【论文阅读】UNIT: Backdoor Mitigation via Automated Neural Distribution Tightening
ECCV2024
https://github.com/Megum1/UNIT
我们的主要贡献总结如下:
- 我们引入了UNIT(“AUtomated Neural DIstribution Tightening”),这是一种创新的后门缓解方法,它为每个神经元近似独特的分布边界,用于有效消除由后门引起的恶意大幅激活。
- UNIT利用优化技术动态细化和收紧不同神经元的独特边界。这一过程由少量干净样本上的代理精度引导,作为测试集上真实精度的近似值。
- 广泛的实验表明,UNIT对14种现有攻击(包括2种高级攻击)有效,优于7种基线防御。此外,UNIT可推广到不同的数据集、网络结构和激活函数。我们进一步表明,UNIT能够抵御3种自适应攻击。
UNIT为模型中的每个神经元近似一个独特且紧密的激活分布。然后,它主动消除超出近似边界的大幅激活值。
现有的后门缓解技术对先前的攻击有效,但它们在消除由高级攻击引起的后门效应方面却力不从心。这是因这些方法要么在没有精确指导以减少后门效应的情况下重新训练整个模型,要么直接修剪一些特定神经元。这种粗粒度的方法无法对抗最近的高级攻击。例如,高级攻击可能会将后门行为隐藏在主要处理正常特征的良性神经元内。在这种情况下,修剪这些神经元会不必要地影响良性效用。另一方面,保留这些神经元会保留模型中的后门行为。
该方法基于这样的观察结果:对于各种带有后门的模型,存在一组后门神经元,负责后门行为。这些神经元对中毒输入的激活值明显高于对干净样本的激活值。需要注意的是,后门神经元也可能参与良性特征提取。鉴于没有中毒样本用于准确识别后门神经元,我们建议使用少量干净样本为每个单独的神经元近似一个干净的分布。该近似限定了每个神经元的最大激活值。在推理过程中,我们的防御机制UNIT将大幅激活值剪辑到近似的边界。一个直接的想法是对所有神经元的激活值应用统一的百分位边界(例如,覆盖98%值的阈值)。我们在第4节的图4中的结果揭示了这种方法对高级攻击的局限性,因为它忽略了不同神经元具有不同贡献的事实。