k8s原理及操作
简介
kubernetes的本质是一组服务器集群,它可以在集群的每个节点上运行特定的程序,来对节点中的容器
进行管理。目的是实现资源管理的自动化,主要提供了如下的主要功能:
- 自我修复:一旦某一个容器崩溃,能够在1秒中左右迅速启动新的容器
- 弹性伸缩:可以根据需要,自动对集群中正在运行的容器数量进行调整
- 服务发现:服务可以通过自动发现的形式找到它所依赖的服务
- 负载均衡:如果一个服务起动了多个容器,能够自动实现请求的负载均衡
- 版本回退:如果发现新发布的程序版本有问题,可以立即回退到原来的版本
- 存储编排:可以根据容器自身的需求自动创建存储卷
名词解释
- Master:集群控制节点,每个集群需要至少一个master节点负责集群的管控
- Node:工作负载节点,由master分配容器到这些node工作节点上,然后node节点上的
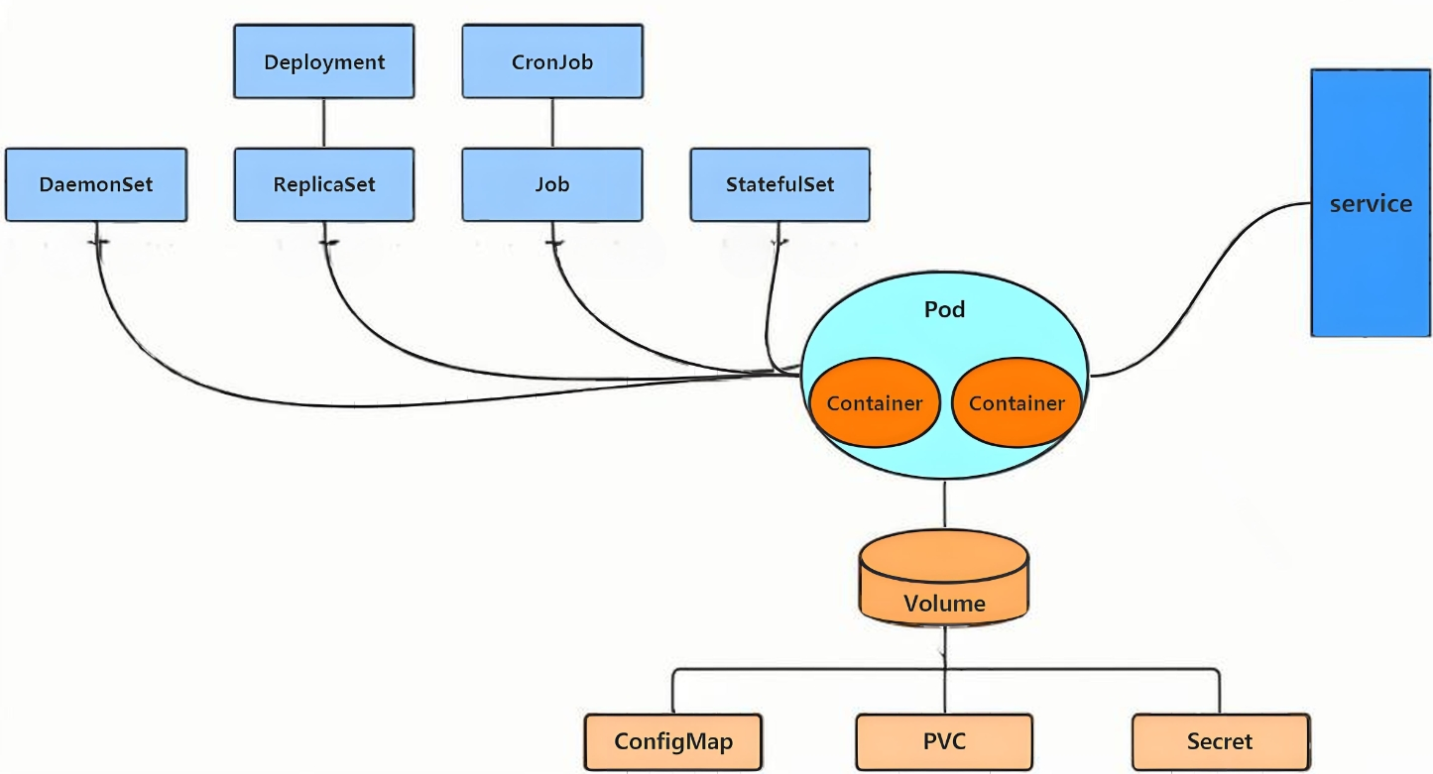
- Pod:kubernetes的最小控制单元,容器都是运行在pod中的,一个pod中可以有1个或者多个容器
- Controller:控制器,通过它来实现对pod的管理,比如启动pod、停止pod、伸缩pod的数量等等
- Service:pod对外服务的统一入口,下面可以维护者同一类的多个pod
- Label:标签,用于对pod进行分类,同一类pod会拥有相同的标签
- NameSpace:命名空间,用来隔离pod的运行环境
架构
组件
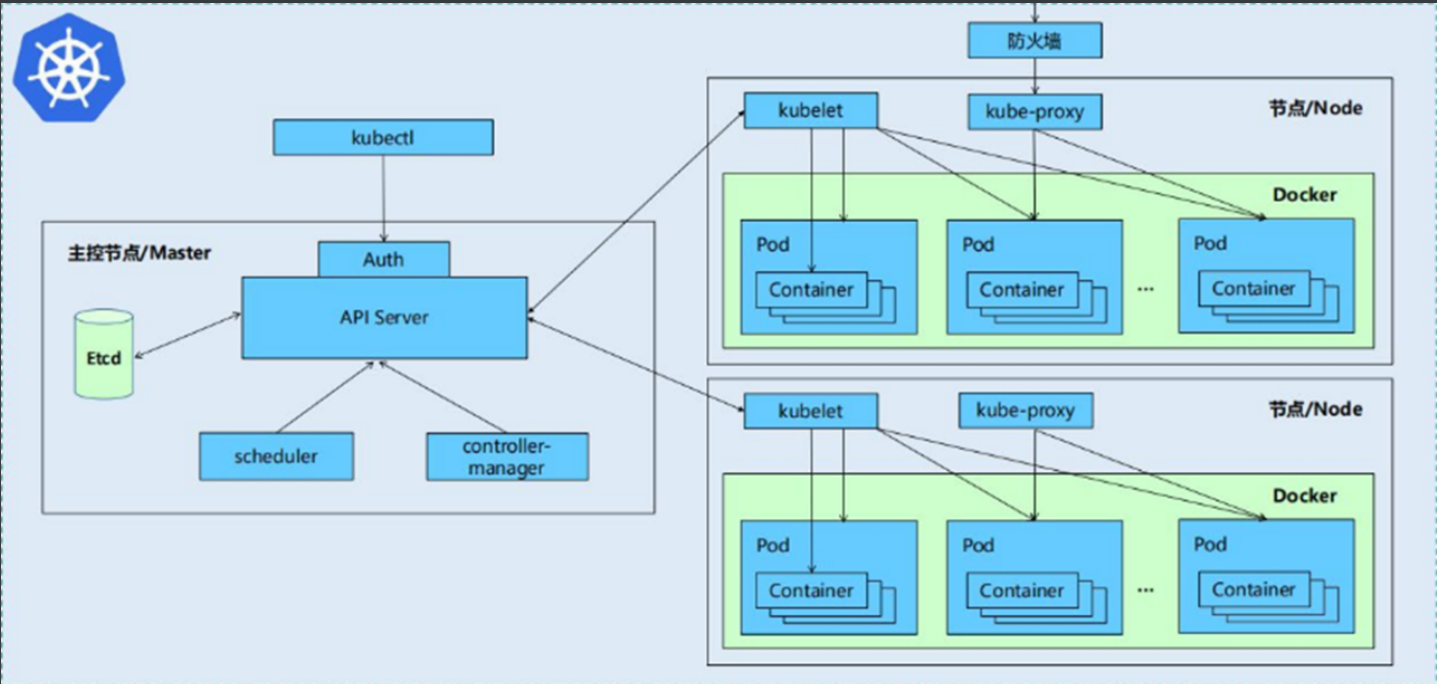
一、控制平面组件(Control Plane)
控制平面负责集群的全局决策(如调度、管理工作负载、检测和响应集群事件等),通常运行在集群的主节点(Master Node)上。
-
kube-apiserver
资源操作的唯一入口,接收用户输入的命令,提供认证、授权、API注册和发现等机制
-
etcd
集群的分布式键值数据库,存储集群的所有状态(如 Pod、Service、配置等),通常需要高可用部署。
-
kube-scheduler
根据预定的调度策略,将Pod调度到相应的node节点上,仅调度,不部署(部署由kubelet完成)
-
kube-controller-manager
运行一系列控制器进程的组件,确保集群状态与期望状态一致。
-
cloud-controller-manager(可选,云环境使用)
- 与云服务提供商(如 AWS、GCP、阿里云)集成,管理云资源(如负载均衡、节点实例)。
- 仅在集群运行在云平台时需要,将云厂商特有逻辑与核心控制器分离。
二、节点组件(Node)
节点组件运行在每个工作节点(Worker Node)上,负责维护 Pod 的运行状态,并与控制平面通信。
-
kubelet
kubelet接收一组通过各类机制提供给它的 PodSpec,确保这些 PodSpec 中描述的容器处于运行状态且健康。负责维护容器的生命周期,同时也负责Volume(CVI)和网络(CNI)的管理
-
kube-proxy
-
负责为Service提供cluster内部的服务发现和负载均衡
-
运行在每个节点上的网络代理,负责实现 Kubernetes Service 的网络规则。
-
维护节点上的网络规则(如 iptables 或 ipvs 规则),实现 Pod 间的通信、Service 的负载均衡和外部流量转发。
-
支持多种模式(userspace、iptables、ipvs),其中 ipvs 性能最优(适合大规模集群)。
-
-
容器运行时(Container Runtime)
- 负责运行容器的软件,是 Kubernetes 的底层依赖。
- 支持的容器运行时:Docker、containerd、CRI-O 等(需符合 Kubernetes CRI 规范)。
- 例如:Docker 作为容器运行时,实际通过 containerd 与 kubelet 交互。
三、附加组件(Add-ons)
附加组件用于增强集群功能,常见的有:
-
CoreDNS
提供集群内的 DNS 服务,解析 Service 和 Pod 的域名(如
my-service.default.svc.cluster.local),实现 Pod 间通过服务名通信。 -
Ingress Controller
实现 Ingress 资源的规则,管理外部访问集群内 HTTP/HTTPS 服务(如 Nginx Ingress、Traefik)。
-
Dashboard
Kubernetes 的 Web UI,用于可视化管理集群资源(如部署 Pod、查看日志)。
-
Metrics Server
收集集群资源 metrics(CPU、内存使用情况),为 HPA(Horizontal Pod Autoscaler)和 kubectl top 命令提供数据。
-
网络插件(CNI Plugin)
实现 Pod 网络互联互通(如 Calico、Flannel、Weave Net),需符合 CNI 规范。
总结
- 控制平面:负责集群的决策和管理(apiserver、etcd、scheduler、controller-manager)。
- 节点组件:负责执行控制平面的指令,运行和维护 Pod(kubelet、kube-proxy、容器运行时)。
- 附加组件:扩展集群功能(DNS、Ingress、监控等)。
分层
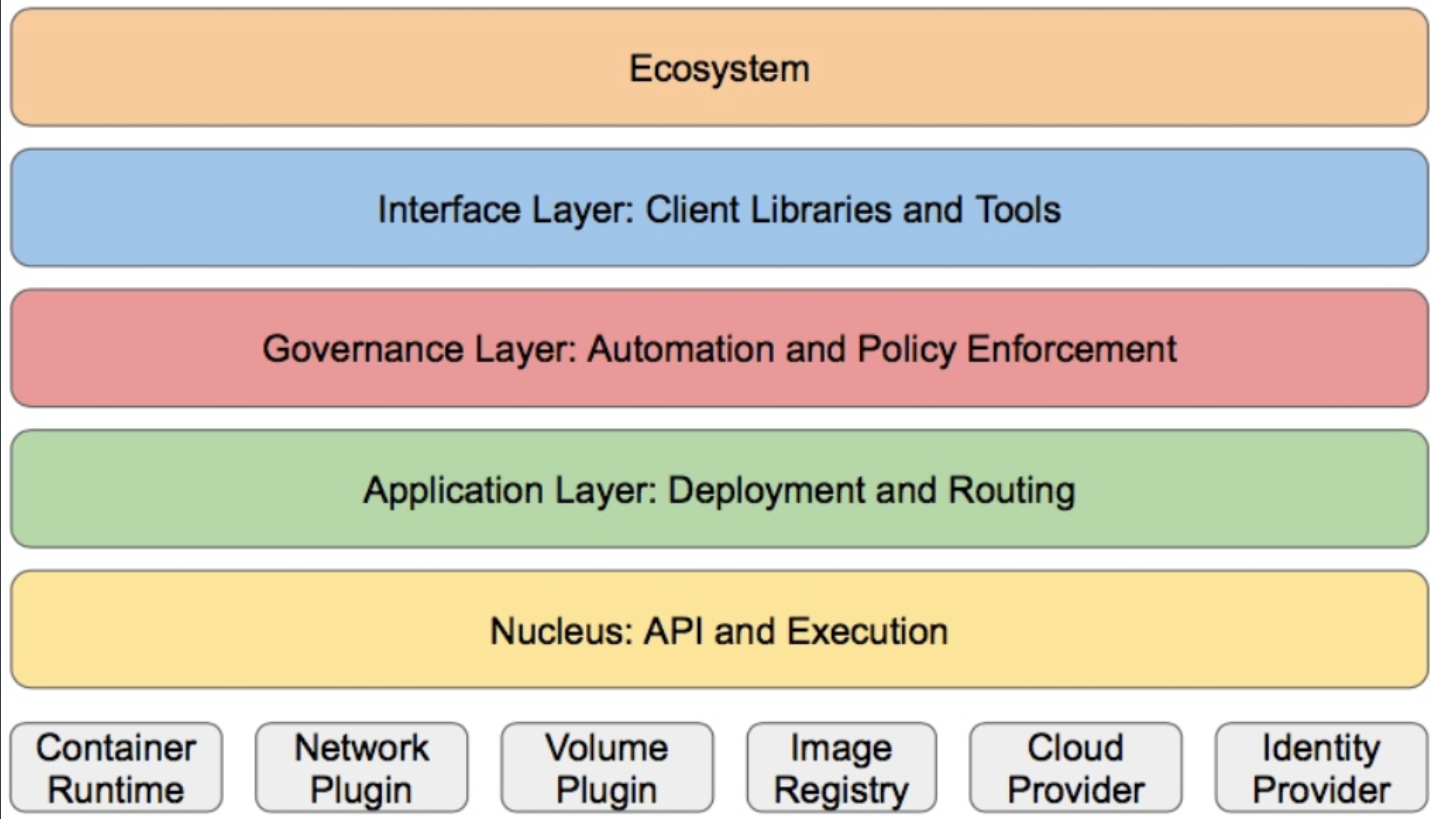
- 核心层:Kubernetes最核心的功能,对外提供API构建高层的应用,对内提供插件式应用执行环境
- 应用层:部署(无状态应用、有状态应用、批处理任务、集群应用等)和路由(服务发现、DNS解
- 析等)
- 管理层:系统度量(如基础设施、容器和网络的度量),自动化(如自动扩展、动态Provision等)
- 以及策略管理(RBAC、Quota、PSP、NetworkPolicy等)
- 接口层:kubectl命令行工具、客户端SDK以及集群联邦
- 生态系统:在接口层之上的庞大容器集群管理调度的生态系统,可以划分为两个范畴
- Kubernetes外部:日志、监控、配置管理、CI、CD、Workflow、FaaS、OTS应用、ChatOps等
- Kubernetes内部:CRI、CNI、CVI、镜像仓库、Cloud Provider、集群自身的配置和管理等
工作流程
当我们要运行一个web服务时
- kubernetes环境启动之后,
master和node都会将自身的信息存储到etcd数据库中 - web服务的安装请求会首先被发送到
master节点的apiServer组件 - apiServer组件会调用scheduler组件来决定到底应该把这个服务安装到哪个
node节点上,在此时,它会从etcd中读取各个node节点的信息,然后按照一定的算法进行选择,并将结果告知apiServer apiServer调用controller-manager去调度Node节点安装web服务kubelet接收到指令后,会通知docker,然后由docker来启动一个web服务的pod- 如果需要访问web服务,就需要通过
kube-proxy来对pod产生访问的代理
集群部署
一、环境
| 主机名 | ip | 角色 |
|---|---|---|
| harbor | 192.168.60.200 | harbor仓库 |
| master | 192.168.60.100 | master,k8s集群控制节点 |
| k8s-1 | 192.168.60.110 | worker,k8s集群工作节点 |
| k8s-2 | 192.168.60.120 | worker,k8s集群工作节点 |
二、禁用selinux、firewalld、swap分区
所有节点
vim /etc/selinux/config
# 将SELINUX=enforcing 改为 SELINUX=disabled
SELINUX=disabled
#重启后生效
reboot#关闭防火墙,并禁止开机自启
systemctl disable --now firewalld
# 彻底屏蔽防火墙服务(防止被其他服务激活)
systemctl mask firewalldKubernetes 的调度器基于节点的可用内存进行决策,而 swap 会干扰这种内存管理机制,可能导致 Pod 调度不准确或性能问题。
#屏蔽swap
systemctl mask swap.target
#立即禁用当前所有激活的 swap 分区
swapoff -a
#编辑系统自动挂载配置文件,防止系统重启后自动挂载swap
vim /etc/fstab
#注释
#/dev/mapper/rhel-swap none swap defaults 0 0
三、本地解析
所有节点
192.168.60.100 master.dl.org
192.168.60.110 k8s-1.dl.org
192.168.60.120 k8s-2.dl.org www.dl.org
192.168.60.200 reg.dl.org
四、安装docker
所有节点
#配置镜像仓库
vim /etc/yum.repos.d/docker.repo
[docker]
name=docker
baseurl=https://mirrors.aliyun.com/docker-ce/linux/rhel/9/x86_64/stable/
gpgcheck=0
#安装
dnf install docker-ce -y
五、设定docker配置
所有节点
vim /etc/docker/daemon.json
{"registry-mirrors": ["https://reg.timinglee.org"],#当拉取镜像时,Docker 会优先从该镜像源获取,提高下载速度。"exec-opts": ["native.cgroupdriver=systemd"], #设置 Docker 的 cgroup 驱动为 systemd。"log-driver": "json-file", #指定容器日志的驱动程序为 json-file"log-opts": {"max-size": "100m" #单个日志文件的最大大小为 100MB},"storage-driver": "overlay2" #设置 Docker 的存储驱动为 overlay2
}
六、配置harbor仓库
harbor:192.160.60.200
#解压
tar zxf harbor-offline-installer-v2.5.4.tgz
#进入目录
cd harbor/
#复制配置文件
cp harbor.yml.tmpl harbor.yml
#编辑
vim harbor.ymlhostname: reg.dl.org #定义仓库主机名certificate: /etc/docker/certs/dl.crt #指定证书、密钥private_key: /etc/docker/certs/dl.key
harbor_admin_password: dll #设置管理员密码#安装 Harbor 镜像仓库,并额外启用 ChartMuseum 组件。
#允许在 Harbor 中管理和分发 Kubernetes 应用的 Helm Chart 包。
./install.sh --with-chartmuseum#复制证书
scp /etc/docker/certs/dl.crt root@192.168.60.100:/etc/docker/certs.d/reg.dl.org/ca.crt
scp /etc/docker/certs/dl.crt root@192.168.60.110:/etc/docker/certs.d/reg.dl.org/ca.crt
scp /etc/docker/certs/dl.crt root@192.168.60.120:/etc/docker/certs.d/reg.dl.org/ca.crt#所有主机启动docker
systemctl enable --now docker#登录harbor仓库
docker login reg.dl.org#查看docker信息
docker infoClient: Docker Engine - CommunityVersion: 27.1.2Context: defaultDebug Mode: falsePlugins:buildx: Docker Buildx (Docker Inc.)Version: v0.16.2Path: /usr/libexec/docker/cli-plugins/docker-buildxcompose: Docker Compose (Docker Inc.)Version: v2.29.1Path: /usr/libexec/docker/cli-plugins/docker-composeServer:Containers: 37Running: 17Paused: 0Stopped: 20Images: 25Server Version: 27.1.2Storage Driver: overlay2 #Docker 的存储驱动为 overlay2Backing Filesystem: xfsSupports d_type: trueUsing metacopy: falseNative Overlay Diff: trueuserxattr: falseLogging Driver: json-file #指定容器日志的驱动程序为 json-fileCgroup Driver: systemd #资源管理为systemdCgroup Version: 2Plugins:Volume: localNetwork: bridge host ipvlan macvlan null overlayLog: awslogs fluentd gcplogs gelf journald json-file local splunk syslogSwarm: inactiveRuntimes: io.containerd.runc.v2 runcDefault Runtime: runcInit Binary: docker-initcontainerd version: 8fc6bcff51318944179630522a095cc9dbf9f353runc version: v1.1.13-0-g58aa920init version: de40ad0Security Options:seccompProfile: builtincgroupnsKernel Version: 5.14.0-427.13.1.el9_4.x86_64Operating System: Red Hat Enterprise Linux 9.4 (Plow)OSType: linuxArchitecture: x86_64CPUs: 4Total Memory: 3.543GiBName: masterID: 7275dfce-7a45-46bf-8e61-89dcf6940e2aDocker Root Dir: /var/lib/dockerDebug Mode: falseExperimental: falseInsecure Registries:127.0.0.0/8Registry Mirrors:https://reg.dl.org/ #认证harbor仓库Live Restore Enabled: false
七、安装k8s部署工具
所有节点
#配置仓库
vim /etc/yum.repos.d/k8s.repo
[k8s]
name=k8s
baseurl=https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.30/rpm
gpgcheck=0#安装软件
dnf install kubelet-1.30.0 kubeadm-1.30.0 kubectl-1.30.0 -y
八、设置kubectl命令补全功能
master
dnf install bash-completion -y
echo "source <(kubectl completion bash)" >> ~/.bashrc
source ~/.bashrc
九、安装cri-docker
所有节点
软件下载地址:https://github.com/Mirantis/cri-dockerd
dnf install libcgroup-0.41-19.el8.x86_64.rpm
dnf install cri-dockerd-0.3.14-3.el8.x86_64.rpmvim /lib/systemd/system/cri-docker.service#指定网络插件名称及基础容器镜像
