YOLO中model.predict方法返回内容Results详解
1.执行代码
results=model.predict('YOLO/ultralytics/assets/zidane.jpg')
print(results)
结果如下:
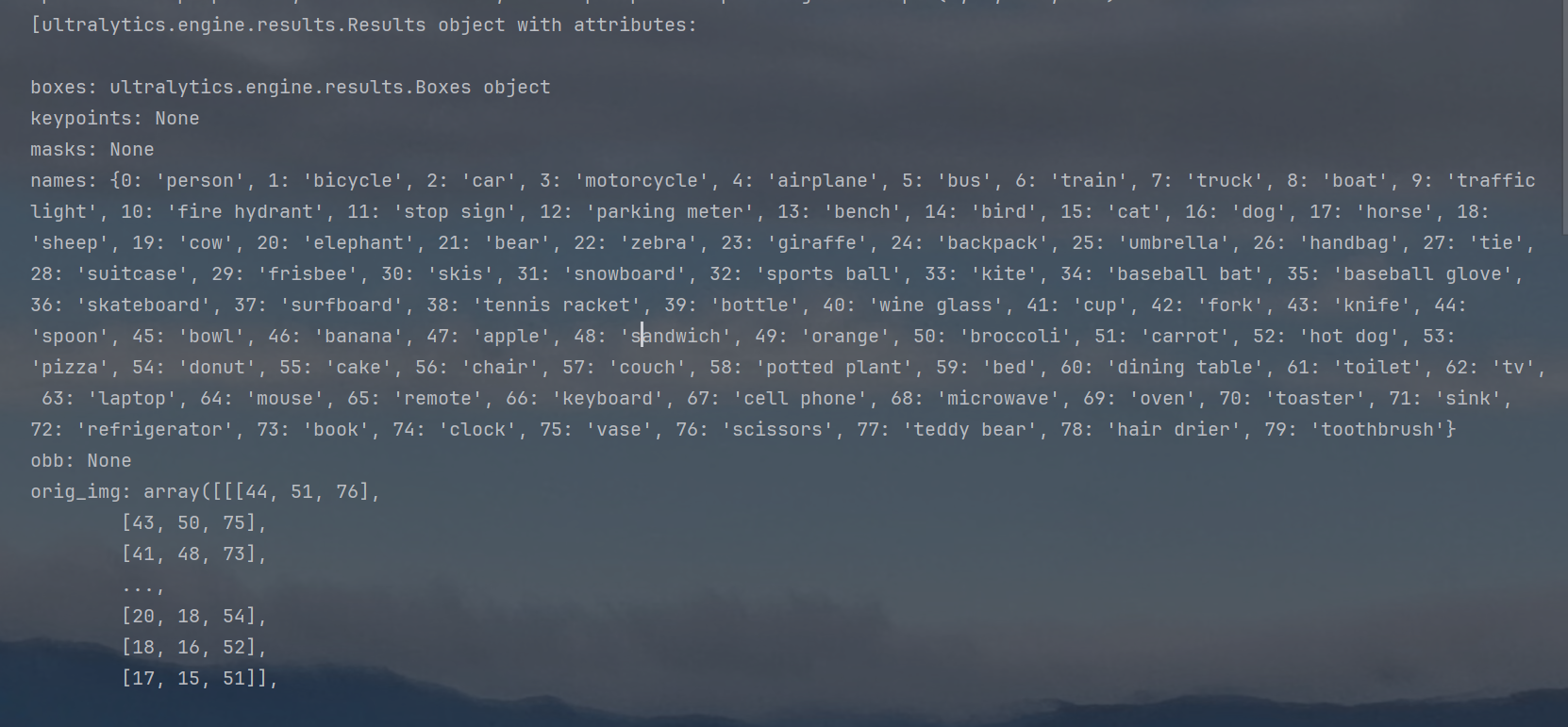

可以看出结果是一个数组形式,数组里每个元素都是Ultralytics的Results对象
1)为什么结果是数组,而不是单个对象?
因为有时候要预测的不是单张图片,而是一个批量,此时就有很多张图片,也就有很多个Results对象
2)Results对象里边有什么?
