深入剖析扩散模型对镜子反射理解局限:MirrorVerse 项目改进数据集与训练方法以提升反射处理表现的研究
概述
自从生成式人工智能开始引起公众关注以来,计算机视觉研究领域对开发能够理解和复制物理定律的人工智能模型的兴趣日益浓厚。然而,教导机器学习系统模拟诸如重力和液体动力学等现象的挑战,至少在过去五年一直是研究工作的重点。
自2022年潜在扩散模型(LDMs)主导生成式人工智能领域以来,研究人员越来越关注LDM架构在理解和再现物理现象方面的有限能力。如今,随着OpenAI具有里程碑意义的生成式视频模型Sora的推出,以及开源视频模型混元视频和Wan 2.1的发布(后者可能影响更为深远),这一问题变得更加突出。
反射效果不佳
大多数旨在提高LDM对物理现象理解的研究都集中在步态模拟、粒子物理和牛顿运动的其他方面。这些领域受到关注是因为基本物理行为的不准确会立即破坏人工智能生成视频的真实性。
然而,有一小部分但在不断增长的研究集中在LDM的一个最大弱点上——它相对缺乏生成准确反射的能力。

摘自2025年1月的论文《反射现实:使扩散模型能够产生逼真的镜面反射》,展示了“反射失败”的示例以及研究人员自己的方法。 来源:https://arxiv.org/pdf/2409.14677
这个问题在计算机图形图像(CGI)时代也是一个挑战,并且在视频游戏领域仍然存在。在该领域,光线追踪算法用于模拟光线与表面相互作用的路径。光线追踪通过计算虚拟光线如何从物体上反射或穿过物体,来创建逼真的反射、折射和阴影效果。
然而,每增加一次反射都会极大地增加计算成本,因此实时应用程序必须通过限制允许的光线反射次数来在延迟和准确性之间进行权衡。
在传统基于3D(即CGI)的场景中,对虚拟计算的光束的表示,使用了20世纪60年代首次开发的技术和原理,并在1982 - 1993年(从《创:战纪》[1982年]到《侏罗纪公园》[1993年])达到顶峰。 来源:https://www.unrealengine.com/en-US/explainers/ray-tracing/what-is-real-time-ray-tracing
例如,描绘一个放在镜子前的镀铬茶壶可能涉及一个光线追踪过程,其中光线在反射表面之间反复反射,形成一个几乎无限的循环,但对最终图像的实际效果提升有限。在大多数情况下,反射深度达到两到三次就已经超出了观众的感知范围。如果只进行一次反射,镜子会显示为黑色,因为光线至少需要完成两次传播才能形成可见的反射。
每增加一次反射都会急剧增加计算成本,通常会使渲染时间翻倍,因此更快地处理反射是提高光线追踪渲染质量的最重要机会之一。
自然地,反射在许多不太明显的场景中也会出现,并且对于实现照片级真实感至关重要。例如,雨后城市街道或战场的反光表面;商店橱窗或玻璃门中对面街道的反射;或者所描绘角色眼镜中的反射,其中可能需要呈现物体和环境。

在《黑客帝国》(1999年)的一个标志性场景中,通过传统合成技术实现的模拟双重反射。
图像问题
由于这个原因,在扩散模型出现之前流行的框架,如神经辐射场(NeRF),以及一些较新的模型,如高斯溅射,在自然地实现反射方面仍然面临挑战。
REF2 - NeRF项目(如下图所示)提出了一种基于NeRF的建模方法,用于处理包含玻璃箱的场景。在这种方法中,折射和反射使用依赖和独立于观察者视角的元素进行建模。这种方法使研究人员能够估计发生折射的表面,特别是玻璃表面,并能够分离和建模直接光和反射光的成分。

