【Linux】进程的基本概念
目录
- 概念
- 描述进程-PCB
- 如何查看进程
- 通过系统目录进行查看
- 通过ps指令进行查看
- 通过系统调用获取进程的PID和PPID(进程标⽰符)
- 通过系统调用创建子进程
- 通过一段代码来介绍fork
- 为什么要有子进程?
- fork为什么给子进程返回0,给父进程返回子进程的PID
- fork函数到底做了啥?
- 一个函数是如何做到返回两次的?
- 一个变量为什么会有不同的内容?
- 通过fork来理解bash的命令行是如何来工作的?
- end
概念
课本概念: 程序的一个执行实例,正在执行的程序等。(就是执行任务)
内核观点: 担当分配系统资源(CPU时间,内存)的实体。
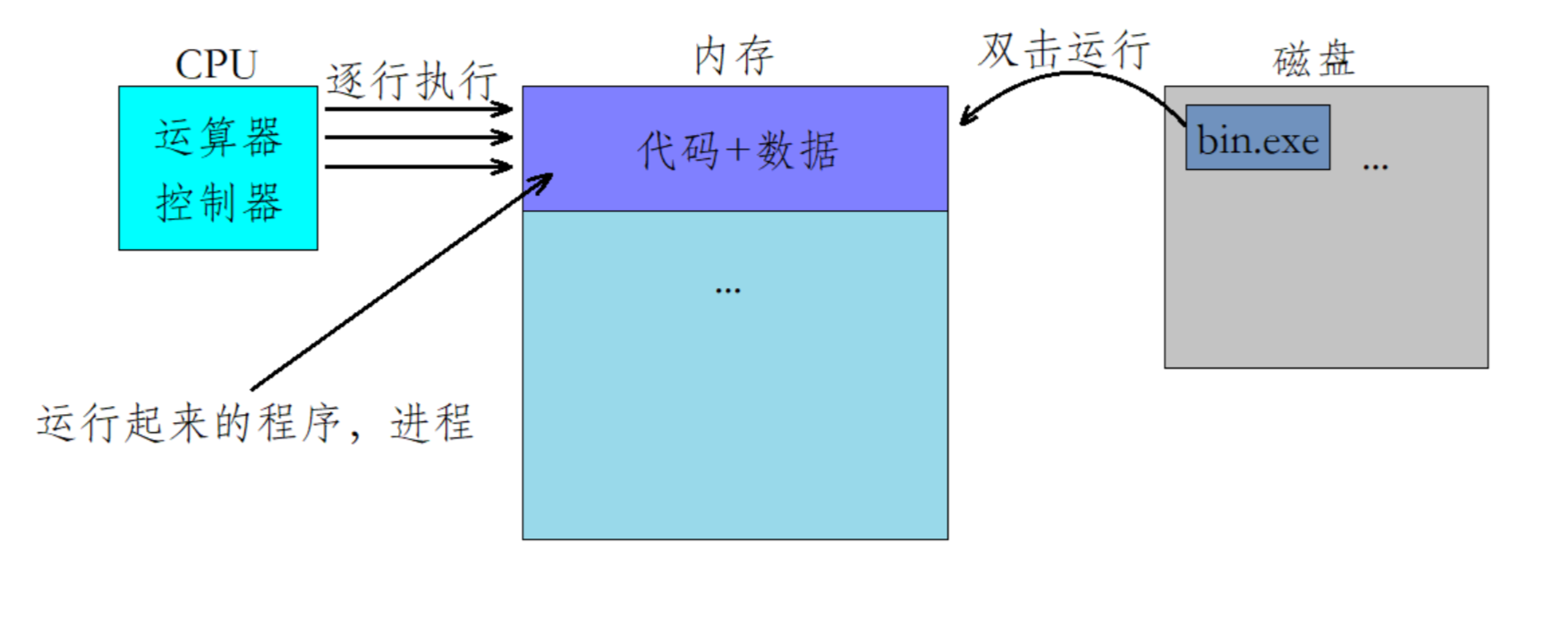
- 我们写完代码后经过编译和链接后形成一个可执行文件,打开这个可执行文件就会加载到内存中交给CPU处理,CPU才能对其进行逐行的语句执行,而一旦将这个程序加载到内存后,我们就不应该将这个程序再叫做程序了,严格意义上将应该将其称之为进程。
描述进程-PCB
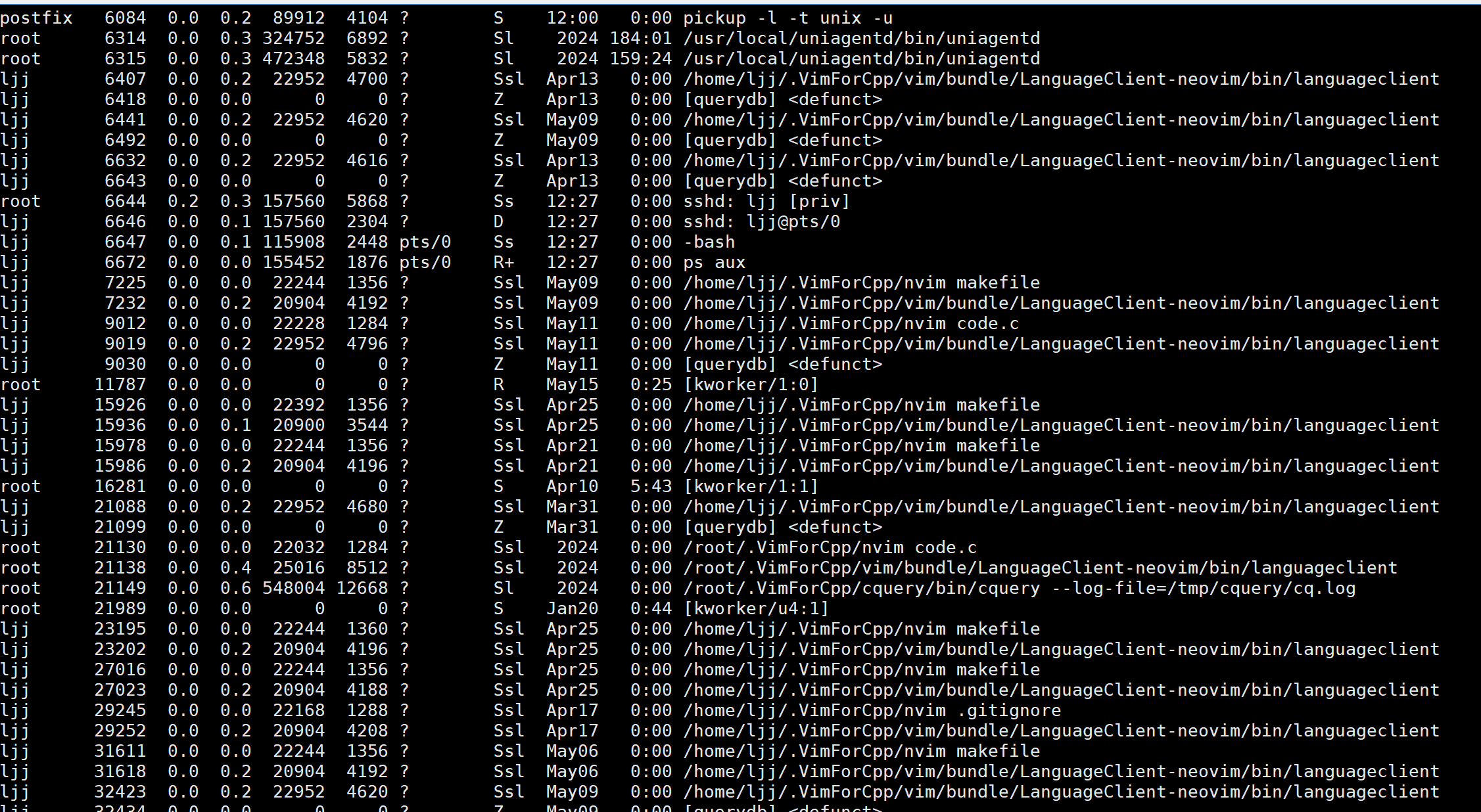
- 系统当中可以同时存在大量进程,使用命令ps aux便可以显示系统当中存在的进程。
- 而我们开机第一个运行的就是操作系统,运行操作系统就是一个进程。我们都知道操作系统是软件和硬件的管理者,那么进程也是操作系统来管理的。那么操作系统到底是如何来管理进程的呢?
