第七章 数据库编程
1 数据库编程基础
1.1 数据库系统概述
数据库系统是由数据库、数据库管理系统(DBMS)和应用程序组成的完整系统。其主要目的是高效地存储、管理和检索数据。现代数据库系统通常分为以下几类:
- 关系型数据库(RDBMS):如MySQL、PostgreSQL、Oracle等,使用表格结构存储数据
- NoSQL数据库:如MongoDB、Cassandra、Redis等,适用于非结构化或半结构化数据
- NewSQL数据库:如CockroachDB、TiDB等,结合了关系型和NoSQL的优点
- 内存数据库:如Redis、Memcached等,数据主要存储在内存中
1.2 关系型数据库基础架构
以MySQL 8.0为例,该架构清晰地呈现了从客户端发送SQL语句到数据存储的完整处理流程,其核心组件及功能如下:
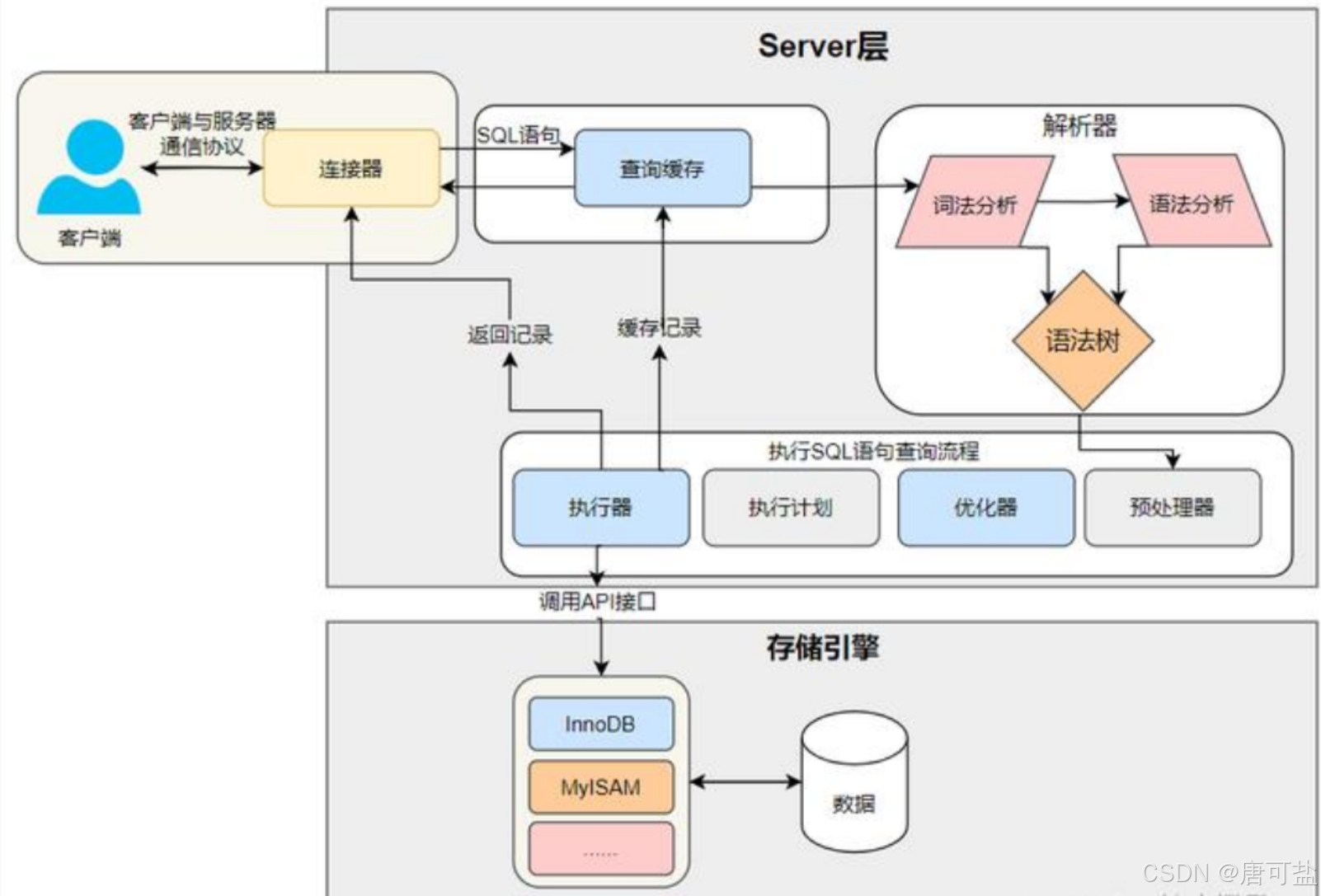
- 连接器(Connector):负责客户端与MySQL服务器之间的通信协议,建立和管理连接,处理用户认证和权限验证。
- 查询缓存(Query Cache):用于缓存SQL语句的执行结果。当收到查询请求时,MySQL会首先检查查询缓存,若存在匹配的缓存结果,则直接返回,避免重复执行查询,提高响应速度。
- 解析器(Parser):包含词法分析和语法分析。词法分析将SQL语句分解为一个个标记(token),语法分析则根据SQL语法规则,将标记组合成语法树,以便后续处理。
- 执行器(Executor):负责执行SQL语句的查询流程。它包括执行计划生成、优化器(Optimizer)和预处理器(Preprocessor)。执行计划确定如何高效地执行查询,优化器对执行计划进行优化,预处理器则处理一些准备工作,如检查表是否存在、权限验证等。最终,执行器调用API接口与存储引擎交互,执行数据操作。
- 存储引擎(Storage Engine):如InnoDB、MyISAM等,负责数据的实际存储和检索。不同的存储引擎提供不同的功能,例如InnoDB支持事务处理和外键约束,而MyISAM则提供更高的读取性能。
MySQL数据库架构的设计使其能够高效地处理客户端请求,并通过查询缓存和优化器提高查询性能。同时,支持多种存储引擎,使其能够适应不同的应用场景和数据存储需求。
1.3 数据库连接技术
1.3.1 Java连接MySQL
目前已经很少有下方举例的这种写法了,很多框架都做了封装,只需yaml文件对连接的数据库进行配置。
// Java中使用JDBC连接MySQL的示例
import java.sql.*;public class MySQLDemo {// MySQL 8.0 以下版本 - JDBC 驱动名及数据库 URLstatic final String JDBC_DRIVER = "com.mysql.jdbc.Driver"; static final String DB_URL = "jdbc:mysql://localhost:3306/RUNOOB";// MySQL 8.0 以上版本 - JDBC 驱动名及数据库 URL//static final String JDBC_DRIVER = "com.mysql.cj.jdbc.Driver"; //static final String DB_URL = "jdbc:mysql://localhost:3306/RUNOOB? useSSL=false&allowPublicKeyRetrieval=true&serverTimezone=UTC";// 数据库的用户名与密码,需要根据自己的设置static final String USER = "root";static final String PASS = "123456";public static void main(String[] args) {Connection conn = null;Statement stmt = null;try{// 注册 JDBC 驱动Class.forName(JDBC_DRIVER);// 打开链接System.out.println("连接数据库...");conn = DriverManager.getConnection(DB_URL,USER,PASS);// 执行查询System.out.println(" 实例化Statement对象...");stmt = conn.createStatement();String sql;sql = "SELECT id, name, url FROM websites";ResultSet rs = stmt.executeQuery(sql);// 展开结果集数据库while(rs.next()){// 通过字段检索int id = rs.getInt("id");String name = rs.getString("name");String url = rs.getString("url");// 输出数据System.out.print("ID: " + id);System.out.print(", 站点名称: " + name);System.out.print(", 站点 URL: " + url);System.out.print("\n");}// 完成后关闭rs.close();stmt.close();conn.close();}catch(SQLException se){// 处理 JDBC 错误se.printStackTrace();}catch(Exception e){// 处理 Class.forName 错误e.printStackTrace();}finally{// 关闭资源try{if(stmt!=null) stmt.close();}catch(SQLException se2){}// 什么都不做try{if(conn!=null) conn.close();}catch(SQLException se){se.printStackTrace();}}System.out.println("Goodbye!");}
}1.3.2 Python连接MySQL
#1 使用pymysql模块import pymysql## 建立数据库连接
try:conn = pymysql.connect(host='localhost', # 数据库主机地址,本地数据库一般为 'localhost'user='root', # 数据库用户名password='your_password', # 数据库密码,替换为你自己设置的密码database='test_db', # 要连接的数据库名,如果不存在需要先创建charset='utf8mb4' # 字符编码)print("数据库连接成功!")
