educoder平台课-Python程序设计-6.序列类型
课程来源:头歌实践教学平台
6.1 元组
元组:组合数据类型之一,使用一对圆括号“( )”来存放一组数据,数据项之间用逗号“,”隔开。
元组是序列类型数据的一种,和列表非常相像,可以用来存储一组数据。
输出时,元组都要由圆括号标注,这样才能正确地解释嵌套元组。输入时,圆括号可有可无。
元组和列表最大的区别在于:列表是可变数据类型(mutable),而元组是不可变数据类型(immutable)。 元组数据产生后,其内部元素无法增加、删除和修改,可近似将元组看作为“常量列表”。元组中的每个数据项称为一个元素,各元素类型可以相同,也可以不同,也可以将列表或元组作为元组的元素。
如下例所示:创建的三个元组中,tupa中有5个整型数据,tupb中有4个字符串型数据,tupc中有4个元素,其中包括2个字符串型数据、1个整型数据和1个列表。
tupa = (1, 2, 3, 4, 5)
tupb = ('湖北', '河北', '山东', '山西')
tupc = ('Susan', 'Female', 19, [85, 74, 99, 89, 92])print(tupa)
print(tupb)
print(tupc)
元组是序列类型,因此支持使用切片的方法访问元组中的元素,但不能使用切片的方法修改、增加或删除元组中的元素。
tupa = (1, 2, 3, 4, 5) print(tupa[1:3])
元组切片得到的是一个新的元组,其中的数据也不能被修改和删除。
tupa = (1, 2, 3, 4, 5) tupa[1] = 10 #错误操作,将元组中的元素进行修改会导致TypeError
使用del命令可以删除整个元组,但不能用del删除元组中的元素。
tupa = (1, 2, 3, 4, 5) del tupa #可以删除整个元组 print(tupa) #删除后的元组无法访问,会导致NameError
Python 中有一些针对元组的优化策略,对元组的访问和处理速度远快于列表。当一组数据仅被用于遍历或类似操作,而不进行任何修改操作时,一般建议应用处理速度更快的元组而不用列表。 当程序运行需要的传递参数时,可以使用元组,以避免传递的参数在函数中被修改。
元组的创建有以下几种方法:
- 用一对空的圆括号“()”或无参数的tuple()函数创建一个空元组。例如:()和tuple()
- 只有一个单独元素的元组可以通过在元素后加逗号来构建,例如:a, 或 (a,)
- 用逗号分隔的多个元素,例如:a,b,c 或 (a,b,c)
- 用内置的tuple()函数,参数为空或可迭代对象,例如:tuple() 或 tuple(iterable)。
t1 = (1, 2, 3, 4, 5) # 生成一个元组(1, 2, 3, 4, 5)并赋值给T1 t2 = 1, 2, 3, 4, 5 # 生成一个元组(1, 2, 3, 4, 5)并赋值给T2 print(t1,t2) # t1,t2相同(1, 2, 3, 4, 5) (1, 2, 3, 4, 5) t3 = (1, ) # 生成一个元组(1, ) 并赋值给T3,(1, ) 不同于(1), (1) 相当于整数1 t4 = 1, # 生成一个元组(1, ) 并赋值给T4 print(t3,t4) # t3,t4相同,(1,) (1,) t5 = () # 生成一个空元组 () 并赋值给 T5 t6 = tuple() # 使用元组生成器产生一个空元组赋值给T6 print(t5,t6) # t5,t6相同,() () t7 = tuple([0,1,2]) # 将一个列表转换为元组(1, 2, 3)赋值给T7 t8 = tuple(range(3)) # 将一个可遍历对象转换为元组(0, 1, 2)赋值给T8 print(t7,t8) # t7,t8相同(0, 1, 2) (0, 1, 2)
当元组的元素包含列表等可变元素时,情况有些特殊,虽然不可直接改变元组元素的值,但可以修改作为元素的列表的值。
t = (1,2,[3,4]) t[2][1] = 0 print(t) # 修改元组中列表(1, 2, [3, 0]) t[2].append(10) print(t) # 修改元组中列表(1, 2, [3, 0, 10])
因为元组数据是不可变类型的,使用dir(tuple)或dir(元组名)可以看到,除“魔法方法”外,元组的内置方法非常少,只有两个:count和index,其用法和含义与列表完全相同。
dir(tuple)
区别一个对象是可变类型还是不可变类型,可以通过dir 函数查看其是否有“__hash__”魔法方法,或者说是否可以使用Python内置hash方法对其求“哈希值”。如下示例:
print(hash((1, 2, 3))) # 元组数据可哈希,输出该数据的哈希值 print(hash([1, 2, 3])) # 列表不可哈希,抛出错误TypeError: unhashable type: 'list'
由上例可以看到,元组数据是可哈希的,为不可变数据类型;而列表数据是不可哈希的,为可变数据类型。
在Python中,元组(tuple)在某些情况下比列表(list)有性能优势,但差异可能不显著。
1. 不可变性
元组是不可变的,而列表是可变的。这意味着元组的内容一旦创建就不能改变,因此Python可以对其进行优化,保证其在内存中的存储是连续的。这使得访问元组元素的速度比访问列表元素快。 列表是可变的,需要考虑插入、删除和修改操作,因此在内存中可能不连续存储。
2. 内存效率
由于元组的不可变性,Python可以更高效地管理和存储元组。这主要体现在以下几个方面:
内存分配:元组在创建时一次性分配所需内存,而列表可能需要动态调整其大小,这会增加额外的开销。 内存占用:元组的内存占用通常小于列表,特别是小规模数据时。
3. 哈希值和缓存
元组是不可变对象,可以被用作字典的键或存储在集合中,这要求它们是可哈希的。这些特性允许Python在某些情况下缓存元组,提高访问速度。
4. 操作优化
由于元组的不可变性,Python解释器可以对元组进行更多的优化。例如:
常量折叠:编译时可以将一些操作提前计算和优化。 缓存和引用:在函数调用中使用元组来传递固定数量的参数比使用列表更高效,因为不需要重新分配内存。
虽然元组的访问和处理速度确实通常比列表快,但这主要是由于其不可变性和由此带来的内存和优化优势。在需要频繁修改的数据结构中,列表仍然是更合适的选择。元组适用于需要不可变性和轻量级存储的场景。
6.2 列表
列表(list)是组合数据类型之一,为可变数据类型。用一对方括号“[]”括起来的一组数据,数据项之间用逗号“,”隔开。
列表中的每个数据项称为一个元素,元素的数据类型无限制,各元素类型可以相同,也可以不同,甚至可以将列表或元组作为列表的元素。
lsa = [1, 2, 3, 4, 5] lsb = ['湖北', '河北', '山东', '山西'] lsc = ['Susan', 'Female', 19, [85, 74, 99, 89, 92]] print(lsa, lsb, lsc, sep = '\n')
上面的三个列表中,lsa中有5个整型数据,lsb中有4个字符串型数据,lsc中有4个元素,其中包括2个字符串型数据、1个整型数据和1个列表。
6.3 列表的创建
列表的创建主要有以下几种方法:
(1)将用方括号“[]”括起来的一组数据赋值给一个变量,数据可以是多个,也可以是0个,数据个数为0时创建一个空列表。
(2)使用list()函数,将元组、range对象、字符串、字典的键、集合或其它类型的可迭代对象类型的数据转换为列表,当参数为空时生成一个空列表。
(3)使用split()函数将一个字符串按指定特符切分后,转为列表。
Ls = [3,4,5,6,7]
print(Ls)
print(list()) # list()函数的参数为空时,产生一个空列表,输出结果为:[]
L1= list((1,2,3,4,5)) # 将元组(1,2,3,4,5) 转为列表
print(L1) # 输出结果为:[1, 2, 3, 4, 5]
L2 = list(range(5)) # 将range对象转为列表
print(L2) # 输出结果为:[0, 1, 2, 3, 4]
L3 = list('12345') # 将字符串转为列表
print(L3) # 输出结果为:['1', '2', '3', '4', '5']
s = '我,是,中,国,人' # 这是一个字符串
L = s.split(',') # 根据逗号(,)对字符串s进行切分并转为列表
print(L) # 输出结果为:['我', '是', '中', '国', '人']
由于列表中可以包含不同类型的数据,各元素可能占用空间大小不同,所以在创建列表时,Python采用动态分配的方法进行数据存储,数据存储在大小不一、不连续的内存单元中,以提高内存的利用率。
但随之带来的问题是,当列表中的数据项较多时,遍历列表的效率会较低,遍历时间较长。因此在访问数据量较大的列表时,一般会根据所解决问题的需求来采用适当的方法提高效率,比如减少循环次数,或转换为集合或字典及使用相关方法等等。
6.4 列表的更新
赋值语句是改变对象值的最简单的方法,在列表中,也可以通过索引赋值改变列表中指定序号元素值。
1.索引赋值的方法为:
ls[i] = a
其中i 为列表中的元素序号,要求i为整数且在列表序号范围内(-len(ls) <= i < len(ls)),当i值超出列表序号范围时,抛出错误:IndexError: list assignment index out of range。 a 为新值,其值可以与列表中原有元素的数据类型相同,也可以是不同的数据类型,甚至可以是一个列表或元组。
ls = [88,56,95,46,100,77] # 通过赋值创建列表L ls[2] = 66 print(ls) # 序号为2的元素被替换为66,输出:[88, 56, 66, 46, 100, 77]ls[3] = 'pass' # 序号为3的元素赋字符串类型新值 print(ls) # 序号为3的元素被替换,输出:[88, 56, 66, 'pass', 100, 77]ls[5] = ['True','False'] # 序号为5的元素赋列表类型新值 print(ls) # 序号为5的元素被替换, [88, 56, 66, 'pass', 100, ['True', 'False']]
除了按索引赋值以外,还可以用切片赋值的方法更新列表中的数据,切片赋值要求新值也为列表。
其操作相当于将原列表中切片中元素删除,同时用新的列表中的元素代替切片的位置。
当切片连续时(如ls[i:j]),此时新列表长度不限,可为空列表、与切片等长列表或超出切片长度的列表。
当切片不连续时(如,ls[i:j:step]),要求新列表与切片元素数量相等,再按顺序一一替换。
ls = [88,56,95,46,100,77] # 通过赋值创建列表ls print(ls) # 输出原列表中元素[88, 56, 95, 46, 100, 77]ls[1:3] =[33,44] # 序号为1和2的元素被替换为新列表中的33和44 print(ls) # 输出:[88, 33, 44, 46, 100, 77]ls[1:3] = [] # 序号为1和2的元素被替换为新列表中空值 print(ls) # 输出[88, 46, 100, 77],列表长度减少2ls = [88,56,95,46,100,77] # 通过赋值创建列表ls ls[1:3] =[33,44,55,66] # 序号为1和2的元素被替换为33、44、55、66 print(ls) # 输出[88, 33, 44, 55, 66, 46, 100, 77],列表长度增加2
ls = [88, 56, 95, 46, 100, 77] # 通过赋值创建列表ls print(ls[0:6:2]) # 切片返回结果,3个元素,输出[88, 95, 100]ls[0:6:2] = [10, 20, 30] # 将切片返回的3个元素用新列表中对应位置的元素替代 print(ls) # 输出[10, 56, 20, 46, 30, 77]ls = [88, 56, 95, 46, 100, 77] # 通过赋值创建列表ls ls[0:6:2] = ['Python', 'C语言', 'VB'] # 新列表元素的数据可为任意类型 print(ls) # 输出['Python', 56, 'C语言', 46, 'VB', 77]
如果输出id(ls)查看每次操作前后列表ls的id,可以发现,当列表长度没有增加且新加入的数据类型与原数据类型相同时,更新前后列表的id没有发生变化,也就是说,此时的更新是原地操作。而当更新列表后长度增加的操作,或更新后新加入的数据的类型与原数据类型不同时,更新前后列表的id会发生变化。也就是说,此时的更新是重新创建了新的列表,并将原列表和更新的数据一起放入新列表。
可以这样理解列表被创建后,就不能再往列表中增加元素了,如需增加新的元素,需要将整个列表中的元素复制一遍,再添加需要增加的元素。
2.为了解决这个问题,python提供了三种方法向列表中添加元素:
append()
extend()
insert()
这三种方法都是原地操作,不影响列表在内存中的起始地址。
2.1 append()在列表末尾添加一个元素
append()方法的使用方式为:
ls.append(x) # ls为操作的列表名,x为增加的元素。 # 相当于: a[len(a):] = [x]
ls = [88, 56, 95, 46, 100, 77] # 通过赋值创建列表ls
ls.append(100) # 在原列表末尾增加新元素数字100
print(ls) # 输出[88, 56, 95, 46, 100, 77, 100]ls = [88, 56, 95, 46, 100, 77] # 通过赋值创建列表ls
ls[len(ls):] = [100] # 在原列表末尾增加新元素数字100