- 这时我们就应该想到管理的六字真言:先描述,再组织t操作系统也是一样的,操作系统并不需要直接的和进程见面进行管理,而是对进程的属性进行描述,而操作系统只需要对这些描述的信息进行管理就行了。
- 那么描述进程属性是存放在哪里的呢。他是存放在一个叫做PCB的数据结构中,在Linux操作系统下,我们把他称为task_struct.
- 操作系统将每一个进程都进行描述,形成了一个个的进程控制块(PCB),并将这些PCB以双链表的形式组织起来。
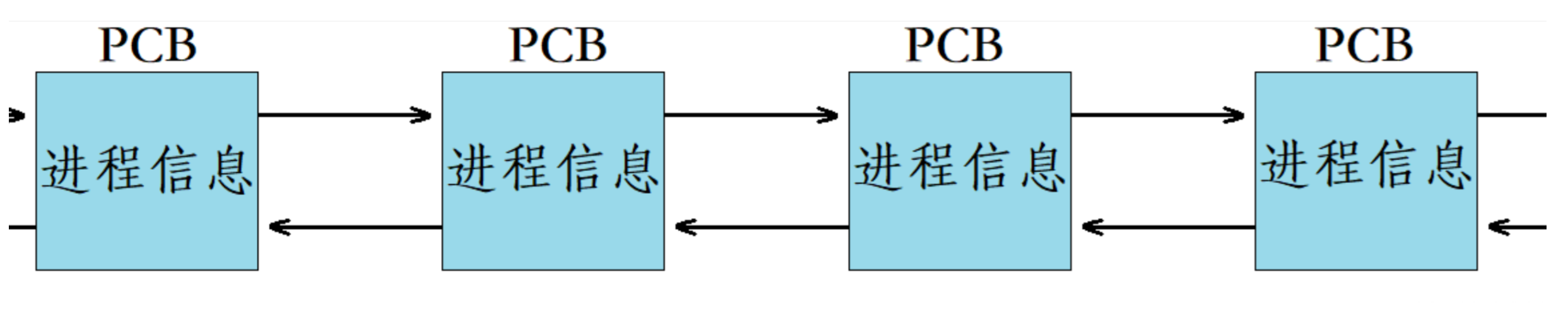
