【完整源码+数据集+部署教程】室内场景分割系统源码和数据集:改进yolo11-DWR
背景意义
研究背景与意义
随着智能家居和自动化技术的快速发展,室内场景理解在计算机视觉领域中变得愈发重要。室内场景分割不仅是计算机视觉的基础任务之一,也是实现智能家居、机器人导航、增强现实等应用的关键技术。传统的图像分割方法在处理复杂的室内环境时往往面临诸多挑战,如光照变化、物体遮挡和背景复杂性等。因此,开发一种高效且准确的室内场景分割系统显得尤为重要。
YOLO(You Only Look Once)系列模型因其快速和高效的特性,已成为目标检测和分割领域的热门选择。YOLOv11作为该系列的最新版本,进一步提升了模型的准确性和实时性。然而,针对室内场景的特定需求,YOLOv11的标准配置可能并不足以满足所有应用场景的要求。因此,改进YOLOv11以适应室内场景分割,尤其是在对天花板、墙壁等特定类别进行精准识别和分割,将为智能家居系统的实现提供强有力的支持。
本研究基于ADE20K数据集,该数据集包含2500幅经过精确标注的室内场景图像,涵盖了天花板、墙壁等关键类别。通过对这些图像进行深度学习训练,模型能够有效学习到室内环境的特征,从而实现高效的场景分割。研究的意义在于,不仅为室内场景分割提供了一种新的技术方案,也为相关领域的研究提供了数据支持和理论基础。通过改进YOLOv11模型,期望能够提升室内场景分割的准确性和实时性,为未来的智能家居、机器人导航等应用奠定坚实的基础。
图片效果
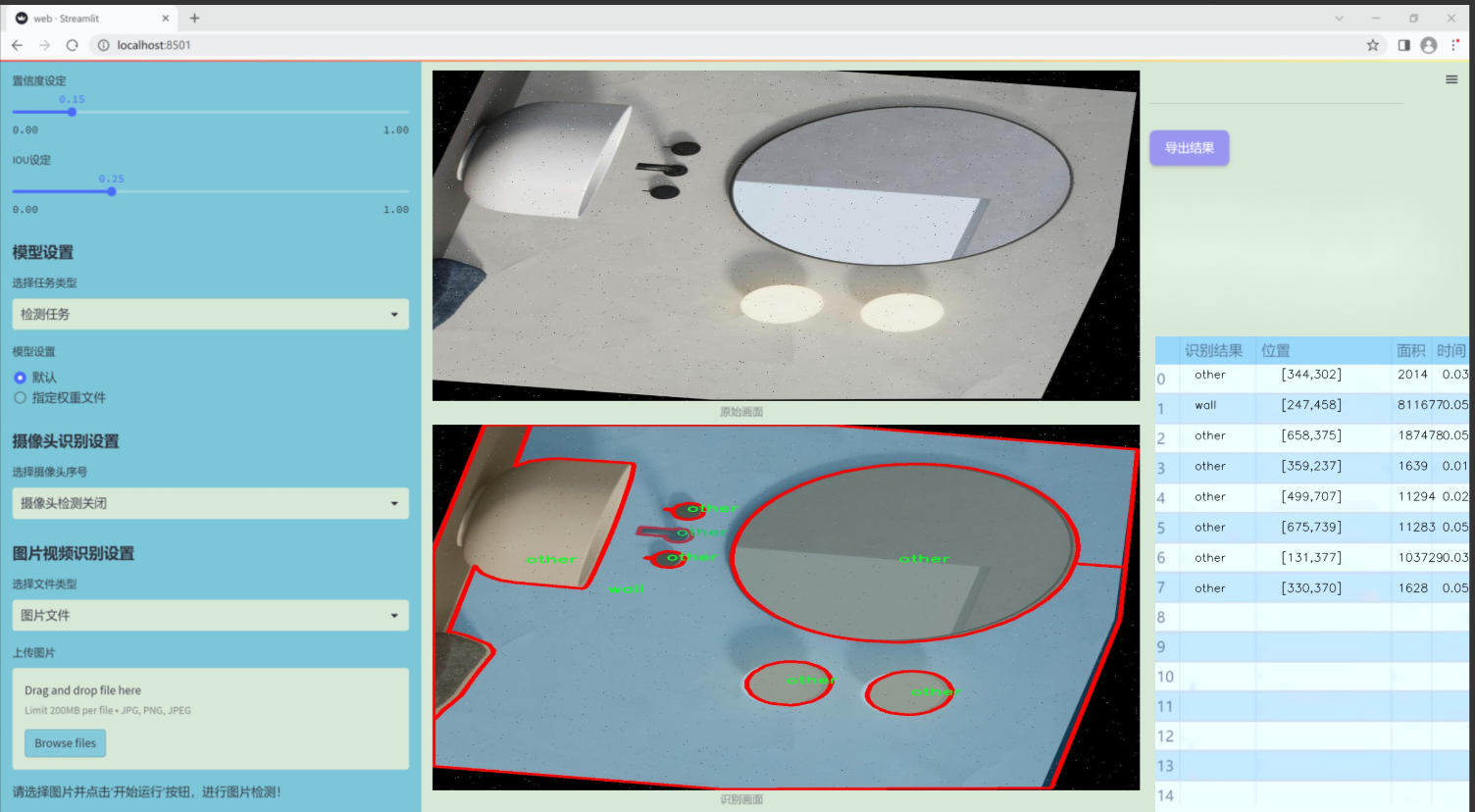
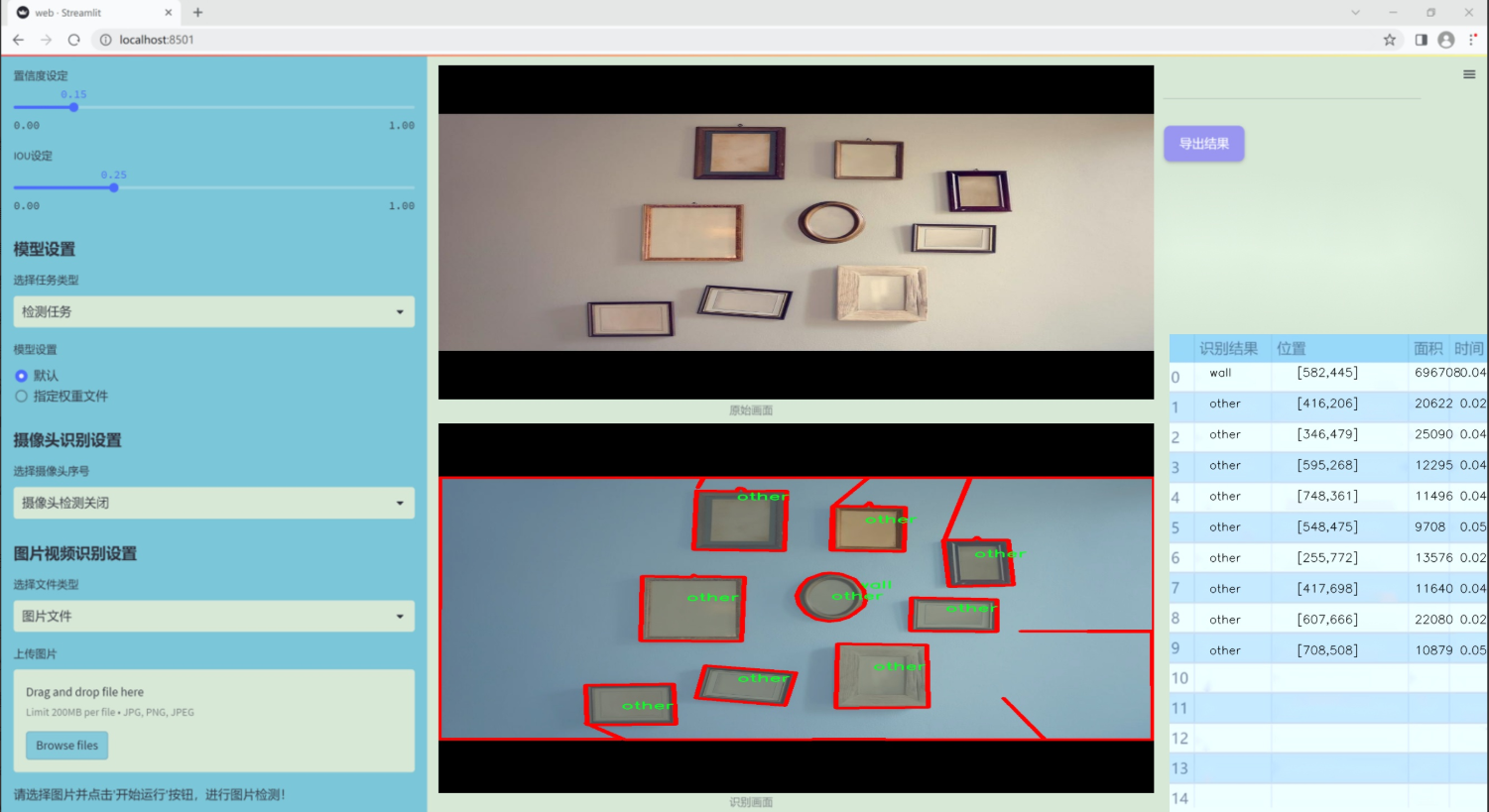
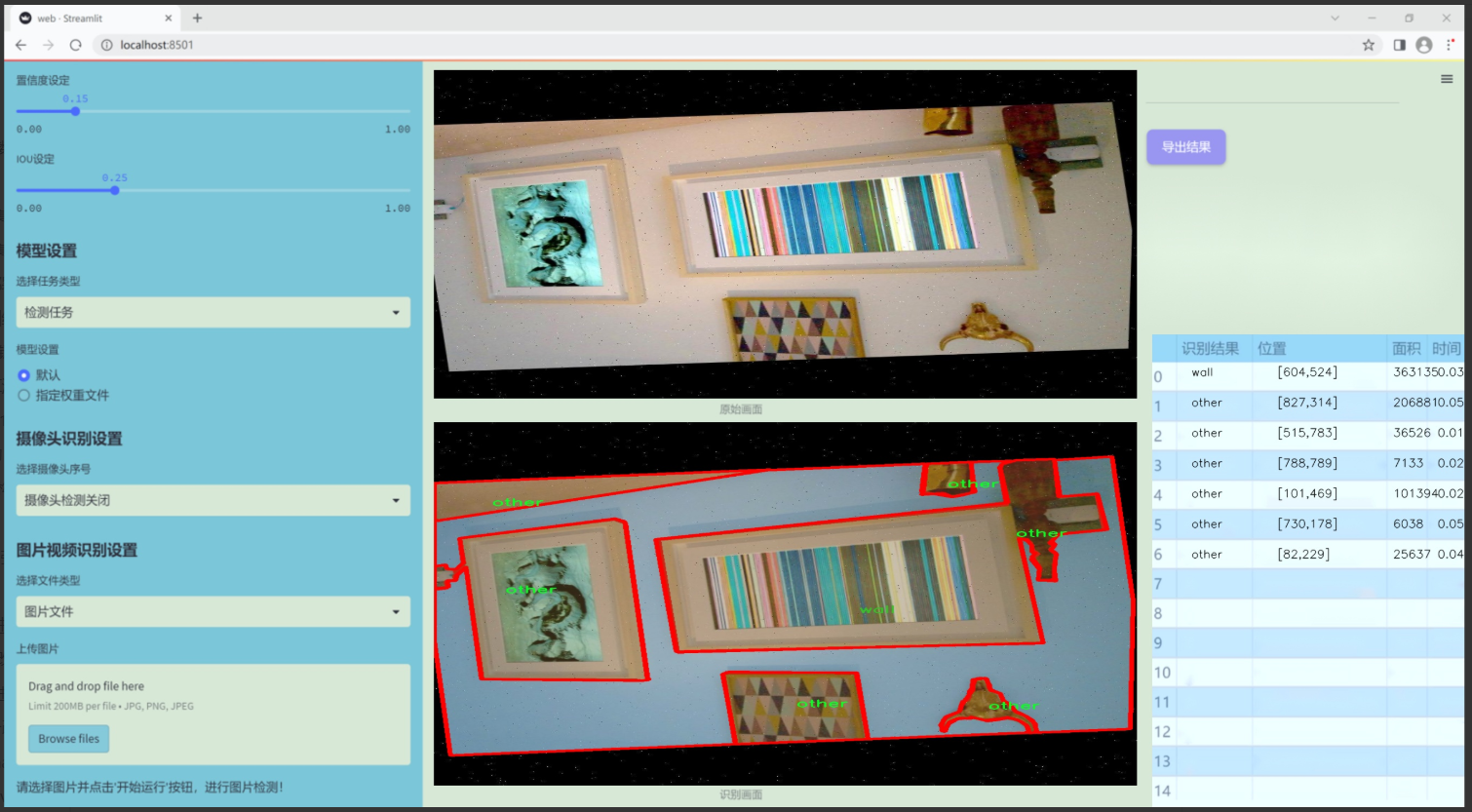
数据集信息
本项目数据集信息介绍
本项目所使用的数据集为“ade20k-dataset-v4.0.1”,该数据集专注于室内场景的分割任务,旨在为改进YOLOv11的室内场景分割系统提供丰富的训练素材。该数据集包含三种主要类别,分别是“ceiling”(天花板)、“other”(其他)和“wall”(墙壁),共计三个类别。这些类别的选择反映了室内环境中常见的结构元素,为模型的训练提供了必要的多样性和代表性。
在数据集的构建过程中,研究团队对每一类进行了精细的标注,以确保在训练过程中,模型能够准确识别和分割出不同的室内元素。天花板作为室内空间的重要组成部分,其形状、颜色和材质的多样性为模型的学习提供了丰富的特征信息。墙壁则是室内环境的基础构件,其位置和设计风格直接影响空间的视觉效果和功能性。而“其他”类别则涵盖了各种可能出现的室内物体和结构,确保模型在面对复杂场景时能够具备更强的适应能力。
通过对这些类别的深度学习,改进后的YOLOv11模型将能够在多种室内环境中实现更高效的分割,提升其在实际应用中的表现。这一数据集不仅为模型提供了必要的训练基础,也为后续的测试和验证提供了可靠的数据支持。随着对室内场景理解的不断深入,模型的分割精度和实时性将得到显著提升,为智能家居、室内导航等应用场景的实现奠定坚实的基础。
