【MySQL】MySQL表操作基础(二):增删改查(进阶)
目录
一. 数据库约束
1)NOT NULL
2)UNIQUE
3)DEFAULT
4) PRIMARY KEY
5)FOREIGN KEY
二. 表的设计
1)一对一
2)一对多
3)多对多
三. 增加
四. 查询
1)聚合查询
2)分组查询
3)联合查询(内连接)
4)联合查询(外连接)
5)联合查询(自连接)
6)子查询
7)合并查询
五. 补充
1)查询关键字的执行顺序
一. 数据库约束
数据库的数据有的时候存在一些要求,比如姓名这栏不能为空,学号这栏不能重复,这样的要求,如果只是靠人来约束,人工来检查,很难实现并且成本也很大
于是数据库提供了自动对数据合法性进行校验检查的一系列机制,从而保证数据库中不能添加一些非法的数据
常见的MySQL约束:
- NOT NULL:表示这一列不能存储NULL值
- UNIQUE:表示这一列的值不能重复出现
- DEFAULT:表示这一列中存在没有赋值的,赋予默认值。
- PRIMARY KEY:表示这个数据属于这一个的唯一标识(具有NOT NULL 和 UNIQUE 的作用)
- FOREIGN KEY:表示这一列的数据参考匹配另一个表中某列的数据。
- CHECK:表示这一列数据只能选择符合指定的条件的数据。
这些约束都是在创建表的时候加入的限制约束,引入约束后会导致执行效率变低
1)NOT NULL
格式:create table 表名 (列名 类型 限制);create table student (id int not null,
name varchar(29) not null);- 在创建表的时候对列进行限制约束,这时候使用desc进行查看,会发现这里的NULL为no,表示不能为空。
- 如果在复制的时候对NOT NULL的列没有进行赋值,则会出现错误提醒。

2)UNIQUE
格式:create table 表名 (列名 类型 限制);create table student(id int UNIQUE,
name varchar(20));- UNIQUE表示这一列的数据不能出现重复
- UNIQUE会对插入和修改进行限制
- 在插入的时候会进行一次查询操作,检查这一列的所有的数据,确保这次的插入不会和之前的数据出现重复。
- 在修改的时候也会进行一次查询操作,确保这次修改的值不会和之间的数据出现重复。
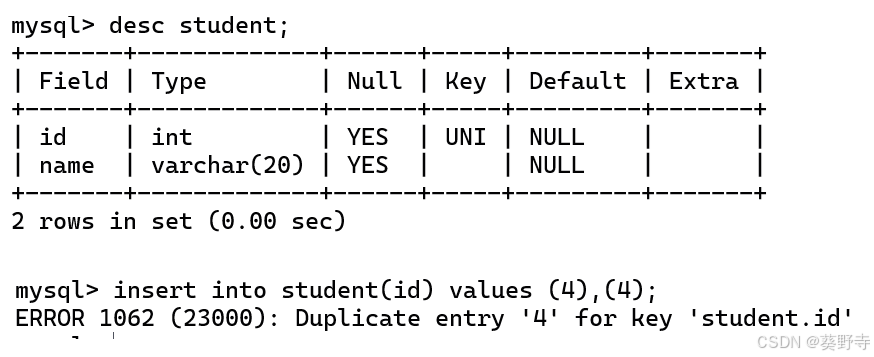
3)DEFAULT
格式:create table 表名 (列名 类型 限制);、create table student(id int ,
name varchar(20) default "wangwu");- 在后续查询数据的时候,如果没有指定数据,那么就会默认使用default的值。
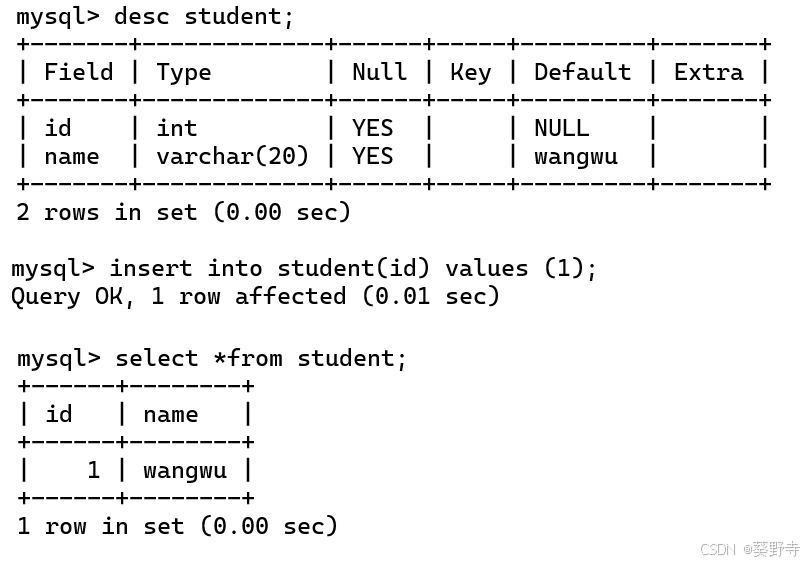
4) PRIMARY KEY
格式:create table 表名 (列名 类型 限制);create table student(id int PRIMARY key,
