置过程
以下是在应用程序中设置库的方法:
- 实现所需的功能(闪存写入、内存分配/释放)
- 创建一个初始化库的函数:
void UpgradeInit(void)
{bs_user_interface bsFunc;bsFunc.bs_flash_write = YourFlashWriteFunction;bsFunc.bs_malloc = YourMemoryAllocationFunction;bsFunc.bs_free = YourMemoryFreeFunction;bs_user_func_register(&bsFunc);
}- 在使用任何差异更新函数之前,请在应用程序开始时调用 Call。
UpgradeInit()
内存注意事项
该库需要足够的内存来执行其作。以下是关键的内存要求:
- 最小 RAM:10KB(可以通过修改源代码以使用较小的恢复块来减少)
- 默认还原块大小:1KB(可以调整以平衡性能与内存使用)
- 堆使用:为修补过程分配临时缓冲区
- 堆栈使用情况:取决于编译器和优化设置
在实现内存分配函数时,请确保:
- 堆至少有 20KB 可用于测试
- 内存分配已正确实现并正常工作
系统集成
下图显示了 MCU BSDiff 升级如何与您的固件集成:
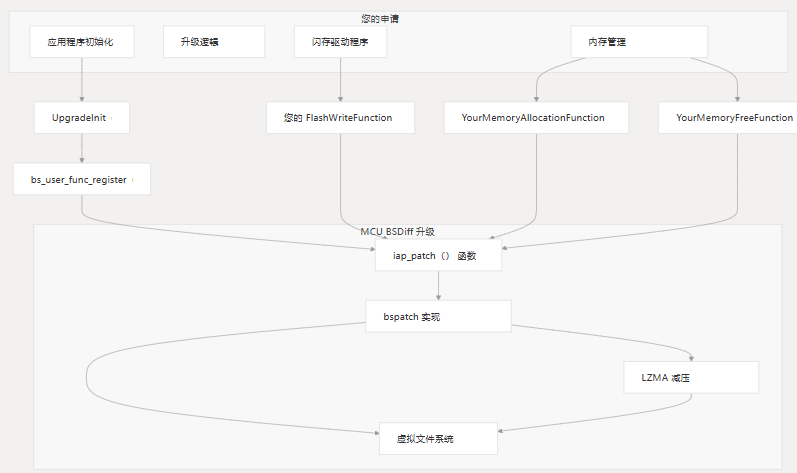
使用库
设置后,您可以使用该函数应用差异补丁。函数签名为:iap_patch
int iap_patch(const uint8_t *old, uint32_t oldsize, const uint8_t *patch, uint32_t patchsize, uint32_t newfile);哪里:
old:指向 Flash 中旧固件的指针(执行区域)oldsize:旧固件的大小patch:指向下载的差异补丁数据的指针patchsize:补丁数据的大小newfile:将写入新固件的地址
该函数在成功时返回新固件的大小或错误代码。
故障 排除
如果您在安装或设置过程中遇到问题:
- 验证内存分配函数是否正常工作
- 确保有足够的堆内存(至少 20KB 用于测试)
- 检查 flash 写入作
- 验证源文件是否正确包含
- 使用正确的 CRC 验证补丁文件的完整性
常见问题与内存分配或堆/堆栈空间不足有关。
核心组件
核心组件概述
MCU BSDiff 升级系统由四个主要组件组成,这些组件协同工作,在资源受限的设备上实现高效的固件更新:
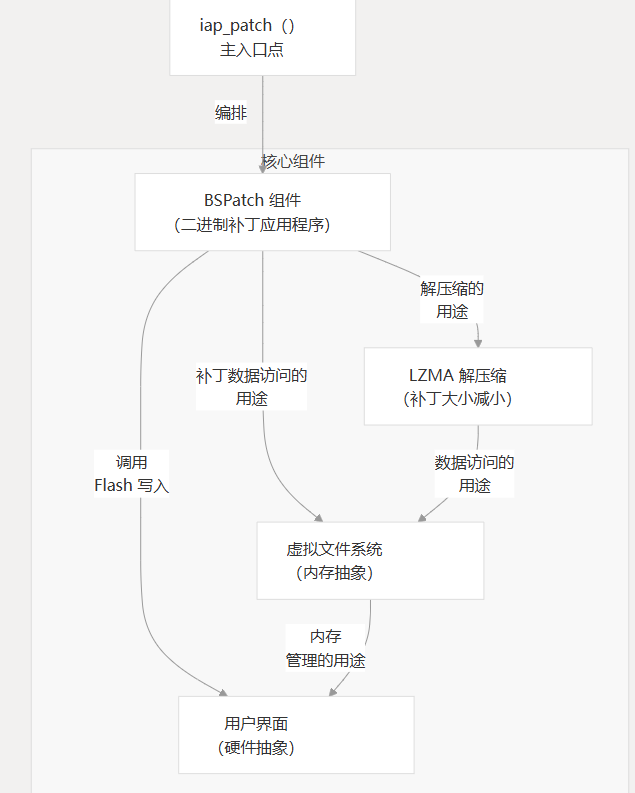
这些组件中的每一个在修补过程中都有特定的角色:
- BSPatch 组件:实现重建新固件的二进制修补算法
- 虚拟文件系统:提供一个抽象层,用于将内存中的数据作为文件处理
- LZMA 解压缩:处理压缩补丁数据的解压缩
- 用户界面:定义特定于硬件的作,如 flash 写入和内存管理
组件架构和交互
下图说明了核心组件的架构以及它们在修补过程中的交互方式:
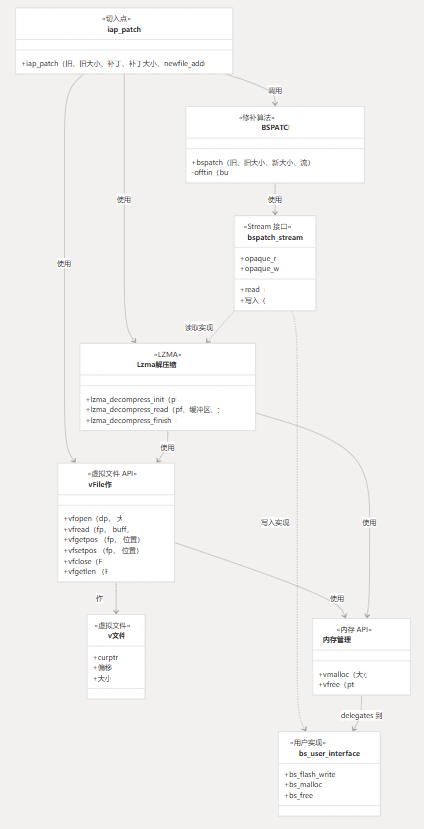
BSPatch 组件
BSPatch 组件是负责应用二进制补丁以从旧固件映像重建新固件映像的核心算法。
主要功能
iap_patch:修补过程的主要入口点bspatch:实现补丁应用程序算法offtin:用于解码补丁流中数字的辅助函数
补丁申请流程
修补过程遵循以下步骤:
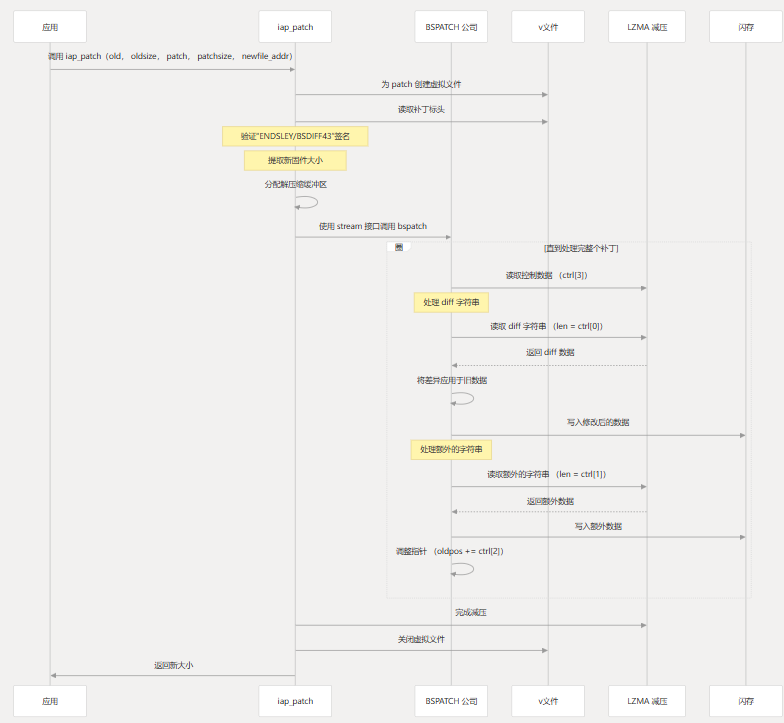
虚拟文件系统
虚拟文件系统 (vFile) 提供了一个抽象层,允许修补算法将内存缓冲区视为文件。
关键数据结构
vFile Structure:
- curptr: Pointer to data in memory
- offset: Current position within the data
- size: Total size of the data
主要功能
vfopen:从内存缓冲区创建虚拟文件vfread:从虚拟文件中读取数据vfgetpos:获取虚拟文件中的当前位置vfsetpos:设置虚拟文件中的位置vfclose:关闭虚拟文件vfgetlen:获取虚拟文件的总长度
内存管理
vFile 系统还提供内存管理函数,这些函数委托给用户提供的实现:
vmalloc:使用用户提供的分配器分配内存vfree:使用用户提供的释放器释放内存
LZMA 减压
LZMA (Lempel-Ziv-Markov chain Algorithm) 解压缩组件负责解压缩补丁数据,从而显著减小补丁大小。
主要功能
lzma_decompress_init:初始化 LZMA 解码器lzma_decompress_read:解压缩并读取数据块lzma_decompress_finish:清理 LZMA 资源
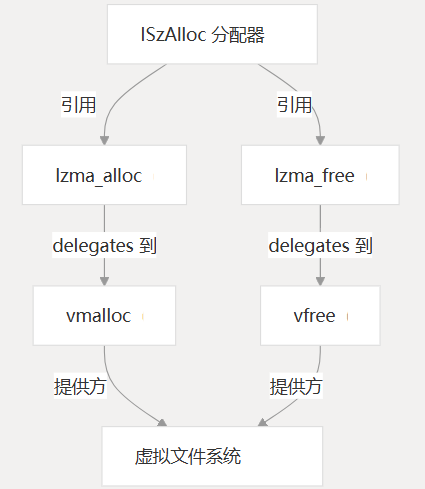
LZMA 的内存分配
LZMA 使用自定义内存分配器,这些分配器委托给用户提供的函数:
lzma_alloc:为 LZMA 内部结构分配内存lzma_free:释放为 LZMA 分配的内存
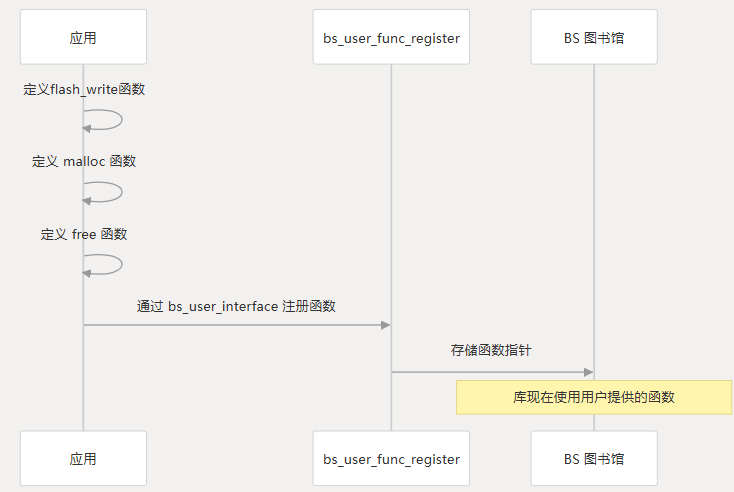
用户界面功能
User Interface 组件是一组必须由用户实现的函数,以提供特定于硬件的作:
User Interface 组件是一组必须由用户实现的函数,以提供特定于硬件的作:
typedef struct bs_user_interface {bs_flash_write_func bs_flash_write; // Function to write to flash memorybs_malloc_func bs_malloc; // Function to allocate memorybs_free_func bs_free; // Function to free memory
} bs_user_interface;这些函数在库中注册以启用硬件抽象。
注册流程
内存架构
修补过程需要仔细的内存管理,以便在资源受限的设备上高效运行。
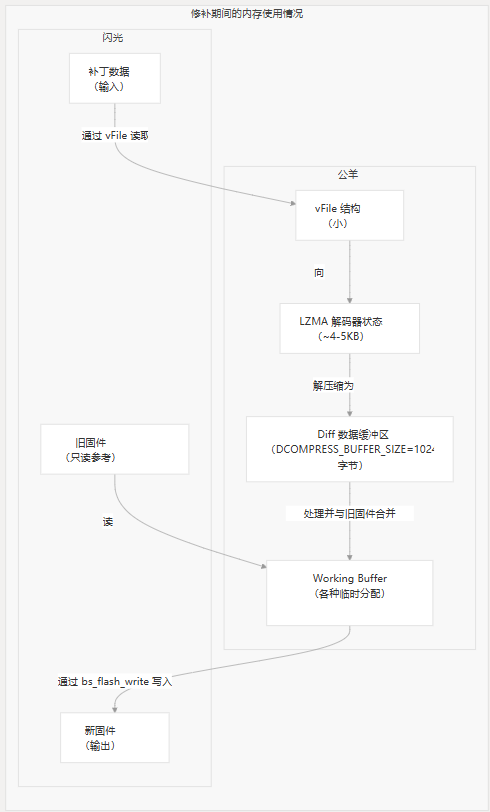
关键内存注意事项
- Differential Buffer:固定大小为 1024 字节 (WRITE_BLOCK_SIZE),用于处理 diff 块
- 解压缩缓冲区:解压缩数据的固定大小为 1024 字节 (DCOMPRESS_BUFFER_SIZE)
- LZMA 状态:需要几 KB 的 RAM 才能进入解压缩状态
- vFile 结构:文件抽象的开销小
通过以小块处理固件而不是将整个映像加载到内存中,可以显著降低总 RAM 使用量。
与固件更新过程集成
下图说明了核心组件如何集成到完整的固件更新过程中:
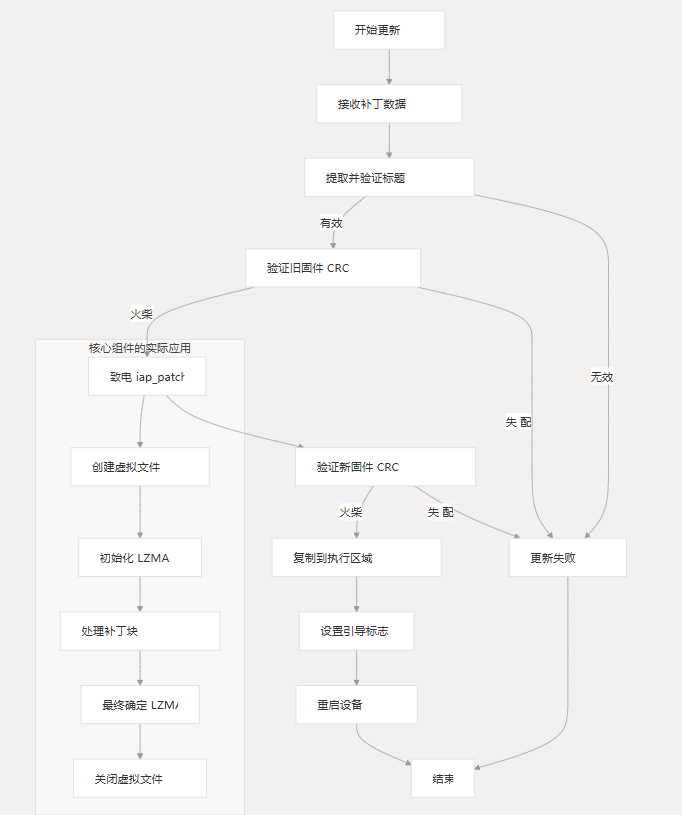
上述过程显示了核心组件(在子图中突出显示)如何适应整个固件更新工作流程。
总结
MCU BSDiff 升级系统的核心组件协同工作,以实现高效的固件更新:
- BSPatch 组件:应用二进制修补算法
- 虚拟文件系统:为内存数据提供文件抽象
- LZMA 解压缩:通过压缩减小补丁大小
- 用户界面:抽象化特定于硬件的作
这些组件旨在在资源受限的嵌入式设备上高效运行,同时提供强大的固件更新机制。
BSDiff/BSPatch 实现
目的和范围
本文档详细介绍了 MCU BSDiff 升级系统中的 BSDiff/BSPatch 算法实现。它涵盖了将差异更新应用于嵌入式设备固件的二进制修补机制,侧重于核心算法、控制流、数据结构和集成点。
算法概述
BSDiff/BSPatch 是一种二进制差分算法,它通过仅传输版本之间的差异而不是完整的固件映像来实现高效的固件更新。该系统中的实现基于 Colin Percival 的 BSDiff 算法,并适用于资源受限的嵌入式环境。
核心组件
BSDiff/BSPatch 实现由几个关键组件组成,这些组件协同工作以将补丁应用于现有固件映像。
BSPatch 流接口
BSPatch 实现使用流抽象将 I/O作与核心算法分开。这允许算法使用不同的输入源和输出目标。
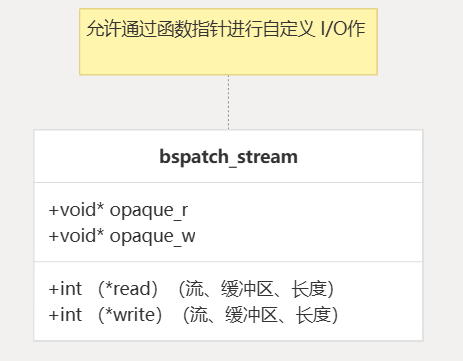
关键数据结构
补丁格式依赖于多种数据结构来有效地编码二进制文件之间的差异:
-
控制块:三个 64 位整数,用于指定:
- 差异数据的长度
- 额外数据的长度
- 旧文件中的偏移调整
-
Diff Data:要添加到旧文件中相应字节的数据
-
Extra Data:要直接插入到新文件中的新数据
补丁申请流程
补丁应用程序过程遵循结构化顺序将旧固件转换为新版本。
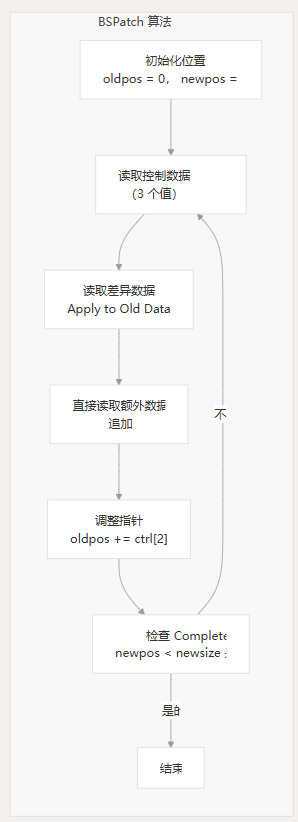
核心算法实现
核心函数实现二进制修补算法。它读取控制数据,将 diff 数据应用于旧文件,附加额外数据,并在循环中调整文件指针,直到新文件完成。bspatch
补丁格式处理
补丁格式包括:
- 16 字节签名 “ENDSLEY/BSDIFF43”
- 一个 8 字节的新文件大小值
- 一系列控制块、差异数据和额外数据
每次迭代都会处理:
- 控制块:三个 64 位整数
- Diff Data:要从旧文件添加到相应字节的数据
- Extra Data:直接追加的新数据
该进程以块为单位工作以保持内存效率,使用 1024 字节 () 的缓冲区大小 ()。WRITE_BLOCK_SIZE
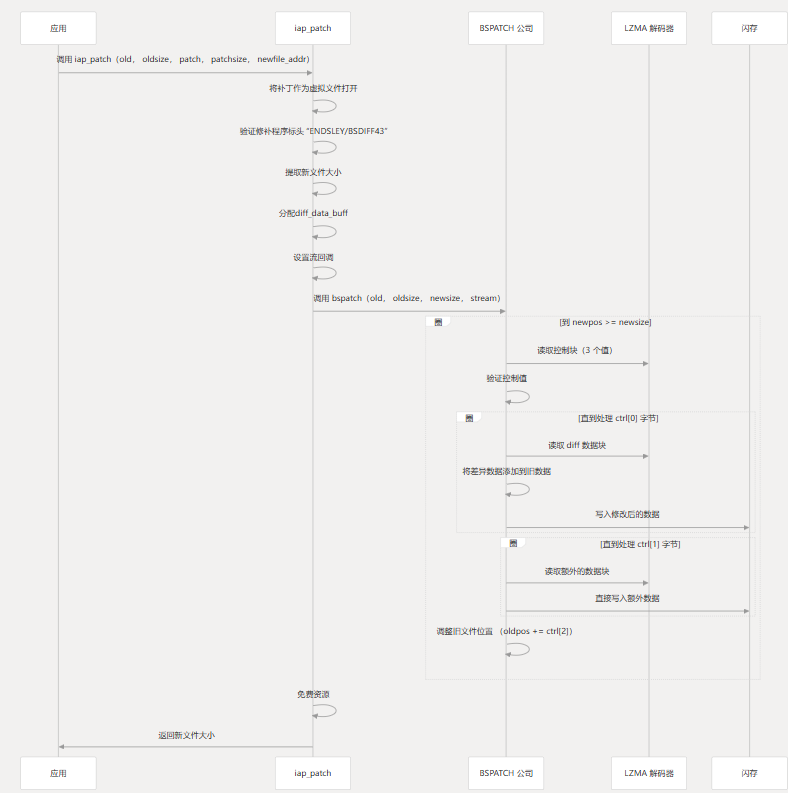
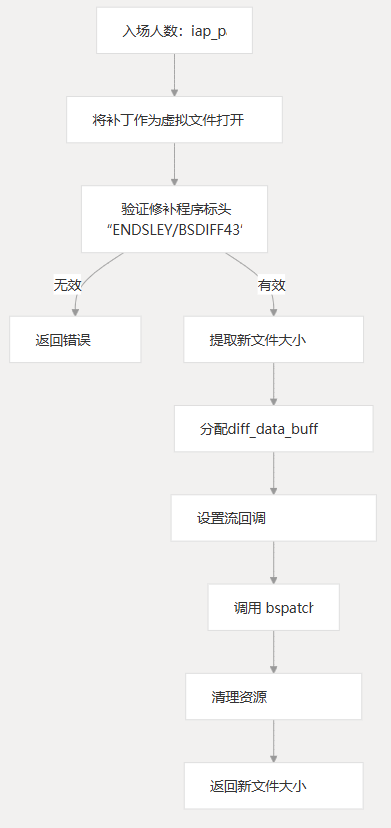
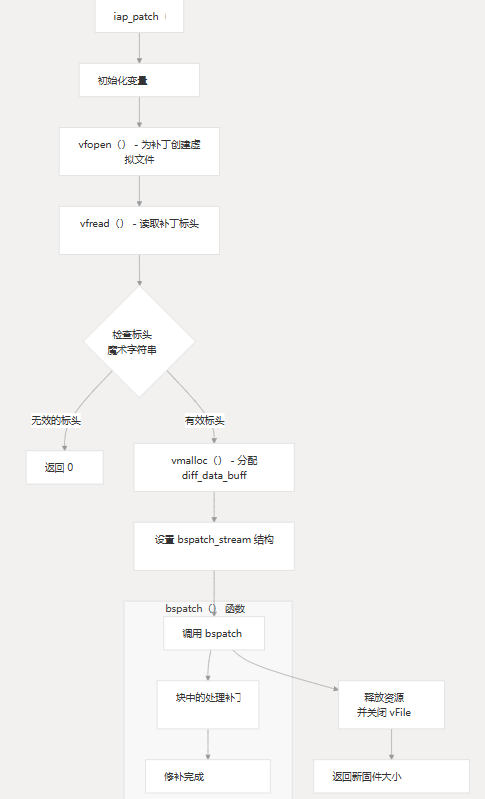
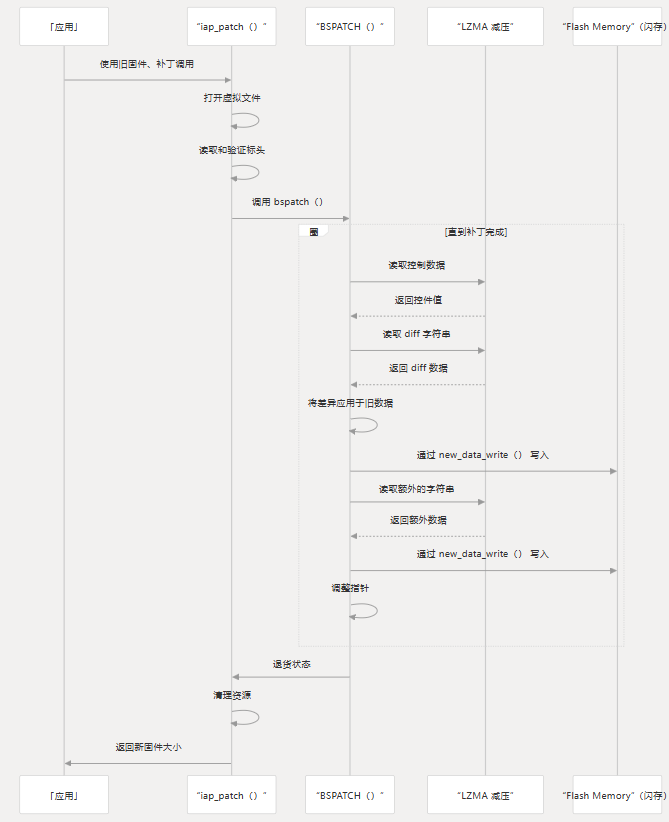
入场点: iap_patch
该函数用作用户应用补丁的主要入口点。它:iap_patch
- 以虚拟文件的形式打开补丁
- 验证补丁标头
- 提取新文件大小
- 设置 read 和 write 回调
- 应用补丁的调用
bspatch - 清理资源
与 LZMA 和闪存集成
该实现通过流回调与 LZMA 解压缩和 flash memory作集成。
读取压缩的补丁数据
功能:patch_data_read
- 从虚拟文件中读取压缩数据
- 使用 LZMA 解码器对其进行解压缩
- 缓冲并返回解压后的数据
编写新固件
功能:new_data_write
- 使用用户提供的 flash 写入功能
- 将数据写入指定地址
- 递增写入位置指针
内存管理注意事项
该实现专为资源受限的环境而设计,具有仔细的内存管理:
| 缓冲区 | 目的 | 大小 | 分配 |
|---|---|---|---|
diff_data_buff | 保存解压缩的补丁数据 | 1024 字节 (DCOMPRESS_BUFFER_SIZE) | 动态 (vmalloc) |
buf_data | 用于处理块的工作缓冲区 | 1024 字节 (WRITE_BLOCK_SIZE) | 动态 (vmalloc) |
仅在需要时分配内存,并在使用后立即释放内存,以最大限度地减少 RAM 占用。
Offtin:关键效用函数
该函数将 8 字节缓冲区转换为 64 位有符号整数。它广泛用于解析 patch 格式的控制值。offtin
int64_t offtin(uint8_t *buf)
{int64_t y;y = buf[7] & 0x7F;y = y * 256;y += buf[6];// ... continues for all bytesif (buf[7] & 0x80){y = -y;}return y;
}
此函数处理 patch 中 64 位控件值的字节序和符号转换。
错误处理和验证
该实施包括几个验证点,以确保稳健性:
- 补丁标头验证
- 控制数据健全性检查
- 缓冲区分配检查
- Flash 写入错误检测
这些验证有助于防止在处理损坏的补丁数据时发生崩溃和无效作。
与 MCU BSDiff 升级系统集成
BSDiff/BSPatch 组件通过定义明确的接口与 MCU BSDiff 升级系统的其他部分集成:
总结
