【ELF2学习板】利用OpenMP采用多核并行技术提升FFTW的性能
目录
引言
OpenMP简介
编译OpenMP支持的FFTW库
部署与测试
测试程序
程序部署
测试结果
结语
引言
在前面已经介绍了在ELF2开发板上运行FFTW计算FFT。今天尝试利用RK3588的多核运算能力来加速FFT运算。FFTW利用多核能力可以考虑使用多线程或者OpenMP。今天介绍一下OpenMP的测试结果。
OpenMP简介
OpenMP(Open Multi-Processing)是一种基于共享内存的并行编程模型,旨在简化多核CPU的并行计算开发。它通过编译器指令(Compiler Directives)、运行时库函数和环境变量,帮助开发者轻松实现多线程并行化。
OpenMP的核心特性包括:
-
基于指令的并行化
通过#pragma omp编译指导语句实现并行控制,无需手动管理线程。 -
共享内存模型
所有线程共享同一内存空间,可通过共享变量直接通信。 -
工作共享(Work-Sharing)
自动将任务(如循环迭代)分配到多个线程。 -
数据环境管理
明确控制变量的共享(shared)或私有(private)属性。 -
动态线程调度
支持运行时调整线程数量和任务分配策略。
编译OpenMP支持的FFTW库
FFTW默认的选项是不编译OpenMP的,所以想使用OpenMP需要重新编译一下FFTW库。
交叉编译前用如下命令配置:
./configure --prefix=/mnt/d/test/install --host=arm-linux --enable-float --enable-openmp CC=aarch64-linux-gnu-gcc然后执行make和make install就可以得到相应的头文件和库文件。此时库文件会多一个libfftw3f_omp.a。

部署与测试
测试程序
为了使程序支持OpenMP并利用多核系统提升速度,需要进行以下修改:
-
包含OpenMP头文件:添加
#include <omp.h>以使用OpenMP函数。 -
初始化FFTW多线程支持:在
main函数开始时调用fftwf_init_threads()。 -
设置FFTW使用的线程数:使用
omp_get_max_threads()获取可用线程数,并通过fftwf_plan_with_nthreads()配置。 -
并行化初始化数据的循环(可选):使用
#pragma omp parallel for加速数据初始化。 -
编译时链接OpenMP和FFTW多线程库:确保编译器链接
-lfftw3_omp并添加-fopenmp选项。
修改后的代码如下:
#include <stdio.h>
#include <stdlib.h>
#include <fftw3.h>
#include <time.h>
#include <omp.h> // 添加OpenMP头文件// 计算时间差(单位:微秒)
long long get_time_diff_us(struct timespec start, struct timespec end) {return (end.tv_sec - start.tv_sec) * 1000000LL + (end.tv_nsec - start.tv_nsec) / 1000;
}int main() {const int N = 2048;fftwf_complex *in, *out, *back;fftwf_plan p, q;struct timespec start, end;long long fft_time_us, ifft_time_us;// 初始化FFTW多线程支持fftwf_init_threads();int threads = omp_get_max_threads(); // 获取可用线程数printf("可用线程数 = %d\n", threads);fftwf_plan_with_nthreads(threads); // 设置FFTW使用的线程数// 分配内存in = (fftwf_complex*) fftwf_malloc(sizeof(fftwf_complex) * N);out = (fftwf_complex*) fftwf_malloc(sizeof(fftwf_complex) * N);back = (fftwf_complex*) fftwf_malloc(sizeof(fftwf_complex) * N);// 并行初始化输入数据#pragma omp parallel for // 使用OpenMP并行化循环for (int i = 0; i < N; i++) {in[i][0] = (float)i; // 实部in[i][1] = 0.0f; // 虚部}// 创建FFT计划p = fftwf_plan_dft_1d(N, in, out, FFTW_FORWARD, FFTW_ESTIMATE);// 记录FFT开始时间clock_gettime(CLOCK_MONOTONIC, &start);// 执行FFT(自动多线程加速)fftwf_execute(p);// 记录FFT结束时间clock_gettime(CLOCK_MONOTONIC, &end);// 计算FFT时间fft_time_us = get_time_diff_us(start, end);// 创建IFFT计划q = fftwf_plan_dft_1d(N, out, back, FFTW_BACKWARD, FFTW_ESTIMATE);// 记录IFFT开始时间clock_gettime(CLOCK_MONOTONIC, &start);// 执行IFFT(自动多线程加速)fftwf_execute(q);// 记录IFFT结束时间clock_gettime(CLOCK_MONOTONIC, &end);// 计算IFFT时间ifft_time_us = get_time_diff_us(start, end);// 输出结果printf("2048点单精度FFT所需时间: %lld 微秒\n", fft_time_us);printf("2048点单精度IFFT所需时间: %lld 微秒\n", ifft_time_us);// 释放计划和内存fftwf_destroy_plan(p);fftwf_destroy_plan(q);fftwf_free(in);fftwf_free(out);fftwf_free(back);return 0;
}关键修改说明:
-
多线程初始化:通过
fftwf_init_threads()和fftwf_plan_with_nthreads()启用FFTW的多线程支持。 -
并行数据初始化:使用OpenMP指令加速数据填充循环(根据实际情况可选)。
-
FFT/IFFT并行计算:FFTW会在执行
fftwf_execute()时自动使用配置的线程数进行并行计算。
这些修改使得FFT和IFFT计算过程能够利用多核CPU,从而显著提升处理速度。
程序编译的命令行为:
aarch64-linux-gnu-gcc -o fftwtest-openmp fftwtest-openmp.c -Iinclude -Llib -lfftw3f -lm -lfftw3f_omp -fopenmp程序部署
ELF2开发板默认是没有OpenMP支持库的,需要将主机的/usr/aarch64-linux-gnu/lib/libgomp.so.1 拷贝到开发板的/usr/lib目录下,否则程序运行时会报告错误。
测试结果
我本来对程序的运行时间是没啥期待的,因为2048点对于FFT计算来说太短了,很难并并行加速。结果还行,有些效果,差不多50微秒左右,比NEON加速还快一些。
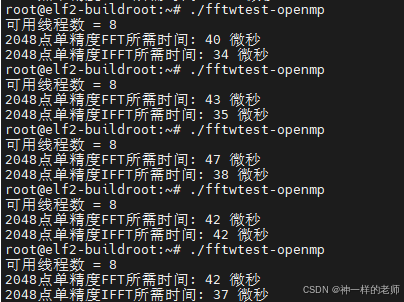
RK3588搭载四核A76+四核A55,所以OpenMP可用线程数为8。
结语
OpenMP加速的结果令人欣慰。不过CPU计算FFT可能也就是这个水平了,估计没法大幅度提升了。