虽然一些神经元可能完全被攻陷,但其他神经元可能仍然完全良性。为解决这一挑战,UNIT采用了一个优化过程,为不同的神经元定制独特的边界。该优化过程由少量干净样本上的代理精度引导,作为测试集上真实精度的近似值。这一过程使UNIT能够精心收紧边界以减轻后门效应,同时确保精度符合防御者的预期。
现有后门缓解方法的局限性
为了应对消除中毒模型中的后门效应这一挑战,提出了各种方法。它们主要分为两类:(1)遗忘和(2)剪枝。遗忘方法利用基于训练的技术,如微调、蒸馏和克隆,以根除后门行为。这些方法基于灾难性遗忘假设,即神经网络在持续学习其他模式时自然倾向于忘记特定行为。例如,NAD采用标准微调创建教师模型,然后通过知识蒸馏将仅良性知识传递给学生模型。相比之下,剪枝方法涉及识别和移除恶意神经元。它们推测存在一个小的神经元子集负责后门行为,移除这些神经元可以消除后门影响。例如,ANP基于对干净样本的敏感性分析识别恶意神经元,并有效地剪枝它们。接下来,我们将深入探讨遗忘和剪枝方法固有的局限性,并介绍我们的想法以应对这些挑战。
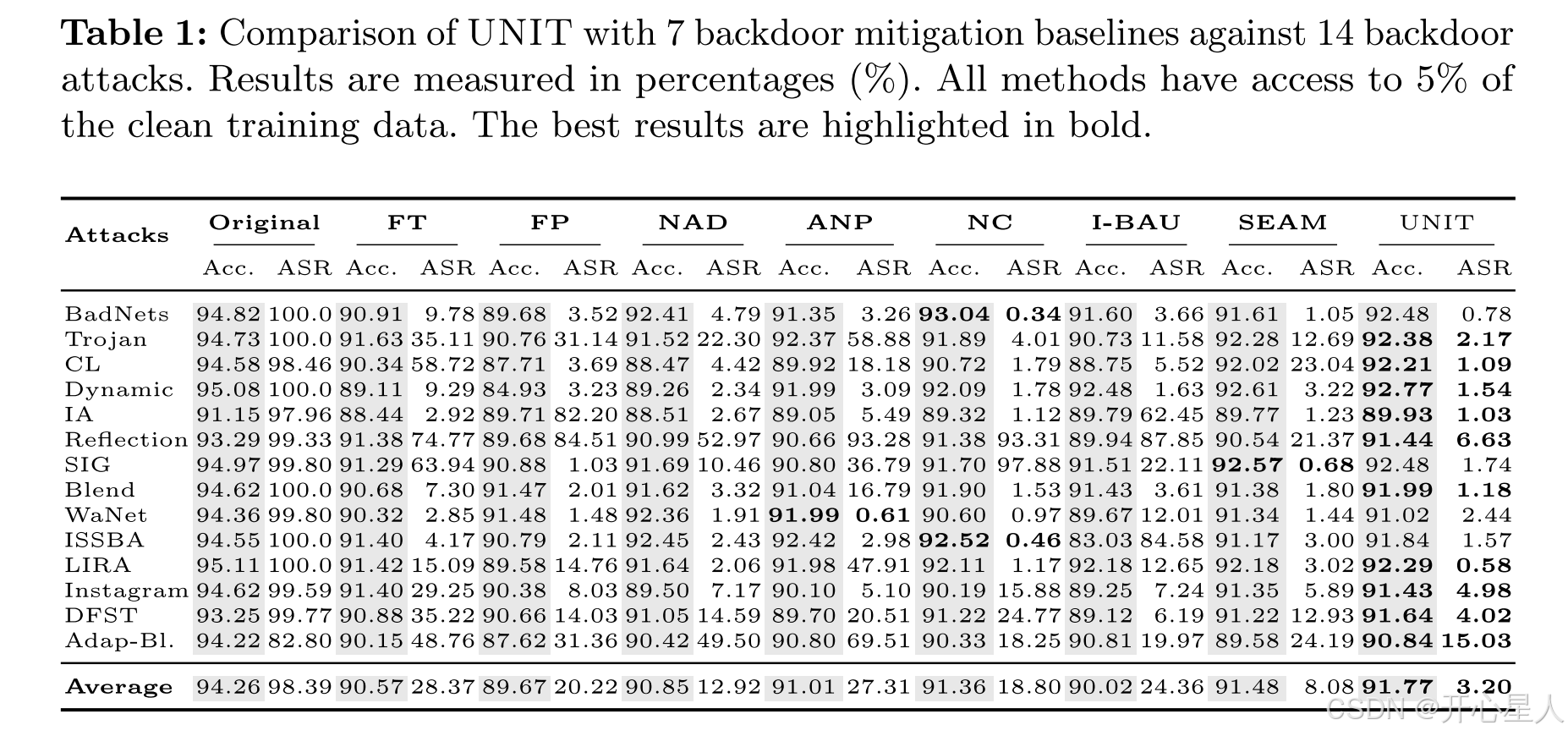
粗粒度修复:最近的高级攻击设法将后门行为隐藏在良性神经元内,创造了能够抵抗现有缓解方法的混合神经元。当前技术的一个普遍局限性在于它们的粗粒度特性,这在对抗高级攻击时是不足够的。本质上,这些方法难以在单个神经元内部操作,以消除后门成分,同时保留良性部分。此外,后门缓解的一个隐含要求是保留良性功能。换句话说,修复后的模型的良性精度不应遭受显著退化。这一约束限制了遗忘和剪枝方法的效力。例如,剪枝可能会移除或保留整个神经元。在处理混合神经元时,直接剪枝它们会显著降低干净分类性能。相反,保留这些神经元会保持后门行为。图1概念性地说明了现有方法的这种局限性。左侧虚线框显示了对高级攻击的缓解。左半部分展示了中毒图像(描绘为左上角有红色触发器的熊猫)在后门模型中的处理过程。值得注意的是,该模型包含三种类型的神经元:(1)良性神经元(描绘为卡通熊猫),主要提取良性特征;(2)后门神经元(描绘为红色恶魔),处理后门行为;(3)混合神经元(描绘为半熊猫半恶魔),同时服务于这两种目的。