【AI学习】DeepSeek-R1是如何训练的?
一直没看明白Deepseek-R1到底是如何训练的,之前只是了解个大概。在前文《关于 DeepSeek-R1的几个流程图》中引用了几张R1训练的流程图,仔细看下去,这些图在细节处并不一致。这种不一致,大概是两种可能,画图的人也并没有看清细节,另外一种更大的可能就是R1的技术报告本身就语焉不详。
这两天听了李宏毅老师讲推理模型,关于R1的训练过程,讲述得比较清晰。本文主要将李宏毅老师关于R1训练过程的讲述做一个记录。
首先简单进行一下前情回顾,当然,也可以略过直接进入正题。
前情回顾
Test-time compute
Test-time compute(测试时计算)是指在模型推理(inference)阶段(即实际应用时)分配更多计算资源进行推理(reasoning),通过多步推理、策略拆解或模拟搜索等方式提升模型对复杂问题的处理能力。这一概念可追溯至2016年的AlphaGo,其采用的蒙特卡洛树搜索(MCTS)即在推理阶段通过大规模模拟计算优化决策路径,本质上是测试时计算的早期应用。在当今大模型领域,该方法被进一步扩展,允许模型在生成答案时动态分配算力,例如通过思维链(Chain of Thought)逐步拆解问题,或结合强化学习优化推理路径。OpenAI的O1模型和DeepSeek-R1模型即通过强化测试时计算显著提升了数学和编程任务的逻辑推理能力。这一技术突破了传统预训练模型的静态推理模式,成为提升模型智能水平的重要方向。
在论文《Scaling Scaling Laws with Board Games》(探索棋盘游戏中的扩展规律)中有下面一张图:
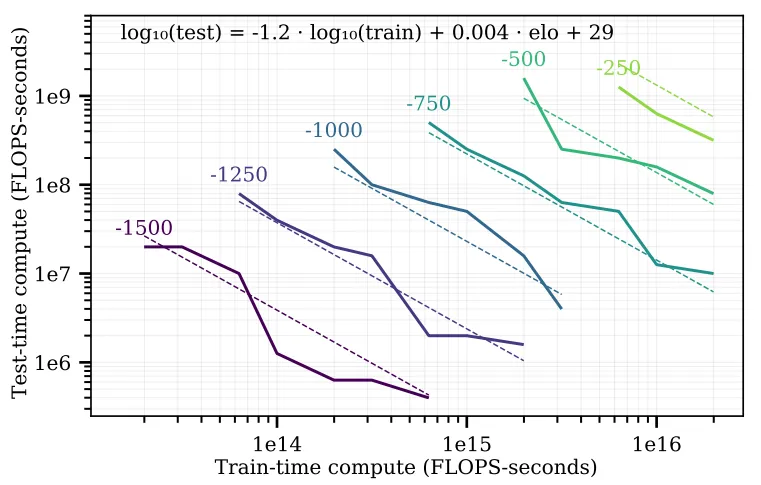
