SKNet、空间注意力介绍
5月8日复盘
2. SKNet
Selective Kernel Networks
可选择的 卷积核尺寸
目的:bSKNet中的神经元可以捕获不同尺度的目标物体,这验证了神经元根据输入自适应调整其感受野大小的能力。
SKNet论文地址:https://arxiv.org/pdf/1903.06586
2.0 基本认知
SK是对SE的改进版,可以动态调整感受野大小,分为Split-Fuse-Select共3个阶段,模型流程图如下:
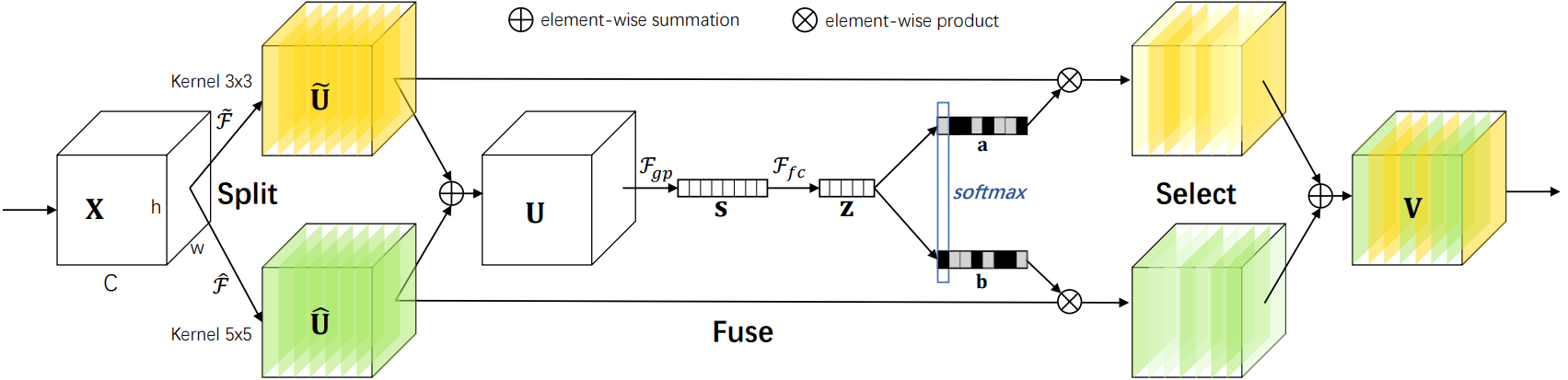
2.1 Split阶段
-
在Split阶段会分出多个分支,每个分支实现不同大小的感受野,从而捕获不同的特征。
-
为提高效率,传统的5×5卷积被替换为带有3×3卷积核和膨胀大小为2的膨胀卷积。
-
具体公式如下:
F ~ : X → U ~ ∈ R h × w × C F ^ : X → U ^ ∈ R h × w × C \widetilde{\mathcal{F}}:\mathbf{X}\to\widetilde{\mathbf{U}}\in\mathbb{R}^{h\times w\times C} \\ \widehat{\mathcal{F}}:\mathbf{X}\to\widehat{\mathbf{U}}\in\mathbb{R}^{h\times w\times C} F :X→U ∈Rh×w×CF :X→U ∈Rh×w×C
2.2 Fuse阶段
该阶段会整合分支信息,具体步骤如下:
-
通过element-wise summation得到 U U U
U = U ~ + U ^ \mathbf{U}=\widetilde{\mathbf{U}}+\widehat{\mathbf{U}} U=U +U -
通过global average pooling得到特征 s s s
s c = F g p ( U c ) = 1 H × W ∑ i = 1 H ∑ j = 1 W U c ( i , j ) s_c=\mathcal{F}_{gp}(\mathbf{U}_c)=\frac1{H\times W}\sum_{i=1}^H\sum_{j=1}^W\mathbf{U}_c(i,j) sc=Fgp(Uc)=H×W1i=1∑Hj=1∑WUc(i,j)
就是一个平均池化操作。 -
通过FC全连接层得到 z ∈ R d × 1 \mathbf{z}\in\mathbb{R}^{d\times1} z∈Rd×1
z = F f c ( s ) = δ ( B ( W s ) ) \mathbf{z}=\mathcal{F}_{fc}(\mathbf{s})=\delta(\mathcal{B}(\mathbf{W}\mathbf{s})) z=Ffc(s)=δ(B(Ws))