Ref2Nerf论文中的示例。 来源:https://arxiv.org/pdf/2311.17116
在过去4 - 5年中,其他针对NeRF的反射解决方案包括NeRFReN、反射现实和Meta在2024年的__平面反射感知神经辐射场__项目。
对于高斯溅射(GSplat),如Mirror - 3DGS、反射高斯溅射和RefGaussian等论文针对反射问题提供了解决方案,而2023年的Nero项目提出了一种将反射特性融入神经表示的定制方法。
MirrorVerse
让扩散模型遵循反射逻辑可能比使用诸如高斯溅射和NeRF等明确的结构、非语义方法更困难。在扩散模型中,只有当训练数据包含广泛场景中的各种不同示例时,这种规则才有可能可靠地嵌入模型中,这使得模型在很大程度上依赖于原始数据集的分布和质量。
传统上,添加此类特定行为是低秩自适应(LoRA)或对基础模型进行微调的范畴;但这些并不是理想的解决方案,因为LoRA即使在没有提示的情况下也倾向于使输出偏向其自身的训练数据,而微调——除了成本高昂之外——可能会使主要模型不可逆转地偏离主流,并产生一系列相关的定制工具,这些工具将无法与该模型的任何其他变体(包括原始模型)一起使用。
一般来说,改进扩散模型需要训练数据更加关注反射的物理原理。然而,许多其他领域也需要类似的特别关注。在超大规模数据集的背景下,定制数据整理既昂贵又困难,以这种方式解决每一个弱点是不切实际的。
尽管如此,解决LDM反射问题的方案还是不时出现。最近来自印度的一项努力是__MirrorVerse__项目,它提供了一个改进的数据集和训练方法,能够在扩散研究的这一特定挑战中提升当前的技术水平。

最右侧是MirrorVerse的结果,与中间两列的两种先前方法进行对比。 来源:https://arxiv.org/pdf/2504.15397
正如我们在上面的示例(新研究PDF中的特征图像)中看到的,MirrorVerse在解决相同问题的近期方法上有所改进,但远非完美。
在右上角的图像中,我们可以看到陶瓷罐子的位置比它们应该在的位置稍微偏右;而在下面的图像中,从技术上讲根本不应该有杯子的反射,但在右侧区域却生硬地添加了一个不准确的反射,这违背了自然反射角度的逻辑。
因此,我们关注这种新方法,不仅是因为它可能代表了基于扩散的反射技术的当前水平,还为了说明这对于静态和视频潜在扩散模型来说可能是一个难以解决的问题。因为反射率的必要数据示例很可能与特定的动作和场景纠缠在一起。
因此,LDM的这一特定功能可能仍然不如NeRF、GSplat等特定结构的方法,以及传统的CGI技术。
新论文的标题是__MirrorVerse:推动扩散模型真实地反射世界__,由印度科学学院班加罗尔视觉与人工智能实验室以及三星班加罗尔研发中心的三位研究人员撰写。该论文有一个[相关项目页面](https://mirror - verse.github.io/),以及一个在Hugging Face上的数据集,源代码在GitHub上发布。
方法
研究人员从一开始就注意到,像Stable Diffusion和Flux这样的模型在遵循基于反射的提示方面存在困难,并巧妙地说明了这个问题:

摘自论文:当前最先进的文本到图像模型SD3.5和Flux在被提示在场景中生成反射时,在产生一致且几何准确的反射方面表现出重大挑战。
研究人员开发了__MirrorFusion 2.0__,这是一个基于扩散的生成模型,旨在提高合成图像中镜面反射的照片级真实感和几何准确性。该模型的训练基于研究人员自己新整理的数据集__MirrorGen2__,该数据集旨在解决先前方法中观察到的泛化弱点。
MirrorGen2在早期方法的基础上进行了扩展,引入了__随机对象定位__、随机旋转__和__显式对象接地,目标是确保在相对于镜面的更广泛的对象姿势和放置范围内,反射仍然合理。
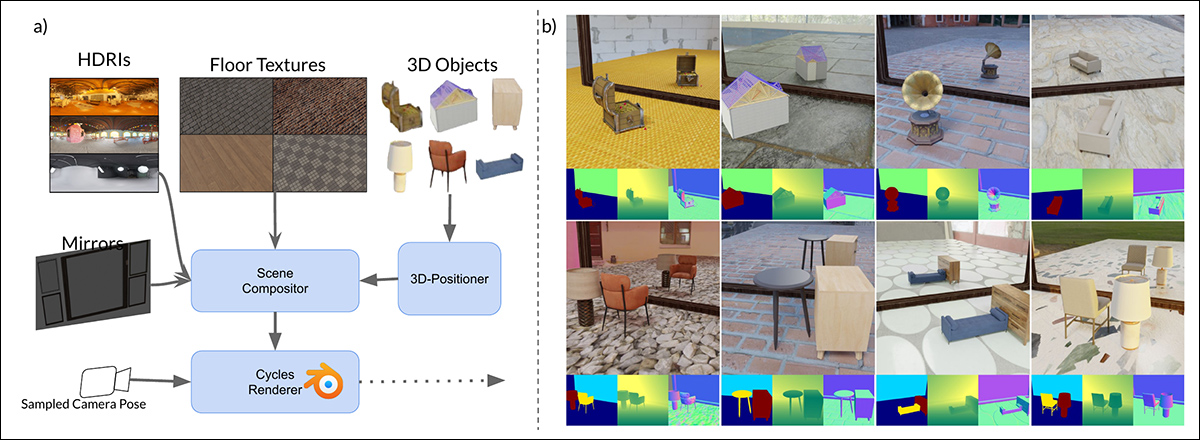
MirrorVerse中合成数据生成的示意图:数据集生成管道通过使用3D定位器在场景中随机定位、旋转和接地对象,应用了关键的增强技术。对象还以语义一致的组合进行配对,以模拟复杂的空间关系和遮挡,使数据集能够捕捉多对象场景中更真实的交互。
为了进一步增强模型处理复杂空间排列的能力,MirrorGen2管道纳入了__成对__对象场景,使系统能够更好地表示反射环境中多个元素之间的遮挡和交互。
论文中指出:
“类别是手动配对的,以确保语义一致性——例如,将椅子与桌子配对。在渲染过程中,在定位和旋转主[对象]之后,从配对类别中采样并安排一个额外的[对象],以防止重叠,确保场景内有不同的空间区域。”
关于显式对象接地,作者确保在输出的合成数据中,生成的对象“锚定”在地面上,而不是不恰当地“悬浮”,这种“悬浮”现象在大规模生成合成数据或使用高度自动化方法时可能会出现。
由于数据集创新是该论文新颖性的核心,我们将比通常更早地进入这部分内容的介绍。
数据和测试
SynMirrorV2
研究人员的SynMirrorV2数据集旨在提高镜面反射训练数据的多样性和真实性。该数据集的3D对象来自Objaverse和亚马逊伯克利对象(ABO)数据集,随后通过OBJECT 3DIT以及V1 MirrorFusion项目的过滤过程对这些选择进行了细化,以消除低质量的资产。最终得到了一个包含66,062个对象的精炼池。

Objaverse数据集中的示例,用于创建新系统的整理数据集。 来源:https://arxiv.org/pdf/2212.08051
场景构建涉及将这些对象放置在来自CC - Textures的纹理地板和来自PolyHaven CGI仓库的高动态范围图像(HDRI)背景上,使用全墙或高矩形镜子。照明使用一个位于对象上方和后方45度角的区域光进行标准化。对象被缩放以适应一个单位立方体,并使用预先计算的镜子和相机视角视锥体的交集进行定位,以确保可见性。
围绕y轴应用了随机旋转,并使用接地技术来防止“漂浮伪影”。
为了模拟更复杂的场景,数据集还纳入了根据ABO类别基于语义一致的配对安排的多个对象。次要对象被放置以避免重叠,创建了3,140个多对象场景,旨在捕捉不同的遮挡和深度关系。

作者数据集中包含多个(超过两个)对象的渲染视图示例,下方可见对象分割和深度图可视化的图示。
训练过程
研究人员认识到,仅靠合成的真实性不足以使模型强大地泛化到真实世界的数据,因此为训练MirrorFusion 2.0开发了一个三阶段的课程学习过程。
在第一阶段,作者使用Stable Diffusion v1.5检查点初始化了条件分支和生成分支的权重,并在SynMirrorV2数据集的单对象训练分割上对模型进行了微调。与上述__反射现实__项目不同,研究人员没有冻结生成分支。然后他们对模型进行了40,000次迭代的训练。
在第二阶段,模型在SynMirrorV2的多对象训练分割上又进行了10,000次迭代的微调,以教导系统处理遮挡和现实场景中更复杂的空间排列。
最后,在第三阶段,使用来自MSD数据集的真实世界数据进行了额外的10,000次迭代的微调,使用由Matterport3D单目深度估计器生成的深度图。

MSD数据集中的示例,真实世界场景被分析为深度和分割图。 来源:https://arxiv.org/pdf/1908.09101
在训练过程中,20%的训练时间省略了文本提示,以鼓励模型充分利用可用的深度信息(即“掩码”方法)。
所有阶段的训练都在四个NVIDIA A100 GPU上进行(未提供显存规格,但每张卡可能是40GB或80GB)。在AdamW优化器下,使用1e - 5的学习率,每个GPU的批量大小