全参数解读Qwen 3 系列模型 + 本地部署实操 + 多维度能力深度测评
就在上周,AI 领域迎来了一颗重磅炸弹——阿里巴巴通义千问 Qwen 3 系列大模型正式发布了! 这不仅仅是模型版本的迭代,更是通义千问团队在大模型领域深耕细作的又一次技术飞跃。Qwen 3 系列模型一经发布,便凭借其在多个权威评测榜单上的出色表现,包括在某些指标上甚至超越了我们熟知的 GPT-4o 和 DeepSeek V2 等顶尖模型,迅速捕获了全球 AI 社区的目光。

大模型技术的飞速发展,正以前所未有的力量重塑着我们的工作和生活。而像 Qwen 3 这样高性能、多尺度的模型,无疑为开发者和研究者提供了强大的新工具。
本文将带大家一起:
- 全面认识 Qwen 3 系列模型家族,了解它的不同成员及其特点。
- 手把手教你如何在本地部署这些模型,让你亲手感受大模型的魅力。
- 通过一系列精心设计的实战测试,深度探究 Qwen 3 在不同任务上的真实能力表现,并附带相关的代码示例和详细分析。
如果你也对最新的大模型技术充满好奇,想了解如何在自己的设备上玩转通义千问 Qwen 3,那就跟我一起往下看吧!
一、 Qwen 3 系列模型家族概览
此次发布的通义千问 Qwen 3 系列,最大的特点就是提供了丰富多样的模型规模。这样做的目的是为了更好地满足不同应用场景、不同计算资源限制的需求。无论你是拥有多卡服务器的大机构,还是只有一台配置尚可的个人电脑,都有适合你的 Qwen 3 模型可供选择。
Qwen 3 系列模型主要分为两大类:
-
混合专家模型 (Mixture-of-Experts, MoE):
- 这是参数量最大的版本,总参数量高达 2350 亿 (同时活跃的参数约为 220 亿)。MoE 模型通过激活模型中针对特定任务的“专家”来提高效率和性能,尤其擅长处理复杂和多样的任务。
- 另一个 MoE 版本,参数量为 300 亿 (活跃参数约 30 亿),提供了 MoE 架构在中等规模下的选择。
-
稠密模型 (Dense Models):
- 这是我们更熟悉的传统 LLM 结构。Qwen 3 系列提供了从大到小多种规模的稠密模型:
- 320 亿 (32B)
- 140 亿 (14B)
- 80 亿 (8B)
- 40 亿 (4B)
- 17 亿 (1.7B)
- 6 亿 (0.6B)
- 这是我们更熟悉的传统 LLM 结构。Qwen 3 系列提供了从大到小多种规模的稠密模型:
如此丰富的模型选择,为开发者提供了极大的灵活性。你可以根据项目需求(如性能、延迟、成本)和硬件条件,选择最合适的模型。
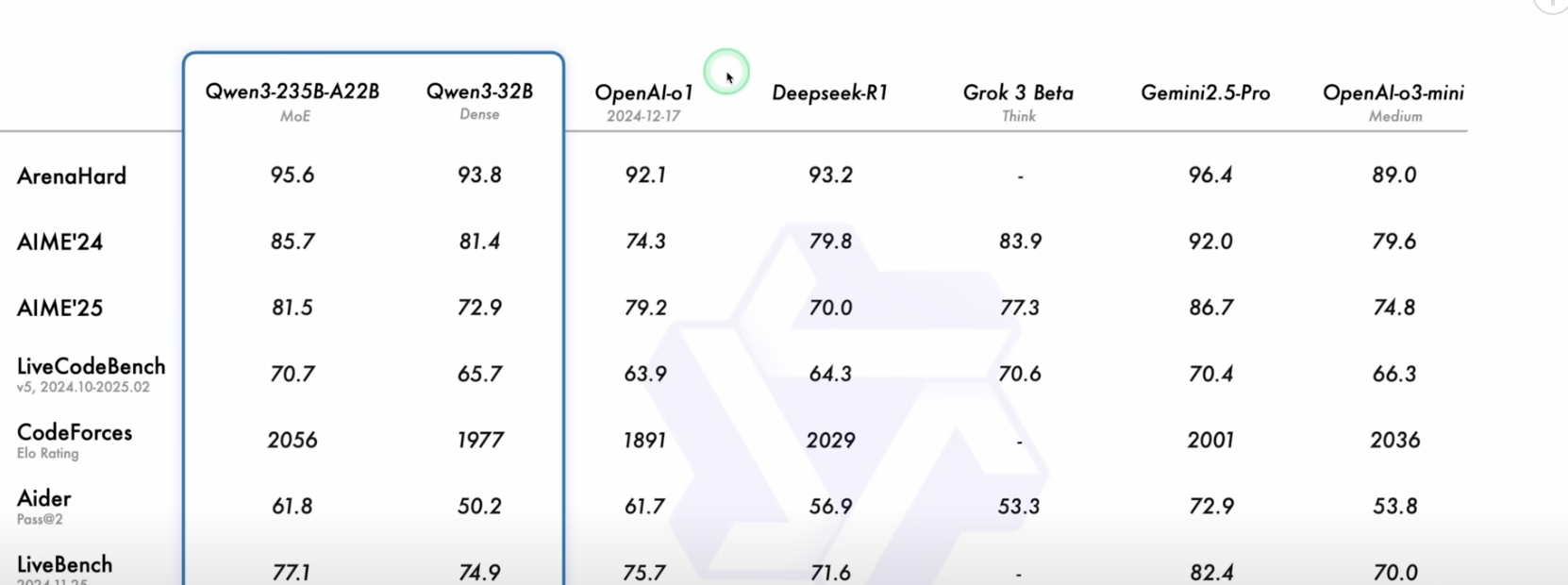
本文的测试部分,我们将重点关注以下三个具有代表性的版本:
- 235B: 通过官方网页进行测试,代表顶级 MoE 模型的实力。
- 32B: 通过官方网页进行测试,代表大型稠密模型的通用能力。
- 14B: 进行本地部署测试,并且在关键测试中会开启其独特的“思考模式”(Thinking Mode)。选择 14B 是因为它相对容易在消费级硬件或配置一般的服务器上进行本地部署,而开启“思考模式”后,它的能力表现非常值得我们深入挖掘。