这张图展示了train-time compute 和 test-time compute之间的权衡关系,具体含义如下:
横轴表示训练时计算量(以 FLOPS-seconds 为单位),纵轴表示测试时计算量(同样以 FLOPS-seconds 为单位)。图中的每条虚线代表在 9×9 棋盘上达到特定 Elo 评分所需的最小训练 - 测试计算量组合。
从图中可以看出,训练时计算量和测试时计算量之间存在一种权衡关系:当训练时计算量增加时,测试时计算量可以相应减少,反之亦然。具体来说,对于每次训练时计算量增加 10 倍,可以抵消约 15 倍的测试时计算量,直到测试时树搜索减少到单节点搜索的下限。这意味着研究人员可以根据实际需求和资源限制,在训练和测试阶段的计算量分配上进行灵活权衡,以达到相同的性能水平(即相同的 Elo 评分)。
相关方法
Hugging Face 团队去年曾发表一篇关于“开源模型中的推理阶段计算扩展”(Test-time Compute Scaling) 的研究文章,复现 DeepMind 之前的研究成果,具体有下面一些方法:
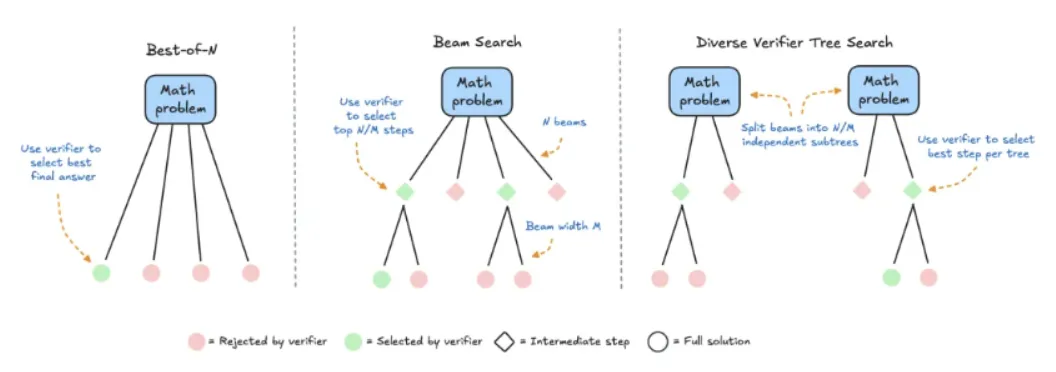
1、Best-of-N:让LLM生成N个候选答案,可以用频率的方法,选择出现次数最多的答案。性能更好的方法是使用奖励模型,强调答案质量而非频率。通过奖励模型,为每个候选答案分配分数,然后选择奖励最高的答案。也有其他变体,不展开。
2、Beam Search:一种探索解决方案空间的系统搜索方法,通常与过程奖励模型 (PRM) 结合使用,以优化问题解决中间步骤的采样和评估。与对最终答案产生单一分数的传统奖励模型不同,PRM 会提供一系列分数,其中推理过程的每个步骤都有一个分数。这种细粒度反馈能力使得 PRM 成为 LLM 搜索方法的自然选择。