name varchar(20));- 在一个表中只能有一个primary key,是一行记录中的唯一身份标识。
- 具有NOT NULL 和 UNIQUE 的作用
- 主键中的数据不能为空,主键中的数据要唯一,一个表中只能有一个主键
- 对于带有主键的表来说,每次插入/删除都要涉及查询操作,确保不会重复
虽然只能有一个主键,但是主键不一定只是一个列,可以使用多个列共同构成一个主键。(联合主键)
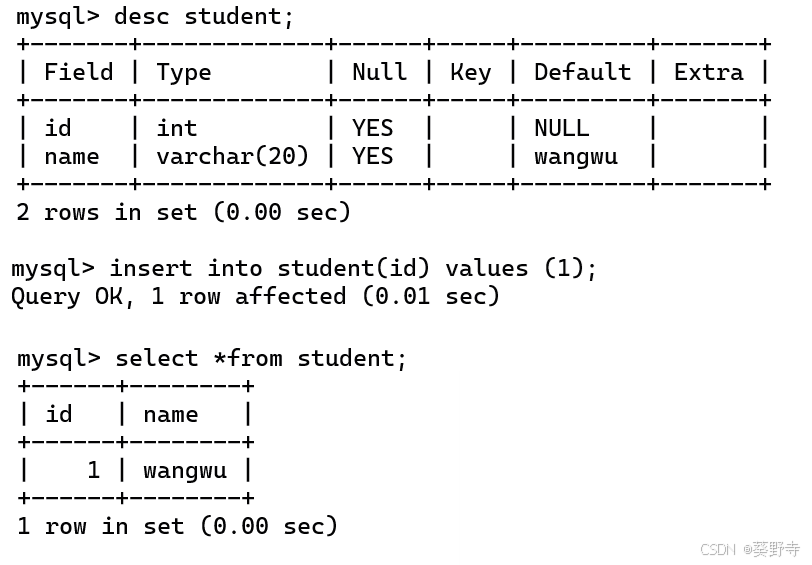
自增主键
每一次都要插入的时候,都要确保主键唯一,每一次的手动输入可能会输错重复,我们经常会使用数字来标识一个主键,数据库服务器会自动分配一个主键,从1开始依次分配主键的值。
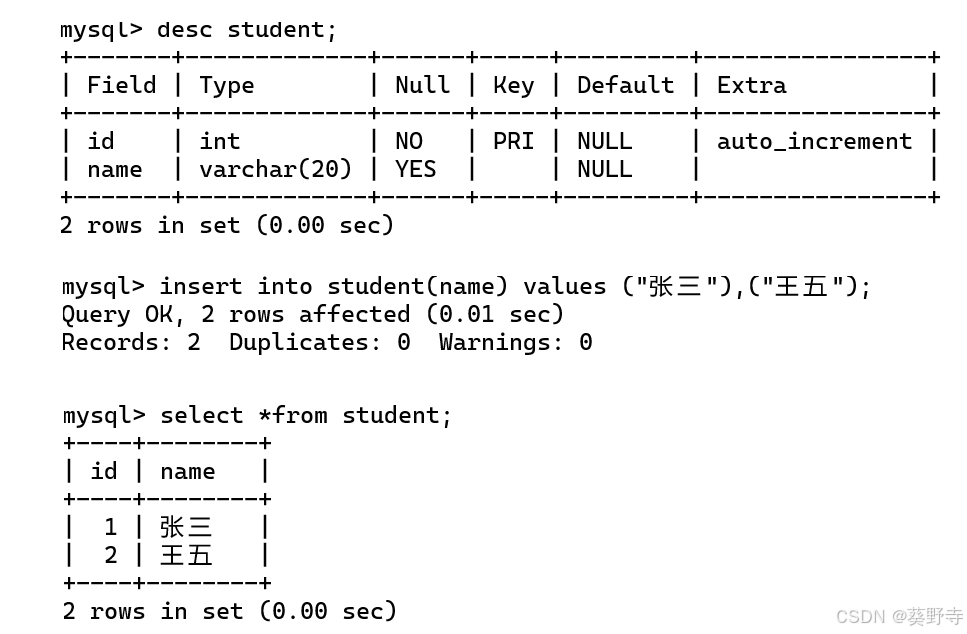
create table student(id int PRIMARY key auto_increment,
name varchar(20));- 在使用的时候直接添加其他列的数据,主键数字会自动增加
- 如果手动输入一个较大的数值,那就会从这个数值之后依次增加
这样的id自动分配,存在一定的局限性
- 如果是单个数据库服务器,那么id自动分配没有问题。
- 如果是一个分布式系统,存在多个数据库服务器构成的集群,这样的分配就存在问题。
这里的核心问题就是要保证这个数据库中的id不会和另外的数据库中的id重复
1)根据时间戳进行分配
如果这台主机添加的速度非常慢,那么时间戳就可以解决这个问题,保证同一时刻下只有一个商品被添加。
如果添加的速度非常快,同一时刻下插入了多个数据,这个数据可以被插入数据库1,也可能是数据库2,如何保证他们之间的id不会重复?
2)添加主机编号/机房编号
在id中添加主机编号,那么就可以保证同一时刻内添加到不同主机上的id编号是不同的。
如果同一时刻内,添加到同一主机的数据很多,依然会出现id重复的现象
3)增加随机数
即使出现了同一个时刻同一主机上添加了很多的数据,也可以根据随机数实现进行id的分散,达到区分的目的
如果两次添加的数据刚好重复呢?这样的情况是可能出现的,我们可以在后面继续添加随机数,让这样的概率变小,让误差控制在合理的范围内即可
5)FOREIGN KEY
格式:foreign key(列名) references 另外表的表名(另外表的列名) create table student(id int PRIMARY key auto_increment,name varchar(20));create table score(id int ,score int,
foreign key(id) references student(id));- student表的数据约束的score表,一般将学生表称为父表,用于约束别人的表,成绩表称为子表。被别人约束的表。
- 针对父表的修改和删除操作。如果这个数据已经被此表引用,那么操作会失败。
- 只有子表将数据删除,父表才能将对应的数据删除。
- 父表中被引用的外键,如果没有被创建,那么字表的创建会失败。
- 在子表中指定外键约束的时候,要求父类的这一列是主键或者unique。。
只能是先有父数据,才能有子数据