MCU BSDiff 升级系统中的 BSDiff/BSPatch 实现为在嵌入式设备上应用固件更新提供了一种有效的机制。通过处理块中的差分补丁并与 LZMA 压缩集成,它可以最大限度地减少内存使用量,同时实现带宽高效的更新。该实施包括强大的错误处理和验证,以确保在资源受限的环境中可靠运行。
虚拟文件系统
目的和范围
虚拟文件系统 (VFS) 是一个轻量级抽象层,可提供对 MCU BSDiff 升级系统中内存缓冲区的类似文件的访问。它使二进制修补算法能够像文件一样从内存区域读取数据,而无需在嵌入式设备上提供实际的文件系统支持。本页详细介绍了修补过程中的 VFS 架构、组件和用法。
架构概述
虚拟文件系统在内存缓冲区上创建抽象,允许使用类似文件的作来访问它们。这对于可能没有物理文件系统但需要处理存储在内存中的固件补丁数据的嵌入式系统尤其重要。
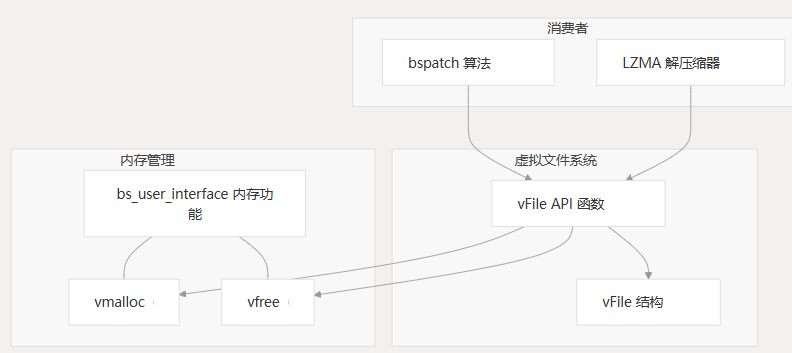
图:虚拟文件系统体系结构和关系
vFile 结构
虚拟文件系统的核心是结构,它封装了将内存缓冲区视为文件所需的所有信息。vFile
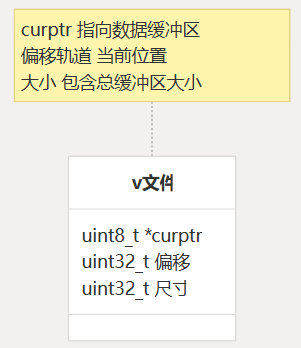
图:vFile 结构
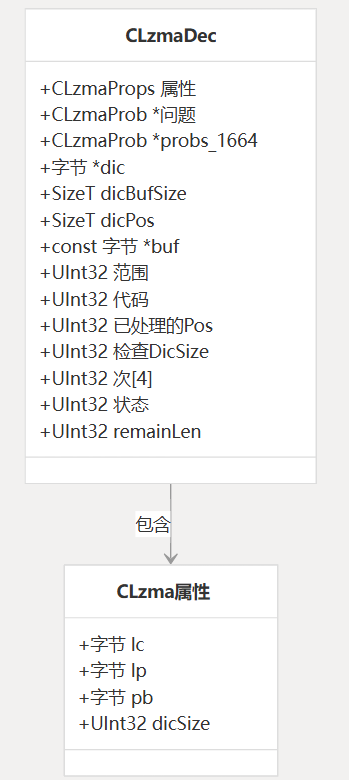
该结构由三个关键成员组成:vFile
curptr:指向内存中数据缓冲区开头的指针offset:缓冲区中的当前位置(类似于文件指针)size:缓冲区的总大小(以字节为单位)
这种简单的结构提供了足够的上下文来处理内存缓冲区上的类似文件的作。
API 参考
虚拟文件系统提供了一组全面的函数,用于模拟标准文件作。
| 功能 | 描述 | 参数 | 返回值 |
|---|---|---|---|
vfopen | 打开虚拟文件 | 数据指针、大小 | vFile 指针 |
vfread | 从虚拟文件中读取数据 | vFile 指针、缓冲区、长度 | 读取的字节数 |
vfgetpos | 获取当前位置 | vFile 指针、位置指针 | 指向当前位置的指针 |
vfsetpos | 设置当前位置 | vFile 指针, 位置 | 新位置 |
vfclose | 关闭虚拟文件 | vFile 指针 | 成功时为 0 |
vfgetlen | 获取文件长度 | vFile 指针 | 文件大小 |
vmalloc | 分配内存 | 大小 | 内存指针 |
vfree | 释放内存 | 内存指针 | 没有 |
功能详情
打开和关闭虚拟文件
-
vfopen:创建一个新结构体,并使用提供的数据缓冲区和大小对其进行初始化。
vFilevFile *vfopen(const uint8_t *dp, uint32_t size); -
vfclose:释放结构。
vFileint vfclose(vFile *fp);
读取数据
- vfread:将指定数量的字节从虚拟文件读取到缓冲区中。如果请求的读取将超过文件大小,则返回可用字节数。
int vfread(vFile *fp, uint8_t *buff, int len);
位置管理
-
vfgetpos:获取虚拟文件中的当前位置。
uint8_t *vfgetpos(vFile *fp, uint32_t *position); -
vfsetpos:设置虚拟文件中的当前位置。
int vfsetpos(vFile *fp, uint32_t position); -
vfgetlen:获取虚拟文件的总长度。
uint32_t vfgetlen(vFile *fp);
内存管理
-
vmalloc:使用用户提供的内存分配函数分配内存。
void *vmalloc(size_t size); -
vfree:使用用户提供的 memory free 函数释放内存。
void vfree(void *ptr);
作流程
使用 Virtual File System 时的典型作顺序如下所示:

图:虚拟文件系统作流程
内存管理集成
虚拟文件系统使用依赖关系注入模式进行内存管理。它不是直接调用 and ,而是通过 .这允许 VFS 在具有自定义内存管理的环境中工作。malloc free bs_user_interface
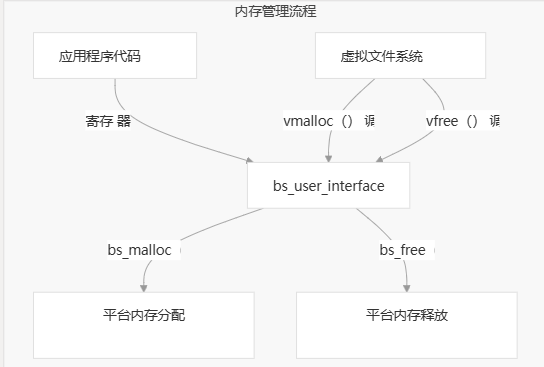
图:内存管理集成
and 函数充当用户提供的内存管理函数的包装器:vmalloc vfree
void *vmalloc(size_t size)
{if (bs_user_func.bs_malloc == NULL){return NULL;}return bs_user_func.bs_malloc((size_t)size);
}void vfree(void *ptr)
{if (bs_user_func.bs_free == NULL){return;}bs_user_func.bs_free(ptr);
}这种设计允许 Virtual File System 与平台无关,并使用不同的内存管理方案。
修补过程中的使用情况
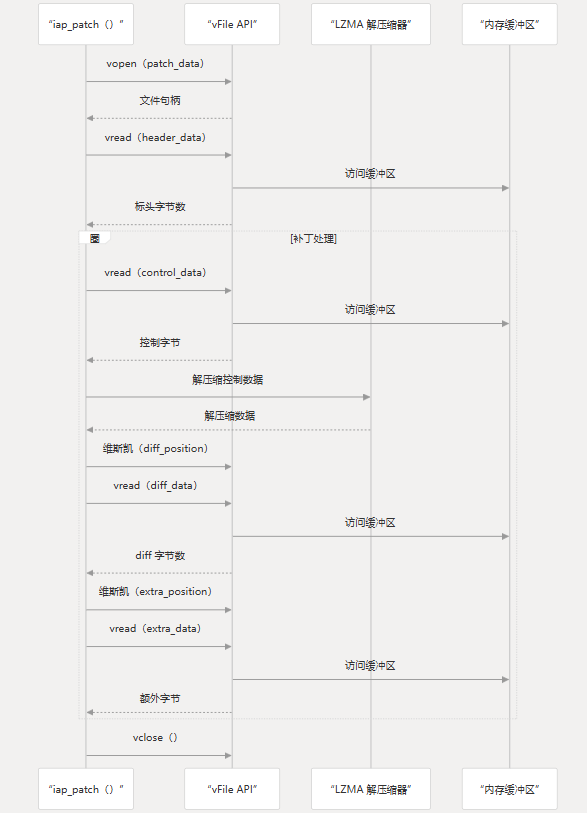
在 MCU BSDiff 升级系统中,虚拟文件系统是使 bspatch 算法能够高效处理数据的关键组件。以下是 VFS 在修补工作流程中的通常使用方式:
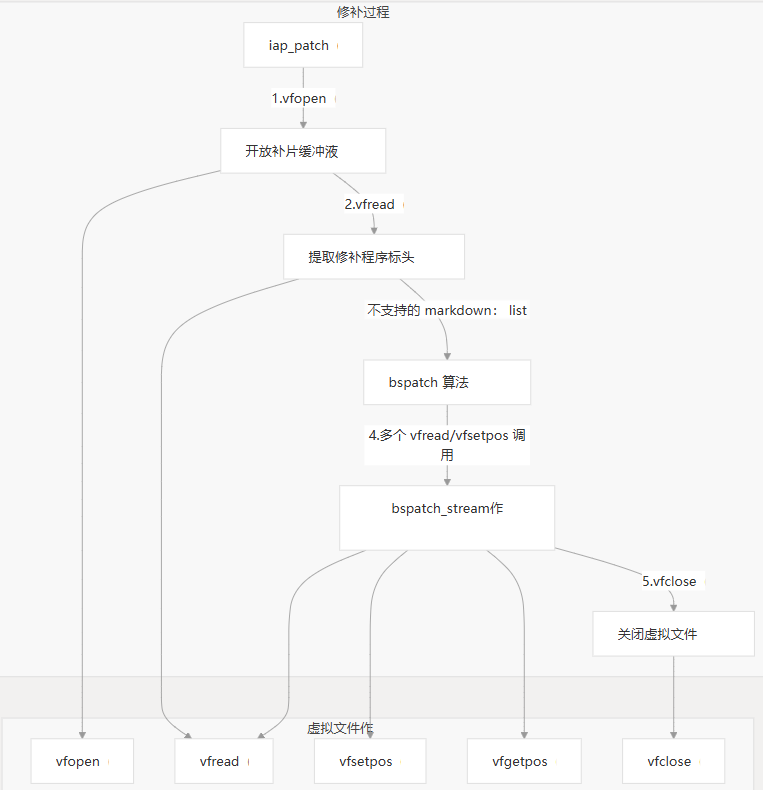
图:修补过程中的虚拟文件系统使用情况
- 修补过程开始时,将打开一个或多个虚拟文件以访问补丁数据
vfopen() - 读取 patch 标头以提取有关补丁的元数据
vfread() - bspatch 算法使用 VFS 读取压缩的数据块
- 在整个修补过程中,该算法使用 、 和 来导航补丁数据
vfread()vfsetpos()vfgetpos() - 修补完成后, 调用 以释放资源
vfclose()
示例用法
以下是虚拟文件系统的典型使用模式:
// Example patch buffer in memory
const uint8_t *patch_buffer = /* pointer to patch data */;
uint32_t patch_size = /* size of patch data */;// Open a virtual file for the patch
vFile *patch_file = vfopen(patch_buffer, patch_size);
if (patch_file == NULL) {// Handle errorreturn ERROR_CODE;
}// Read header data
uint8_t header_buffer[HEADER_SIZE];
int bytes_read = vfread(patch_file, header_buffer, HEADER_SIZE);
if (bytes_read != HEADER_SIZE) {// Handle errorvfclose(patch_file);return ERROR_CODE;
}// Process header...// Skip to a specific position in the file
vfsetpos(patch_file, data_offset);// Read data block
uint8_t data_buffer[BLOCK_SIZE];
bytes_read = vfread(patch_file, data_buffer, BLOCK_SIZE);// Process data...// Get current position
uint32_t current_pos;
vfgetpos(patch_file, ¤t_pos);// Clean up
vfclose(patch_file);此示例演示了使用 Virtual File System 时的典型作顺序。
内存注意事项
虚拟文件系统设计为非常轻量级,使其适用于资源受限的嵌入式系统:
- 最小内存开销:该结构仅为 12 字节(
vFilecurptroffsetsize) - 无内部缓冲:VFS 不维护任何内部缓冲区;它直接在提供的内存上运行
- 尽可能零复制:该函数返回指向缓冲区中当前位置的直接指针,允许在适当时进行零复制访问
vfgetpos() - 边界检查:该函数包括边界检查,以防止读取超出缓冲区末尾
vfread()
这些特性使 Virtual File System 成为在 RAM 有限的嵌入式设备上执行固件更新作的理想解决方案。
总结
虚拟文件系统是一个简单而强大的抽象,它提供对 MCU BSDiff 升级系统中内存缓冲区的类似文件的访问。其轻量级设计、与平台无关的内存管理和全面的 API 使其非常适合嵌入式应用,尤其是在固件差异更新的情况下。
主要优势包括:
- 通过轻量级实现最大限度地减少 RAM 使用
- 提供熟悉的文件作以使用内存缓冲区
- 通过依赖关系注入与自定义内存管理集成
- 支持高效处理固件更新的补丁数据
通过将内存抽象为文件,虚拟文件系统弥合了 BSDiff 修补算法的面向文件的设计与嵌入式系统以内存为中心的性质之间的差距。
LZMA 压缩
目的和范围
本文档介绍了 MCU BSDiff 升级机制中使用的 LZMA(Lempel-Ziv-Markov 链算法)压缩系统。它解释了如何将 LZMA 压缩集成到修补系统中以减小固件更新包的大小。
贴片系统中的 LZMA 概述
LZMA 是一种压缩算法,以其高压缩率和解压缩速度而闻名,非常适合带宽有限但处理能力合理的嵌入式系统。在 MCU BSDiff 升级系统中,LZMA 压缩应用于固件补丁数据,以最大限度地减少传输大小。
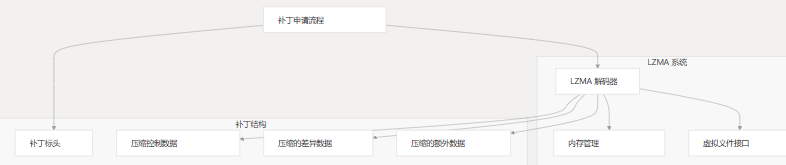
LZMA 组件架构
MCU BSDiff 升级中的 LZMA 子系统由多个组件组成,这些组件协同工作以提供高效的解压缩功能。
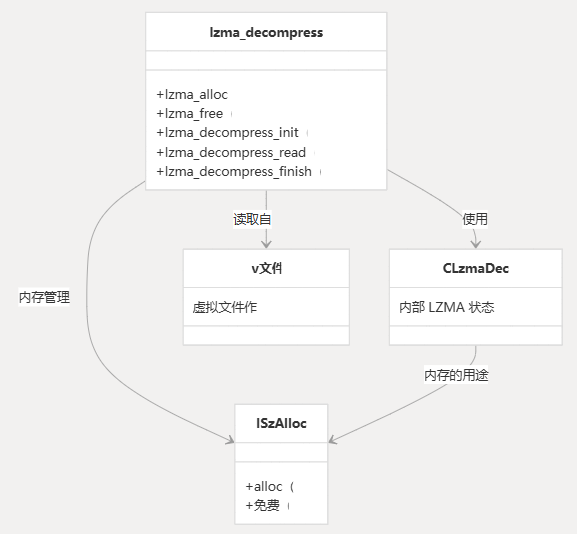
内存管理
LZMA 解压缩需要内存来存储其内部状态和工作缓冲区。系统实现自定义内存分配接口,以优化受限设备上的内存使用。
分配接口包括:
lzma_alloc- 为 LZMA 解压缩器分配内存lzma_free- 释放分配给 LZMA作的内存
这两个函数都包装了系统提供的虚拟内存分配器 ( 和 )。vmallocvfree
struct ISzAlloc {void *(*Alloc)(void *p, size_t size);void (*Free)(void *p, void *address);
};
| 功能 | 目的 | 实现 |
|---|---|---|
lzma_alloc | 为 LZMA 分配内存 | 调用和可选的调试日志记录vmalloc |
lzma_free | 释放 LZMA 使用的内存 | 调用和可选的调试日志记录vfree |
ISzAlloc allocator | 全局分配结构 | 指向上述分配函数 |
减压过程
LZMA 解压缩过程涉及从初始化到数据提取的几个步骤。该系统以适用于嵌入式设备的内存高效方式实现此过程。
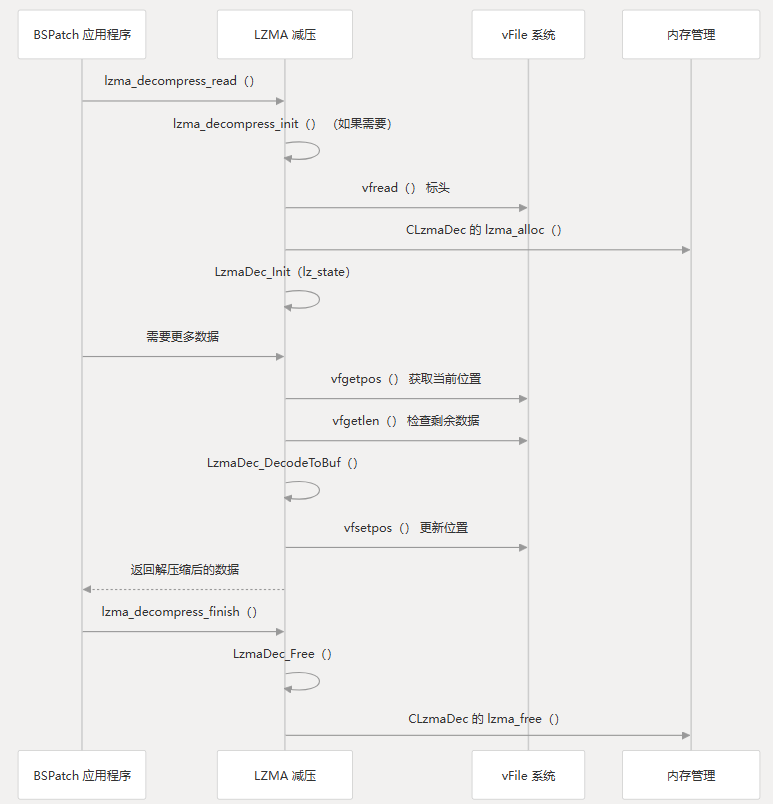
LZMA 解压缩初始化
初始化过程 () 通过以下方式准备 LZMA 解码器以进行作:lzma_decompress_init
- 读取 LZMA properties 标头(9 字节:5 字节属性 + 8 字节未压缩大小)
- 分配和初始化 LZMA 解码器状态
- 设置解码器的属性
Header Structure:
- LZMA properties (5 bytes)
- Uncompressed size (8 bytes, little-endian)LZMA 数据解压缩
该函数负责按需解压缩数据。它遵循以下步骤:lzma_decompress_read
- 确保解压缩器已初始化
- 获取源数据中的当前位置
- 确定要处理的压缩数据量
- 调用 解压数据
LzmaDec_DecodeToBuf - 更新虚拟文件位置
- 返回解压后的数据量
此函数与虚拟文件系统连接以读取压缩数据,通常由 bspatch 系统调用以从补丁中提取控制、差异和额外数据。
与 Patch 应用程序集成
LZMA 解压缩是补丁应用程序过程的关键组成部分。下图显示了 LZMA 如何适应整个修补系统:

内存使用注意事项
LZMA 解压缩需要一定数量的内存来存储其内部状态和工作缓冲区。该实现包括用于跟踪内存使用情况的可选调试功能:
#ifdef LZMA_RAM_USE_DEBUG
static int ram_used_size = 0;
static int ram_used_max = 0;
#endif
可以通过取消注释定义来启用内存使用情况报告,这将跟踪:LZMA_RAM_USE_DEBUG
- 当前内存使用情况
- 最大内存使用峰值
这对于在内存受限的环境中优化内存分配非常有用。
LZMA 状态管理
该实现维护一个静态 LZMA 解码器状态指针 (),该指针在初始化期间分配,在清理期间释放。此状态包含:lz_state
- LZMA 解码器上下文
- 当前流的属性
- 用于解压缩过程的内部缓冲区
static CLzmaDec *lz_state = NULL;
正确初始化和清理此状态对于防止内存泄漏和确保跨多个补丁应用程序正确运行至关重要。
结论
LZMA 压缩是 MCU BSDiff 升级系统的关键组件,提供补丁数据的高效压缩,以最大限度地降低传输成本。该实施侧重于内存效率和与虚拟文件系统的集成,以支持受限嵌入式设备上的固件更新。
LZMA 子系统主要用于设备端的解压缩,具有以下关键功能:
lzma_decompress_init:初始化 LZMA 解码器lzma_decompress_read:按需读取和解压缩数据lzma_decompress_finish:解压缩完成后清理资源
LZMA 解码器
目的和角色
LZMA 解码器在补丁应用过程中充当关键组件,与虚拟文件系统 (VFile) 和 BSPatch 实现 (BSDiff/BSPatch 实现) 一起工作。它提供了一种高效的解压缩机制,使补丁系统能够:
- 从补丁文件中读取和解析 LZMA 压缩的数据
- 根据 BSPatch 算法的要求解压缩 control、diff 和额外的数据序列
- 在受限的 MCU 环境中高效管理内存资源
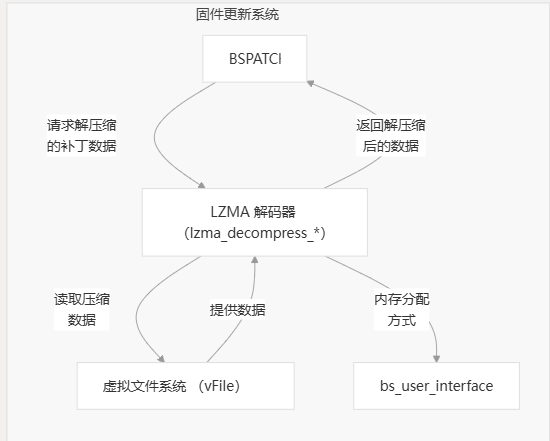
核心组件
LZMA 解码器实现由两个主要部分组成:
- High-level Interface:提供与 Virtual File System 集成的函数
lzma_decompress.c - 核心 LZMA 引擎:LZMA 解压缩实现
LzmaDec.c
关键数据结构
LZMA 解码器使用的核心数据结构是 state 对象:CLzmaDec
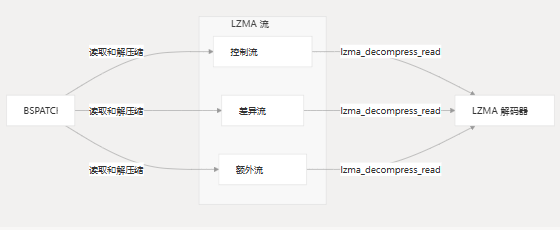
解压缩工作流
LZMA 解压缩过程遵循特定的作顺序:

内存管理
LZMA 解码器实现自定义内存管理,以与系统的内存分配功能集成:
解码器维护一个静态对象,以在多个解压缩调用之间保留状态:lz_state
static CLzmaDec *lz_state = NULL;主要功能及其作用
| 功能 | 目的 | 源 |
|---|---|---|
lzma_decompress_init() | 初始化 LZMA 解码器状态,读取和解析 LZMA 标头 | lzma/lzma_decompress.c54-97 |
lzma_decompress_read() | Main 函数解压数据,返回解压后数据的大小 | lzma/lzma_decompress.c99-156 |
lzma_decompress_finish() | 释放 LZMA 解码器使用的所有资源 | lzma/lzma_decompress.c158-167 |
lzma_alloc() | LZMA 解码器的自定义分配器函数 | lzma/lzma_decompress.c19-37 |
lzma_free() | LZMA 解码器的自定义免费功能 | lzma/lzma_decompress.c39-49 |
LZMA 标头结构
补丁文件中的 LZMA 压缩数据以包含压缩属性和未压缩大小的标头开头:
+---------------+------------------+
| LZMA Props | Uncompressed Size|
| (5 bytes) | (8 bytes) |
+---------------+------------------+
标头解析为 :lzma_decompress_init()
uint8_t header[LZMA_PROPS_SIZE + 8]; vfread(pf, header, headerSize);标头包含:
- LZMA 属性(5 字节)- 包含 lc、lp、pb 参数和字典大小
- Uncompressed size (8 bytes, little-endian) - 解压缩数据的总大小
在 BSPatch 上下文中的使用
BSPatch 算法使用 LZMA 解码器来解压缩三种类型的数据:
- Control data - 补丁过程的说明
- 差异数据 - 要应用于原始文件的差异
- Extra data - 要插入的新数据
这些数据流中的每一个都使用 LZMA 进行压缩,并且必须在补丁应用期间解压缩。
集成要求
要将 LZMA 解码器集成到您的系统中,请确保:
- 虚拟文件系统已正确实现,以提供对内存缓冲区的类似文件的访问
- 内存分配函数 ( 和 ) 可用
vmallocvfree - LZMA 压缩数据包括正确的标头(LZMA 属性 + 未压缩的大小)
典型的使用模式是:
// Create virtual file from compressed data
vFile *pf = create_virtual_file(compressed_data, size);// Allocate output buffer
uint8_t *buffer = vmalloc(output_buffer_size);// Decompress data
int decompressed_size = lzma_decompress_read(pf, buffer, output_buffer_size);// Use decompressed data
// ...// Cleanup
lzma_decompress_finish();资源注意事项
LZMA 解码器在实现时考虑了资源受限的 MCU 环境:
- 内存使用情况:解码器在调用之间保持最小状态
- 分块处理:数据可以分块解压缩,以最大限度地减少内存需求
- 可选调试:可以使用定义
LZMA_RAM_USE_DEBUG
与 BSPatch 的关系
LZMA 解码器是 BSPatch 流程中的关键组件,因为它能够高效存储和传输补丁数据。二进制 diff patch 格式使用 LZMA 压缩来减小 control、diff 和 extra 数据流的大小。
LZMA 编码器
本页记录了 MCU BSDiff 升级系统中使用的 LZMA (Lempel-Ziv-Markov chain Algorithm) 编码器组件。编码器负责在补丁创建期间压缩数据,该过程发生在主机端,而不是目标设备上。
目的和角色
LZMA 编码器压缩二进制差分数据以显著减小补丁大小。在 MCU BSDiff 升级系统中,编码器专门用于在主机上生成补丁,而只有解码器集成到嵌入式设备固件中。这种资源分配针对嵌入式应用程序进行了优化,在这些应用程序中,设备端压缩会占用大量资源。
架构概述
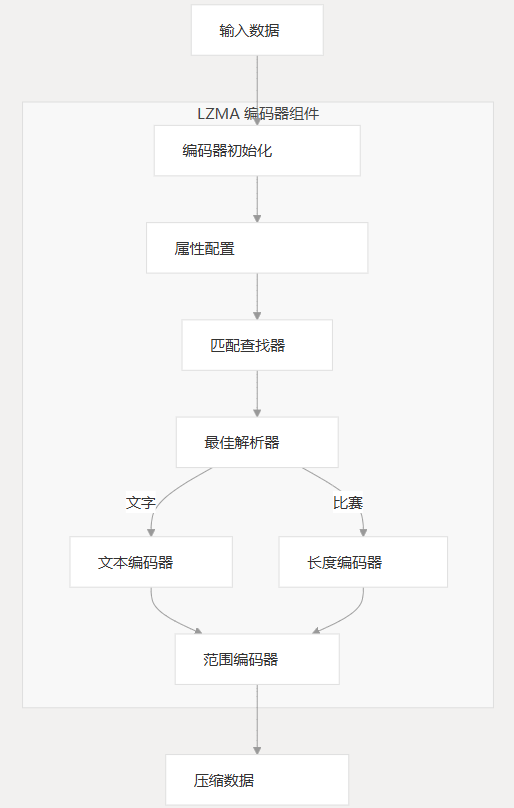
LZMA 编码器实现了一种复杂的压缩算法,该算法将基于字典的压缩(类似于 LZ77)与范围编码相结合。它处理输入数据以查找重复的模式,然后使用统计建模有效地对这些模式进行编码,以实现高压缩率。
关键数据结构
LZMA 编码器使用几个核心数据结构来维护其状态和配置:
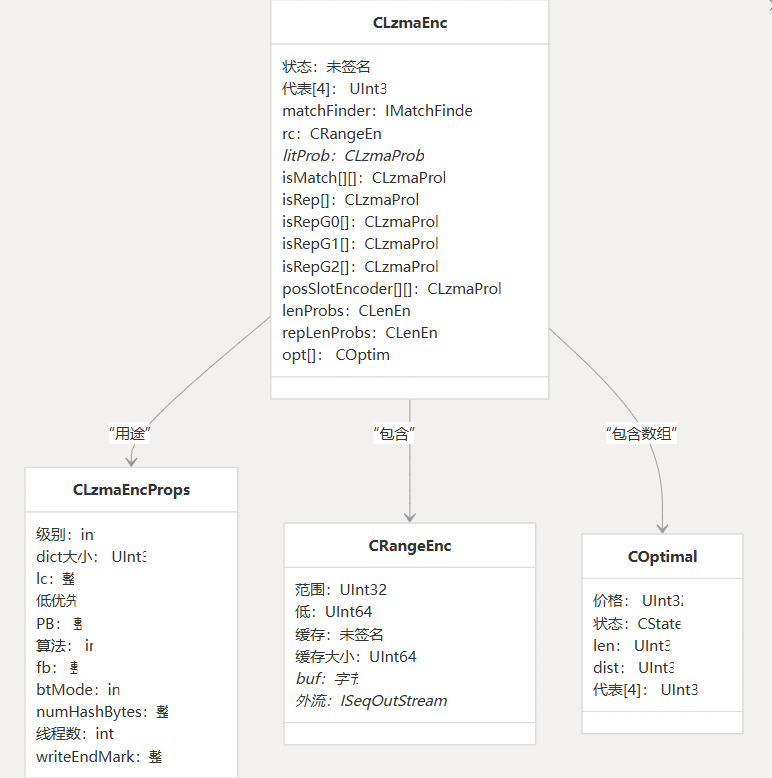
配置参数
LZMA 编码器可以通过影响压缩率和性能的几个参数进行配置:
| 参数 | 描述 | 违约 | 范围 | 冲击 |
|---|---|---|---|---|
level | 压缩级别 | 5 | 0-9 | 值越高,压缩效果越好,但速度越慢 |
dictSize | 字典大小(以字节为单位) | 级别相关 | 4KB-4GB | 较大的词典可以提高压缩率,但会占用更多内存 |
lc | 文本上下文位数 | 3 | 0-8 | 影响文本编码适应数据的方式 |
lp | 文本位置位数 | 0 | 0-4 | 影响 position 如何影响 Literals encoding |
pb | 位置位数 | 2 | 0-4 | 影响位置状态的计算方式 |
algo | 算法变体 | 级别相关 | 0-1 | 0 = 快速,1 = 正常(更好的压缩) |
fb | 快速字节数 | 级别相关 | 5-273 | 更多的字节可以提高压缩率,但速度更慢 |
btMode | 二叉树模式 | 级别相关 | 0-1 | 1=二叉树,0=哈希链 |
编码过程
LZMA 编码过程包括几个步骤,从初始化到生成压缩输出:
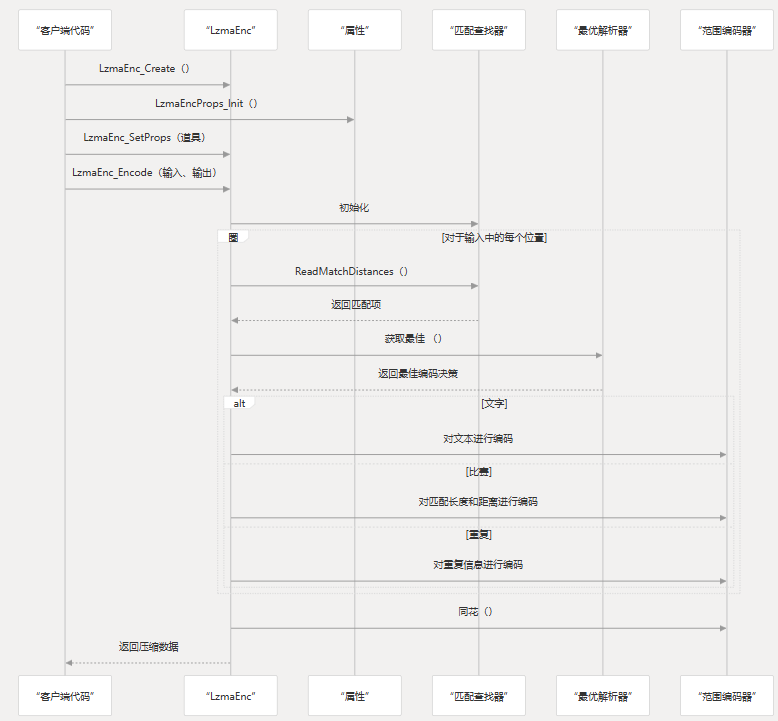
匹配查找和最优解析
LZMA 压缩的一个关键部分是查找重复序列(匹配项)并确定编码数据的最佳方式:
-
匹配查找:编码器使用二叉树或哈希链结构来有效地在先前处理的数据中查找匹配的序列。
-
最佳解析:编码器评估多种编码可能性,以找到位成本最低的编码路径:
- 将字节编码为文本
- 将序列编码为匹配项(具有长度和距离)
- 将序列编码为最近使用的匹配项的重复
编码器维护一个价格模型,该模型估计不同编码决策的位成本,并选择总体成本最低的路径。
范围编码器
LZMA 编码器使用范围编码器对 bitstream的决策进行最终编码:
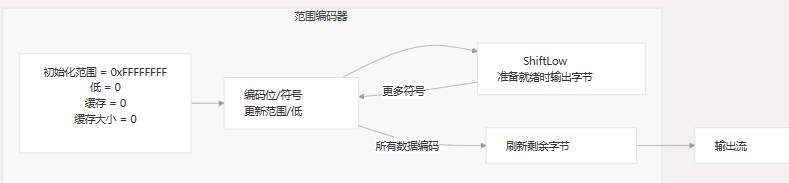
范围编码器维护内部状态变量:
range:当前范围 (初始化为 0xFFFFFFFF)low:电流范围的下限cache:确认后要输出的字节cacheSize: 待处理位数
与 BSDiff 系统集成
在 MCU BSDiff 升级系统中,LZMA 编码器在主机上创建补丁时使用:
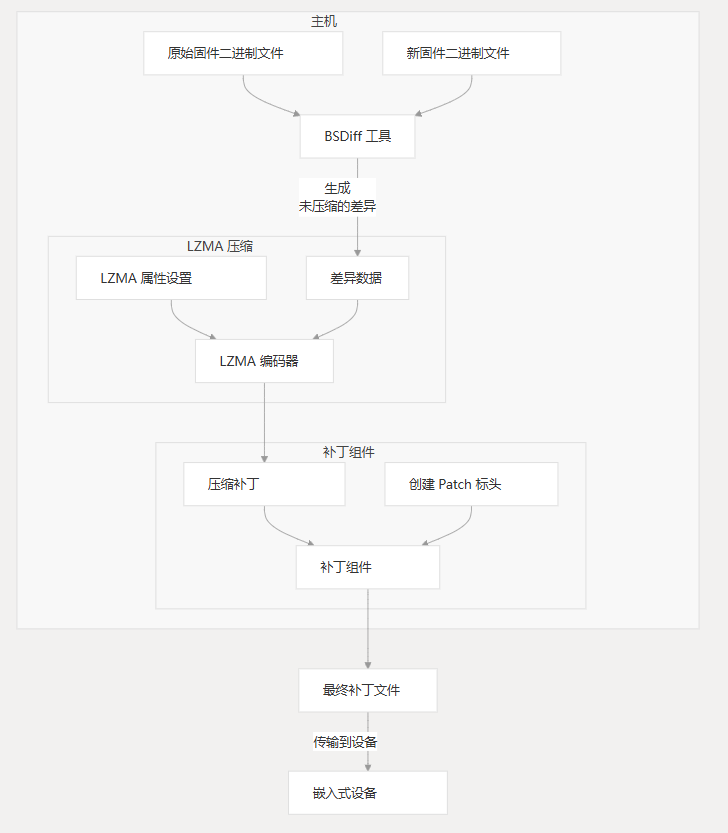
API 函数
LZMA 编码器提供以下关键功能:
| 功能 | 描述 |
|---|---|
LzmaEnc_Create | 创建并分配 LZMA 编码器实例 |
LzmaEnc_Destroy | 释放编码器使用的资源 |
LzmaEnc_SetProps | 使用指定的属性配置编码器 |
LzmaEnc_Encode | 将数据从输入流压缩到输出流 |
LzmaEnc_MemEncode | 编码函数的内存到内存版本 |
LzmaEnc_WriteProperties | 将编码器属性写入输出(解压缩需要) |
LzmaEncProps_Init | 使用默认值初始化编码器属性 |
LzmaEncProps_Normalize | 将编码器属性规范化为有效值 |
性能注意事项
使用 LZMA 编码器创建 Patch 时,请考虑以下性能因素:
- 内存使用:较高的压缩级别和较大的字典大小需要更多的内存。
- 压缩时间:压缩级别越高,需要的处理时间就越长。
- 压缩比:LZMA 编码器可以实现高压缩比,特别是对于固件映像中常见的重复二进制数据。
- 多线程处理:对于主机环境,编码器可以使用多个线程来提高性能(如果进行了相应的设置)。
numThreads
总结
LZMA 编码器为 MCU BSDiff 升级系统的补丁创建过程提供高压缩功能。它在主机侧运行,以生成紧凑的补丁,这些补丁可以在目标嵌入式设备上进行有效解压缩。编码器的可配置性允许根据应用要求平衡压缩比与性能。
集成指南
本指南提供了将 MCU BSDiff 升级库集成到嵌入式应用中的详细说明。它涵盖了将差分固件更新功能整合到设备中的必要步骤。
系统要求
在集成 MCU BSDiff 升级库之前,请确保您的系统满足以下要求:
- RAM:修补过程至少 10KB 可用 RAM
- ROM/Flash:大约 5KB 用于库代码
- Flash 写入功能:您的系统必须提供一种写入编程 Flash 存储器的方法
- 内存管理:您的系统需要支持动态内存分配和释放
