神经网络—损失函数
文章目录
- 前言
- 一、损失函数概念
- 二、损失函数原理
- 1、分类问题中常见的损失函数
- (1)0-1损失函数
- 原理
- 优缺点
- (2)交叉熵损失(Cross-Entropy Loss)
- 原理
- 优缺点
- (3) 合页损失(Hinge Loss)
- 原理
- 优缺点
- 2、回归问题中常见的损失函数
- (1) 均方误差(Mean Squared Error, MSE)
- 原理
- 优缺点
- (2) 平均绝对误差(Mean Absolute Error, MAE)
- 原理
- 优缺点
- 总结
前言
损失函数在神经网络中充当核心导航者,通过量化预测与真实值的差异,为模型训练明确优化目标(如最小化误差)。它不仅评估当前性能,还通过反向传播计算梯度,指导参数调整方向,确保任务适配(如分类用交叉熵、回归用均方误差),并可通过正则化项控制模型复杂度,防止过拟合,是驱动整个学习过程的关键机制。
一、损失函数概念
神经网络中的损失函数(Loss Function)用于量化模型预测结果与真实值之间的差距,作为衡量模型性能的核心指标。它通过计算预测误差(如分类错误或回归偏差),为反向传播提供梯度方向,指导优化算法(如梯度下降)调整网络权重和偏置,逐步缩小误差,使模型输出逼近真实数据分布。不同任务对应不同损失函数(如交叉熵用于分类、均方误差用于回归),其本质是定义模型优化的目标函数。
二、损失函数原理
1、分类问题中常见的损失函数
(1)0-1损失函数
0-1损失函数是分类任务中最直观的损失函数之一,主要用于衡量分类模型的错误率。其核心思想是:若预测结果与真实标签一致,则损失为0;若不一致,则损失为1。
原理
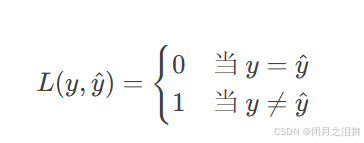
y:真实标签(如分类任务中的类别)。
y^:模型的预测结果。
对于所有样本,0-1损失是错误分类样本的占比:
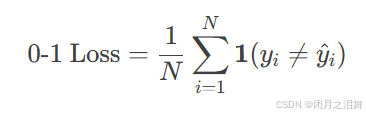
1(⋅) 是指示函数(条件满足时为1,否则为0)。
优缺点
优点:
1、直观性:直接反映分类错误率(如准确率 = 1 - 0-1损失)。
2、无参数依赖:仅关注分类结果的对错,不依赖预测概率的置信度。
缺点:
1、无法梯度优化:函数是离散的、非凸的,梯度几乎处处为0或不存在,无法通过梯度下降等算法优化模型参数。
2、对概率不敏感:即使预测概率接近真实标签(如正确类别概率为0.51,错误类别为0.49),只要最终分类错误,损失值仍为1。
(2)交叉熵损失(Cross-Entropy Loss)
原理
交叉熵衡量两个概率分布之间的差异。在分类任务中,真实标签是one-hot编码的确定分布(如类别3的概率为1,其余为0),而模型输出是预测的概率分布。交叉熵通过计算两者之间的信息差异,指导模型调整预测概率逼近真实分布。
公式:
对于单个样本的多分类任务:
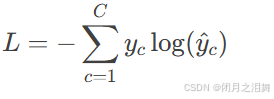

与Softmax的配合,Softmax将模型输出的原始得分(logits)转换为概率分布,交叉熵直接优化该分布与真实标签的匹配度,梯度计算高效。
优缺点
优点:梯度更新方向明确,收敛速度快。
缺点:对类别不平衡敏感,需结合加权或采样策略。
适用于绝大多数分类任务(如文本分类、图像识别)。
(3) 合页损失(Hinge Loss)
原理
数学定义:合页损失用于最大化分类边界(Margin),要求正确类别的得分比其他类别至少高出一个固定边界值(通常为1)。
公式推导:
对于二分类任务,标签编码为yi∈{−1,1},模型输出为原始得分y^i (未归一化):
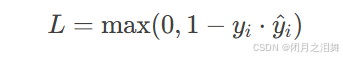
 对于多分类问题
对于多分类问题

优缺点
优点:生成清晰的分类边界,对噪声鲁棒。
缺点:不直接输出概率,需后处理(如Platt Scaling)。
适用场景:支持向量机(SVM)、需要强分类边界的任务。
2、回归问题中常见的损失函数
(1) 均方误差(Mean Squared Error, MSE)
原理
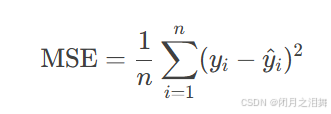
优缺点
优点:数学性质良好(处处可导),梯度计算高效,适合梯度下降优化。
缺点:对离群点敏感(平方放大误差),可能导致模型过度拟合异常值。
适用场景:数据噪声较小且分布均匀的任务(如温度预测、房价回归)。
(2) 平均绝对误差(Mean Absolute Error, MAE)
原理
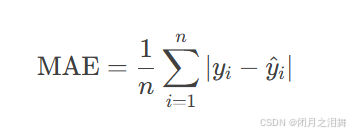
优缺点
优点:对离群点鲁棒(线性惩罚),梯度稳定。
缺点:在零点处不可导,收敛速度可能较慢。
适用场景:存在明显离群点的数据(如传感器噪声数据)。
总结

损失函数在神经网络中反映的是模型预测结果与真实标签之间的差异程度,损失函数将模型的预测(如分类概率、回归值)与真实标签(Ground Truth)的差异转化为数值形式。
模型应该向损失函数更小的方向发展,反应在图片上,既是针对一个下山的任务,损失函数就是此刻下山者距离山底的长度,那么距离山脚越近那么越接近终点。
损失函数是模型训练的“指南针”,通过量化误差生成梯度信号,驱动参数沿降低损失的方向迭代更新。其设计需兼顾数学可导性、任务适配性及鲁棒性,直接影响模型的收敛速度与最终性能。理解损失函数与参数更新的关系,是掌握神经网络训练机制的核心。