13.Ext系列文件系统
文件分类:
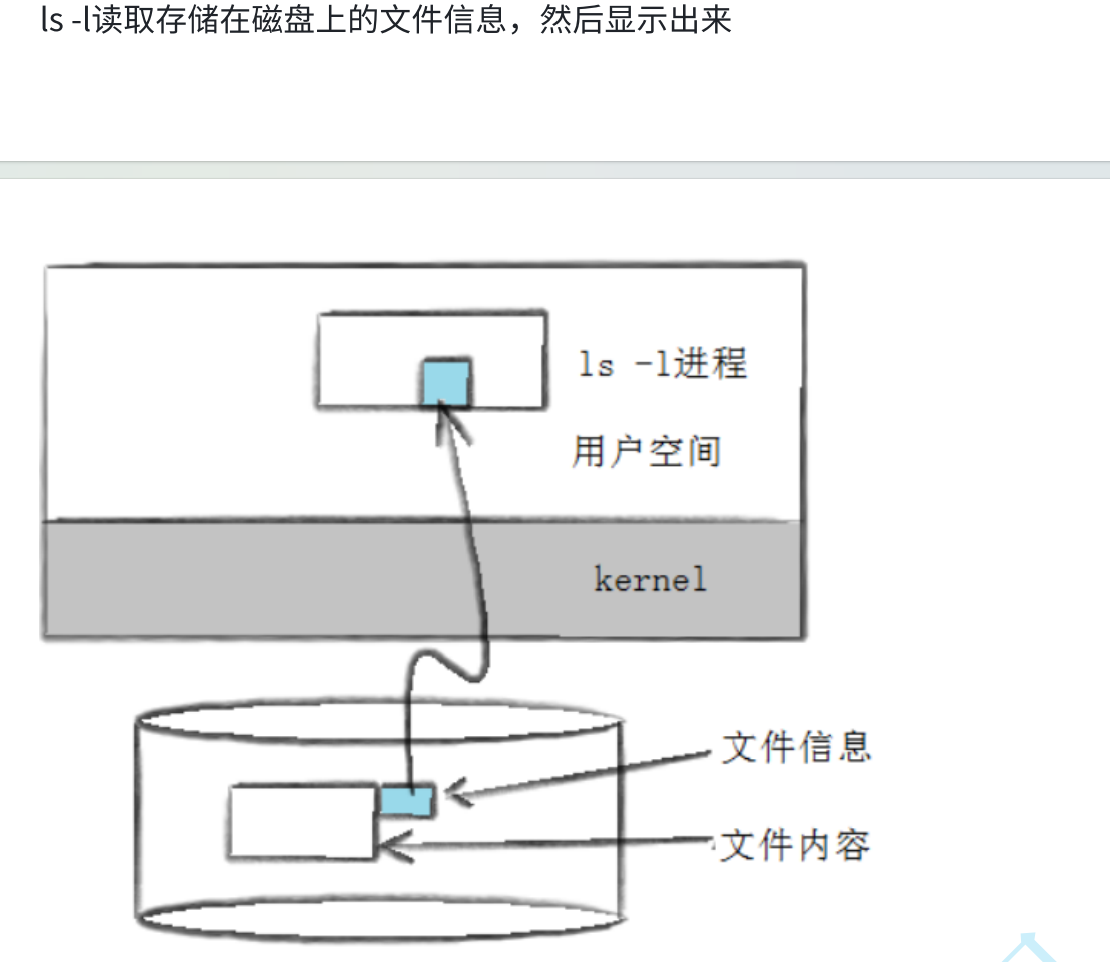
被打开的文件->基础IO,内存级的
没有被打开的文件->存在磁盘上
核心问题:如何被我们找到?
目录结构组织的,目录是树状的。(最基本诉求,文件系统)
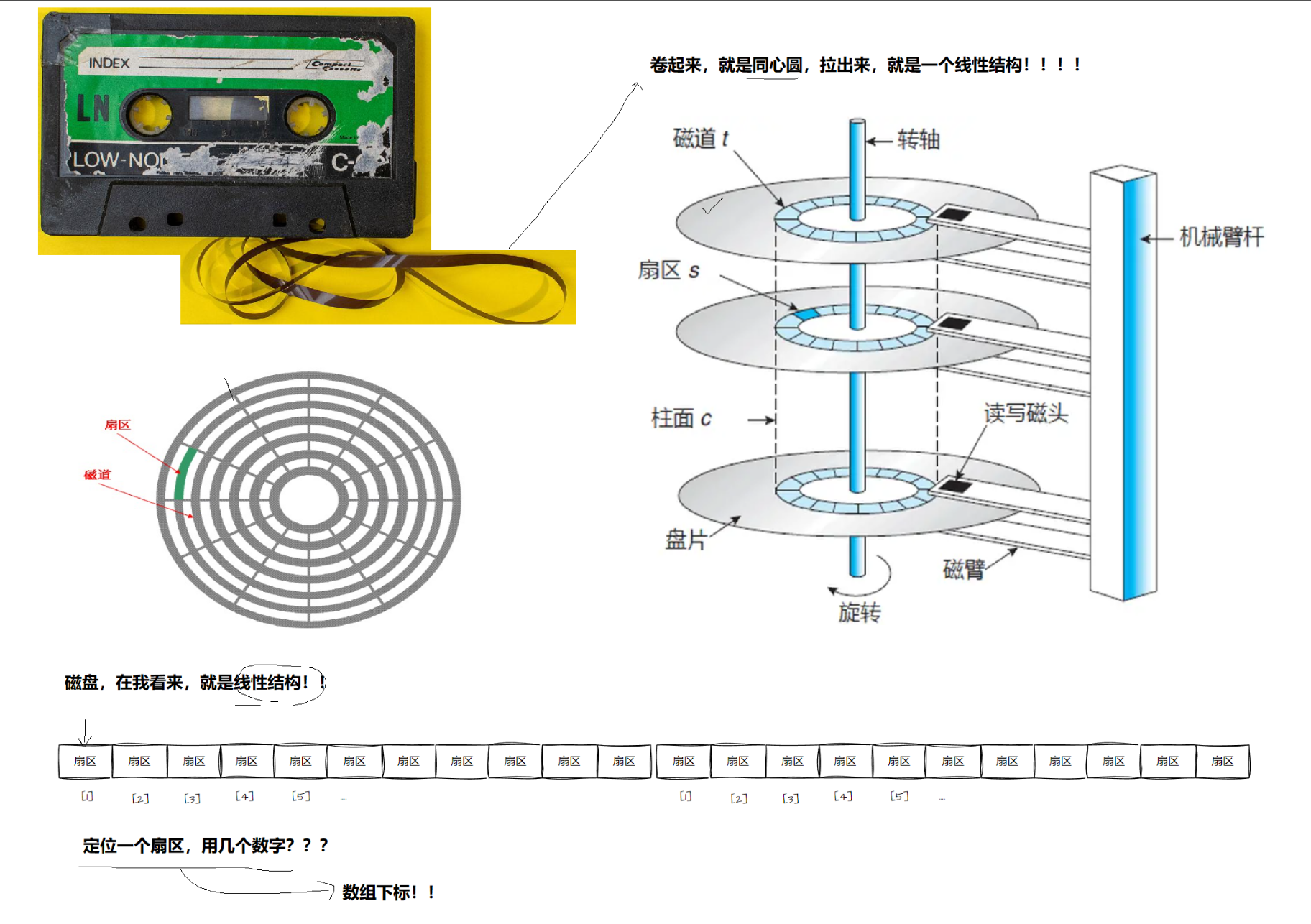
一、磁盘
磁盘用南北磁极表示0,1。
通过改变对应位置的南北级来改变数据表示。
高温可以消磁。
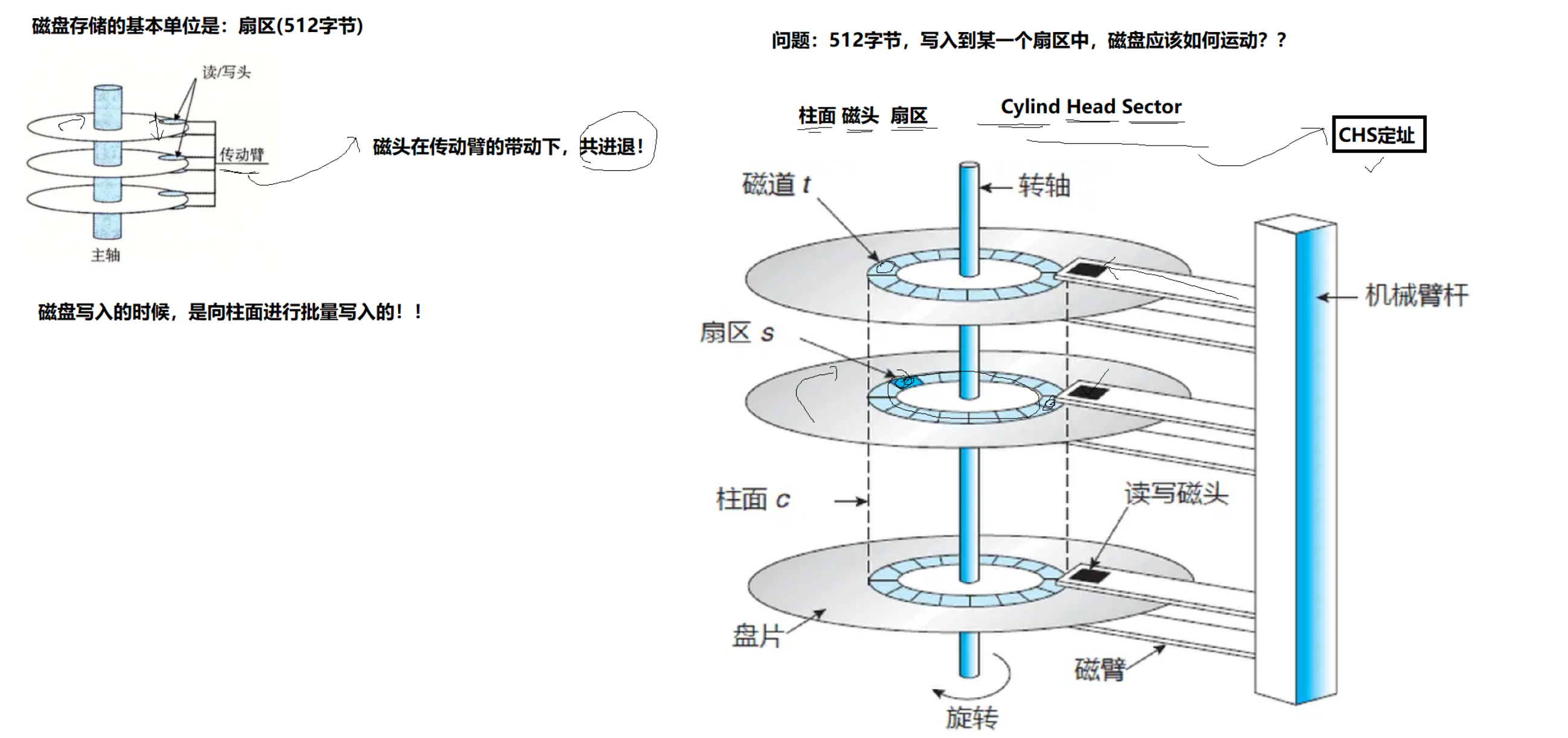
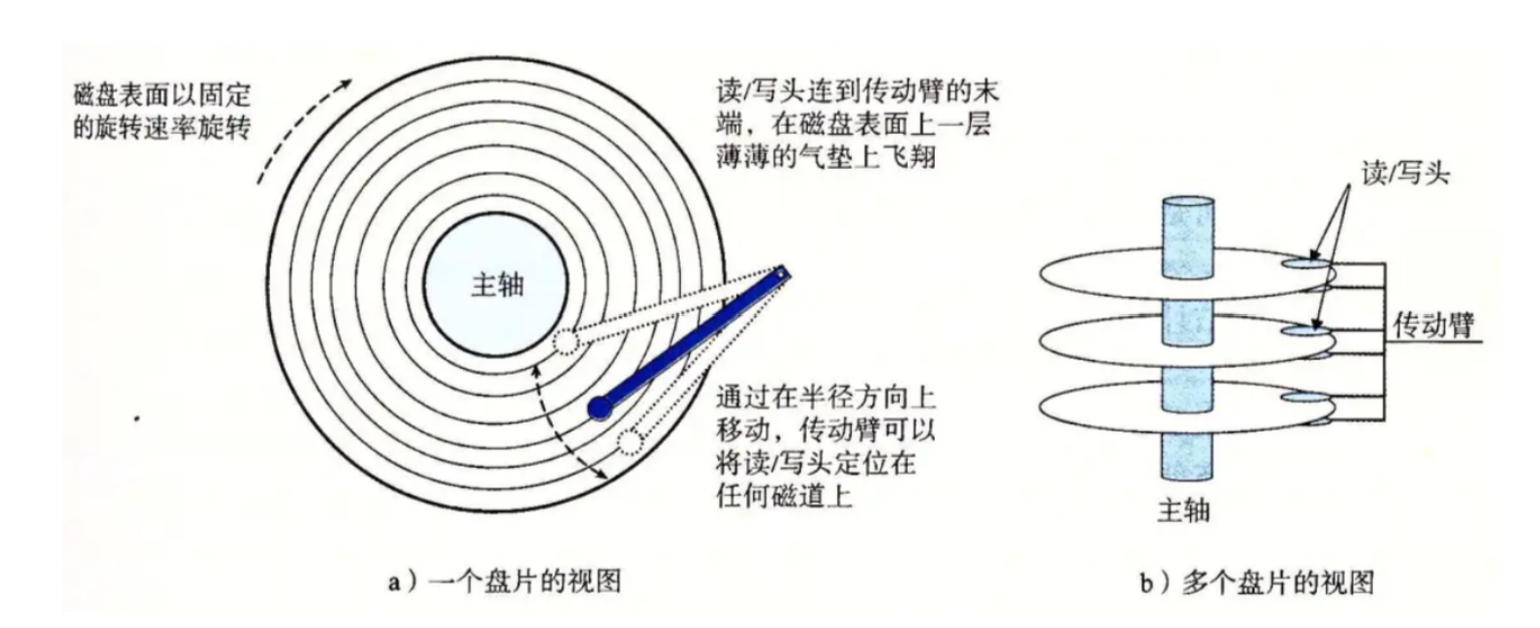
磁盘的物理结构:
磁盘存储的基本单位是:扇区(512字节)
磁头在传动臂的驱动下,是共进退的;因此,磁盘写入的时候,可以向柱面上批量写入。
CHS(Cylind Head Sector)定址:首先确定柱面,然后磁头确定对应的磁道,转轴带动盘片转动确定对应的扇区。
逻辑结构:
将磁盘的每个磁道拉直,就形成了一个数组,因此,对于磁盘的地址,只需采用一个数字(数组下标)即可记录,这种地址叫做LBA(Logical Block Address)。(线性结构)
注:扇区从1开始编号,磁头从0开始编号。
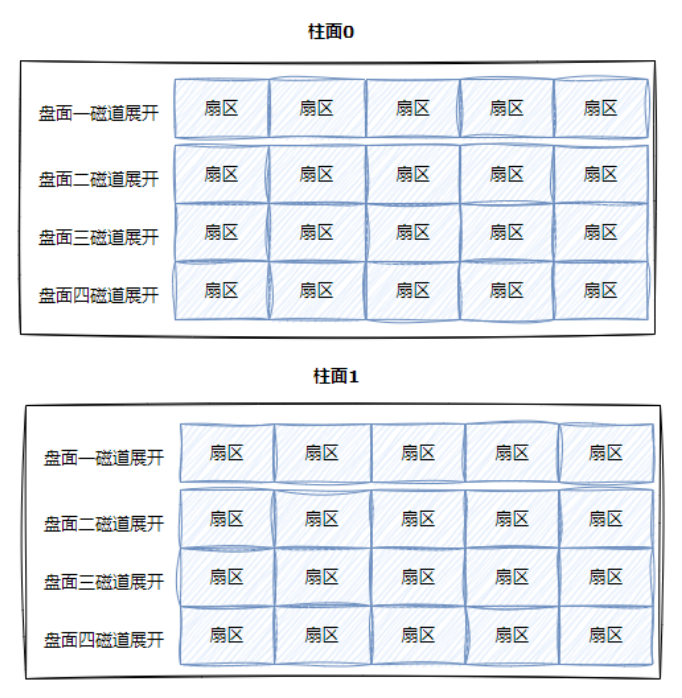