集成过程概述
下图说明了 MCU BSDiff 升级系统的集成工作流程:
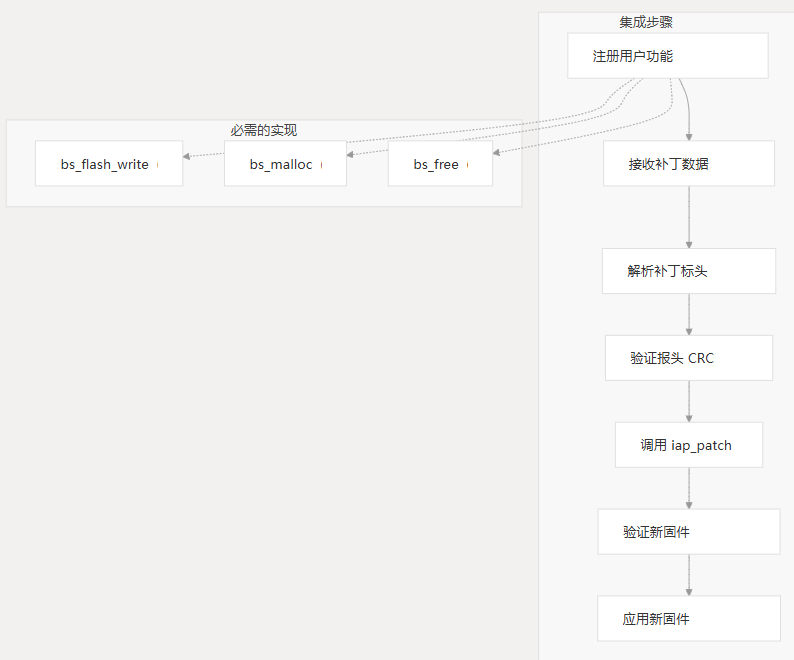
步骤 1:注册所需函数
集成的第一步是注册所需的用户功能。您必须提供三个基本功能:
- Flash 写入功能:将数据写入 Flash 存储器
- Memory Allocation Function:从堆中分配内存
- 内存释放功能:释放分配的内存
这些函数通过使用结构体的函数进行注册。bs_user_func_register() bs_user_interface
注册码示例
下面是如何注册这些函数的示例:
void UpgradeInit(void)
{bs_user_interface bsFunc;bsFunc.bs_flash_write = my_flash_write;bsFunc.bs_malloc = my_malloc_function;bsFunc.bs_free = my_free_function;bs_user_func_register(&bsFunc);
}第 2 步:实现所需的功能
Flash 写入功能
flash write 函数必须同时处理对 flash 存储器的擦除和写入。函数原型为:
int my_flash_write(uint32_t addr, const unsigned char *p, uint32_t len);此函数应:
- 如有必要,擦除闪存扇区
- 将数据写入指定地址的 flash
- 成功时返回 0,失败时返回非零
重要提示:此功能必须包括 Flash 擦除逻辑,因为库本身不处理 Flash 擦除。
内存分配和释放
内存分配和释放函数遵循标准的 malloc/free 模式:
void *my_malloc_function(uint32_t size); void my_free_function(void *ptr);请注意,修补过程可能需要高达 20KB 的堆内存。如果您的系统 RAM 有限,则可能需要通过修改源代码来减小缓冲区大小来优化补丁应用程序。
内存分配和释放
内存分配和释放函数遵循标准的 malloc/free 模式:
void *my_malloc_function(uint32_t size); void my_free_function(void *ptr);请注意,修补过程可能需要高达 20KB 的堆内存。如果您的系统 RAM 有限,则可能需要通过修改源代码来减小缓冲区大小来优化补丁应用程序。
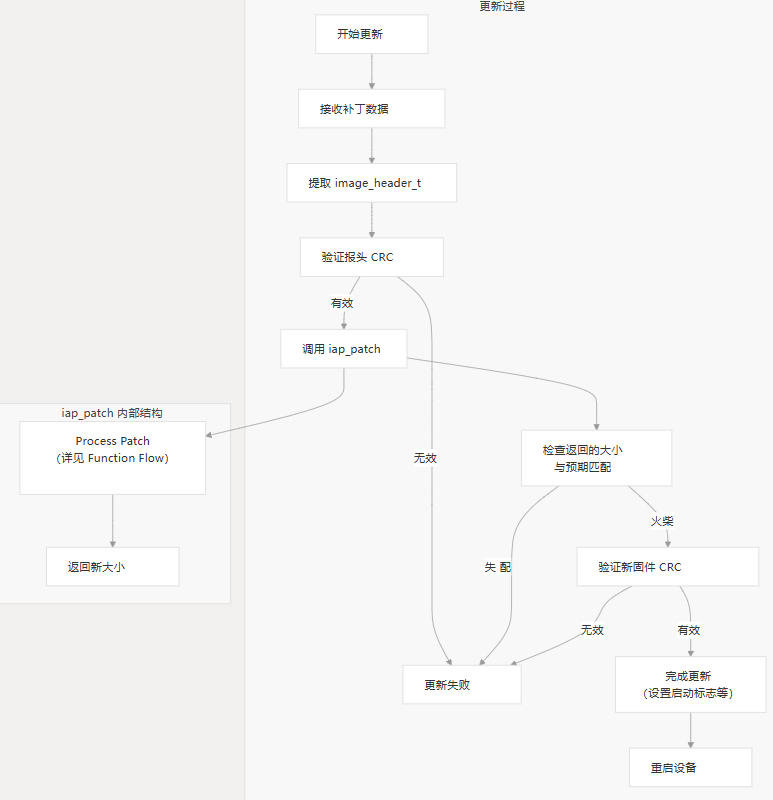
步骤 3:处理补丁数据
补丁文件结构
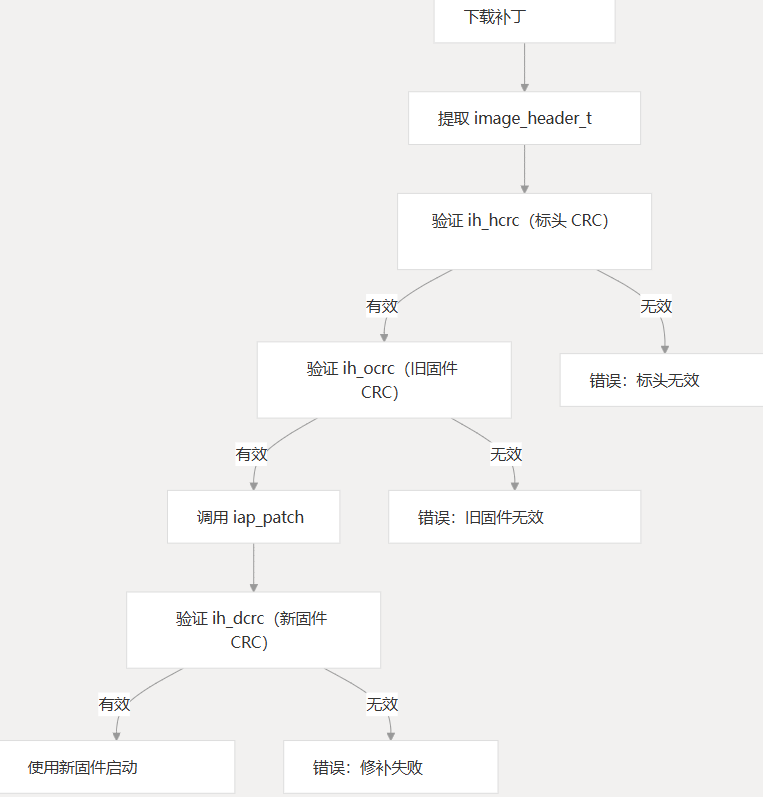
补丁文件包括一个标头结构 (),后跟实际的补丁数据:image_header_t
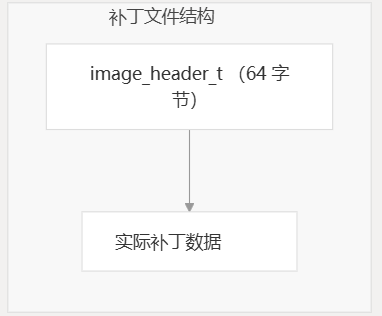
该结构包含关键信息:image_header_t
| 田 | 描述 |
|---|---|
| ih_magic | 用于验证的幻数 |
| ih_hcrc | 标头 CRC 校验和 |
| ih_size | 补丁数据的大小 |
| ih_load | 旧固件的大小 |
| ih_ep | 新固件的大小 |
| ih_dcrc | 新固件的 CRC |
| ih_ocrc | 旧固件的 CRC |
提取和验证标头信息
在应用补丁之前,您应该提取并验证标头信息:
- 从收到的补丁数据中复制标头
- 验证标头 CRC
- 根据预期值检查旧固件 CRC
- 如果需要,将值从 big-endian 转换为 little-endian
第 4 步:应用补丁
修补过程的核心是功能:iap_patch()
int iap_patch(const uint8_t *old, uint32_t oldsize, const uint8_t *patch,uint32_t patchsize, uint32_t newfile_addr);参数:
old:指向内存中旧固件的指针oldsize:旧固件的大小patch:指向补丁数据的指针(不带标头)patchsize:补丁数据的大小newfile_addr:应写入新固件的地址
返回值:
- 成功时新固件的大小
- 失败时出现错误代码

第 5 步:验证并应用新固件
应用补丁后,您应该:
- 验证新固件的 CRC
- 如果需要,将新固件复制到执行区域
- 设置适当的标志以从新固件引导
- 重新启动设备
完整的集成示例
以下是完整集成过程的概念示例:
// 1. Initialize the upgrade module
void UpgradeInit(void) {bs_user_interface bsFunc;bsFunc.bs_flash_write = MyFlashWrite;bsFunc.bs_malloc = MyMalloc;bsFunc.bs_free = MyFree;bs_user_func_register(&bsFunc);
}// 2. Process received patch data
bool ProcessPatchData(uint32_t patchDataAddr, uint32_t patchSize) {// Extract headerimage_header_t header;memcpy(&header, (uint8_t*)patchDataAddr, sizeof(image_header_t));// Verify header CRCuint32_t headerCrc = header.ih_hcrc;header.ih_hcrc = 0;if (headerCrc != crc32((uint8_t*)&header, sizeof(image_header_t))) {return false;}// Verify old firmware CRCif (crc32((uint8_t*)FIRMWARE_EXECUTION_ADDR, header.ih_load) != header.ih_ocrc) {return false;}// Apply patchuint32_t newSize = iap_patch((uint8_t*)FIRMWARE_EXECUTION_ADDR,header.ih_load,(uint8_t*)(patchDataAddr + sizeof(image_header_t)),header.ih_size,FIRMWARE_UPGRADE_ADDR);// Verify new firmware size and CRCif (newSize != header.ih_ep) {return false;}if (crc32((uint8_t*)FIRMWARE_UPGRADE_ADDR, header.ih_ep) != header.ih_dcrc) {return false;}// Set boot flags and rebootSetBootFromUpgradePartition();SystemReboot();return true;
}内存使用注意事项
MCU BSDiff 升级库需要仔细的内存管理:
| 内存类型 | 最低要求 | 推荐 |
|---|---|---|
| RAM (堆) | 10KB | 20KB |
| ROM/闪存 | 5KB | 5KB |
如果您的设备具有严格的 RAM 限制,请考虑:
- 在升级过程中增加堆大小
- 在修补期间禁用非关键任务或功能
- 修改库代码以减小缓冲区大小(默认情况下,补丁以 1KB 块处理)
错误处理
修补过程可能会遇到多种类型的错误。以下是处理它们的方法:
| 错误条件 | 检测方法 | 建议的作 |
|---|---|---|
| 标头 CRC 不匹配 | CRC 验证失败 | 中止并请求新补丁 |
| 旧固件 CRC 不匹配 | 计算的 CRC != ih_ocrc | 中止,基本固件不正确 |
| 修补应用程序失败 | iap_patch 返回错误的大小 | 中止并记录错误详细信息 |
| 新固件 CRC 不匹配 | 计算的 CRC != ih_dcrc | Abort,补丁可能已损坏 |
用户界面实现
本页介绍如何实现 MCU BSDiff 升级系统所需的用户界面功能。这些函数提供了必要的硬件抽象层,允许 differential update library 在各种微控制器平台上工作。
概述
MCU BSDiff 升级系统需要用户提供的三个关键功能才能与特定于平台的硬件配合使用:
- Flash Writing - 将数据写入 Flash 存储器
- Memory Allocation - 为临时缓冲区分配内存
- 内存释放 - 释放分配的内存
这些功能必须由用户实现,并在使用修补功能之前向系统注册。

所需的用户界面功能
系统需要三个用户实现的函数,在使用修补功能之前必须注册这些函数:
Flash 写入功能
typedef int (*bs_flash_write_func)(uint32_t addr, const unsigned char *p, uint32_t len);此函数将数据写入指定地址的闪存。它应该包括写入之前任何必要的 flash 擦除作。
参数:
addr:要写入的闪存地址p:指向要写入的数据的指针len:要写入的数据的长度
返回值:
0:成功- 其他值: Error code
重要的实施注意事项:
- 该函数应处理任何必需的闪存擦除作
- 它必须确保特定 MCU 所需的正确对齐和写入大小
- 如果在多线程环境中使用,则实现必须是线程安全的
内存分配功能
typedef void *(*bs_malloc_func)(uint32_t size);此函数为修补过程中使用的临时缓冲区分配内存。
参数:
size:要分配的内存大小(以字节为单位)
返回值:
- 非 NULL 指针:内存分配成功
- NULL 指针:内存分配失败
重要的实施注意事项:
- 系统最多可以请求大约 20KB 的堆空间
- 内存分配失败将导致整个修补过程失败
- 实施应确保与目标平台正确对齐
无记忆功能
typedef void (*bs_free_func)(void *ptr);此函数可释放以前分配的内存。
参数:
ptr:指向要释放的内存块的指针
重要的实施注意事项:
- 必须正确释放先前由相应 malloc 函数分配的内存
- 应正常处理 NULL 指针
- 必须与内存分配功能兼容
函数注册流程
在使用修补功能之前,您必须使用该函数向系统注册所需函数的实现。bs_user_func_register()
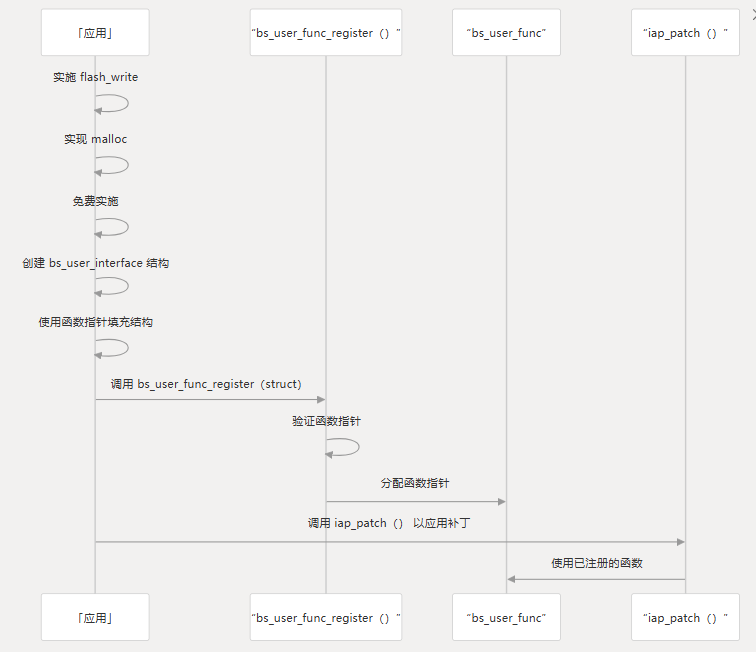
注册示例
下面是如何注册所需函数的实现的示例:
void UpgradeInit(void)
{bs_user_interface bsFunc;bsFunc.bs_flash_write = xmq25qxxWrite;bsFunc.bs_malloc = (bs_malloc_func)pvPortMalloc;bsFunc.bs_free = vPortFree;bs_user_func_register(&bsFunc);
}在此示例中:
xmq25qxxWrite是用户的 flash 写入功能pvPortMalloc是用户的内存分配函数(可能来自 FreeRTOS)vPortFree是用户的内存释放函数(可能来自 FreeRTOS)
内存要求和注意事项
MCU BSDiff 系统需要大量的 RAM 来执行差分修补。了解这些要求对于成功实施至关重要。
| 资源 | 最低要求 | 推荐 |
|---|---|---|
| RAM | ≥ 10KB | ≥ 20KB |
| 堆 | ~20KB 用于分配 | ~20KB |
| 只读存储器 | ~5KB 代码 | ~5KB |
内存分配模式
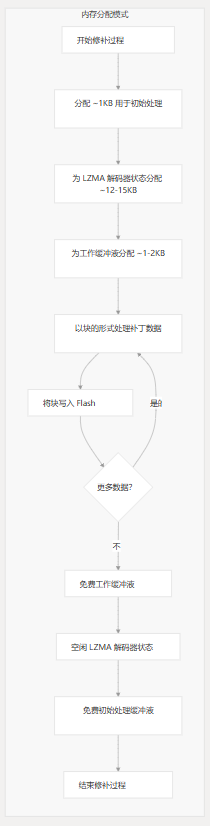
常见的内存相关问题
- 堆空间不足:最常见的问题是没有为修补过程提供足够的堆内存。
- 碎片化:长时间运行的系统可能会遇到堆碎片化,从而难以分配大型连续块。
- 自定义 Malloc 实现问题:实现自己的内存分配函数的用户有时会在这些实现中遇到 bug。
要解决内存问题:
- 使用更大的堆(至少 20KB)进行测试
- 修改源码以减小 chunk 大小以进行恢复(默认为 1KB)
- 检查您的内存分配实现是否存在错误
闪存注意事项
必须谨慎实现 flash 写入功能,以确保可靠的固件更新。
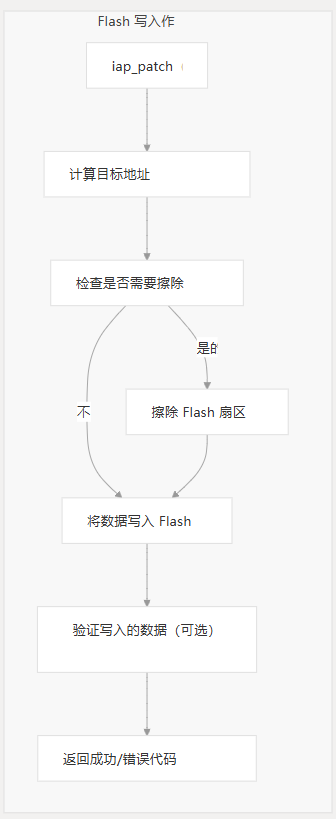
重要的 Flash 注意事项
- 写入前擦除:大多数闪存需要在写入前擦除。您的 flash write 函数应该可以处理这个问题。
- 对齐要求:许多 MCU 对闪存作有特定的对齐要求。
- 写入大小限制:某些闪存控制器需要写入特定的字长(例如,一次 4 个字节)。
- 写保护:确保在写入之前正确禁用任何写保护机制。
- 验证:考虑添加验证以确保数据写入正确。
集成流程
以下序列图显示了在补丁应用程序过程中如何使用用户界面功能:
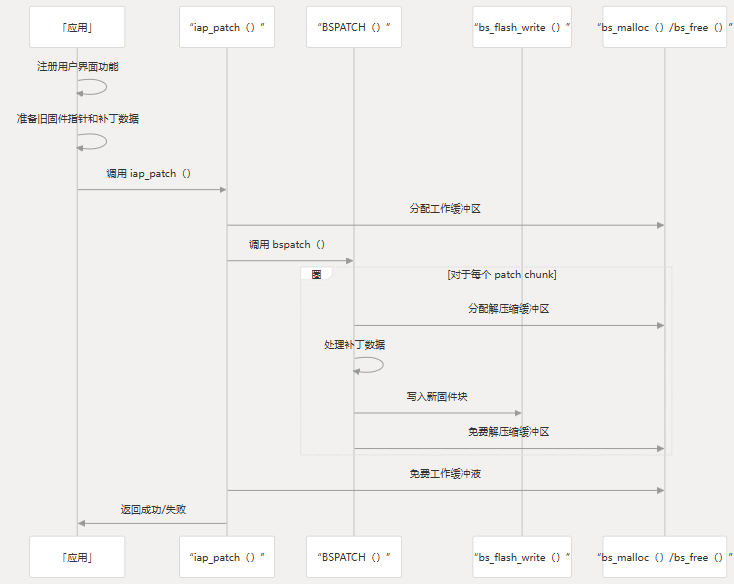
完整的实施示例
下表显示了需要实施的关键组件:
| 元件 | 目的 | 必需的实施 |
|---|---|---|
| Flash 写入功能 | 将数据写入闪存 | 处理擦除、对齐和写入 |
| 内存分配 | 提供临时缓冲区 | 分配正确对齐的内存块 |
| 内存释放 | 释放临时缓冲区 | 释放分配的内存,无泄漏 |
| 注册功能 | 将功能连接到系统 | 在使用 patch 函数之前调用一次 |
典型的集成工作流程包括:
- 实现 3 个必需的功能
- 创建并填充结构
bs_user_interface - 使用 注册函数
bs_user_func_register() - 在应用补丁时使用适当的参数调用
iap_patch()
常见问题和疑难解答
内存相关问题
-
“malloc failed” 错误
- 增加堆大小(建议至少 20KB)
- 通过优化其他位置的内存使用来减少碎片
- 检查自定义 malloc 实现是否存在错误
-
堆栈溢出
- 增加执行更新的任务的堆栈大小
- 考虑将大型缓冲区从堆栈移动到堆
Flash 相关问题
-
写入失败
- 确保在写入前正确擦除
- 检查对齐方式和大小要求
- 验证 Flash Protection 是否已禁用
-
验证失败
- 在 flash 写入功能中实现 CRC 或其他验证
- 检查闪存的硬件问题
总结
正确实现用户界面功能对于 MCU BSDiff 升级系统正常工作至关重要。这三个必需的函数提供了必要的硬件抽象,以允许系统跨不同的 MCU 平台工作。
要记住的要点:
- 在使用修补功能之前实现并注册所有三个必需的函数
- 确保有足够的堆空间(建议至少 20KB)
- 在 flash 写入功能中处理 flash 擦除作
- 使用特定硬件平台进行全面测试
数据类型和结构
本页记录了整个 MCU BSDiff 升级系统使用的关键数据类型和结构。了解这些类型对于在嵌入式项目中有效地集成和使用库至关重要。
核心类型定义
系统使用标准 C 类型,以实现一致的跨平台行为。在处理二进制数据时,提供了以下宏用于字节序转换:stdint.h
BigtoLittle16(x): Converts a 16-bit value between big and little endian
BigtoLittle32(x): Converts a 32-bit value between big and little endian
在处理 patch 标头时,这些转换尤为重要,因为其字段以 big-endian 格式存储
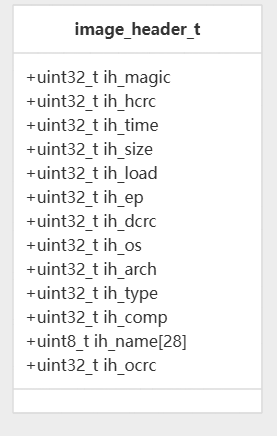
图像标题结构
该结构存储有关差异补丁的元数据。此标头由修补程序生成工具自动添加到每个修补程序文件的开头。image_header_t
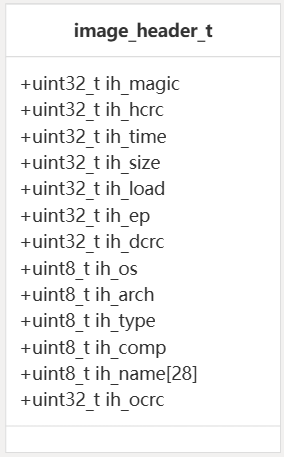
| 田 | 描述 |
|---|---|
ih_magic | 用于标头识别的幻数 |
ih_hcrc | 标头的 CRC 校验和(大端) |
ih_time | 创建时间戳 |
ih_size | 差异补丁数据的大小 (big endian) |
ih_load | 旧固件的大小 |
ih_ep | 新固件的大小 |
ih_dcrc | 新固件的 CRC 校验和(大端) |
ih_os, , ,ih_archih_typeih_comp | 系统标识符 |
ih_name | 图像的名称标识符 (28 字节) |
ih_ocrc | 旧固件的 CRC 校验和 (big endian) |
当设备收到补丁时,它必须解析此标头以提取必要的信息,例如新旧固件大小及其各自的 CRC 校验和以进行验证。
用户界面结构
该结构定义了 BSDiff 库和特定于硬件的代码之间的接口。它包含函数指针,库将调用这些指针来执行依赖于硬件的作。bs_user_interface

| 田 | 类型 | 描述 |
|---|---|---|
bs_flash_write | bs_flash_write_func | 将数据写入闪存的功能 |
bs_malloc | bs_malloc_func | 分配内存的函数 |
bs_free | bs_free_func | 释放内存的函数 |
在使用修补功能之前,您必须实现这些函数并使用该函数将它们注册到库中:bs_user_func_register
int bs_user_func_register(bs_user_interface *user_func);此注册步骤对于使库适应不同的硬件平台至关重要。
函数指针类型
Flash 写入功能
typedef int (*bs_flash_write_func)(uint32_t addr, const unsigned char *p, uint32_t len);此函数将数据写入 Flash 存储器。在写入之前,您的实现必须处理任何必要的 flash 擦除作。参数:
addr:要写入的 flash 地址p:指向要写入的数据的指针len:要写入的数据长度- 返回值:0 表示成功,非零表示失败
内存分配函数
typedef void *(*bs_malloc_func)(uint32_t size); typedef void (*bs_free_func)(void *ptr);这些函数在修补过程中处理动态内存分配:
bs_malloc_func:分配指定大小的内存,返回指向已分配内存的指针,失败时返回 NULLbs_free_func:释放以前分配的内存
系统在运行期间可能需要分配最多 20KB 的内存。
实用程序数据类型
该系统包括几种用于处理二进制数据的联合类型:

这些联合提供了对作为单个字节的多字节值的便捷访问:
| 联合类型 | 目的 |
|---|---|
U64_U8 | 将 64 位无符号整数作为 8 个单独的字节访问 |
F64_U8 | 将 64 位浮点值作为 8 个独立字节访问 |
U32_U8 | 将 32 位无符号整数作为 4 个单独的字节访问 |
U16_U8 | 将 16 位无符号整数作为 2 个单独的字节访问 |
I16_U8 | 将 16 位有符号整数作为 2 个单独的字节访问 |
这些联合有助于字节级作,例如字节序转换。
主要 API 功能
主要的 API 功能是 :iap_patch
int iap_patch(const uint8_t *old, uint32_t oldsize, const uint8_t *patch,uint32_t patchsize, uint32_t newfile_addr);参数:
old:指向旧固件数据的指针oldsize:旧固件的大小patch:指向补丁数据的指针(在image_header_t)patchsize:补丁数据的大小newfile_addr:应写入新固件的 Flash 地址
返回值:成功时新固件的大小,失败时为负错误代码。
集成数据流
下图说明了这些数据结构在典型应用程序中如何相互关联:
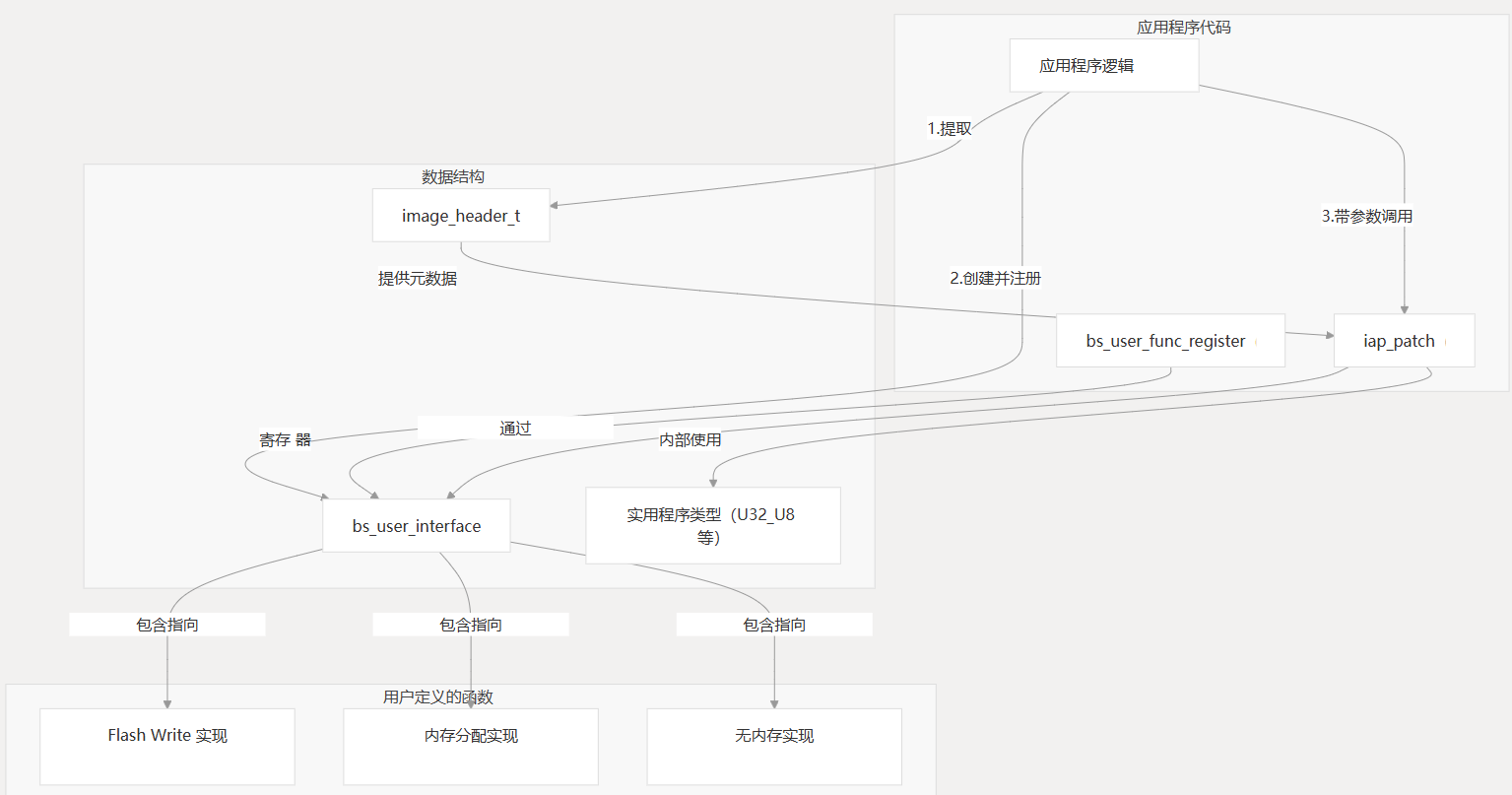
此图显示了典型的集成流程:
- 应用程序从补丁数据的开头提取
image_header_t - 应用程序创建一个结构,其中包含指向其硬件特定功能的指针
bs_user_interface - 应用程序使用
bs_user_func_register - 应用程序使用适当的参数进行调用
iap_patch - 该函数使用已注册的函数来执行硬件作
iap_patch
修补顺序
以下序列图显示了典型修补作期间的数据流:
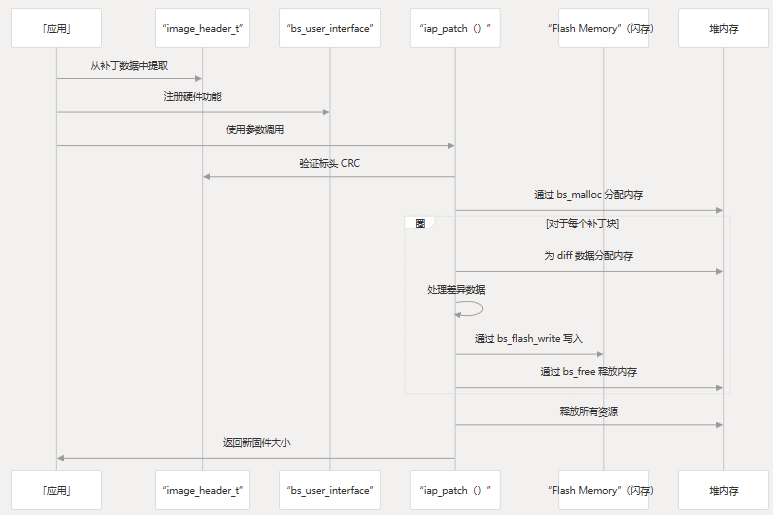
此图说明了在修补过程中如何使用各种数据结构。
内存要求
修补过程需要大量的动态内存分配。根据文档,系统通常需要大约 20KB 的堆内存。来自 README:
您可以先使用 malloc 进行测试,从而提供超过 20KB 的堆内存。如果要减少这种情况,则需要修改源代码以一次恢复较小的块(当前为 1KB)。
主要内存需求来自:
- 补丁数据的缓冲区
- LZMA 解压缩的工作内存
- diff 数据的临时存储
如果系统中的内存有限,则可能需要修改源代码以一次处理较小的块。
总结
了解这些数据类型和结构对于将 MCU BSDiff 升级系统集成到嵌入式项目中至关重要。要记住的关键点:
- 该结构包含有关补丁的元数据,位于补丁文件的开头
image_header_t - 该结构定义了硬件抽象层,必须由您实现
bs_user_interface - 函数指针类型定义了闪存作和内存管理的接口
- 实用程序联合类型有助于对多字节值进行字节级作
- 系统需要足够的堆内存(通常约为 20KB)才能运行
在实施您自己的系统时,请特别注意:
- 从收到的补丁中正确解析结构
image_header_t - 根据您的硬件实现功能
bs_user_interface - 确保有足够的内存可用于修补过程
内存管理
目的
本文档介绍了在 MCU BSDiff 升级系统中的修补过程中如何管理内存。它涵盖了内存分配架构、修补过程中使用的关键缓冲区,以及如何正确实现用户提供的内存功能。
内存要求
MCU BSDiff 升级系统在嵌入式环境典型的严格内存限制下运行:
| 资源 | 最低要求 | 推荐 | 笔记 |
|---|---|---|---|
| ram | 10KB | 20KB + | 补丁处理的主要约束 |
| 只读存储器 | 5KB | 8KB | 库的代码大小 |
系统使用固定大小的缓冲区以块的形式处理补丁数据,这有助于管理受限设备上的内存使用情况。
内存分配架构
MCU BSDiff 升级系统实现了分层内存管理方法:
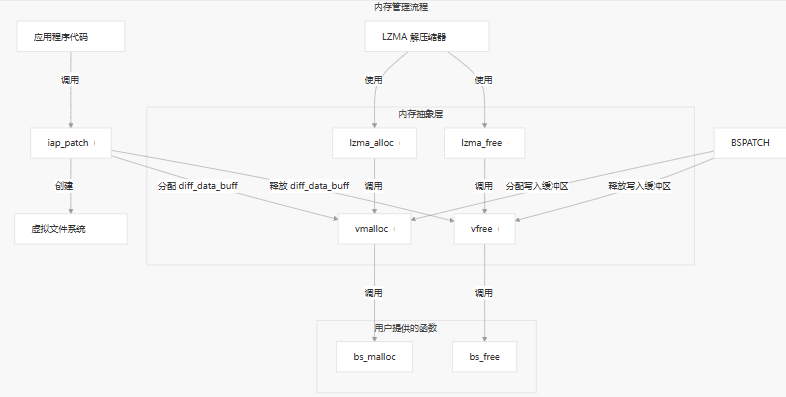
Key Memory Buffers
差分数据缓冲器
此缓冲区在将解压缩的补丁数据应用于旧固件之前保存数据:
- 大小:(默认为 1024 字节)
DCOMPRESS_BUFFER_SIZE - 分配:
diff_data_buff = vmalloc(DCOMPRESS_BUFFER_SIZE); - Deallocation(释放):
vfree(diff_data_buff); - 使用者:LZMA 解压缩器和补丁数据读取器
写入缓冲区
在修补期间用于在将修改后的数据块写入 flash 之前存储它们:
- 大小:(默认为 1024 字节)
WRITE_BLOCK_SIZE - 分配:
buf_data = (uint8_t *)vmalloc(WRITE_BLOCK_SIZE + 1); - Deallocation(释放):
vfree(buf_data); - 使用者:BSDiff 补丁算法
LZMA 解码器状态
保持 LZMA 解压缩过程的状态:
- 分配:
lz_state = (CLzmaDec *)lzma_alloc(NULL, sizeof(CLzmaDec)); - 初始化:
LzmaDec_Allocate(lz_state, header, LZMA_PROPS_SIZE, &allocator); - Deallocation: 后跟
LzmaDec_Free(lz_state, &allocator);lzma_free(NULL, lz_state);
内存分配策略
系统以固定大小的块处理补丁数据,以最大限度地减少内存使用量:
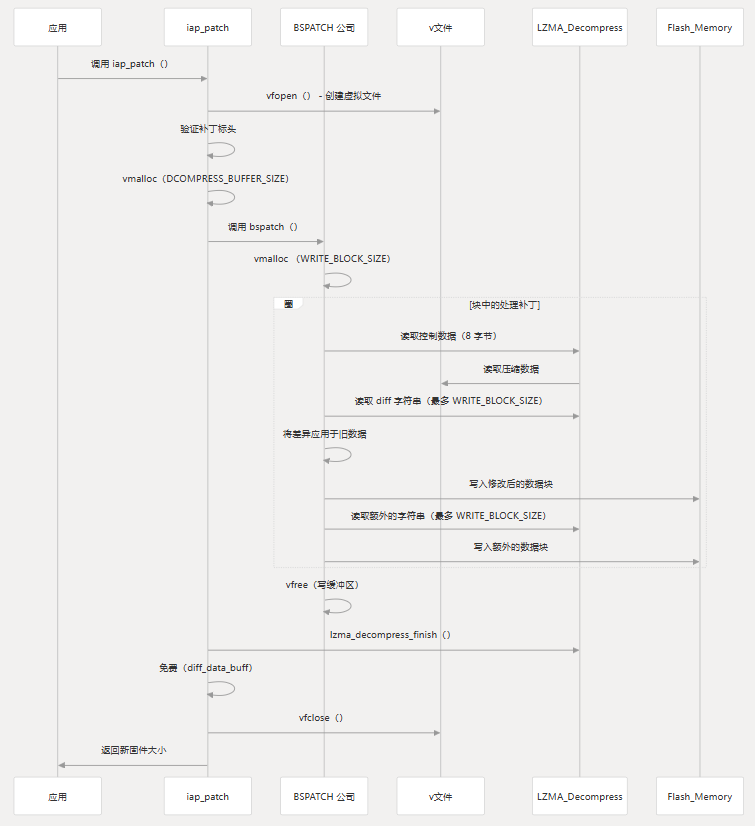
用户提供的内存函数
系统要求用户通过以下结构体实现和注册内存分配功能:bs_user_interface
示例实现:
void UpgradeInit(void)
{bs_user_interface bsFunc;bsFunc.bs_flash_write = xmq25qxxWrite;bsFunc.bs_malloc = (bs_malloc_func)pvPortMalloc;bsFunc.bs_free = vPortFree;bs_user_func_register(&bsFunc);
}内存使用流程
补丁应用程序期间的内存分配和释放流程如下:
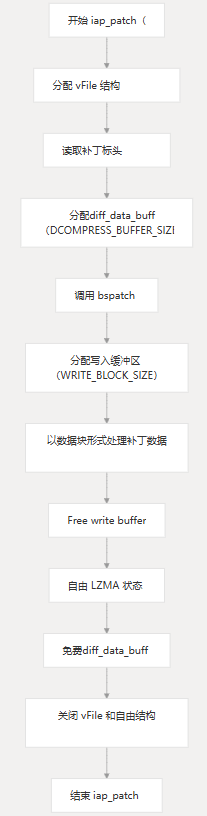
虚拟内存系统
系统使用虚拟文件系统抽象来简化内存作:
关键虚拟内存功能
| 功能 | 目的 | 用法 |
|---|---|---|
vmalloc(size) | 分配内存块 | 用于整个系统以进行动态分配 |
vfree(ptr) | 可用内存块 | 与每个 vmalloc 调用配对 |
vfopen(ptr, size) | 从内存缓冲区创建虚拟文件 | 用于处理补丁数据 |
vfclose(vf) | 关闭虚拟文件并释放资源 | 在补丁处理后调用 |
vfread(vf, buf, size) | 从虚拟文件中读取数据 | 用于读取补丁内容 |
常见内存问题
使用 MCU BSDiff 升级系统时遇到的最常见的内存相关问题是:
- 堆内存不足 - 系统需要足够的堆空间(建议 20KB+)
- 自定义 malloc 实现问题 - 用户提供的内存分配函数问题
- 内存碎片 - 长时间运行的系统在多次更新后可能会出现碎片
内存使用优化
要优化严重受限设备的内存使用:
- Modify 和 constants in
WRITE_BLOCK_SIZEDCOMPRESS_BUFFER_SIZE和减小缓冲区大小(以性能为代价) - 实施高效的内存分配器,最大限度地减少碎片
- 考虑一个专门用于升级过程的单独内存池
构建系统
本页记录了 MCU BSDiff 升级库的构建系统配置。它涵盖了基于 CMake 的构建基础设施和 Conan 包管理集成,支持对各种嵌入式目标进行交叉编译。
概述
MCU BSDiff 升级库使用基于 CMake 的现代构建系统,并支持 Conan 包管理。此配置允许库:
- 针对各种目标架构(Cortex-M0、M3、M4、M4F)进行交叉编译
- 使用不同的编译器(GNU ARM、IAR、Keil/ARMCC)构建
- 打包并作为可重用组件分发
- 通过依赖项管理集成到其他项目中
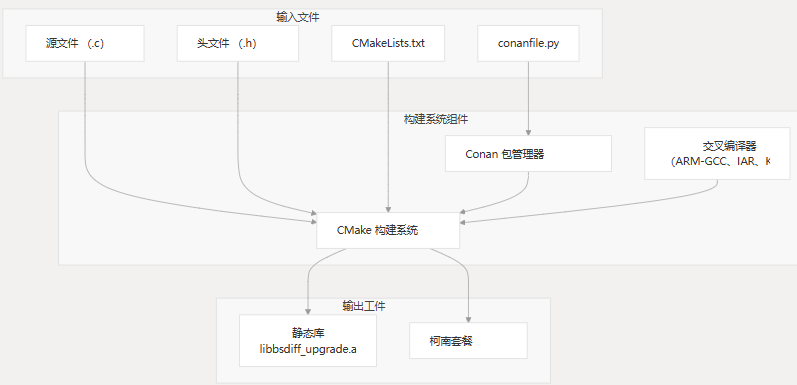
CMake 配置
该库使用 CMake 作为其主要构建工具。CMake 配置处理编译器标志、包含路径、源文件发现和生成静态库。
主要特点
- 使用 globbing 自动发现源文件
- 支持多个编译器工具链
- 特定于编译器的优化设置
- 自动标头目录检测和包含
- Debug/Release 构建类型支持
CMake 文件结构
源文件发现
构建系统会自动发现项目目录中的所有源文件:
file(GLOB_RECURSE DIR_LIB_SRCS"${CMAKE_CURRENT_LIST_DIR}/*.c"
)它还标识所有头文件及其目录:
file(GLOB_RECURSE Head_Files "${CMAKE_CURRENT_SOURCE_DIR}/*.h"
)# Find header directories
FOREACH(Head_Files ${Head_Files})string(REGEX REPLACE "(.*/)" "" HEAD_FILE ${Head_Files})string(REPLACE ${HEAD_FILE} "" HEAD_FILE_DIR ${Head_Files})list(APPEND HEAD_INCLUDE_DIR ${HEAD_FILE_DIR})
ENDFOREACH(Head_Files)# Remove duplicates
list(REMOVE_DUPLICATES HEAD_INCLUDE_DIR)交叉编译支持
CMake 配置为交叉编译设置环境:
set(CMAKE_SYSTEM_NAME Generic) set(CMAKE_SYSTEM_PROCESSOR arm) set(CMAKE_TRY_COMPILE_TARGET_TYPE STATIC_LIBRARY)
特定于编译器的优化标志是根据检测到的编译器设置的:
库目标和安装
该库构建为静态库,并随其头文件一起安装:
add_library(${PROJECT_NAME} STATIC ${DIR_LIB_SRCS})target_include_directories(${PROJECT_NAME}PUBLIC${HEAD_INCLUDE_DIR}
)install(FILES ${Head_Files} DESTINATION include)
install(TARGETS ${PROJECT_NAME})Conan 包管理
该项目使用 C/C++ 包管理器 Conan 来管理依赖项并使库可作为包分发。该脚本定义如何构建和分发包。conanfile.py
包配置
特定于编译器的标志
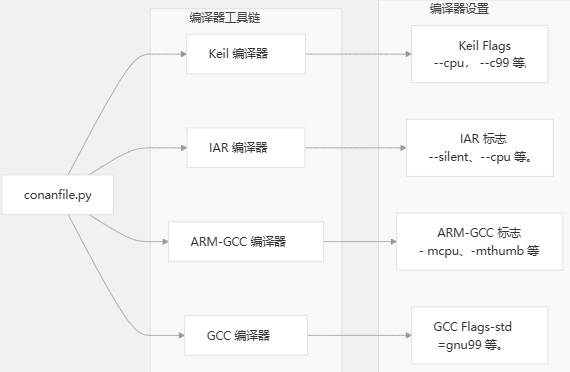
Conan 配置为不同的架构和编译器工具链提供了详细的编译器标志:
| 编译器 | 建筑 | 关键标志 |
|---|---|---|
| Keil | Cortex-M4F | --cpu Cortex-M4.fp.sp -O3 --c99 |
| Keil | Cortex-M4 | --cpu Cortex-M4 -O3 --c99 |
| Keil | Cortex-M3 | --cpu Cortex-M3 -O3 --c99 |
| Keil | Cortex-M0 | --cpu Cortex-M0 -O3 --c99 |
| IAR | Cortex-M4F | --cpu=Cortex-M4 --fpu=VFPv4_sp |
| IAR | Cortex-M4 | --cpu=Cortex-M4 |
| IAR | Cortex-M0 | --cpu=Cortex-M0 |
| ARM-GCC | Cortex-M4F | -mcpu=cortex-m4 -mfloat-abi=hard -mfpu=fpv4-sp-d16 |
| ARM-GCC | Cortex-M4 | -mcpu=cortex-m4 |
| ARM-GCC | Cortex-M0 | -mcpu=cortex-m0 |
| GCC | Host | -fdata-sections -ffunction-sections -Wall -std=gnu99 |
构建和打包过程
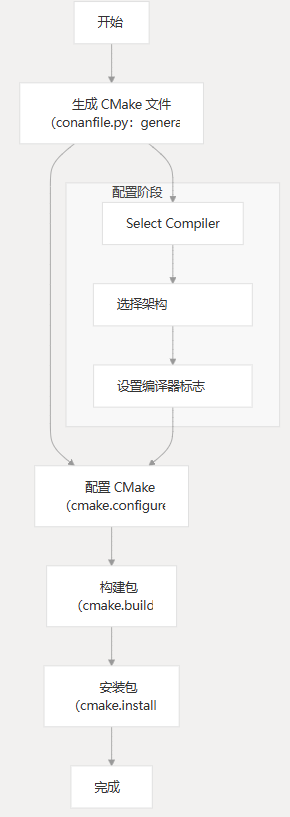
Conan 构建过程使用 CMake 来配置和构建库:
构建流程工作流程
完整的构建过程结合了 CMake 和 Conan 来创建简化的工作流程:
交叉编译支持矩阵
构建系统支持编译器和目标架构的多种组合:
| 特征 | 凯尔/ARMCC | IAR | ARM-GCC 技术 | 海湾合作委员会 |
|---|---|---|---|---|
| 皮质-M0 | ✓ | ✓ | ✓ | - |
| 皮质-M3 | ✓ | - | - | - |
| 皮质-M4 | ✓ | ✓ | ✓ | - |
| 皮质-M4F | ✓ | ✓ | ✓ | - |
| 主机编译 | - | - | - | ✓ |
| 调试版本 | ✓ | ✓ | ✓ | ✓ |
| 发布版本 | ✓ | ✓ | ✓ | ✓ |
CMake 配置
本页记录了 MCU BSDiff 升级项目的 CMake 构建系统配置。它涵盖了构建系统设置、编译器配置和库生成过程。
概述
MCU BSDiff 升级项目使用 CMake 作为其构建系统,以实现跨平台构建并支持多个编译器。该系统主要为基于 ARM 的嵌入式目标设计,支持 IAR、ARMCC 和 GCC 工具链。
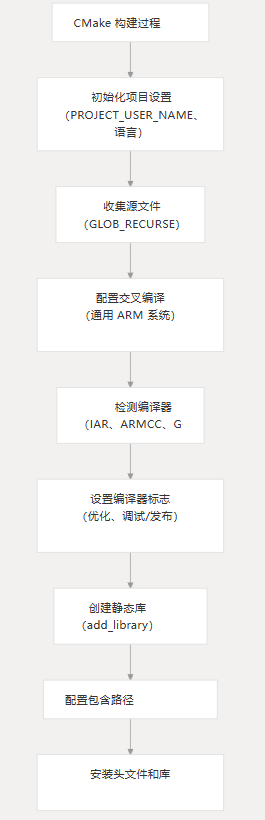
基本配置
CMake 系统要求最低版本为 3.15,并设置一个名为支持 C 语言的项目。构建系统配置为针对基于 ARM 的嵌入式系统进行交叉编译。bsdiff_upgrade
cmake_minimum_required(VERSION 3.15)
set(PROJECT_USER_NAME bsdiff_upgrade)
set(USER_LANGUAGES C)
set(CMAKE_SYSTEM_NAME Generic)
set(CMAKE_SYSTEM_PROCESSOR arm)源文件集合
构建系统使用 自动收集项目目录中的所有源文件,以递归方式搜索子目录。.c GLOB_RECURSE
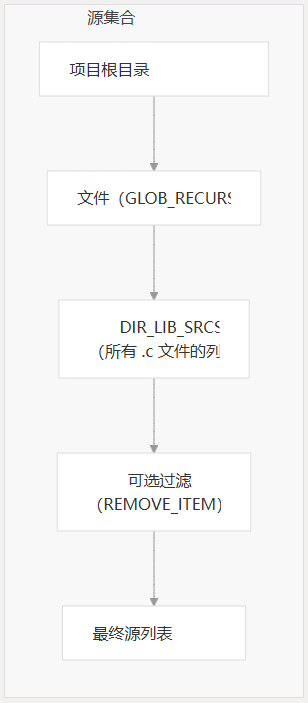
构建系统还包括一种机制,可以根据需要从编译中排除特定文件,尽管目前在配置中已注释掉。
交叉编译设置
该项目专门针对嵌入式系统进行交叉编译:
- 设置为
CMAKE_SYSTEM_NAMEGeneric - 设置为
CMAKE_SYSTEM_PROCESSORarm - 用作 try-compile 目标类型
STATIC_LIBRARY - 对 Unix 主机环境进行特殊处理,以确保编译器功能
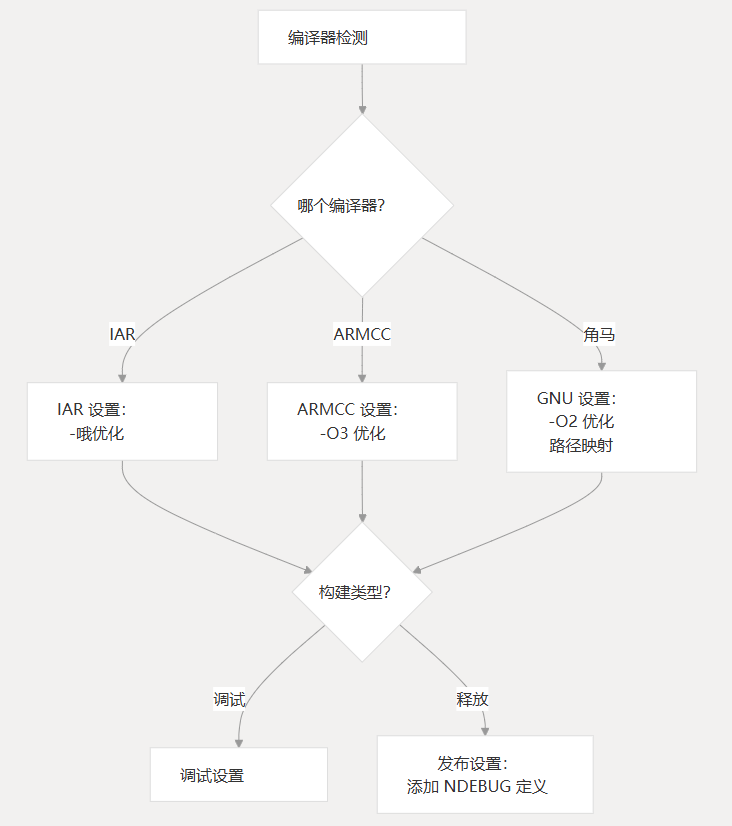
编译器检测和配置
构建系统会检测正在使用的编译器,并根据编译器和构建类型应用适当的优化标志和构建设置。
支持的编译器
| 编译器 | 优化标志 | 调试处理 |
|---|---|---|
| IAR | -Oh | 有條件的 |
| ARMCC 公司 | -O3 | 有條件的 |
| 海湾合作委员会 | -O2 | 有条件的路径重新映射 |
对于 Release builds,添加了该标志以禁用调试断言。-DNDEBUG
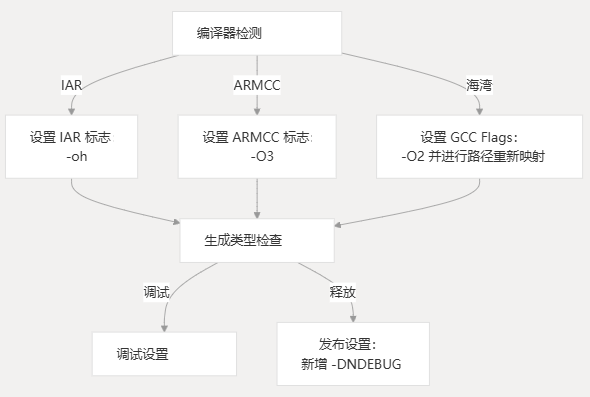
IAR 编译器的特殊处理
IAR 编译器接收其 DLib 库的额外配置:
- 找到编译器安装目录
- 查找 DLib_Config_Full.h 文件
- 根据需要转换路径以实现 WSL/Linux 兼容性
- 将 DLib 配置添加到编译器标志中
库创建
构建系统从所有收集的源文件创建一个静态库:
add_library(${PROJECT_NAME} STATIC ${DIR_LIB_SRCS})
这将创建 libbs_diff_upgrade.a(或等效的平台特定名称)。
依赖关系管理
构建系统支持使用基于列表的方法处理包依赖项:
- 遍历变量(当前已注释掉)
PACKAGE_LIST - 用于查找每个依赖项
find_package - 从找到的包中添加包含目录和链接库
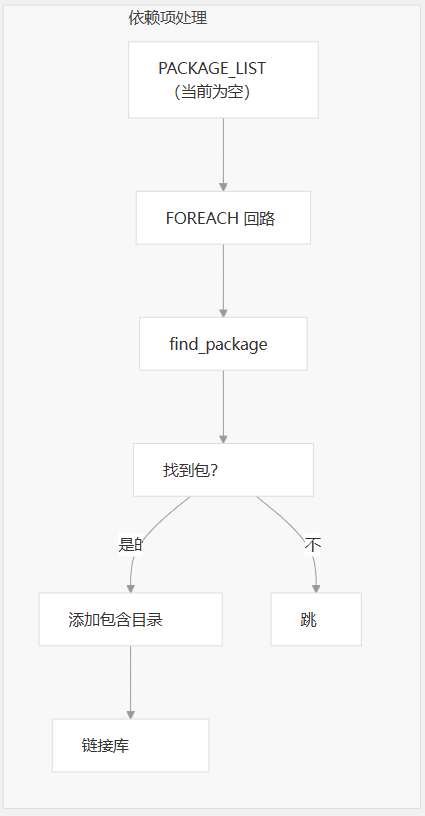
标题管理
构建系统查找并处理项目中的所有头文件:
- 使用 收集所有文件
.hGLOB_RECURSE - 从头文件中提取目录路径
- 删除重复的目录
- 将这些目录配置为库的公共包含路径
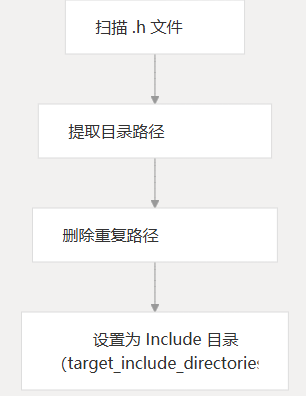
安装
CMake 系统配置库和头文件的安装:
install(FILES ${Head_Files} DESTINATION include)
install(TARGETS ${PROJECT_NAME})
这允许用户使用标准 CMake 安装命令将库安装到他们的系统中。
使用构建系统
要在项目中使用 bsdiff_upgrade CMake 配置:
-
使用适当的工具链文件配置构建:
cmake -DCMAKE_TOOLCHAIN_FILE=<toolchain_file> -DCMAKE_BUILD_TYPE=<Debug|Release> <source_dir>-
构建库:
cmake --build . -
安装(可选):
cmake --install .