父表和子表之间相互约束,对于外键来说,只是两个表的对应列产生了关联关系,其他的列是不受影响的。
二. 表的设计
一般在使用数据库的时候,会根据自己的需求场景,创建出对应的表,在项目开始前,明确当前要创建几个表,表内的属性都是什么,表之间是否存在联系。
- 明确需求,确定表中具体实体具备的属性(学生实体,具有学号,姓名,性别等属性)
- 确定实体之间的关系(学生表和课程表之间的联系)
每一个实体都对应一个表,表中的列就对应实体的属性
这里重点讨论各个表之间的关系
1)一对一
 举例:用户和用户详情,学生和账号的关系
举例:用户和用户详情,学生和账号的关系
一个学生只能拥有一个账号,一个账号也只能被一个学生拥有
学生表(学生id,学生姓名)账号(账号id,账号密码)- 一个表中的一条记录只对应另一个表中的一条记录
- 通常用于拆分大表
2)一对多
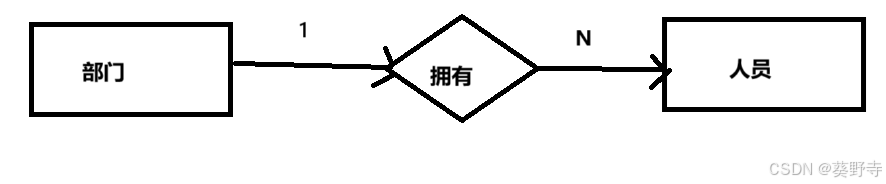
举例:一个部分有多个员工,多个员工都在这一个部门
部门表(部门id,部门名字)人员表(人员id,姓名,部门id)- 一个表中的一条记录可以对应另一个表中的多条记录
3)多对多

举例:一个学生可以选择多个课程,一个课程也可以被多个同学选
学生(学生id,姓名)课程(课程id,课程名)学生-课程(学生id,课程id)- 一个表中的多条记录可以对应另一个表中的多条记录
- 这种关系需要中间关联表来实现
一般在一个项目开始之前,会使用E-R图,将各个实体之间的关系画出来,然后根据这个E-R图设计,但是现在提倡“敏捷开发“,很有可能你讲E-R图画好,项目写一半了,领导突然说需求变一下,这时候又要重新编写代码,重新设计E-R图,非常的费时,一个错误的E-R图不仅不会指导你,还可能误导你,随着这样的演变,E-R图已经慢慢被淘汰,更像是项目总结会使用的工具
三. 增加
将插入操作和查询操作配合使用,达到添加效率增加的效果
格式:insert into 表名1 select *from 表名2;insert into student2 select *from student;这里查询出来的结果集合,列数和类型必须和插入表相匹配 ,列名不要求匹配
四. 查询
1)聚合查询
相比于之前的表达式查询,聚合查询针对点发生了改变
- 表达式查询:针对列和列之间的运算
- 聚合查询:针对行和行之间的运算
MySQL之间常见的聚合函数,通过聚合函数可以实现行之间的运算
1. COUNT
格式:select count(列名) from 表名;SELECT COUNT(id) FROM student;- 返回查询的数据的数量
- 在使用的时候,如果查询的这一列,出现null不会进行计数
- 但是在查询全部的时候,出现null也会进行计数
- 在计数的时候,我们通常会使用主键,或者unique的列进行统计个数,或者搭配distinct达到去重的目的
2. SUM
格式:select sum(列名) from 表名;SELECT SUM(chinese) FROM student;- 对这一列的若干行,进行求和运算
- 遇见NUll值则不会参与运算
- 只能针对数字类型使用,如果是其他类型则会返回零