其中 B \mathcal{B} B 是batch normalization, δ \delta δ 是ReLU, W ∈ R d × C \mathbf{W}\in\mathbb{R}^{d\times{C}} W∈Rd×C。注意这里通过reduction ratio r r r 和阈值 L L L 两个参数控制 z z z 的输出通道 d d d:
d = max ( C / r , L ) d=\max(C/r,L) d=max(C/r,L)
L L L 默认值为32。 -
通过两个不同的FC层(即矩阵A、B)分别得到 a a a 和 b b b,这里将通道从 d d d 又映射回原始通道数 C C C。
-
对 a , b a,b a,b 对应通道 c c c 处的值进行 s o f t m a x softmax softmax 处理。
a c = e A c z e A c z + e B c z b c = e B c z e A c z + e B c z a_{c}=\frac{e^{{\mathbf{A}_{c}\mathbf{z}}}}{e^{{\mathbf{A}_{c}\mathbf{z}}}+e^{{\mathbf{B}_{c}\mathbf{z}}}} \\ \\ b_{c}=\frac{e^{{\mathbf{B}_{c}\mathbf{z}}}}{e^{{\mathbf{A}_{c}\mathbf{z}}}+e^{{\mathbf{B}_{c}\mathbf{z}}}} ac=eAcz+eBczeAczbc=eAcz+eBczeBcz
在公式中, A , B ∈ R d × C A,B\in\mathbb{R}^{d\times C} A,B∈Rd×C, A c z A_c z Acz 和 B c z B_c z Bcz 分别代表不同(3×3、5×5)的卷积核经过全局池化( F g p F_{gp} Fgp)和全连接层( F f c F_{fc} Ffc)后得到的特征。 a , b a,b a,b分别表示 U ~ 和 U ^ \widetilde{\mathbf{U}} 和 \widehat{\mathbf{U}} U 和U 的注意力系数。
2.3 Select阶段

具体步骤如下:
- U ~ 和 U ^ \widetilde{\mathbf{U}} 和 \widehat{\mathbf{U}} U 和U 分别与 s o f m a x sofmax sofmax 处理后的 a , b a,b a,b 相乘,再相加,得到最终输出的 V V V 和原始输入 X X X 的维度一致。
V c = a c ⋅ U ~ c + b c ⋅ U ^ c a c + b c = 1 \mathbf{V}_c=a_c\cdot\widetilde{\mathbf{U}}_c+b_c\cdot\widehat{\mathbf{U}}_c \\ \quad a_c+b_c=1 Vc=ac⋅U c+bc⋅U cac+bc=1