处于同一个柱面的磁道扇区数是相同的,对于同一个柱面,磁道和扇区就组成了一个二维数组,对于柱面,磁道,扇区,就组成了一个三维数组。(CHS定址)
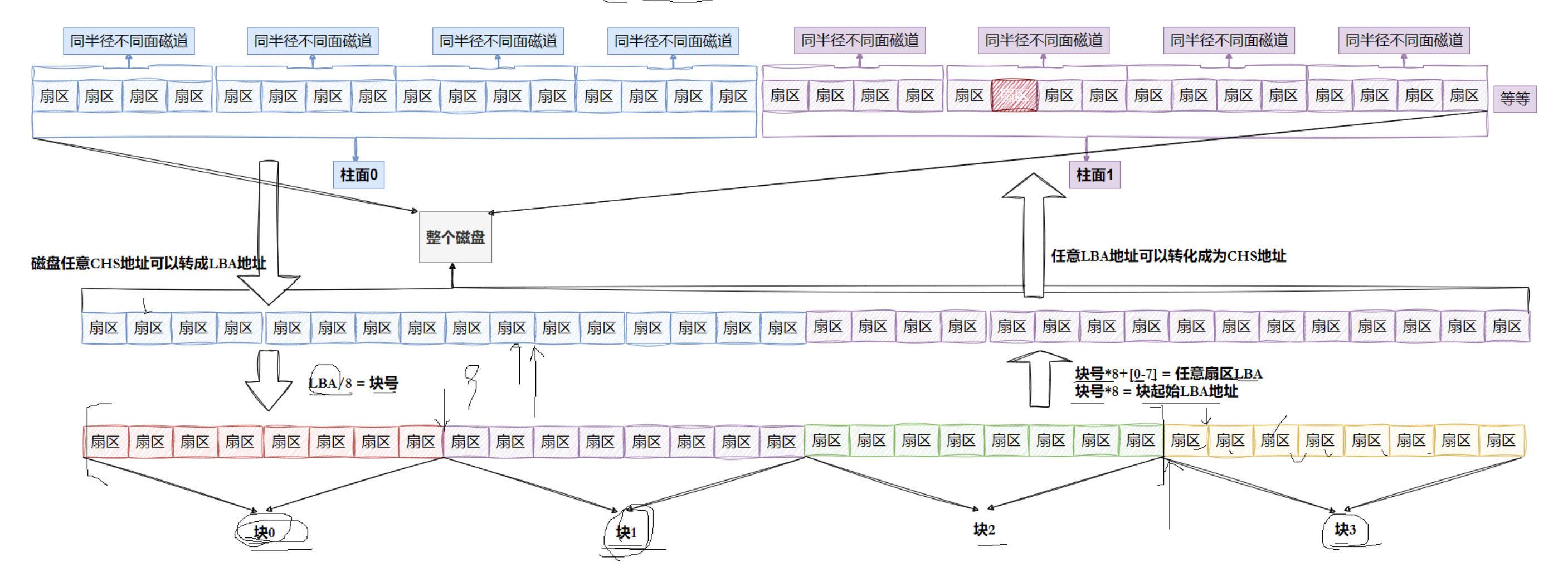
OS只需要使用LBA就可以了!!LBA地址转成CHS地址,CHS如何转换成为LBA地址。谁做啊??磁盘自己来做!固件(硬件电路)LBA转CHS:CHS转LBA:
二、文件系统(重点)
1.块概念,文件系统载体,inode
块的概念:OS访问磁盘,不以扇区为单位,而是以“块”为单位,一般是4KB(可调整),8个连续扇区。
块地址:
本质就是LBA地址,只不过记录块的起始LBA地址。
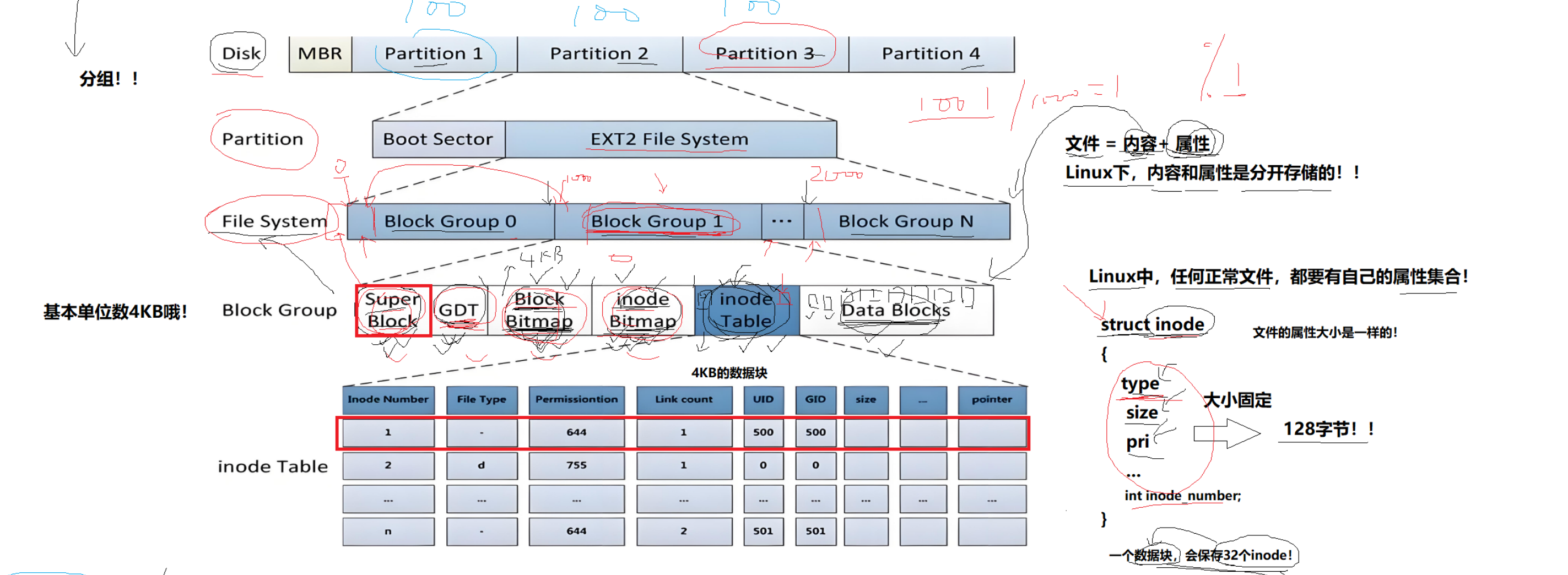
磁盘的管理,分区管理:
一个分区一套文件系统,文件系统的载体是分区,因此不同分区可以有不同文件系统。(分治思想)
文件=内容+属性;Linux下,内容和属性是分开存储的。
Linux中,任何正常文件,都有自己的属性集合,struct inode,大小固定,128字节。
特别地,文件名不会作为属性保存到inode中,原因:文件名大小可变,而inode大小固定。
文件名保存在目录的内容中,与inode相互映射。
ls -li查看文件的属性以及inode编号。
2.ext2文件系统