把这些PCB用双链表组织起来,那么我们只需要遍历双链表就可以访问到所有的PCB,如果我们要删除某个进程的信息,就是删除双链表对应的节点,所以对进程的管理实际上就是数据结构的增删查改。
如何查看进程
通过系统目录进行查看
- 在根目录下有一个叫做proc的文件,这里面就是我们Linux下的所有进程
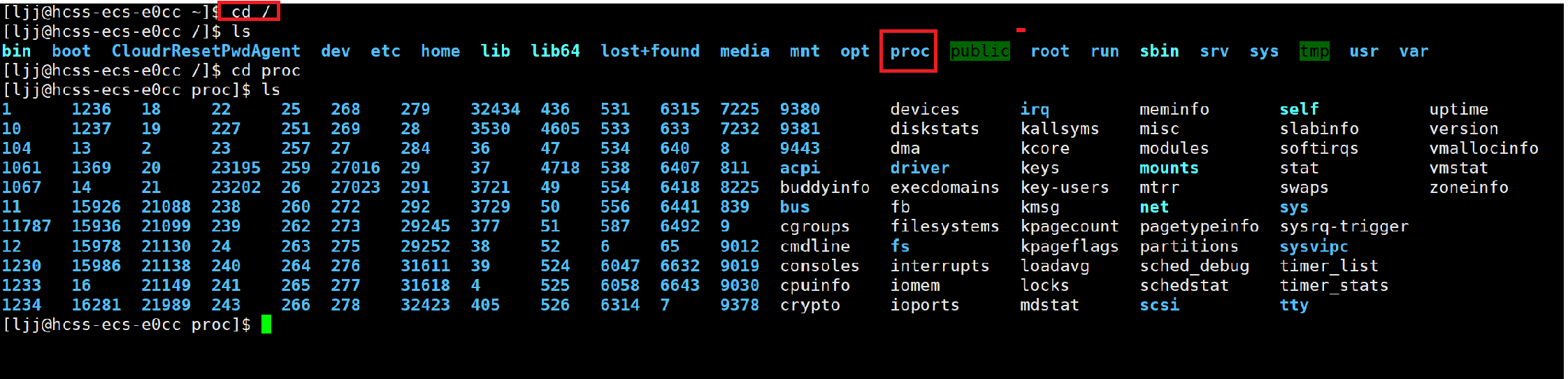
- 这些进程的名字有的名字是一个数字,这些数字其实就是进程的PID(可以理解为身份证)
- 如果我们想要查看进程的信息,就可以用ls指令来显示这些文件,这就是进程的信息

通过ps指令进行查看
- 单独使用ps命令,会显示所有进程信息。