①boxes对象:存有每个预测框的信息(下边细讲)
②keypoints:关键点对象,包含每个对象的检测关键点(关键点估计那里会用上,这里没涉及)
③masks:包含检测掩码的掩码对象(就是目标检测的进一步好像,之前是用框来判定对象,现在是用掩码,这里没涉及)
④names:每类的名称与对应的索引index
⑤obb:包含定向包围盒的 OBB 对象(不是很了解,这里没涉及)
⑥orig_img:原始输入图像的array数组
⑦orig_shape:原始输入图像的高宽
⑧path:原始图像的路径
⑨probs:如果是分类任务,就会有每类的概率
⑩save_dir:预测结果保存的路径
⑪speed:预处理(进行缩放裁剪归一化等)、推理、后处理(置信度阈值过滤、非极大值抑制等)所花时间
2.查看boxes对象,执行如下代码
print(results[0].boxes)
结果如下:
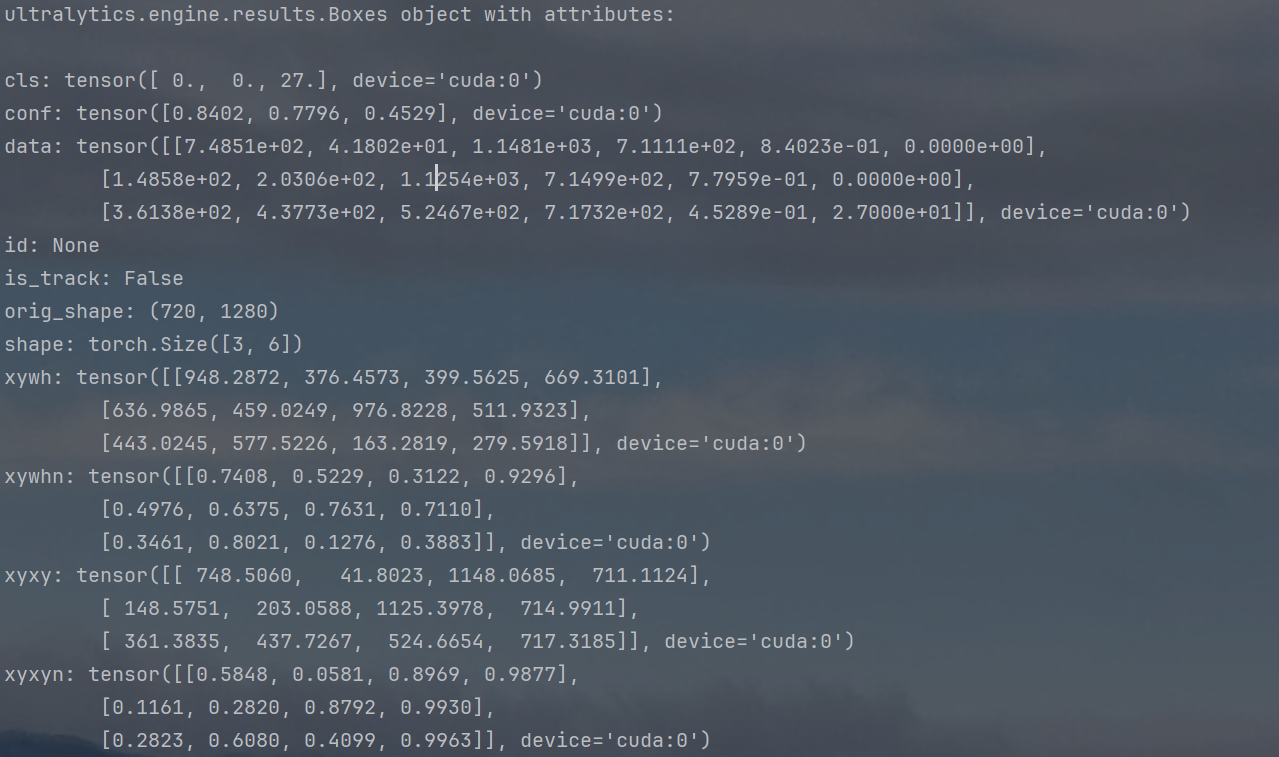
此时的boxes对象是包含了所有框的
①cls:有三个值[0.,0.,27.] ,对应的就是第1、2、3个框圈中的物体类别
