Java-114 深入浅出 MySQL 开源分布式中间件 ShardingSphere 深度解读
点一下关注吧!!!非常感谢!!持续更新!!!
🚀 AI篇持续更新中!(长期更新)
AI炼丹日志-31- 千呼万唤始出来 GPT-5 发布!“快的模型 + 深度思考模型 + 实时路由”,持续打造实用AI工具指南!📐🤖
💻 Java篇正式开启!(300篇)
目前2025年09月01日更新到:
Java-113 深入浅出 MySQL 扩容全攻略:触发条件、迁移方案与性能优化
MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈!
大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解
基本介绍
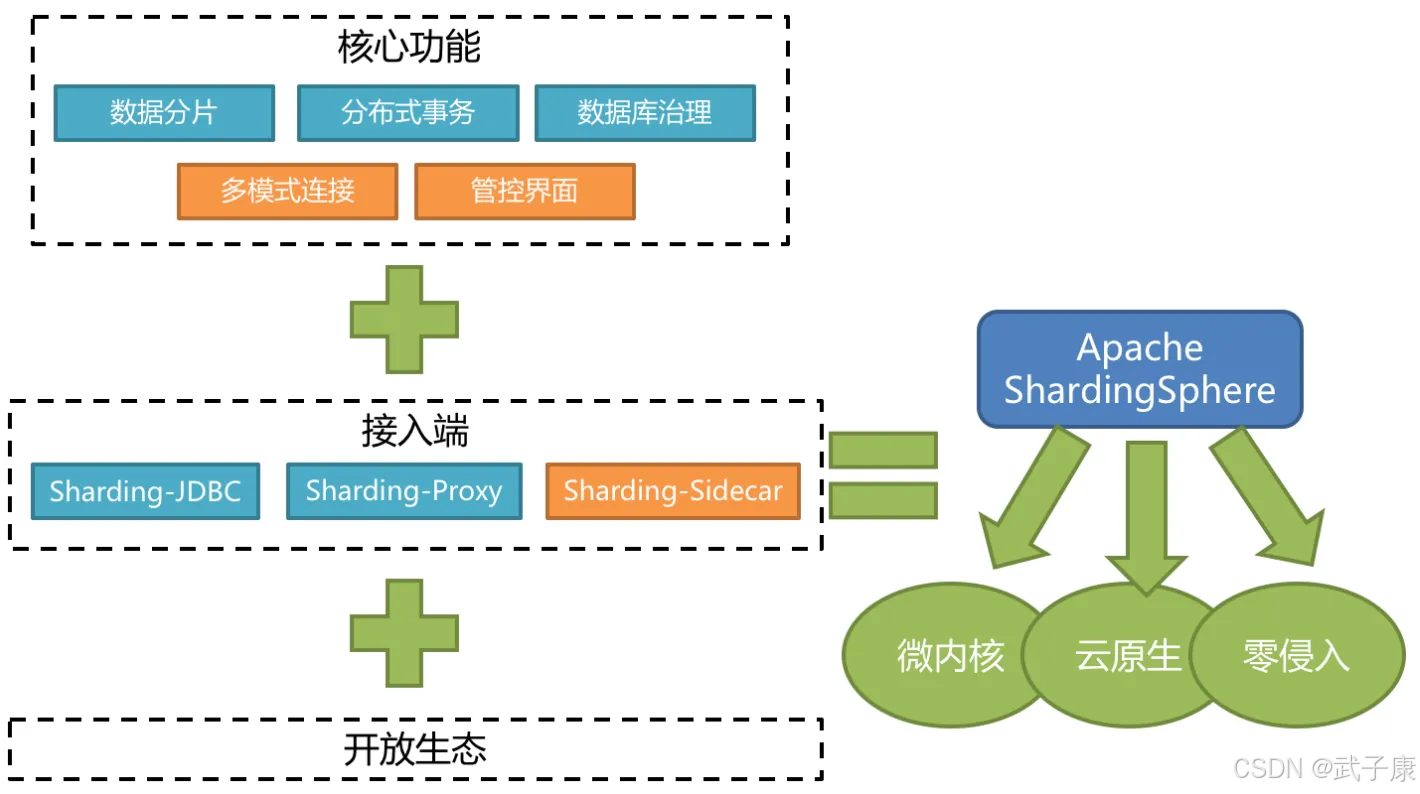
Apache ShardingSphere 是一款开源的分布式数据库中间件组成的生态圈,旨在为关系型数据库提供分布式能力的增强解决方案。它采用插件化架构设计,可以无缝对接各类业务系统,帮助企业应对海量数据存储和高并发访问的挑战。
ShardingSphere 生态系统由三个独立的产品组件构成:
-
Sharding-JDBC
定位为轻量级 Java 框架,以 JDBC 驱动形式提供服务。它直接在应用的 JDBC 层实现数据分片、读写分离等能力,无需额外部署,具有性能损耗低、接入简单等特点。适用于 Java 应用开发,支持 Spring Boot、MyBatis 等主流框架集成。 -
Sharding-Proxy
提供透明化的数据库代理服务,以独立进程方式运行。Proxy 支持 MySQL/PostgreSQL 协议,使得任何兼容这些协议的客户端工具(如 Navicat、Workbench)都能直接连接使用。它特别适合需要对数据库操作进行统一管控的场景,如多租户SaaS系统。 -
Sharding-Sidecar
作为云原生环境下的解决方案,以 Sidecar 模式部署在服务网格中。它结合 Service Mesh 技术,为微服务架构提供数据库治理能力,包括流量控制、熔断降级等特性,适用于 Kubernetes 等容器化环境。
这三个产品既可独立使用,也可混合部署形成完整解决方案。例如在微服务架构中,可以组合使用 Sharding-JDBC 处理应用层分片,同时通过 Sharding-Proxy 提供统一的SQL审计功能。项目采用 Apache 2.0 开源协议,已在国内多家大型互联网公司(如京东、美团)的生产环境中得到验证。