print(ls) # 输出[88, 56, 95, 46, 100, 77, 100]ls.append('python') # 在原列表末尾增加新元素字符串'python'
print(ls) # 输出[88, 56, 95, 46, 100, 77, 100, 'python']
如果输出id(ls)可以发现,应用append()方法向列表中增加元素时,可以增加同类型元素,也可以增加不同类型元素,其列表的id不变,说明只是修改了原列表而没有重建列表。
用append()向列表末尾增加元素非常快,此时,列表的作用相当于栈(stack)
2.2 extend()是将另一个可迭代对象转为列表并追加到当前列表的末尾
extend()方法的使用方式为:
ls.extend(iterable) # 相当于: ls[len(ls):] = iterable
ls = [88, 56, 95, 46, 100, 77] L = [10, 20, 30] ls.extend(L) # 在原列表末尾增加新列表中的元素10,20,30 print(ls) # 输出[88, 56, 95, 46, 100, 77, 10, 20, 30]ls = [88, 56, 95, 46, 100, 77] L = [10, 20, 30] ls[len(ls):] = L # 在原列表末尾增加新列表中的元素10,20,30 print(ls) # 输出[88, 56, 95, 46, 100, 77, 10, 20, 30]
ls = [88, 56, 95, 46, 100, 77] ls.extend(range(5)) # 在原列表末尾增加新列表中的元素0, 1, 2, 3, 4 print(ls) # 输出[88, 56, 95, 46, 100, 77, 0, 1, 2, 3, 4]ls = [88, 56, 95, 46, 100, 77] ls[len(ls):] = range(5) # 在原列表末尾增加新列表中的元素0, 1, 2, 3, 4 print(ls) # 输出[88, 56, 95, 46, 100, 77, 0, 1, 2, 3, 4]
与ls.extend(L)功能类似的一个操作是赋值运算+=
ls = [88, 56, 95, 46, 100, 77] L = [10, 20, 30]ls += L # 不创建新对象,在原列表末尾增加新列表中的元素10,20,30 print(ls) # 输出[88, 56, 95, 46, 100, 77, 10, 20, 30]
+=运算符会调用__iadd__方法,该方法的参数类型是可迭代对象(iterable),也就是说,L的类型并不局限于列表,可以是元组、range、字符串、集合和字典等,会先将其它类型的对象转为列表类型,再附加到列表的末尾。
ls = [88, 56, 95, 46, 100, 77]
L1 = {35,65}
L2 = range(10, 30, 10)
L3 = (1, 2, 3)
L4 = "abc"ls += L1 # 不创建新对象,在原列表末尾增加集合中的元素35,65
print(ls) # 输出[88, 56, 95, 46, 100, 77, 35, 65]
ls += L2 # 不创建新对象,在原列表末尾增加新列元素10,20
print(ls) # 输出[88, 56, 95, 46, 100, 77, 35, 65, 10, 20]
ls += L3 # 不创建新对象,在原列表末尾增加新元组中的元素1,2,3
print(ls) # 输出[88, 56, 95, 46, 100, 77, 35, 65, 10, 20, 1, 2, 3]
ls += L4 # 不创建新对象,在原列表末尾增加新字符串中的元素a,b,c
print(ls) # 输出[88, 56, 95, 46, 100, 77, 35, 65, 10, 20, 1, 2, 3, 'a', 'b', 'c']
2.3 insert()是向列表中任意位置插入一个一元素,insert()方法的使用方式为:
ls.insert(i,x)
ls为操作的列表名,i为插入位置的序号,x为增加的元素。
ls.insert(0, x) # 在列表开头插入元素ls.insert(len(ls), x) # 等同于 ls.append(x)
ls = [88,56,95,46,100,77] ls.insert(2,99) # 在序号为2的位置插入新值99 print(ls) # 输出[88, 56, 99, 95, 46, 100, 77]
列表底层是通过变长数组实现的。在数组头部或中间插入或删除元素,需要逐个移动插入位置之后的每个元素。这在数据量大时会消耗大量时间,效率低下。
列表适用于处理动态数据集,特别适合用于读操作远多于写操作的场景。
列表可用来实现栈操作。
列表不适合用作队列,可使用 collections.deque 来实现队列操作。
6.5 列表的删除
列表有3个方法可被用于删除列表中的元素,这三个方法分别为:
pop()
remove()
clear()
下面分别介绍其用法。
(1)pop()方法的使用方式为:
ls.pop([i])
i 两边的方括号表示该参数是可选的,不是要求输入方括号
其中ls为要操作的列表名,i为要删除的列表元素的序号。
ls.pop(i)可用于移除列表中序号为“i”的一个元素,此处i为整数且不超过列表序号范围。
当括号中无参数时,ls.pop()移除列表的最后一个元素。
pop()方法是唯一一个能删除列表元素又能返回值的列表方法,其返回值为被移除的元素。
L = list('7319826540') # 将字符串转为列表L
print(L) # 输出列表元素['7', '3', '1', '9', '8', '2', '6', '5', '4', '0']L.pop() # 移除列表中最后一个元素
print(L) # 输出列表元素['7', '3', '1', '9', '8', '2', '6', '5', '4']s=L.pop() # 移除列表中最后一个元素,并将移除的元素赋值给s
print(L,s) # 输出列表元素及移除的数据['7', '3', '1', '9', '8', '2', '6', '5'] 4L.pop(3) # 移除列表中序号为3的元素
print(L) # 输出列表元素['7', '3', '1', '8', '2', '6', '5']s=L.pop(-3) # 移除列表中序号为3的元素,并将移除的元素赋值给s
print(L,s) # 输出列表元素及被移除的数据['7', '3', '1', '8', '6', '5'] 2
(2)remove()方法的使用方式为:
ls.remove(x)
其中ls为要操作的列表名,x为要删除的数据。
ls.remove(x)方法可用于删除列表中第一个与参数“x”值相同的元素。
列表中存在多个与参数“x”值相同的元素时,只删除第一个,保留其它元素。
当列表中不存在与参数“x”相同的元素时,抛出错误“ValueError: list.remove(x): x not in list”。
L = list('7319826540') # 将字符串转为列表L
print(L) # 输出列表元素['7', '3', '1', '9', '8', '2', '6', '5', '4', '0']L.remove('1') # 删除列表中元素'1'(字符串)
print(L) # 输出修改过的列表['7', '3', '9', '8', '2', '6', '5', '4', '0']
L = list('7319826540') # 将字符串转为列表L
L.remove(1) # 删除列表中元素1(整数)
print(L) # 删除对象在列表中不存在,抛出错误ValueError: list.remove(x): x not in list
为避免触发异常,在使用此方法删除元素前建议先做成员测试:
L = list('7319826540') # 将字符串转为列表L
if 1 in L:L.remove(1) # 若列表中存在整数1,则删除列表中元素1(整数)
print(L) # 查看结果['7', '3', '1', '9', '8', '2', '6', '5', '4', '0']
(3)clear()方法的使用方式为:
ls. clear()
ls. clear()方法可用于删除列表中全部元素,即清空列表。
若L为当前操作的列表,则L.clear()作用与del L[:]相同。
L = list('7319826540') # 将字符串转为列表L
print(L) # 输出列表元素['7', '3', '1', '9', '8', '2', '6', '5', '4', '0']
L.clear() # 删除列表中全部元素
print(L) # 输出修改过的列表[]
L = list('7319826540') # 将字符串转为列表L
del L[:] # 删除列表中全部元素
print(L) # 输出修改过的列表[]
L = list('7319826540') # 将字符串转为列表L
del L # 删除列表对象L
print(L) # NameError: name 'L' is not defined
当一个列表不再使用时,可以del 命令删除列表对象, del命令也可以被用于删除列表中的元素。
ls= list(range(5)) # 将range对象转为列表ls print(ls) # 输出结果为:[0, 1, 2, 3, 4]del ls[1] # 索引,删除列表ls中序号为“1”的元素 print(ls) # 输出结果为:[0, 2, 3, 4]del ls[1:3] # 切片,删除列表对象ls中序号1,2的元素 print(ls) # [0, 4]
ls= list(range(5)) # 将range对象转为列表ls print(ls) # 输出结果为:[0, 1, 2, 3, 4]del ls # 删除列表对象ls print(ls) # 列表ls不存在了,抛出错误, NameError: name 'ls' is not defined。
6.6 列表的排序
python中提供了sort()和reverse()两个方法对列表元素进行排序。
(1)sort()方法
ls.sort(*, key=None, reverse=False)
ls为要排序的列表,ls.sort()方法可以对列表ls中的数据在原地进行排序,默认规则是直接比较元素大小(注意字符串的比较是逐位比较每个字符的大小)。缺省时参数reverse=False,为升序排序;当设置参数reverse=True时,为降序排序。排序后,列表中的元素变为一个有序序列。
L = ['73','13','9','82','6','5','04'] # 通过赋值创建列表L print(L) # 输出列表原始元素['73', '13', '9', '82', '6', '5', '04'] L.sort() # 比较字符串大小,缺省升序排序 print(L) # 输出修改过的列表['04', '13', '5', '6', '73', '82', '9'],字符串'13'< '5' print(L.sort()) # L.sort()无返回值,输出None
ls = [88,56,95,46,100,77] # 通过赋值方式创建列表ls ls.sort(reverse=True) # 比较数字大小,降序排序 print(ls) # 输出修改过的列表[100, 95, 88, 77, 56, 46]
参数key可以指定排序时应用的规则,不影响列表中元素的值。例如:
L = ['app', 'Apple', 'at', 'AM'] L.sort() # 按字符串大小排序,依序比较各字符Unicode值 print(L) # ['AM', 'Apple', 'app', 'at'] # 默认排序规则排序L.sort(key=str.lower) # 按转小写后排序 print(L) # ['AM', 'app', 'Apple', 'at'] # 字符串中的字符按小写顺序排序L.sort(key=lambda x: x.lower()) # 按转小写后排序 print(L) # ['AM', 'app', 'Apple', 'at'] # 字符串中的字符按小写顺序排序L.sort(key=len) # 按字符串长度排序 print(L) # ['AM', 'at', 'app', 'Apple'] # 字符串中的字符按小写顺序排序L.sort(key=lambda x: len(x)) # 按字符串长度排序 print(L) # ['AM', 'at', 'app', 'Apple'] # 字符串中的字符按小写顺序排序
使用的sort方法,不使用key参数时,Python严格按照列表元素中每个数据字符串的ASCII码大小排序,'A' < ‘a’,故所有'A'开头的字符串都在'a'开头的字符串之前。当提供了参数key = str.lower时,Python执行的操作是将key参数得到的str.lower方法,依次应用于列表中的每个数据项,将字符串中所有字符转换为小写字符,并以此结果作为依据,进行统一排序。排序后,列表中的实际数据项仍为原数据项值,并不会受排序参数key得到的函数和方法影响,key参数得到的函数或方法,只作为排序依据使用。
内置排序函数sorted(iterable)可以对可迭代对象进行排序,根据 iterable 中的项返回一个新的已排序列表,创新新的排序后的对象
sorted(iterable, /, *, key=None, reverse=False)
具有两个可选参数,星号*表示它们都必须指定为关键字参数key 指定带有单个参数的函数,用于从 iterable 的每个元素中提取用于比较的键 (例如 key=str.lower)。 默认值为 None (直接比较元素)。
reverse 为一个布尔值。 如果设为 True,则每个列表元素将按反向顺序比较进行排内置的 sorted() 确保是稳定的,如果一个排序确保不会改变比较结果相等的元素的相对顺序就称其为稳定的序。
