机器学习的一百个概念(13)布里尔分数
前言
本文隶属于专栏《机器学习的一百个概念》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!
本专栏目录结构和参考文献请见[《机器学习的一百个概念》
ima 知识库
知识库广场搜索:
| 知识库 | 创建人 |
|---|---|
| 机器学习 | @Shockang |
| 机器学习数学基础 | @Shockang |
| 深度学习 | @Shockang |
思维导图
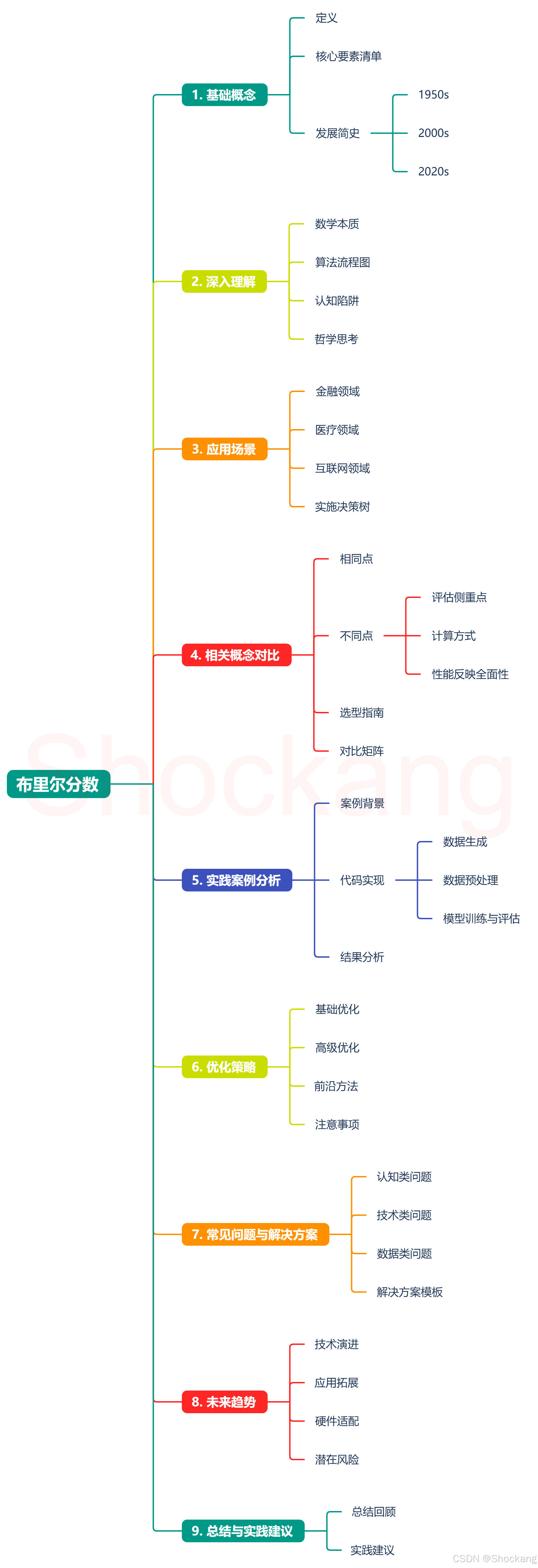
📚 第一章:基础概念
📌|🌟 一、基础概念
🔍 定义:
布里尔分数(Brier Score)宛如一个给概率预测“打分”的得力工具哦。想象一下,当你猜测明天是否会下雨时,心里会有一个觉得会下雨的可能性数值,比如60%,这就类似模型预测的概率 p ^ i \hat{p}_i p^i 啦。而第二天到底下没下雨则对应着真实情况,也就是真实标签 y i y_i yi(下雨了就是1,没下就是0)。布里尔分数呢,就是把针对众多不同猜测(也就是很多个样本)时,你心里猜的可能性和实际发生情况之间的差距,通过特定的计算方式( B S = 1 N ∑ i = 1 N ( y i − p ^ i ) 2 BS=\frac{1}{N}\sum_{i = 1}^{N}(y_i-\hat{p}_i)^2 BS=N1∑i=1N(yi−p^i)2,这里 N N N是样本数量哦)算出一个总的分数。这个分数越小,就表明你对下雨这件事的概率预测得越精准呢,对于模型来说也是同样的道理呀。
👉 核心要素清单:
❗️要点一:它是用于衡量概率预测准确性的评估指标,适用于二分类或多分类问题哦,这意味着它能帮我们查看模型猜某个样本属于某一类的概率准不准,比如猜某个人得某种病的概率呀。
❗️要点二:计算方式是通过计算预测概率与真实标签之间的均方误差来评估模型的预测能力的,也就是按照那个公式 B S = 1 N ∑ i = 1 N ( y i − p ^ i ) 2 BS=\frac{1}{N}\sum_{i = 1}^{N}(y_i-\hat{p}_i)^2 BS=N1∑i=1N(yi−p^i)2 来算哦,要牢记这个公式呢。
❗️要点三:它主要关注的是预测概率和实际发生情况(真实标签)之间的差异程度,是从这个角度来衡量模型好坏的,不像有些指标只看分类结果对不对哦。
🕰️ 发展简史:
- 1950s:
🚀 诞生背景:布里尔分数最初由Glenn W. Brier于1950年提出呢,那个时候呀,它主要是应用在天气预报的概率预测分析领域哦。当时的技术突破点就是人们意识到需要一种更科学的方法来衡量天气预报中对天气情况(比如降雨、晴天等)的概率预测到底准不准呀,于是布里尔分数就应运而生啦,它给气象领域评估概率预测模型的准确性提供了一个很好的量化工具呢。
经过对其诞生背景的了解,我们能更好地明白它后续是如何发展演变的哦。
- 2000s:
⚡ 关键改进:在2000s期间呀,随着计算机技术的发展以及机器学习领域的逐渐兴起,布里尔分数虽然核心的计算方式和基本概念没有太大改变,但它开始被更多地应用到了除气象领域之外的其他领域哦。比如在一些简单的分类任务中,人们开始尝试用它来评估模型预测概率的准确性,这也算是它应用范围上的一种拓展和改进啦,让更多的研究者和实践者认识到了它的价值呢。
从这里可以看出,随着时代发展,它的应用领域在不断拓宽呢。
- 2020s:
🔮 最新形态:到了2020s呀,布里尔分数在多分类任务中的应用更加成熟啦,而且在和其他一些先进的机器学习技术结合方面也有了一些新的探索哦。比如说在一些复杂的多分类场景下,人们会结合深度学习等技术,尝试用布里尔分数更精准地评估模型在概率预测方面的性能,并且也在不断研究如何根据布里尔分数的评估结果更好地优化模型呢,这就是它在这个时期的一些技术演进啦。
理解了这些基础概念和发展历程,我们就能更深入地探究布里尔分数的内在原理以及它在不同场景下的具体表现哦。接下来让我们一起进入【深入理解】章节吧。
🚀 第二章:深入理解
🚀|🌟 二、深入理解
📐 数学本质:
布里尔分数的数学本质是通过计算预测概率与真实标签之间的均方误差(MSE)来衡量模型的预测能力。其核心数学公式为: Brier Score = 1 N ∑ i = 1 N ( p i − y i ) 2 \text{Brier Score} = \frac{1}{N} \sum_{i=1}^N (p_i - y_i)^2 Brier Score=N1i=1∑N(pi−yi)