项目状态
SharingSphere 项目状态如下:

ShardingSphere 是一个开源的分布式数据库中间件生态系统,其核心定位是作为关系型数据库的增强层,而非替代品。它专注于在分布式场景下最大化利用传统关系型数据库(如 MySQL、PostgreSQL、Oracle 等)的固有能力,通过中间件的方式提供水平扩展方案。
具体而言,ShardingSphere 通过以下方式实现其定位:
- 计算能力增强:提供 SQL 路由、重写、执行结果归并等分布式计算功能
- 存储能力扩展:支持数据分片(Sharding)机制,将数据分散存储在多个数据库节点
- 分布式事务支持:在保持原有数据库事务特性的基础上,提供跨库事务能力
- 兼容性保证:完全兼容原生 SQL 语法,支持主流数据库协议(如 JDBC)
典型应用场景包括:
- 电商平台的订单库水平拆分
- 金融系统的账户数据分片存储
- 物联网海量设备数据的分布式存储
与 NewSQL 数据库不同,ShardingSphere 不重新实现存储引擎和查询引擎,而是通过对现有数据库的"增强"来获得分布式能力,这使得用户既可以利用已有数据库的成熟功能,又能获得分布式系统所需的扩展性。
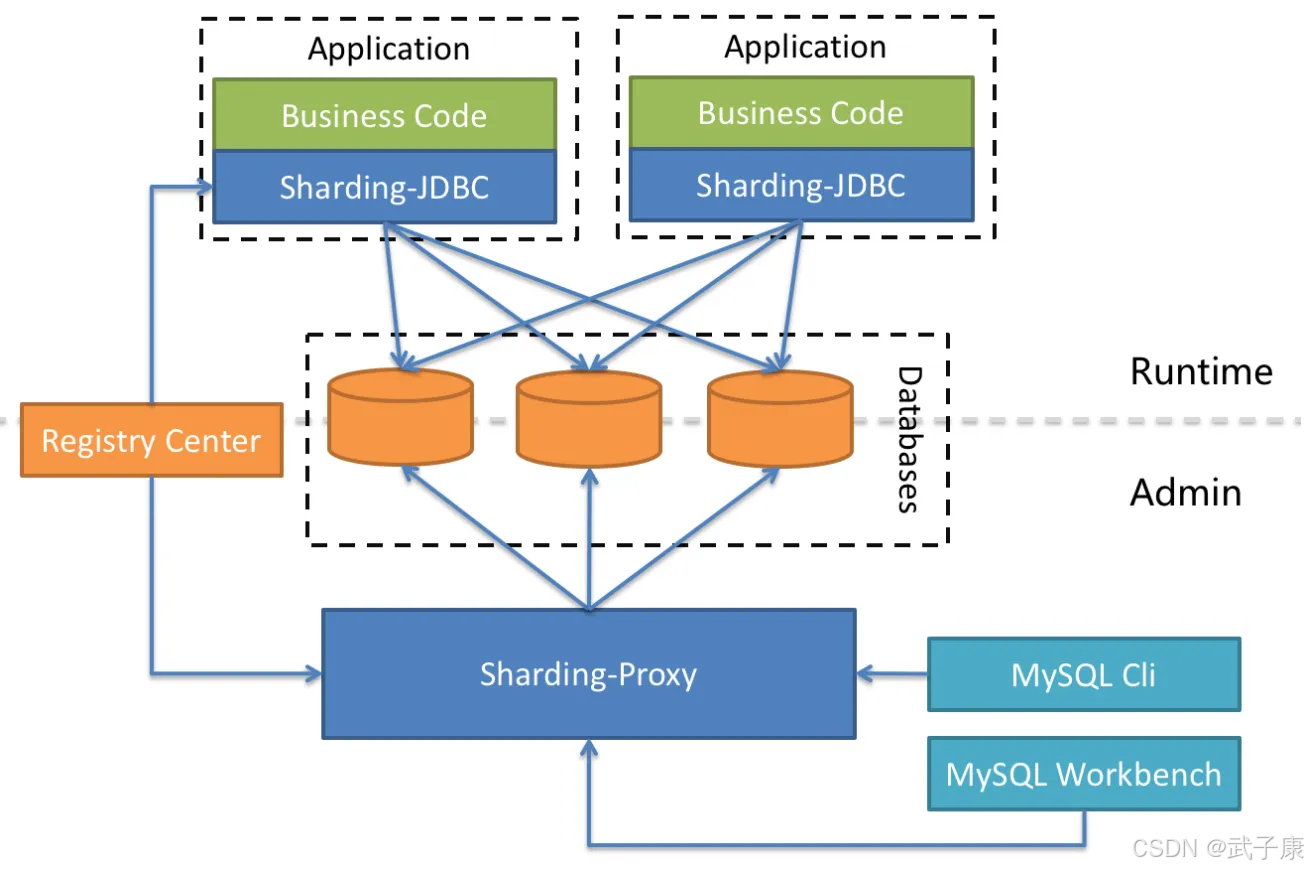
● Sharding-JDBC:被定位为轻量级的Java框架,在Java的JDBC层提供的额外服务,以Jar包形式使用。它通过重写JDBC规范实现了数据库分片、读写分离、分布式事务等功能,开发者只需引入依赖即可快速集成。例如在Spring Boot项目中,仅需配置数据源规则和分片策略就能实现水平分表。其优势在于无中心化架构,兼容所有基于JDBC的ORM框架如MyBatis、Hibernate等。
● Sharding-Proxy:被定位为透明化的数据库代理端,提供封装了数据库二进制协议的服务端版本,用于完成对异构语言的支持。它模拟MySQL/PostgreSQL协议,任何兼容这些协议的客户端(如PHP、Python、Go等应用)都可以直接连接。典型部署场景包括:为遗留系统提供分片能力而无需改造代码,或在混合技术栈的微服务架构中统一数据访问层。支持通过Admin UI进行动态配置管理,相比JDBC版本更便于运维监控。