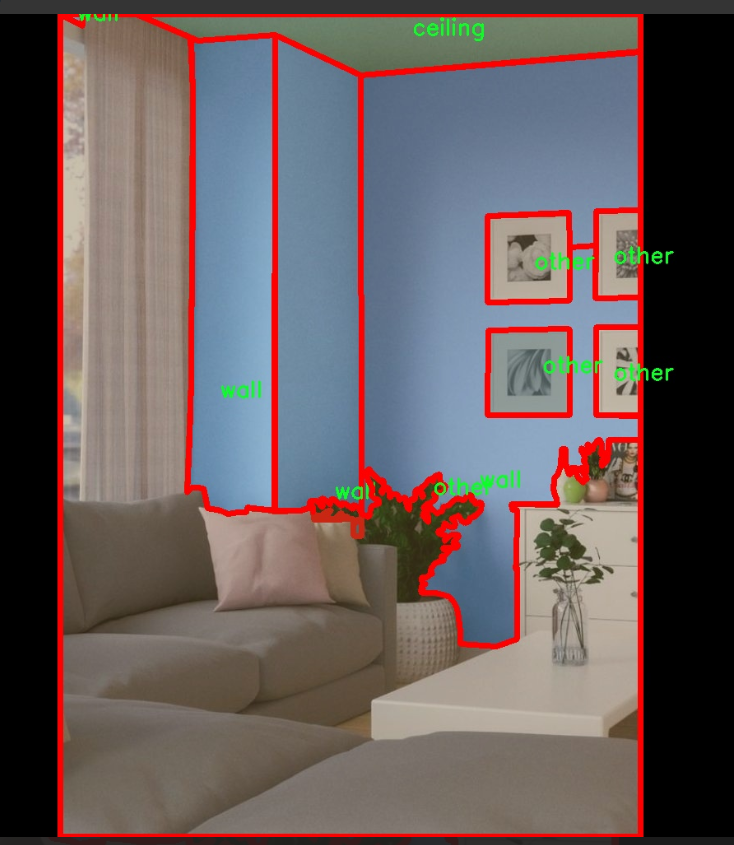




核心代码
以下是经过简化并添加详细中文注释的核心代码部分:
import torch
import torch.nn as nn
class KACNConvNDLayer(nn.Module):
def init(self, conv_class, norm_class, input_dim, output_dim, degree, kernel_size,
groups=1, padding=0, stride=1, dilation=1,
ndim: int = 2, dropout=0.0):
super(KACNConvNDLayer, self).init()
# 初始化参数self.inputdim = input_dim # 输入维度self.outdim = output_dim # 输出维度self.degree = degree # 多项式的阶数self.kernel_size = kernel_size # 卷积核大小self.padding = padding # 填充self.stride = stride # 步幅self.dilation = dilation # 膨胀self.groups = groups # 分组卷积的组数self.ndim = ndim # 数据的维度(1D, 2D, 3D)# 初始化 dropout 层self.dropout = Noneif dropout > 0:if ndim == 1:self.dropout = nn.Dropout1d(p=dropout)elif ndim == 2:self.dropout = nn.Dropout2d(p=dropout)elif ndim == 3:self.dropout = nn.Dropout3d(p=dropout)# 检查 groups 参数的有效性if groups <= 0:raise ValueError('groups must be a positive integer')if input_dim % groups != 0:raise ValueError('input_dim must be divisible by groups')if output_dim % groups != 0:raise ValueError('output_dim must be divisible by groups')# 初始化归一化层self.layer_norm = nn.ModuleList([norm_class(output_dim // groups) for _ in range(groups)])# 初始化多项式卷积层self.poly_conv = nn.ModuleList([conv_class((degree + 1) * input_dim // groups,output_dim // groups,kernel_size,stride,padding,dilation,groups=1,bias=False) for _ in range(groups)])# 注册缓冲区,用于存储多项式的阶数arange_buffer_size = (1, 1, -1,) + tuple(1 for _ in range(ndim))self.register_buffer("arange", torch.arange(0, degree + 1, 1).view(*arange_buffer_size))# 使用 Kaiming 正态分布初始化卷积层的权重for conv_layer in self.poly_conv:nn.init.normal_(conv_layer.weight, mean=0.0, std=1 / (input_dim * (degree + 1) * kernel_size ** ndim))def forward_kacn(self, x, group_index):# 对输入进行前向传播x = torch.tanh(x) # 应用tanh激活函数x = x.acos().unsqueeze(2) # 计算反余弦并增加维度x = (x * self.arange).flatten(1, 2) # 乘以阶数并展平x = x.cos() # 计算余弦x = self.poly_conv[group_index](x) # 通过对应的卷积层x = self.layer_norm[group_index](x) # 归一化if self.dropout is not None:x = self.dropout(x) # 应用dropoutreturn xdef forward(self, x):# 前向传播的主函数split_x = torch.split(x, self.inputdim // self.groups, dim=1) # 按组分割输入output = []for group_ind, _x in enumerate(split_x):y = self.forward_kacn(_x.clone(), group_ind) # 对每组进行前向传播output.append(y.clone()) # 存储输出y = torch.cat(output, dim=1) # 合并所有组的输出return y
代码说明:
KACNConvNDLayer: 这是一个自定义的卷积层,支持多维卷积(1D, 2D, 3D)。它使用多项式卷积和归一化层。
初始化方法: 在初始化中,设置了输入输出维度、卷积参数、分组数、dropout等,并进行了必要的参数检查。
前向传播: forward_kacn 方法实现了对输入的具体处理,包括激活、卷积和归一化等操作。
分组处理: forward 方法将输入分成多个组,分别通过 forward_kacn 进行处理,然后将结果合并。