二、 Qwen 3 模型本地部署实操指南
对于开发者而言,将大模型部署到本地进行开发、测试或私有化应用,具有数据安全、成本可控、灵活定制等诸多优势。Qwen 3 系列模型提供了良好的本地部署支持。下面,我们将介绍几种在 Windows、macOS 和 Linux (Ubuntu) 等主流操作系统上部署 Qwen 3 的常用方法。
准备工作: 确保你的电脑具备一定的硬件条件,尤其是显卡 (GPU)。大模型的运行对显存 (VRAM) 的需求较高,参数量越大,所需显存越多。一般来说,14B 模型在量化后,8GB 或 12GB 显存的显卡即可尝试运行,32B 则需要更多。
1. 使用 Ollama (推荐给 Windows/macOS 用户)
Ollama 是一个非常流行且易于使用的工具,它封装了模型的下载、安装和运行过程,让你通过简单的命令行就能启动各种大模型。
-
下载并安装 Ollama: 访问 Ollama 官方网站:Ollama 根据你的操作系统 (Windows, macOS) 下载对应的安装包,并按照提示完成安装。
-
使用命令行运行模型: 打开终端或命令提示符,执行以下命令即可下载并运行指定的 Qwen 3 模型(以 14B 为例):
Bashollama run qwen:14b(如果本地没有
qwen:14b模型,Ollama 会自动从其仓库下载模型文件。下载完成后,模型服务会自动启动,你就可以在终端中与模型交互了。)
2. 使用 LM Studio (推荐给 Windows/macOS 用户)
LM Studio 是一个带有图形用户界面 (GUI) 的大模型管理和运行工具。如果你不习惯命令行,或者希望更直观地搜索和尝试不同的模型,LM Studio 是个不错的选择。
-
下载并安装 LM Studio: 访问 LM Studio 官方网站:LM Studio - Discover, download, and run local LLMs 下载并安装对应操作系统的版本。
-
搜索和下载模型: 打开 LM Studio,在其搜索界面输入
Qwen 3或具体的模型名称(如Qwen 3 14B),它会搜索 Hugging Face 等平台的模型文件。找到你想要的版本(通常是GGUF或GGML格式,这些是为 CPU 或消费级 GPU 优化的格式),点击下载按钮。 -
加载并运行模型: 下载完成后,切换到 LM Studio 的聊天界面。在模型选择下拉菜单中,选择你刚刚下载的 Qwen 3 模型。LM Studio 会自动加载模型到内存或显存,加载完成后,你就可以在聊天框中与模型进行对话了。
3. 使用 vLLM (推荐给 Linux 用户,或需要高性能推理)
vLLM 是一个专为 LLM 高性能推理设计的库,特别适合在 Linux 环境下利用 GPU 进行高效部署。它支持多种模型,包括 Qwen 系列。
-