except pymysql.Error as e:print(f"数据库连接失败:{e}")
finally:if conn:conn.close()#2 使用MySQL Connector模块import mysql.connector# 连接到数据库
conn = mysql.connector.connect(host='localhost',user='root',password='password',database='mydatabase'
)# 创建游标对象
cursor = conn.cursor()# 执行SQL查询
cursor.execute("SELECT * FROM mytable")# 获取查询结果
result = cursor.fetchall()# 打印查询结果
for row in result:print(row)# 关闭游标和连接
cursor.close()
conn.close()1.4 SQL基础
结构化查询语言(SQL)是与关系型数据库交互的标准语言。以下是SQL的核心命令分类:
1.4.1 数据定义语言(DDL)
-- 创建表
CREATE TABLE employees (id INT PRIMARY KEY,name VARCHAR(100) NOT NULL,department VARCHAR(50),salary DECIMAL(10,2),hire_date DATE
);-- 修改表结构
ALTER TABLE employees ADD COLUMN email VARCHAR(100);-- 删除表
DROP TABLE employees;1.4.2 数据操作语言(DML)
-- 插入数据
INSERT INTO employees (id, name, department, salary, hire_date)
VALUES (1, 'John Doe', 'Engineering', 75000.00, '2020-01-15');-- 更新数据
UPDATE employees SET salary = 80000.00 WHERE id = 1;-- 删除数据
DELETE FROM employees WHERE id = 1;1.4.3 数据查询语言(DQL)
-- 基本查询
SELECT * FROM employees;-- 条件查询
SELECT name, salary FROM employees WHERE department = 'Engineering' AND salary > 70000;-- 排序
SELECT * FROM employees ORDER BY salary DESC;-- 分组和聚合
SELECT department, AVG(salary) as avg_salary
FROM employees
GROUP BY department
HAVING AVG(salary) > 60000;1.4.4 数据控制语言(DCL)
-- 授予权限
GRANT SELECT, INSERT ON employees TO user1;-- 撤销权限
REVOKE INSERT ON employees FROM user1;2 编程技术精要
2.1 事务处理与ACID保障
# 金融交易场景实现START TRANSACTION;
-- 账户A扣款
UPDATE accounts SET balance = balance - 1000 WHERE account_id = 'A123';
-- 账户B收款
UPDATE accounts SET balance = balance + 1000 WHERE account_id = 'B456';
-- 检查账户状态
SELECT @row_count = ROW_COUNT();
IF @row_count < 2 THENROLLBACK;SIGNAL SQLSTATE '45000' SET MESSAGE_TEXT = 'Transfer failed: account not found';
ELSECOMMIT;
END IF;2.2 存储过程
2.2.1 PL/SQL块结构
PL/SQL(Procedural Language extensions to SQL)是Oracle数据库的过程化编程语言,其基本单位是"块"(Block)。一个完整的PL/SQL块由以下三部分组成:
# PL/SQL块的基本结构[DECLARE]-- 声明部分(可选):定义变量、常量、游标等
BEGIN-- 执行部分(必需):包含PL/SQL语句和SQL语句
[EXCEPTION]-- 异常处理部分(可选):处理运行时错误
END;示例:
DECLAREv_emp_name VARCHAR2(100);v_salary NUMBER;
BEGINSELECT employee_name, salary INTO v_emp_name, v_salaryFROM employeesWHERE employee_id = 100;DBMS_OUTPUT.PUT_LINE('Employee: ' || v_emp_name || ', Salary: ' || v_salary);
EXCEPTIONWHEN NO_DATA_FOUND THENDBMS_OUTPUT.PUT_LINE('Employee not found');