ExecStart=/usr/bin/cri-dockerd --container-runtime-endpoint fd:// --network-plugin=cni --pod-infra-container-image=reg.dl.org/k8s/pause:3.9systemctl daemon-reload #重新加载 systemd 服务的配置文件
systemctl start cri-docker #启动 cri-dockerd 服务
ll /var/run/cri-dockerd.sock #查看 cri-dockerd 服务创建的 Unix 域套接字文件
十、拉取镜像
master
kubeadm config images pull \ #通过 kubeadm 工具拉取 Kubernetes 控制平面和核心组件的镜像
--image-repository registry.aliyuncs.com/google_containers \ #指定镜像仓库地址
--kubernetes-version v1.30.0 \ #指定版本
--cri-socket=unix:///var/run/cri-dockerd.sock #指定 CRI 接口套接字 kubeadm config images pull --image-repository registry.aliyuncs.com/google_containers --kubernetes-version v1.30.0 --cri-socket=unix:///var/run/cri-dockerd.sock#上传镜像至harbor仓库
#tag
docker images | awk '/google/{ print $1":"$2}' | awk -F "/" '{system("docker tag "$0" reg.timinglee.org/k8s/"$3)}'
#push
docker images | awk '/k8s/{system("docker push "$1":"$2)}'
十一、集群初始化
#启动kubelet服务
systemctl start kubelet.service#执行初始化命令
kubeadm init --pod-network-cidr=10.244.0.0/16 \ #指定 Pod 网络的 CIDR 范围
--image-repository reg.dl.org/k8s \ #指定 Kubernetes 组件镜像的拉取源
--kubernetes-version v1.30.0 \ #指定初始化的 Kubernetes 版本
--cri-socket=unix:///var/run/cri-dockerd.sock #显式指定 CRI(容器运行时接口)的套接字路径#指定集群配置文件变量
echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
source ~/.bash_profile
十二、安装网络插件
https://github.com/flannel-io/flannel
wget https://github.com/flannel-io/flannel/releases/latest/download/kube-flannel.yml
#拉取镜像
docker pull docker.io/flannel/flannel:v0.25.5
docekr pull docker.io/flannel/flannel-cni-plugin:v1.5.1-flannel1#上传至harbor仓库(在仓库中建立flannel项目)
docker tag flannel/flannel:v0.25.5 reg.dl.org/flannel/flannel:v0.25.5
docker tag flannel/flannel-cni-plugin:v1.5.1-flannel1 reg.dl.org/flannel/flannel-cni-plugin:v1.5.1-flannel1#编辑kube-flannel.yml 修改镜像下载位置
vim kube-flannel.yml146: image: reg.dl/flannel/flannel:v0.25.5
173: image: reg.dl/flannel/flannel-cni-plugin:v1.5.1-flannel1
184: image: reg.dl/flannel/flannel:v0.25.5#安装flannel网络插件
kubectl apply -f kube-flannel.yml
十二、节点扩容
master节点查看token
[root@master media]# kubeadm token create --print-join-command
kubeadm join 192.168.60.100:6443 --token sd0z2s.h424t6d9njs5zet0 --discovery-token-ca-cert-hash sha256:54f338e34b57ebbb8ab695521e84a8282d6a7263397f415e8f6056f9c82e34a9 k8s-1 k8s-2
kubeadm join 192.168.60.100:6443 --token sd0z2s.h424t6d9njs5zet0 --discovery-token-ca-cert-hash sha256:54f338e34b57ebbb8ab695521e84a8282d6a7263397f415e8f6056f9c82e34a9 --cri-socket=unix:///var/run/cri-dockerd.sock [root@master media]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-1 Ready <none> 10d v1.30.0
k8s-2 Ready <none> 10d v1.30.0
master Ready control-plane 10d v1.30.0
如此一个k8s集群便完成了
k8s资源管理
1.1 资源管理介绍
- 在kubernetes中,所有的内容都抽象为资源,用户需要通过操作资源来管理kubernetes。
- kubernetes的本质上就是一个集群系统,用户可以在集群中部署各种服务
- 所谓的部署服务,其实就是在kubernetes集群中运行一个个的容器,并将指定的程序跑在容器中。
- kubernetes的最小管理单元是pod而不是容器,只能将容器放在
Pod中, - kubernetes一般也不会直接管理Pod,而是通过
Pod控制器来管理Pod的。 - Pod中服务的访问是由kubernetes提供的
Service资源来实现。 - Pod中程序的数据需要持久化是由kubernetes提供的各种存储系统来实现
1.2 资源管理方式
-
命令式对象管理:直接使用命令去操作kubernetes资源
kubectl run nginx-pod --image=nginx:latest --port=80 -
命令式对象配置:通过命令配置和配置文件去操作kubernetes资源
kubectl create/patch -f nginx-pod.yaml -
声明式对象配置:通过apply命令和配置文件去操作kubernetes资源
kubectl apply -f nginx-pod.yaml
| 类型 | 适用环境 | 优点 | 缺点 |
|---|---|---|---|
| 命令式对象管理 | 测试 | 简单 | 只能操作活动对象,无法审计、跟踪 |
| 命令式对象配置 | 开发 | 可以审计、跟踪 | 项目大时,配置文件多,操作麻烦 |
| 声明式对象配置 | 开发 | 支持目录操作 | 意外情况下难以调试 |
1.2.1 命令式对象管理
kubectl是kubernetes集群的命令行工具,通过它能够对集群本身进行管理,并能够在集群上进行容器化应用的安装部署
kubectl命令的语法如下:
kubectl [command] [type] [name] [flags]
comand:指定要对资源执行的操作,例如create、get、delete
type:指定资源类型,比如deployment、pod、service
name:指定资源的名称,名称大小写敏感
flags:指定额外的可选参数
# 查看所有pod
kubectl get pod # 查看某个pod
kubectl get pod pod_name# 查看某个pod,以yaml格式展示结果
kubectl get pod pod_name -o yaml
1.2.2 资源类型
kubernetes中所有的内容都抽象为资源
kubectl api-resources
常用资源类型
| 资源分类 | 资源名称 | 缩写 | 资源作用 |
|---|---|---|---|
| 集群级别资源 | nodes | no | 集群组成部分 |
| namespaces | ns | 隔离 Pod | |
| pod 资源 | pods | po | 装载容器 |
| pod 资源控制器 | replicationcontrollers | rc | 控制 pod 资源 |
| replicasets | rs | 控制 pod 资源 | |
| deployments | deploy | 控制 pod 资源 | |
| daemonsets | ds | 控制 pod 资源 | |
| jobs | 控制 pod 资源 | ||
| cronjobs | cj | 控制 pod 资源 | |
| horizontalpodautoscalers | hpa | 控制 pod 资源 | |
| statefulsets | sts | 控制 pod 资源 | |
| 服务发现资源 | services | svc | 统一 pod 对外接口 |
| ingress | ing | 统一 pod 对外接口 | |
| 存储资源 | volumeattachments | 存储 | |
| persistentvolumes | pv | 存储 | |
| persistentvolumeclaims | pvc | 存储 | |
| 配置资源 | configmaps | cm | 配置 |
| secrets | 配置 |
基本命令
| 命令分类 | 命令 | 翻译 | 命令作用 |
|---|---|---|---|
| 基本命令 | create | 创建 | 创建一个资源 |
| edit | 编辑 | 编辑一个资源 | |
| get | 获取 | 获取一个资源 | |
| patch | 更新 | 更新一个资源 | |
| delete | 删除 | 删除一个资源 | |
| explain | 解释 | 展示资源文档 | |
| 运行和调试 | run | 运行 | 在集群中运行一个指定的镜像 |
| expose | 暴露 | 暴露资源为 Service | |
| describe | 描述 | 显示资源内部信息 | |
| logs | 日志 | 输出容器在 pod 中的日志 | |
| attach | 缠绕 | 进入运行中的容器 | |
| exec | 执行 | 执行容器中的一个命令 | |
| cp | 复制 | 在 Pod 内外复制文件 | |
| rollout | 首次展示 | 管理资源的发布 | |
| scale | 规模 | 扩(缩)容 Pod 的数量 | |
| autoscale | 自动调整 | 自动调整 Pod 的数量 | |
| 高级命令 | apply | rc | 通过文件对资源进行配置 |
| label | 标签 | 更新资源上的标签 | |
| 其他命令 | cluster - info | 集群信息 | 显示集群信息 |
| version | 版本 | 显示当前 Server 和 Client 的版本 |
pod管理与优化
Pod 是 Kubernetes(K8s)中最小的部署和调度单元,而非单个容器 —— 它是一组(一个或多个)紧密关联的容器的集合,这些容器共享网络、存储资源和运行时环境,在逻辑上视为一个 “应用实例” 协同工作。
- 容器组合性
Pod 内的容器共享同一网络命名空间,拥有相同的 IP 地址和端口空间,可通过localhost直接通信,且共享Volume,便于数据交互。 - 资源共享边界
Pod 是资源分配的基本单位(而非容器),K8s 会为 Pod 分配 CPU、内存等资源,Pod 内的所有容器共同竞争这些资源(可通过resources为单个容器设置资源限制)。 - 生命周期与调度绑定
Pod 作为一个整体被 K8s 调度到集群的某个Node上,其内部所有容器始终运行在同一节点;若 Pod 被删除、重启或调度迁移,所有容器会同步操作,不会单独拆分。
自主式pod创建
优点:
- 灵活性高:可以精确控制 Pod 的各种配置参数,包括容器的镜像、资源限制、环境变量、命令和参数等,满足特定的应用需求。
- 学习和调试方便:对于学习 Kubernetes 的原理和机制非常有帮助,通过手动创建 Pod 可以深入了解 Pod 的结构和配置方式。在调试问题时,可以更直接地观察和调整 Pod 的设置。
- 适用于特殊场景:在一些特殊情况下,如进行一次性任务、快速验证概念或在资源受限的环境中进行特定配置时,手动创建 Pod 可能是一种有效的方式。
缺点:
- 管理复杂:如果需要管理大量的 Pod,手动创建和维护会变得非常繁琐和耗时。难以实现自动化的扩缩容、故障恢复等操作。
- 缺乏高级功能:无法自动享受 Kubernetes 提供的高级功能,如自动部署、滚动更新、服务发现等。这可能导致应用的部署和管理效率低下。
- 可维护性差:手动创建的 Pod 在更新应用版本或修改配置时需要手动干预,容易出现错误,并且难以保证一致性。相比之下,通过声明式配置或使用 Kubernetes 的部署工具可以更方便地进行应用的维护和更新。
#查看所有pods
[root@master ~]# kubectl get pods
No resources found in default namespace.#建立一个名为app的pod
[root@master ~]# kubectl run app --image myapp:v1
pod/app created
#查看
[root@master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
app 1/1 Running 0 4s#显示pod的较为详细的信息
[root@master ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
app 1/1 Running 0 95s 10.244.231.200 k8s-1 <none> <none>#删除
[root@master ~]# kubectl delete pod app
pod "app" deleted
利用控制器管理pod(推荐)
高可用性和可靠性:
- 自动故障恢复:如果一个 Pod 失败或被删除,控制器会自动创建新的 Pod 来维持期望的副本数量。确保应用始终处于可用状态,减少因单个 Pod 故障导致的服务中断。
- 健康检查和自愈:可以配置控制器对 Pod 进行健康检查(如存活探针和就绪探针)。如果 Pod 不健康,控制器会采取适当的行动,如重启 Pod 或删除并重新创建它,以保证应用的正常运行。
可扩展性:
- 轻松扩缩容:可以通过简单的命令或配置更改来增加或减少 Pod 的数量,以满足不同的工作负载需求。例如,在高流量期间可以快速扩展以处理更多请求,在低流量期间可以缩容以节省资源。
- 水平自动扩缩容(HPA):可以基于自定义指标(如 CPU 利用率、内存使用情况或应用特定的指标)自动调整 Pod 的数量,实现动态的资源分配和成本优化。
版本管理和更新:
- 滚动更新:对于 Deployment 等控制器,可以执行滚动更新来逐步替换旧版本的 Pod 为新版本,确保应用在更新过程中始终保持可用。可以控制更新的速率和策略,以减少对用户的影响。
- 回滚:如果更新出现问题,可以轻松回滚到上一个稳定版本,保证应用的稳定性和可靠性。
声明式配置:
- 简洁的配置方式:使用 YAML 或 JSON 格式的声明式配置文件来定义应用的部署需求。这种方式使得配置易于理解、维护和版本控制,同时也方便团队协作。