● Sharding-SideCar:被定位为Kubernetes或Mesos的云原生数据库代理,以DaemonSet形式运行在每个计算节点上,自动代理所有对数据库的访问。其设计遵循Service Mesh模式,通过sidecar容器与服务实例共同调度,实现流量拦截、SQL路由、熔断等治理能力。特别适合在容器化环境中为无状态服务提供透明的数据库接入,例如在K8s集群中自动为Deployment注入分片能力,同时与Istio等服务网格方案深度集成。
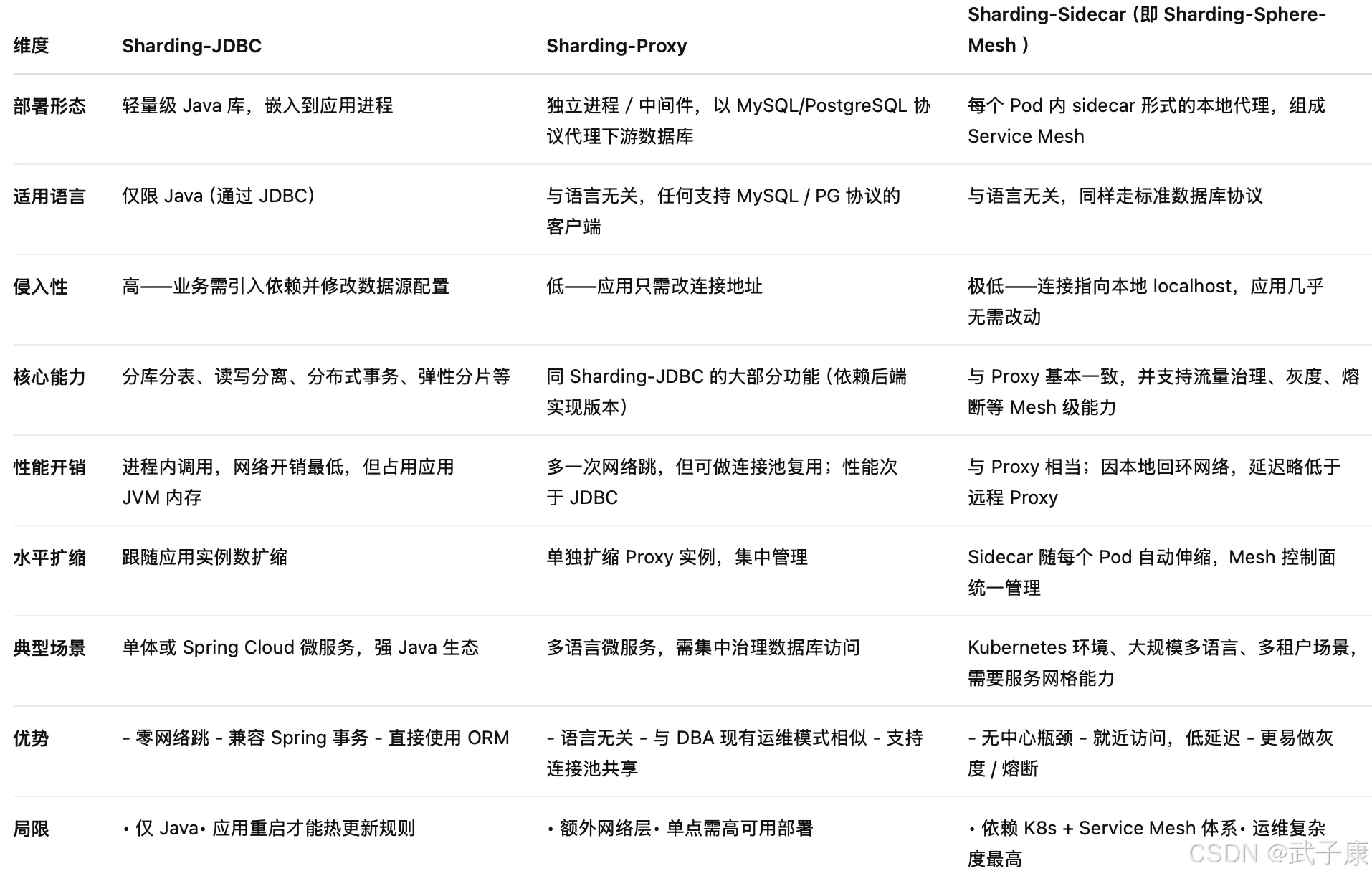
Sharding-JDBC、Sharding-Proxy、Sharding-SideCar 三者的区别如下:
ShardingSphere 的访问地址:
https://shardingsphere.apache.org/document/current/cn/downloads/

Sharding-JDBC
概述
Sharding-JDBC 是 Apache ShardingSphere 项目下的一个轻量级 Java 框架,提供了数据库分片(Sharding)、读写分离、分布式事务等功能。它通过 JDBC 层对应用程序透明地实现了数据库的水平扩展能力,无需修改业务代码即可实现数据分片。
核心特性
1. 分库分表
Sharding-JDBC 支持多种分片策略:
- 精确分片(=,IN)
- 范围分片(BETWEEN)
- 复合分片(多个条件组合)
- 强制路由(Hint)
示例场景:订单表按用户ID分片,用户ID为奇数的订单存储在db0,偶数的存储在db1。
2. 读写分离
支持一主多从的读写分离架构:
- 自动路由写操作到主库
- 读操作根据负载均衡策略分配到从库
- 支持权重负载均衡和轮询负载均衡
3. 分布式事务
提供多种分布式事务解决方案:
- XA强一致性事务
- SAGA柔性事务
- 本地事务(适用于非跨库操作)
配置方式
1. Java API配置
// 创建数据分片规则配置
ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration();// 配置分表规则
TableRuleConfiguration orderTableRuleConfig = new TableRuleConfiguration("t_order", "ds${0..1}.t_order${0..1}");
shardingRuleConfig.getTableRuleConfigs().add(orderTableRuleConfig);// 配置分片算法
StandardShardingStrategyConfiguration shardingStrategy = new StandardShardingStrategyConfiguration("user_id", new PreciseShardingAlgorithm() {...});