其中 V = [ V 1 , V 2 , . . . , V c ] , V c ∈ R H × W \mathbf{V} = [\mathbf{V}_1,\mathbf{V}_2,...,\mathbf{V}_c], \mathbf{V}_c \in \mathbb{R}^{H\times W} V=[V1,V2,...,Vc],Vc∈RH×W
2.4 融入模型
ResNeXt加入SE和SK:
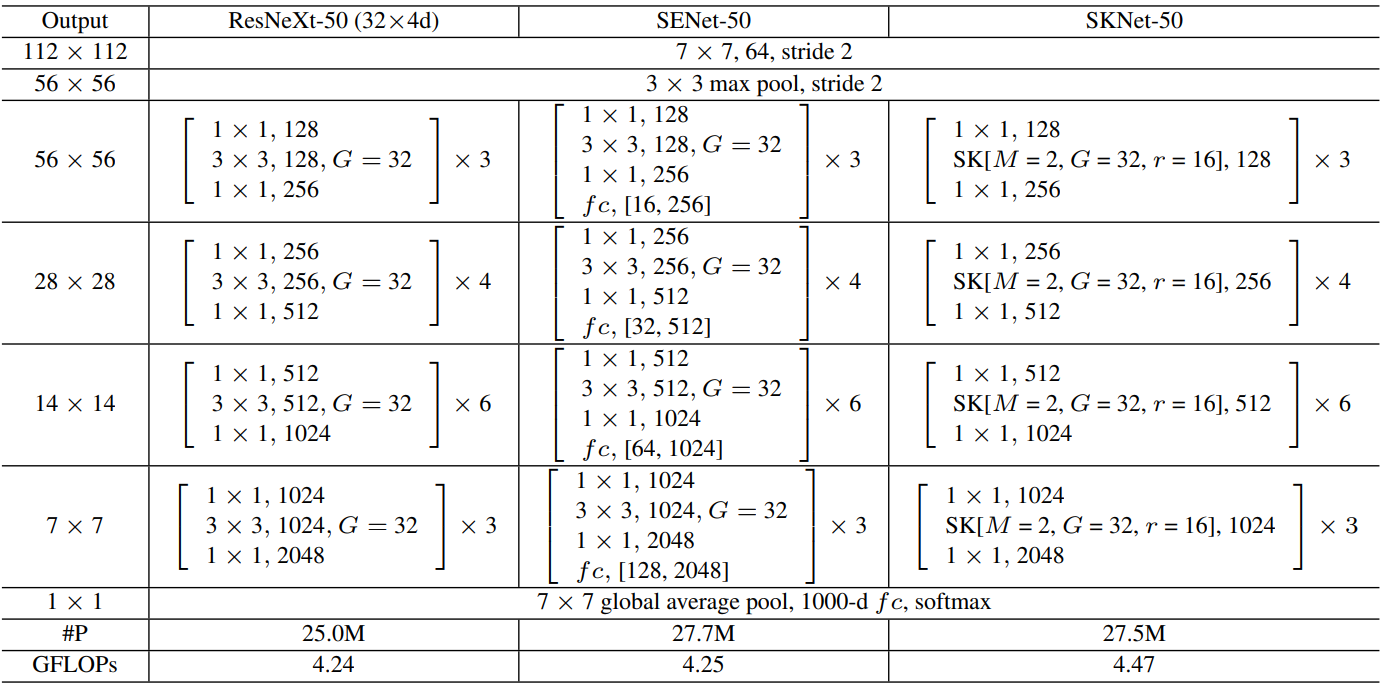
其中M表示SK中的分支数,M=2表示5×5和3×3两个分支。
2.5 注意力权重分析
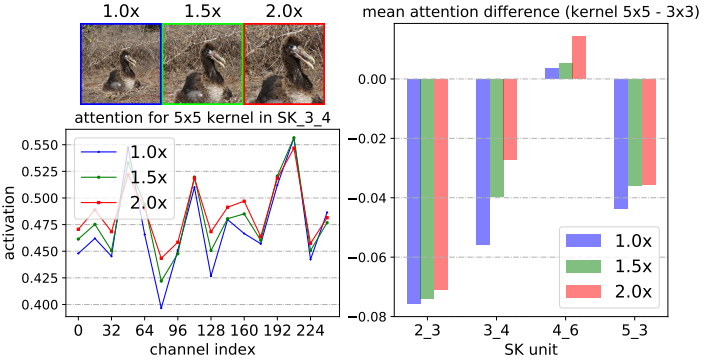
| 
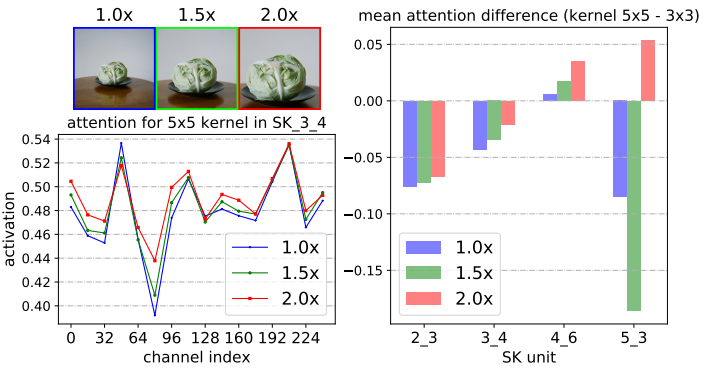
|
图标注解:
-
通过中心裁剪和随后的调整大小,逐步将中心对象从1.0× 扩大到2.0×
-
SK_X_Y 中的 X 代表网络的不同层级(Stage),数字越大表示层越深。
-
Y 代表该层级中的第几个SK模块。
-
不同的SK模块在不同的层级负责提取不同尺度、不同语义的特征。
-
从第2层到第5层,特征从低级(如边缘、纹理)逐渐过渡到高级语义信息(如物体、场景等)。
-
channel index(32、64、96等) 表示不同通道编号。
-
activation表示每个通道上的注意力权重值。这个值越高,表明网络对该通道上的特征越重视。
结论:
- 当目标物体增大时,对大核(5×5) 的关注权值增大,这表明神经元自适应地变大。
- 我们发现了一个关于自适应选择跨深度作用的令人惊讶的模式:目标对象越大,越会将更多的注意力分配给更大的对象。
- 随着网络加深,5x5卷积核的权重值也逐渐在变大,但在更高层时又不同。
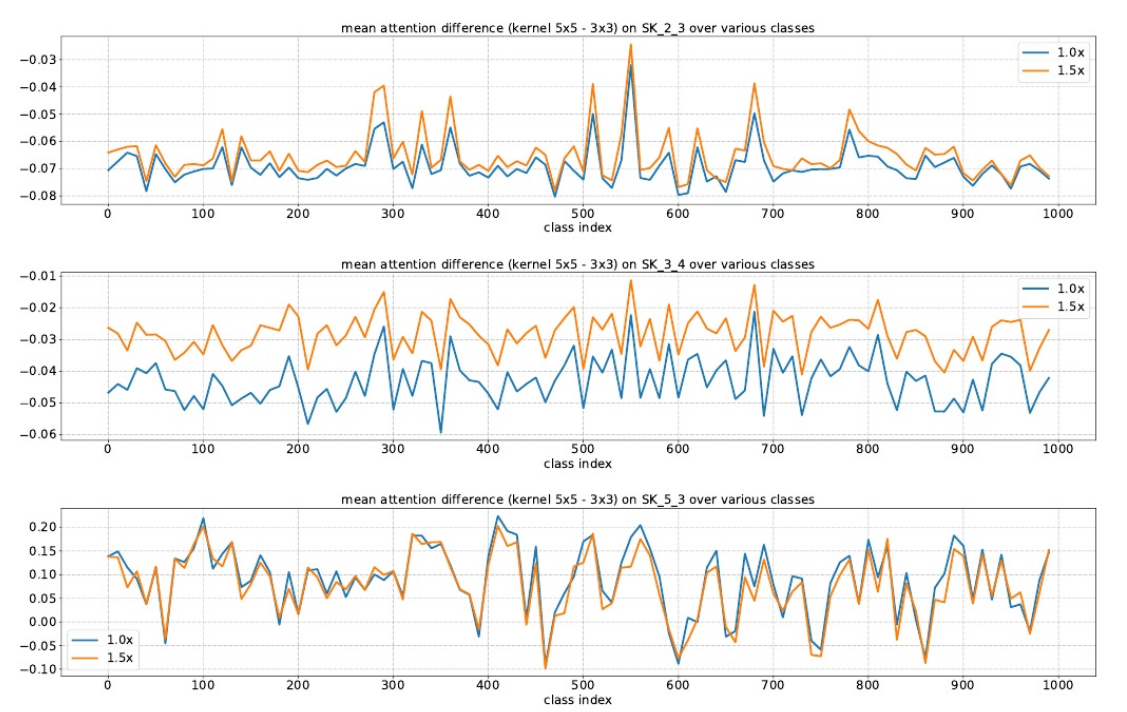
对于使用ImageNet上所有验证样本的1000个类别中的每一个,在SKNet-50的SK单元上的平均注意差(内核的平均注意值5×5减去内核的平均 注意值3×3)。在低级或中级SK单元(例如,SK 2.3, SK 34 4)上,如果目标对象变大(1.0x→1.5x),则明显更强调5×5核。
结论:
在低级和中级阶段(例如,SK 23 3, SK 34 4),通过选择性核机制的核。然而,在更高的层次(例如,SK 53 3),所有的尺度信息都丢失了,这样的模式消失了。
这表明在网络的前期,可以根据对象大小的语义感知选择合适的核大小,从而有效地调整这些神经元的RF大小。然而,这种模式不存在于像SK 5.3这样的非常高层中,因为对于高层表示, “尺度”部分编码在特征向量中,与低层的情况相比, 内核大小的影响较小。