这个程序文件定义了一个名为 kacn_conv.py 的模块,主要实现了一个自定义的卷积层,名为 KACNConvNDLayer,以及它的三个特化版本:KACNConv3DLayer、KACNConv2DLayer 和 KACNConv1DLayer。这些类是基于 PyTorch 框架构建的,利用了深度学习中的卷积操作。
首先,KACNConvNDLayer 类是一个通用的多维卷积层,它接受多个参数,包括卷积类型、归一化类型、输入和输出维度、卷积核大小、组数、填充、步幅、扩张、维度数量和 dropout 比例。构造函数中,首先调用父类的构造函数,然后初始化了多个属性,包括输入和输出维度、卷积核的相关参数等。特别地,dropout 只在指定的维度下被创建。
在参数验证方面,类确保了组数是正整数,并且输入和输出维度能够被组数整除。接着,类创建了一个归一化层的列表和一个多项式卷积层的列表,后者的数量与组数相同。多项式卷积层的权重使用 Kaiming 正态分布初始化,以便于训练的开始。
forward_kacn 方法是这个类的核心,定义了前向传播的具体操作。输入首先经过一个激活函数(双曲正切),然后进行一系列的数学变换,最后通过对应的卷积层和归一化层处理,并在必要时应用 dropout。
forward 方法则负责将输入张量按组进行分割,并对每个组调用 forward_kacn 方法,最后将所有组的输出拼接在一起,形成最终的输出。
接下来的三个类 KACNConv3DLayer、KACNConv2DLayer 和 KACNConv1DLayer 是对 KACNConvNDLayer 的特化,分别用于三维、二维和一维卷积操作。它们在构造函数中调用父类的构造函数,并传入相应的卷积和归一化层类型。
总体而言,这个文件实现了一个灵活且可扩展的卷积层结构,能够处理不同维度的输入数据,并通过多项式卷积和归一化操作来增强模型的表达能力。
10.4 RFAConv.py
以下是代码中最核心的部分,并附上详细的中文注释:
import torch
import torch.nn as nn
from einops import rearrange
class RFAConv(nn.Module):
def init(self, in_channel, out_channel, kernel_size, stride=1):
super().init()
self.kernel_size = kernel_size
# 通过平均池化和卷积生成权重self.get_weight = nn.Sequential(nn.AvgPool2d(kernel_size=kernel_size, padding=kernel_size // 2, stride=stride),nn.Conv2d(in_channel, in_channel * (kernel_size ** 2), kernel_size=1, groups=in_channel, bias=False))# 