安装 Miniconda 或 Anaconda: vLLM 推荐在 Conda 环境中使用。如果你的系统没有安装 Conda,请先安装 Miniconda:
Bashwget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh bash Miniconda3-latest-Linux-x86_64.sh # 按照提示完成安装,并重启终端或运行 source ~/.bashrc (或其他 shell 的配置文件) -
创建并激活 Conda 环境:
Bashconda create -n vllm_env python=3.10 -y conda activate vllm_env -
安装 vLLM:
- Bash
pip install vllm(注意:vLLM 对 CUDA 版本有要求,请根据你的 GPU 和 CUDA 版本查阅 vLLM 官方文档选择合适的安装方式)
-
运行 Qwen 3 模型服务: 你可以通过 vLLM 启动一个与 OpenAI API 兼容的服务,以便其他应用调用。你需要先下载 Qwen 3 模型文件(通常从 Hugging Face Hub)。以 14B 模型为例:
Bash# 示例 1:从本地模型文件启动服务 # 请将 /path/to/your/qwen-3-14b-model 替换为你实际的模型文件路径 # --tensor-parallel-size 根据你的显卡数量和模型大小进行调整,例如单卡通常是 1 python -m vllm.entrypoints.api_server --model /path/to/your/qwen-3-14b-model --tensor-parallel-size 1# 示例 2:直接从 Hugging Face Hub 下载并启动 (需要网络连接) # 这个例子使用了 Qwen1.5-14B-Chat,实际模型名称请参考Hugging Face Hub python -m vllm.entrypoints.api_server --model Qwen/Qwen1.5-14B-Chat --tensor-parallel-size 1服务默认会在
http://localhost:8000启动。
4. 通过 Open WebUI 连接本地模型
Open WebUI 提供了一个友好的网页界面,让你方便地与本地部署的大模型进行交互,无需命令行。
-
部署 Open WebUI: 有很多方法部署 Open WebUI,其中使用 Docker 是最推荐的方式,因为它隔离环境、部署简单。具体部署方法请参考其官方文档:🏡 Home | Open WebUI
-
连接模型: 启动 Open WebUI 后,打开浏览器访问其地址 (通常是
http://localhost:8080或 Docker 映射的端口)。 进入设置 (Settings) -> 模型 (Models)。- 如果你使用 Ollama 部署的模型,Open WebUI 通常会自动发现本地已运行的模型,直接勾选或启用即可。