构建系统根据检测到的环境自动处理交叉编译设置和特定于编译器的优化。
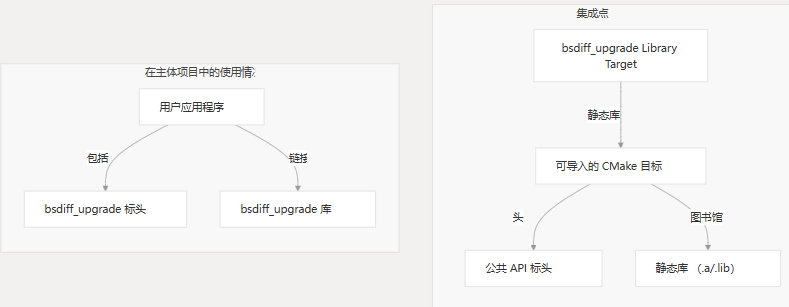
集成点
将 bsdiff_upgrade 库集成到项目中时,请注意 CMake 配置的以下关键方面:
- 该库构建为静态库(或等效库)
libbs_diff_upgrade.a - 所有标头都作为公共 include 公开
- 该系统针对嵌入式 ARM 目标进行了优化
- 支持多个编译器工具链(IAR、ARMCC、GCC)
与项目架构的关系
CMake 构建系统位于 MCU BSDiff 升级系统的基础,提供将核心组件编译成可用库的构建基础设施。
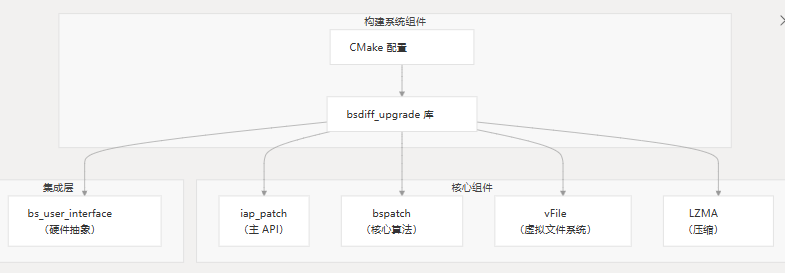
CMake 系统确保所有组件都正确编译并链接在一起,并为嵌入式目标提供适当的优化级别和编译器标志。
Conan 包管理
本页记录了 MCU BSDiff 升级项目中使用的 Conan 包管理系统。它解释了如何使用 Conan 打包、构建和分发项目,重点介绍了对嵌入式目标的跨平台和跨编译器支持。
概述
MCU BSDiff 升级系统利用 Conan 进行包管理,以简化依赖项处理、构建配置和交叉编译。Conan 支持跨不同的开发环境和编译器工具链进行一致的构建,这对于嵌入式固件开发至关重要。
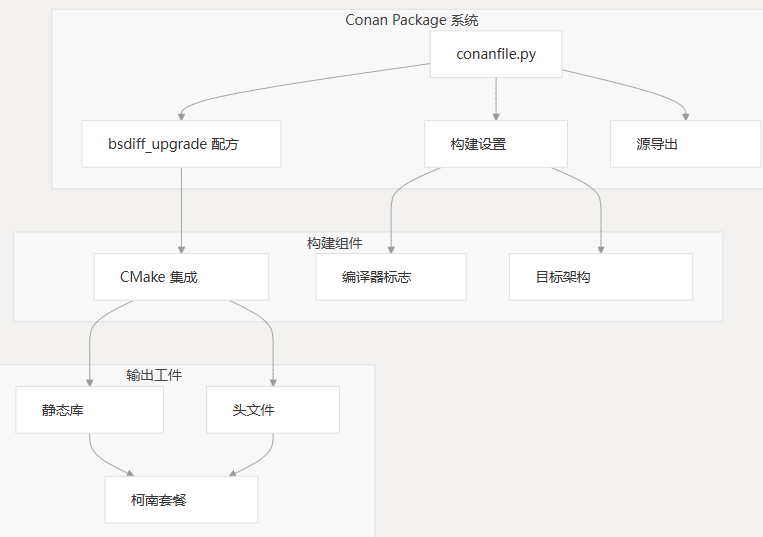
包配置
MCU BSDiff 升级系统打包为名为 的 Conan 配方。软件包配置由以下关键组件定义:bsdiff_upgrade conanfile.py
| 元件 | 描述 |
|---|---|
| 包名称 | bsdiff_upgrade |
| 版本 | 1.0.3 |
| 导出的源 | CMakeLists.txt、readme.md、bsdiff/自由/, lzma/用户/ |
| 设置 | 作系统, 编译器, build_type, arch |
| 选项 | 共享 (True/False)、fPIC (True/False) |
| 默认选项 | 共享=False,fPIC=False |
该软件包会导出所有必要的源文件,并定义对嵌入式目标至关重要的构建设置。
交叉编译器支持
Conan 配置的关键特性之一是对各种嵌入式编译器的全面支持。该软件包可以通过以下方式构建:
- Keil MDK - ARM Cortex-M 开发的行业标准
- IAR Embedded Workbench - 广泛用于工业应用
- ARM-GCC - 用于 ARM 目标的开源编译器
- GCC - 用于基于主机的测试和开发
每个编译器都有在构建过程中设置的特定标志和配置。
架构支持
该软件包支持多种 ARM Cortex-M 架构,并针对每个目标进行了特定优化:
| 建筑 | FPU 支持 | 描述 |
|---|---|---|
| Cortex-M0 | 不 | 超低功耗内核,最少的功能集 |
| Cortex-M3 | 不 | 具有增强性能的通用内核 |
| Cortex-M4 | 不 | 用于数字信号控制的高性能内核 |
| Cortex-M4F | 是的 | 带浮点单元 (FPU) 的 Cortex-M4 |
构建系统根据目标架构自动选择适当的编译器标志。
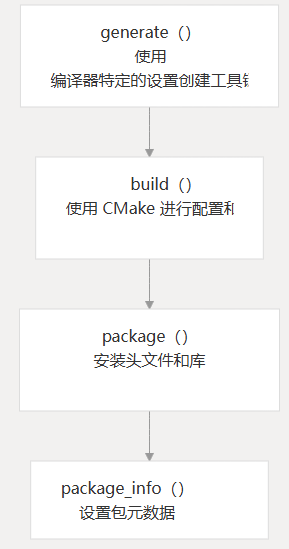
Conan 和 CMake 集成
Conan 包系统与 CMake 紧密集成,以提供无缝的构建体验。集成通过几个关键功能进行处理:
主要集成功能包括:
- layout() - 设置构建目录结构
- generate() - 使用适当的编译器标志创建 CMake 配置文件
- build() - 执行构建过程
- package() - 将构建工件收集到 Conan 包中
使用软件包
要在其他项目中使用 MCU BSDiff 升级包,您需要:
- 安装 Conan
- 将包引用添加到项目的 conanfile.txt 或 conanfile.py
- 为目标架构配置适当的项目
- 使用 Conan 安装依赖项
- 使用 CMake 构建您的项目
将包添加到项目的示例:
[requires]
bsdiff_upgrade/1.0.3@xian/stable[generators]
cmake_find_package
该软件包将自动为您指定的目标架构和编译器配置自身。
构建过程
MCU BSDiff 升级包的构建过程包括几个步骤:
在构建过程中,Conan:
- 确定适当的编译器和体系结构设置
- 生成具有正确编译器标志的 CMake 工具链文件
- 使用 CMake 配置构建
- 编译源代码
- 打包生成的库和头文件
编译器配置详细信息
该软件包为编译器和体系结构的不同组合提供了详细的编译器标志配置。这些标志对于确保库在目标硬件上正常运行至关重要。
例如,对于具有 Cortex-M4F 体系结构的 ARM-GCC 编译器,使用以下标志:
-x c -mcpu=cortex-m4 -mthumb -Wstack-protector -mfloat-abi=hard -mfpu=fpv4-sp-d16 -std=gnu99
-fdata-sections -ffunction-sections --param max-inline-insns-single=500 -Wall
这些标志支持硬件浮点运算、代码大小优化和适当的警告。
总结
MCU BSDiff Upgrade 中的 Conan 包管理系统提供:
- 跨不同开发平台的一致构建环境
- 支持多个编译器工具链(Keil、IAR、ARM-GCC、GCC)
- 针对各种 ARM Cortex-M 架构的优化配置
- 与 CMake 无缝集成
- 轻松分发和使用 library
这种灵活性对于嵌入式固件开发至关重要,因为可能需要为具有不同编译器工具链的不同目标设备构建相同的代码。
API 参考
目的和范围
本文档对 MCU BSDiff 升级系统中的所有公共 API 提供了全面的参考。对于希望将 Differential Update 机制集成到其嵌入式项目中的开发人员,它可以作为技术指南。API 参考 重点介绍开发人员需要了解的接口、数据结构和函数签名,以便有效地实施固件差异更新。
API 概述
MCU BSDiff 升级系统公开了几个关键 API,这些 API 协同工作,在资源受限的设备上启用差分固件更新。
API 关系图
主要 API - iap_patch
该函数是应用差异补丁以升级固件的主要入口点。这是用户将调用以执行固件更新的主要函数。iap_patch
函数签名
int iap_patch(const uint8_t *old, uint32_t oldsize, const uint8_t *patch, uint32_t patchsize, uint32_t newfile_addr);参数
| 参数 | 类型 | 描述 |
|---|---|---|
| old | const uint8_t* | 指向内存中旧固件映像的指针 |
| oldsize | uint32_t | 旧固件映像的大小(以字节为单位) |
| patch | const uint8_t* | 指向差异补丁数据的指针(无标头) |
| patchsize | uint32_t | 补丁数据的大小(以字节为单位) |
| newfile_addr | uint32_t | 应写入新固件的地址 |
返回值
| 价值 | 描述 |
|---|---|
| >0 | Success 返回新固件的大小(以字节为单位) |
| 0 | 失败 |
iap_patch工艺流程
用户界面 API - bs_user_interface
该结构定义了用户必须实现的回调,以启用 flash作和内存管理。bs_user_interface
结构定义
typedef struct {bs_flash_write_func bs_flash_write;bs_malloc_func bs_malloc;bs_free_func bs_free;
} bs_user_interface;函数指针类型
| 函数指针 | 类型 签名 | 描述 |
|---|---|---|
| bs_flash_write_func | int (*)(uint32_t addr, const unsigned char *p, uint32_t len) | Flash 写入功能 |
| bs_malloc_func | void )(uint32_t 大小)( | 内存分配功能 |
| bs_free_func | 无效 (*)(void *ptr) | 内存释放功能 |
bs_user_func_register
此函数注册用户提供的接口函数实现。
int bs_user_func_register(bs_user_interface *user_func);实现示例
补丁标头 API - image_header_t
该结构包含有关补丁的元数据,包括 CRC 校验和、文件大小和其他信息。image_header_t
结构定义
typedef struct image_header {uint32_t ih_magic; /* Image Header Magic Number */uint32_t ih_hcrc; /* Image Header CRC Checksum (big-endian) */uint32_t ih_time; /* Image Creation Timestamp */uint32_t ih_size; /* Patch data size (big-endian) */uint32_t ih_load; /* Old firmware size */uint32_t ih_ep; /* New firmware size */uint32_t ih_dcrc; /* New firmware CRC (big-endian) */uint8_t ih_os; /* Operating System */uint8_t ih_arch; /* CPU architecture */uint8_t ih_type; /* Image Type */uint8_t ih_comp; /* Compression Type */uint8_t ih_name[IH_NMLEN]; /* Image Name */uint32_t ih_ocrc; /* Old firmware CRC (big-endian) */
} image_header_t;关键字段
| 田 | 描述 | 用法 |
|---|---|---|
| ih_magic | 用于验证的幻数 | 用于验证标头是否有效 |
| ih_hcrc | 标头 CRC | 用于验证标头完整性 |
| ih_size | 补丁数据大小 | 差分贴片的大小(无接头) |
| ih_load | 旧固件大小 | 旧固件的大小(以字节为单位) |
| ih_ep | 新固件大小 | 修补后新固件的大小 |
| ih_dcrc | 新固件 CRC | 用于验证新固件的完整性 |
| ih_ocrc | 旧固件 CRC | 用于验证旧固件的完整性 |
修补过程中的标头使用情况
虚拟文件 API (vFile)
虚拟文件 API 提供了将内存区域视为文件的抽象,使补丁应用程序算法能够高效地读取和写入数据。
关键 vFile 函数
虽然 vFile API 主要由修补系统在内部使用,但了解其核心功能有助于调试和自定义实施。
| 功能 | 描述 |
|---|---|
| VOPEN | 从内存缓冲区打开虚拟文件 |
| vread | 从虚拟文件中读取数据 |
| vwrite | 将数据写入虚拟文件 |
| vseek | 设置文件位置指示器 |
| vclose | 关闭虚拟文件并释放资源 |
修补过程中的 vFile 使用情况
效用函数
CRC32 计算
该函数计算数据缓冲区的 32 位 CRC 校验和,用于验证整个修补过程中的数据完整性。crc32
unsigned int crc32(const unsigned char *buf, unsigned int size);参数
| 参数 | 类型 | 描述 |
|---|---|---|
| BUF | const 无符号字符* | 指向数据缓冲区的指针 |
| 大小 | 无符号整数 | 数据缓冲区的大小(以字节为单位) |
返回值
| 价值 | 描述 |
|---|---|
| uint32_t | 计算的 CRC32 校验和 |
完整的 API 使用流程
下图说明了使用 MCU BSDiff 升级 API 执行固件更新的完整流程:
总结
本 API 参考 全面概述了 MCU BSDiff 升级系统中的所有公共 API。通过实现所需的用户界面功能并遵循所述工作流程,开发人员可以将差分固件更新集成到其嵌入式应用程序中,与完整的固件更新相比,显著降低带宽要求和更新时间。
iap_patch API
目的和范围
该 API 是在 MCU BSDiff 升级系统中应用差分固件补丁的主要入口点。本文档提供了 API 的全面参考,包括 API 的参数、返回值、内部流程和集成要求。iap_patch
API 签名
int iap_patch(const uint8_t *old, uint32_t oldsize, const uint8_t *patch, uint32_t patchsize, uint32_t newfile_addr);参数
| 参数 | 类型 | 描述 |
|---|---|---|
old | const uint8_t * | 指向闪存中当前固件的指针。这是将要修补的基本固件。 |
oldsize | uint32_t | 当前固件的大小(以字节为单位)。此值可以从 patch 标头获取。 |
patch | const uint8_t * | 指向差异补丁数据的指针。请注意,这应该指向 header 之后的实际补丁数据。image_header_t |
patchsize | uint32_t | 补丁数据的大小(以字节为单位)。此值可以从 patch 标头获取。 |
newfile_addr | uint32_t | 应写入新固件的闪存地址。 |
返回值
该函数返回一个整数,表示修补后新固件的大小,如果在修补过程中发生错误,则返回 0。
功能流程图
内部组件
该函数依赖于多个内部组件来执行其任务:iap_patch
虚拟文件系统
修补过程使用虚拟文件抽象 () 来处理内存作。这允许将内存中的补丁数据视为类似文件的流。vFile
LZMA 减压
补丁数据使用 LZMA 压缩进行压缩,以最小化其大小。该函数使用解压缩模块来提取实际的补丁指令。iap_patch
二进制修补过程
内部修补过程遵循 bsdiff 算法,该算法应用一系列作将旧固件转换为新固件。
集成要求
用户界面注册
在调用 之前,应用程序必须使用 注册所需的用户界面函数。这些函数处理特定于硬件的作:iap_patch bs_user_func_register()
内存要求
该函数的作需要大量的 RAM:iap_patch
- 它为 LZMA 解压缩分配一个缓冲区 ()(默认为 1024 字节)
diff_data_buff - 虚拟文件系统需要额外的内存来执行其作
- 该进程需要内存来保存中间数据
bspatch
如文档中所述,总 RAM 要求至少约为 10KB,根据补丁复杂性,可能需要更多。
补丁文件结构
所需的 patch 文件具有特定的结构:iap_patch
- 一个可选结构(64 字节),包含有关补丁和固件版本的元数据
image_header_t - 实际的补丁数据,以魔术字符串 “ENDSLEY/BSDIFF43” 开头,后跟新的固件大小
- LZMA 压缩补丁说明
┌───────────────────┐
│ image_header_t │ (64 bytes, optional, handled before calling iap_patch)
├───────────────────┤
│ "ENDSLEY/BSDIFF43"│ (16 bytes, magic string)
├───────────────────┤
│ New size (8B) │ (8 bytes, size of new firmware)
├───────────────────┤
│ │
│ LZMA-compressed │
│ patch data │
│ │
└───────────────────┘集成到固件更新过程中
该函数通常用于固件更新过程,如下所示:iap_patch
错误处理
该函数可能以多种方式失败:iap_patch
- 如果无法打开虚拟文件(内存分配失败)
- 如果 patch 标头与预期格式不匹配
- 如果新固件大小无效
- 如果 diff 缓冲区的内存分配失败
- 如果修补过程本身失败
在所有错误情况下,该函数都返回 0,调用方应根据补丁标头中预期的新固件大小检查此返回值。
使用示例
以下是如何在固件更新过程中使用 API 的简化示例:iap_patch
// First, register user interface functions
void UpgradeInit(void)
{bs_user_interface bsFunc;bsFunc.bs_flash_write = MyFlashWriteFunction;bsFunc.bs_malloc = MyMallocFunction;bsFunc.bs_free = MyFreeFunction;bs_user_func_register(&bsFunc);
}// Later, during the update process
int ApplyFirmwareUpdate(uint32_t patchAddress, uint32_t patchSize)
{image_header_t header;uint32_t currentFirmwareAddr = FIRMWARE_EXECUTION_ADDR;uint32_t newFirmwareAddr = FIRMWARE_UPDATE_ADDR;// Read patch headerReadFlash(patchAddress, (uint8_t*)&header, sizeof(image_header_t));// Verify header CRCuint32_t headerCrc = header.ih_hcrc;header.ih_hcrc = 0;if (crc32((uint8_t*)&header, sizeof(image_header_t)) != headerCrc) {return ERROR_INVALID_HEADER;}// Verify old firmware CRCif (crc32((uint8_t*)currentFirmwareAddr, header.ih_load) != header.ih_ocrc) {return ERROR_INVALID_OLD_FIRMWARE;}// Apply patchuint32_t newSize = iap_patch((const uint8_t*)currentFirmwareAddr, header.ih_load,(const uint8_t*)(patchAddress + sizeof(image_header_t)), header.ih_size,newFirmwareAddr);// Verify resultif (newSize != header.ih_ep) {return ERROR_PATCH_FAILED;}// Verify new firmware CRCif (crc32((uint8_t*)newFirmwareAddr, newSize) != header.ih_dcrc) {return ERROR_VERIFICATION_FAILED;}// Update boot flags to use new firmwareSetBootFlags(BOOT_FROM_UPDATE);return SUCCESS;
}内存架构
使用 API 时,了解内存架构至关重要:iap_patch
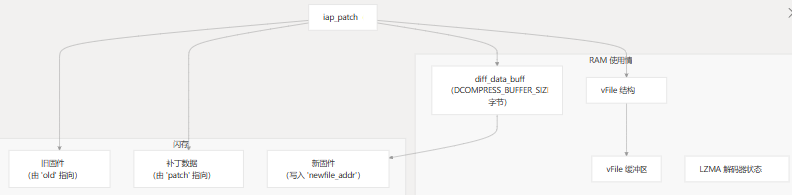
限制和注意事项
- RAM 要求:补丁应用程序进程需要大量 RAM(建议至少 10KB)。
- Flash Write Access:该函数必须在写入之前处理任何必要的 Flash 扇区擦除。
bs_flash_write - 错误处理:应用程序必须验证返回的大小,并对生成的固件执行 CRC 验证。
- 补丁格式:补丁必须遵循预期的格式,并具有正确的魔术字符串和标头结构。
- 原子性:修补过程不是原子的 - 如果中断(例如,由于断电),固件可能会处于不一致的状态。
总结
API 提供了一个简单的接口,用于将二进制差分补丁应用于嵌入式系统中的固件。通过处理补丁提取、解压缩和应用程序的复杂细节,它允许开发人员以最低的带宽要求实施高效的无线更新。API 需要注册用户特定的 flash 写入和内存管理函数,使其能够适应各种硬件平台,同时保持修补算法和硬件特定作之间的明确分离。iap_patch
bs_user_interface API