END;2.2.2 变量和常量的定义
1. 变量定义规范
- 语法:
变量名 [CONSTANT] 数据类型 [NOT NULL] [:= 初始值] - 关键特性:
- 作用域从声明处到块结束
- 支持
%TYPE属性引用表结构(如v_salary employees.salary%TYPE) - 复合类型:记录(RECORD)、表(TABLE)、嵌套表(VARRAY)
DECLAREv_count NUMBER := 0; -- 数字变量并初始化v_name VARCHAR2(50); -- 字符串变量v_hiredate DATE := SYSDATE; -- 日期变量v_valid BOOLEAN DEFAULT TRUE; -- 布尔变量
BEGIN-- 使用变量
END;2. 常量定义要点
- 必须初始化且值不可变
- 示例:c_commission_pct CONSTANT NUMBER(3,2) := 0.15;
DECLAREc_pi CONSTANT NUMBER := 3.14159;c_tax_rate CONSTANT NUMBER(5,2) := 0.08;
BEGIN-- 使用常量
END;2.2.3 控制结构
1. 条件控制
- IF-THEN-ELSIF:多分支判断
#语法:IF condition1 THENstatements1;
ELSIF condition2 THENstatements2;
ELSEstatements3;
END IF;#示例:
DECLAREv_score NUMBER := 85;
BEGINIF v_score >= 90 THENDBMS_OUTPUT.PUT_LINE('优秀');ELSIF v_score >= 80 THENDBMS_OUTPUT.PUT_LINE('良好');ELSEDBMS_OUTPUT.PUT_LINE('一般');END IF;
END;- CASE表达式:模式匹配
#语法:
CASE selectorWHEN value1 THEN statements1;WHEN value2 THEN statements2;...ELSE else_statements;
END CASE;#示例:
CASE WHEN v_grade = 'A' THEN v_bonus := 5000;WHEN v_grade = 'B' THEN v_bonus := 3000;ELSE v_bonus := 1000;
END CASE;2. 循环控制
- 基本LOOP
#语法:LOOPstatements;EXIT [WHEN condition];
END LOOP;- WHILE-LOOP
#语法:
WHILE condition LOOPstatements;
END LOOP;- FOR-LOOP
#语法:
FOR counter IN [REVERSE] start_value..end_value LOOPstatements;
END LOOP;- 示例:
BEGIN-- 基本LOOPDECLAREv_counter NUMBER := 1;BEGINLOOPDBMS_OUTPUT.PUT_LINE('Counter: ' || v_counter);v_counter := v_counter + 1;EXIT WHEN v_counter > 5;END LOOP;END;-- FOR循环FOR i IN 1..5 LOOPDBMS_OUTPUT.PUT_LINE('Index: ' || i);END LOOP;-- WHILE循环DECLAREj NUMBER := 1;BEGINWHILE j <= 5 LOOPDBMS_OUTPUT.PUT_LINE('While index: ' || j);j := j + 1;END LOOP;END;
END;2.2.4 存储过程
存储过程是存储在数据库中的命名PL/SQL块,可以被多次调用。
1. 创建存储过程
#语法:CREATE [OR REPLACE] PROCEDURE procedure_name (param1 IN NUMBER,param2 OUT VARCHAR2,param3 IN OUT DATE
)
IS-- 局部变量声明
BEGIN-- 执行逻辑
EXCEPTION-- 异常处理
END procedure_name;参数模式:
- IN:输入参数(默认)
- OUT:输出参数
- IN OUT:既可输入也可输出
示例:
CREATE OR REPLACE PROCEDURE update_salary (p_emp_id IN employees.employee_id%TYPE,p_percent IN NUMBER,p_status OUT VARCHAR2
) ASv_current_salary employees.salary%TYPE;v_new_salary employees.salary%TYPE;