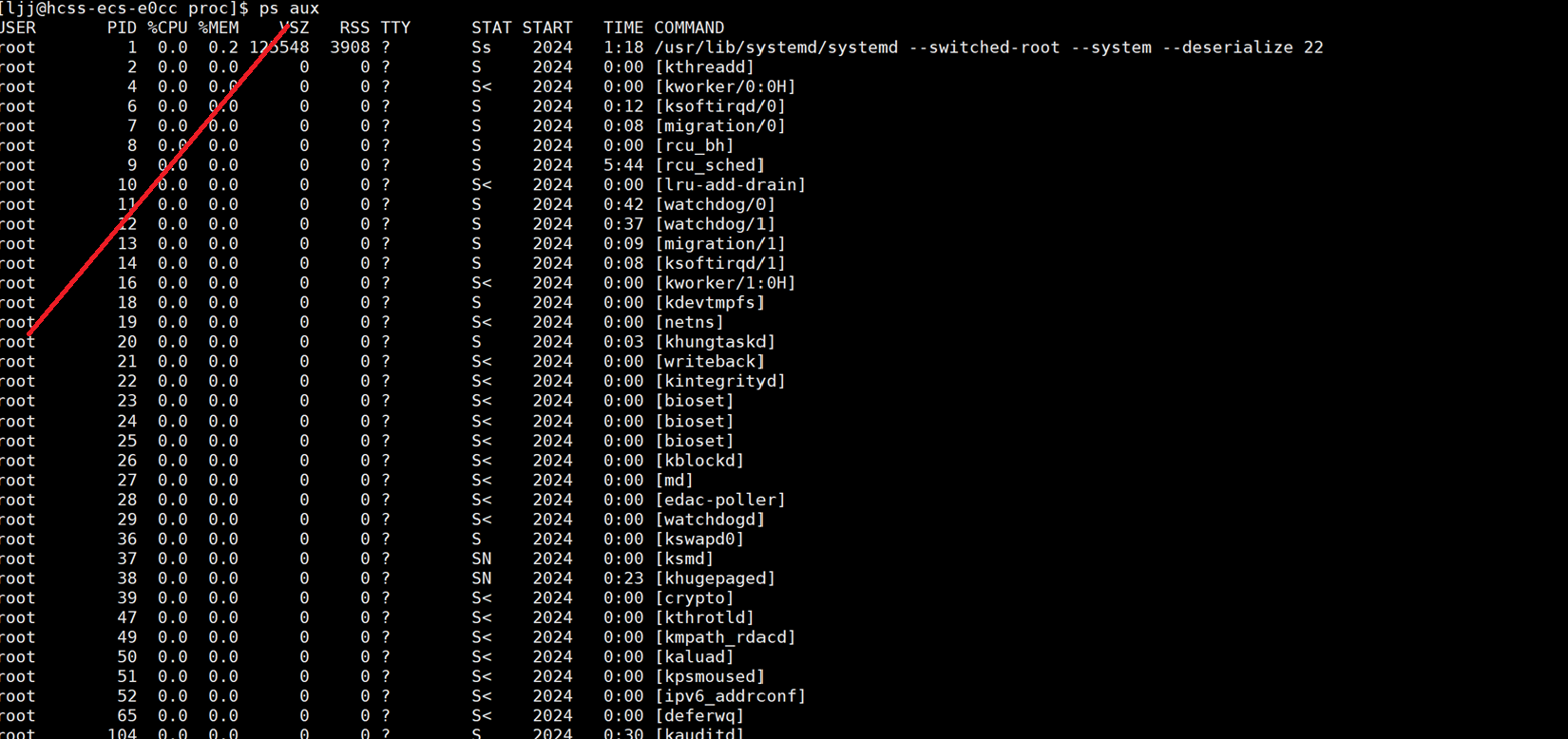
- ps命令与grep命令搭配使用,即可只显示某一进程的信息。
ps aux | head -1 && ps aux | grep proc
- 解释一下这个命令,ps aux拿到所有进程信息, |是管道,意思是把ps aux拿到的数据的输出作为 head -1 的输入,head -1 表示只取输入内容的第一行,也就是进程信息列表的表头 ,比如 F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD 。交给下个指令
- && :是逻辑与操作符,表示只有当左边的指令执行成功的时候才执行右边的指令