在模型推理后,输出对应于被误分类的攻击目标标签,用红色十字表示。左侧图形的右半部分描绘了通过遗忘和剪枝修复后的模型。观察到后门神经元被有效地遗忘或剪枝,而混合神经元,表现出良性与恶意行为,仍然不受影响。这是因为消除这些混合神经元可能导致良性任务的准确性大幅下降。然而,这些混合神经元的存在仍然有助于维持高攻击成功率,因为它们参与了后门行为。这突显了现有缓解技术的局限性。
严重依赖精细参数调整:现有方法严重依赖精细的参数调整,以在各种攻击中实现最佳性能。例如,剪枝技术需要仔细确定剪枝率,根据具体情况调整。神经元移除的程度直接影响模型的整体精度;过度剪枝会降低性能,而剪枝不足可能无法充分对抗后门效应。我们在附录A.3中详细的经验分析突出了现有方法对参数调整的敏感性。这种敏感性是一个显著的局限性,削弱了这些方法的泛化能力和实际应用性。
我们的想法:自动神经分布收紧:我们引入了一种新技术UNIT,它自动近似并收紧每个神经激活的独特分布边界。随后在推理过程中,它剪辑超出边界的激活值,针对潜在的后门激活。UNIT采用基于优化的方法自动细化单个神经元的激活边界。它由少量干净样本(<5%)上的代理精度引导,该精度近似真实测试精度。这一近似通常是准确的,如我们在第A.5节中详细描述的消融研究所证明的那样。该过程涉及边界的动态调整:如果观察到的代理精度退化低于防御者的预期,则进一步收紧边界。相反,放松边界以恢复精度。这确保了在维持良性精度的同时消除后门的平衡方法。UNIT以高度粒度运行,分析并调整单个神经元的独特边界。图1中的右侧图形可视化了通过UNIT实现的积极结果。值得注意的是,后门神经元和混合神经元的后门部分都被停用。
此外,与现有方法相比,UNIT是一种自动化技术,不需要精细的参数调整。防御者只需要指定一个精度退化的界限,以平衡良性精度和后门缓解。UNIT的参数高效特性强调了它的泛化能力和实用性。
神经激活的关键观察
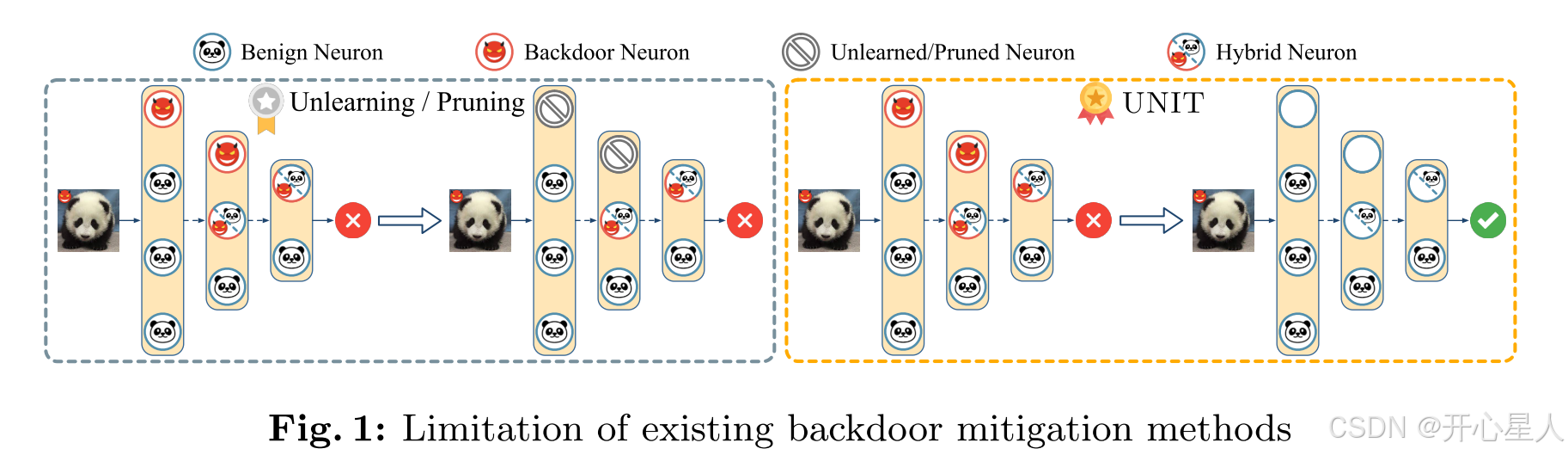