- 期望状态管理:只需要定义应用的期望状态(如副本数量、容器镜像等),控制器会自动调整实际状态与期望状态保持一致。无需手动管理每个 Pod 的创建和删除,提高了管理效率。
服务发现和负载均衡:
- 自动注册和发现:Kubernetes 中的服务(Service)可以自动发现由控制器管理的 Pod,并将流量路由到它们。这使得应用的服务发现和负载均衡变得简单和可靠,无需手动配置负载均衡器。
- 流量分发:可以根据不同的策略(如轮询、随机等)将请求分发到不同的 Pod,提高应用的性能和可用性。
多环境一致性:
- 一致的部署方式:在不同的环境(如开发、测试、生产)中,可以使用相同的控制器和配置来部署应用,确保应用在不同环境中的行为一致。这有助于减少部署差异和错误,提高开发和运维效率。
#创建控制器
[root@master ~]# kubectl create deployment app --image myapp:v1
deployment.apps/app created
[root@master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
app-fbf9c96c4-vm4kv 1/1 Running 0 5s#扩容
[root@master ~]# kubectl scale deployment app --replicas 4
deployment.apps/app scaled
[root@master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
app-fbf9c96c4-5chcb 1/1 Running 0 4s
app-fbf9c96c4-djgg5 1/1 Running 0 4s
app-fbf9c96c4-td9ff 1/1 Running 0 4s
app-fbf9c96c4-vm4kv 1/1 Running 0 63s版本更新
#利用控制器建立pod
[root@master ~]# kubectl create deployment app --image myapp:v1 --replicas 2
deployment.apps/timinglee created#暴漏端口
[root@master ~]# kubectl expose deployment app --port 80 --target-port 80
service/app exposed
[root@master ~]# kubectl get services
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
app ClusterIP 10.244.231.200 <none> 80/TCP 8s#访问服务
[root@master ~]# curl 10.244.231.200
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>#产看历史版本
[root@k8s-master ~]# kubectl rollout history deployment app
deployment.apps/app
REVISION CHANGE-CAUSE
1 <none>#更新控制器镜像版本
[root@k8s-master ~]# kubectl set image deployments/app myapp=myapp:v2
deployment.apps/app image updated#查看历史版本
[root@k8s-master ~]# kubectl rollout history deployment app
deployment.apps/app
REVISION CHANGE-CAUSE
1 <none>
2 <none>#访问内容测试
[root@k8s-master ~]# curl 10.244.231.200
Hello MyApp | Version: v2 | <a href="hostname.html">Pod Name</a>#版本回滚
[root@k8s-master ~]# kubectl rollout undo deployment app --to-revision 1
deployment.apps/timinglee rolled back
[root@k8s-master ~]# curl 10.244.231.200
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>
利用yaml文件部署应用
用yaml文件部署应用有以下优点
声明式配置:
- 清晰表达期望状态:以声明式的方式描述应用的部署需求,包括副本数量、容器配置、网络设置等。这使得配置易于理解和维护,并且可以方便地查看应用的预期状态。
- 可重复性和版本控制:配置文件可以被版本控制,确保在不同环境中的部署一致性。可以轻松回滚到以前的版本或在不同环境中重复使用相同的配置。
- 团队协作:便于团队成员之间共享和协作,大家可以对配置文件进行审查和修改,提高部署的可靠性和稳定性。
灵活性和可扩展性:
- 丰富的配置选项:可以通过 YAML 文件详细地配置各种 Kubernetes 资源,如 Deployment、Service、ConfigMap、Secret 等。可以根据应用的特定需求进行高度定制化。
- 组合和扩展:可以将多个资源的配置组合在一个或多个 YAML 文件中,实现复杂的应用部署架构。同时,可以轻松地添加新的资源或修改现有资源以满足不断变化的需求。
与工具集成:
- 与 CI/CD 流程集成:可以将 YAML 配置文件与持续集成和持续部署(CI/CD)工具集成,实现自动化的应用部署。例如,可以在代码提交后自动触发部署流程,使用配置文件来部署应用到不同的环境。
- 命令行工具支持:Kubernetes 的命令行工具
kubectl对 YAML 配置文件有很好的支持,可以方便地应用、更新和删除配置。同时,还可以使用其他工具来验证和分析 YAML 配置文件,确保其正确性和安全性。
资源清单参数
| 参数名称 | 类型 | 参数说明 |
|---|---|---|
| version | String | 这里是指的是K8S API的版本,目前基本上是v1,可以用kubectl api-versions命令查询 |
| kind | String | 这里指的是yaml文件定义的资源类型和角色,比如:Pod |
| metadata | Object | 元数据对象,固定值就写metadata |
| metadata.name | String | 元数据对象的名字,这里由我们编写,比如命名Pod的名字 |
| metadata.namespace | String | 元数据对象的命名空间,由我们自身定义 |
| Spec | Object | 详细定义对象,固定值就写Spec |
| spec.containers[] | list | 这里是Spec对象的容器列表定义,是个列表 |
| spec.containers[].name | String | 这里定义容器的名字 |
| spec.containers[].image | string | 这里定义要用到的镜像名称 |
| spec.containers[].imagePullPolicy | String | 定义镜像拉取策略,有三个值可选: (1) Always: 每次都尝试重新拉取镜像 (2) IfNotPresent:如果本地有镜像就使用本地镜像 (3) )Never:表示仅使用本地镜像 |
| spec.containers[].command[] | list | 指定容器运行时启动的命令,若未指定则运行容器打包时指定的命令 |
| spec.containers[].args[] | list | 指定容器运行参数,可以指定多个 |
| spec.containers[].workingDir | String | 指定容器工作目录 |
| spec.containers[].volumeMounts[] | list | 指定容器内部的存储卷配置 |
| spec.containers[].volumeMounts[].name | String | 指定可以被容器挂载的存储卷的名称 |
| spec.containers[].volumeMounts[].mountPath | String | 指定可以被容器挂载的存储卷的路径 |
| spec.containers[].volumeMounts[].readOnly | String | 设置存储卷路径的读写模式,ture或false,默认为读写模式 |
| spec.containers[].ports[] | list | 指定容器需要用到的端口列表 |
| spec.containers[].ports[].name | String | 指定端口名称 |
| spec.containers[].ports[].containerPort | String | 指定容器需要监听的端口号 |
| spec.containers[] ports[].hostPort | String | 指定容器所在主机需要监听的端口号,默认跟上面containerPort相同,注意设置了hostPort同一台主机无法启动该容器的相同副本(因为主机的端口号不能相同,这样会冲突) |
| spec.containers[].ports[].protocol | String | 指定端口协议,支持TCP和UDP,默认值为 TCP |
| spec.containers[].env[] | list | 指定容器运行前需设置的环境变量列表 |
| spec.containers[].env[].name | String | 指定环境变量名称 |
| spec.containers[].env[].value | String | 指定环境变量值 |
| spec.containers[].resources | Object | 指定资源限制和资源请求的值(这里开始就是设置容器的资源上限) |
| spec.containers[].resources.limits | Object | 指定设置容器运行时资源的运行上限 |
| spec.containers[].resources.limits.cpu | String | 指定CPU的限制,单位为核心数,1=1000m |
| spec.containers[].resources.limits.memory | String | 指定MEM内存的限制,单位为MIB、GiB |
| spec.containers[].resources.requests | Object | 指定容器启动和调度时的限制设置 |
| spec.containers[].resources.requests.cpu | String | CPU请求,单位为core数,容器启动时初始化可用数量 |
| spec.containers[].resources.requests.memory | String | 内存请求,单位为MIB、GIB,容器启动的初始化可用数量 |
| spec.restartPolicy | string | 定义Pod的重启策略,默认值为Always. (1)Always: Pod-旦终止运行,无论容器是如何 终止的,kubelet服务都将重启它 (2)OnFailure: 只有Pod以非零退出码终止时,kubelet才会重启该容器。如果容器正常结束(退出码为0),则kubelet将不会重启它 (3) Never: Pod终止后,kubelet将退出码报告给Master,不会重启该 |
| spec.nodeSelector | Object | 定义Node的Label过滤标签,以key:value格式指定 |
| spec.imagePullSecrets | Object | 定义pull镜像时使用secret名称,以name:secretkey格式指定 |
| spec.hostNetwork | Boolean | 定义是否使用主机网络模式,默认值为false。设置true表示使用宿主机网络,不使用docker网桥,同时设置了true将无法在同一台宿主机 上启动第二个副本 |
获得资源帮助
kubectl explain pod.spec.containers
示例1:运行简单的单个容器pod
用命令获取yaml模板
[root@k8s-master ~]# kubectl run timinglee --image myapp:v1 --dry-run=client -o yaml > pod.yml
[root@k8s-master ~]# vim pod.yml
apiVersion: v1
kind: Pod
metadata:labels:run: timing #pod标签name: timinglee #pod名称
spec:containers:- image: myapp:v1 #pod镜像name: timinglee #容器名称
示例2:运行多个容器pod
[!WARNING]
注意如果多个容器运行在一个pod中,资源共享的同时在使用相同资源时也会干扰,比如端口
#一个端口干扰示例:
[root@k8s-master ~]# vim pod.yml
apiVersion: v1
kind: Pod
metadata:labels:run: timingname: timinglee
spec:containers:- image: nginx:latestname: web1- image: nginx:latestname: web2[root@k8s-master ~]# kubectl apply -f pod.yml
pod/timinglee created[root@k8s-master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
timinglee 1/2 Error 1 (14s ago) 18s#查看日志
[root@k8s-master ~]# kubectl logs timinglee web2
2024/08/31 12:43:20 [emerg] 1#1: bind() to [::]:80 failed (98: Address already in use)
nginx: [emerg] bind() to [::]:80 failed (98: Address already in use)
2024/08/31 12:43:20 [notice] 1#1: try again to bind() after 500ms
2024/08/31 12:43:20 [emerg] 1#1: still could not bind()
nginx: [emerg] still could not bind()
[!NOTE]
在一个pod中开启多个容器时一定要确保容器彼此不能互相干扰
[root@k8s-master ~]# vim pod.yml[root@k8s-master ~]# kubectl apply -f pod.yml
pod/timinglee created
apiVersion: v1
kind: Pod
metadata:labels:run: timingname: timinglee
spec:containers:- image: nginx:latestname: web1- image: busybox:latestname: busyboxcommand: ["/bin/sh","-c","sleep 1000000"][root@k8s-master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
timinglee 2/2 Running 0 19s
示例3:理解pod间的网络整合
同在一个pod中的容器公用一个网络
[root@k8s-master ~]# vim pod.yml
apiVersion: v1
kind: Pod
metadata:labels:run: timingleename: test
spec:containers:- image: myapp:v1name: myapp1- image: busyboxplus:latestname: busyboxpluscommand: ["/bin/sh","-c","sleep 1000000"][root@k8s-master ~]# kubectl apply -f pod.yml