- ps aux | grep proc, 当ps aux执行成功列出了所有的进程信息后把他的输出(所有的进程信息)作为给grep指令的输入,grep去查找这些进程信息中,proc名字的进程

通过系统调用获取进程的PID和PPID(进程标⽰符)
- 通过使用系统调用函数,getpid(自己的身份)和getppid(父进程的身份)即可分别获取进程的PID和PPID。
我们可以通过一段代码来进行测试。
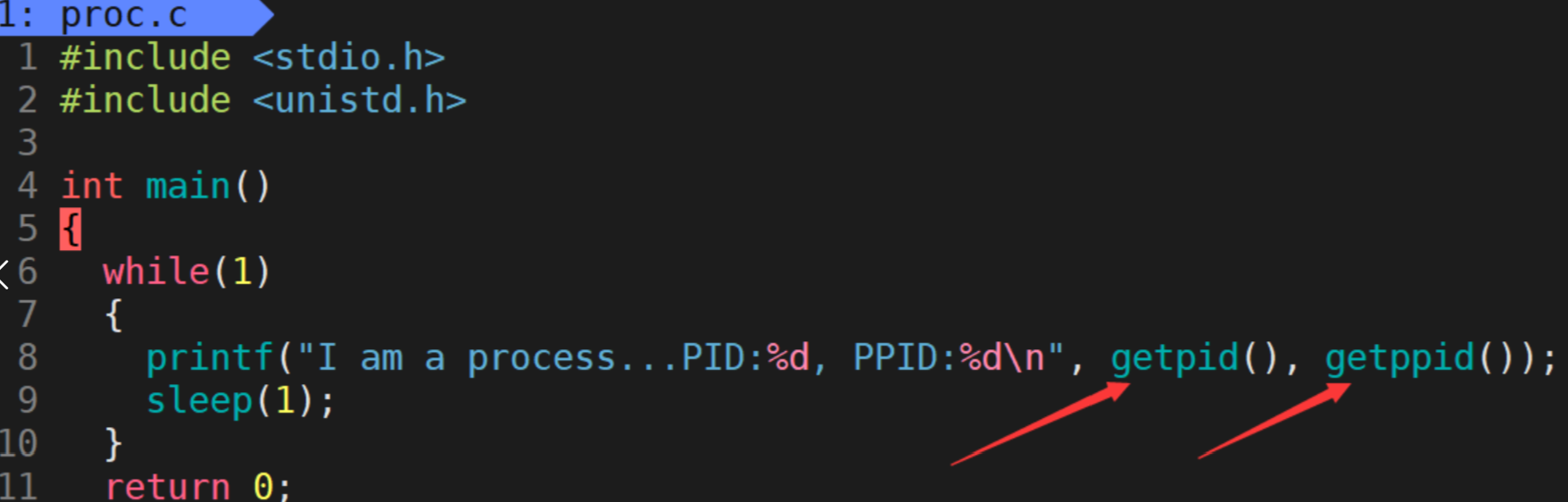
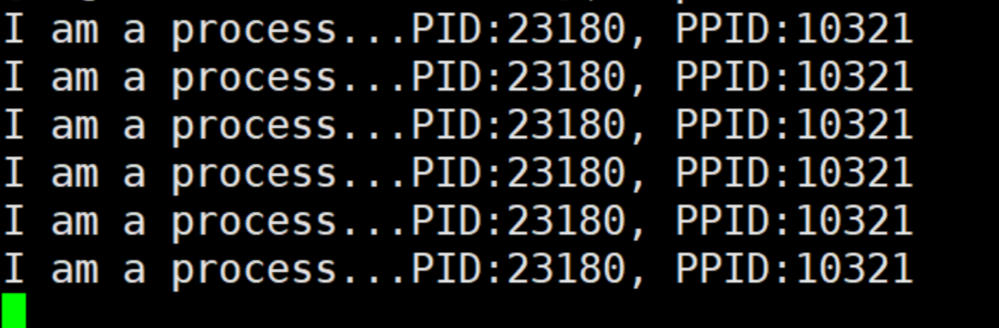