orderTableRuleConfig.setTableShardingStrategyConfig(shardingStrategy);// 创建数据源
DataSource dataSource = ShardingDataSourceFactory.createDataSource(createDataSourceMap(), shardingRuleConfig, new Properties());
2. YAML配置
dataSources:ds0: !!com.zaxxer.hikari.HikariDataSourcedriverClassName: com.mysql.jdbc.DriverjdbcUrl: jdbc:mysql://localhost:3306/ds0username: rootpassword: ds1: !!com.zaxxer.hikari.HikariDataSourcedriverClassName: com.mysql.jdbc.DriverjdbcUrl: jdbc:mysql://localhost:3306/ds1username: rootpassword: shardingRule:tables:t_order:actualDataNodes: ds${0..1}.t_order${0..1}tableStrategy:standard:shardingColumn: user_idpreciseAlgorithmClassName: com.example.MyPreciseShardingAlgorithm
最佳实践
-
分片键选择:
- 选择高基数列作为分片键
- 避免频繁更新的列作为分片键
- 考虑业务查询模式
-
分片策略优化:
- 避免数据倾斜
- 预留扩容空间
- 考虑热点数据问题
-
事务处理:
- 尽量减少跨分片事务
- 合理设置事务超时时间
- 考虑使用最终一致性方案
性能调优
-
连接池配置:
- 合理设置最大连接数
- 配置连接存活时间
- 启用连接泄漏检测
-
SQL优化:
- 避免全表扫描
- 减少跨库JOIN
- 使用绑定变量
-
监控指标:
- SQL执行时间
- 连接池使用情况
- 分片命中率
适用场景
- 单表数据量超过500万
- 数据库成为系统性能瓶颈
- 需要水平扩展数据库能力
- 需要实现读写分离架构
限制与注意事项
- 不支持跨库外键约束