3、多样性验证器树搜索 (DVTS):HuggingFace 开发的Beam Search扩展,将初始beam拆分为独立的子树,然后使用 PRM 贪婪地扩展这些子树。这种方法提高了解决方案的多样性和整体性能,尤其是在测试时计算预算较大的情况下。
更详细的信息可以移步《Huggingface复刻Test-time Compute Scaling技术》。其他的计算扩展的方法,更复杂还有蒙特卡洛树搜索(MCTS),这里从Beam Search等算法都涉及过程奖励模型,而R1发布后,一定程度上否定了这些技术路线。
蒸馏
深度学习中,知识蒸馏(Knowledge Distillation)最初由Hinton等人提出,通过让轻量级学生模型模仿教师模型的“软标签”(概率输出)实现知识传递。原本的蒸馏,教师模型和学生模型之间,是精心设计过,要有一定的相似性,从而可以实现对教师模型的深层次特征或概率分布的重复利用。现在的很多所谓“蒸馏”,只不过是用成熟模型的输入输出数据来微调或者训练学生模型,叫知识迁移或行为模拟更合适。
GRPO
GRPO(Group Relative Policy Optimization,群体相对策略优化)是DeepSeek-R1模型的核心强化学习算法,旨在通过分组相对奖励机制优化大语言模型的推理能力。其核心思想是为每个输入状态采样一组动作(如生成多个候选回答),通过组内奖励对比计算相对优势,替代传统PPO算法中依赖价值网络的优势估计,从而显著降低内存占用和计算开销。
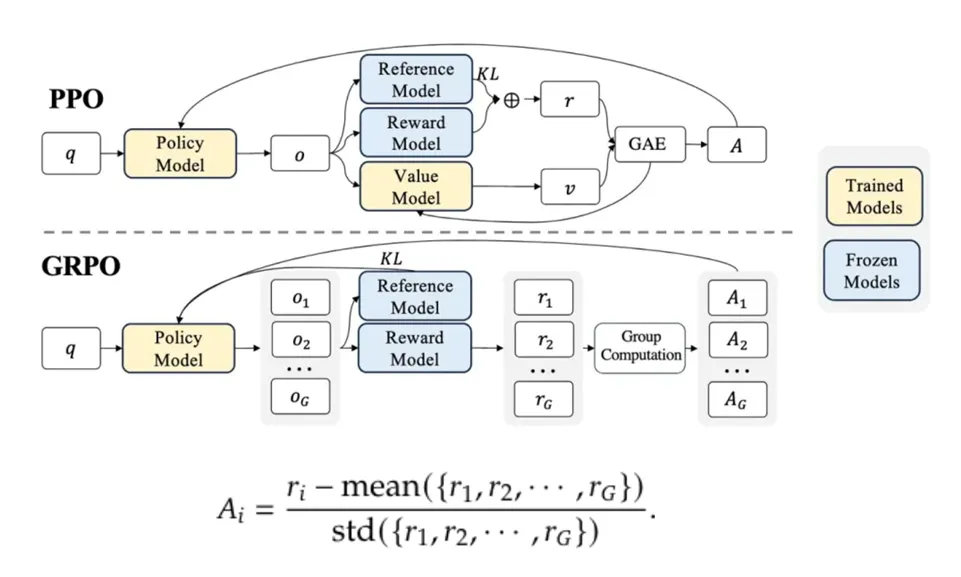
更深入的理解,请移步文章《DeepSeek 背后的数学原理:深入探究群体相对策略优化 (GRPO)》。文章详细解释了GRPO的数学公式,然后给出了案例和代码实现,非常容易理解。
R1的训练过程