我们想要在硬盘上储文件,必须先把硬盘格式化为某种格式的文件系统,才能存储文件。文件系统的目的就是组织和管理硬盘中的文件。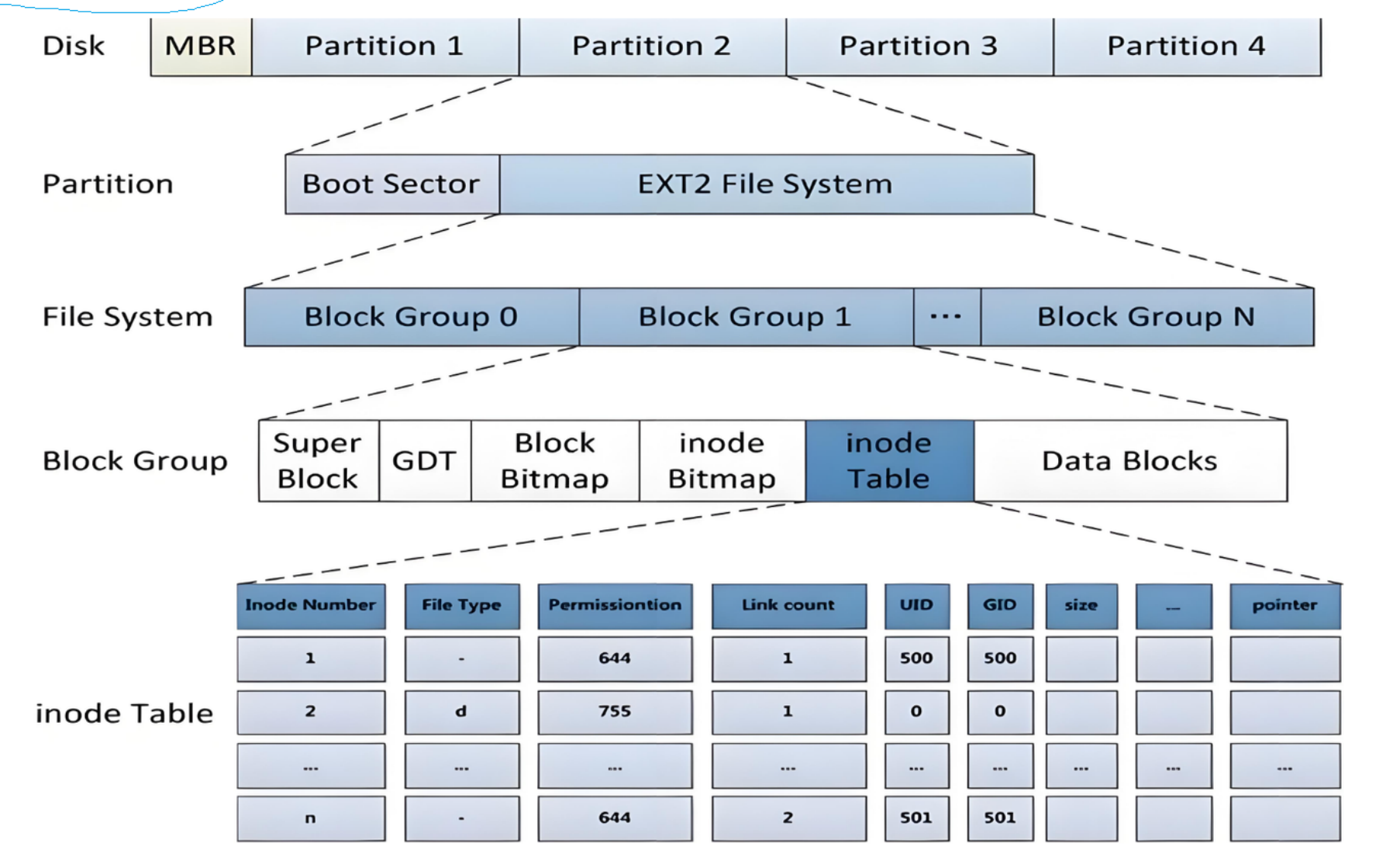 Block Group块组划分:1)Super Block(超级块): 存放文件系统本身的结构信息,描述整个分区的文件系统信息。记录的信息主要有:bolck 和 inode的 总量,未使用的block和inode的数量,⼀个block和inode的大小,最近一次挂载的时间,最近一次写入 数据的时间,最近⼀次检验磁盘的时间等其他文件系统的相关信息。Super Block的信息被破坏,可 以说整个文件系统结构就被破坏了。(分区全局属性)
Block Group块组划分:1)Super Block(超级块): 存放文件系统本身的结构信息,描述整个分区的文件系统信息。记录的信息主要有:bolck 和 inode的 总量,未使用的block和inode的数量,⼀个block和inode的大小,最近一次挂载的时间,最近一次写入 数据的时间,最近⼀次检验磁盘的时间等其他文件系统的相关信息。Super Block的信息被破坏,可 以说整个文件系统结构就被破坏了。(分区全局属性) 超级块在每个块组的开头都有一份拷贝(第一个块组必须有,后面的块组可以没有)。 