pod/test created
[root@k8s-master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
test 2/2 Running 0 8s
[root@k8s-master ~]# kubectl exec test -c busyboxplus -- curl -s localhost
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>示例4:端口映射
[root@k8s-master ~]# vim pod.yml
apiVersion: v1
kind: Pod
metadata:labels:run: timingleename: test
spec:containers:- image: myapp:v1name: myapp1ports:- name: httpcontainerPort: 80hostPort: 80protocol: TCP#测试
[root@k8s-master ~]# kubectl apply -f pod.yml
pod/test created[root@k8s-master ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
test 1/1 Running 0 12s 10.244.1.2 k8s-node1.timinglee.org <none> <none>
[root@k8s-master ~]# curl k8s-node1.timinglee.org
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>示例5:如何设定环境变量
[root@k8s-master ~]# vim pod.yml
apiVersion: v1
kind: Pod
metadata:labels:run: timingleename: test
spec:containers:- image: busybox:latestname: busyboxcommand: ["/bin/sh","-c","echo $NAME;sleep 3000000"]env:- name: NAMEvalue: timinglee[root@k8s-master ~]# kubectl apply -f pod.yml
pod/test created
[root@k8s-master ~]# kubectl logs pods/test busybox
timinglee
示例6:资源限制
[!NOTE]
资源限制会影响pod的Qos Class资源优先级,资源优先级分为Guaranteed > Burstable > BestEffort
QoS(Quality of Service)即服务质量
资源设定 优先级类型 资源限定未设定 BestEffort 资源限定设定且最大和最小不一致 Burstable 资源限定设定且最大和最小一致 Guaranteed
[root@k8s-master ~]# vim pod.yml
apiVersion: v1
kind: Pod
metadata:labels:run: timingleename: test
spec:containers:- image: myapp:v1name: myappresources:limits: #pod使用资源的最高限制 cpu: 500mmemory: 100Mrequests: #pod期望使用资源量,不能大于limitscpu: 500mmemory: 100Mroot@k8s-master ~]# kubectl apply -f pod.yml
pod/test created[root@k8s-master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
test 1/1 Running 0 3s[root@k8s-master ~]# kubectl describe pods testLimits:cpu: 500mmemory: 100MRequests:cpu: 500mmemory: 100M
QoS Class: Guaranteed
示例7 容器启动管理
[root@k8s-master ~]# vim pod.yml
apiVersion: v1
kind: Pod
metadata:labels:run: timingleename: test
spec:restartPolicy: Alwayscontainers:- image: myapp:v1name: myapp
[root@k8s-master ~]# kubectl apply -f pod.yml
pod/test created[root@k8s-master ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
test 1/1 Running 0 6s 10.244.2.3 k8s-node2 <none> <none>[root@k8s-node2 ~]# docker rm -f ccac1d64ea81
示例8 选择运行节点
[root@k8s-master ~]# vim pod.yml
apiVersion: v1
kind: Pod
metadata:labels:run: timingleename: test
spec:nodeSelector:kubernetes.io/hostname: k8s-node1restartPolicy: Alwayscontainers:- image: myapp:v1name: myapp[root@k8s-master ~]# kubectl apply -f pod.yml
pod/test created[root@k8s-master ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
test 1/1 Running 0 21s 10.244.1.5 k8s-node1 <none> <none>示例9 共享宿主机网络
[root@k8s-master ~]# vim pod.yml
apiVersion: v1
kind: Pod
metadata:labels:run: timingleename: test
spec:hostNetwork: truerestartPolicy: Alwayscontainers:- image: busybox:latestname: busyboxcommand: ["/bin/sh","-c","sleep 100000"]
[root@k8s-master ~]# kubectl apply -f pod.yml
pod/test created
[root@k8s-master ~]# kubectl exec -it pods/test -c busybox -- /bin/sh
/ # ifconfig
...eth0 Link encap:Ethernet HWaddr 00:0C:29:6A:A8:61inet addr:172.25.254.20 Bcast:172.25.254.255 Mask:255.255.255.0inet6 addr: fe80::8ff3:f39c:dc0c:1f0e/64 Scope:LinkUP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1RX packets:27858 errors:0 dropped:0 overruns:0 frame:0TX packets:14454 errors:0 dropped:0 overruns:0 carrier:0collisions:0 txqueuelen:1000RX bytes:26591259 (25.3 MiB) TX bytes:1756895 (1.6 MiB)
.../ # exit
pod生命周期
init容器
-
Pod 可以包含多个容器,应用运行在这些容器里面,同时 Pod 也可以有一个或多个先于应用容器启动的 Init 容器。
-
Init 容器与普通的容器非常像,除了如下两点:
-
它们总是运行到完成
-
init 容器不支持 Readiness,因为它们必须在 Pod 就绪之前运行完成,每个 Init 容器必须运行成功,下一个才能够运行。
-
-
如果Pod的 Init 容器失败,Kubernetes 会不断地重启该 Pod,直到 Init 容器成功为止。但是,如果 Pod 对应的 restartPolicy 值为 Never,它不会重新启动。
INIT 容器的功能
- Init 容器可以包含一些安装过程中应用容器中不存在的实用工具或个性化代码。
- Init 容器可以安全地运行这些工具,避免这些工具导致应用镜像的安全性降低。
- 应用镜像的创建者和部署者可以各自独立工作,而没有必要联合构建一个单独的应用镜像。
- Init 容器能以不同于Pod内应用容器的文件系统视图运行。因此,Init容器可具有访问 Secrets 的权限,而应用容器不能够访问。
- 由于 Init 容器必须在应用容器启动之前运行完成,因此 Init 容器提供了一种机制来阻塞或延迟应用容器的启动,直到满足了一组先决条件。一旦前置条件满足,Pod内的所有的应用容器会并行启动。
INIT 容器示例
[root@k8s-master ~]# vim pod.yml
apiVersion: v1
kind: Pod
metadata:labels:name: initpodname: initpod
spec:containers:- image: myapp:v1name: myappinitContainers:- name: init-myserviceimage: busyboxcommand: ["sh","-c","until test -e /testfile;do echo wating for myservice; sleep 2;done"][root@k8s-master ~]# kubectl apply -f pod.yml
pod/initpod created
[root@k8s-master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
initpod 0/1 Init:0/1 0 3s[root@k8s-master ~]# kubectl logs pods/initpod init-myservice
wating for myservice
wating for myservice
wating for myservice
wating for myservice
wating for myservice
wating for myservice
[root@k8s-master ~]# kubectl exec pods/initpod -c init-myservice -- /bin/sh -c "touch /testfile"[root@k8s-master ~]# kubectl get pods NAME READY STATUS RESTARTS AGE
initpod 1/1 Running 0 62s
探针
探针是由 kubelet 对容器执行的定期诊断:
- ExecAction:在容器内执行指定命令。如果命令退出时返回码为 0 则认为诊断成功。
- TCPSocketAction:对指定端口上的容器的 IP 地址进行 TCP 检查。如果端口打开,则诊断被认为是成功的。
- HTTPGetAction:对指定的端口和路径上的容器的 IP 地址执行 HTTP Get 请求。如果响应的状态码大于等于200 且小于 400,则诊断被认为是成功的。
每次探测都将获得以下三种结果之一:
- 成功:容器通过了诊断。
- 失败:容器未通过诊断。
- 未知:诊断失败,因此不会采取任何行动。
Kubelet 可以选择是否执行在容器上运行的三种探针执行和做出反应:
- livenessProbe:指示容器是否正在运行。如果存活探测失败,则 kubelet 会杀死容器,并且容器将受到其重启策略的影响。如果容器不提供存活探针,则默认状态为 Success。
- readinessProbe:指示容器是否准备好服务请求。如果就绪探测失败,端点控制器将从与 Pod 匹配的所有 Service 的端点中删除该 Pod 的 IP 地址。初始延迟之前的就绪状态默认为 Failure。如果容器不提供就绪探针,则默认状态为 Success。
- startupProbe: 指示容器中的应用是否已经启动。如果提供了启动探测(startup probe),则禁用所有其他探测,直到它成功为止。如果启动探测失败,kubelet 将杀死容器,容器服从其重启策略进行重启。如果容器没有提供启动探测,则默认状态为成功Success。
ReadinessProbe 与 LivenessProbe 的区别
- ReadinessProbe 当检测失败后,将 Pod 的 IP:Port 从对应的 EndPoint 列表中删除。
- LivenessProbe 当检测失败后,将杀死容器并根据 Pod 的重启策略来决定作出对应的措施
StartupProbe 与 ReadinessProbe、LivenessProbe 的区别
- 如果三个探针同时存在,先执行 StartupProbe 探针,其他两个探针将会被暂时禁用,直到 pod 满足 StartupProbe 探针配置的条件,其他 2 个探针启动,如果不满足按照规则重启容器。
- 另外两种探针在容器启动后,会按照配置,直到容器消亡才停止探测,而 StartupProbe 探针只是在容器启动后按照配置满足一次后,不在进行后续的探测。
探针实例
存活探针示例:
[root@k8s-master ~]# vim pod.yml
apiVersion: v1
kind: Pod
metadata:labels:name: livenessname: liveness
spec:containers:- image: myapp:v1name: myapplivenessProbe:tcpSocket: #检测端口存在性port: 8080initialDelaySeconds: 3 #容器启动后要等待多少秒后就探针开始工作,默认是 0periodSeconds: 1 #执行探测的时间间隔,默认为 10stimeoutSeconds: 1 #探针执行检测请求后,等待响应的超时时间,默认为 1s#测试:
[root@k8s-master ~]# kubectl apply -f pod.yml
pod/liveness created
[root@k8s-master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
liveness 0/1 CrashLoopBackOff 2 (7s ago) 22s[root@k8s-master ~]# kubectl describe pods
Warning Unhealthy 1s (x9 over 13s) kubelet Liveness probe failed: dial tcp 10.244.2.6:8080: connect: connection refused
3.2.1.2 就绪探针示例:
[root@k8s-master ~]# vim pod.yml
apiVersion: v1
kind: Pod
metadata:labels:name: readinessname: readiness
spec:containers:- image: myapp:v1name: myappreadinessProbe:httpGet:path: /test.htmlport: 80initialDelaySeconds: 1periodSeconds: 3timeoutSeconds: 1#测试:
[root@k8s-master ~]# kubectl expose pod readiness --port 80 --target-port 80[root@k8s-master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
readiness 0/1 Running 0 5m25s[root@k8s-master ~]# kubectl describe pods readiness