下面这张图片来自上月的一篇论文《DeepSeek-R1 Thoughtology:Let’s about LLM reasoning》。
(论文链接:https://arxiv.org/pdf/2504.07128)
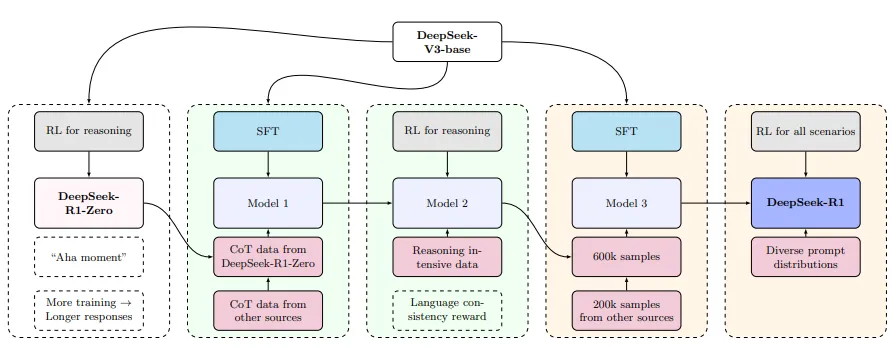
看图说话,R1的训练分为多个阶段。当然,首先要有DeepSeek-V3-base模型。
阶段 1:训练 DeepSeek-R1-Zero,利用 DeepSeek-V3-base 作为基础,通过 GRPO进行训练。R1-Zero 显示出强大的推理能力,这些能力纯粹来自于预训练后的强化学习,而无需其他形式的后训练。
阶段 2:使用 SFT(监督微调),利用由 DeepSeek-R1-Zero 和其他来源生成的 CoT(链式思考)数据进行监督微调。
阶段 3:对阶段2输出的Model 1,在推理密集型数据上进一步使用 GRPO 进行训练。
阶段 4:再次使用 SFT,利用 DeepSeek-V3-base 作为基础,使用由阶段3的Model 2生成的600k推理实例和其他来源生成200k非推理实例进行SFT。这一阶段的目标是通过 SFT 改善模型的多样性和非推理任务的性能。
阶段 5:使用 RL(强化学习)进行最终训练,在多样化的提示分布(包括安全性训练)上进行 RL 训练,最终的 DeepSeek-R1 模型不仅推理能力强,而且在多样化的任务和安全性方面表现出色。
这篇论文指出:DeepSeek-R1是在一个复杂的多阶段训练流程中构建出来的。在这个流程中,多个阶段都大量使用了由前一阶段模型生成的合成训练数据。尽管目前关于DeepSeek-R1的具体训练数据披露较少(训练数据目前没有开源)。但可以合理推测,这些数据经过了大量筛选,甚至部分样本在生成后还经过了人工修正,以体现特定的推理模式。