- 分页查询性能可能下降
- 分布式事务性能开销较大
- 需要仔细设计分片策略
Sharding-Proxy 是 Apache ShardingSphere 生态中的一个独立组件,它定位为透明化的数据库代理,通过代理层对数据库进行分片、读写分离等操作,对应用程序完全透明。
核心功能
-
SQL 解析与路由:
- 支持标准 SQL 语法解析
- 根据配置的分片规则自动路由到正确的数据节点
- 例如:SELECT * FROM t_order WHERE user_id = 100 会被路由到 user_id 分片为 100 的节点
-
分布式事务支持:
- 提供 XA 分布式事务
- 支持柔性事务(Saga)
- 可配置的事务隔离级别
-
读写分离:
- 自动将写操作路由到主库
- 读操作可配置负载均衡策略
- 支持基于 Hint 的强制主库路由
-
数据加密:
- 透明化字段级加密
- 支持多种加密算法
- 加密字段在数据库中存储为密文
架构设计
Sharding-Proxy 采用模块化设计:
- 前端(Frontend)实现 MySQL/PostgreSQL 协议
- 核心模块处理 SQL 解析、路由和改写
- 后端(Backend)与真实数据库交互
典型应用场景
-
数据库水平扩展:
- 单表数据量超过 500 万时
- 需要线性扩展写能力
- 示例:电商订单表按用户 ID 分片
-
多租户 SaaS 系统:
- 每个租户数据独立存储
- 共享同一套应用代码
- 通过分片键自动路由
-
合规性要求高的系统:
- 需要字段级加密
- 审计日志要求
- 例如金融行业的客户信息表
性能优化建议
-
连接池配置:
- 建议最大连接数不超过 500
- 空闲连接超时设置为 5-10 分钟
- 使用连接预热
-
SQL 改写优化:
- 避免全表扫描的改写
- 优先使用分片键查询
- 批处理操作合并
-
缓存策略:
- 元数据缓存 5-10 分钟
- 路由结果缓存
- 查询结果缓存(对实时性要求不高的场景)
与 Sharding-JDBC 对比
| 特性 | Sharding-Proxy | Sharding-JDBC |
|---|---|---|
| 部署方式 | 独立进程 | Jar 包集成 |
| 协议支持 | MySQL/PG | JDBC |
| 性能 | 中等 | 高 |
| 适用场景 | 多语言/遗留系统 | Java 新项目 |
| 运维复杂度 | 较高 | 低 |
版本兼容性
当前稳定版本 5.3.2 支持:
- MySQL 5.7/8.0