该 API 提供了硬件抽象层,使 MCU BSDiff 升级系统能够在不同的硬件平台上运行。本文档详细介绍了开发人员将二进制差分更新功能集成到其嵌入式系统中必须实现的用户界面功能。bs_user_interface
概述
API 充当通用二进制修补算法和固件更新所需的硬件特定作之间的桥梁。通过实现此接口,开发人员可以调整 MCU BSDiff 升级系统,使其与特定的内存管理和闪存写入机制配合使用。bs_user_interface
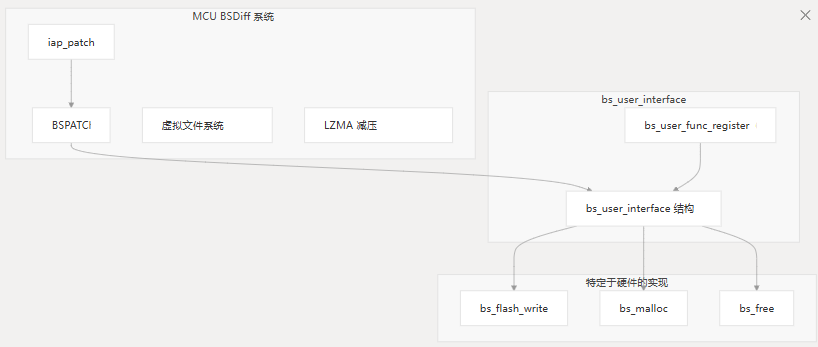
API 结构
这被定义为一个结构,其中包含必须由用户实现的三个函数指针:bs_user_interface
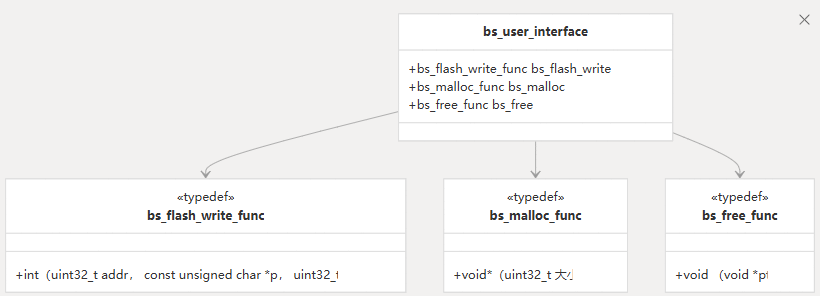
全局变量
该库维护结构的全局实例:bs_user_interface
bs_user_interface bs_user_func;
此全局变量存储已注册的函数指针,并由 patching 算法在内部用于访问特定于硬件的实现。
必需的函数实现
Flash 写入功能
typedef int (*bs_flash_write_func)(uint32_t addr, const unsigned char *p, uint32_t len);此函数负责将数据写入指定地址的 Flash 存储器。
参数:
addr:用于写入的目标闪存地址p:指向要写入的数据缓冲区的指针len:要写入的数据的长度
返回值:
0:成功- 其他值: Error code
重要说明:
- 实现必须在写入之前处理 Flash 擦除
- 修补算法将调用此函数以写入新固件
- 该实现必须确保根据特定硬件要求正确处理闪存
内存分配功能
typedef void *(*bs_malloc_func)(uint32_t size);此函数在修补过程中分配内存。
参数:
size:要分配的内存大小(以字节为单位)
返回值:
- 非 NULL 指针:内存分配成功
- NULL:分配失败
重要说明:
- 该实现应能够处理最大约 20KB 的分配请求
- 通过此函数分配的内存将使用相应的
bs_free_func
无记忆功能
typedef void (*bs_free_func)(void *ptr);此函数可释放以前分配的内存。
参数:
ptr:指向要释放的内存的指针
返回值:
- 没有
注册流程
要使用 MCU BSDiff 升级系统,您必须使用以下函数注册所需函数的实现:bs_user_func_register
int bs_user_func_register(bs_user_interface *user_func);参数:
user_func:指向包含用户实现的结构体的指针bs_user_interface
返回值:
0:成功1:失败(通常是由于 NULL 指针)
示例用法:
bs_user_interface my_interface;
my_interface.bs_flash_write = my_flash_write_implementation;
my_interface.bs_malloc = my_malloc_implementation;
my_interface.bs_free = my_free_implementation;if (bs_user_func_register(&my_interface) != 0) {// Handle registration failure
}
注册函数检查所有必需的函数指针是否为非 NULL,并将它们存储在全局变量中,以供修补算法稍后使用。bs_user_func
集成流程
下图说明了 如何与整个修补过程集成:bs_user_interface
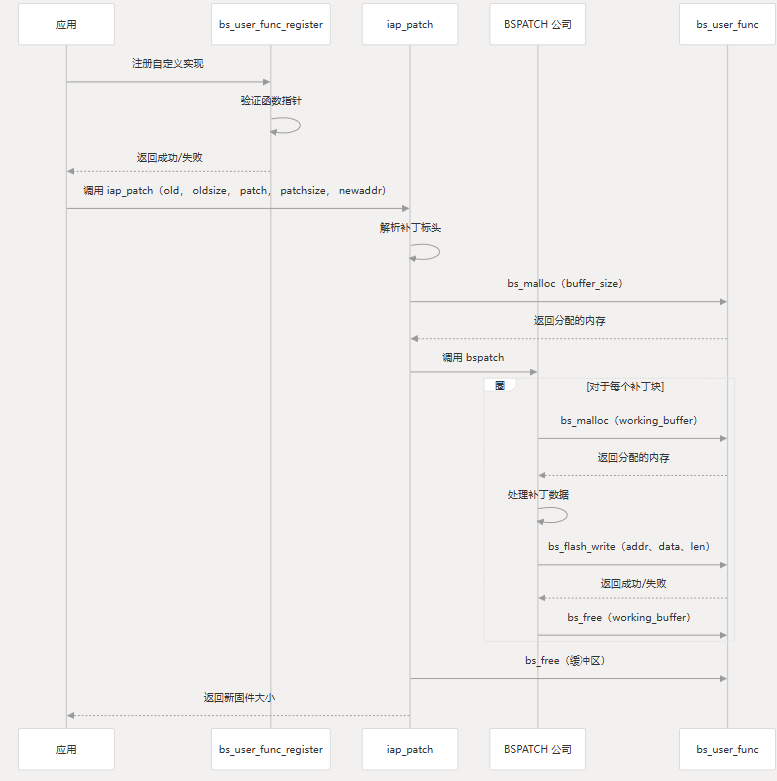
内存要求
MCU BSDiff 升级系统专为资源受限的环境而设计,但仍需要一定量的 RAM 才能正常运行。下表概述了大致的内存要求:
| 元件 | 近似大小 | 笔记 |
|---|---|---|
| LZMA 减压缓冲器 | 15-20 KB | 主内存使用者 |
| 工作缓冲液 | 1-2 KB | 用于数据处理 |
| 控制结构 | < 1 KB | 用于管理修补过程 |
实施的最佳实践
Flash 写入功能
- 确保正确擦除:flash 写入功能必须在写入数据之前处理扇区擦除。
- 手柄对齐:许多闪存控制器需要对写入作进行特定的对齐。
- 检查边界:实施边界检查以防止写入指定区域之外。
- 错误处理:提供有意义的错误代码以进行调试。
内存管理功能
- 堆碎片:在修补过程中要注意潜在的堆碎片。
- 分配失败:对分配失败实施可靠的错误处理。
- 内存泄漏:确保在应用程序代码中正确配对分配和空闲调用。
- 静态分配:如果您的系统堆功能有限,请考虑使用静态分配。
与 Image Header 的关系
该文件还定义了一个结构,其中包含有关固件映像的元数据:bs_user_interface.himage_header_t
修补过程使用此结构在应用之前验证和确认修补数据。
相关组件
它与 MCU BSDiff 升级系统中的其他几个组件交互:bs_user_interface
- iap_patch:应用补丁的主要入口点,它使用用户提供的函数
- bspatch:依赖用户函数进行内存作的核心二进制修补算法
- 虚拟文件系统:使用内存分配函数抽象内存访问
- LZMA 解压缩:对其工作缓冲区使用内存分配函数
总结
API 是 MCU BSDiff 升级系统的关键组件,可实现跨平台兼容性。通过实现所需的函数并通过 注册它们,开发人员可以调整二进制修补系统,使其能够使用其特定的硬件和内存管理系统。bs_user_interfacebs_user_func_register
该设计优先考虑灵活性和最低资源消耗,使其适用于资源受限的嵌入式系统,同时仍为差分固件更新提供强大的机制。
vFile API
vFile API 提供了一个虚拟文件系统抽象,允许将内存缓冲区视为文件。这是 MCU BSDiff 升级系统的核心组件,有助于读取存储在内存中的补丁数据,而无需实际的文件系统。
架构概述
vFile API 设计为简单和轻量级,提供足够的类似文件的行为来支持修补作,而不会产生不必要的开销。它充当原始内存缓冲区和需要按顺序访问该数据的组件之间的抽象层。
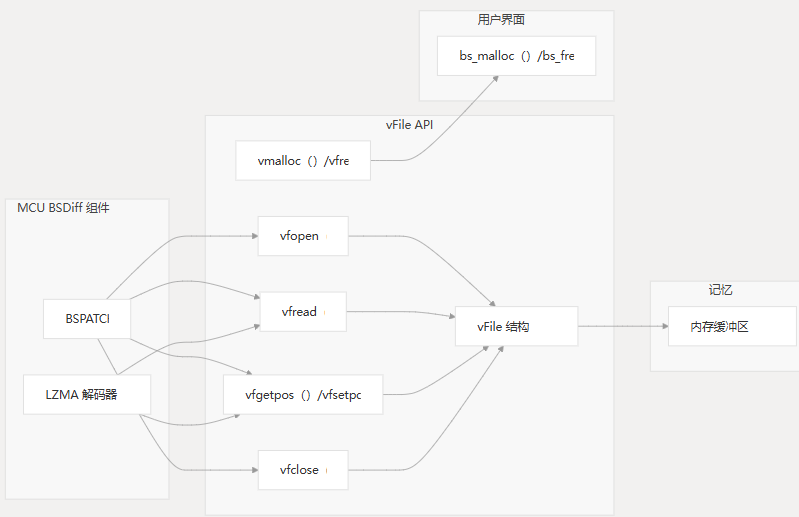
vFile 结构
vFile 结构是表示虚拟文件的核心数据类型。它包含指向内存缓冲区的指针、当前位置 (偏移量) 和缓冲区的总大小。

| Field | 类型 | 描述 |
|---|---|---|
curptr | uint8_t * | 指向被视为文件的内存缓冲区开头的指针 |
offset | uint32_t | 内存缓冲区中的当前位置 (读取位置) |
size | uint32_t | 内存缓冲区的总大小(以字节为单位) |
内存管理功能
vFile API 包括两个用于内存分配的帮助程序函数,这些函数委托给用户提供的内存管理函数。
vmalloc
void *vmalloc(size_t size)使用用户提供的分配函数分配内存。
参数:
size:要分配的字节数
返回:
- 指向已分配内存的指针,如果分配失败或未提供分配函数,则为 NULL
实施说明:
- 此函数调用用户提供的函数
bs_malloc - 如果未设置,则返回 NULL
bs_malloc
免费
void vfree(void *ptr)使用用户提供的 free 函数释放以前分配的内存。
参数:
ptr:指向要释放的内存的指针
实施说明:
- 此函数调用用户提供的函数
bs_free - 如果未设置,则不执行任何作
bs_free
核心 vFile作
创建和打开虚拟文件
vFile *vfopen(const uint8_t *dp, uint32_t size)创建指向指定内存缓冲区的新虚拟文件结构。
参数:
dp:指向内存缓冲区的指针size:内存缓冲区的大小(以字节为单位)
返回:
- 指向新 vFile 结构的指针,如果内存分配失败,则为 NULL
实施说明:
- 为 vFile 结构分配内存
- 使用缓冲区指针和大小初始化结构
- 将初始偏移量设置为 0(缓冲区的开头)
从虚拟文件读取
int vfread(vFile *fp, uint8_t *buff, int len)将数据从虚拟文件读取到提供的缓冲区中。
参数:
fp:指向 vFile 结构的指针buff:用于存储读取数据的缓冲区len:要读取的字节数
返回:
- 实际读取的字节数,如果到达缓冲区末尾,则可能小于请求的字节数
- 如果文件指针为 NULL,则为 0
实施说明:
- 检查请求的读取是否超过缓冲区大小并相应地进行调整
- 将数据从内存缓冲区复制到提供的目标缓冲区
- 更新文件偏移量
获取当前位置
uint8_t *vfgetpos(vFile *fp, uint32_t *position)获取虚拟文件中的当前位置。
参数:
fp:指向 vFile 结构的指针position:指向将存储当前偏移量的uint32_t的指针
返回:
- 指向内存缓冲区中当前位置的指针
- 如果文件指针为 NULL,则为 NULL
设置当前位置
int vfsetpos(vFile *fp, uint32_t position)设置虚拟文件中的当前位置。
参数:
fp:指向 vFile 结构的指针position:从内存缓冲区开始的所需偏移量
返回:
- 新的偏移量,如果文件指针为 NULL,则为 -1
关闭虚拟文件
int vfclose(vFile *fp)关闭虚拟文件并释放关联的资源。
参数:
fp:指向要关闭的 vFile 结构的指针
返回:
- 始终返回 0
实施说明:
- 释放为 vFile 结构分配的内存
- 不释放 vFile 指向的内存缓冲区
获取文件长度
uint32_t vfgetlen(vFile *fp)获取虚拟文件的总大小。
参数:
fp:指向 vFile 结构的指针
返回:
- 内存缓冲区的大小(以字节为单位)
使用流程
vFile API 的典型使用模式遵循以下顺序:
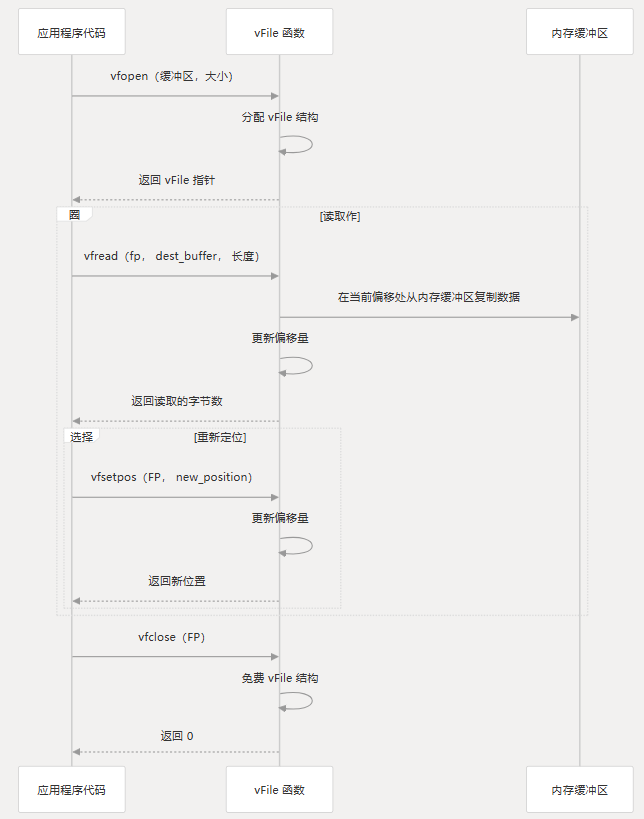
与 BSDiff 系统集成
vFile API 是 BSDiff 修补过程用来高效访问补丁数据的基本组件。虚拟文件抽象允许在解压缩和修补作期间按顺序访问补丁数据(可能存储在闪存中)。
示例用法
下面是一个伪代码示例,显示了 vFile API 在 MCU BSDiff 升级系统中的通常使用方式:
// First, register memory management functions
bs_user_func.bs_malloc = my_malloc_function;
bs_user_func.bs_free = my_free_function;// Open a virtual file pointing to the patch data
vFile *patch_file = vfopen(patch_data_buffer, patch_size);
if (patch_file == NULL) {// Handle error - couldn't create vFilereturn ERROR_CODE;
}// Read header data
uint8_t header_buffer[HEADER_SIZE];
int bytes_read = vfread(patch_file, header_buffer, HEADER_SIZE);
if (bytes_read != HEADER_SIZE) {// Handle error - couldn't read headervfclose(patch_file);return ERROR_CODE;
}// Process header...// Reposition to start of actual patch data
vfsetpos(patch_file, HEADER_SIZE);// Continue reading and processing patch data
while (more_data_needed) {bytes_read = vfread(patch_file, data_buffer, buffer_size);if (bytes_read == 0) {break; // End of file reached}// Process data...
}// When done, close the file
vfclose(patch_file);内存注意事项
vFile API 设计为轻量级的,适用于资源受限的嵌入式系统:
- vFile 结构本身只有 12 个字节(指针为 4 个字节,偏移量为 4 个字节,大小为 4 个字节)
- 打开虚拟文件时,仅进行一次额外的内存分配(对于 vFile 结构)
- 不会创建数据副本;API 直接与提供的内存缓冲区一起使用
- 内存管理功能委托给用户,允许自定义分配策略
这些设计选择使 vFile API 特别适合 RAM 有限的嵌入式系统。
局限性
- vFile API 仅支持读取作;没有写入支持
- Seek 仅限于从文件开头开始的绝对定位
- 整个内存缓冲区必须在 vFile 的整个生命周期内可访问
- 错误处理最少;大多数函数在失败时只返回 0 或 NULL
这些限制是有意为之的,因为 API 是专门为 BSDiff 修补过程的需求而设计的,其中补丁数据的受控顺序读取是主要要求。
总结
vFile API 提供了一个简单的抽象,用于访问内存缓冲区,就像它们是文件一样。它是 MCU BSDiff 升级系统的核心组件,可在固件更新过程中高效访问补丁数据。API 的轻量级设计使其非常适合资源受限的嵌入式系统。
CRC 和实用程序函数
本页介绍了 MCU BSDiff 升级系统提供的 CRC(循环冗余校验)实现和各种实用功能。这些函数支持核心作,例如数据验证、内存作、字节序转换和字符串处理。
概述
MCU BSDiff 升级系统包括多个实用程序功能,这些功能对于在资源受限的设备上执行可靠的固件修补作至关重要。这些实用程序可分为:
- CRC 计算函数
- 内存比较和作实用程序
- 数据格式转换函数
- 字符串处理实用程序
- 与时间相关的函数
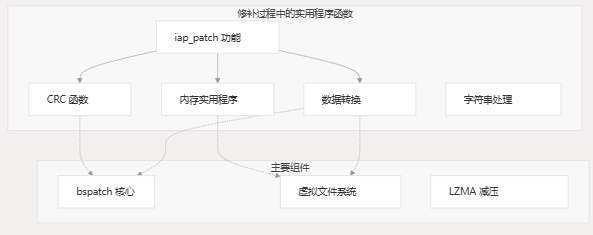
CRC 函数
该系统实现了两种 CRC 算法进行数据完整性验证:
CRC32 实施
CRC32 实现使用标准查找表方法进行高效计算。这主要用于验证固件映像和补丁的完整性。

CRC32 函数采用两个参数:
- 指向数据缓冲区的指针
- 缓冲区的大小(以字节为单位)
它返回一个 32 位无符号整数,表示计算出的 CRC 值。
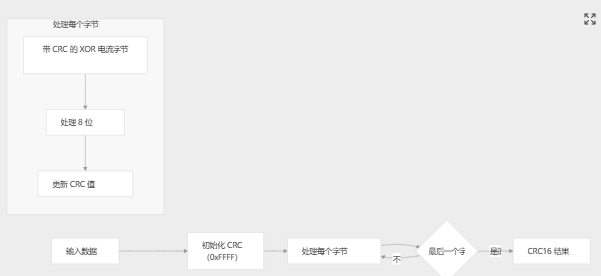
CRC16 实现
CRC16 函数实现了 Modbus CRC16 算法,该算法适用于 CRC32 可能过头的较小数据集。
内存实用程序函数
该系统提供了多个内存实用程序函数,用于比较和作内存区域,这些函数对于补丁应用程序过程至关重要。
内存比较函数
| 功能 | 描述 | 参数 |
|---|---|---|
mylib_memcmp | 比较两个内存区域 | p1(第一个指针)、(第二个指针)、(要比较的字节数)p2size |
mylib_memcmp_b | 将内存区域与单个值进行比较 | p1(内存指针)、(要比较的字节)、(要比较的字节)valuesize |
内存辅助函数
| 功能 | 描述 | 参数 |
|---|---|---|
mylib_sum | 计算数组中的字节数和 | p(指向数组的指针)、(数组长度)size |
mylib_uDelay | 微秒延迟功能 | us(延迟(以微秒为单位) |
_msize | 返回堆内存分配的大小 | mp(内存指针) |
数据转换函数
该系统包括各种数据转换函数,用于处理不同的数据格式和字节序问题,这些问题在处理固件映像和网络通信时很常见。
字节序转换
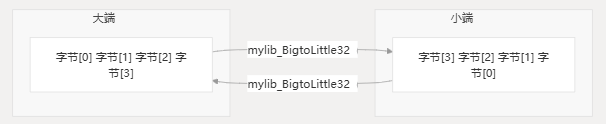
系统提供了在 big 和 little-endian 格式之间进行转换的函数:
| 功能 | 描述 | 参数 |
|---|---|---|
mylib_BigtoLittle16 | 在字节序之间转换 16 位值 | frm(源)、(目标)、(半字数)tosize |
mylib_BigtoLittle32 | 在字节序之间转换 32 位值 | frm(源)、(目标)、(字数)tosize |
mylib_BigtoLittle_fp64 | 转换 64 位浮点值 | dat(要转换的值) |
数字格式转换
| 功能 | 描述 | 参数 |
|---|---|---|
mylib_HEXtoBCD | 将二进制转换为 BCD | hex(二进制值) |
mylib_BCDtoHEX | 将 BCD 转换为二进制 | bcd(BCD 值) |
my_itoa | 将整数转换为字符串表示 | value(整数)、(输出缓冲区)、(数字基数)strradix |
htoi | 将十六进制字符串转换为整数 | s(十六进制字符串) |
字符串处理实用程序
系统提供了几个字符串处理函数,以方便数据格式化和解析:
| 功能 | 描述 | 参数 |
|---|---|---|
mylib_bytes_to_string | 将字节数组转换为十六进制字符串 | str(输出)、(源)、(长度)bytessize |
mylib_string_to_bytes | 将十六进制字符串转换为字节数组 | str(源)、(输出)bytes |
strlwr | 将字符串转换为小写 | str(要转换的字符串) |
strval | 从字符串中提取数字字符 | str(源)、(输出)num |
tolower | 将字符转换为小写 | c(角色) |
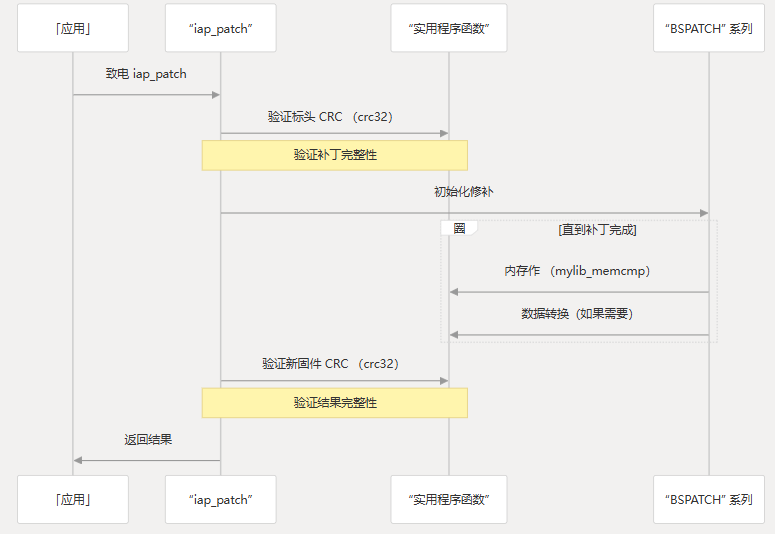
与 Patch Application Process 集成
实用程序功能集成在整个补丁应用程序过程中。下图说明了这些函数通常用于何处:
函数引用表
CRC 函数
| 功能 | 描述 | 返回值 |
|---|---|---|
crc32(const unsigned char *buf, unsigned int size) | 计算 CRC32 校验和 | 32 位 CRC 值 |
mylib_crc16(uint8_t *p, uint16_t size) | 计算 CRC16 校验和 | 16 位 CRC 值 |
内存功能
| 功能 | 描述 | 返回值 |
|---|---|---|
mylib_memcmp(const void *p1, const void *p2, int size) | 内存比较 | 如果相等,则为 TRUE,否则为 FALSE |
mylib_memcmp_b(uint8_t *p1, uint8_t value, int size) | 将内存与值进行比较 | 如果所有字节都等于值,则为 TRUE,否则为 FALSE |
mylib_sum(const uint8_t *p, uint16_t size) | 数组中的字节求和 | 32 位总和值 |
_msize(const void *mp) | 获取分配的内存大小 | 大小(以字节为单位) |
字节序函数
| 功能 | 描述 | 返回值 |
|---|---|---|
mylib_BigtoLittle16(const void *frm, void *to, uint16_t size) | 16 位字节序转换 | 无效 |
mylib_BigtoLittle32(const void *frm, void *to, uint16_t size) | 32 位字节序转换 | 无效 |
mylib_BigtoLittle_fp64(double dat) | 64 位浮点端转换 | 转换双倍 |
字符串函数
| 功能 | 描述 | 返回值 |
|---|---|---|
mylib_bytes_to_string(char *str, const uint8_t *bytes, int size) | 字节到十六进制字符串 | 输出字符串的长度 |
mylib_string_to_bytes(char *str, uint8_t *bytes) | 十六进制字符串到字节 | 输出数组的长度 |
strlwr(char *str) | 将字符串转换为小写 | 已转换的字符串指针 |
strval(char *str, char *num) | 提取数字字符 | 输出字符串的长度 |
常见使用模式
CRC 和实用程序函数最常用于以下场景:
- 补丁头验证:使用 CRC32 验证补丁头的完整性
- 内存作:在补丁应用程序期间,从旧固件读取和写入新固件时
- 数据格式转换:处理具有不同字节序要求的固件映像或补丁时
- 固件验证:修补后使用 CRC32 验证结果固件的完整性
结论
CRC 和实用程序功能构成了 MCU BSDiff 升级系统的关键支持层,可在嵌入式设备上实现可靠的固件修补。这些函数处理数据验证、内存作以及修补过程在资源受限的环境中正常工作所需的各种转换。