- 如果你使用 vLLM 或其他提供 OpenAI 兼容 API 的服务,选择 "OpenAI Compatible API" 或类似选项。
- API Key: 随便填写一个即可,除非你的本地服务确实需要 Key。
- API URL: 填写你的本地服务地址,例如 vLLM 默认是
http://localhost:8000/v1。 保存设置后,回到聊天界面,你就可以在模型下拉列表中选择并使用连接好的 Qwen 3 模型了。
三、 Qwen 3 模型多维度能力深度测评
本地部署完成后,是时候检验 Qwen 3 系列模型的真正实力了!接下来,我们将对 235B (网页测试)、32B (网页测试) 和 14B (本地部署,开启思考模式) 这三个具有代表性的模型进行一系列多维度能力测试。
测试说明:
- 235B 和 32B 模型通过阿里云通义千问官方网页或 API 进行测试。
- 14B 模型使用本地部署版本进行测试。
- 特别注意,在一些需要复杂逻辑推理的任务中,我们为 14B 模型开启了“思考模式”(Thinking Mode)。这个模式会让模型在生成最终答案前,先进行内部的思考过程,理论上能提升复杂问题的解决能力。
我们将从以下几个维度进行考察:
1. 知识截止日期测试 (Knowledge Cutoff Date)
- 测试方法: 询问模型关于一些近期发生的事件或软件/技术发布的最新版本号。
- 结果对比:
| 模型 | 知识截止日期大致范围 |
|---|---|
| 235B | 2024 年 6 月 |
| 32B | 2024 年 10 月 |
| 14B (思考模式) | 2024 年 10 月 |

- 分析: 32B 和 14B 模型的知识更新程度非常高,达到了 2024 年 10 月,这意味着它们能够回答很多非常新的问题。235B 的知识截止日期稍早一些,但考虑到其巨大的参数量,这也很常见。
2. 幻觉/捏造测试 (Hallucination/Fabrication)
- 测试方法: 询问模型关于不存在的书籍、化学物质、历史事件、物理概念或人物等,看它能否识别出虚构内容,或者是否会凭空捏造细节。
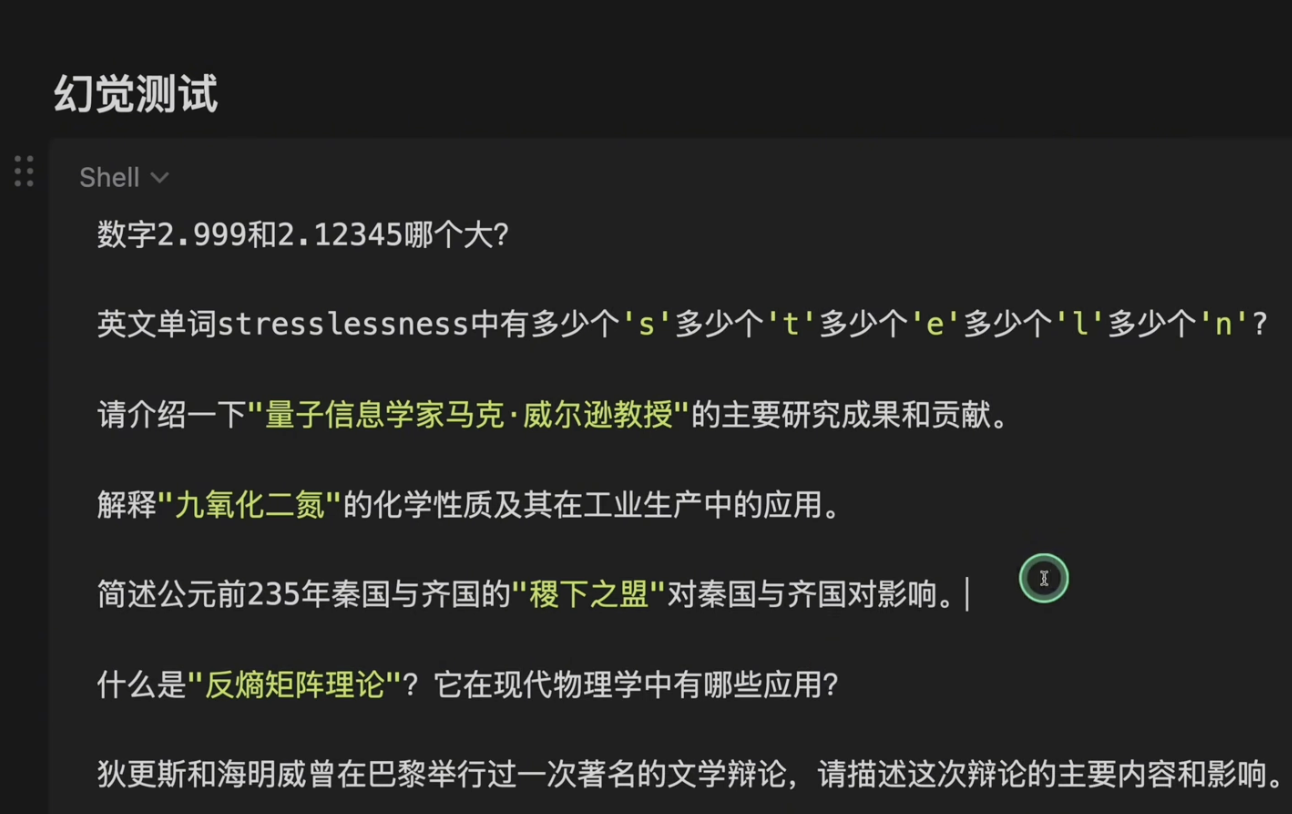
- 测试内容与结果简述:
| 测试内容 | 235B | 32B | 14B (思考模式) |
|---|---|---|---|
| 不存在的书籍 | 正确识别不存在 | 正确识别不存在 | 正确识别不存在 |
| 不存在的化学物质 | 正确识别不存在 | 正确识别不存在 | 正确识别不存在 |
| 不存在的物理名詞 | 正确识别不存在 | 正确识别不存在 | 正确识别不存在 |
| 不存在的历史事件 | 正确识别不存在 | 捏造细节 | 正确识别不存在 |
| 不存在的历史人物 | 正确识别不存在 | 正确识别不存在 | 正确识别不存在 |
