deepseek系列论文汇总(时至2025.5)
deepseek系列论文汇总(时至2025.5)
- deepseek系列
- 一、基础架构与训练优化
- 二、推理能力与强化学习
- 三、前沿探索与技术创新
- 四、其他
- 研究价值与应用
deepseek系列
详细论文笔记查看:deepseek系列论文笔记
以下是截至2025年4月的DeepSeek系列核心论文汇总,涵盖架构创新、训练优化及推理能力突破等方向,按发布时间排序:
一、基础架构与训练优化
-
DeepSeek LLM
• 标题:DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
• 时间:2024年1月
• 链接:arXiv:2401.02954
• 突破:首次提出分组查询注意力(GQA)降低推理成本,并优化多步学习率调度器提升训练效率,奠定了后续模型的高效训练基础。 -
DeepSeekMoE
• 标题:DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models
• 时间:2024年1月
• 链接:arXiv:2401.06066
• 突破:通过细粒度专家分割与共享专家隔离策略,实现MoE架构的灵活性与性能平衡,计算成本不变下模型性能提升30%。 -
DeepSeek Math
• 标题:DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
• 时间:2024年2月
• 链接:arXiv:2402.03300
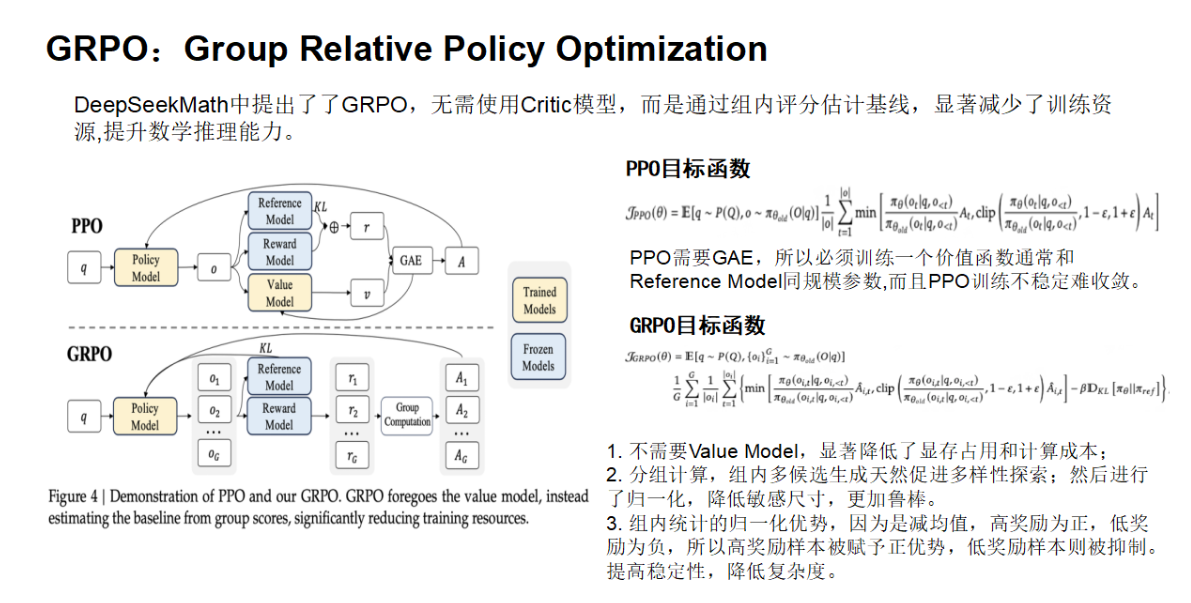
• 突破: 高效强化学习算法:提出组相对策略优化(GRPO),作为 PPO 的变体,通过群组奖励归一化和迭代训练机制,减少对价值网络的依赖,显著降低训练资源消耗,同时提升数学推理能力。 -
DeepSeek-V2
• 标题:DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
• 时间:2024年5月
• 链接:arXiv:2405.04434
• 突破:引入多头潜在注意力(MLA)机制,减少推理时KV缓存需求,使推理速度提升40%,训练成本降低50%。最后,我们遵循 DeepSeekMath (Shao et al., 2024) 采用组相对策略优化 (GRPO) 来进一步使模型与人类偏好保持一致,并产生 DeepSeek-V2 Chat (RL)。- 为了促进 MLA 和 DeepSeekMoE 的进一步研究和开发,我们还为开源社区发布了 DeepSeek-V2-Lite,这是一个配备 MLA 和 DeepSeekMoE 的较小模型。它总共有 15.7B 个参数,其中每个 token 激活了 2.4B。
-
DeepSeek-V3
• 标题:DeepSeek-V3 Technical Report
• 时间:2024年12月
[2024年12月27日提交(v1),最后修订于2025年2月18日(此版本,v2)]
• 链接:arXiv:2412.19437
• 突破:总参数量达671B,激活参数仅37B/Token,采用无辅助损失负载均衡策略,支持FP8混合精度训练,降低60%显存占用。
二、推理能力与强化学习
-
DeepSeek-R1
• 标题:DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
