Qwen3-8B安装与体验-速度很快!
目录
步骤一、下载模型
步骤二、安装模型依赖包
步骤三、写代码
步骤四、运行代码
步骤五、中文提问 & 运行代码
步骤一、下载模型
安装下载命令
pip install modelscope
下载模型
modelscope download --model Qwen/Qwen3-8B --local_dir /root/autodl-tmp/Qwen/Qwen3-8B
步骤二、安装模型依赖包
pip install transformers peft diffusers
步骤三、写代码
from modelscope import AutoModelForCausalLM, AutoTokenizermodel_name = "/root/autodl-tmp/Qwen/Qwen3-8B"# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name,torch_dtype="auto",device_map="auto"
)
# prepare the model input
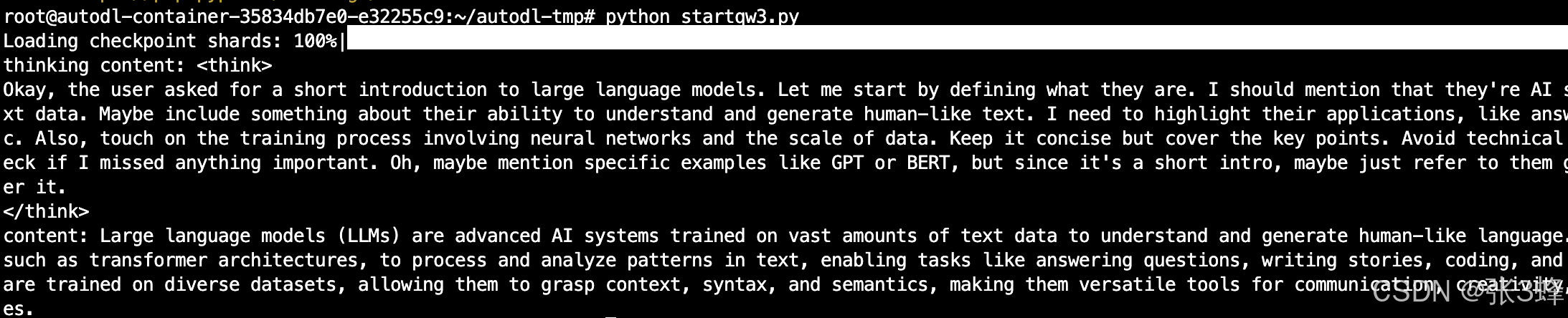
prompt = "Give me a short introduction to large language model."
messages = [{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True,enable_thinking=True # Switches between thinking and non-thinking modes. Default is True.
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)# conduct text completion
generated_ids = model.generate(**model_inputs,max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist() # parsing thinking content
try:# rindex finding 151668 (</think>)index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:index = 0thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")print("thinking content:", thinking_content)
print("content:", content)步骤四、运行代码
python startqw3.py
步骤五、中文提问 & 运行代码
from modelscope import AutoModelForCausalLM, AutoTokenizermodel_name = "/root/autodl-tmp/Qwen/Qwen3-8B"# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name,torch_dtype="auto",device_map="auto"
)
# prepare the model input
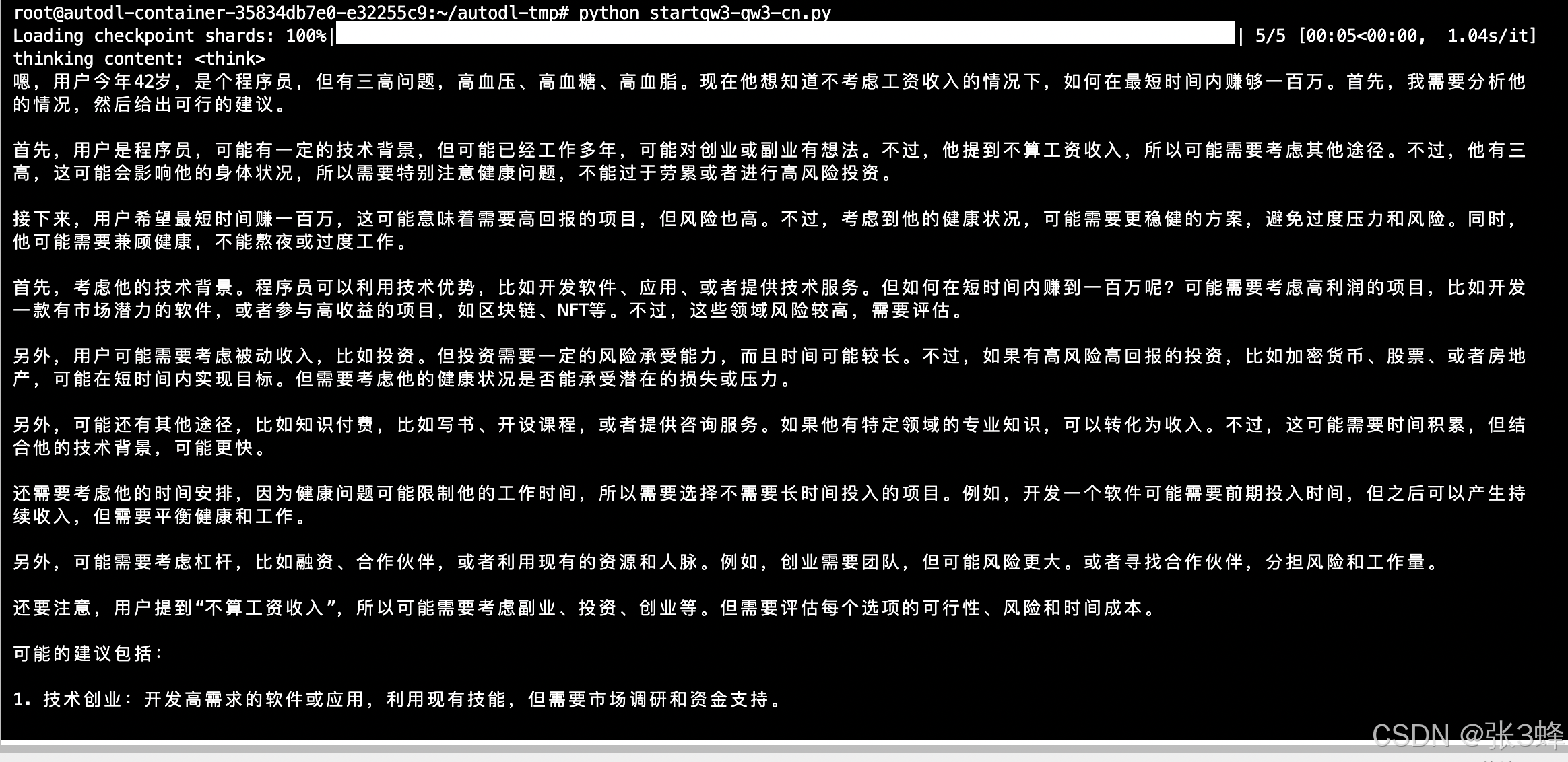
prompt = "1.我今年42岁是个程序员。2.我三高,高血压高血糖高血脂。3.不算工资收入,我如何在最短的时间内赚够一百万。请用中文思考和回复"
messages = [{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True,enable_thinking=True # Switches between thinking and non-thinking modes. Default is True.
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)# conduct text completion
generated_ids = model.generate(**model_inputs,max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist() # parsing thinking content
try:# rindex finding 151668 (</think>)index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:index = 0thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")print("thinking content:", thinking_content)
print("content:", content)