生成特征的卷积层self.generate_feature = nn.Sequential(nn.Conv2d(in_channel, in_channel * (kernel_size ** 2), kernel_size=kernel_size, padding=kernel_size // 2, stride=stride, groups=in_channel, bias=False),nn.BatchNorm2d(in_channel * (kernel_size ** 2)),nn.ReLU())# 最终的卷积层self.conv = nn.Conv2d(in_channel, out_channel, kernel_size=kernel_size, stride=kernel_size)def forward(self, x):b, c = x.shape[0:2] # 获取输入的批量大小和通道数weight = self.get_weight(x) # 计算权重h, w = weight.shape[2:] # 获取特征图的高度和宽度# 对权重进行softmax归一化weighted = weight.view(b, c, self.kernel_size ** 2, h, w).softmax(2) # b c*k**2, h, w# 生成特征并调整形状feature = self.generate_feature(x).view(b, c, self.kernel_size ** 2, h, w) # b c*k**2, h, w# 加权特征weighted_data = feature * weighted# 重新排列特征图conv_data = rearrange(weighted_data, 'b c (n1 n2) h w -> b c (h n1) (w n2)', n1=self.kernel_size, n2=self.kernel_size)return self.conv(conv_data) # 通过卷积层输出结果
class SE(nn.Module):
def init(self, in_channel, ratio=16):
super(SE, self).init()
self.gap = nn.AdaptiveAvgPool2d((1, 1)) # 全局平均池化
self.fc = nn.Sequential(
nn.Linear(in_channel, ratio, bias=False), # 通道压缩
nn.ReLU(),
nn.Linear(ratio, in_channel, bias=False), # 通道恢复
nn.Sigmoid() # 激活函数
)
def forward(self, x):b, c = x.shape[0:2] # 获取输入的批量大小和通道数y = self.gap(x).view(b, c) # 全局平均池化并调整形状y = self.fc(y).view(b, c, 1, 1) # 通过全连接层并调整形状return y # 返回通道注意力