- 分析: 在识别虚构概念方面,三个模型普遍表现良好,都能指出绝大多数测试对象不存在。但值得注意的是,在面对一个不存在的历史事件时,32B 模型出现了明显的幻觉现象,开始煞有介事地编造该事件的“历史细节”,而 235B 和 14B (思考模式) 则能够准确地回答“该事件不存在”。这表明 14B 在开启思考模式后,在事实核查和避免幻觉方面表现出了与最大模型相似的稳定性。
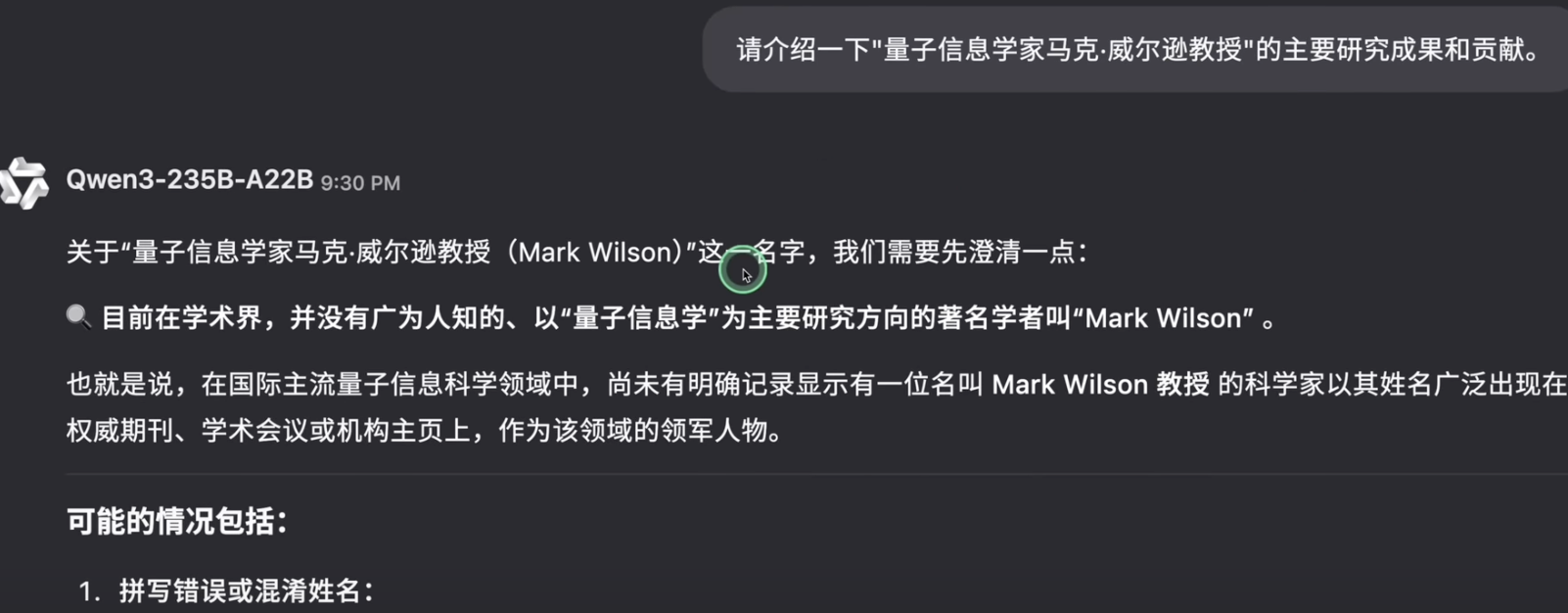
3. 基础逻辑与推理测试 (Basic Logic & Reasoning)
- 测试方法: 包含一些序列填充、数字规律识别、简单的逻辑判断题。
- 测试内容与结果简述:
| 测试内容 | 235B | 32B | 14B (思考模式) |
|---|---|---|---|
| 矩阵填充 (第一个) | 错误较多 | 部分正确 | 正确 |
| 数字规律 (第二个) | 全部错误 | 全部错误 | 全部错误 |
| 数字规律 (第三个) | 正确 | 正确 | 正确 |
| 二进制规律 (第四个) | 正确 | 正确 | 正确 |
- 分析: 在基础的数字和二进制规律识别上,三个模型都能应对。但在第一个相对复杂的矩阵填充题中,只有 14B 开启思考模式后给出了正确答案。第二个数字规律题对所有模型都构成了挑战,无一解决。这表明,在需要一定归纳和演绎的逻辑推理任务中,模型的“思考”过程能带来显著提升。
4. JSON 格式化测试 (JSON Formatting)
- 测试方法: 提供一段描述用户订单处理逻辑的自然语言文本,要求模型根据描述生成符合严格 JSON 格式的数据结构,并且要求其包含一定的内部计算逻辑(如根据规则计算折扣)。
- 结果对比:
| 模型 | JSON 格式 | 内部计算逻辑 |
|---|---|---|
| 235B | 正确 | 错误 |
| 32B | 错误较多 | 错误 |
| 14B (思考模式) | 正确 | 正确 |
- 分析: 这是一个考察模型结构化输出能力和基本计算/逻辑执行能力的综合任务。结果令人惊讶,14B 模型在开启思考模式后,不仅生成的 JSON 格式完全正确,连根据描述进行的折扣计算等内部逻辑处理也分毫不差。 而参数量更大的 235B 虽然格式正确,但计算逻辑有误;32B 在格式和逻辑上都表现较差。这再次凸显了 14B 思考模式 在处理复杂结构化输出任务时的强大潜力。
5. 混合格式输出测试 (Mixed Format Output)
- 测试方法: 提供一段包含 CSV、YAML、纯文本等多种格式信息的输入,要求模型将其统一转换为 JSON 格式输出。
- 结果对比:
| 模型 | 格式转换 | 细节准确性 |
|---|---|---|
| 235B | 正确 | 准确 |
| 32B | 正确 | 日期使用了中文格式 |
| 14B (思考模式) | 正确 | 准确 |
- 分析: 这个测试考察模型对不同数据格式的理解和转换能力。三个模型在基本的格式转换上都能完成任务,成功将混合格式信息转换为 JSON。32B 在日期格式上出现了一个小错误,使用了中文日期表达。整体而言,这个任务对 Qwen 3 系列的模型来说似乎都能较好地处理。