BEGIN-- 获取当前工资SELECT salary INTO v_current_salaryFROM employeesWHERE employee_id = p_emp_id;-- 计算新工资v_new_salary := v_current_salary * (1 + p_percent/100);-- 更新工资UPDATE employeesSET salary = v_new_salaryWHERE employee_id = p_emp_id;p_status := 'SUCCESS: Salary updated from ' || v_current_salary || ' to ' || v_new_salary;COMMIT;
EXCEPTIONWHEN NO_DATA_FOUND THENp_status := 'ERROR: Employee not found';WHEN OTHERS THENp_status := 'ERROR: ' || SQLERRM;ROLLBACK;
END update_salary;2. 调用存储过程
#示例:DECLAREv_status VARCHAR2(200);
BEGINupdate_salary(p_emp_id => 100, p_percent => 10, p_status => v_status);DBMS_OUTPUT.PUT_LINE(v_status);
END;# 或者使用EXEC命令: EXEC update_salary(100, 10, :status);
PRINT status;2.2.5 实战案例
#以电商订单处理为例,优化后的存储过程实现DELIMITER //
CREATE PROCEDURE process_order(IN order_id BIGINT,OUT result_code INT
)
BEGINDECLARE EXIT HANDLER FOR SQLEXCEPTIONBEGINROLLBACK;SET result_code = -1;END;START TRANSACTION;-- 库存校验优化SELECT IF(i.available_stock >= oi.quantity, 1, 0) INTO @stock_okFROM inventory iINNER JOIN order_items oi USING(product_id)WHERE oi.order_id = order_idFOR UPDATE SKIP LOCKED;IF @stock_ok THEN-- 批量更新优化UPDATE inventory JOIN (SELECT product_id, SUM(quantity) AS total FROM order_items WHERE order_id = order_idGROUP BY product_id) AS t USING(product_id)SET available_stock = available_stock - t.total;UPDATE orders SET status = 'PROCESSING',update_time = NOW(6)WHERE order_id = order_id;ELSESIGNAL SQLSTATE '45000'SET MESSAGE_TEXT = 'Insufficient stock';END IF;COMMIT;SET result_code = 0;
END //
DELIMITER ;优化关键点:
- 使用
SKIP LOCKED避免行锁竞争 - 批量更新减少事务日志量
- 精确的锁粒度控制
- 显式事务边界定义
2.3 ODBC编程
2.3.1 数据库互联概述
1. 数据库互联的必要性
在现代应用开发中,程序经常需要访问多种不同的数据库系统。由于各数据库厂商提供的接口各不相同,直接使用原生API会导致:
- 应用程序与特定数据库绑定,移植性差
- 开发人员需要学习多种数据库接口
- 维护成本高,代码复用率低
2. 主流数据库互联技术
- ODBC (Open Database Connectivity)
- 微软主导的开放标准
- 跨平台、跨数据库的通用接口
- Windows平台支持最佳
- JDBC (Java Database Connectivity)
- Java语言的数据库连接标准
- 平台无关性
- 主要用于Java应用
- ADO.NET
- .NET框架的数据访问组件
- 支持多种数据源
- 提供断开式数据访问
- 原生API
- 各数据库厂商提供的专用接口
- 如Oracle的OCI、MySQL的C API等
- 性能最优但缺乏通用性
2.3.2 ODBC工作原理
1. ODBC体系结构
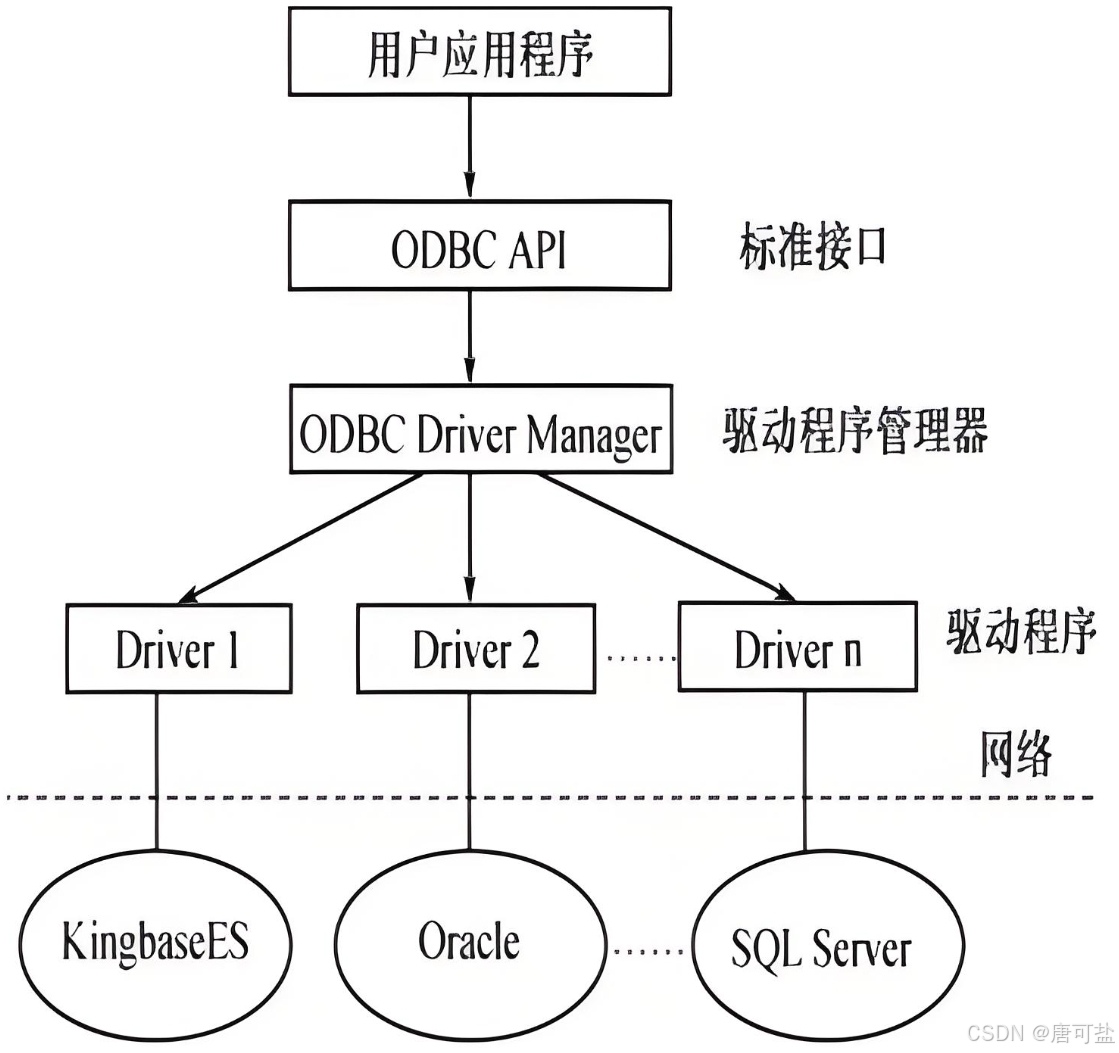
ODBC应用系统的体系结构
ODBC采用分层架构,包含四个主要组件: 应用程序、驱动程序管理器(Driver Manager)、数据库驱动程序(Driver)、数据源。
2. 各组件功能
- 应用程序
- 调用ODBC API函数
- 提交SQL语句
- 处理结果集
- 驱动程序管理器
- 加载/卸载驱动程序
- 处理ODBC函数调用
- 参数验证和转发
- 数据库驱动程序
- 连接特定数据库
- 将SQL转换为数据库原生命令
- 返回执行结果
- 数据源
- 实际的数据库系统
- 如Oracle、SQL Server、MySQL等
2.3.3 ODBC API概述