但是为了保险起见,其他位置有可能有。2)GDT(块注描述符表, Group Descriptor Table): 描述块组属性信息,整个分区分成多个块组就对应有多少个块组描述符。每个块组描 述符存储⼀个块组 的描述信息,如在这个块组中从哪里 开始是inode Table,从哪里 开始是Data Blocks,空闲的inode和数据块还有多少个等等。 块组描述符在每个块组的开头都有一份拷贝。(分区全局属性)类似于进程地址空间的struct mm_struct,记录各个分区的开始和结束位置。
超级块在每个块组的开头都有一份拷贝(第一个块组必须有,后面的块组可以没有)。 但是为了保险起见,其他位置有可能有。2)GDT(块注描述符表, Group Descriptor Table): 描述块组属性信息,整个分区分成多个块组就对应有多少个块组描述符。每个块组描 述符存储⼀个块组 的描述信息,如在这个块组中从哪里 开始是inode Table,从哪里 开始是Data Blocks,空闲的inode和数据块还有多少个等等。 块组描述符在每个块组的开头都有一份拷贝。(分区全局属性)类似于进程地址空间的struct mm_struct,记录各个分区的开始和结束位置。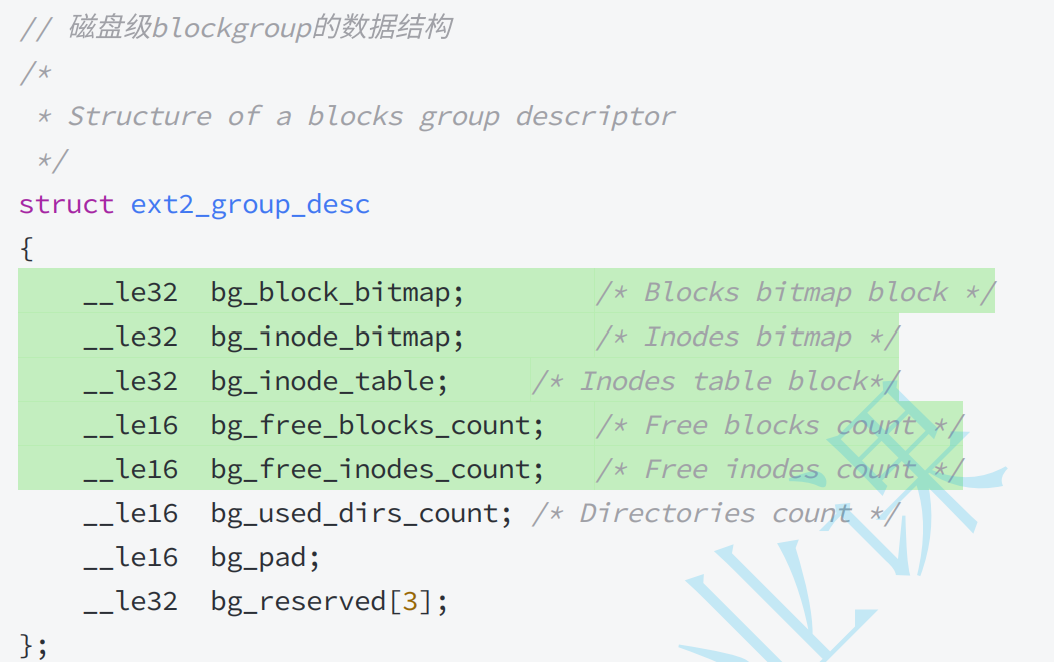 3)Block Bitmap(块位图):记录Data Block中块的使用情况。