②conf:存了所有框圈中物体的置信度
③data:是一个数组,每个数组的内容是[x_center, y_center, width, height,confidence, class_id],对应某个检测框的坐标、置信度、类别
④id:model.track方法会用上,定义相邻帧的物体是否是同一个
⑤is_track:判断是否在执行model.track方法
⑥orig_shape:同上
⑦shape:边界框数据的形状(3个框,每个框6个属性)
⑧xywh:框的坐标(中心点格式)
⑨xywhn:框的坐标(中心点格式且归一化)
⑩xyxy:边界框坐标(像素值)
⑪xyxyn:边界框坐标(像素值且归一化)
3.其实YOLO还为boxes对象实现了迭代方法,可以遍历每个框(具体实现得等我以后把源码读熟):
for box in results[0].boxes:print(box)
结果如下:
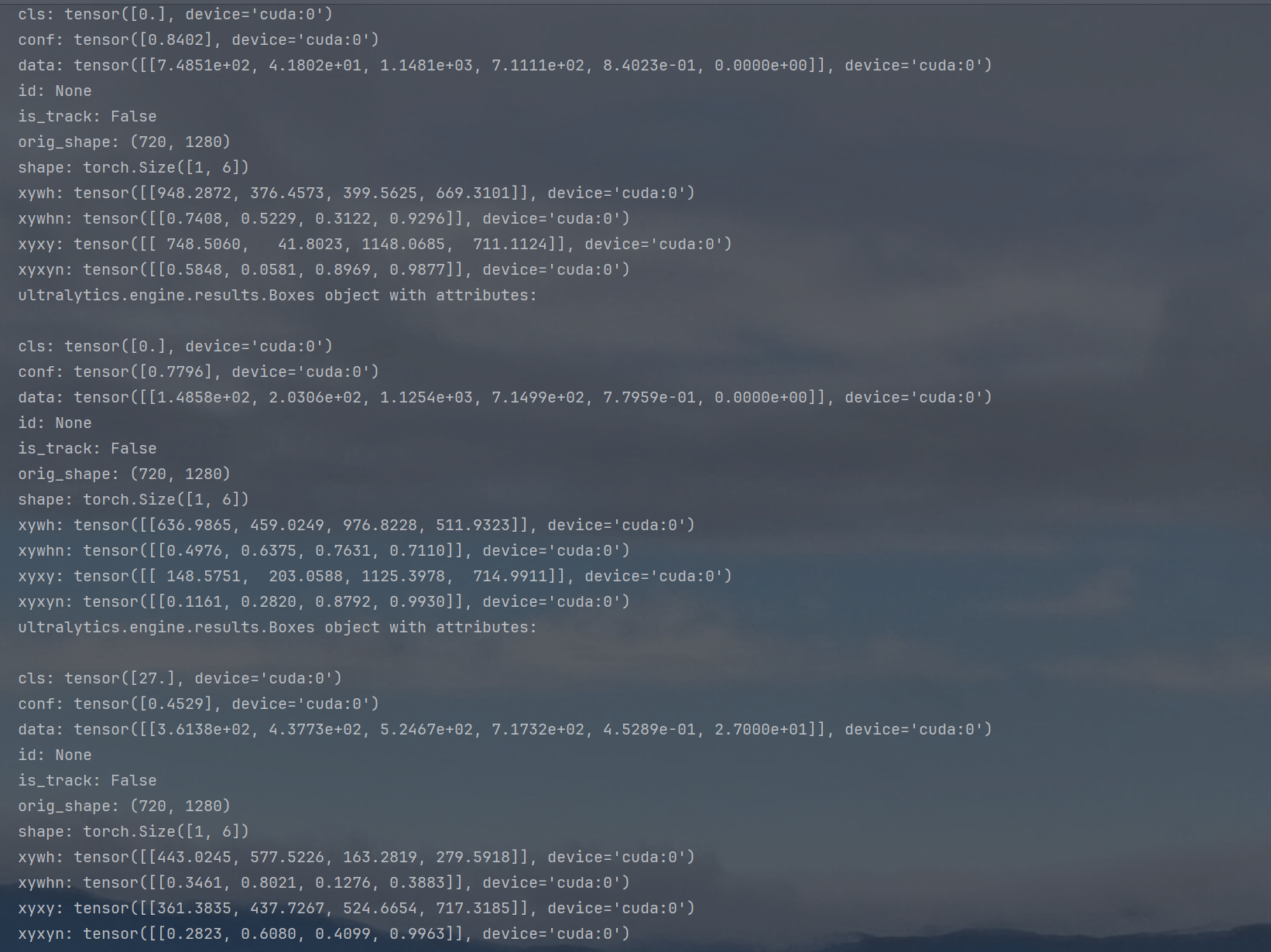
就是把上边的Boxes每个框信息拆开来了