- 当运行该代码生成的可执行程序后,便可循环打印该进程的PID和PPID。
通过系统调用创建子进程
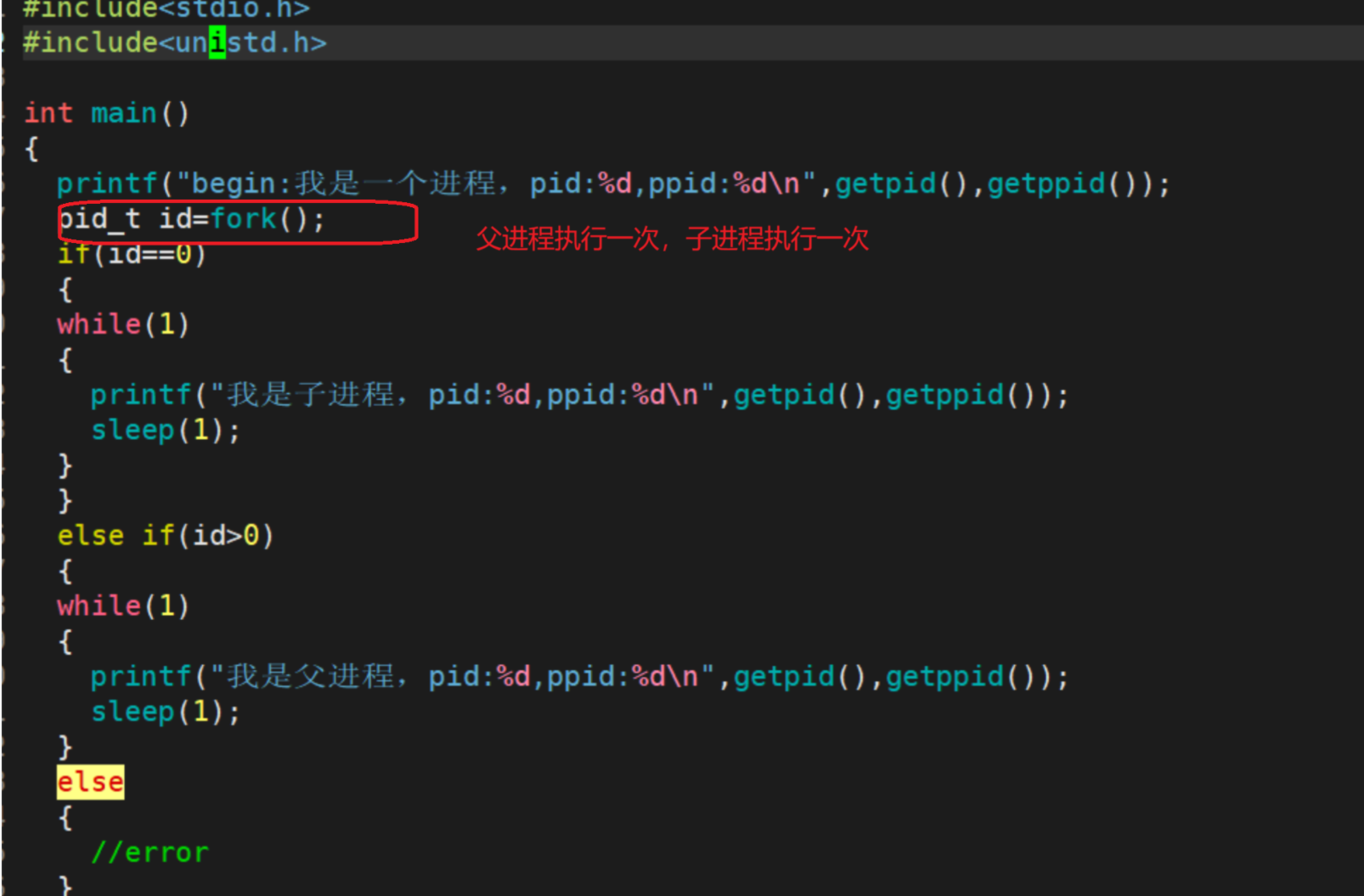
通过一段代码来介绍fork
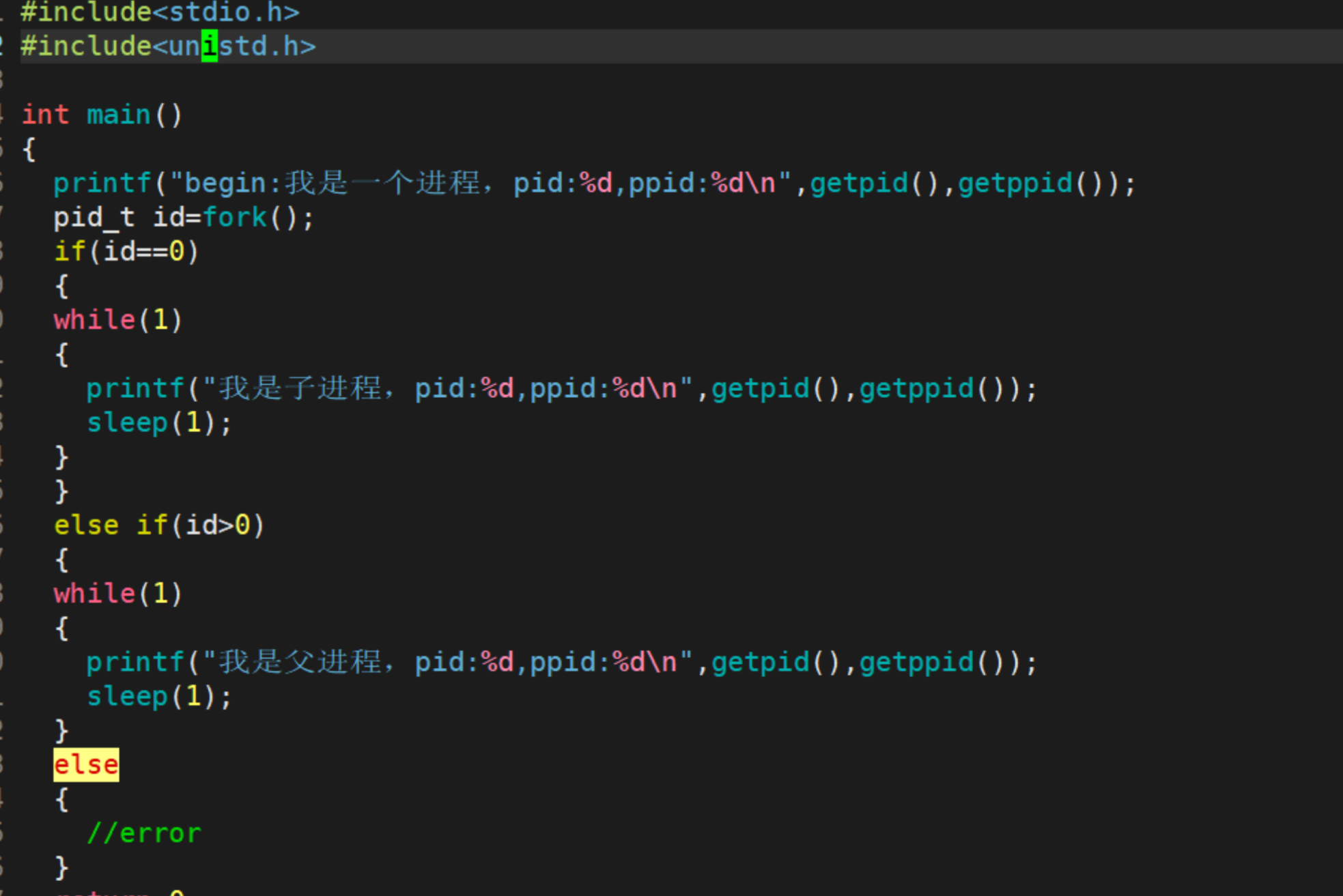
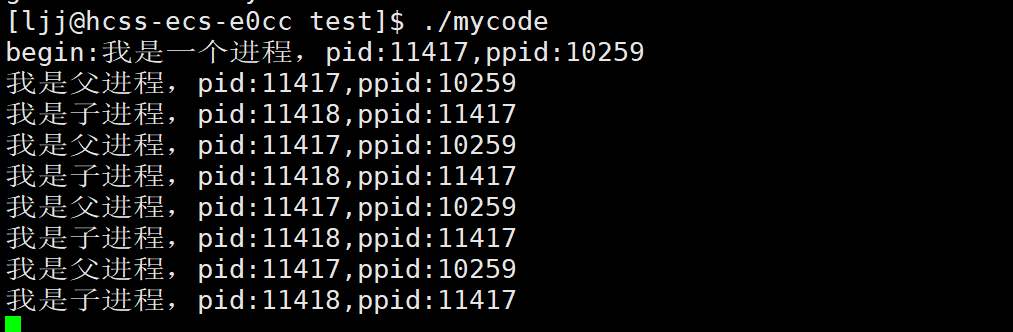
- 这个时候你会发现,if和else if居然在同时运行
这是为啥呢?在我们写过的程序中,怎么可能同时满足if又满足else if, 接下来我们就要对于这个现象进行剖析
为什么要有子进程?