4)Inode Bitmap(inode位图): 每个bit表示一个inode是否空闲可用。5)inode Table(inode节点表):存储inode,同一分区跨组编号,不可跨分区。6)Data Block(数据块):存储数据,同一分区跨组编号,不可跨分区。
3)Block Bitmap(块位图):记录Data Block中块的使用情况。4)Inode Bitmap(inode位图): 每个bit表示一个inode是否空闲可用。5)inode Table(inode节点表):存储inode,同一分区跨组编号,不可跨分区。6)Data Block(数据块):存储数据,同一分区跨组编号,不可跨分区。
 回归最原本问题(如何找到文件),拿到一个文件的inode,就可以找到文件的所有内容。原因:inode中有datablocks数组,记录该文件对应的数据块的编号,拿到了编号就可以得到该文件的内容。如何确定分组?有了inode号(inode分区内跨组编号),每个分组inode数量是固定的,通过除运算,可以得到组号,通过取模运算,可以得到在该组的位置。
回归最原本问题(如何找到文件),拿到一个文件的inode,就可以找到文件的所有内容。原因:inode中有datablocks数组,记录该文件对应的数据块的编号,拿到了编号就可以得到该文件的内容。如何确定分组?有了inode号(inode分区内跨组编号),每个分组inode数量是固定的,通过除运算,可以得到组号,通过取模运算,可以得到在该组的位置。
