关于计算机系统和数据原子性的联系
目录
1、计算机架构
1.1、处理器架构
1.2、内存寻址能力
1.3、性能差异
1.4、软件兼容性
1.5、指令集
1.6、开发和维护
2.、基本数据类型
3、原子类型
3.1、基本概念
3.2、基本数据类型的原子性
3.3、原子操作的解释
3.4、不保证原子性
3.5、解决方案
4、原子性
4.1、原子类
4.2、同步块、锁和关键字
4.3、volatile 关键字
4.4、并发容器
前言
计算机系统的架构、内存管理、硬件设计、以及 Java 的内存模型等因素共同影响着数据的原子性。
在多线程编程中,不仅要关注操作的原子性,还要考虑这些底层的系统和硬件特性,以便更好地实现数据的一致性和线程安全,不同的基本数据类型在计算机内存中占用的字节数会影响它们的原子性。
1、计算机架构
32位和64位计算机架构的区别主要体现在以下几个方面:
1.1、处理器架构
位数定义:
32位和64位指的是计算机处理器(CPU)在单个时钟周期内可以处理的数据位数。32位处理器一次可以处理32位的数据,64位处理器则可以处理64位的数据。
寄存器宽度:
64位处理器的寄存器宽度更宽,意味着它们可以在单个指令中处理更多的数据。
1.2、内存寻址能力
如下图所示:
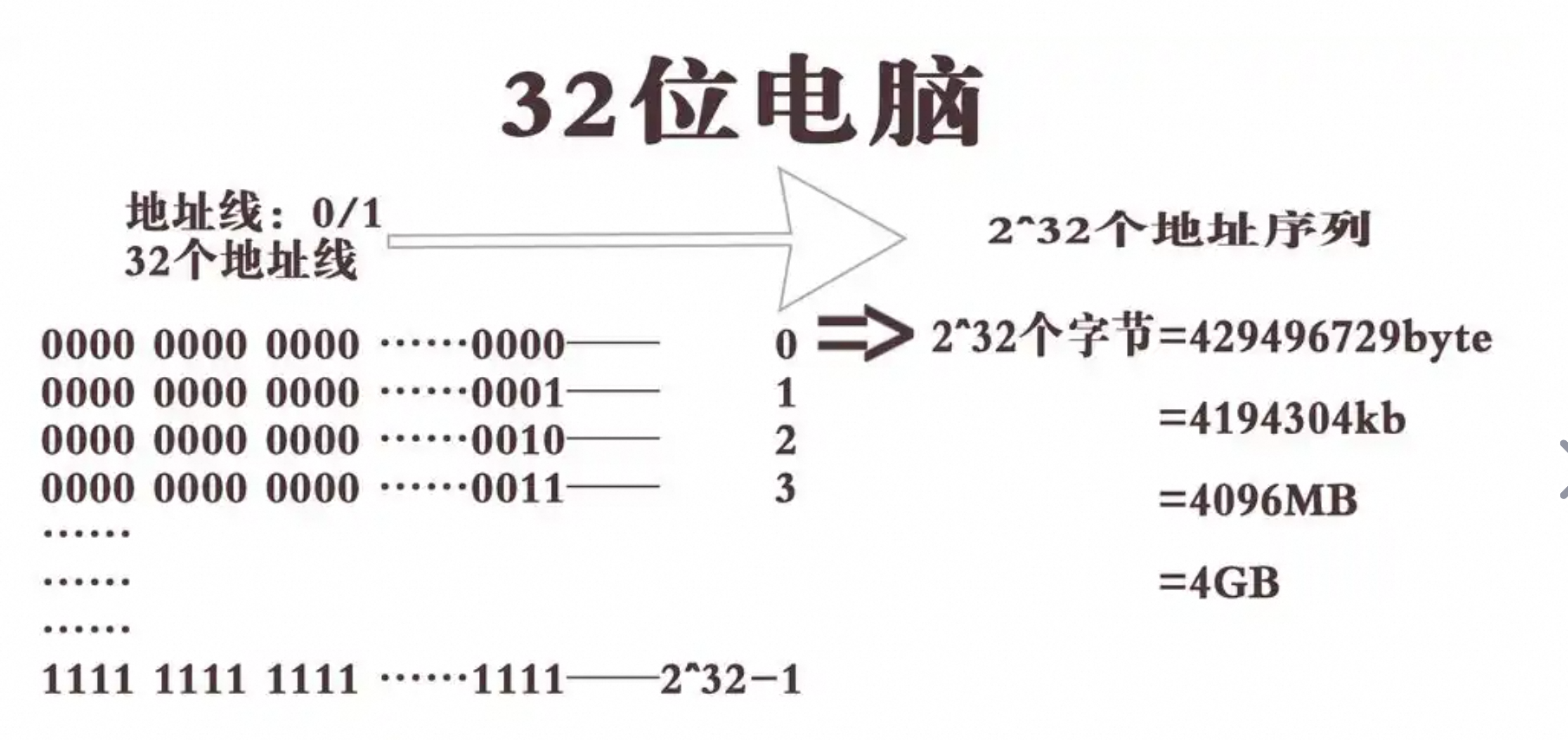
内存地址空间:
32位系统的理论最大寻址空间是 232232 字节(约4GB),而64位系统的理论最大寻址空间是 264264 字节(约16EB),实际上远超过当前计算机硬件所支持的内存量。这意味着64位系统可以支持更大的物理内存。
实际可用内存:
在32位系统中,通常可用的内存小于4GB,因为操作系统和硬件的要求(比如BIOS、显卡等)会占用一部分地址空间。而64位系统可以使用超出4GB的内存,适用于需要处理大量数据的应用程序。
1.3、性能差异
数据处理:
在处理大数据集(例如,大型数据库、图像处理、科学计算等)时,64位处理器优于32位处理器,因为它们可以在单个操作中处理更多的数据。
浮点运算:
64位处理器能够对浮点数进行更高精度的计算。
1.4、软件兼容性
如下图所示:

操作系统和应用程序:
32位操作系统只能运行32位应用程序,而64位操作系统能够同时运行32位和64位应用程序。为了充分利用64位硬件,通常需要使用64位版本的操作系统和应用程序。
驱动程序:
与硬件相对应的驱动程序也需要匹配相应的位数(32位或64位),这可能影响某些老旧硬件的兼容性。
1.5、指令集
指令集架构(ISA):
64位处理器通常支持更多指令和更复杂的数据类型,能够执行更多类型的计算。
1.6、开发和维护
开发复杂性:
开发针对64位架构的软件时,开发人员需要考虑内存管理和数据结构大小的问题,这可能增加开发的复杂性。
总结:
选择32位还是64位计算机时,主要考虑的因素包括你需要处理的数据量、使用的应用程序,以及系统的内存要求。
对于大多数现代应用,尤其是需要大量内存和高性能的任务,64位系统是更合适的选择。
对于一些老旧的应用和硬件,与其兼容性则可能需要使用32位系统。
2.、基本数据类型
在 Java 中,基本数据类型及其对应的字节占用如下图示:
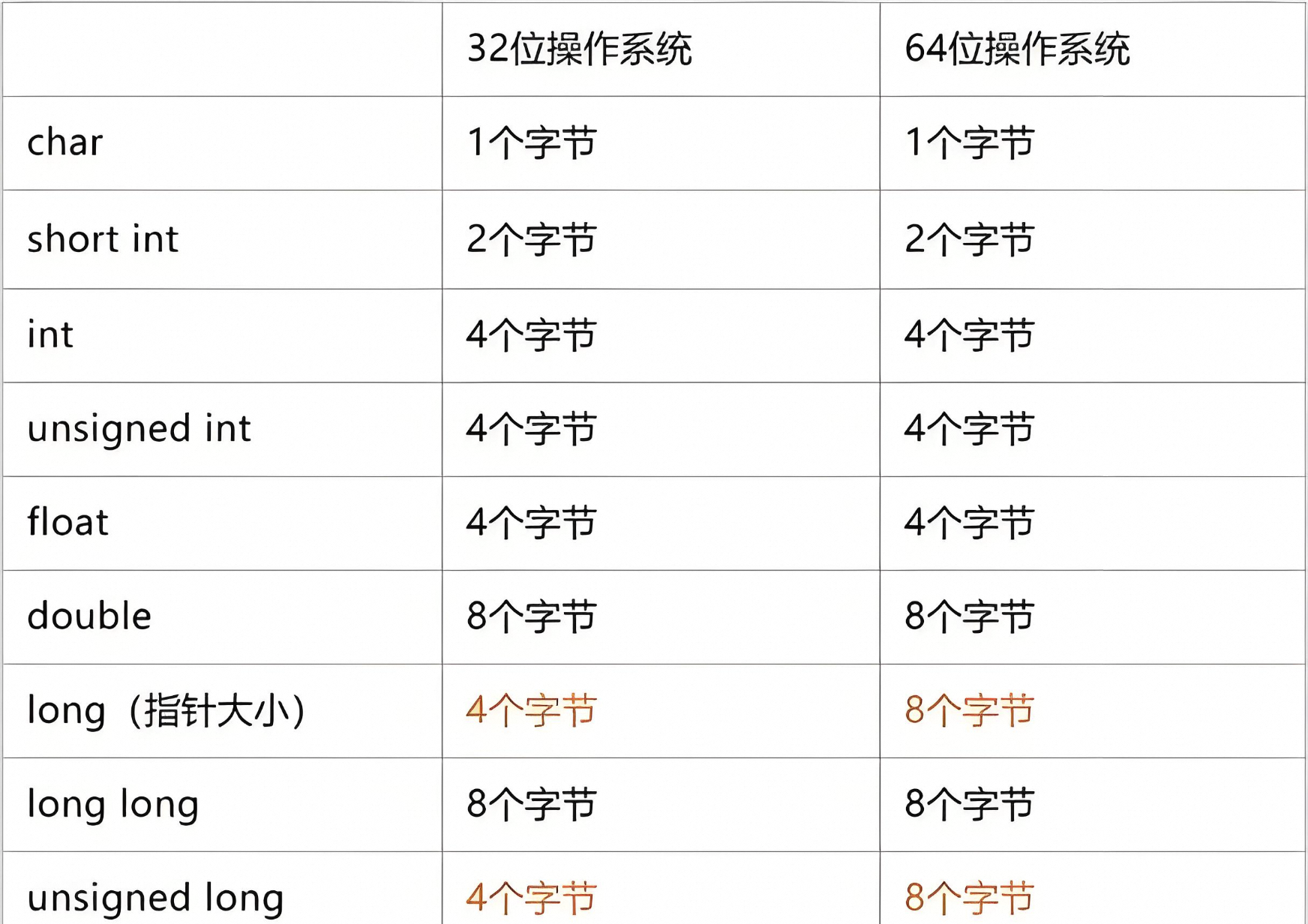
了解更多基本数据类型可参考:java关键字-CSDN博客
-
byte
- 字节数: 1 字节
- 取值范围: -128 到 127
- 用途: 用于节省内存,通常用于处理原始二进制数据,例如文件 I/O。
-
boolean
- 字节数: 1 字节(尽管实际存储可能只需 1 位,但在 Java 中 JVM 通常使用 1 字节来存储)
- 取值范围: true 或 false
- 用途: 代表真/假(逻辑值),常用于条件控制语句。
-
char
- 字节数: 2 字节
- 取值范围: '\u0000' (或 0) 到 '\uffff' (或 65,535)
- 用途: 表示单个 16 位 Unicode 字符,用于处理字符和字符串。
-
short
- 字节数: 2 字节
- 取值范围: -32,768 到 32,767
- 用途: 用于节省内存,主要用于较小范围的整数。
-
int
- 字节数: 4 字节
- 取值范围: -2,147,483,648 到 2,147,483,647
- 用途: 表示常用的整数类型,适用于大多数整数计算。
-
float
- 字节数: 4 字节
- 取值范围: 大约 3.4E-38 到 3.4E+38(精确度为大约 7 位十进制数)
- 用途: 用于表示单精度浮点数,适用于需要小数的数字运算。
-
long
- 字节数: 8 字节
- 取值范围: -9,223,372,036,854,775,808 到 9,223,372,036,854,775,807
- 用途: 表示大范围的整数,主要用于存储非常大的整数值。
-
double
- 字节数: 8 字节
- 取值范围: 大约 1.7E-308 到 1.7E+308(精确度为大约 15 位十进制数)
- 用途: 用于表示双精度浮点数,适用于需要高精度小数的计算。
小结
Java 中的基本数据类型设计是为了高效使用内存和处理数据。不同的数据类型适合不同的应用场景;例如,
int是默认的整型,double是默认的浮点型,boolean类型用于实现逻辑条件判断。
通过选择合适的类型,开发者可以合理利用内存并提高程序性能。
3、原子类型
Java 中的
int等其他基本数据类型(如byte、short、char、boolean等)被认为是原子性的,而long和double类型并不一定被视为完全原子性的。
3.1、基本概念
1.原子性:
在多线程环境中,原子性指的是操作的不可分割性。一个原子操作要么完全执行,要么完全不执行,不会被其他线程的操作打断。
3.2、基本数据类型的原子性
基础类型的分类:
Java 的基本数据类型有:byte、short、int、long、char、float、double 和 boolean。
其中,byte、short、int、char 和 boolean 都是 32 位以下的基本数据类型(boolean 通常占用 1 位,但在 JVM 的实现中它可能为 1 字节),因此这些类型的读写操作在最常见的 CPU 架构上是原子性的。
3.3、原子操作的解释
1、32 位和 64 位系统:
在大多数现代 CPU 架构下,32 位整数(int)和较小类型的变量可以在一个 CPU 指令中读写。这意味着对于这些类型,单一的读写操作一般不会被分割或打断。