2.6 性能对比
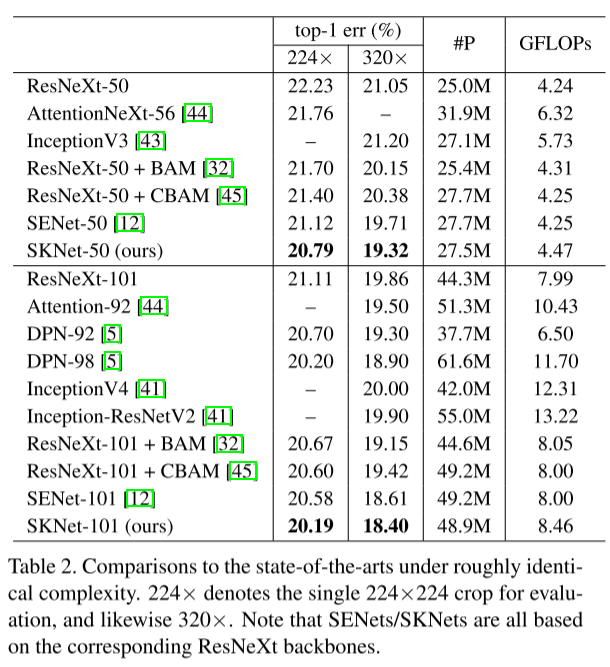
总之,作者想表达的就是自己模型性能最好!
三、 空间注意力
空间注意力(Spatial Attention)是一种专注于特征图的空间维度的重要性分配的机制。它通过对特征图中的特定空间位置进行加权,从而突出对任务最有贡献的区域,抑制无关或冗余的区域,以提高模型的性能
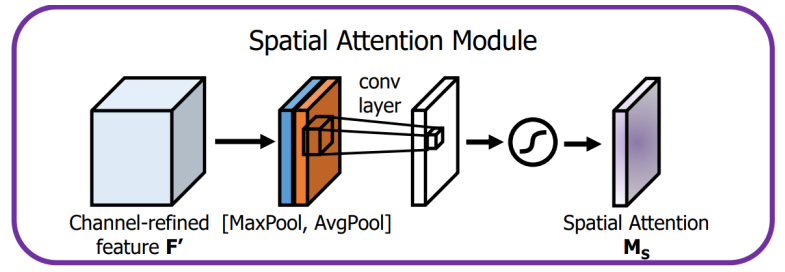
1. Spatial Attention Module
- 这里介绍的空间注意力是 CBAM 中的组成模块
- 论文地址:【https://arxiv.org/pdf/1807.06521】
- 空间注意力模块通过卷积操作为特征图的每个空间位置生成权重,聚焦在图像中的关键区域,这是对通道注意力的补充
- 空间注意力模块计算公式如下:
- F a v g s ∈ R 1 × H × W \mathbf{F_{avg}^s}\in\mathbb{R}^{1\times H\times W} Favgs∈R1×H×W表示通道中的平均池化特征
- F m a x s ∈ R 1 × H × W \mathbf{F_{max}^s}\in\mathbb{R}^{1\times H\times W} Fmaxs∈R1×H×W表示通道中的最大池化特征
- f 7 × 7 f^{7\times7} f7×7表示滤波器大小为 7×7 的卷积操作
- σ \sigma σ表示 sigmoid 激活函数
M s ( F ) = σ ( f 7 × 7 ( [ A v g P o o l ( F ) ; M a x P o o l ( F ) ] ) ) = σ ( f 7 × 7 ( [ F a v g s ; F m a x s ] ) ) , \begin{aligned} \mathbf{M_s}(\mathbf{F})& \begin{aligned}&=\sigma(f^{7\times7}([AvgPool(\mathbf{F});MaxPool(\mathbf{F})]))\end{aligned} \\ &=\sigma(f^{7\times7}([\mathbf{F_{avg}^s};\mathbf{F_{max}^s}])), \end{aligned} Ms(F)=σ(f7×7([AvgPool(F);MaxPool(F)]))=σ(f7×7([Favgs;Fmaxs])),
-
空间注意力模块布局如下:
- 输入特征:通道注意力模块的输出 $ F’$ 就是空间注意力模块的输入
- 池化操作:
- 在 F ′ F' F′ 的通道维度上进行全局的 MaxPool 和 AvgPool,生成 2 个二维特征图,维度为 1 × H × W 1 × H × W 1×H×W