- 在运行的时候,会进行一次强转,将出现的数据类型转为double。如果转换成功则参与运算,反之会发出警告
3. AVG
格式:select avg(列名) from 表名;SELECT avg(chinese) FROM student;- 获取选中这一列数据的平均值
- 使用方式的注意事项和SUM类似,遇到NULL值不会参与运算
4. MAX和MIN
格式:select min(列名) from 表名;
格式:select max(列名) from 表名;SELECT min(chinese) FROM student;SELECT MAX(chinese) from student;- 得到要查数据的最大值或最小值
- 这个在使用的时候,一般会指定具体某一列
- 这里的使用细节和上面的一样,NULL值不参与运算
2)分组查询
通过在查询语句的后面使用group by关键字,从而实现分组查询的功能
格式:select 列名 from 表名 group by 列名;SELECT role,count(*)FROM student GROUP BY role;- 通过group by 关键字进行指定分组,将这一列中,值相同的行放在一组
- 分组查询一般要搭配聚合函数一起使用,如果不搭配使用,那么返回的数值,会是其中随便一个值,这样的查询没有意义
- 在使用的时候,不能返回 *
搭配条件使用
这里的搭配条件要区分清楚条件是分组前的条件还是分组后的条件
- 1. 在分组之前,进行筛选,针对筛选后的结果,再分组。(where 子句)
- 2. 在分组之后,进行筛选。(having 子句)
分组前
SELECT role,count(*)FROM student where name!="张三" GROUP BY role ;- 含义:查询每个职位的人员个数,但是排除张三
- 分组查询也可以搭配where语句一起使用,达到一种限制的作用
分组后
SELECT role,count(*)FROM student GROUP BY role having count(*)=1 ;- 含义:查询每个职位的人员个数,但是只要总人数为1的
- 这里使用在group by后使用having关键字,达到分组后筛选的效果
3)联合查询(内连接)
联合查询一般用于多个表之间的查询,通过使用笛卡尔积进行查询。
假如存在两张表,学生(学生id,姓名,班级id)班级表(班级id,班级名)这两张表在进行笛卡尔积的时候,会将所有的结果展现出来

根据这张表,我们发现所谓的笛卡尔积运算,就是通过排列组合的方式得到一个更大的表
- 笛卡尔积的列数就是这两个表列数的相加
- 笛卡尔积的行数就是这两个表行数的相乘
- 其中有很多的非法数据,实际中并不存在这个数据,但是表中显示
我们可以添加一些约束条件,将正确的数据筛选出来
找classid和课程id相等的,就是真正存在的数据

真正存在的数据就是表中的3条数据 (有效条件)
当进行多个表之间的连接的时候,有以下步骤
- 先将多个表进行笛卡尔积
- 加上连接条件,筛选出有效数据
后续可以结合自己的需求,进一步的添加条件,对结果进行筛选,从而得到自己需要的值
注意这里的求多个表的笛卡尔积,存在一定的危险性!!!