• 时间:2025年1月
• 链接:arXiv:2501.12948
• 突破:基于DeepSeek-V3-Base,通过多阶段强化学习训练(RL)显著提升逻辑推理能力,支持思维链(CoT)和过程透明化输出。 -
DeepSeek-R1 蒸馏模型
• 标题:Distilling Reasoning Capabilities from DeepSeek-R1 to Smaller Models
• 时间:2025年1月
• 链接:GitHub项目页
• 突破:将R1的推理能力迁移至Qwen、Llama等轻量模型,使小型模型在GSM8K等数学推理基准上准确率提升25%。
DeepSeek-R1-Zero是一个通过大规模强化学习(RL)训练的模型,在初步步骤中没有使用监督微调(SFT),它展示了出色的推理能力。通过强化学习,DeepSeek-R1-Zero自然地展现出许多强大且有趣的推理行为。然而,它也遇到了一些挑战,如可读性差和语言混用问题。
为了解决这些问题并进一步提升推理性能,我们引入了DeepSeek-R1,该模型在强化学习之前结合了多阶段训练和冷启动数据。
DeepSeek-R1在推理任务上的表现与OpenAI-o1-1217相当。为了支持研究社区,我们开源了DeepSeek-R1-Zero、DeepSeek-R1以及从DeepSeek-R1基于Qwen和Llama蒸馏出的六个密集模型(分别为15亿、70亿、80亿、140亿、320亿和700亿参数)。

二、推理优化版本
-
DeepSeek-R1(671B满血版)
- 核心能力:通过强化学习优化,专攻复杂推理(如数学计算、代码生成)。
- 训练流程:基于V3基座模型,分阶段融合冷启动数据与多领域微调。
-
R1-Zero
- 定位:R1训练中间产物,纯强化学习驱动,无人工调节。
- 用途:生成冷启动思维链数据,用于后续模型优化。
-
R1蒸馏版
- 分类:包括Qwen-1.5B/7B/32B、Llama-8B/70B等不同参数规模的轻量化版本。
- 优势:推理速度提升3-5倍,硬件成本降低90%。
三、前沿探索与技术创新
DeepSeek-V3
• 标题:DeepSeek-V3 Technical Report
• 时间:2024年12月
• 链接:arXiv:2412.19437
• 突破:总参数量达671B,激活参数仅37B/Token,采用无辅助损失负载均衡策略,支持FP8混合精度训练,降低60%显存占用。
四、其他
https://cloud.tencent.com/developer/article/2505000
研究价值与应用
• 学术工具化:部分成果已转化为论文辅助工具,如参考文献自动生成(支持GB/T 7714等格式)、选题建议与文献分析功能。
• 开源生态:DeepSeek-R1系列模型及代码已在GitHub开源,推动学术界在推理优化领域的协同创新。
如需获取完整论文列表或特定领域研究细节,可访问DeepSeek官方GitHub或arXiv平台检索标题关键词。
参考:
https://blog.csdn.net/weixin_44986037/category_12971052.html?spm=1001.2014.3001.5482
https://blog.csdn.net/youcans/article/details/145391398
https://cloud.tencent.com/developer/article/2505000