Warning Unhealthy 26s (x66 over 5m43s) kubelet Readiness probe failed: HTTP probe failed with statuscode: 404[root@k8s-master ~]# kubectl describe services readiness
Name: readiness
Namespace: default
Labels: name=readiness
Annotations: <none>
Selector: name=readiness
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.100.171.244
IPs: 10.100.171.244
Port: <unset> 80/TCP
TargetPort: 80/TCP
Endpoints: #没有暴漏端口,就绪探针探测不满足暴漏条件
Session Affinity: None
Events: <none>kubectl exec pods/readiness -c myapp -- /bin/sh -c "echo test > /usr/share/nginx/html/test.html"[root@k8s-master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
readiness 1/1 Running 0 7m49s[root@k8s-master ~]# kubectl describe services readiness
Name: readiness
Namespace: default
Labels: name=readiness
Annotations: <none>
Selector: name=readiness
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.100.171.244
IPs: 10.100.171.244
Port: <unset> 80/TCP
TargetPort: 80/TCP
Endpoints: 10.244.2.8:80 #满组条件端口暴漏
Session Affinity: None
Events: <none>k8s的控制器
控制器也是管理pod的一种手段
- 自主式pod:pod退出或意外关闭后不会被重新创建
- 控制器管理的 Pod:在控制器的生命周期里,始终要维持 Pod 的副本数目
Pod控制器是管理pod的中间层,使用Pod控制器之后,只需要告诉Pod控制器,想要多少个什么样的Pod就可以了,它会创建出满足条件的Pod并确保每一个Pod资源处于用户期望的目标状态。如果Pod资源在运行中出现故障,它会基于指定策略重新编排Pod
当建立控制器后,会把期望值写入etcd,k8s中的apiserver检索etcd中我们保存的期望状态,并对比pod的当前状态,如果出现差异代码自驱动立即恢复
Replicaset控制器
概述
ReplicaSet是kubernetes中的一种副本控制器,简称rs,主要作用是控制由其管理的pod,使pod副本的数量始终维持在预设的个数。它的主要作用就是保证一定数量的Pod能够在集群中正常运行,它会持续监听这些Pod的运行状态,在Pod发生故障时重启pod,pod数量减少时重新运行新的 Pod副本。官方推荐不要直接使用ReplicaSet,用Deployments取而代之,Deployments是比ReplicaSet更高级的概念,它会管理ReplicaSet并提供很多其它有用的特性,最重要的是Deployments支持声明式更新,声明式更新的好处是不会丢失历史变更。所以Deployment控制器不直接管理Pod对象,而是由 Deployment 管理ReplicaSet,再由ReplicaSet负责管理Pod对象。
工作原理
Replicaset核心作用在于用户创建指定数量的pod副本,并确保pod副本一直处于满足用户期望的数量, 起到多退少补的作用,并且还具有自动扩容缩容等制。
Replicaset控制器主要由三个部分组成:
- 用户期望的pod副本数:用来定义由这个控制器管控的pod副本有几个
- 标签选择器:选定哪些pod是自己管理的,如果通过标签选择器选到的pod副本数量少于我们指定的数量,需要用到下面的组件
- pod资源模板:如果集群中现存的pod数量不够我们定义的副本中期望的数量怎么办,需要新建pod,这就需要pod模板,新建的pod是基于模板来创建的。
#编写一个ReplicaSet资源清单
[root@master1 ~]# cat replicaset.yml
---
apiVersion: apps/v1
kind: ReplicaSet
metadata:name: frontendlabels:app: nginxtier: frontend
spec:replicas: 3selector:matchLabels:tier: frontendtemplate:metadata:labels:tier: frontendspec:containers:- name: nginximage: nginximagePullPolicy: IfNotPresent[root@master ~]# kubectl apply -f replicaset.yaml
replicaset.apps/frontend created
[root@master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
frontend-7rrp6 1/1 Running 0 9s
frontend-drmcf 1/1 Running 0 9s
frontend-qnlz6 1/1 Running 0 9s
[root@master ~]# kubectl get rs
NAME DESIRED CURRENT READY AGE
frontend 3 3 3 41sDeployment控制器
Deployment对象,顾名思义,是用于部署应用的对象。它使Kubernetes中最常用的一个对象,它为ReplicaSet和Pod的创建提供了一种声明式的定义方法,从而无需像前两篇文章中那样手动创建ReplicaSet和Pod对象(使用Deployment而不直接创建ReplicaSet是因为Deployment对象拥有许多ReplicaSet没有的特性,例如滚动升级和回滚)。
通过Deployment对象,你可以轻松的做到以下事情:
- 创建ReplicaSet和Pod
- 滚动升级(不停止旧服务的状态下升级)和回滚应用(将应用回滚到之前的版本)
- 平滑地扩容和缩容
- 暂停和继续Deployment
创建
生成模板
kubectl create deployment deployment --image myapp:v1 --dry-run=client -o yaml > deployment.yml[root@master ~]# vim deployment.yml
apiVersion: apps/v1
kind: Deployment
metadata:name: deployment
spec:replicas: 4selector:matchLabels:app: myapptemplate:metadata:labels:app: myappspec:containers:- image: myapp:v1name: myapp生效
kubectl apply -f deployment.yml查看
[root@master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
deployment-74d589986c-kxcvx 1/1 Running 0 2m11s
deployment-74d589986c-s277p 1/1 Running 0 2m11s
deployment-74d589986c-zlf8v 1/1 Running 0 2m11s版本迭代
[root@k8s-master ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
deployment-5d886954d4-2ckqw 1/1 Running 0 2m40s 10.244.2.14 k8s-node2 <none> <none>
deployment-5d886954d4-m8gpd 1/1 Running 0 2m40s 10.244.1.17 k8s-node1 <none> <none>
deployment-5d886954d4-s7pws 1/1 Running 0 2m40s 10.244.1.16 k8s-node1 <none> <none>
deployment-5d886954d4-wqnvv 1/1 Running 0 2m40s 10.244.2.15 k8s-node2 <none> <none>#pod运行容器版本为v1
[root@k8s-master ~]# curl 10.244.2.14
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>[root@k8s-master ~]# kubectl describe deployments.apps deployment
Name: deployment
Namespace: default
CreationTimestamp: Sun, 01 Sep 2024 23:19:10 +0800
Labels: <none>
Annotations: deployment.kubernetes.io/revision: 1
Selector: app=myapp
Replicas: 4 desired | 4 updated | 4 total | 4 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 25% max unavailable, 25% max surge #默认每次更新25%#更新容器运行版本
[root@k8s-master ~]# vim deployment.yml
apiVersion: apps/v1
kind: Deployment
metadata:name: deployment
spec:minReadySeconds: 5 #最小就绪时间5秒replicas: 4selector:matchLabels:app: myapptemplate:metadata:labels:app: myappspec:containers:- image: myapp:v2 #更新为版本2name: myapp[root@k8s2 pod]# kubectl apply -f deployment-example.yaml#更新过程
[root@k8s-master ~]# watch - n1 kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE
deployment-5d886954d4-8kb28 1/1 Running 0 48s
deployment-5d886954d4-8s4h8 1/1 Running 0 49s
deployment-5d886954d4-rclkp 1/1 Running 0 50s
deployment-5d886954d4-tt2hz 1/1 Running 0 50s
deployment-7f4786db9c-g796x 0/1 Pending 0 0s#测试更新效果
[root@k8s-master ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
deployment-7f4786db9c-967fk 1/1 Running 0 10s 10.244.1.26 k8s-node1 <none> <none>
deployment-7f4786db9c-cvb9k 1/1 Running 0 10s 10.244.2.24 k8s-node2 <none> <none>
deployment-7f4786db9c-kgss4 1/1 Running 0 9s 10.244.1.27 k8s-node1 <none> <none>
deployment-7f4786db9c-qts8c 1/1 Running 0 9s 10.244.2.25 k8s-node2 <none> <none>[root@k8s-master ~]# curl 10.244.1.26
Hello MyApp | Version: v2 | <a href="hostname.html">Pod Name</a>
版本回滚
[root@k8s-master ~]# vim deployment.yml
apiVersion: apps/v1
kind: Deployment
metadata:name: deployment
spec:replicas: 4selector:matchLabels:app: myapptemplate:metadata:labels:app: myappspec:containers:- image: myapp:v1 #回滚到之前版本name: myapp[root@k8s-master ~]# kubectl apply -f deployment.yml
deployment.apps/deployment configured#测试回滚效果
[root@k8s-master ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
deployment-5d886954d4-dr74h 1/1 Running 0 8s 10.244.2.26 k8s-node2 <none> <none>
deployment-5d886954d4-thpf9 1/1 Running 0 7s 10.244.1.29 k8s-node1 <none> <none>
deployment-5d886954d4-vmwl9 1/1 Running 0 8s 10.244.1.28 k8s-node1 <none> <none>
deployment-5d886954d4-wprpd 1/1 Running 0 6s 10.244.2.27 k8s-node2 <none> <none>[root@k8s-master ~]# curl 10.244.2.26
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>
滚动更新策略
[root@k8s-master ~]# vim deployment.yml
apiVersion: apps/v1
kind: Deployment
metadata:name: deployment
spec:minReadySeconds: 5 #最小就绪时间,指定pod每隔多久更新一次replicas: 4strategy: #指定更新策略rollingUpdate:maxSurge: 1 #比定义pod数量多几个maxUnavailable: 0 #比定义pod个数少几个selector:matchLabels:app: myapptemplate:metadata:labels:app: myappspec:containers:- image: myapp:v1name: myapp
[root@k8s2 pod]# kubectl apply -f deployment-example.yaml
暂停及恢复
在实际生产环境中我们做的变更可能不止一处,当修改了一处后,如果执行变更就直接触发了
我们期望的触发时当我们把所有修改都搞定后一次触发
暂停,避免触发不必要的线上更新
[root@k8s2 pod]# kubectl rollout pause deployment deployment-example[root@k8s2 pod]# vim deployment-example.yaml
apiVersion: apps/v1
kind: Deployment
metadata:name: deployment-example