- PostgreSQL 9.6+
- OpenJDK 8/11/17
- 建议生产环境使用 CentOS 7+ 或同等 Linux 发行版
注意:Sharding-Proxy 5.x 版本配置与 4.x 不兼容,升级需谨慎。
概述
Sharding-SideCar 是一种数据库中间件架构模式,它通过独立的代理服务(SideCar)来实现数据库分片(Sharding)功能。这种架构将分片逻辑从应用层解耦出来,使应用程序无需关心底层数据分布细节。
核心特点
-
透明化分片:
- 应用程序像访问单库一样访问数据库集群
- 所有分片路由、SQL改写、结果归并等操作由SideCar代理完成
- 支持JDBC协议,兼容大多数ORM框架
-
独立部署:
- 作为独立进程运行,与应用服务隔离
- 可采用容器化部署方式(如Docker)
- 支持横向扩展以应对高并发场景
-
功能丰富:
- 完整的分片功能(库分片、表分片)
- 分布式事务支持(XA、SAGA等)
- 读写分离、数据加密等增强功能
典型架构
[Application] │▼
[Sharding-SideCar] ←→ [Registry Center]│├─→ [Database Shard 1]├─→ [Database Shard 2]└─→ [Database Shard N]
组件说明:
- Registry Center:存储分片规则和拓扑信息(常用Zookeeper/Etcd)
- Sharding-SideCar:执行实际的分片操作,通常以集群方式部署
- Database Shards:物理数据库节点,可以是主从架构
实现方案
1. 开源实现
-
ShardingSphere-Proxy:Apache顶级项目,功能完善
- 支持MySQL/PostgreSQL协议
- 提供Admin控制台
- 完善的监控指标
-
Vitess:CNCF毕业项目,针对大规模场景
- 原生支持K8s部署
- 内置VTTablet管理组件
- 特别适合云原生环境
2. 云服务商方案
- AWS RDS Proxy:托管式数据库代理服务
- 阿里云PolarDB-Proxy:针对PolarDB优化的代理层
- 腾讯云TDSQL-C:分布式数据库的代理组件
配置示例(YAML格式)
# 数据源配置
dataSources:ds_0:url: jdbc:mysql://db-host-0:3306/dbusername: rootpassword: 123456ds_1:url: jdbc:mysql://db-host-1:3306/dbusername: rootpassword: 123456# 分片规则