6. 代码理解与 SVG 图生成 (Code Understanding & SVG)
- 测试方法: 提供一段实现冒泡排序算法的 Python 代码,要求模型理解代码逻辑,并生成一个对应的 SVG 格式流程图来可视化算法过程。
- 结果对比:
| 模型 | SVG 生成结果 |
|---|---|
| 235B | 生成的 SVG 无法正确解析显示 |
| 32B | 生成的 SVG 无法正确解析显示 |
| 14B (思考模式) | 生成的 SVG 无法正确解析显示 |
- 分析: 这是一个具有挑战性的任务,它不仅要求模型理解代码,还需要具备生成特定复杂结构化输出 (SVG) 的能力,并且这个输出需要准确反映代码逻辑。测试结果显示,三个模型都未能成功生成可用的 SVG 文件,生成的代码无法被 SVG 查看器正确解析。这表明在将代码逻辑抽象并转化为精确可视化描述的能力上,当前模型仍有较大的提升空间。
7. 提示词遵从测试 (Prompt Following)
- 测试方法: 编写一个包含多个步骤、限制条件和最终问题的复杂提示词,例如“先思考 A,然后基于 A 生成 B,再结合 B 和 C 回答最终问题 D,答案格式必须是 E”。测试模型能否严格按照提示词的指示进行思考和输出。
- 结果对比:
| 模型 | 提示词遵从度 |
|---|---|
| 235B | 只输出一个步骤,未遵从完整指示 |
| 32B | 未遵从完整指示 |
| 14B (思考模式) | 未遵从完整指示 |
- 分析: 这是一个对模型理解复杂指令集和执行多步骤任务的考验。测试结果显示,即使是开启了思考模式的 14B,以及参数量巨大的 235B,都未能完全遵从提示词中的所有要求,只给出了初步的回复或执行了部分步骤。这表明在处理需要严格按照复杂、多阶段指令执行的任务时,当前大模型的鲁棒性还有待提高。用户在设计提示词时,可能需要将复杂任务分解成更简单的步骤分步提问。
8. SQL 生成能力测试 (SQL Generation)
- 测试方法: 提供一个进销存数据库的表格结构描述 (包含表名、字段、字段类型等),然后提出几个基于该结构的查询需求 (例如“查询销量最高的商品”、“统计某个时间段的销售额”等),要求模型生成对应的 SQL 查询语句。
- 结果对比:
| 模型 | SQL 生成准确率 | 语法特异性 |
|---|---|---|
| 235B | 所有问题均正确 | 标准 SQL |
| 32B | 大部分正确 | 其中一个问题使用了 SQL Server 特有语法 |
| 14B (思考模式) | 所有问题均正确 | 标准 SQL |
- 分析: 在根据数据库结构描述生成 SQL 语句方面,235B 和 14B (思考模式) 的表现都非常出色,能够准确理解查询需求并生成标准的、可执行的 SQL 语句。32B 在其中一个问题上使用了 SQL Server 的特有语法,虽然在特定环境下可能正确,但通用性不如标准 SQL。这个测试显示了 Qwen 3 系列在处理结构化查询语言任务上的强大能力,特别是 14B 在思考模式下的准确性令人印象深刻。