ODBC是一种使用SQL的程序设计接口。使用ODBC让应用程序的编写者避免了与数据源相联的复杂性。这项技术目前已经得到了大多数DBMS厂商们的广泛支持。ODBC是一种使用SQL 的程序设计接口。使用ODBC让应用程序的编写者避免了与数据源相联的复杂性。这项技术目前已经得到了大多数DBMS厂商们的广泛支持。
Microsoft Developer Studio为大多数标准的数据库格式提供了32位ODBC驱动器。这些标准数据格式包括有:SQL Server,Access,Paradox,dBase,FoxPro,Excel,Oracle以及Microsoft Text。如果用户希望使用其他数据格式,用户需要相应的ODBC驱动器及DBMS。
ODBC API是一个内容丰富的数据库编程接口,包括60多个函数、SQL数据类型以及常量的声明。ODBC API 是独立于DBMS和操作系统的,而且它与编程语言无关。ODBCAPI 以X/Open和ISO/IEC中的CLI规范为基础,ODBC 3.0完全实现了这两种规范,并添加了基于视图的数据库应用程序开发人员所需要的共同特性,例如可滚动光标。ODBC API中的函数由特定DBMS驱动程序的开发人员实现,应用程序用这些驱动程序调用函数,以独立于DBMS的方式访问数据。
ODBC API涉及了数据源连接与管理、结果集检索、数据库管理、数据绑定、事务操作等内容。
- ODBCAPI编程步骤
通常使用ODBCAPI开发数据库应用程序需要经过如下步骤:
- 连接数据源。
- 分配语句句柄。
- 准备并执行SQL语句。
- 获取结果集。
- 提交事务。
- 断开数据源连接并释放环境句柄。
2.3.4 ODBC的工作流程
2.3.4.1. 初始化环境
工作流程开始于应用程序初始化ODBC环境,分配环境句柄。2.3.4.2. 建立连接
- 应用程序通过以下步骤与数据源建立连接:
- 分配连接句柄
- 设置连接属性(可选)
- 实际连接到数据源
2.3.4.3. 执行SQL语句
连接建立后,应用程序可以:
- 分配语句句柄
- 准备SQL语句(可选)
- 执行SQL语句
- 处理结果(对于查询)
2.3.4.4. 终止处理
完成数据库操作后:
- 释放语句句柄
- 断开与数据源的连接
- 释放连接句柄
- 释放环境句柄
2.3.4.4 编程实例
C语言ODBC示例:
#include <windows.h>
#include <sql.h>
#include <sqlext.h>
#include <stdio.h>void show_error(SQLHANDLE handle, SQLSMALLINT type) {SQLCHAR sqlstate[6];SQLCHAR message[SQL_MAX_MESSAGE_LENGTH];SQLINTEGER native;SQLSMALLINT len;SQLRETURN ret;printf("Error details:\n");int i = 1;while ((ret = SQLGetDiagRec(type, handle, i, sqlstate, &native, message, sizeof(message), &len)) != SQL_NO_DATA) {printf("%s:%ld:%ld:%s\n", sqlstate, native, len, message);i++;}
}int main() {SQLHENV env;SQLHDBC dbc;SQLHSTMT stmt;SQLRETURN ret;// 1. 分配环境句柄ret = SQLAllocHandle(SQL_HANDLE_ENV, SQL_NULL_HANDLE, &env);if (!SQL_SUCCEEDED(ret)) {printf("Failed to allocate environment handle\n");return 1;}// 设置ODBC版本ret = SQLSetEnvAttr(env, SQL_ATTR_ODBC_VERSION, (void*)SQL_OV_ODBC3, 0);if (!SQL_SUCCEEDED(ret)) {printf("Failed to set ODBC version\n");SQLFreeHandle(SQL_HANDLE_ENV, env);return 1;}// 2. 分配连接句柄ret = SQLAllocHandle(SQL_HANDLE_DBC, env, &dbc);if (!SQL_SUCCEEDED(ret)) {printf("Failed to allocate connection handle\n");SQLFreeHandle(SQL_HANDLE_ENV, env);return 1;}// 3. 连接到数据源ret = SQLConnect(dbc, (SQLCHAR*)"YourDSN", SQL_NTS, (SQLCHAR*)"username", SQL_NTS, (SQLCHAR*)"password", SQL_NTS);if (!SQL_SUCCEEDED(ret)) {printf("Failed to connect to data source\n");show_error(dbc, SQL_HANDLE_DBC);SQLFreeHandle(SQL_HANDLE_DBC, dbc);SQLFreeHandle(SQL_HANDLE_ENV, env);return 1;}// 4. 