spec:minReadySeconds: 5strategy:rollingUpdate:maxSurge: 1maxUnavailable: 0replicas: 6 selector:matchLabels:app: myapptemplate:metadata:labels:app: myappspec:containers:- name: myappimage: nginxresources:limits:cpu: 0.5memory: 200Mirequests:cpu: 0.5memory: 200Mi[root@k8s2 pod]# kubectl apply -f deployment-example.yaml#调整副本数,不受影响
[root@k8s-master ~]# kubectl describe pods deployment-7f4786db9c-8jw22
Name: deployment-7f4786db9c-8jw22
Namespace: default
Priority: 0
Service Account: default
Node: k8s-node1/172.25.254.10
Start Time: Mon, 02 Sep 2024 00:27:20 +0800
Labels: app=myapppod-template-hash=7f4786db9c
Annotations: <none>
Status: Running
IP: 10.244.1.31
IPs:IP: 10.244.1.31
Controlled By: ReplicaSet/deployment-7f4786db9c
Containers:myapp:Container ID: docker://01ad7216e0a8c2674bf17adcc9b071e9bfb951eb294cafa2b8482bb8b4940c1dImage: myapp:v2Image ID: docker-pullable://myapp@sha256:5f4afc8302ade316fc47c99ee1d41f8ba94dbe7e3e7747dd87215a15429b9102Port: <none>Host Port: <none>State: RunningStarted: Mon, 02 Sep 2024 00:27:21 +0800Ready: TrueRestart Count: 0Environment: <none>Mounts:/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-mfjjp (ro)
Conditions:Type StatusPodReadyToStartContainers TrueInitialized TrueReady TrueContainersReady TruePodScheduled True
Volumes:kube-api-access-mfjjp:Type: Projected (a volume that contains injected data from multiple sources)TokenExpirationSeconds: 3607ConfigMapName: kube-root-ca.crtConfigMapOptional: <nil>DownwardAPI: true
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300snode.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:Type Reason Age From Message---- ------ ---- ---- -------Normal Scheduled 6m22s default-scheduler Successfully assigned default/deployment-7f4786db9c-8jw22 to k8s-node1Normal Pulled 6m22s kubelet Container image "myapp:v2" already present on machineNormal Created 6m21s kubelet Created container myappNormal Started 6m21s kubelet Started container myapp#但是更新镜像和修改资源并没有触发更新
[root@k8s2 pod]# kubectl rollout history deployment deployment-example
deployment.apps/deployment-example
REVISION CHANGE-CAUSE
3 <none>
4 <none>#恢复后开始触发更新
[root@k8s2 pod]# kubectl rollout resume deployment deployment-example[root@k8s2 pod]# kubectl rollout history deployment deployment-example
deployment.apps/deployment-example
REVISION CHANGE-CAUSE
3 <none>
4 <none>
5 <none>#回收
[root@k8s2 pod]# kubectl delete -f deployment-example.yaml
DaemonSet控制器
简介
DaemonSet:服务守护进程,它的主要作用是在Kubernetes集群的所有节点中运行我们部署的守护进程,相当于在集群节点上分别部署Pod副本,如果有新节点加入集群,Daemonset会自动的在该节点上运行我们需要部署的Pod副本,相反如果有节点退出集群,Daemonset也会移除掉部署在旧节点的Pod副本。
特征:
- 这个 Pod 运行在 Kubernetes 集群里的每一个节点(Node)上;
- 每个节点上只会运行一个这样的 Pod 实例;
- 如果新的节点加入 Kubernetes 集群后,该 Pod 会自动地在新节点上被创建出来;
- 而当旧节点被删除后,它上面的 Pod 也相应地会被回收掉。
调度特性
默认情况下,Pod被分配到具体哪一台Node上运行是由Scheduler(负责分配调度Pod到集群内的Node上,它通过监听ApiServer,查询还未分配Node的Pod,然后根据调度策略为这些Pod分配Node)决定的。但是,DaemonSet对象创建的Pod却拥有一些特殊的特性:
- Node的 unschedulable属性会被DaemonSet Controller忽略。
- 即使Scheduler还未启动,DaemonSet Controller也能够创建并运行Pod。
常用场景:
- 网络插件的 Agent 组件,如(Flannel,Calico)需要运行在每一个节点上,用来处理这个节点上的容器网络;
- 存储插件的 Agent 组件,如(Ceph,Glusterfs)需要运行在每一个节点上,用来在这个节点上挂载F远程存储目录;
- 监控系统的数据收集组件,如(Prometheus Node Exporter,Cadvisor)需要运行在每一个节点上,负责这个节点上的监控信息搜集。
- 日志系统的数据收集组件,如(Fluent,Logstash)需要运行在每一个节点上,负责这个节点上的日志信息搜集。
apiVersion: apps/v1
kind: DaemonSet
metadata:name: daemonset-example
spec:selector:matchLabels:app: nginxtemplate:metadata:labels:app: nginxspec:tolerations: #对于污点节点的容忍- effect: NoScheduleoperator: Existscontainers:- name: nginximage: nginx[root@master ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
daemonset-67njh 1/1 Running 0 6s 10.244.0.8 master <none> <none>
daemonset-jo1k2 1/1 Running 0 6s 10.244.2.38 k8s-2 <none> <none>
daemonset-dsafe 1/1 Running 0 6s 10.244.1.40 k8s-1 <none> <none>
job控制器
Job,主要用于负责批量处理(一次要处理指定数量任务)短暂的一次性(每个任务仅运行一次就结束)任务
Job特点如下:
- 当Job创建的pod执行成功结束时,Job将记录成功结束的pod数量
- 当成功结束的pod达到指定的数量时,Job将完成执行
[root@k8s2 pod]# vim job.yml
apiVersion: batch/v1
kind: Job
metadata:name: pi
spec:completions: 6 #一共完成任务数为6 parallelism: 2 #每次并行完成2个template:spec:containers:- name: piimage: perl:5.34.0command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"] 计算Π的后2000位restartPolicy: Never #关闭后不自动重启backoffLimit: 4 #运行失败后尝试4重新运行[root@k8s2 pod]# kubectl apply -f job.yml
cronjob 控制器
-
Cron Job 创建基于时间调度的 Jobs。
-
CronJob控制器以Job控制器资源为其管控对象,并借助它管理pod资源对象,
-
CronJob可以以类似于Linux操作系统的周期性任务作业计划的方式控制其运行时间点及重复运行的方式。
-
CronJob可以在特定的时间点(反复的)去运行job任务。
apiVersion: batch/v1
kind: CronJob
metadata:name: hello
spec:schedule: "* * * * *"jobTemplate:spec:template:spec:containers:- name: helloimage: busyboximagePullPolicy: IfNotPresentcommand:- /bin/sh- -c- date; echo Hello from the Kubernetes clusterrestartPolicy: OnFailure[root@k8s2 pod]# kubectl apply -f cronjob.yml
statefulset控制器
5.1 功能特性
-
Statefulset是为了管理有状态服务的问提设计的
-
StatefulSet将应用状态抽象成了两种情况:
-
拓扑状态:应用实例必须按照某种顺序启动。新创建的Pod必须和原来Pod的网络标识一样
-
存储状态:应用的多个实例分别绑定了不同存储数据。
-
StatefulSet给所有的Pod进行了编号,编号规则是:(statefulset名称)−(statefulset名称)-(statefulset名称)−(序号),从0开始。
-
Pod被删除后重建,重建Pod的网络标识也不会改变,Pod的拓扑状态按照Pod的“名字+编号”的方式固定下来,并且为每个Pod提供了一个固定且唯一的访问入口,Pod对应的DNS记录。
5.2 StatefulSet的组成部分
-
Headless Service:用来定义pod网络标识,生成可解析的DNS记录
-
volumeClaimTemplates:创建pvc,指定pvc名称大小,自动创建pvc且pvc由存储类供应。
-
StatefulSet:管理pod的
5.3 构建方法
#建立无头服务
[root@k8s-master statefulset]# vim headless.yml
apiVersion: v1
kind: Service
metadata:name: nginx-svclabels:app: nginx
spec:ports:- port: 80name: webclusterIP: Noneselector:app: nginx
[root@k8s-master statefulset]# kubectl apply -f headless.yml#建立statefulset
[root@k8s-master statefulset]# vim statefulset.yml
apiVersion: apps/v1
kind: StatefulSet
metadata:name: web
spec:serviceName: "nginx-svc"replicas: 3selector:matchLabels:app: nginxtemplate:metadata:labels:app: nginxspec:containers:- name: nginximage: nginxvolumeMounts:- name: wwwmountPath: /usr/share/nginx/htmlvolumeClaimTemplates:- metadata:name: wwwspec:storageClassName: nfs-clientaccessModes:- ReadWriteOnceresources:requests:storage: 1Gi
[root@k8s-master statefulset]# kubectl apply -f statefulset.yml
statefulset.apps/web configured
root@k8s-master statefulset]# kubectl get pods
NAME READY STATUS RESTARTS AGE
web-0 1/1 Running 0 3m26s
web-1 1/1 Running 0 3m22s
web-2 1/1 Running 0 3m18s[root@reg nfsdata]# ls /nfsdata/
default-test-claim-pvc-34b3d968-6c2b-42f9-bbc3-d7a7a02dcbac
default-www-web-0-pvc-0390b736-477b-4263-9373-a53d20cc8f9f
default-www-web-1-pvc-a5ff1a7b-fea5-4e77-afd4-cdccedbc278c
default-www-web-2-pvc-83eff88b-4ae1-4a8a-b042-8899677ae854
5.4 测试:
#为每个pod建立index.html文件[root@reg nfsdata]# echo web-0 > default-www-web-0-pvc-0390b736-477b-4263-9373-a53d20cc8f9f/index.html
[root@reg nfsdata]# echo web-1 > default-www-web-1-pvc-a5ff1a7b-fea5-4e77-afd4-cdccedbc278c/index.html
[root@reg nfsdata]# echo web-2 > default-www-web-2-pvc-83eff88b-4ae1-4a8a-b042-8899677ae854/index.html#建立测试pod访问web-0~2
[root@k8s-master statefulset]# kubectl run -it testpod --image busyboxplus
/ # curl web-0.nginx-svc
web-0
/ # curl web-1.nginx-svc
web-1
/ # curl web-2.nginx-svc
web-2#删掉重新建立statefulset
[root@k8s-master statefulset]# kubectl delete -f statefulset.yml
statefulset.apps "web" deleted
[root@k8s-master statefulset]# kubectl apply -f statefulset.yml
statefulset.apps/web created#访问依然不变
[root@k8s-master statefulset]# kubectl attach testpod -c testpod -i -t
If you don't see a command prompt, try pressing enter.