L = ['app', 'Apple', 'at', 'AM'] print(sorted(L)) # ['AM', 'Apple', 'app', 'at'] 默认排序规则排序 print(sorted(L, key=str.lower)) # ['AM', 'app', 'Apple', 'at'] 字符串中的字符按小写顺序排序 print(sorted(L, key=lambda x: x.lower())) # ['AM', 'app', 'Apple', 'at'] 字符串中的字符按小写顺序排序 print(sorted(L, key=len)) # ['at', 'AM', 'app', 'Apple'] , 字符串中的字符按长度排序 print(sorted(L, key=lambda x: len(x))) # ['at', 'AM', 'app', 'Apple'] 字符串中的字符按长度排序
(2)reverse()方法
ls.reverse()方法的作用是不比较元素大小,直接将列表ls中的元素逆序。
L = ['73','13','9','82','6','5','04'] #通过赋值创建元素为字符串的列表L print(L) # 输出列表原始元素['73', '13', '9', '82', '6', '5', '04'] L.reverse() # 将列表元素逆序 print(L) # 输出修改过的列表['04', '5', '6', '82', '9', '13', '73']ls = [88,56,95,46,100,77] # 通过赋值方式创建元素为整数的列表ls ls.reverse() # 将列表元素逆序 print(ls) # 输出修改过的列表[77, 100, 46, 95, 56, 88]
这两种方法都是原地操作,直接修改了原始的列表中的数据,有时,我们只希望在输出时进行排序或逆序输出,不改变列表中的原始数据的顺序。此时,可以使用Python的内置函数sorted()和reversed()。这两个函数都是只返回排序或逆序的对象的结果,而不对原列表进行任何修改,也就是说,不会改变列表中元素原始的顺序。 注意:使用这两个内置函数时,列表要放在括号中作为函数的参数。reversed(ls)产生的是一个逆序的对象,需要用list()函数将其转为列表才可以输出。
L = ['73','13','9','82','6','5','04'] # 通过赋值创建列表L print(L) # 输出列表原始元素 ['73', '13', '9', '82', '6', '5', '04'] print(sorted(L))# 将列表元素排序输出 ['04', '13', '5', '6', '73', '82', '9'] print(L) # 列表L元素顺序不变 ['73', '13', '9', '82', '6', '5', '04']ls = [88,56,95,46,100,77] # 创建列表ls,值为: [88, 56, 95, 46, 100, 77] print(reversed(ls)) # <list_reverseiterator object at 0x00000126AC5CA6E0>print(list(reversed(ls))) # 将列表元素逆序并转为列表输出 [77, 100, 46, 95, 56, 88] print(ls) # 列表ls元素顺序不变 [88, 56, 95, 46, 100, 77]
练一练
实例 5.1 成绩统计分析 有10名同学的python课程成绩分别为:94, 89, 96, 88, 92, 86, 69, 95, 78, 85,利用列表分析成绩,输出平均值、最高的3个成绩和最低的3个成绩、成绩中位数。 分析: 平均成绩可以将所有成绩加和再除以10获得,最高和最低成绩需要排序后输出前后各3个成绩,中位数也需要先排序再求取。如果原列表顺序不需要保留,可以使用列表的sort()方法进行排序。
# 利用列表存储数据,统计平均成绩、中位数、最高三个成绩和最低三个成绩
scores = [94, 89, 96, 88, 92, 86, 69, 95, 78, 85]
scores.sort() # 对成绩列表排序,默认升序,scores 中原来顺序丢失print(sum(scores)/10) # 利用sum()函数对序列元素求和计算平均成绩
print('最高3个成绩为:', scores[-1: -4: -1]) # 后面3个成绩,步长-1表示逆序
print('最低3个成绩为:', scores[0: 3]) # 前面3个成绩,顺序输出,升序count = len(scores)# 取得成绩个数if count % 2 == 0: # 当列表元素数目为偶数时,中位数为中间两个数据的算术平均数median = (scores[count // 2 -1] + scores[count // 2 ])/2
else: # 当列表元素数目为奇数时,中位数即列表中间的数字median = scores[ count // 2 ]print('成绩中位数是:{:.2f}'.format(median))
print(scores)
# sort()方法使原列表排序发生变化,[69, 78, 85, 86, 88, 89, 92, 94, 95, 96]
很多时候,希望原列表中的顺序可以被保留下来,这时,可以使用Python内置函数sorted()在输出时进行排序:
scores = [94, 89, 96, 88, 92, 86, 69, 95, 78, 85]print(sum(scores)/10)
print('最高3个成绩为:',sorted(scores)[-1: -4: -1])#输出时排序,不影响原列表
print('最低3个成绩为:', sorted(scores)[0: 3])count = len(scores) # 取得成绩个数
if count % 2 == 0: # 当列表元素数目为偶数时,中位数为中间两个数据的算术平均数median = (sorted(scores)[count // 2 -1] + sorted(scores)[count // 2 ])/2
else: # 当列表元素数目为奇数时,中位数即列表中间的数字median = sorted(scores)[ count // 2 ]print('成绩中位数:{:.2f}'.format(median))
print(scores)
# sorted()函数不改变原列表顺序[94, 89, 96, 88, 92, 86, 69, 95, 78, 85]
拓展一下这个问题,当成绩数据保存在文件中时,如何对成绩进行分析? 文件中的数据如下: 王龙 94 张龙 89 梁龙 96 杨林 88 刘雪 92 魏琴 86 杜鑫 69 刘君 95 王娜 78 周华 85 读文件中的数据的应用非常多,可以先将文件中的数据读取为列表形式,再用上述方法对列表中的数据进行分析和统计。
6.1 score.txt
scores = [] # 创建空列表
with open('6.1 score.txt','r',encoding='utf-8') as data:for line in data: # 遍历文件对象line = line.strip() # 去除行末的换行符line = line.split() # 根据空白字符将字符串切分为列表line = int(line[1]) # 索引方法获取列表中序号为1的元素scores.append(line) # 将其转为整数附加到列表末尾
print(scores) # 输出列表
# 字符串的处理方法可以连续使用,上述代码可以简化为下面形式
scores = [] # 创建空列表
with open('6.1 score.txt','r',encoding='utf-8') as data:for line in data: # 遍历文件对象scores.append(int(line.strip().split()[1]))
print(scores) # 输出列表
# [94, 89, 96, 88, 92, 86, 69, 95, 78, 85]
实例 5.2 二维列表的排序 列表score = [[ 'Angle', '0121701100106',99], [ 'Jack', '0121701100107',86], [ 'Tom', '0121701100109',65], [ 'Smith', '0121701100111', 100], ['Bob', '0121701100115',77], ['Lily', '0121701100117', 59]] 每个列表元素的三个数据分别代表姓名、学号和成绩,请分别按姓名、学号和成绩排序输出。 分析:二维列表的排序可以用lambda函数指定排序关键字,而且可以指定多个排序关键字,将用于确定排序的关键字按顺序放在同一个括号中,放于lambda关键字的冒号后面即可。
# 二维列表元素排序以及根据多个字段用不同的排序规则进行排序
score = [[ 'Angle', '0121701100106',99], [ 'Jack', '0121701100107',86], [ 'Tom', '0121701100109',77], [ 'Smith', '0121701100111', 100], ['Bob', '0121701100115',77], ['Lily', '0121701100117', 59]]
print('按姓名排序')
print(sorted(score, key=lambda x:x[0])) # 按元素中序号为0的元素“姓名”排序
print('按学号排序')
print(sorted(score, key=lambda x:x[1])) # 按元素中序号为1的元素“学号”排序
print('优先按成绩排序再按姓名排序')
print(sorted(score, key=lambda x:(x[2],x[0])))
#先按成绩升序排序,成绩相同时再按学号升序排序 6.1 score.txt
元素为字符串的二维列表排序
对列表[('hubei', 'wuhan'), ('hubei', 'huangshi'), ('hubei', 'huanggang'), ('hunan', 'shangsha')]进行排序,先输出默认排序结果;再先按城市名升序排序,城市名相同时按省名升序排序;再先按省名降序排序,省名相同时按城市名升序排序;
对于多个排序关键字都是字符串类型的,排序一个升序一个降序时,可以将字符依次转为unicode编码做排序依据,以值的正负表示降序或升序。
city = [('hubei', 'wuhan'), ('hubei', 'huangshi'), ('hubei', 'huanggang'), ('hunan', 'shangsha')]print(sorted(city))
print(sorted(city, key=lambda x: (x[1], x[0])))
print(sorted(city, key=lambda x: ([-ord(i) for i in x[0]], [ord(i) for i in x[1]])))
6.7 列表的赋值和复制
将一个列表ls直接赋值给另一个变量lsnew时,并不会产生新的对象,只相当于给原列表存储的位置多加了一个标签lsnew,可以同时使用ls和lsnew两个标签访问原列表。当列表ls的值发生变化时,lsnew同时发生变化。
当使用copy()方法复制或用列表切片再赋值时,相当于创建一个新对象,再拷贝数据的一个副本,称为浅复制。新对象与原列表无直接关联,对其中一个操作也不会影响另一个对象。
# 只拷贝第一层的叫浅拷贝,如元素为可变数据类型,只拷贝其首地址,可变数据类型元素值发生变化,会影响用浅拷贝创建的对象。 # 递归拷贝到底的叫深拷贝,拷贝结果完全独立于原对象 import copyls = [2,5,['a',[22,33],'c'],9] # 创建一个对象ls ls1 = ls # ls对象加一个新标签,值随ls变化而变化 ls2 = ls[1:3] # 切片,得到新对象 ls3 = ls.copy() # 产生新对象 ls4 = [x for x in ls] # 列表推导式ls5 = copy.deepcopy(ls) # 产生新对象,递归拷贝ls中所有元素,对象创建后完全独立于ls ls.append(10) # ls 末尾增加一个元素 ls[2][1].append(44) # ls 中序号为2的元素['a',[22,33],'c']中序号为1的元素[22,33]末尾增加一个元素 print(id(ls),id(ls1),id(ls2),id(ls3),id(ls4),id(ls5))print(ls,ls1,ls2,ls3,ls4,ls5)
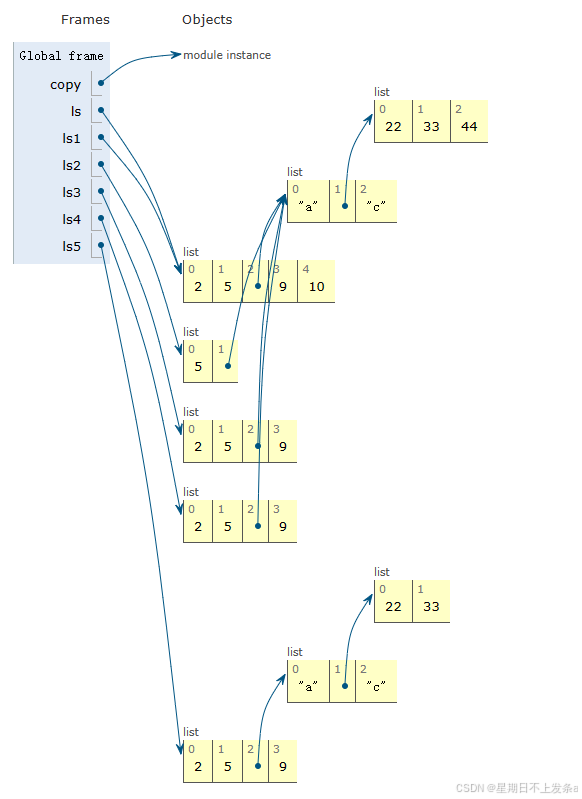
由上例可以看出,ls1和ls的id值相同,表示它们指向同一序列,而ls2、ls3、ls4和ls5的id值各不相同,表明它们指向不同对象。 不同的是,ls5在创建时,递归复制了ls里所有元素,称为深复制,这种方法创建的对象完全独立于原始对象,原始对象的任何变化都不会影响到深复制创建的对象。 ls2、ls3和ls4只复制一层元素,当其中某可变数据类型元素的值发生变化时,ls2、ls3和ls4中对应元素的值也会发生变化。 与字符串一样,当列表乘一个整数n时是一种重复操作,相当于一个id的对象被复制n次。
ls = [[ ]] * 3 # ls[0]被复制3次 print(ls) # [[], [], []] print(id(ls[0]),id(ls[1]),id(ls[2])) # ls[0],ls[1],ls[2]id相同,是同一对象的不同标签 # 输出2438949169160 2438949169160 2438949169160 ls[0].append(3) # 列表ls[0]新增一个元素 print(ls) # [[3], [3], [3]],对象值改变,通过不同标签访问的都是修改过的值 ls[0].append(5) # 列表ls[0]新增一个元素 print(ls) # [[3, 5], [3, 5], [3, 5]],对象值改变,通过不同标签访问的都是修改过的值