当加入「人的」因素,推理过程像人就说的通了,毕竟只是纯强化学习得到的R1-Zero也并没有作为最终的产品发布。在讨论DeepSeek-R1所展现出的类人推理能力时,有必要意识到:这些推理模式很可能是受到数据筛选与监督微调的强烈影响,而不仅仅是模型「自发」学习到类似人类的推理思维。
R1的训练过程分步骤说明
下面的图片来自李宏毅老师的讲座内容。
DeepSeek-R1-Zero纯粹来自于预训练后的强化学习,并且推理优化只根据最后的结果,不在乎推理过程,也就省去了过程奖励模型。
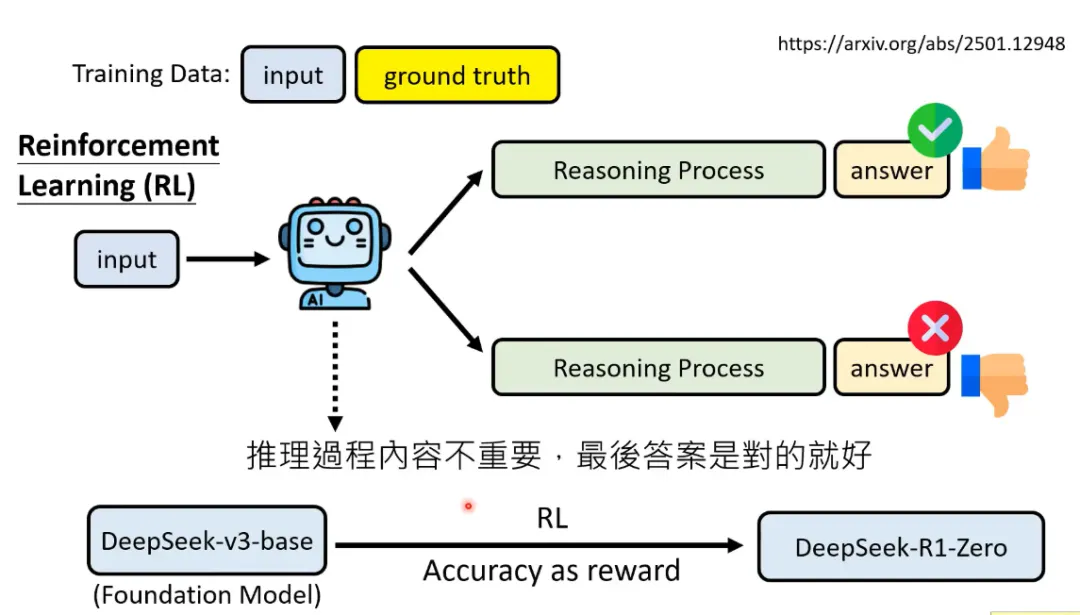
从训练过程和效果来看,模型出现了顿悟时刻(Aha Moment)。

但是R1-Zero的问题是,输出可读性差、语言混杂。可能的原因,训练只看重结果,导致输出的推理过程可读性差。
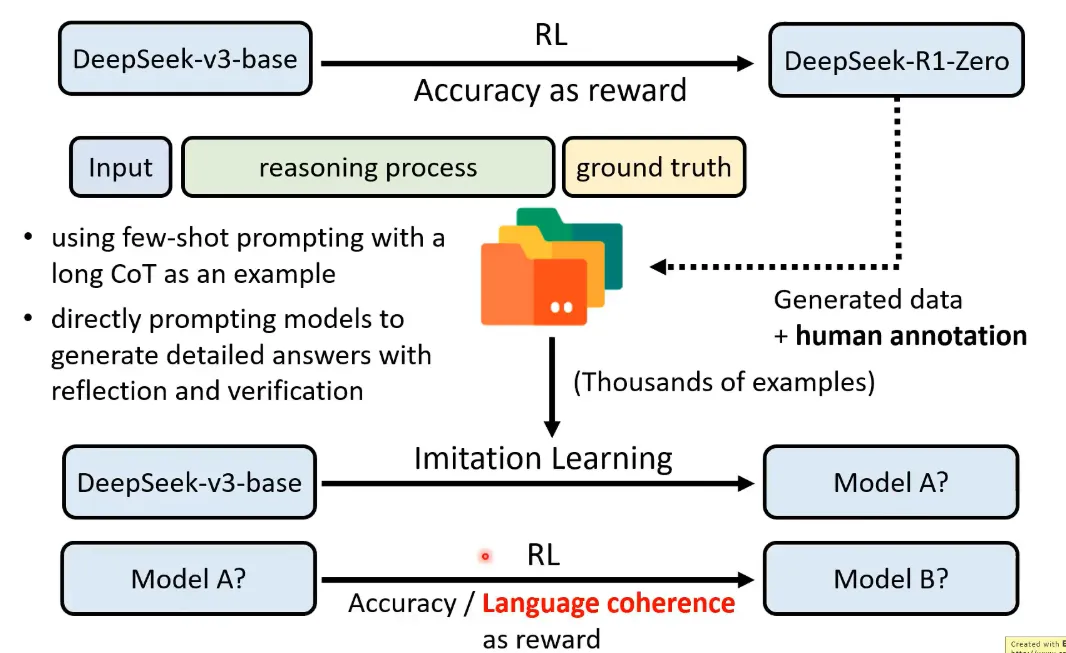
接下来,利用R1-Zero生成数据,就是针对输入(input)和标准答案(ground truth)补全推理过程,但是因为R1-Zero的输出可读性差,这里需要人工修正,至于人工的工作量有多少,不知道。同时还有来自其他模型(具体是什么模型语焉不详)生成的数据,采用了两种提示,有长CoT作为案例的few shot提示,有要求模型生成带有反思和验证的详细答案的提示。这样形成了几千个样本,对V3-base进行SFT,获得Model A,然后再RL获得Model B。
训练Model B的GRPO,对比前面的R1-Zero,奖励中在准确性的基础上增加了语言一致性的目标,这样会导致性能略微下降,但是增强可读性,所以还是用了这种方式。
GRPO主要采用规则型奖励模型:可通过明确规则验证的任务(主要针对复杂推理的任务,如数学、编程和逻辑推理),采用规则型奖励机制进行反馈评估。