之所有要有子进程,其实就是父进程想让子进程去绑他做一些事情,也就是说在父进程做事情的同时,子进程也可以同时做事情,父进程和子进程分别去做不同的事情。 那我们说完成一个任务总有知道是谁完成的吧,所以子进程和父进程都要有一个返回值。用来区分这个进程是子进程还是父进程。
- 解决方法就是fork要有两个返回值!!——>所以返回不同的值的意义是为了区分不同的执行流,让父进程和子进程分别执行不同的代码块!!
fork为什么给子进程返回0,给父进程返回子进程的PID
因为在Linux系统中父进程和子进程的关系是1:n的,也就是说父进程可以有1个或多个子进程,但是子进程的父进程只能有1个。父进程如果有多个子进程,那么这个父进程就要通过这些子进程的pid来区分不同的子进程进行管理。而如果是子进程为啥返回0,因为子进程不需要父进程的pid,他可以通过getpid这个函数来获得。
fork函数到底做了啥?
- 因为fork函数会创建一个进程,而进程=(内核数据结果)+代码和数据,所以首先:
- 创建一个task_struct结构体
- 吧进程的属性填写到task_struct里面
- 让子进程和父进程指向同样的代码,因为子进程继承了父进程的大多数属性。(跟子进程拷贝父进程的PCB有一定的关系,就是继承了pcb里面的属性,还有进程的地址空间,页表这些), 所以这里fork创建子进程后的代码是父进程和子进程共享的,那么return就会return两次,父进程return1次,子进程return1次。
- 这个时候补充一个知识:因为进程之间具有独立性,也就是说进程之间不能互相影响(比如说我关掉了洛谷这个进程并不影响我在爱奇艺上看电视),所以上面fork函数返回两次给id这个变量就会导致子进程修改一次,父进程修改一次。
- 这个时候就发生了写时拷贝
任何平台,进程都是具有独立性的,在子进程和进程共享代码的时候,因为代码是只读的,这是没有问题的。但是数据就不一样了,数据可以修改。那这个时候数据也是共享的,他们其中的一个改了数据就不行了。所以说,我们的子进程/父进程如果想要修改数据,就要想办法把修改的数据拷贝一份出来,让其指向新拷贝出来的那一块数据。这样才能做到进程之间互相不影响
一个函数是如何做到返回两次的?
- 父子的代码是共享的,所以return ret也是属于代码,因此父子进程各返回了一次!
一个变量为什么会有不同的内容?
- 这就是因为子进程修改了数据导致触发了写时拷贝,导致一个变量会有两个值。但是有人说不对呀,变量地址不都是一样的吗?一个物理地址,怎么会有两个值?这就要等我后面说虚拟地址空间的时候来解释了
- 但是要注意的是,子进程被创建好之后,究竟是先运行子进程还是先运行父进程,其实是由调度器(因为CPU只有一个,所以他的作用就是在当前进程中选一个合适的放到CPU中,进程之间会竞争CPU资源,所以调度器会遵循着自己的一套原则来保证进程之间的公平性)这个后面我会在进程优先级讲解
通过fork来理解bash的命令行是如何来工作的?
- bash这个进程主要是用于做命令行解析的工作,bash创建一个子进程来替他执行指令操作,因为进程的独立性就是子进程失败了也不会影响bash这个进程。这样就达到了让bash这个进程专注于命令行解释的工作。
- 什么事命令行解释?

end
感谢你的阅读,如果对你有帮助的话,给博主点一个赞吧。