严格来说,Python 中赋值语句并不是把对象的值赋给变量名,而是在变量名和对象之间创建绑定关系,或者说给存储在数据起一个名字或加一个标签以方便重复访问。 对于自身可变(如列表)或者包含可变项(如列表做为元素)的集合对象,在程序开发时有时会需要生成其副本用于改变操作,避免改变原对象。copy 模块提供了通用的浅层 (shallow) 复制和深层 (deep)复制操作,语法如下:
copy.copy(x) # 返回 x 的浅层复制。 copy.deepcopy(x[, memo]) # 返回 x 的深层复制。 exception copy.error # 针对模块特定错误引发。
浅层复制和深层复制都会创新一个新的对象,他们之间的区别仅与复合对象 (即包含其他对象的对象,如列表或类的实例) 相关: ● 一个浅层复制会构造一个新的复合对象,然后(在可能的范围内)将原对象中找到的引用插入其中。 ● 一个深层复制会构造一个新的复合对象,然后递归地将原始对象中所找到的对象的副本插入。
import copy ls = [1,2,'123',[4,5,(7,8,[9,10])]] ls2 = copy.copy(ls) ls3 = copy.deepcopy(ls)
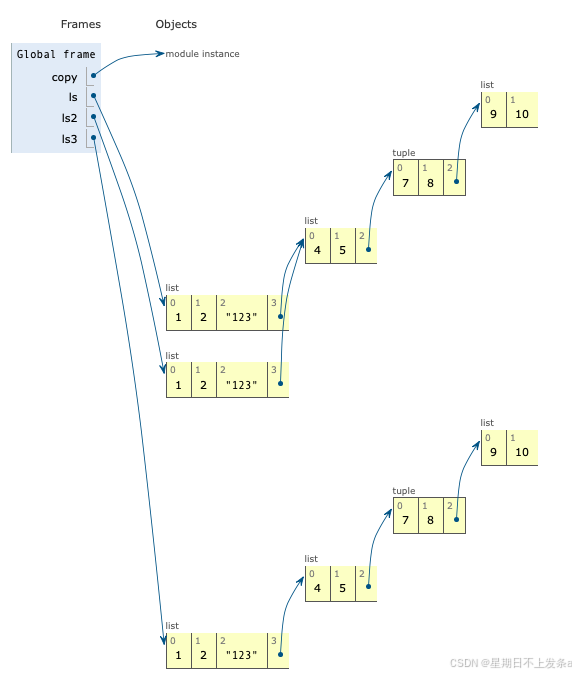
深度复制操作通常存在两个问题, 而浅层复制操作并不存在这些问题:
- 递归对象 (直接或间接包含对自身引用的复合对象) 可能会导致递归循环。
- 由于深层复制会复制所有内容,因此可能会过多复制(例如本应该在副本之间共享的数据)。
deepcopy() 函数通过以下操作避免这些问题:
- 保留在当前复制过程中已复制的对象的 "备忘录" (memo) 字典;
- 允许用户定义的类重载复制操作或复制的组件集合。 该模块不复制模块、方法、栈追踪(stack trace)、栈帧(stack frame)、文件、套接字、窗口、数组以及任何类似的类型。
它通过不改变地返回原始对象来(浅层或深层地)“复制”函数和类;这与 pickle 模块处理这类问题的方式是相似的。 制作字典的浅层复制可以使用 dict.copy() 方法,而制作列表的浅层复制可以通过赋值整个列表的切片完成,例如:
copied_list = original_list[:]
类可以使用与控制序列化(pickling)操作相同的接口来控制复制操作,关于这些方法的描述信息可参考 pickle模块。实际上,copy 模块使用的正是从 copyreg 模块中注册的 pickle 函数。 想要给一个类定义它自己的拷贝操作实现,可以通过定义特殊方法 copy() 和 deepcopy()。 调用前者以实现浅层拷贝操作,该方法不用传入额外参数。 调用后者以实现深层拷贝操作;它应传入一个参数即 memo字典。 如果 deepcopy() 实现需要创建一个组件的深层拷贝,它应当调用 deepcopy() 函数并以该组件作为第一个参数,而将 memo 字典作为第二个参数。
# 以下两种方法都可以获得包含以3个空列表为元素的列表 lists = [[]] * 3 print(lists) # [[], [], []]ls = [[] for i in range(3)] print(ls) # [[], [], []]
从图中可以看到,lists的三个元素引用自同一个对象,是重复引用。而ls中的3个元素是分3次创建的3个空列表,是3个独立的对象。两个列表虽然看似相同,但包含的对象数量是不同的。
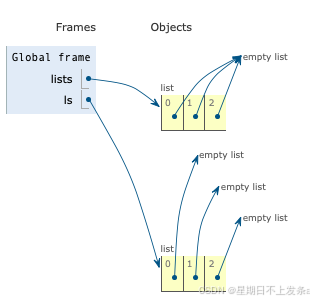
# 以下两种方法都可以获得包含以3个空列表为元素的列表 lists = [[]] * 3 lists[0].append(3) print(lists) # [[3], [3], [3]] # 上述代码中3个元素中由lists[0]重复得到,都引用自lists[0],是同一个对象。 # 当这个对象的改变时,引用这个对象的所有名字的值也会发生相应的变化ls = [[] for i in range(3)] ls[0].append(3) ls[1].append(5) ls[2].append(7) print(ls) # [[3], [5], [7]]
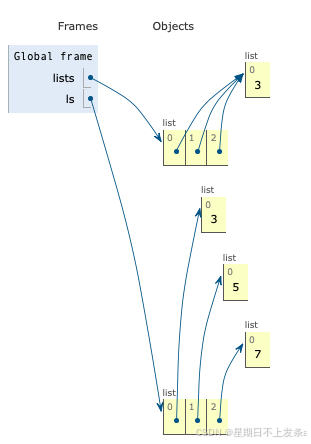
lists中的三个空列表是同一个对象的3次引用,所以改变其中一个值的时候,3个元素的值同时发生了变化。而ls中的三个空列表是3个独立的对象,改变列表的值的时候,相互之间无影响。
# 以下两种方法都可以获得包含以3个空列表为元素的列表 lists = [[]] * 3 lists[0].append(3) lists[1].append(6) lists[2].append(9) print(lists) # [[3, 6, 9], [3, 6, 9], [3, 6, 9]] # 上述代码中3个元素中由lists[0]重复得到,都引用自lists[0],是同一个对象。 # 当这个对象的改变时,引用这个对象的所有名字的值也会发生相应的变化ls = [[] for i in range(3)] ls[0].append(3) ls[1].append(5) ls[2].append(7) print(ls) # [[3], [5], [7]]
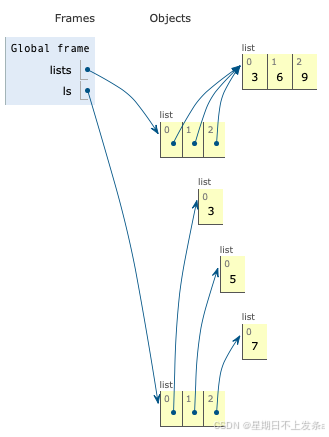
6.8 推导式
推导式(comprehensions)又称解析式,可以从一个数据序列构建另一个新的数据序列的结构体。 推导式是Python的一种独有特性,本质上可以将其理解成一种集合了变换和筛选功能的函数,通过这个函数把一个序列转换成另一个序列。
共有三种推导式:
列表(list)推导式
字典(dict)推导式
集合(set)推导式
本节学习列表推导式。 列表推导式是一种创建新列表的便捷的方式,通常用于根据一个列表中的每个元素通过某种运算或筛选得到另外一系列新数据,创建一个新列表。
列表推导式由1个表达式跟一个或多个for从句、0个或多个if从句构成。 for前面是一个表达式,in 后面是一个列表或能生成列表的对象。将in后面列表中的每一个数据作为for前面表达式的参数,再将计算得到的序列转成列表。if是一个条件从句,可以根据条件返回新列表。
例如,计算0-9中每个数的平方,存储于列表中输出,可以用以下方法实现:
squares = [] # 创建空列表squares for x in range(10): # x依次取0-10中的数字squares.append(x**2) # 向列表中增加x的平方 print(squares) # 输出列表squares,[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]#用lambda函数实现,将0-9中每个数映射为其平方并转为列表 squares = list(map(lambda x: x**2, range(10))) print(squares) # 输出列表squares,[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
也可以用列表推导式来实现:
squares = [x**2 for x in range(10)]#计算range(10)中每个数的平方,推导出新列表 print(squares) # 输出新列表squares,[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
[x ** 2 for x in range(10)]是一个列表推导式,推导式生成的序列放在列表中,for从句前面是一个表达式,in后面是一个列表或能生成列表的对象。将in后面列表中的每一个数据作为for前面表达式的参数,再将计算得到的序列转成列表。可以发现,用列表推导式实现的代码更简洁。
for前面也可以是一个内置函数或自定义函数,例如:
def fun(x):return x + x ** 2 + x ** 3 # 返回x + x ** 2 + x ** 3y = [fun(i) for i in range(10)] # 列表推导式,按函数fun(x),推导出新列表 print(y) # 输出列表[0, 3, 14, 39, 84, 155, 258, 399, 584, 819]
列表推导式还可以用条件语句(if从句)对数据进行过滤,用符合特定条件的数据推导出新列表,例如:
def fun(x):return x + x**2 + x ** 3 # 返回x + x ** 2 + x ** 3# 列表推导式,根据原列表中的偶数,推导新列表 y = [fun(i) for i in range(10) if i%2 is 0] print(y) # 输出列表[0, 14, 84, 258, 584]
可以用多个for从句对多个变量进行计算,例如:
ls = [(x, y) for x in [1,2,3] for y in [3,1,4] if x != y] print(ls) # 输出[(1, 3), (1, 4), (2, 3), (2, 1), (2, 4), (3, 1), (3, 4)]
in 后面也可以直接是一个列表,例如:
ls = [-4, -2, 0, 2, 4] print([x*2 for x in ls])# 将原列表每个数字乘2,推导出新列表 [-8, -4, 0, 4, 8] print([x for x in ls if x >= 0]) # 过滤列表,返回只包含正数的列表[0, 2, 4] print([abs(x) for x in ls]) # 应用abs()函数推导新列表[4, 2, 0, 2, 4] # 调用strip()方法去除每个元素前后的空字符,返回['banana', 'apple', 'pear'] freshfruit = [' banana', ' apple ', 'pear '] print([fruit.strip() for fruit in freshfruit]) # # 生成一个每个元素及其平方(number, square)构成的元组组成的列表 print([(x, x**2) for x in range(6)]) # [(0, 0), (1, 1), (2, 4), (3, 9), (4, 16), (5, 25)]
车牌限行是看尾号单双,末尾为字母时看倒数第一个非字母的数字:
# 鄂A.27F37
# 鄂A.2737F
license_plate = input()# 鄂A.27F37->2737
license_plate_int = int(''.join([x for x in license_plate if x.isdigit()]))
if license_plate_int % 2 == 0:print('限行')
else:print('允许通行')
将列表中的0移到列表末尾
ls = [1,4,5,0,7,0,4,0,9] ls_new = [x for x in ls if x]+[x for x in ls if not x] print(ls_new) # [1, 4, 5, 7, 4, 9, 0, 0, 0]print(sorted(ls,key=lambda x:(x==0))) # x!=0的元素值为False(0),排在前面;x==0的元素值是True(1),排在后面
将列表中的奇偶分开
ls = [1,4,5,0,7,0,4,0,9] odd = [x for x in ls if x%2] even = [x for x in ls if not x%2] print(odd,even) # [1, 5, 7, 9] [4, 0, 0, 4, 0]# 奇数位是奇数,偶数位是偶数 print([x for y in zip(odd,even) for x in y]) # [1, 4, 5, 0, 7, 0, 9, 4]
嵌套的列表推导式:
zip(odd, even)将两个列表配对,生成元组序列:(1,4), (5,0), (7,0), (9,4)- 注意:
even列表比odd多一个元素(5个 vs 4个),所以最后一个even元素0被忽略了
- 注意:
- 对于每个元组
y,再遍历其中的元素x,即先取元组的第一个元素,再取第二个元素
用列表推导式写水仙花数
# 用列表推导式写水仙花数 print(*[i for i in range(100, 1000) if i == sum([int(j) ** 3 for j in str(i)])])
葡萄酒数据分析: /data/bigfiles/winemag-data.csv