- 卷积层:
- 把池化得到的特征图连接起来 F c o n c a t ∈ R 2 × H × W F_{concat}\in\mathbb{R}^{2 \times H\times W} Fconcat∈R2×H×W
- 使用一个 7 × 7 7 \times 7 7×7的卷积核对拼接后的特征图进行卷积操作,经 Sigmoid 激活后,生成空间注意力图 M S M_S MS,维度为 $1 \times H \times W $
- 输出:
- 空间注意力图 M S M_S MS与经过通道注意力增强后的特征图 $ F’$ 逐元素相乘,输出最终的增强特征图
1.1 实验结论
-
这个实验结论是 CBAM 论文中给出的,不仅仅是添加了空间注意力,还添加了通道注意力
-
可以看出都比不用(baseline)效果要好

1.2 构建
import torch
import torch.nn as nn# 空间注意力模块
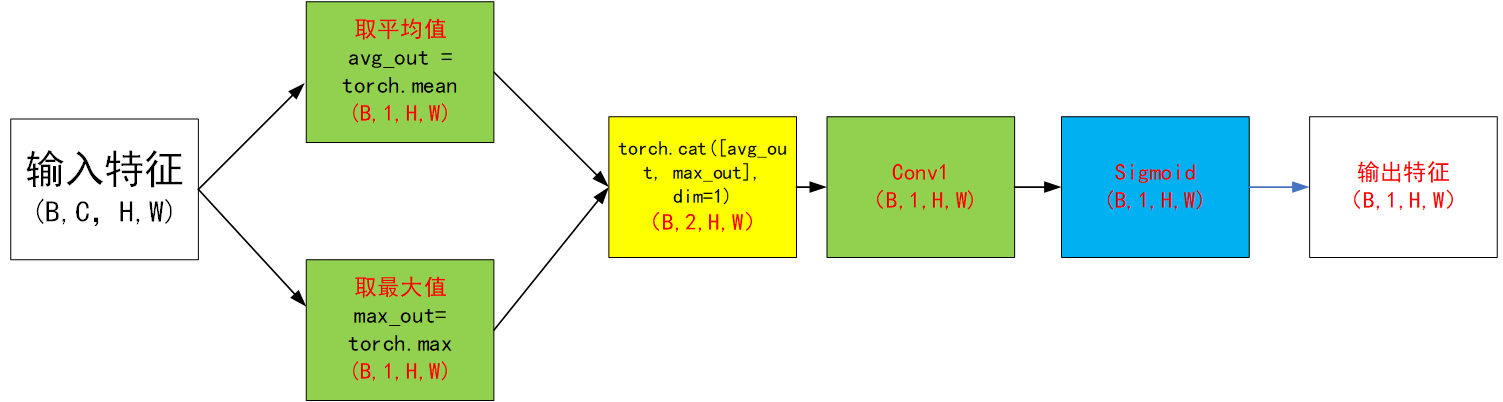
class SpatialAttentionModule(nn.Module):def __init__(self):super(SpatialAttentionModule, self).__init__()self.conv = nn.Sequential(nn.Conv2d(in_channels=2, out_channels=1, kernel_size=7, stride=1, padding=3),nn.Sigmoid(),)def forward(self, x):max_pool = torch.max(x, dim=1, keepdim=True)[0]avg_pool = torch.mean(x, dim=1, keepdim=True)pool = torch.cat([max_pool, avg_pool], dim=1)out = self.conv(pool)return out
2. Learn to Pay Attention
论文地址:https://arxiv.org/pdf/1804.02391
源代码地址:https://github.com/SaoYan/LearnToPayAttention
空间注意力(Spatial Attention)主要用于CV,它在空间维度上选择性地关注输入特征图的不同位置,从而提升模型对关键区域的感知能力。其实现原理是基于不同像素位置,生成对应概率掩码,是比较低层的注意力机制。
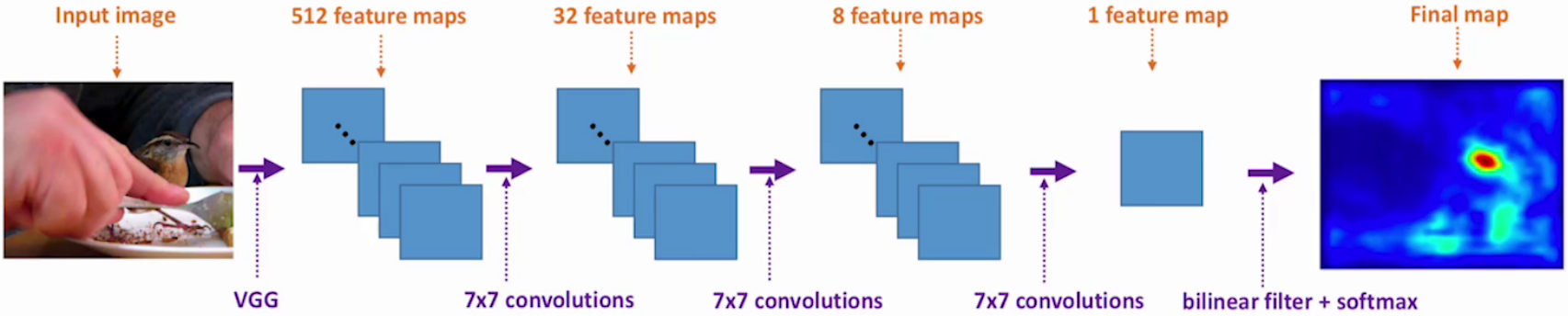
2.0 基本认知
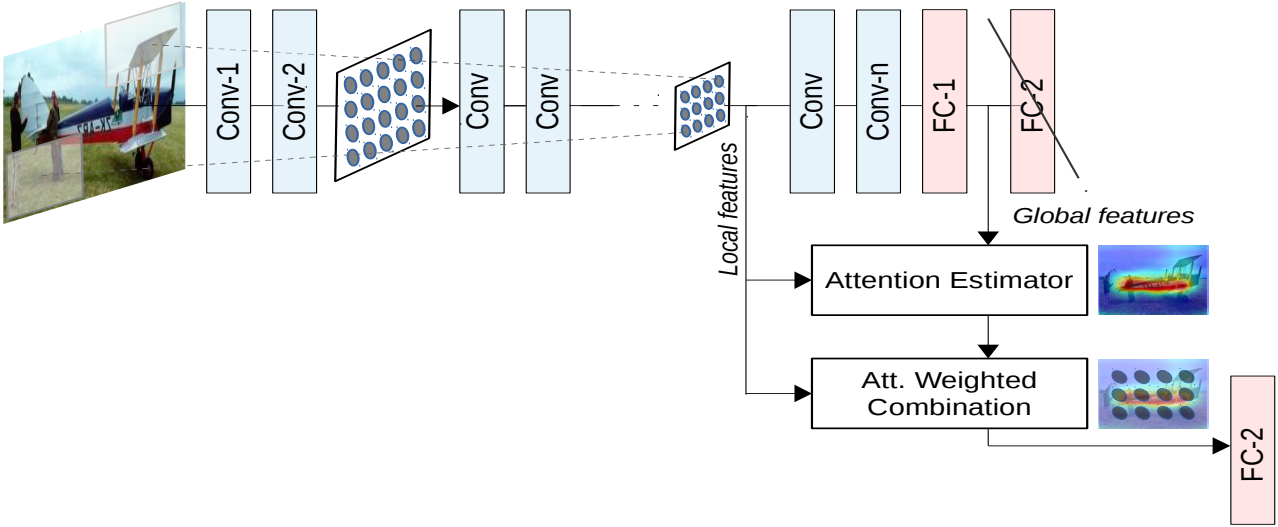
结合全局特征和局部特征获得注意力机制,使用加权的局部特征来识别目标。
-