前面提到笛卡尔积后得到的结果,是两个表中行数的乘积,如果出现三个表的笛卡尔积运算,每个表中的数据是100,三个表进行笛卡尔积,100x100x100 = 一百万条数据,一次性得到这么多的数据,很有可能导致服务器的堵塞
联合查询的常见写法
写法1:
select 列名 from 表1,表2…;
写法2:
select 列名 from 表1 join 表2… on 条件 ;写法1:
select s1.id,s1.name,s2.name from student as s1,class as s2 where s1.id = s2.id; 写法2:
select s1.id,s1.name,s2.name from student as s1 join class as s2 ON s1.id = s2.id; 上面的这些查询方式,也可以称为内连接查询,对应的还存在外连接查询
内连接
-
仅返回两个表中 满足连接条件 的行。
-
如果某行在左表或右表中没有匹配项,则该行不包含在结果中。
只显示匹配到的信息,如果出现没有对应的信息则不回返回

4)联合查询(外连接)
1)左外连接
SELECT 列名
FROM 左表
LEFT JOIN 右表 ON 连接条件;- 左外连接会返回 左表 的所有记录,以及 右表中与左表匹配的记录。如果右表中没有匹配的记录,则结果中右表对应的字段值为NULL
- 如果每一个记录都是对应的关系,不存在NULL值,那么返回的结果和内连接是相同的
- 如果存在不对应的关系,那么返回的结果就和内连接不同


2)右外连接
SELECT 列名
FROM 左表
RIGHT JOIN 右表 ON 连接条件;- 右外连接会返回 右表的所有记录,以及 左表中与右表匹配的记录。如果左表中没有匹配的记录,则结果中左表对应的字段值为NULL
- 如果每一个记录都是对应的关系,不存在NULL值,那么返回的结果和内连接是相同的
- 如果存在不对应的关系,那么返回的结果就和内连接不同


总结:
左外连接:以左表为主,保留左表所有记录,右表匹配不到的补NULL
右外连接:以右表为主,保留右表所有记录,左表匹配不到的补NULL
5)联合查询(自连接)
在MySQL中不能进行与行之间的比较,但是可以进行列与列之间的比较,我们可以通过自连接的方式,将行与行的比较转化为列与列的比较
- 通过自连接的方式,将行与行的比较转化为列与列的比较
- 自连接主要用于处理表中存在 层次关系 或 递归关系 的数据
- 自连接中必须使用起别名的方式
- 最好使用左外连接的方式,进行连接
举例:查询员工的老板
SELECT E.*,M.*
FROM Employees AS E
LEFT JOIN Employees AS M
ON E.id ;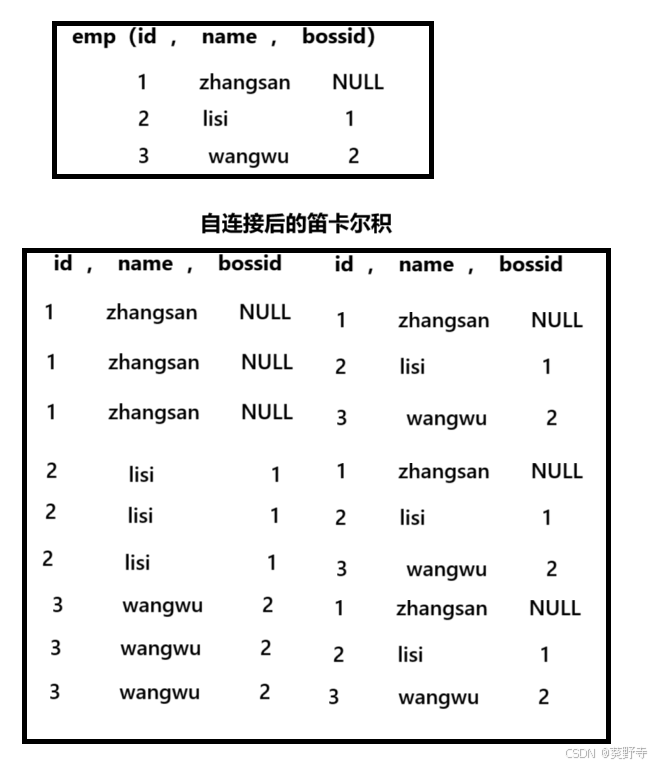
增加一些限制条件进行左外连接的方式
SELECT
E.*,M.*
FROM Employees AS E
LEFT JOIN Employees AS M
ON E.bossid = M.id; 这里由于张三的id = boosid,不存在,由于左外连接的机制,只保留左边的表,右表全部为空
这里由于张三的id = boosid,不存在,由于左外连接的机制,只保留左边的表,右表全部为空