后门行为可以通过后门模型上的触发器激活。为了说明这种输入模式如何改变输出预测,我们深入研究模型内部,特别是检查干净样本和中毒样本的神经激活值。我们使用CIFAR-10数据集和ResNet18架构作为研究对象,并通过各种攻击(包括BadNets、Trojan、IA、SIG、WaNet、ISSBA、LIRA、Reflection、Instagram、DFST和Adap-Blend)可视化干净模型和一系列后门模型的神经激活分布。为了深入了解中毒样本对模型行为的影响,我们使用Shap(一个深度学习解释器)来识别每个模型在处理中毒样本时第12层中最重要的1%的神经元。这些选定的神经元被称为后门神经元,它们负责后门行为。随后,我们的分析涉及比较这些神经元在1000个干净样本和1000个中毒样本之间的激活值。值得注意的是,由于干净模型没有预定义的触发器,我们使用BadNets触发器生成虚拟中毒样本进行分析。通过应用PCA进行降维,我们在图2中可视化了神经激活分布。蓝色图表代表干净输入的激活分布,而红色图表描绘了中毒样本的分布。观察到在干净模型中,干净和中毒样本的神经激活分布无法区分。相反,在遭受后门攻击的模型中,很明显存在干净和中毒样本之间分布的显著变化。值得注意的是,中毒输入的神经激活值明显大于干净输入的值。这种差异强调了后门触发器显著改变了特定后门神经元的神经激活分布,随后导致目标误分类。
独特的细粒度观察:现有论文已经观察到干净和中毒样本之间的潜在可分离性,主要关注整个层的特征。然而,最近的高级攻击和我们在第A.4节中详细描述的自适应攻击设法减少了这种层级特征区分。然而,这些方法未能消除神经激活水平上的可分离性,如图2所示。这突出了我们的细粒度观察与现有文献之间的明显区别。
method
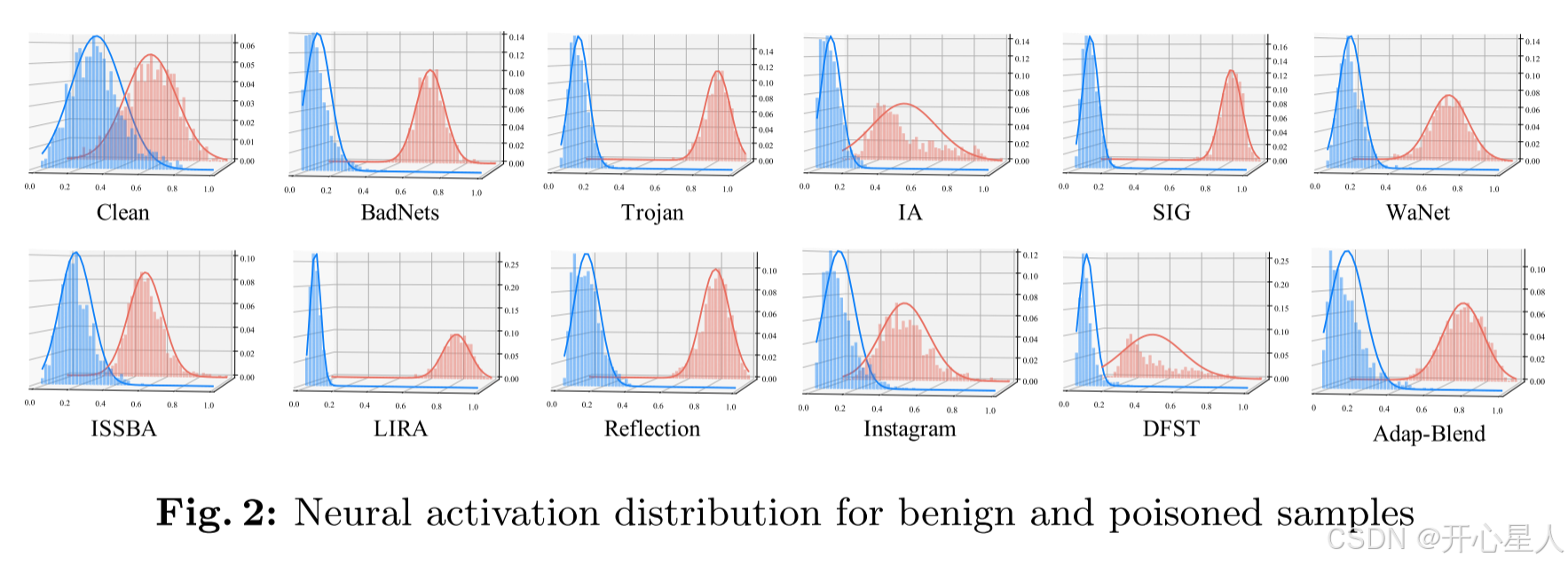
我们的观察发现,在后门神经元上,中毒样本的神经激活与良性样本相比有显著增加。基于这一发现,我们引入了UNIT,这是一种新方法,它基于少量干净训练数据为每个神经元近似一个紧密的良性分布。然后,UNIT战略性地剪辑超出分布边界的激活值。这种近似的必要性源于在典型情况下中毒样本不可用。因此,很难精确识别后门神经元。为了解决这个问题,UNIT将其近似应用于所有神经元,包括良性神经元和后门神经元。