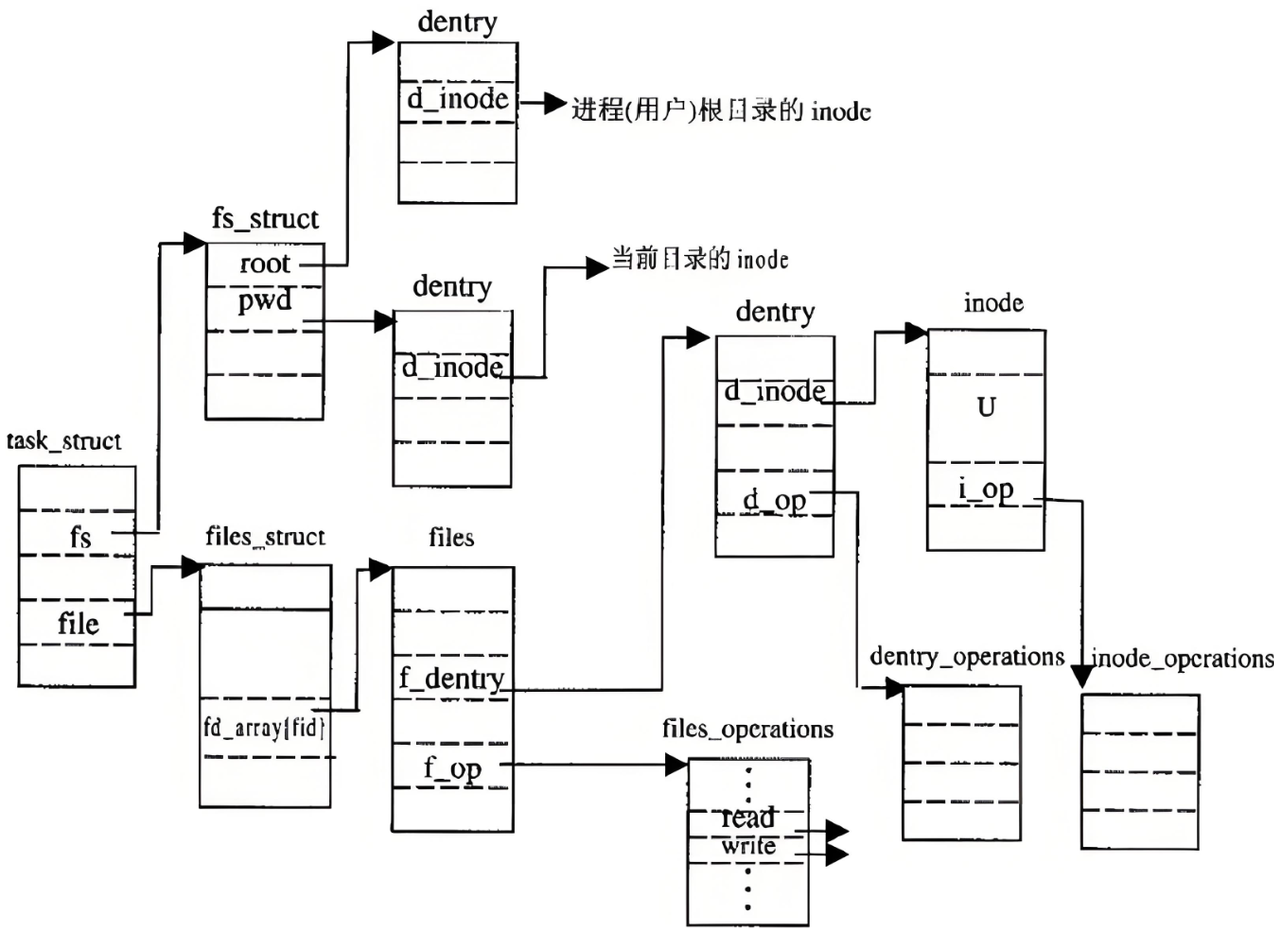
Linux下如何看待目录:文件=内容+属性,文件名不保存在属性inode里,那么就只能保存在内容里。文件名保存在当前文件上级目录的数据内容里。inode和数据内容有映射关系,文件名和inode有映射关系,文件系统只认inode。我们访问任何文件,都必须要有路径!路径+文件名,先打开对应的路径,读取上级目录的内容,找到文件名,找到文件名对应的inode,就拿到了inode对应的数据内容。(上级目录内容->文件名->inode->inode对应内容)路径由谁提供?进程提供。
我们访问任何文件都要从根目录开始进行路径解析->每次路径解析都是IO操作->效率低-> OS会在进行路径解析时,会把我们历史访问的所有目录(路径)形成一颗多叉树进行保存(内存及的)。Linux磁盘中,不存在真正的目录,只有文件。只保存文件属性+文件内容。
Linux目录的概念,怎么产生的?打开的文件是目录的话,由OS自己在内存中进行路径维护。