/ # cu
curl cut
/ # curl web-0.nginx-svc
web-0
/ # curl web-1.nginx-svc
web-1
/ # curl web-2.nginx-svc
web-2
5.5 statefulset的弹缩
首先,想要弹缩的StatefulSet. 需先清楚是否能弹缩该应用
用命令改变副本数
kubectl scale statefulsets <stateful-set-name> --replicas=<new-replicas>
通过编辑配置改变副本数
kubectl edit statefulsets.apps <stateful-set-name>
statefulset有序回收
[root@k8s-master statefulset]# kubectl scale statefulset web --replicas 0
statefulset.apps/web scaled
[root@k8s-master statefulset]# kubectl delete -f statefulset.yml
statefulset.apps "web" deleted
[root@k8s-master statefulset]# kubectl delete pvc --all
persistentvolumeclaim "test-claim" deleted
persistentvolumeclaim "www-web-0" deleted
persistentvolumeclaim "www-web-1" deleted
persistentvolumeclaim "www-web-2" deleted
persistentvolumeclaim "www-web-3" deleted
persistentvolumeclaim "www-web-4" deleted
persistentvolumeclaim "www-web-5" deleted
[root@k8s2 statefulset]# kubectl scale statefulsets web --replicas=0[root@k8s2 statefulset]# kubectl delete -f statefulset.yaml[root@k8s2 mysql]# kubectl delete pvc --all
微服务
用控制器来完成集群的工作负载,那么应用如何暴漏出去?需要通过微服务暴漏出去后才能被访问
- Service是一组提供相同服务的Pod对外开放的接口。
- 借助Service,应用可以实现服务发现和负载均衡。
- service默认只支持4层负载均衡能力,没有7层功能。(可以通过Ingress实现)
ipvs模式
在所有节点中安装ipvsadm
yum install ipvsadm –y
2 修改master节点的代理配置
kubectl -n kube-system edit cm kube-proxymode: "ipvs" #设置kube-proxy使用ipvs模式3 重启pod,在pod运行时配置文件中采用默认配置,当改变配置文件后已经运行的pod状态不会变化,所以要重启pod
kubectl -n kube-system get pods | awk '/kube-proxy/{system("kubectl -n kube-system delete pods "$1)}'[root@master ~]# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.96.0.1:443 rr-> 172.25.254.100:6443 Masq 1 0 0
TCP 10.96.0.10:53 rr-> 10.244.0.2:53 Masq 1 0 0-> 10.244.0.3:53 Masq 1 0 0
TCP 10.96.0.10:9153 rr-> 10.244.0.2:9153 Masq 1 0 0-> 10.244.0.3:9153 Masq 1 0 0
TCP 10.97.59.25:80 rr-> 10.244.1.17:80 Masq 1 0 0-> 10.244.2.13:80 Masq 1 0 0
UDP 10.96.0.10:53 rr-> 10.244.0.2:53 Masq 1 0 0-> 10.244.0.3:53 Masq 1 0 0[!NOTE]
切换ipvs模式后,kube-proxy会在宿主机上添加一个虚拟网卡:kube-ipvs0,并分配所有service IP
[root@k8s-master ~]# ip a | tail inet6 fe80::c4fb:e9ff:feee:7d32/64 scope linkvalid_lft forever preferred_lft forever 8: kube-ipvs0: <BROADCAST,NOARP> mtu 1500 qdisc noop state DOWN group default link/ether fe:9f:c8:5d:a6:c8 brd ff:ff:ff:ff:ff:ff inet 10.96.0.10/32 scope global kube-ipvs0valid_lft forever preferred_lft forever inet 10.96.0.1/32 scope global kube-ipvs0valid_lft forever preferred_lft forever inet 10.97.59.25/32 scope global kube-ipvs0valid_lft forever preferred_lft forever
微服务类型详解
clusterip
clusterip模式只能在集群内访问,并对集群内的pod提供健康检测和自动发现功能
[root@k8s2 service]# vim myapp.yml
---
apiVersion: v1
kind: Service
metadata:labels:app: timingleename: timinglee
spec:ports:- port: 80protocol: TCPtargetPort: 80selector:app: timingleetype: ClusterIPservice创建后集群DNS提供解析
[root@k8s-master ~]# dig timinglee.default.svc.cluster.local @10.96.0.10; <<>> DiG 9.16.23-RH <<>> timinglee.default.svc.cluster.local @10.96.0.10
;; global options: +cmd
;; Got answer:
;; WARNING: .local is reserved for Multicast DNS
;; You are currently testing what happens when an mDNS query is leaked to DNS
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 27827
;; flags: qr aa rd; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
;; WARNING: recursion requested but not available;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 4096
; COOKIE: 057d9ff344fe9a3a (echoed)
;; QUESTION SECTION:
;timinglee.default.svc.cluster.local. IN A;; ANSWER SECTION:
timinglee.default.svc.cluster.local. 30 IN A 10.97.59.25;; Query time: 8 msec
;; SERVER: 10.96.0.10#53(10.96.0.10)
;; WHEN: Wed Sep 04 13:44:30 CST 2024
;; MSG SIZE rcvd: 127
headless(无头服务)
对于无头
Services并不会分配 Cluster IP,kube-proxy不会处理它们, 而且平台也不会为它们进行负载均衡和路由,集群访问通过dns解析直接指向到业务pod上的IP,所有的调度有dns单独完成
[root@k8s-master ~]# vim timinglee.yaml
---
apiVersion: v1
kind: Service
metadata:labels:app: timingleename: timinglee
spec:ports:- port: 80protocol: TCPtargetPort: 80selector:app: timingleetype: ClusterIPclusterIP: None[root@k8s-master ~]# kubectl delete -f timinglee.yaml
[root@k8s-master ~]# kubectl apply -f timinglee.yaml
deployment.apps/timinglee created#测试
[root@k8s-master ~]# kubectl get services timinglee
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
timinglee ClusterIP None <none> 80/TCP 6s[root@k8s-master ~]# dig timinglee.default.svc.cluster.local @10.96.0.10; <<>> DiG 9.16.23-RH <<>> timinglee.default.svc.cluster.local @10.96.0.10
;; global options: +cmd
;; Got answer:
;; WARNING: .local is reserved for Multicast DNS
;; You are currently testing what happens when an mDNS query is leaked to DNS
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 51527
;; flags: qr aa rd; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 1
;; WARNING: recursion requested but not available;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 4096
; COOKIE: 81f9c97b3f28b3b9 (echoed)
;; QUESTION SECTION:
;timinglee.default.svc.cluster.local. IN A;; ANSWER SECTION:
timinglee.default.svc.cluster.local. 20 IN A 10.244.2.14 #直接解析到pod上
timinglee.default.svc.cluster.local. 20 IN A 10.244.1.18;; Query time: 0 msec
;; SERVER: 10.96.0.10#53(10.96.0.10)
;; WHEN: Wed Sep 04 13:58:23 CST 2024
;; MSG SIZE rcvd: 178#开启一个busyboxplus的pod测试
[root@k8s-master ~]# kubectl run test --image busyboxplus -it
If you don't see a command prompt, try pressing enter.
/ # nslookup timinglee-service
Server: 10.96.0.10
Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.localName: timinglee-service
Address 1: 10.244.2.16 10-244-2-16.timinglee-service.default.svc.cluster.local
Address 2: 10.244.2.17 10-244-2-17.timinglee-service.default.svc.cluster.local
Address 3: 10.244.1.22 10-244-1-22.timinglee-service.default.svc.cluster.local
Address 4: 10.244.1.21 10-244-1-21.timinglee-service.default.svc.cluster.local
/ # curl timinglee-service
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>
/ # curl timinglee-service/hostname.html
timinglee-c56f584cf-b8t6mnodeport
通过ipvs暴漏端口从而使外部主机通过master节点的对外ip:来访问pod业务
[root@k8s-master ~]# vim timinglee.yaml
---apiVersion: v1
kind: Service
metadata:labels:app: timinglee-servicename: timinglee-service
spec:ports:- port: 80protocol: TCPtargetPort: 80selector:app: timingleetype: NodePort[root@k8s-master ~]# kubectl apply -f timinglee.yaml
deployment.apps/timinglee created
service/timinglee-service created
[root@k8s-master ~]# kubectl get services timinglee-service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
timinglee-service NodePort 10.98.60.22 <none> 80:31771/TCP 8nodeport在集群节点上绑定端口,一个端口对应一个服务
[root@k8s-master ~]# for i in {1..5}
> do
> curl 172.25.254.100:31771/hostname.html
> done
timinglee-c56f584cf-fjxdk
timinglee-c56f584cf-5m2z5
timinglee-c56f584cf-z2w4d
timinglee-c56f584cf-tt5g6
timinglee-c56f584cf-fjxdk[!NOTE]
nodeport默认端口
nodeport默认端口是30000-32767,超出会报错
[root@k8s-master ~]# vim timinglee.yaml
apiVersion: v1
kind: Service
metadata:labels:app: timinglee-servicename: timinglee-service
spec:ports:- port: 80protocol: TCPtargetPort: 80nodePort: 33333selector:app: timingleetype: NodePort[root@k8s-master ~]# kubectl apply -f timinglee.yaml
deployment.apps/timinglee created
The Service "timinglee-service" is invalid: spec.ports[0].nodePort: Invalid value: 33333: provided port is not in the valid range. The range of valid ports is 30000-32767
如果需要使用这个范围以外的端口就需要特殊设定
[root@k8s-master ~]# vim /etc/kubernetes/manifests/kube-apiserver.yaml- --service-node-port-range=30000-40000
[!NOTE]
添加“–service-node-port-range=“ 参数,端口范围可以自定义
修改后api-server会自动重启,等apiserver正常启动后才能操作集群
集群重启自动完成在修改完参数后全程不需要人为干预
loadbalancer
云平台会为我们分配vip并实现访问,如果是裸金属主机那么需要metallb来实现ip的分配
[root@k8s-master ~]# vim timinglee.yaml---
apiVersion: v1
kind: Service
metadata:labels:app: timinglee-servicename: timinglee-service
spec:ports:- port: 80protocol: TCPtargetPort: 80selector:app: timingleetype: LoadBalancer[root@k8s2 service]# kubectl apply -f myapp.yml默认无法分配外部访问IP
[root@k8s2 service]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 4d1h
myapp LoadBalancer 10.107.23.134 <pending> 80:32537/TCP 4sLoadBalancer模式适用云平台,裸金属环境需要安装metallb提供支持
metalLB
为LoadBalancer分配vip
部署方式
1.设置ipvs模式
[root@k8s-master ~]# kubectl edit cm -n kube-system kube-proxy
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
mode: "ipvs"
ipvs:strictARP: true[root@k8s-master ~]# kubectl -n kube-system get pods | awk '/kube-proxy/{system("kubectl -n kube-system delete pods "$1)}'2.下载部署文件
[root@k8s2 metallb]# wget https://raw.githubusercontent.com/metallb/metallb/v0.13.12/config/manifests/metallb-native.yaml3.修改文件中镜像地址,与harbor仓库路径保持一致
[root@k8s-master ~]# vim metallb-native.yaml
...
image: metallb/controller:v0.14.8
image: metallb/speaker:v0.14.84.上传镜像到harbor
[root@k8s-master ~]# docker pull quay.io/metallb/controller:v0.14.8
[root@k8s-master ~]# docker pull quay.io/metallb/speaker:v0.14.8[root@k8s-master ~]# docker tag quay.io/metallb/speaker:v0.14.8 reg.timinglee.org/metallb/speaker:v0.14.8
[root@k8s-master ~]# docker tag quay.io/metallb/controller:v0.14.8 reg.timinglee.org/metallb/controller:v0.14.8[root@k8s-master ~]# docker push reg.timinglee.org/metallb/speaker:v0.14.8
[root@k8s-master ~]# docker push reg.timinglee.org/metallb/controller:v0.14.8部署服务
[root@k8s2 metallb]# kubectl apply -f metallb-native.yaml
[root@k8s-master ~]# kubectl -n metallb-system get pods
NAME READY STATUS RESTARTS AGE
controller-65957f77c8-25nrw 1/1 Running 0 30s
speaker-p94xq 1/1 Running 0 29s
speaker-qmpct 1/1 Running 0 29s
speaker-xh4zh 1/1 Running 0 30s配置分配地址段
[root@k8s-master ~]# vim configmap.yml
apiVersion: metallb.io/v1beta1
kind: IPAddressPool
metadata:name: first-pool #地址池名称namespace: metallb-system
spec:addresses:- 172.25.254.50-172.25.254.99 #修改为自己本地地址段--- #两个不同的kind中间必须加分割
apiVersion: metallb.io/v1beta1
kind: L2Advertisement
metadata:name: examplenamespace: metallb-system
spec:ipAddressPools:- first-pool #使用地址池 [root@k8s-master ~]# kubectl apply -f configmap.yml
ipaddresspool.metallb.io/first-pool created
l2advertisement.metallb.io/example created[root@k8s-master ~]# kubectl get services
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 21h
timinglee-service LoadBalancer 10.109.36.123 172.25.254.50 80:31595/TCP 9m9s#通过分配地址从集群外访问服务
[root@reg ~]# curl 172.25.254.50
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>externalname
- 开启services后,不会被分配IP,而是用dns解析CNAME固定域名来解决ip变化问题
- 一般应用于外部业务和pod沟通或外部业务迁移到pod内时
- 在应用向集群迁移过程中,externalname在过度阶段就可以起作用了。
- 集群外的资源迁移到集群时,在迁移的过程中ip可能会变化,但是域名+dns解析能完美解决此问题
[root@k8s-master ~]# vim timinglee.yaml
---
apiVersion: v1
kind: Service
metadata:labels:app: timinglee-servicename: timinglee-service
spec:selector:app: timingleetype: ExternalNameexternalName: www.timinglee.org[root@k8s-master ~]# kubectl apply -f timinglee.yaml[root@k8s-master ~]# kubectl get services timinglee-service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
timinglee-service ExternalName <none> www.timinglee.org <none> 2m58sIngress-nginx
ingress-nginx功能
- 一种全局的、为了代理不同后端 Service 而设置的负载均衡服务,支持7层
- Ingress由两部分组成:Ingress controller和Ingress服务
- Ingress Controller 会根据你定义的 Ingress 对象,提供对应的代理能力。
- 业界常用的各种反向代理项目,比如 Nginx、HAProxy、Envoy、Traefik 等,都已经为Kubernetes 专门维护了对应的 Ingress Controller。
部署ingress
下载部署文件
[root@k8s-master ~]# wget https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v1.11.2/deploy/static/provider/baremetal/deploy.yaml
上传ingress所需镜像到harbor
[root@k8s-master ~]# docker tag registry.k8s.io/ingress-nginx/controller:v1.11.2@sha256:d5f8217feeac4887cb1ed21f27c2674e58be06bd8f5184cacea2a69abaf78dce reg.timinglee.org/ingress-nginx/controller:v1.11.2[root@k8s-master ~]# docker tag registry.k8s.io/ingress-nginx/kube-webhook-certgen:v1.4.3@sha256:a320a50cc91bd15fd2d6fa6de58bd98c1bd64b9a6f926ce23a600d87043455a3 reg.timinglee.org/ingress-nginx/kube-webhook-certgen:v1.4.3[root@k8s-master ~]# docker push reg.timinglee.org/ingress-nginx/controller:v1.11.2