# 先得到二维列表 [[0, 'Italy', "Aromas include tropical fruit, broom, brimstone and dried herb. The palate isn't overly expressive, offering unripened apple, citrus and dried sage alongside brisk acidity.", 87, 13.0, 'Sicily & Sardinia'], [10, 'US', 'Soft, supple plum envelopes an oaky structure in this Cabernet, supported by 15% Merlot. Coffee and chocolate complete the picture, finishing strong at the end, resulting in a value-priced wine of attractive flavor and immediate accessibility.', 87, 19.0, 'California'], [20, 'US', 'Ripe aromas of dark berries mingle with ample notes of black pepper, toasted vanilla and dusty tobacco. The palate is oak-driven in nature, but notes of tart red currant shine through, offering a bit of levity.', 87, 23.0, 'Virginia'], [30, 'France', 'Red cherry fruit comes laced with light tannins, giving this bright wine an open, juicy character.', 86, 15.0, 'Beaujolais'], [40, 'Italy', "Catarratto is one of Sicily's most widely farmed white grape varieties. This expression shows a mineral note, backed by citrus and almond blossom touches.", 86, 17.0, 'Sicily & Sardinia'],[50, 'Italy', "This blend of Nero d'Avola and Syrah opens with savory aromas of cured meat, dried berry, cassis, tobacco and wet earth. There's a touch of almond bitterness on the finish.", 86, 15.0, 'Sicily & Sardinia'], [60, 'US', 'Syrupy and dense, this wine is jammy in plum and vanilla, with indeterminate structure and plenty of oak. Ripe and full-bodied, it has accents of graphite and leather.', 86, 100.0, 'California'], [70, 'US', 'Aromas of vanilla, char and toast lead to light creamy stone fruit and canned-corn flavors. It provides appeal but the oak seems overweighted.', 86, 12.0, 'Washington'],[80, 'Chile', 'Caramelized oak and vanilla aromas are front and center on a barrel-heavy nose. This feels a bit choppy, with astringent tannins. Herbal salty plum flavors wear a lot of oaky makeup, while this finishes with a forced woody flavor.', 86, 12.0, 'Rapel Valley'], [90, 'US', "This blend of Sangiovese, Malbec, Cabernet Sauvignon, Petite Sirah and other varieties plays well to type. It shows a wealth of ripe, dusty black fruit that's richly round and soft on the palate, approachable and lightly oaked.", 88, 23.0, 'California'] ]
import pandas as pd
import mathdf = pd.read_csv('/data/bigfiles/winemag-data.csv')
wine_ls = df.values.tolist() # 得到数据的二维列表
# print(wine_ls[:3]) # 查看二维列表# 1. 用列表推导式,得到所有的国家列表
countries = [i[1] for i in wine_ls] # 得到国家的列表
print(countries[:10]) # 查看列表前10个元素
print(set(countries)) # 去掉列表中的重复元素,返回集合
print(sorted(set(countries))) # 对集合中的元素进行排序,输出排序列表# 2. 用列表推导式,得到所有的酒的评分的平均分
points = [i[3] for i in wine_ls if not math.isnan(i[3])] # 得到所有非缺失值的酒的评分列表
print(sum(points) / len(points))# 3. 用列表推导式,得到所有的酒的价格的平均价
prices = [i[4] for i in wine_ls if not math.isnan(i[4])] # 得到所有非缺失值的酒的价格列表
print(sum(prices) / len(prices))
练一练
实例 6.2 中读取文件中数据到列表的操作用列表推导式来实现会变得更为简洁。
scores = [] # 创建空列表
with open('5.1 score.txt','r',encoding='utf-8') as data:for line in data: # 遍历文件对象scores.append(int(line.strip().split()[1]))
print(scores) # 输出列表# 列表推导式实现
with open('5.1 score.txt','r',encoding='utf-8') as data:scores = [int(line.strip().split()[1]) for line in data]
print(scores) # 输出列表
实例 6.3 自幂数
自幂数是指一个 n 位数,它的每个位上的数字的 n 次幂之和等于它本身,例如:153 = 13 + 53 + 33,称153是自幂数。 n为1时,自幂数称为独身数。显然0,1,2,3,4,5,6,7,8,9都是自幂数。 n为 2时,没有自幂数。 n为 3时,自幂数称为水仙花数,有4个 n为 4时,自幂数称为四叶玫瑰数,共有3个 n为 5时,自幂数称为五角星数,共有3个 n为 6时,自幂数称为六合数, 只有1个 n为 7时,自幂数称为北斗七星数, 共有4个 n为 8时,自幂数称为八仙数, 共有3个 n为 9时,自幂数称为九九重阳数,共有4个 n为10时,自幂数称为十全十美数,只有1个 编程寻找并输出n位的自幂数,n由用户输入,每行输出一个数字。
# 方法一 n = int(input()) for num in range(10**(n-1),10**n): # 遍历所有n位数sumOfnum = 0for i in str(num): # num转为字符串,对其中的数字进行遍历,i为字符串sumOfnum = sumOfnum + int(i) ** n # i转整数,计算其n次方累加if sumOfnum == num: # 若累加和与num值相同,是素数print(num) # 输出找到的素数
程序中对 num 中每位上的数字的 n 次方求和使用了三条语句,判断是否相等一条语句,这四条语句可以用列表推导式简化为一条语句实现: if num == sum([int(i) ** n for i in str(num)]): 其中:列表推导式 [int(i) ** n for i in str(num)] 得到的是num中每位上的数字的 n 次方的列表,sum()函数可以对列表中可计算元素求和。 在寻找水仙花数时,每次循环都要计算数中每位上的数字的 n次方,当 n 较大时,这个计算量是相当大的。为了减少时间开销,可以计算 0-9 中每个数的 n 次方存放在一个列表中,需要时,用索引的方法从中取 n 次方的计算结果直接用于计算,可以减少很多次幂运算,这个方法相对于其他方法可以减少约 50% 的时间开销。
# 方法二 n = int(input()) ls = [x ** n for x in range(10)] # 推导出0-9中每个数的n次方存于列表 for num in range(10 ** (n - 1),10 ** n): # 遍历所有n位数if num == sum([ls[int(i)] for i in str(num)]): print(num) # 输出找到的素数
例如计算三位自幂数时,先用列表推导式得到一个包含0-9的3次方的一个列表[0, 1, 8, 27, 64, 125, 216, 343, 512, 729]。再判断100-999范围内每个数是否为自幂数时,str(num)把数字转为字符串,根据这个字符串序列推导出一个新列表,新列表中的元素为字符串中字符对应的整数的n次方。例如判断371时,将其转为字串’371’, '3','7','1' 这3个元素分别对应于列表ls中的27、343和1,从而产生新的列表[27,343,1],再用sum()函数对其求和并比较是否等于371,如果相等,可判定该数为自幂数。
星号(*)在函数调用或打印语句中有特殊用途,主要用于解包(unpack)可迭代对象
def isNarcissus(num):"""接收一个n位正整数为参数,判定其各位上数字的n次方的和是否与该数相等,返回布尔值"""return num == sum([int(i) ** len(str(num)) for i in str(num)])print(*[i for i in range(10, 100000) if isNarcissus(i)]) # 153 370 371 407 1634 8208 9474
两次利用列表推导式用一条语句实现
print(*[num for num in range(10, 100000) if num == sum([int(i) ** len(str(num)) for i in str(num)])])
用一条语句输出素数:
print(*[x for x in range(2, int(input())) if not [y for y in range(2, x) if x % y == 0]])
通过列表推导式可以创建一个列表。但是,创建一个包含很多个元素的列表,会占用很大的存储空间,如果仅仅需要访问前面几个元素,那后面绝大多数元素占用的空间都白白浪费了。 所以,如果列表元素可以按照某种算法循环推算出来,那就不必创建完整的列表,从而节省大量的空间。在Python中,这种一边循环一边计算的机制,称为生成器(Generator)。生成器推导式的结果是一个生成器对象,不是列表也不是元组。 生成器对象可以用next()方法或 next()函数进行遍历,也可以将其作为迭代器对象使用。不管用哪种方法访问其中的元素,当所有元素访问结束以后,对象会变空。如果需要重新访问其中的元素,必须重新创建该生成器对象。 创建生成器有很多种方法,一个简单的方法是把一个列表推导式的[]改成(),就创建了一个生成器。
g = ( i ** 3 for i in range(11)) print(type(g)) # <class 'generator'>,g的数据类型为生成器 print(g) # g是生成器对象,<generator object <genexpr> at 0x00000202A663DC00> print(list(g))# 转为列表可输出[0, 1, 8, 27, 64, 125, 216, 343, 512, 729, 1000] print(list(g)) # 生成器对象被遍历后会变成空 []g = ( i ** 3 for i in range(11)) # 重新创建生成器对象
- 这里创建了一个生成器对象
g,它会生成0到10(包括0,不包括11)的每个数字的立方。 - 生成器表达式
(i ** 3 for i in range(11))与列表推导式类似,但使用圆括号()而不是方括号[],表示这是一个生成器而不是列表。 - 生成器是惰性求值的,意味着它不会立即计算所有值,而是在需要时逐个产生。
print(next(g)) # 输出 0
next(g)从生成器g中获取下一个值。- 第一次调用会计算
0 ** 3,结果是0。
print(g.__next__()) # 输出 1。g.__next__()是next(g)另一种写法功能完全相同 print(next(g)) # 输出 8 print(list(g)) # list(g)将生成器g中剩余的所有值转换为列表 输出[ 27, 64, 125, 216, 343, 512, 729, 1000]
可以看出,g是一个生成器对象,也是一个可遍历对象,无法直接使用print函数打印出它的值,可以在循环中作为可遍历对象使用,也可以用list()或tuple()生成器把它转换成列表或元组显示出来。 生成器对于生成大量的可遍历数据非常有效,并且可以大大提高程序对于内存的使用效率。
6.9 常用内置函数
Python有很多内置函数可以非常方便的解决一些问题,本节给出其中三个在列表中使用较多的内置函数:
map() zip() enumerate()
map()函数可以将函数作用于可迭代对象中的每一个元素,返回一个可迭代对象。常用于将一个序列映射为另一种数据类型的序列。语法如下:
map(function, iterable, ...)