 多叉树大小有限制,使用lru算法,来实现节点淘汰。为了方便查找,有哈希结构。这个树形结构,整体构成了Linux的路径缓存结构,打开访问任何文件,都在先在这棵树下根据路径进行查找,找到就返回属性inode和内容,没找到就从磁盘加载路径,添加dentry结构,缓存新路径。
多叉树大小有限制,使用lru算法,来实现节点淘汰。为了方便查找,有哈希结构。这个树形结构,整体构成了Linux的路径缓存结构,打开访问任何文件,都在先在这棵树下根据路径进行查找,找到就返回属性inode和内容,没找到就从磁盘加载路径,添加dentry结构,缓存新路径。
挂载分区(根据路径确定分区)
挂载概念:
磁盘->分区->格式化->我们依旧不能使用这个分区,这个分区不是目录,不能直接进入。我们的分区,一定要和特定的某个目录关联->通过进入这个目录,就相当于进入这个分区(挂载)
得到了文件code.c的inode,如何确定分区?根据路径。
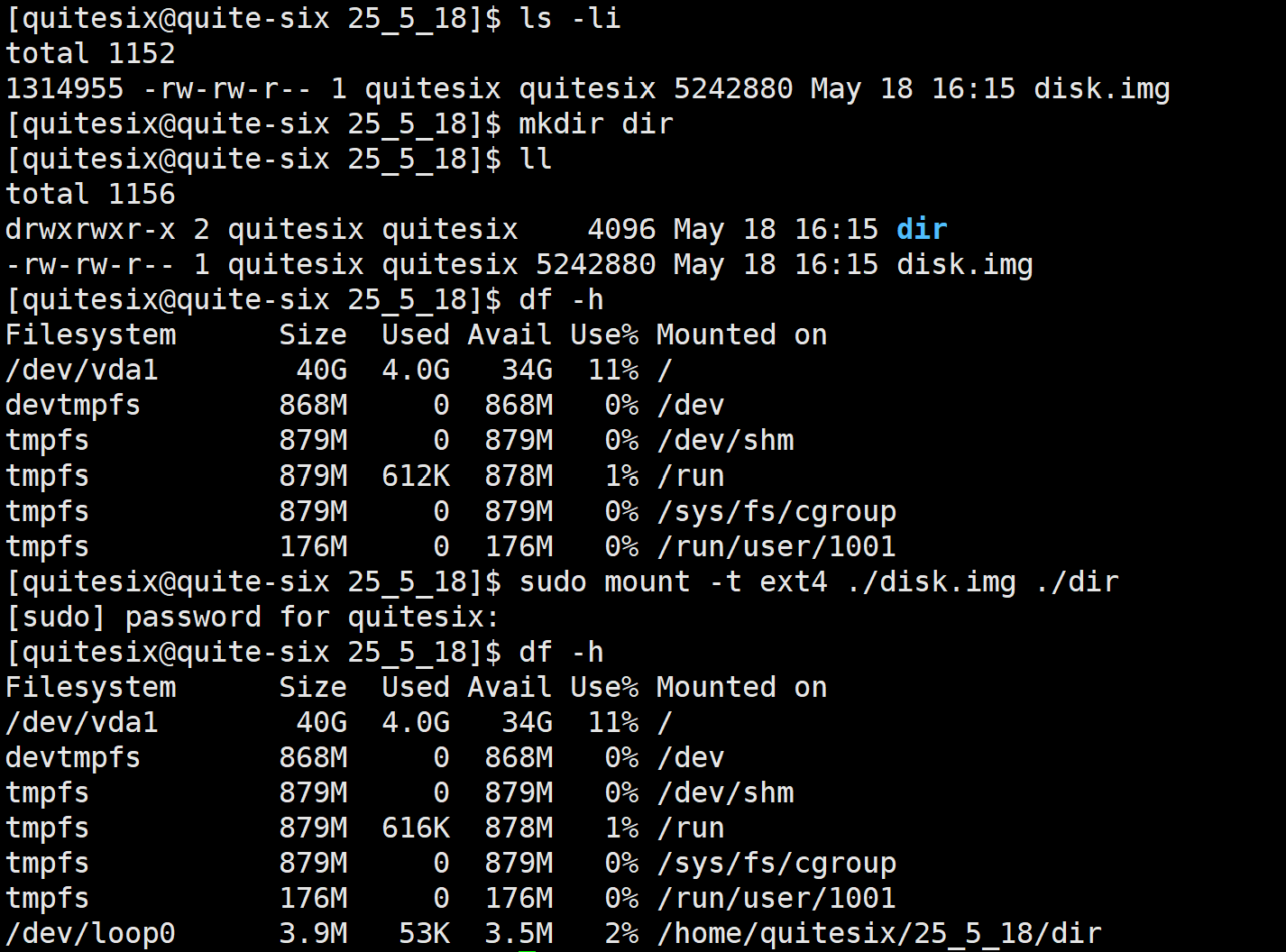
实验:
dd if =/dev/zero of=./disk.img bs=1M count=5 #制作 一个大的磁盘块,就当做一个分区mkfs.ext4 disk.img # 格式化 写入文件系统df -h # 查看可以使用的分区sudo mount -t ext4 ./disk.img ./dir # 将分区挂载到指定的目录sudo umount ./dir # 卸载分区