**Local features:**局部特征
如头部、轮子、尾翼、发动机、机身标志或窗户等,包含丰富的细节,对于识别飞机的具体种类、型号等非常有帮助。
-
**Global features:**全局特征
如整体形状、轮廓、大小、相对背景中的位置等;对于识别是什么飞机很重要,如战斗机、客机还是直升机。
-
特征融合:
在生成注意力权重前会对输入的局部和全局特征进行融合。通过全局池化(Global Average Pooling)来获得全局上下文信息。
-
Attention Estimator:
对输入特征图进行多层卷积、池化、激活等操作,用来挖掘特征之间的关系,从而生成注意力权重图。权重图的每个位置对应特征图中的一个空间位置,表示该位置的重要性。
-
Att. Weighted Combination:
将生成的注意力图与原始特征图逐点相乘,得到加权后的特征图。
2.1 融入模型
基于VGG16网络的多层注意力融合:是为了适配不同大小的目标
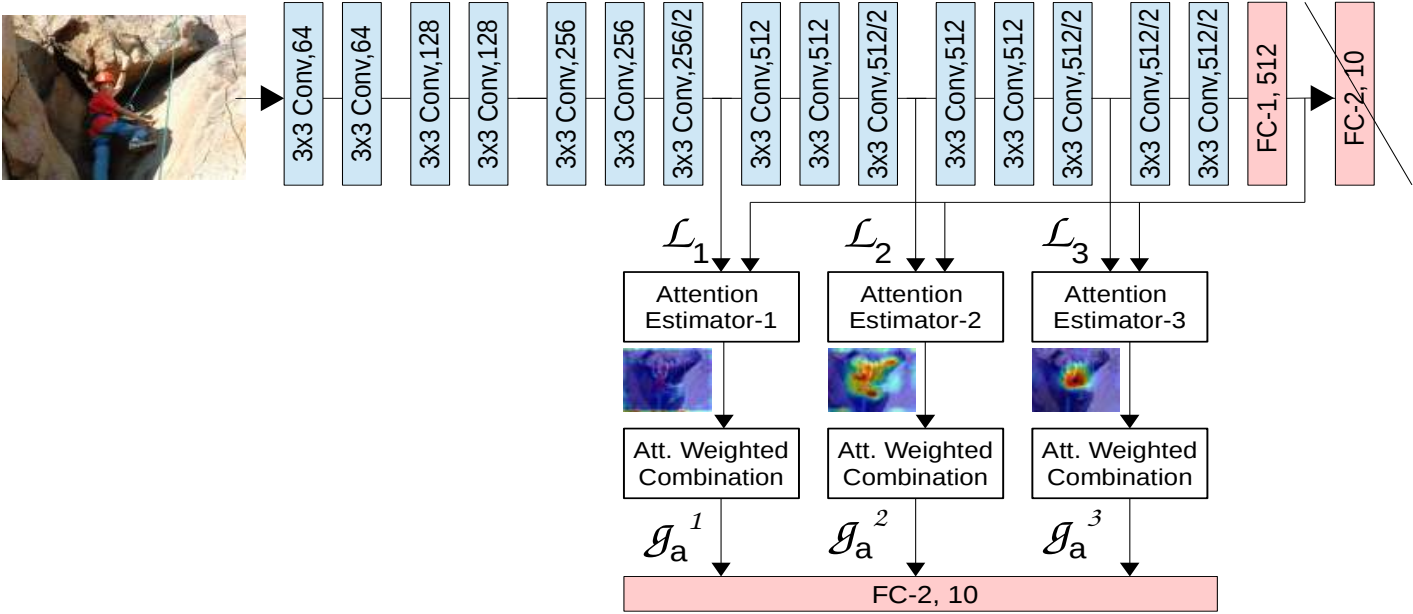
通过多层注意力估计器,模型能够学会在不同的特征层次上关注有用的信息,提升分类性能。
2.1.1 流程概述
- 局部特征向量,s表示特征图层数: L s = { ℓ 1 s , ℓ 2 s , ⋯ , ℓ n s } , s ∈ { 1 , ⋯ , S } \mathcal{L}^s=\{\boldsymbol{\ell}_1^s,\boldsymbol{\ell}_2^s,\cdots,\boldsymbol{\ell}_n^s\},s\in\{1,\cdots,S\} Ls={ℓ1s,ℓ2s,⋯,ℓns},s∈{1,⋯,S}
- L n ( L 1 、 L 2 、 L 3 ) L_n(L_1、L_2、L_3) Ln(L1、L2、L3)为VGG不同层级的局部特征向量,将
FC-1, 512的输出 G G G 视作全局特征,同时移除FC-2, 10层。 - Attention Estimator 接收 L n L_n Ln 和 G G G 作为输入,计算出注意力权重图(Attention map),挖掘特征之间的关系。
- Attention map作用于 L n L_n Ln 的每个channel得到 Weighted local feature G a n \mathscr{G}_{\mathrm{a}}^n Gan。
- 把各个层级下的 G a n \mathscr{G}_{\mathrm{a}}^n Gan进行连接操作后得到 G a : [ G a 1 , G a 2 , G a 3 ] \mathscr{G}_{\mathrm{a}}:[\mathscr{G}_{\mathrm{a}}^1, \mathscr{G}_{\mathrm{a}}^2, \mathscr{G}_{\mathrm{a}}^3] Ga:[Ga1,Ga2,Ga3]