第一个参数是一个函数,如int,float,str等
第二个参数量是一个可迭代对象,如列表等 示例如下所示:
s= ['1','2','3']
print(map(int,s))
# 输出一个可迭代对象 <map object at 0x000002700724EEB8>
print(list(map(int,s))) # 用list()可将其转为列表输出 [1, 2, 3]
print(list(map(float,range(5)))) # 整数序列映射为浮点数序列并转为列表
# 输出[0.0, 1.0, 2.0, 3.0, 4.0]
print(list(map(str,range(5)))) # 整数序列映射为字符串序列并转为列表
# 输出['0', '1', '2', '3', '4']
print('+'.join(map(str,range(5)))) # 整数序列映射为字符串序列并用‘+’连接
# 输出 0+1+2+3+4
print(''.join(map(str,range(5)))) # 整数序列映射为字符串序列并用空字符串连接
# 输出 01234
m,n = map(int,input().split())
# 将在一行中输入的用空格分隔2个数据切分开,转为整型,分别赋值给m,n
print(pow(2,64)) # 结果为数字18446744073709551616
print(str(pow(2,64))) # 结果为字符串'18446744073709551616'
print(map(int,str(pow(2,64))))# 可迭代对象<map object at 0x000001A4A11DEEB8>
print(sum(map(int,str(pow(2,64))))) # 输出2的64次方结果每位上的数加和 88
zip函数可以组合多个可遍历对象,生成一个zip生成器,其语法为:
zip(iter1[, iter2 […]])
iter1、iter2…都是可遍历对象。
采用惰性求值的方式,可以按需要生成一系列元组数据,第i元组数据依次为每个可遍历对象的第i个元素组成的元组,直到所有可遍历对象中最短的元组最后一个元素组成的元组为止。
zip是生成器对象,需要查看其中的数据时,可以用list()函数将其转为列表。 示例如下所示:
x = (1,2,3) y = (4,5,6) z = zip(x,y) # 惰性求值,生成zip对象,可用list转为列表输出 print(list(z)) # [(1, 4), (2, 5), (3, 6)] a = [1,2,3] # 列表a最短,生成元组个数与a长度相同,其他列表中多余元素被丢弃 b = [11,22,33,44] c = [111,222,333,444] z = zip(a,b,c) # 惰性求值,生成zip对象,可用list转为列表输出 print(list(z)) # [(1, 11, 111), (2, 22, 222), (3, 33, 333)]
enumerate函数可以使用一个可遍历对象生成一个enumerate生成器,其语法为:
enumerate(iter[, start])
iter为可遍历对象,start表示序号的起始值。 其采用惰性求值的方式,可以按需要生成一系列两个元素组成的元组数据,第一个元素是以start为起始的一个整数(默认start值为0),第二个元素则是iter可遍历对象的数据元素。
简单的说,就是生成一个新的可遍历序列,给原来iter的每个值对应的增添了一个序号数据,示例如下所示:
a = ['apple', 'banana', 'cherry'] E = enumerate(a) # 生成enumerate对象 print(list(E)) # [(0, 'apple'), (1, 'banana'), (2, 'cherry')]
可以看出,列表a中的所有数据元素都添加了一个序号,形成一个元组,最后构成了enumerate生成器,其也是惰性求值的方式生成数据。
实例5.4 蒙特卡洛方法计算圆周率
利用列表推导式和zip()函数,用蒙特卡洛方法计算圆周率。
分析:
random.random()可以生成一个[0.0, 1.0]之间的数,利用列表推导式可以生成一批数据。
利用zip()函数将两组这样的数合并成一组坐标。
再判断其是否落在圆内,根据落在圆内的点的数量与总数量的比值得到面积
再由面积公式便可计算出圆周率的值。
# 利用列表推导式和zip()函数,用蒙特卡洛方法计算圆周率
import randomN = 100000
lsx = [random.random() for i in range(N)] # 列表推导式随机生成N个小数
lsy = [random.random() for i in range(N)] # 列表推导式随机生成N个小数
# 用zip函数将两个列表中对应序号的数据组成N对坐标值,用list()将其转为列表
ls = list(zip(lsx,lsy))
count = 0
for item in ls:if item[0]**2+item[1]**2<=1: # 判断坐标点是否落在圆内count=count + 1 # 落在圆内的点数量增加 1
PI = 4 * count/N # 计算圆周率值
print('{:.6f}'.format(PI)) # 输出结果3.141880(每次运行结果可能不同)
- 考虑一个单位圆(半径为1的圆)和包围它的单位正方形(边长为2,从(-1,-1)到(1,1))。
- 单位圆的面积是π(因为圆的面积公式是πr²,这里r=1)。
- 单位正方形的面积是4(因为边长为2,面积是2×2=4)。
6.10 列表嵌套及排序
Python中列表中的元素可以仍然是列表,如果一个列表中的每个元素都仍然是列表的话,就构成了列表嵌套。例如:
scores = [['罗明', 95], ['金川', 85], ['戈扬', 80], ['罗旋', 78], ['蒋维', 99]]
scores被称为一个二维列表,它的每一个元素都仍是一个列表,这时仍然可以用索引和切片的方法对其进行访问和操作。
每多一层嵌套,索引时就用多一组方括号。
scores = [['罗明', 95], ['金川', 85], ['戈扬', 80], ['罗旋', 78], ['蒋维', 99]] print(scores[1]) # 输出['金川', 85],这是列表scores的序号为1的元素 print(scores[3:5]) # 输出序号为3和4的[['罗旋', 78], ['蒋维', 99]] print(scores[1][0]) #'金川'这是列表scores的序号为1的元素['金川', 85]中,序号为0的元素print(scores[1][1]) # 85,这是列表scores的序号为1的元素['金川', 85]中,序号为1的元素for ls in scores:print(ls,end = ' ') # ['罗明', 95] ['金川', 85] ['戈扬', 80] ['罗旋', 78] ['蒋维', 99] print()for ls in scores:print(ls[1],end = ' ') # 输出每个元素中序号为1的元素,95 85 80 78 99
处理数据文件时,经常用遍历的方法,利用split()函数将每行数据转为一个列表,并做为列表的一个元素,整个文件被读取后,以一个二维列表的形式存在,可以利用索引和切片等方法,方便的对其中的数据进行分析和处理。
实例 6.5 成绩统计分析进阶
现在一个包含若干学生学习成绩的文件,每位同学有4门课程的成绩,按要求完成以下任务。
文件中每行数据格式如下:
0121801101266,刘雯,92,73,72,64 0121801101077,张佳喜,81,97,61,98 … 0121801101531,佘玉龙,73,89,81,93
读取附件文件中的数据,对数据进行处理,计算每个同学4门课程成绩的平均成绩,将平均成绩置于课程成绩后一列,按照平均分升序排序后输出。
根据以下输入要求,输出相应的数据: 输出平均分最高的同学名字与平均成绩,名字与分数间用一个空格分隔;
输出平均分最低的同学名字与平均成绩,名字与分数间用一个空格分隔;
输出按平均分从低到高的排序数据,要求每个数据之间以空格间隔,每行结尾无空格。
输入一个学生的名字,输出该名同学所在行的的全部数据,各数据项间用一个空格分隔,结尾无空格;
如输入的姓名在文件中不存在,输出 '姓名不存在'
分析:可以使用列表推导式将文件中的数据转为一个二维列表:
with open('5.5 score.txt','r',encoding='utf-8') as f:
ls = [i.strip().split(',') for i in f]
print(ls)
查看一下列表中的数据:
[['0121801101266', '刘雯', '92', '73', '72', '64'], ['0121801101077', '张佳喜', '81', '97', '61', '98'], … ['0121801101531', '佘玉龙', '73', '89', '81', '93']]
查看读取结果,发现所有数据都是字符串类型,如需用于数学运算,需将参与运算的数据转为整数。
此例中可用map(int,x[2:])函数将列表中的成绩数据映射为整型,对映射结果用sum()函数求和再除以课程数量,即成绩列表的长度,即可得到4门课程的平均成绩。
方法如下:
sum(map(int,x[2:]))/len(x[2:])
用列表推导式推导出每位同学的平均成绩,用拼接方法(+)为列表增加一个元素:
score = [x + [sum(map(int,x[2:]))/len(x[2:])] for x in ls]
嵌套的二维列表排序可以应用lambda函数实现,语法为:
sort(key=lambda x:x[n], reverse=True)
key参数为lambda函数(lambda x:x[n]),其中x 为传入的元素,此例中为内层的列表;
x[n] 为排序关键字,此例中为内层列表中序号为n 的元素。
参数x可以是任意变量名,x[i]表示lambda函数返回列表中元素列表的第i个元素,此题中i值为1,表示根据列表中序号为1的元素(成绩)进行排序。
6.5 score.txt
!tar -xvf /data/bigfiles/ff92753b-ab25-4cf4-aefb-74823baeccf1.tar
with open('/data/bigfiles/c41b1db1-faff-4f0e-a5ef-f85b4e68e3dc.txt','r',encoding='utf-8') as f:ls = [i.strip().split(',') for i in f] # 文件中的数据转为二维列表# 计算平均成绩并加到每个列表元素中
score = [x + [sum(map(int,x[2:]))/len(x[2:])] for x in ls] score.sort(key = lambda x:x[6]) # 根据序列为6的元素(平均成绩)升序排序# 输出排序后的最后一个列表元素中姓名和平均成绩,即平均分最高的数据
print(score[-1][1],score[-1][-1]) # 输出排序后的第一个列表元素中姓名和平均成绩,即平均分最低的数据
print(score[0][1],score[0][-1]) # 输出增加了平均成绩并排序后的数据,*表示解包输出,也可用循环方式输出
[print(*x) for x in score] # 输入一个学生的名字,输出其全部信息,如姓名不存在,输出“姓名不存在”
name = input() # 输入一个同学的名字
if name in [x[1] for x in score]: # 如果名字在列表中存在[print(*x) for x in score if x[1] == name] # 输出该同学的成绩数据
else:print('姓名不存在')
6.11 pandas读写数据
列表类型经常被用于数据处理,而数据的存在形式主要有两种,一种是文件形式,一种是数据库形式。对于文本文件中数据,可以用遍历的方法简单的读取,对于其他格式的数据文件或存储在数据库中的数据,可以借助Pandas库来读取。
Pandas是基于Numpy的一个开源库,提供了高性能和高可用性的数据结构用于解决数据分析问题,他纳入了大量的库和一些标准的数据模型,提供了可用于高效操作大型数据集的工具,是使Python成为强大而高效的数据分析工具的重要因素之一。
Pandas兼容所有Python的数据类型,除此外,还支持两种数据结构:
一维数组Series
二维表格型数据结构DataFrame
本章,我们只介绍利用Pandas读取数据的相关知识。
Pandas是第三方库,使用之前需要先安装,安装命令:
pip install pandas
通常,Pandas的引用方式为:
import pandas as pd
Pandas输入输出API提供了对文本、二进制和结构化查询语言(SQL)等不同格式类型文件的读写函数,可以方便快速的读取本地文件,如csv、txt、json和html等文本文件、Excel文件以及关系型数据库中的数据。
其主要方法如表6.2所示。
表 6.2 Pandas常用输入输出API
| 格式类型 | 数据描述 | 读 | 写 |
|---|---|---|---|
| 文本 | CSV | read_csv() | to_csv() |
| 文本 | JSON | read_json() | to_json() |
| 文本 | HTML | read_html() | to_html() |
| 二进制 | MS Excel | read_excel() | to_excel() |
| 二进制 | Python Pickle Format | read_pickle() | to_pickle() |
| SQL | SQL | read_sql() | to_sql() |
这些API可以方便的把各种类型的数据读取为Dataframe格式的数据,再用利用tolist()函数便可将其转为列表类型,这样就可以利用本章学习的方法进行数据分析和处理了。
6.11.1 读Excel文件中数据