而 long 和 double 类型是 64 位的。在某些老旧的 32 位 CPU 上,64 位的数据操作可能被限制为两个步骤:首先读取低 32 位,然后读取高 32 位。这在并发环境中会导致非原子性,因为在这两个步骤之间可能会发生上下文切换或其他线程的操作。
2、Java 内存模型:
Java 内存模型的线程之间包括原子性、可见性和有序性。在 JMM 中,32 位及以下的原始类型的读写操作被认为是原子操作。
而对于 64 位类型,虽然在许多现代编译器和平台上都是原子的,但 Java 不完全保证所有平台都兼容。因此,long 和 double 类型的某些操作可能在JVM实现中表现为非原子。
3.4、不保证原子性
Java 对基本类型的操作并不提供原子性保证。虽然 int 类型的操作是原子的,但 long 和 double 类型的操作,尤其是存取变更的方式,并不被认为是原子的。特别是在某些 JVM 实现或者在某些 CPU 架构上(例如某些 x86 架构),即使对这些类型的存取是原子的,Java 的内存模型并不保证这一点,这就意味着这种保障是不可靠的。
3.5、解决方案
为了保证对 long 和 double 类型的线程安全。
Java 提供了如下几种方法:
1、使用原子类:
Java 提供的 java.util.concurrent.atomic 包中的 AtomicLong 和 AtomicReference<Double> 可以用于原子操作。
AtomicLong atomicLong = new AtomicLong(0);
atomicLong.incrementAndGet(); // 原子的加1操作
2、使用同步机制:
对于复杂操作,可以使用 synchronized 关键字或其他显式锁(如 ReentrantLock)来保护对共享变量的访问。
public synchronized void increment() {sharedLong++;
}
3、使用线程安全的数据结构:
适当使用 java.util.concurrent 包中的数据结构也可以避免多线程访问带来的问题。
小结
1.原子性:
int 与小于 32 位的类型在大多数现代硬件架构上被假定为原子,而 long 和 double 由于其 64 位特性在某些架构下未必是原子的。
2.复合操作:
需要注意的是,尽管单个基本类型的读写是原子的,但复合操作(如自增等)并不保证是原子的。在多线程环境中,组合的读取和写入必须要使用适当的同步机制来确保线程安全。
4、原子性
在Java中,原子性(Atomicity)指的是操作的不可分割性,即操作要么完全成功,要么完全失败,确保其他线程无法在操作的中间状态访问共享数据。
实现原子性通常是多线程编程中的一项重要考虑因素,尤其是在访问共享变量时。
4.1、原子类
Java提供了一些原子类,这些类位于 java.util.concurrent.atomic 包中,专门用于处理简单的整数、布尔值等类型的并发性操作,而不必使用同步。
核心的原子类包括:
AtomicIntegerAtomicLongAtomicBooleanAtomicReference<T>