- 最后将 G a \mathscr{G}_{\mathrm{a}} Ga送入全连接层
FC-2, 10进行分类。
2.1.2 G a \mathscr{G}_{\mathrm{a}} Ga计算过程
计算过程及关联数学公式如下:
a i s = exp ( c i s ) ∑ j = 1 n exp ( c j s ) , i ∈ { 1 ⋯ n } . g a s = ∑ i = 1 n a i s ⋅ ℓ i s g a = [ g a 1 , g a 2 , ⋯ g a S ] \begin{aligned} &a_{i}^{s}=\frac{\operatorname{exp}(c_{i}^{s})}{\sum_{j=1}^{n}\operatorname{exp}(c_{j}^{s})}, i\in\{1\cdots n\}. \\ &\boldsymbol{g}_{a}^{s}=\sum_{i=1}^{n}a_{i}^{s}\cdot\boldsymbol{\ell}_{i}^{s} \\ &\boldsymbol{g}_{a} = [\boldsymbol{g}_{a}^{1},\boldsymbol{g}_{a}^{2},\cdots\boldsymbol{g}_{a}^{S}] \end{aligned} ais=∑j=1nexp(cjs)exp(cis),i∈{1⋯n}.gas=i=1∑nais⋅ℓisga=[ga1,ga2,⋯gaS]
公式注解:
-
c i s c_{i}^{s} cis:第 s s s 层特征图在位置 i i i 处的兼容性分数(compatibility score)。
-
a i s a_i^s ais:通过 softmax 计算得到的第 s s s 层特征图在位置 i i i 处的注意力权重。
-
g a s g_a^s gas:经过注意力加权后的第 s s s 层特征图的全局加权特征向量。
-
ℓ i s \ell_i^s ℓis:第 s s s 层特征图在位置 i i i 处的局部特征向量。
-
a i s ⋅ ℓ i s a_i^s \cdot \ell_i^s ais⋅ℓis:注意力权重 a i s a_i^s ais 和局部特征 l i s l_i^s lis 相乘,表示该位置在注意力机制中的贡献。
-
g a g_a ga:最终得到的全局加权特征向量,它是不同层的加权特征向量 g a s g_a^s gas 的拼接结果。
-
g a s g_a^s gas:是第 s s s 层卷积特征图的加权特征向量。
整个过程最关键的是 a i s a_{i}^{s} ais的计算,而 a i s a_{i}^{s} ais 的计算依赖于 c i s c_{i}^{s} cis,那么 c i s c_{i}^{s} cis是如何计算的呢?