rules:
- !SHARDINGtables:t_order:actualDataNodes: ds_${0..1}.t_order_${0..15}databaseStrategy:standard:shardingColumn: user_idpreciseAlgorithmClassName: com.example.HashMod2AlgorithmtableStrategy:standard:shardingColumn: order_idpreciseAlgorithmClassName: com.example.HashMod16Algorithm
性能优化建议
-
连接池配置:
- 合理设置最大连接数(建议100-500)
- 启用连接复用(如HikariCP的connectionTestQuery)
- 监控连接泄漏情况
-
缓存策略:
- 启用SQL解析缓存(建议大小1000-5000)
- 对热点查询配置结果缓存
- 考虑本地缓存与Redis多级缓存
-
批量操作:
- 使用批量插入代替单条插入
- 对于大批量操作考虑分批次执行
- 启用批量操作的并行执行
适用场景
-
传统架构改造:
- 单库性能达到瓶颈
- 需要平滑迁移到分片架构
- 不能修改应用代码的情况
-
微服务环境:
- 多语言服务需要统一数据访问层
- 服务网格(Service Mesh)架构
- K8s环境下的SideCar模式部署
-
云迁移项目:
- 上云过程中的数据库架构调整
- 混合云场景的统一数据访问
- 需要数据库层弹性的场景
监控指标
-
基础指标:
- QPS/TPS
- 平均响应时间
- 错误率
-
资源指标:
- CPU/Memory使用率
- 网络IO
- 连接数统计
-
业务指标:
- 分片均衡度
- 热点分片检测
- 慢查询统计
演进路线
-
初级阶段:
- 单节点部署
- 静态分片规则
- 基础监控
-
中级阶段:
- 集群化部署
- 动态规则配置
- 完善的高可用机制
-
高级阶段:
- 弹性伸缩能力
- 智能化路由
- 与Service Mesh深度集成
注意事项
-
分布式事务:
- 评估业务对一致性的要求
- XA协议可能影响性能
- 考虑最终一致性方案
-
跨分片查询:
- 避免多表JOIN
- 大数据量查询可能内存溢出
- 考虑使用Elasticsearch等辅助查询
-
扩容挑战:
- 分片数变更需要数据迁移
- 评估扩容过程中的服务影响
- 制定完善的迁移方案