这是最终得到的结果
 在查询的时候,选择指定的列,即可得到最终结果
在查询的时候,选择指定的列,即可得到最终结果
6)子查询
子查询的方式特别类似于嵌套,这种子查询的方式不推荐使用,子查询将很多简单的查询语句拼成一个复杂的查询语句。我们可以使用更多的简单查询代替子查询
- 子查询是 嵌套在其他 SQL 查询语句中的查询
-
子查询,可以任意级别的嵌套,N 个 SQL 组合成了一个巨大的SQL
-
这种组合成巨无霸的查询语句,在实际中不建议使用,不便于理解容易出错
select name from student where classes_id =
(select classes_id from student where name = '张三') ;
可以使用and 等关键字在后面一直拼接
7)合并查询
合并查询用于将多个查询语句的结果集 合并 为一个结果集
SELECT 列1, 列2 FROM 表1
[UNION | UNION ALL]
SELECT 列1, 列2 FROM 表2
-
列数一致:所有查询语句的列数必须相同。
-
数据类型兼容:对应列的数据类型需兼容(如数字与数字、文本与文本)。
-
列名无关:结果集的列名以第一个查询语句的列名为准。
-
union:自动去重,较慢(需去重)
-
union ALL:保留所有行,包括重复行,较快(直接合并)
举例:查询出两个表中的姓名
SELECT Name FROM student
UNION
SELECT Name FROM student;SELECT Name FROM student
UNION ALL
SELECT Name FROM student;
五. 补充
1)查询关键字的执行顺序
- FROM:确定查询的原始数据来源
- ON:指定表的连接条件(与join配合使用)
- JOIN:根据on的条件连接表
- WHERE:过滤行数据,仅保留满足条件的记录。
- GROUP BY:对数据进行分组,通常与聚合函数(sum,avg等)配合使用。
- HAVING:对分组后的结果进行过滤(仅作用于
GROUP BY后的分组) - SELECT:选择需要返回的列,可包含计算字段或别名。
- DISTINCT:对 select 的结果进行去重。
- ORDER BY: 对最终结果集进行排序(升序或降序)
- LIMIT / OFFSET : 限制返回的行数(如分页查询)
FROM → ON → JOIN → WHERE → GROUP BY → HAVING → SELECT → DISTINCT → ORDER BY → LIMIT1. FROM 和 JOIN 的优先级
先通过 FROM 确定主表,再通过JOIN和ON连接其他表
2. WHERE 与 HAVING 的区别
-
WHERE:在分组前过滤原始数据。
-
HAVING:在分组后过滤聚合结果。
3. DISTINCT去重
DISTINCT 作用于 SELECT后的结果集。
4. 聚合函数
在where中不能使用聚合函数,因为还没有分组,所以无法使用
5. 别名作用域范围
别名的作用域始于 SELECT 子句:
只有 SELECT之后的子句(如 DISTINCT、ORDER BY、LIMIT)可以访问别名