这些类提供了一系列原子操作的方法,例如 incrementAndGet(), decrementAndGet(), 和 compareAndSet() 等,确保在并发环境中对变量的更新是原子的。
import java.util.concurrent.atomic.AtomicInteger;public class AtomicExample {public static void main(String[] args) {AtomicInteger atomicInt = new AtomicInteger(0);// 原子性加1atomicInt.incrementAndGet();// 原子性设置值atomicInt.set(5);// 原子性比较和设置atomicInt.compareAndSet(5, 10);System.out.println(atomicInt.get()); // 输出 10}
}
4.2、同步块、锁和关键字
对于复杂的操作,Java提供了 synchronized 关键字和 ReentrantLock 等工具来确保多个线程在执行特定代码块时,彼此不能干扰。
public class SynchronizedExample {private int counter = 0;public synchronized void increment() {counter++;}public int getCounter() {return counter;}
}
4.3、volatile 关键字
volatile 关键字用于指示一个变量的值对所有线程是可见的,确保读写操作不会被缓存。但它并不能保证复合操作(如读取-修改-写入)的原子性。
了解更多volatile介绍可参考:对于Synchronized和Volatile的深入理解_java的synchronized,volatile要怎么使用,有啥区别-CSDN博客
public class VolatileExample {private volatile int counter = 0;public void increment() {counter++; // 这不是原子操作}public int getCounter() {return counter;}
}
4.4、并发容器
Java的 java.util.concurrent 包提供了一些线程安全的容器(例如 ConcurrentHashMap, CopyOnWriteArrayList 等),它们内建了对内部数据结构的同步,确保了并发访问的原子性。
总结
通过使用原子变量、多线程同步机制如 synchronized、显式锁等,可以确保复杂操作和共享变量的安全访问,选择合适的同步方式可以有效防止数据竞争和一致性问题。
如果在多线程中安全使用
long和double,推荐使用AtomicLong和AtomicDouble以确保原子操作的安全性,可以避免由数据竞争导致的问题。
参考文章:
1、对于Synchronized和Volatile的深入理解_java的synchronized,volatile要怎么使用,有啥区别-CSDN博客
2、java关键字-CSDN博客