用Pandas可以读取Excel文件中的数据为Dataframe类型,Excel文件的读取主要应用read_excel()方法,使用时可能需要先用“pip install xlrd”安装xlrd模块。
read_excel()方法大部分参数都有默认值,只需要设置少量的参数便可以完成大部分的数据读取工作。
其主要参数及其意义如下:
pd.read_excel(io, sheet_name=0, header=0, names=None, usecols=None, squeeze=False, converters=None, skiprows=None, nrows=None, skipfooter=0)
- io:Excel的存储路径
- sheet_name:要读取的工作表名称,默认读取第一个工作表。可以是整型数字、列表名或SheetN。整型数字:目标sheet所在的位置,以0为起始,比如sheet_name = 1代表第2个工作表。列表名:目标sheet的名称,中英文皆可。SheetN:代表第N个sheet,S要大写,注意与整型数字的区别。
- header:用哪一行作列名。默认为0 ,如果设置为[0,1],则表示将前两行作为多重索引。
- names:自定义最终的列名。一般适用于Excel缺少列名,或者需要重新定义列名的情况。names的长度必须和Excel列长度一致,否则会报错。
- index_col:用作索引的列
- usecols:需要读取哪些列。可以使用整型,从0开始,如[0,2,3];也可以使用Excel传统的列名A、B等字母,如"A:C, E" = "A, B, C, E",注意两边都包括。usecols 可避免读取全量数据,而是以分析需求为导向选择特定数据,提高效率。
- squeeze:当数据仅包含一列。squeeze为True时,返回Series,反之返回DataFrame。
- converters:强制规定列数据类型,主要用途是保留以文本形式存储的数字。
- skiprows:跳过特定行。skiprows= n 跳过前n行; skiprows = [a, b, c] 跳过第a+1,b+1,c+1行(索引从0开始)。
- nrows:需要读取的行数,nrows = n 读取前n行。
- skipfooter: 跳过末尾行数,skipfooter = n 跳过末尾的n行。
pandas默认将文本类的数据读取为整型,converters 参数可以指定各列数据的类型,如converters = {'出货量':float, '月份':str }, 将“出货量”列数据类型规定为浮点数,“月份”列规定为字符串类型。
实例 6.6 读取Excel文件中的证券数据
import pandas as pddata_df = pd.read_excel('/data/bigfiles/6,6 stock.xlsx') # 读取数据为dataframe类型
print(data_df)
import pandas as pddata_df = pd.read_excel('/data/bigfiles/6,6 stock.xlsx') # 读取数据为dataframe类型
title = data_df.columns.tolist() # dataframe数据中标题行转为列表类型
print('输出列表类型的表头\n',title) # 输出列表类型数据
print()data_ls = data_df.values.tolist() # dataframe数据转为列表类型
print('输出列表类型的数据\n',data_ls) # 输出列表类型数据
[[Timestamp('2018-01-15 00:00:00'),4.265, 4.56, 1.65, 1.736, 0.92, 1.634],
[Timestamp('2018-01-16 00:00:00'), 4.308, 4.595, 1.7, 1.75, 0.941, 1.631],
[Timestamp('2018-01-17 00:00:00'), 4.295, 4.59, 1.699, 1.74, 0.973, 1.639],
[Timestamp('2018-01-18 00:00:00'), 4.323, 4.621, 1.675, 1.744, 0.98, 1.636],
[Timestamp('2018-01-19 00:00:00'), 4.335, 4.632, 1.683, 1.74, 1.002, 1.63]]
data_df.columns本身是一个Index对象,表示DataFrame的列名。.tolist()方法将其转换为Python列表,因此title是一个列表。print()函数在输出时会显示列表的语法(包括方括号和逗号分隔的元素),因此你会看到列表类型的输出。
值得注意的是,与遍历方法读取文件不同,用缺省参数读取的数据中,数值类型的数据直接被转为数值型,可以直接参与数值运算和统计分析。
日期读取为日期时间戳类型,可以用strftime()转为字符串。
import pandas as pddata_df = pd.read_excel('/data/bigfiles/6,6 stock.xlsx') # 读取数据为dataframe类型data_ls = data_df.values.tolist() # dataframe数据转为列表类型for lst in data_ls:lst[0] = lst[0].strftime("%Y-%m-%d") # 日期时间格式化为年-月-日形式
print('输出列表类型的数据\n', data_ls) # 输出列表类型数据
[['2018-01-15', 4.265, 4.56, 1.65, 1.736, 0.92, 1.634], ['2018-01-16', 4.308, 4.595, 1.7, 1.75, 0.941, 1.631], ['2018-01-17', 4.295, 4.59, 1.699, 1.74, 0.973, 1.639], ['2018-01-18', 4.323, 4.621, 1.675, 1.744, 0.98, 1.636], ['2018-01-19', 4.335, 4.632, 1.683, 1.74, 1.002, 1.63]]
pip install openpyxl
6.11.2 读文本文件中数据
读文本文件和csv文件进列表,对列表中的数据进行统计分析。将用常规分隔符分隔的文本文件读取到DataFrame可以使用read_csv()方法
其主要参数及意义如下:
pandas.read_csv(filepath_or_buffer, sep='\t', delimiter=None, header='infer', names=None, engine=None,encoding=None)
- filepath_or_buffer:带路径文件名或URL,字符串类型。
- sep:分隔符,缺省值为'\t',当文本中的分隔符不是制表符时,可用sep=’分隔符’来指定。Python可自动检测分隔符。
- delimiter:参数sep的替代参数,缺省值为None。
- header:整型或整型列表,用作列名的行号和数据的开头。
- names:要使用的列名的列表,如果文件不包含标题行,则应显式传递header = None。
- engine:使用解析器引擎,其值可为'c'或'python'。c引擎速度更快,而Python引擎目前功能更加完善。
- encoding:默认None,编码在读/写时用UTF(例如'utf-8')
实例 6.7读取csv文件中的数据
6.7 score.csv
import pandas as pdscore_df = pd.read_csv('/data/bigfiles/6,7 score.csv',encoding='utf-8') # dataframe
print(score_df) # 查看数据格式
import pandas as pdscore_df = pd.read_csv('/data/bigfiles/6,7 score.csv',encoding='utf-8') # dataframe
title = score_df.columns.tolist() # dataframe数据中标题行转为列表类型
score_ls = [title] + score_df.values.tolist() # 转为列表类型
print('输出列表类型的数据\n',score_ls) # 输出列表数据
[['姓名', 'C语言', 'Java', 'Python', 'C#'] ['罗明', 95, 96, 85, 63, 91], ['朱佳', 75, 93, 66, 85, 88], ['李思', 86, 76, 96, 93, 67], ['郑君', 88, 98, 76, 90, 89], ['王雪', 99, 96, 91, 88, 86]]
6.11.3 读数据库中数据
在实际应用中,使用文本文件或Excel存储数据并不是最好的方式,我们能够对这些类型的文件中的数据能的操作非常有限,数据处理效率也不高,更常用的方式是将数据存储到数据库中,通过连接数据库进行相关操作。 目前应用最多的是关系型数据库,关系型数据库的主要构成是二维表。
二维表包含多行多列,把一个表中的数据用Python表现出来,可以用一个列表表示多行,列表的每一个元素用一个元组表示二维表中的一行记录。
比如一个二维表包含ID、姓名、年龄、籍贯、薪水,可以用以下形式表示:
[(1, '李明', 23, '吉林', 20000.00), (2, '韩雷', 26, '湖北', 25000.00), (3, '肖红', 30, '江西', 30000.00)]
这种表示方法无法直观的展示关系数据库的表结构,可以使用对象-关系映射 (ORM:Object-Relational Mapping)技术把关系数据库的表结构映射到对象上。在Python中,广泛应用的一个对象-关系映射框架是SQLAlchemy,这个框架可以为开发者提供高效的数据库访问设计和高性能的数据访问方法,实现了完整的企业级持久模型。
SQLAlchemy支持大部分主流数据库,如SQLite、MySQL、Postgres、Oracle、MS SQLServer 和 Firebird等。在使用之前,需要通过pip install sqlalchemy安装这个库。
SQLite是Python 内置的一个轻量级数据库,可以直接使用。使用其他数据库时,需要pip安装与数据库匹配的驱动,例如mysqlclient、 pymssql、 psycopg2、 cx-Oracle或 fdb等。只有安装数据库的驱动之后,才可以连接数据库对数据进行操作。本书以SQLite数据库作为范例进行讲解。
sqlalchemy.create_engine(args, *kwargs)函数可被用于创建数据库引擎,数据库位置可用本地路径,也可用网络URL。
from sqlalchemy import *
import pandas as pd# 定义元信息,绑定到引擎,test.db为数据库名,./表示当前路径。
engine = create_engine('sqlite:data/bigfiles/6,8 test.db', echo=True)
metadata = MetaData(engine) # 绑定元信息
Pandas中的read_sql()方法可以查询数据库中的数据并直接返回DateFrame,在方法的参数中可以传入SQL语句。read_sql()方法的主要参数及意义如下:
pandas.read_sql(sql, con, index_col=None, coerce_float=True, params=None, parse_dates=None, columns=None, chunksize=None)
- sql : 表名或查询语句
- con : 连接数据库的引擎,一般可以用SQLAlchemy之类的模块创建
- columns : 需要从表中查询的列名的列表
实例 6.8 读取SQLite数据库中的数据
SQLite数据库中文件“6.8 test.db”的score表中存储了学生的成绩数据,请将数据库中的数据读入到列表中。
6.8 test.db
from sqlalchemy import *
import pandas as pd# 定义引擎,6.8 test.db为数据库名,./表示当前路径
engine = create_engine('sqlite:data/bigfiles/6,8 test.db') # , echo=True)
score_df = pd.read_sql('score', engine) # 从score表读数据dataframe
print(score_df) # 查看输出dataframe格式数据
姓名 C语言 Java Python C# C++ 0 罗明 95 96 85 63 91 1 朱佳 75 93 66 85 88 2 李思 86 76 96 93 67 3 郑君 88 98 76 90 89 4 王雪 99 96 91 88 86
from sqlalchemy import *
import pandas as pd# 定义引擎,6.8 test.db为数据库名,./表示当前路径
engine = create_engine('sqlite:data/bigfiles/6,8 test.db') # , echo=True)
score_df = pd.read_sql('score', engine) # 从score表读数据dataframetitle = score_df.columns.tolist() # dataframe数据转为列表类型
score_ls = score_df.values.tolist() # dataframe数据转为列表类型
print('输出列表类型的数据:\n', [title] + score_ls) # 输出转为列表的数据