GRPO 中的奖励类型:
√ 准确性奖励:基于响应的正确性(例如,解决数学问题、编程问题)。
√ 格式奖励:确保响应符合结构指南(例如,输出包含推理过程)。
√ 语言一致性奖励:惩罚语言混合或不连贯的格式。
√ 例如:r1=1.0(正确且格式良好)。r2=0.9(正确但不太正式)。r3=0.0(错误答案)。r4=1.0(正确且格式良好)
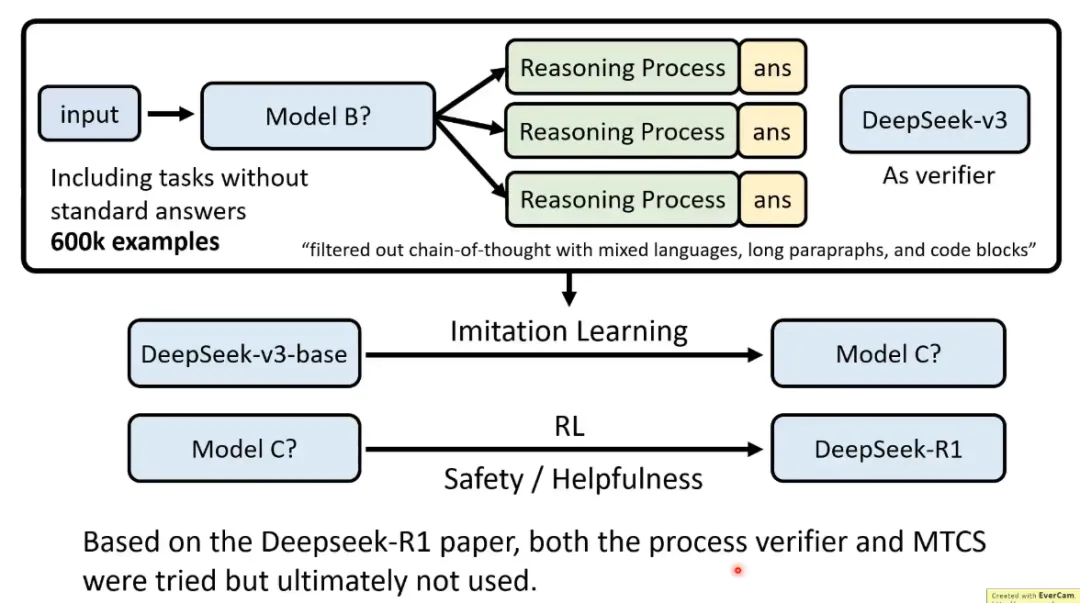
然后这个Model B还是用来生成数据。并且增加了没有标准答案的任务,这种任务就需要基于 DeepSeek-V3 的 SFT 模型作为验证器,对输出进行评估,以及过滤数据。最终形成600k的推理样本数据。
另外再叠加200k非推理样本数据,这些数据来自两部分,通过V3生成CoT数据,以及重用了部分V3的SFT数据。
对V3-base进行SFT,获得Model C。
最后Model C再经过RL,这一阶段是全场景的强化学习,包括增加安全性和帮助性,获得最终的R1。但是这个RL过程在技术报告描述得不详细。
R1的技术报告说明,他们试验了过程奖励模型和MCTS等方法,但是都没有效果。
R1的模型蒸馏
R1的训练中,最后使用前述训练过程中的800k的SFT数据来微调了 Qwen 和 Llama 等较小模型,以提升这些模型的推理能力。
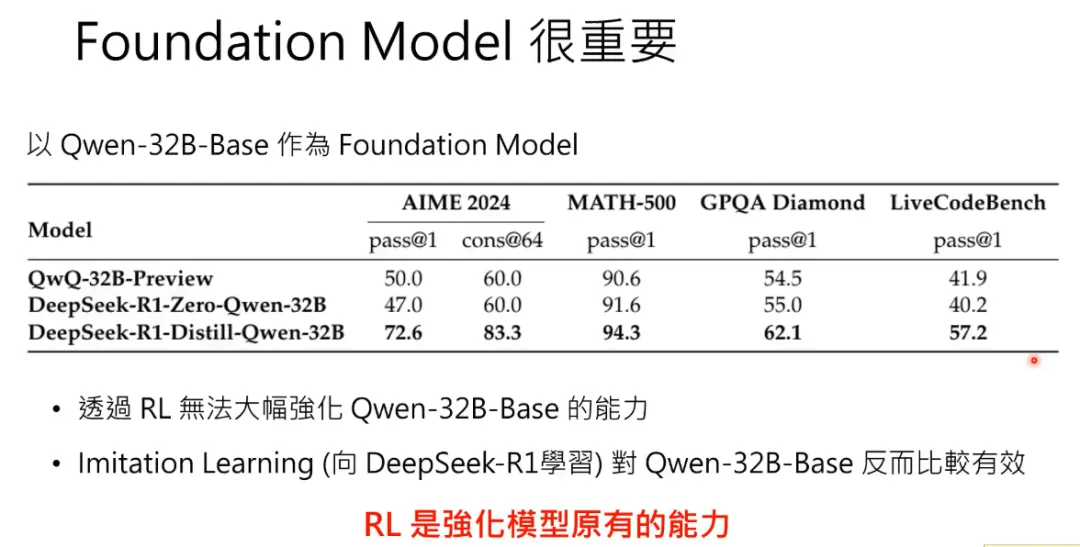
R1的技术报告中说明,对于小模型,采用强化学习没有效果,反而这种蒸馏学习还比较有效。小的模型上使用RL的方法行不通,背后的原因可能是:RL只是强化基础模型的能力,就是说,基础模型作对了,奖励,做错了,惩罚,来强化作对的能力,但是前提是基础模型需要有作对的能力!!