2.1.3 兼容性得分计算
兼容性得分,compatibility score,论文给出了两种方式:
- 内积法:两个特征直接做点乘得到
c i s = ⟨ ℓ i s , g ⟩ , i ∈ { 1 ⋯ n } . c_i^s=\langle\ell_i^s,\boldsymbol{g}\rangle, i\in\{1\cdots n\}. cis=⟨ℓis,g⟩,i∈{1⋯n}.
- 有参法:将两个张量逐元素相加后,再经过一个全连接层进行学习, 下式中 u \boldsymbol{u} u 就是学习到的线性映射
c i s = ⟨ u , ℓ i s + g ⟩ , i ∈ { 1 ⋯ n } c_i^s=\langle\boldsymbol{u},\boldsymbol{\ell}_i^s+\boldsymbol{g}\rangle, i\in\{1\cdots n\} cis=⟨u,ℓis+g⟩,i∈{1⋯n}
2.2 实验效果
从可视化和数据化两个方面进行观察。
2.2.1 效果可视化

图阅读注解:
proposed:表示加入LTPA注意力机制existing:表示加入传统的注意力机制
2.2.2 效果数据化
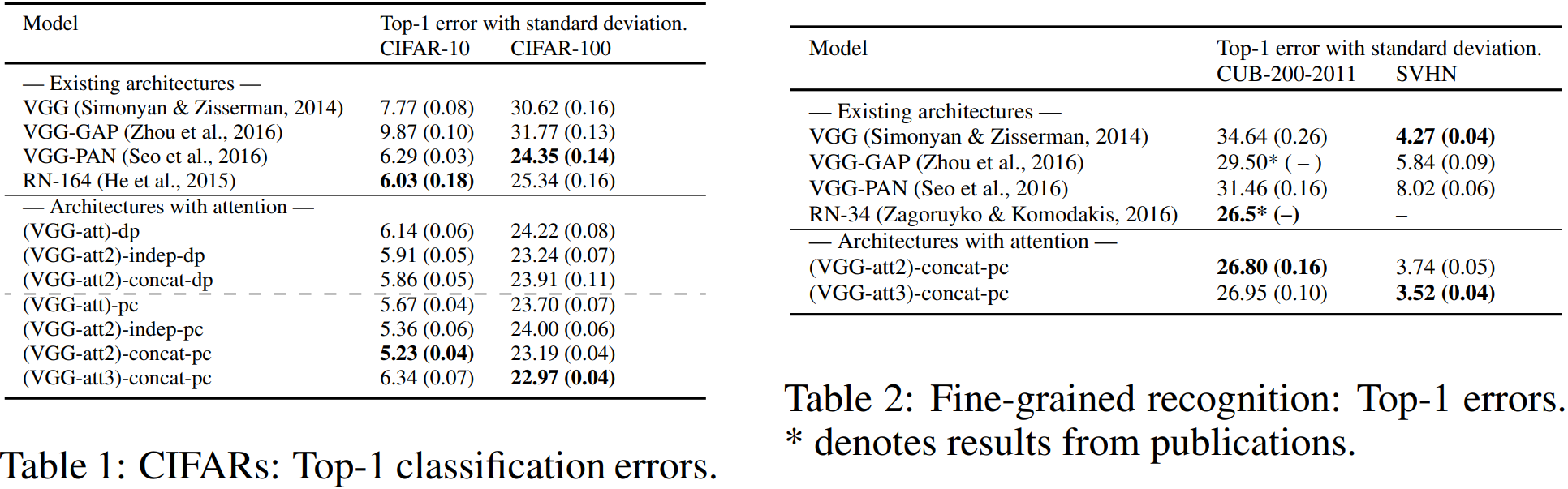
表阅读注解:
- 注意力获取方法:pc表示有参法,dp表示内积法
- 最终预测策略:concat表示特征拼接后预测,indep表示多尺度独立预测结果相加