此外,我们将近似的良性分布尽可能收紧,旨在有效减轻后门行为。图3展示了UNIT的概览,以一个典型的神经元为例。x轴表示不同样本的神经激活值,而y轴表示这些值对应的样本密度。在这个图中,良性神经激活用蓝色表示,中毒神经激活用红色表示。UNIT基于少量干净样本近似一个紧密的分布,如图中绿色区域所示。为了在模型推理过程中减轻后门效应,UNIT通过剪辑超出近似边界的激活值来限制神经激活值。在放大图中,UNIT确保激活值保持在绿色边界内,而不是沿着红色线(代表恶意的大值)延伸。尽管这种策略可能会对干净样本的精度造成轻微损失,但它在中和中毒样本的后门效应方面非常有效,从而增强了模型的安全性和完整性。
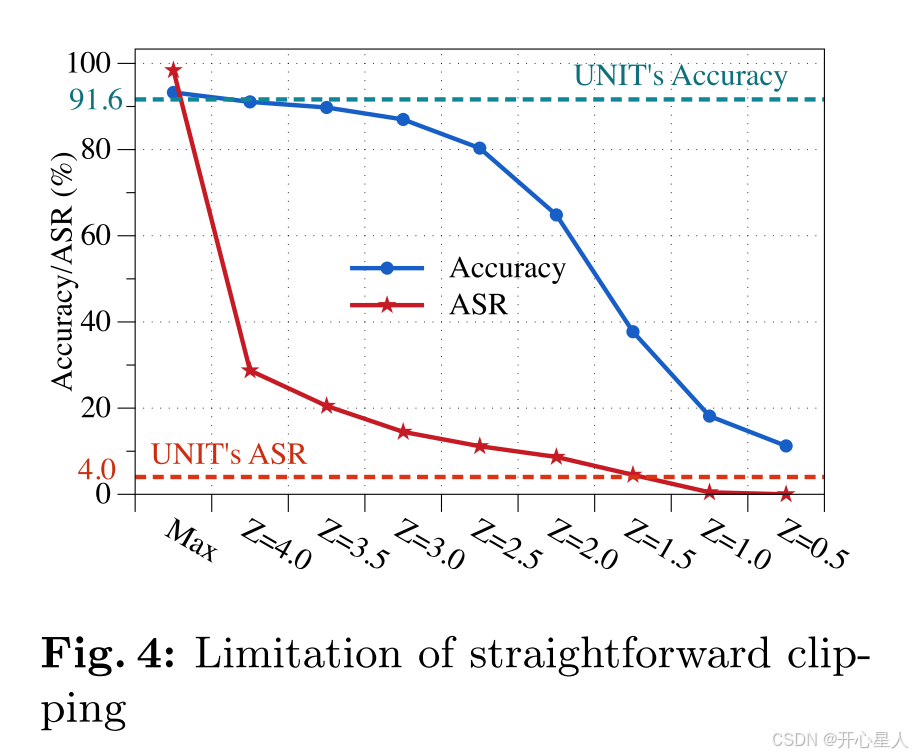
一个直接的想法是为所有神经激活值采用统一的百分位阈值。然而,这种方法可能不准确且粗粒度,因为不同神经元对后门效应的贡献各不相同。图4展示了这种方法对DFST攻击(使用CIFAR-10和ResNet-18发起)的有效性,其中原始模型实现了92.25%的干净精度和99.77%的攻击成功率(ASR)。x轴表示各种统一剪辑百分位,而y轴显示剪辑后对应的精度和ASR。“Max”表示将边界设置在每个神经元的最大激活值处。在其他情况下,我们假设激活呈高斯分布,并采用Z分数进行百分位近似。例如,“Z=3.0”表示将边界设置在平均激活值加上三倍标准差处,对应于0.98百分位。我们可以观察到,即使在中等干净精度为90%(Z=3.5)的情况下,ASR仍然显著高达20%。相反,将ASR降低到4%(Z=1.5)会导致精度急剧下降至40%。这突显了该方法对抗高级攻击的局限性。
另一方面,我们的方法采用基于优化的技术,精心为每个单独的神经元近似和收紧独特的边界,如图4中的蓝色和红色虚线所示。注意,UNIT能够将ASR降低到4.0%,同时保持91.6%的高精度。UNIT的详细信息概述在算法1中,该算法包含两个主要阶段:(1)初始化(第1-3行),收集干净的训练样本以近似一个宽松的良性边界;(2)自动收紧(第4-16行),致力于在干净精度的指导下细化近似的边界。