分配语句句柄ret = SQLAllocHandle(SQL_HANDLE_STMT, dbc, &stmt);if (!SQL_SUCCEEDED(ret)) {printf("Failed to allocate statement handle\n");SQLDisconnect(dbc);SQLFreeHandle(SQL_HANDLE_DBC, dbc);SQLFreeHandle(SQL_HANDLE_ENV, env);return 1;}// 5. 执行SQL查询ret = SQLExecDirect(stmt, (SQLCHAR*)"SELECT id, name, age FROM employees", SQL_NTS);if (!SQL_SUCCEEDED(ret)) {printf("Failed to execute SQL\n");show_error(stmt, SQL_HANDLE_STMT);} else {// 绑定列SQLINTEGER id, age;SQLCHAR name[50];SQLINTEGER id_ind, age_ind, name_ind;ret = SQLBindCol(stmt, 1, SQL_C_LONG, &id, 0, &id_ind);ret = SQLBindCol(stmt, 2, SQL_C_CHAR, name, sizeof(name), &name_ind);ret = SQLBindCol(stmt, 3, SQL_C_LONG, &age, 0, &age_ind);// 获取结果printf("Employee List:\n");printf("ID\tName\tAge\n");while (SQL_SUCCEEDED(ret = SQLFetch(stmt))) {printf("%d\t%s\t%d\n", id, name, age);}}// 6. 清理SQLFreeHandle(SQL_HANDLE_STMT, stmt);SQLDisconnect(dbc);SQLFreeHandle(SQL_HANDLE_DBC, dbc);SQLFreeHandle(SQL_HANDLE_ENV, env);return 0;
}Python ODBC示例
import pyodbc# 1. 建立连接
conn = pyodbc.connect('DRIVER={ODBC Driver 17 for SQL Server};''SERVER=your_server_name;''DATABASE=your_database_name;''UID=your_username;''PWD=your_password'
)try:# 2. 创建游标cursor = conn.cursor()# 3. 执行SQL查询cursor.execute("SELECT id, name, age FROM employees")# 4. 获取结果print("Employee List:")print("ID\tName\tAge")for row in cursor:print(f"{row.id}\t{row.name}\t{row.age}")# 5. 执行插入操作示例cursor.execute("INSERT INTO employees (name, age) VALUES (?, ?)", "John Doe", 30)conn.commit()print("Insert successful")except pyodbc.Error as e:print(f"Database error: {e}")
finally:# 6. 关闭连接if 'cursor' in locals():cursor.close()if 'conn' in locals():conn.close()2.3.4.5 常见ODBC函数
1 环境函数:
- SQLAllocHandle: 分配环境、连接或语句句柄
- SQLFreeHandle: 释放句柄
- SQLSetEnvAttr: 设置环境属性
2 连接函数:
- SQLConnect: 连接到数据源
- SQLDisconnect: 断开连接
- SQLDriverConnect: 使用连接字符串连接
3 语句函数:
- SQLExecDirect: 直接执行SQL语句
- SQLPrepare/SQLExecute: 准备和执行SQL语句
- SQLBindCol: 绑定结果列到变量
- SQLFetch: 获取结果集中的下一行
4 诊断函数:
- SQLGetDiagRec: 获取诊断记录
- SQLGetDiagField: 获取诊断字段
2.4 触发器应用场景
#审计日志触发器实现CREATE TRIGGER trg_users_audit
BEFORE UPDATE ON users
FOR EACH ROW