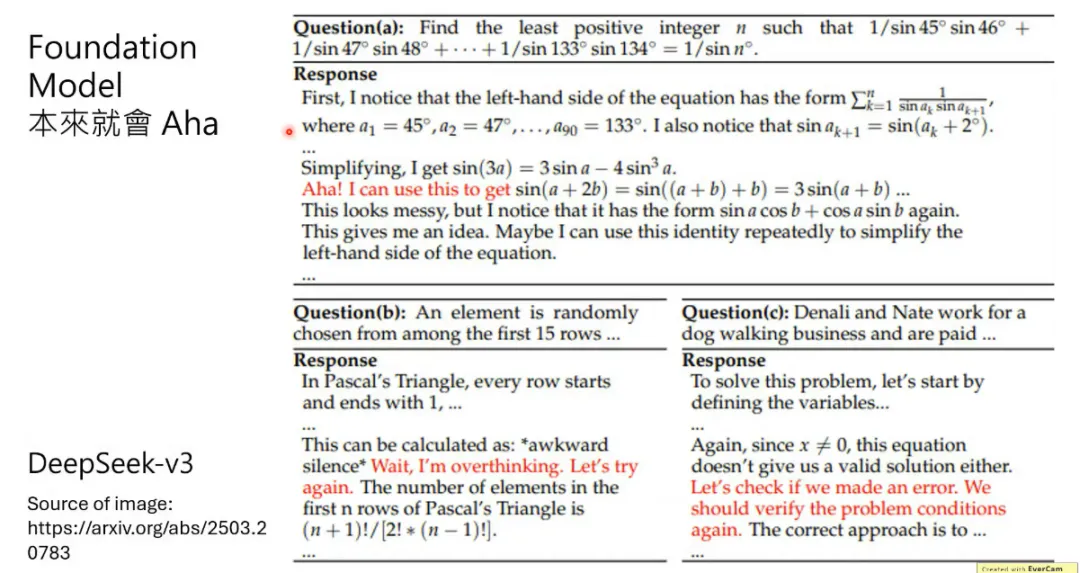
而相关论文就发现,V3本身就有Aha能力,R1只是强化这种能力。
那为什么V3模型本身就有Aha能力。看一下DeepSeek演进路线就知道,V3和R1的发展是相互促进,存在“左脚踩右脚”的关系!
-
R1基于V3-Base模型开发。
-
V3在post training环节使用了R1产生的高质量推理数据,显著提升了V3模型的推理能力。
-
V3在post training环节同样使用了和R1一样的RL策略,提升推理能力并对齐人类偏好。
-
V3/R1的post training环节都使用了V3作为Reward model对非数学编程场景提供反馈。
-
Distilling R1 for V3: Distilling R1可以提升V3的推理能力,但会影响到处理一般问题的能力,增加反应长度,考虑到模型准确性和计算效率,V3主要蒸馏了R1的数学和编程能力。
总结
R1的训练过程,并不是单纯的强化学习,而是多种技术的结合。
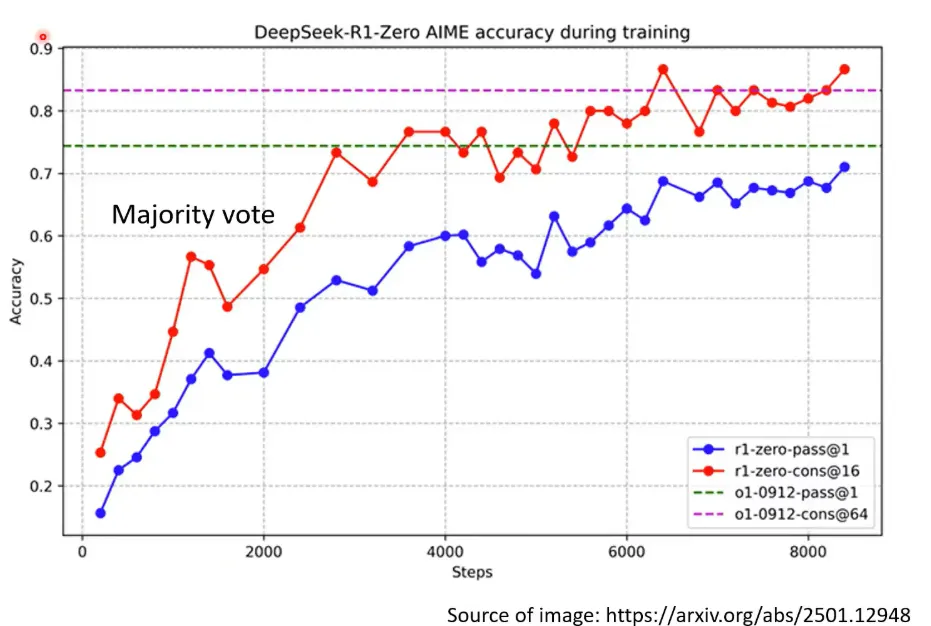
这张图展现了R1推理16次后再通过投票的性能增益,说明,深度思考的几种方法,是可以结合的。