```python [['姓名', 'C语言', 'Java', 'Python', 'C#', 'C++'], ['罗明', 95, 96, 85, 63, 91], ['朱佳', 75, 93, 66, 85, 88], ['李思', 86, 76, 96, 93, 67], ['郑君', 88, 98, 76, 90, 89], ['王雪', 99, 96, 91, 88, 86]] ```
pip install sqlalchemy
类似的方法,也可以从json格式的文件中读取数据到列表:
import pandas as pdscore_df = pd.read_json('/data/bigfiles/6,8 scoreTest.json', encoding='utf-8')
title = score_df.columns.tolist() # dataframe数据转为列表类型
score_ls = score_df.values.tolist() # dataframe数据转为列表类型
print('输出列表类型的数据:\n', [title] + score_ls) # 输出转为列表的数据
pandas 数据显示
若csv文件的某列中有逗号,一般会将该列数据放到一对比引号中。pandas读csv文件时,可以将引号中的数据自动处理为一个元素,用pandas处理此类数据,可以避免用切分方法导致的误切分。
winemag-data.csv
import pandas as pdwine_reviews = pd.read_csv("/data/bigfiles/winemag-data.csv")
print(wine_reviews.shape) # ((12973, 6)
pd.set_option('display.max_columns', None) # 显示所有列
pd.set_option('display.max_rows', None) # 显示所有行
pd.set_option('display.width', None) # 显示宽度是无限
print(wine_reviews.head()) # 返回数据的前5行
6.12 内置函数all,any和filter的用法
Python中的all(), any(), 和 filter()是内置函数,用于对可迭代对象(如列表、元组等)进行操作,以实现不同的逻辑和筛选功能。
all()
all()函数用于检查可迭代对象中的所有元素是否都满足一个条件。如果可迭代对象中的所有元素都为True(或可迭代对象为空),则返回True;否则返回False。
用法:
all(iterable)
示例: 检查一个数字列表是否所有数字都大于0:
numbers = [1, 2, 3, 4, 5] result = all(number > 0 for number in numbers) print(result) # 输出:True
使用all实现素数判定函数:
def is_prime_all(n):if n <= 1:return Falsereturn all(n % i != 0 for i in range(2, int(n**0.5) + 1))# 测试 print(is_prime_all(2)) # True print(is_prime_all(17)) # True print(is_prime_all(4)) # False
any()
any()函数用于检查可迭代对象中是否至少有一个元素满足一个条件。如果可迭代对象中至少有一个元素为True,则返回True;如果可迭代对象为空或所有元素都不满足条件,返回False。
用法:
any(iterable)
示例: 检查一个数字列表中是否至少有一个数字是正数:
numbers = [0, -1, -2, 4, -5] result = any(number > 0 for number in numbers) print(result) # 输出:True
使用any实现素数判定函数:
def is_prime_any(n):if n <= 1:return Falsereturn not any(n % i == 0 for i in range(2, int(n**0.5) + 1))# 测试 print(is_prime_any(2)) # True print(is_prime_any(17)) # True print(is_prime_any(4)) # False
filter()
filter()函数用于从可迭代对象中过滤出满足条件的元素,返回一个filter对象,通常需要使用list()函数转换为列表。
用法:
filter(function, iterable)
function: 用于测试每个元素是否满足条件的函数。返回True或False。 iterable: 要从中过滤元素的可迭代对象。 示例: 从一个数字列表中过滤出所有的偶数:
numbers = [1, 2, 3, 4, 5, 6] even_numbers = filter(lambda x: x % 2 == 0, numbers) print(list(even_numbers)) # 输出:[2, 4, 6]
使用filter实现素数判定函数:
def is_prime_filter(n):if n <= 1:return Falsefactors = filter(lambda i: n % i == 0, range(2, int(n**0.5) + 1))return len(list(factors)) == 0# 测试 print(is_prime_filter(2)) # True print(is_prime_filter(17)) # True print(is_prime_filter(4)) # False
这些函数提供了强大的工具来处理和操作可迭代对象,使得代码更加简洁、易读。
6.13 中国近年废气污染物排放分析
数据文件下载:
废气污染物排放.csv

1.读文件,查看数据格式
def read_file(filename):"""读文件到列表,每行字符串为列表的一个元素,返回列表"""with open(filename,'r',encoding='utf-8') as fr:data_ls = [x.strip() for x in fr]print(data_ls)if __name__ == '__main__':file_name = '/data/bigfiles/废气污染物排放.csv'read_file(file_name)
['数据库:年度数据', '时间:最近20年', '指标,2020年,2019年,2018年,2017年,2016年,2015年,2014年,2013年,2012年,2011年,2010年,2009年,2008年,2007年,2006年,2005年,2004年', '二氧化硫排放量(万吨),318.22,457.30,516.10,610.80,854.90,1859.10,1974.40,2043.90,2118.00,2217.91,2185.00,2214.00,2321.00,2468.00,2588.80,2549.40,2254.90', '氮氧化物排放量(万吨),1181.65,1233.85,1785.22,1785.22,1394.31,1851.02,2078.00,2227.36,2337.76,2404.27,,,,,,,', '烟(粉)尘排放量(万吨),,,,796.26,1010.66,1538.01,1740.75,1278.14,1235.77,1278.83,,,,,,,', '颗粒物排放量(万吨),613.35,,,1684.05,,,,,,,,,,,,,', '注:1.2017年数据来源于第二次全国污染源普查。', '2.2017年全国移动源营运船舶二氧化硫、氮氧化物、颗粒物排放量,因无法以省级行政单元为对象进行调查,故未包含在各省排放总量内。', '3.自2017年,烟(粉)尘排放量指标名称改为颗粒物排放量。', '数据来源:国家统计局']
2.数据清洗
def read_file(filename):"""读文件到列表,每行字符串为列表的一个元素,返回列表"""with open(filename, 'r', encoding='utf-8') as fr:raw_data_ls = [x.strip() for x in fr]return raw_data_lsdef data_clean(raw_data_ls):"""去除无意义的数据仅保留废气污染数据,返回二维列表"""data_ls = raw_data_ls[2:7]clean_data_ls = [x.split(',') for x in data_ls]print(clean_data_ls)if __name__ == '__main__':file_name = '/data/bigfiles/废气污染物排放.csv'raw_data_lst = read_file(file_name)data_clean(raw_data_lst)
[['指标', '2020年', '2019年', '2018年', '2017年', '2016年', '2015年', '2014年', '2013年', '2012年', '2011年', '2010年', '2009年', '2008年', '2007年', '2006年', '2005年', '2004年'], ['二氧化硫排放量(万吨)', '318.22', '457.30', '516.10', '610.80', '854.90', '1859.10', '1974.40', '2043.90', '2118.00', '2217.91', '2185.00', '2214.00', '2321.00', '2468.00', '2588.80', '2549.40', '2254.90'], ['氮氧化物排放量(万吨)', '1181.65', '1233.85', '1785.22', '1785.22', '1394.31', '1851.02', '2078.00', '2227.36', '2337.76', '2404.27', '', '', '', '', '', '', ''], ['烟(粉)尘排放量(万吨)', '', '', '', '796.26', '1010.66', '1538.01', '1740.75', '1278.14', '1235.77', '1278.83', '', '', '', '', '', '', ''], ['颗粒物排放量(万吨)', '613.35', '', '', '1684.05', '', '', '', '', '', '', '', '', '', '', '', '', '']]
3. 查询历年污染物排放
def read_file(filename):"""读文件到列表,每行字符串为列表的一个元素,返回列表"""with open(filename, 'r', encoding='utf-8') as fr:raw_data_ls = [x.strip() for x in fr]return raw_data_lsdef data_clean(raw_data_ls):"""去除无意义的数据仅保留废气污染数据,返回二维列表"""data_ls = raw_data_ls[2:7]clean_data_ls = [x.split(',') for x in data_ls]return clean_data_lsdef pollution_emissions(clean_data_ls, pollutant_name):"""从清洗后的数据中查询历年某项污染物排放量,以“二氧化硫排放量(万吨)”为例,按排放量降序逐年输出,无返回值"""for x in clean_data_ls:if pollutant_name in x[0]:order = clean_data_ls.index(x) # 先获取污染物数据序号pollutant_name = x[0][:-7] # 切取污染物名break # 结束循环# print(pollutant_name, order) # 查看处理结果emissions_of_year = list(zip(clean_data_ls[0], clean_data_ls[order]))[1:] # 将年份与对应数据组合在一起,切除首列sorted_emissions = sorted(emissions_of_year, key=lambda x: float(x[1]), reverse=True) # 根据排放量的数值排序for x in sorted_emissions:print('{1}{0}排放量为{2}万吨'.format(pollutant_name, *x)) # 元组解包输出if __name__ == '__main__':file_name = '/data/bigfiles/废气污染物排放.csv'raw_data_lst = read_file(file_name)data_clean(raw_data_lst)clean_data_lst = data_clean(raw_data_lst)pollutant = input() # 输入污染物名字pollution_emissions(clean_data_lst, pollutant)
2006年二氧化硫排放量为2588.80万吨 2005年二氧化硫排放量为2549.40万吨 2007年二氧化硫排放量为2468.00万吨 2008年二氧化硫排放量为2321.00万吨 2004年二氧化硫排放量为2254.90万吨 2011年二氧化硫排放量为2217.91万吨 2009年二氧化硫排放量为2214.00万吨 2010年二氧化硫排放量为2185.00万吨 2012年二氧化硫排放量为2118.00万吨 2013年二氧化硫排放量为2043.90万吨 2014年二氧化硫排放量为1974.40万吨 2015年二氧化硫排放量为1859.10万吨 2016年二氧化硫排放量为854.90万吨 2017年二氧化硫排放量为610.80万吨 2018年二氧化硫排放量为516.10万吨 2019年二氧化硫排放量为457.30万吨 2020年二氧化硫排放量为318.22万吨
结论,中国在环境保护方面做出了卓有成效的工作,污染排放逐年减少。