class RFCBAMConv(nn.Module):
def init(self, in_channel, out_channel, kernel_size=3, stride=1):
super().init()
self.kernel_size = kernel_size
# 生成特征的卷积层self.generate = nn.Sequential(nn.Conv2d(in_channel, in_channel * (kernel_size ** 2), kernel_size, padding=kernel_size // 2, stride=stride, groups=in_channel, bias=False),nn.BatchNorm2d(in_channel * (kernel_size ** 2)),nn.ReLU())# 计算通道注意力的卷积层self.get_weight = nn.Sequential(nn.Conv2d(2, 1, kernel_size=3, padding=1, bias=False), nn.Sigmoid())self.se = SE(in_channel) # 通道注意力模块# 最终的卷积层self.conv = nn.Conv2d(in_channel, out_channel, kernel_size=kernel_size, stride=kernel_size)def forward(self, x):b, c = x.shape[0:2] # 获取输入的批量大小和通道数channel_attention = self.se(x) # 计算通道注意力generate_feature = self.generate(x) # 生成特征h, w = generate_feature.shape[2:] # 获取特征图的高度和宽度generate_feature = generate_feature.view(b, c, self.kernel_size ** 2, h, w) # 调整形状# 重新排列特征图generate_feature = rearrange(generate_feature, 'b c (n1 n2) h w -> b c (h n1) (w n2)', n1=self.kernel_size, n2=self.kernel_size)# 计算加权特征unfold_feature = generate_feature * channel_attention# 计算最大和平均特征max_feature, _ = torch.max(generate_feature, dim=1, keepdim=True)mean_feature = torch.mean(generate_feature, dim=1, keepdim=True)# 