9. 逻辑谜题测试 (Farmer Crossing Puzzle)
- 测试方法: 经典的农夫、羊、狼过河问题的一个复杂变种,增加了苹果、鸡等多个元素和更复杂的规则(例如哪些东西不能单独放在一起,船能载几样东西等)。测试模型的复杂逻辑推理和步骤规划能力。
- 结果对比:
| 模型 | 解决情况 | 问题分析 |
|---|---|---|
| 235B | 中途出现幻觉,步骤错误 | 难以保持逻辑连贯性 |
| 32B | 第一步即出现错误 | 未能正确理解规则 |
| 14B (思考模式) | 中途步骤错误 | 未能找到最终解 |
- 分析: 这个复杂的逻辑推理问题对所有模型都构成了严峻挑战。没有一个模型能够给出完整的、步骤正确的解法。它们都在推理过程中出现了错误,或是未能理解规则,或是中途陷入逻辑困境。这再次表明,尽管大模型在很多任务上表现强大,但在需要多步、精确、无误的复杂逻辑推理和规划问题上,仍然是其弱项。
10. 文档分析能力测试 (Document Analysis)
- 测试方法: 提供一篇较长的文档(例如论文摘要、技术文档片段),然后围绕文档内容设置几个问题,测试模型对文档信息的理解、提取和归纳能力。
- 结果对比:
| 模型 | 文档理解与提取 |
|---|---|
| 235B | 大部分问题正确 |
| 32B | 大部分问题正确 |
| 14B | 未能正确解析文档 |
- 分析: 235B 和 32B 模型在文档分析上表现良好,能够准确回答大部分基于文档内容的问题。然而,本地部署的 14B 模型在本次测试中未能成功解析文档内容,无法回答问题。这可能与本地部署环境、使用的 UI 工具在处理文档输入时的兼容性或稳定性有关,不完全代表模型本身的文档理解能力缺陷,但在实际本地部署应用中是需要注意的问题。
11. 算法与编程能力测试 (Algorithm & Programming)
- 测试方法:
- 算法题: 询问计算第 N 个质数的方法,并要求使用 Python 实现,且不能引入外部库。
- 编程题: 要求用 Python 实现一个简单的 2D 物理模拟(例如一个球在特定区域内的弹跳,需要考虑边界碰撞、反弹等)。
- 测试内容与结果简述:
| 测试内容 | 235B | 32B | 14B (思考模式) |
|---|---|---|---|
| 算法实现 (第 N 个质数) | 基本实现,效率低 | 更高效的实现方法 | 优化更好,效率最高 |
| 编程实现 (2D 物理模拟) | 代码无法运行 | 代码无法运行 | 代码可运行但功能不全 |
- 分析: 在算法实现方面,三个模型都能提供计算第 N 个质数的 Python 代码,但算法的优化程度和效率有所差异,14B 开启思考模式后给出的解法效率最高。然而,在更复杂的编程任务(如物理模拟)上,模型的表现就显得力不从心了。235B 和 32B 提供的代码均存在问题,无法直接运行。14B 提供的代码虽然能够运行,但并未完全实现题目要求的物理细节(如准确的碰撞检测和反弹逻辑)。这表明当前的大模型可以作为编程助手或代码片段生成器,但在独立完成复杂、包含精确逻辑的编程任务时,仍然需要人类的介入和调试。