BEGINDECLARE v_user_agent VARCHAR(255);DECLARE v_remote_addr VARCHAR(45);-- 获取连接元数据SELECT @@session.http_user_agent,@@session.http_remote_addr INTO v_user_agent, v_remote_addr;INSERT INTO audit_log (table_name,operation_type,changed_by,client_ip,user_agent,change_time,old_data,new_data) VALUES ('users','UPDATE',USER(),v_remote_addr,v_user_agent,NOW(6),JSON_OBJECT('email', OLD.email,'last_login', OLD.last_login),JSON_OBJECT('email', NEW.email,'last_login', NEW.last_login));
END;性能优化措施:
- 避免在触发器中执行复杂业务逻辑
- 使用JSON格式存储变更历史
- 异步日志写入机制
- 限制审计数据保留周期
3 查询优化技术
3.1 执行计划深度解析
使用EXPLAIN ANALYZE获取真实执行统计:
EXPLAIN ANALYZE
SELECT * FROM orders
WHERE user_id = 12345AND order_date > '2025-01-01'AND status IN ('PAID', 'SHIPPED')
ORDER BY total_amount DESC
LIMIT 10;关键输出指标解读:
actual_time: 实际执行时间(毫秒)loops: 扫描次数rows_produced: 实际输出行数filter_effectiveness: 过滤效率
索引优化策略:
- 创建复合索引:
ALTER TABLE orders ADD INDEX idx_query (user_id, order_date, status, total_amount) - 索引下推优化:确保WHERE条件字段位于索引前导列
- 覆盖索引设计:将SELECT字段全部包含在索引中
3.2 锁机制与并发控制
3.2.1 InnoDB锁内存结构:
# Cstruct lock_t {trx_t* trx; // 事务指针ulint type_mode; // 锁模式(LOCK_S/LOCK_X等)dict_index_t* index; // 关联索引dtuple_t* key; // 锁定的索引键值...
};3.2.2 死锁检测与避免:
1 事务重试机制:
# java @Retryable(maxAttempts = 3, backoff = @Backoff(delay = 100))
public void updateOrder(Order order) {// 业务逻辑
}2 乐观锁实现:
UPDATE orders
SET status = 'SHIPPED',version = version + 1
WHERE order_id = 123 AND version = #{currentVersion};3.3 索引优化
#创建适当索引-- 单列索引
CREATE INDEX idx_last_name ON employees(last_name);-- 复合索引
CREATE INDEX idx_dept_salary ON employees(department_id, salary DESC);-- 全文索引(用于文本搜索)
CREATE FULLTEXT INDEX idx_product_desc ON products(description);-- 使用不可见索引测试性能
CREATE INDEX idx_test ON employees(hire_date) INVISIBLE;
-- 查询优化器不会使用该索引
ALTER TABLE employees ALTER INDEX idx_test VISIBLE;3.3.1 分析索引使用情况
-- 查看表索引
SHOW INDEX FROM employees;-- 分析查询执行计划
EXPLAIN ANALYZE
SELECT * FROM employees
WHERE last_name = 'Smith' AND department_id = 3;-- 索引使用统计
SELECT * FROM sys.schema_index_statistics
WHERE table_schema = 'your_database';3.4 查询优化
3.4.1 避免全表扫描
-- 不好的写法
SELECT * FROM employees WHERE YEAR(hire_date) = 2020;-- 优化后的写法
SELECT * FROM employees
WHERE hire_date BETWEEN '2020-01-01' AND '2020-12-31';3.4.2 使用覆盖索引
-- 需要回表
SELECT * FROM employees WHERE last_name LIKE 'Sm%';-- 使用覆盖索引
SELECT id, last_name FROM employees WHERE last_name LIKE 'Sm%';3.4.3 分页优化
-- 低效的分页(偏移量大时)
SELECT * FROM employees ORDER BY id LIMIT 10000, 20;-- 高效的分页(使用游标)
SELECT * FROM employees WHERE id > 10000 ORDER BY id LIMIT 20;