/dev/loop0 在Linux系统中代表第⼀个循环设备(loop device)。循环设备,也被称为回环设备或者loopback设备,是⼀种伪设备(pseudo-device),它允许将文件作为块设备(block device)来使用。 这种机制使得可以将文件(比如ISO镜像文件)挂载(mount)为文件系统,就像它们是物理硬盘分区或者外部存储设备⼀样。结论:分区写入文件系统,无法直接使用,需要和指定的目录关联,进行挂载才能使用。所以,可以根据访问目标文件的"路径前缀"准确判断我在哪⼀个分区。
总结:
3.软链接和硬链接
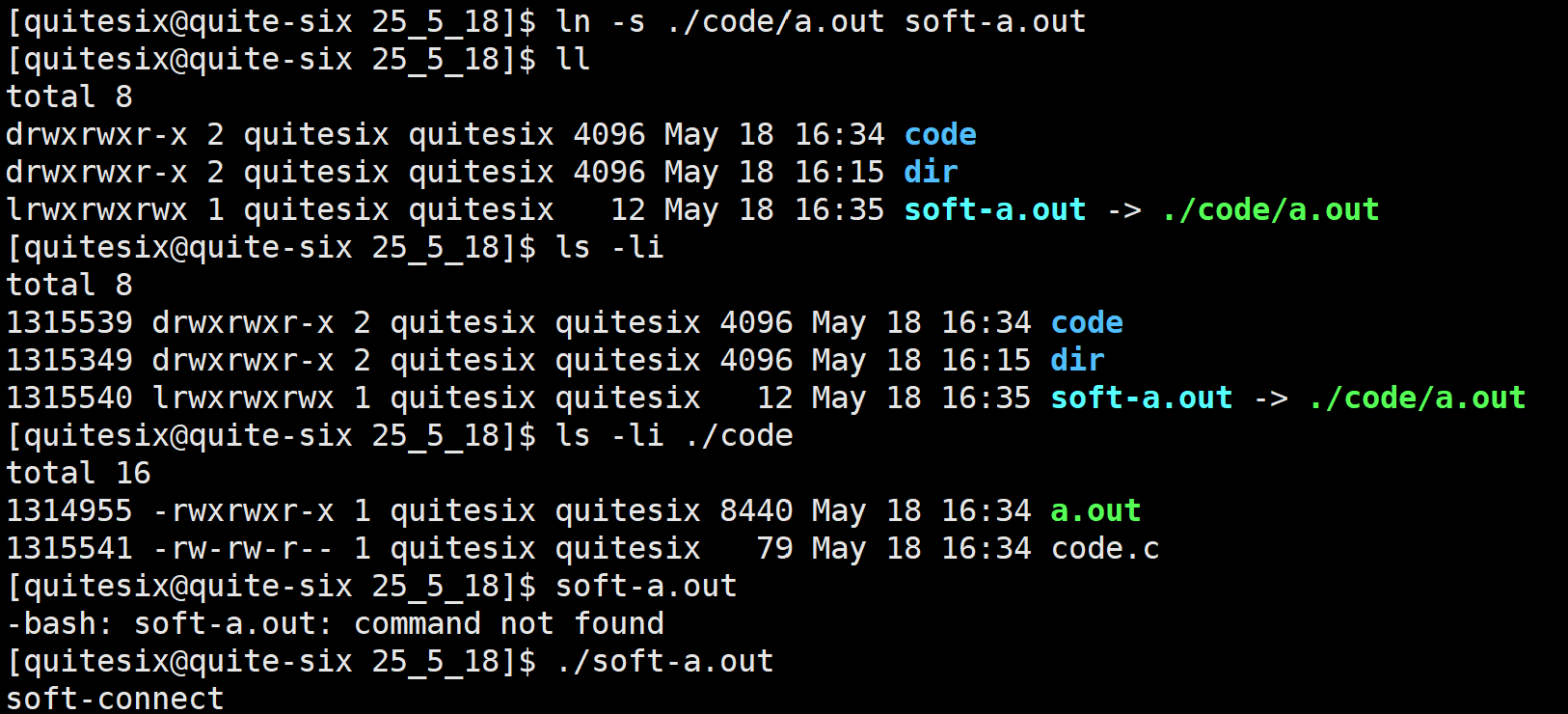
软链接:独立的文件,内容+属性,内容中保存目标文件的路径。
用途:快捷方式。
操作:ln -s srcfile dstfile
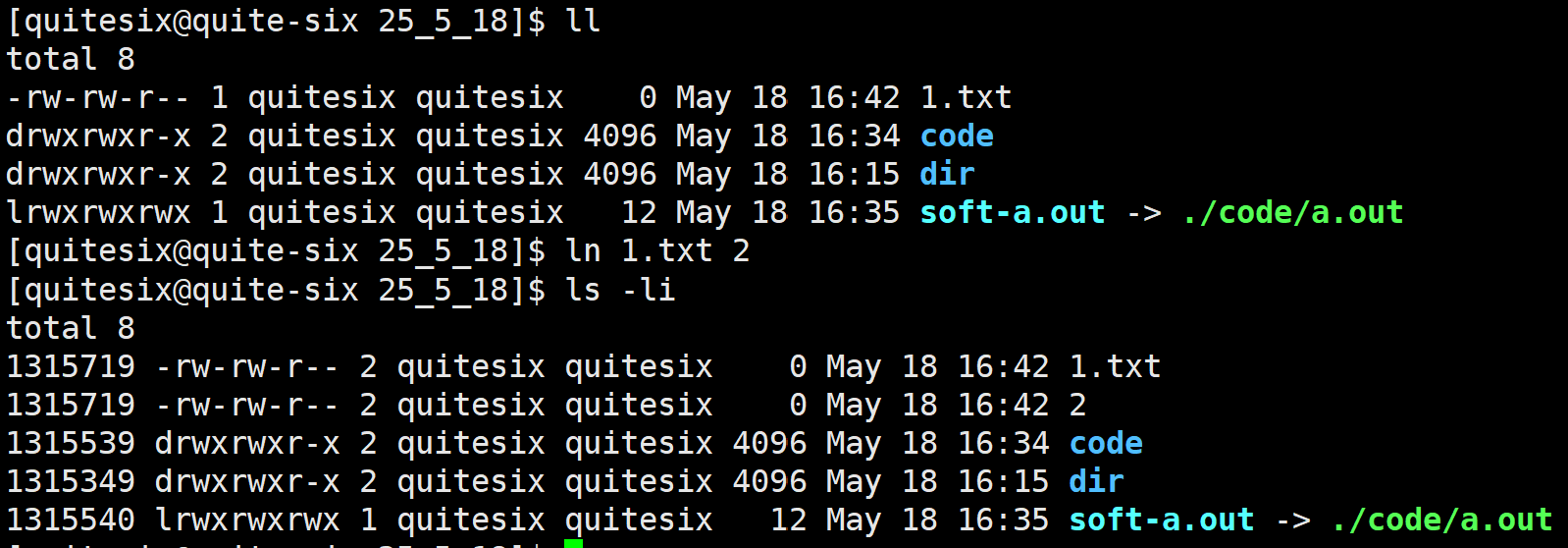
硬链接:不是独立的文件,本质是一组新的文件名指向目标文件。
用途:文件的备份
操作:ln src dst
文件内部有引用计数,_i_links_counts,硬链接的引用计数。
.表示当前目录,.是当前目录的硬链接。
..表示上级目录,..是上级目录的硬链接。
我们在删除文件时干了两件事情:1.在目录中将对应的记录删除,2.将硬连接数-1,如果为0,则将对应的磁盘释放。