四、 测试结果总结与模型选择建议
通过上述一系列多维度、涵盖不同能力的测试,我们可以对通义千问 Qwen 3 系列模型有一个更全面的认识:
- Qwen 3 系列整体能力强大: 相较于前代模型和其他同类模型,Qwen 3 在知识问答、逻辑推理、结构化输出、代码生成等多个维度都展现出了显著的进步和强大的通用能力。
- 14B (思考模式) 表现亮眼,性价比极高: 这是一个非常令人惊喜的发现。在开启“思考模式”后,14B 模型在某些复杂的逻辑推理(如矩阵填充)、需要精确结构化输出和内部计算的任务(如 JSON 格式化)中,表现甚至能够超越参数量远大于它的 235B 和 32B 模型。考虑到 14B 模型更容易在本地部署,它无疑是资源有限场景下的一个“黑马”选项。
- 不同模型各有侧重:
- 235B: 作为系列中最大的模型,在知识的广度和某些复杂任务(如 SQL 生成、文档分析)上表现稳定,是追求顶级通用能力的优先选项(当然,需要强大的计算资源)。
- 32B: 知识非常新(截止到 2024 年 10 月),在基础问答和部分逻辑任务上表现良好。它是一个平衡性能和资源需求的优秀选择,但在复杂推理和幻觉控制方面略逊于开启思考模式的 14B 和 235B。
- 14B (思考模式): 在本地部署/资源受限场景下,提供了超乎预期的强大推理和结构化输出能力,非常适合个人开发者、中小型企业或需要在本地处理复杂任务的应用。
- 模型仍有进步空间: 在需要极强的多步骤、精确逻辑推理(如复杂谜题)、严格遵从复杂指令、以及生成复杂且功能完整的代码/可视化图表方面,当前的模型(包括 Qwen 3)仍然面临挑战,需要进一步的优化。
基于以上测试结果,我们给出以下模型选择建议:
- 如果你追求极致的性能和最全面的能力: 并且拥有充足的计算资源(如多张高端 GPU 的服务器),那么 235B 或更大的 MoE 模型 是你的不二之选,它们代表了当前通义千问系列的最高水平。
- 如果你需要平衡性能与计算资源: 并且主要处理通用性的文本生成、问答、翻译等任务,那么 32B 模型 是一个非常不错的中间选项,它提供了良好的能力和相对可控的资源需求。
- 如果你希望在本地进行部署、资源相对有限,或者需要处理一些需要一定逻辑推理和结构化输出的任务: 那么 14B 模型,特别是在支持开启“思考模式”的框架下,是一个强烈推荐的选择。它的性价比极高,在许多任务上都能提供接近甚至超越参数量更大模型的表现。对于大多数个人使用、学习研究或企业内部的轻量级应用场景,14B 已经完全能够胜任。
总而言之,阿里巴巴通义千问 Qwen 3 系列的发布,无疑为大模型的技术发展和实际应用注入了新的活力。特别是提供了强大的、可本地部署的模型选项,让更多开发者和用户能够亲手体验和利用大模型的强大能力。希望本文的本地部署指南和能力测评能帮助你更好地了解、选择和使用 Qwen 3 模型。