计算感受野注意力receptive_field_attention = self.get_weight(torch.cat((max_feature, mean_feature), dim=1))# 加权特征与感受野注意力相乘conv_data = unfold_feature * receptive_field_attentionreturn self.conv(conv_data) # 通过卷积层输出结果
代码核心部分解释:
RFAConv:该类实现了一种卷积操作,使用自适应权重来加权特征图。它首先通过平均池化和卷积生成权重,然后生成特征并通过softmax进行归一化,最后将加权特征输入到卷积层中。
SE:通道注意力模块,通过全局平均池化和全连接层来生成通道注意力权重,帮助模型关注重要的通道。
RFCBAMConv:结合了特征生成和通道注意力的卷积模块。它首先生成特征,然后计算通道注意力和感受野注意力,最后将这些信息结合起来进行卷积操作。
这些模块的设计旨在增强卷积神经网络的特征提取能力,通过注意力机制使模型能够更好地关注重要的特征。
这个程序文件 RFAConv.py 定义了一些基于卷积神经网络的模块,主要包括 RFAConv、RFCBAMConv 和 RFCAConv。这些模块使用了自定义的激活函数和注意力机制,旨在增强卷积操作的特征提取能力。
首先,文件中引入了必要的库,包括 PyTorch 和 einops。h_sigmoid 和 h_swish 是自定义的激活函数,分别实现了 h-sigmoid 和 h-swish。这些激活函数在前向传播中使用,提供了非线性变换的能力。
RFAConv 类是一个卷积模块,构造函数中定义了几个子模块。get_weight 模块通过平均池化和卷积操作生成权重,用于后续的特征加权。generate_feature 模块则通过卷积、批归一化和 ReLU 激活生成特征。conv 模块是最终的卷积操作。前向传播中,输入数据经过权重计算和特征生成后,进行加权和重排,最后通过卷积层输出结果。
SE 类实现了 Squeeze-and-Excitation (SE) 机制,用于通道注意力的计算。它通过全局平均池化和全连接层生成通道权重,并在前向传播中应用于输入特征。
RFCBAMConv 类结合了 RFAConv 和 SE 机制。它在构造函数中定义了生成特征和获取权重的模块。前向传播中,首先计算通道注意力,然后生成特征并进行重排,接着通过最大池化和平均池化获取特征的统计信息,最后结合通道注意力和接收场注意力进行卷积操作。
RFCAConv 类是另一个卷积模块,增加了对输入特征的高度和宽度的自适应池化。它通过生成特征、池化和卷积操作,计算出注意力权重,并将其应用于特征上。最终,输出通过卷积层生成。
整体来看,这个文件实现了一些先进的卷积模块,结合了特征生成、注意力机制和自适应操作,旨在提高模型的表现和特征提取能力。
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式