[root@k8s-master ~]# docker push reg.timinglee.org/ingress-nginx/kube-webhook-certgen:v1.4.3
安装ingress
[root@k8s-master ~]# vim deploy.yaml
445 image: ingress-nginx/controller:v1.11.2
546 image: ingress-nginx/kube-webhook-certgen:v1.4.3
599 image: ingress-nginx/kube-webhook-certgen:v1.4.3[root@k8s-master ~]# kubectl -n ingress-nginx get pods
NAME READY STATUS RESTARTS AGE
ingress-nginx-admission-create-ggqm6 0/1 Completed 0 82s
ingress-nginx-admission-patch-q4wp2 0/1 Completed 0 82s
ingress-nginx-controller-bb7d8f97c-g2h4p 1/1 Running 0 82s
[root@k8s-master ~]# kubectl -n ingress-nginx get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ingress-nginx-controller NodePort 10.103.33.148 <none> 80:34512/TCP,443:34727/TCP 108s
ingress-nginx-controller-admission ClusterIP 10.103.183.64 <none> 443/TCP 108s#修改微服务为loadbalancer
[root@k8s-master ~]# kubectl -n ingress-nginx edit svc ingress-nginx-controller
49 type: LoadBalancer[root@k8s-master ~]# kubectl -n ingress-nginx get services
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ingress-nginx-controller LoadBalancer 10.103.33.148 172.25.254.50 80:34512/TCP,443:34727/TCP 4m43s
ingress-nginx-controller-admission ClusterIP 10.103.183.64 <none> 443/TCP 4m43s
[!NOTE]
在ingress-nginx-controller中看到的对外IP就是ingress最终对外开放的ip
测试
#生成yaml文件
[root@k8s-master ~]# kubectl create ingress webcluster --rule '*/=timinglee-svc:80' --dry-run=client -o yaml > timinglee-ingress.yml[root@k8s-master ~]# vim timinglee-ingress.yml
aapiVersion: networking.k8s.io/v1
kind: Ingress
metadata:name: test-ingress
spec:ingressClassName: nginxrules:- http:paths:- backend:service:name: timinglee-svcport:number: 80path: /pathType: Prefix #Exact(精确匹配),ImplementationSpecific(特定实现),Prefix(前缀匹配),Regular expression(正则表达式匹配)#建立ingress控制器
[root@k8s-master ~]# kubectl apply -f timinglee-ingress.yml
ingress.networking.k8s.io/webserver created[root@k8s-master ~]# kubectl get ingress
NAME CLASS HOSTS ADDRESS PORTS AGE
test-ingress nginx * 172.25.254.10 80 8m30s[root@reg ~]# for n in {1..5}; do curl 172.25.254.50/hostname.html; done
timinglee-c56f584cf-8jhn6
timinglee-c56f584cf-8cwfm
timinglee-c56f584cf-8jhn6
timinglee-c56f584cf-8cwfm
timinglee-c56f584cf-8jhn6
[!NOTE]
ingress必须和输出的service资源处于同一namespace
ingress 的高级用法
基于路径的访问
1.建立用于测试的控制器myapp
[root@k8s-master app]# kubectl create deployment myapp-v1 --image myapp:v1 --dry-run=client -o yaml > myapp-v1.yaml[root@k8s-master app]# kubectl create deployment myapp-v2 --image myapp:v2 --dry-run=client -o yaml > myapp-v2.yaml[root@k8s-master app]# vim myapp-v1.yaml
apiVersion: apps/v1
kind: Deployment
metadata:labels:app: myapp-v1name: myapp-v1
spec:replicas: 1selector:matchLabels:app: myapp-v1strategy: {}template:metadata:labels:app: myapp-v1spec:containers:- image: myapp:v1name: myapp---apiVersion: v1
kind: Service
metadata:labels:app: myapp-v1name: myapp-v1
spec:ports:- port: 80protocol: TCPtargetPort: 80selector:app: myapp-v1[root@k8s-master app]# vim myapp-v2.yaml
apiVersion: apps/v1
kind: Deployment
metadata:labels:app: myapp-v2name: myapp-v2
spec:replicas: 1selector:matchLabels:app: myapp-v2template:metadata:labels:app: myapp-v2spec:containers:- image: myapp:v2name: myapp
---
apiVersion: v1
kind: Service
metadata:labels:app: myapp-v2name: myapp-v2
spec:ports:- port: 80protocol: TCPtargetPort: 80selector:app: myapp-v2[root@k8s-master app]# kubectl expose deployment myapp-v1 --port 80 --target-port 80 --dry-run=client -o yaml >> myapp-v1.yaml[root@k8s-master app]# kubectl expose deployment myapp-v2 --port 80 --target-port 80 --dry-run=client -o yaml >> myapp-v1.yaml[root@k8s-master app]# kubectl get services
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 29h
myapp-v1 ClusterIP 10.104.84.65 <none> 80/TCP 13s
myapp-v2 ClusterIP 10.105.246.219 <none> 80/TCP 7s
2.建立ingress的yaml
[root@k8s-master app]# vim ingress1.yml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:annotations:nginx.ingress.kubernetes.io/rewrite-target: / #访问路径后加任何内容都被定向到/name: ingress1
spec:ingressClassName: nginxrules:- host: www.timinglee.orghttp:paths:- backend:service:name: myapp-v1port:number: 80path: /v1pathType: Prefix- backend:service:name: myapp-v2port:number: 80path: /v2pathType: Prefix#测试:
[root@reg ~]# echo 172.25.254.50 www.timinglee.org >> /etc/hosts[root@reg ~]# curl www.timinglee.org/v1
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>
[root@reg ~]# curl www.timinglee.org/v2
Hello MyApp | Version: v2 | <a href="hostname.html">Pod Name</a>#nginx.ingress.kubernetes.io/rewrite-target: / 的功能实现
[root@reg ~]# curl www.timinglee.org/v2/aaaa
Hello MyApp | Version: v2 | <a href="hostname.html">Pod Name</a>基于域名的访问
#在测试主机中设定解析
[root@reg ~]# vim /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
172.25.254.250 reg.timinglee.org
172.25.254.50 www.timinglee.org myappv1.timinglee.org myappv2.timinglee.org# 建立基于域名的yml文件
[root@k8s-master app]# vim ingress2.yml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:annotations:nginx.ingress.kubernetes.io/rewrite-target: /name: ingress2
spec:ingressClassName: nginxrules:- host: myappv1.timinglee.orghttp:paths:- backend:service:name: myapp-v1port:number: 80path: /pathType: Prefix- host: myappv2.timinglee.orghttp:paths:- backend:service:name: myapp-v2port:number: 80path: /pathType: Prefix#利用文件建立ingress
[root@k8s-master app]# kubectl apply -f ingress2.yml
ingress.networking.k8s.io/ingress2 created[root@k8s-master app]# kubectl describe ingress ingress2
Name: ingress2
Labels: <none>
Namespace: default
Address:
Ingress Class: nginx
Default backend: <default>
Rules:Host Path Backends---- ---- --------myappv1.timinglee.org/ myapp-v1:80 (10.244.2.31:80)myappv2.timinglee.org/ myapp-v2:80 (10.244.2.32:80)
Annotations: nginx.ingress.kubernetes.io/rewrite-target: /
Events:Type Reason Age From Message---- ------ ---- ---- -------Normal Sync 21s nginx-ingress-controller Scheduled for sync#在测试主机中测试
[root@reg ~]# curl www.timinglee.org/v1
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>
[root@reg ~]# curl www.timinglee.org/v2
Hello MyApp | Version: v2 | <a href="hostname.html">Pod Name</a>
建立tls加密
#建立证书
[root@k8s-master app]# openssl req -newkey rsa:2048 -nodes -keyout tls.key -x509 -days 365 -subj "/CN=nginxsvc/O=nginxsvc" -out tls.crt
#建立加密资源类型secret
[root@k8s-master app]# kubectl create secret tls web-tls-secret --key tls.key --cert tls.crt
secret/web-tls-secret created
[root@k8s-master app]# kubectl get secrets
NAME TYPE DATA AGE
web-tls-secret kubernetes.io/tls 2 6s
[!NOTE]
secret通常在kubernetes中存放敏感数据,他并不是一种加密方式,在后面课程中会有专门讲解
#建立ingress3基于tls认证的yml文件
[root@k8s-master app]# vim ingress3.yml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:annotations:nginx.ingress.kubernetes.io/rewrite-target: /name: ingress3
spec:tls:- hosts:- myapp-tls.timinglee.orgsecretName: web-tls-secretingressClassName: nginxrules:- host: myapp-tls.timinglee.orghttp:paths:- backend:service:name: myapp-v1port:number: 80path: /pathType: Prefix#测试
[root@reg ~]# curl -k https://myapp-tls.timinglee.org
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>
建立auth认证
#建立认证文件
[root@k8s-master app]# dnf install httpd-tools -y
[root@k8s-master app]# htpasswd -cm auth lee
New password:
Re-type new password:
Adding password for user lee
[root@k8s-master app]# cat auth
lee:$apr1$BohBRkkI$hZzRDfpdtNzue98bFgcU10#建立认证类型资源
[root@k8s-master app]# kubectl create secret generic auth-web --from-file auth
root@k8s-master app]# kubectl describe secrets auth-web
Name: auth-web
Namespace: default
Labels: <none>
Annotations: <none>Type: OpaqueData
====
auth: 42 bytes
#建立ingress4基于用户认证的yaml文件
[root@k8s-master app]# vim ingress4.yml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:annotations:nginx.ingress.kubernetes.io/auth-type: basicnginx.ingress.kubernetes.io/auth-secret: auth-webnginx.ingress.kubernetes.io/auth-realm: "Please input username and password"name: ingress4
spec:tls:- hosts:- myapp-tls.timinglee.orgsecretName: web-tls-secretingressClassName: nginxrules:- host: myapp-tls.timinglee.orghttp:paths:- backend:service:name: myapp-v1port:number: 80path: /pathType: Prefix#建立ingress4
[root@k8s-master app]# kubectl apply -f ingress4.yml
ingress.networking.k8s.io/ingress4 created
[root@k8s-master app]# kubectl describe ingress ingress4
Name: ingress4
Labels: <none>
Namespace: default
Address:
Ingress Class: nginx
Default backend: <default>
TLS:web-tls-secret terminates myapp-tls.timinglee.org
Rules:Host Path Backends---- ---- --------myapp-tls.timinglee.org/ myapp-v1:80 (10.244.2.31:80)
Annotations: nginx.ingress.kubernetes.io/auth-realm: Please input username and passwordnginx.ingress.kubernetes.io/auth-secret: auth-webnginx.ingress.kubernetes.io/auth-type: basic
Events:Type Reason Age From Message---- ------ ---- ---- -------Normal Sync 14s nginx-ingress-controller Scheduled for sync#测试:
[root@reg ~]# curl -k https://myapp-tls.timinglee.org
<html>
<head><title>401 Authorization Required</title></head>
<body>
<center><h1>401 Authorization Required</h1></center>
<hr><center>nginx</center>
</body>
</html>[root@reg ~]# curl -k https://myapp-tls.timinglee.org -ulee:lee
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>
rewrite重定向
#指定默认访问的文件到hostname.html上
[root@k8s-master app]# vim ingress5.yml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:annotations:nginx.ingress.kubernetes.io/app-root: /hostname.htmlnginx.ingress.kubernetes.io/auth-type: basicnginx.ingress.kubernetes.io/auth-secret: auth-webnginx.ingress.kubernetes.io/auth-realm: "Please input username and password"name: ingress5
spec:tls:- hosts:- myapp-tls.timinglee.orgsecretName: web-tls-secretingressClassName: nginxrules:- host: myapp-tls.timinglee.orghttp:paths:- backend:service:name: myapp-v1port:number: 80path: /pathType: Prefix
[root@k8s-master app]# kubectl apply -f ingress5.yml
ingress.networking.k8s.io/ingress5 created
[root@k8s-master app]# kubectl describe ingress ingress5
Name: ingress5
Labels: <none>
Namespace: default
Address: 172.25.254.10
Ingress Class: nginx
Default backend: <default>
TLS:web-tls-secret terminates myapp-tls.timinglee.org
Rules:Host Path Backends---- ---- --------myapp-tls.timinglee.org/ myapp-v1:80 (10.244.2.31:80)
Annotations: nginx.ingress.kubernetes.io/app-root: /hostname.htmlnginx.ingress.kubernetes.io/auth-realm: Please input username and passwordnginx.ingress.kubernetes.io/auth-secret: auth-webnginx.ingress.kubernetes.io/auth-type: basic
Events:Type Reason Age From Message---- ------ ---- ---- -------Normal Sync 2m16s (x2 over 2m54s) nginx-ingress-controller Scheduled for sync#测试:
[root@reg ~]# curl -Lk https://myapp-tls.timinglee.org -ulee:lee
myapp-v1-7479d6c54d-j9xc6[root@reg ~]# curl -Lk https://myapp-tls.timinglee.org/lee/hostname.html -ulee:lee
<html>
<head><title>404 Not Found</title></head>
<body bgcolor="white">
<center><h1>404 Not Found</h1></center>
<hr><center>nginx/1.12.2</center>
</body>
</html>#解决重定向路径问题
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:annotations:nginx.ingress.kubernetes.io/rewrite-target: /$2nginx.ingress.kubernetes.io/use-regex: "true"nginx.ingress.kubernetes.io/auth-type: basicnginx.ingress.kubernetes.io/auth-secret: auth-webnginx.ingress.kubernetes.io/auth-realm: "Please input username and password"name: ingress6
spec:tls:- hosts:- myapp-tls.timinglee.orgsecretName: web-tls-secretingressClassName: nginxrules:- host: myapp-tls.timinglee.orghttp:paths:- backend:service:name: myapp-v1port:number: 80path: /pathType: Prefix- backend:service:name: myapp-v1port:number: 80path: /lee(/|$)(.*) #正则表达式匹配/lee/,/lee/abcpathType: ImplementationSpecific#测试
[root@reg ~]# curl -Lk https://myapp-tls.timinglee.org/lee/hostname.html -ulee:lee
myapp-v1-7479d6c54d-j9xc6
Canary金丝雀发布(灰度发布)
金丝雀发布(Canary Release)也称为灰度发布,是一种软件发布策略。
主要目的是在将新版本的软件全面推广到生产环境之前,先在一小部分用户或服务器上进行测试和验证,以降低因新版本引入重大问题而对整个系统造成的影响。
是一种Pod的发布方式。金丝雀发布采取先添加、再删除的方式,保证Pod的总量不低于期望值。并且在更新部分Pod后,暂停更新,当确认新Pod版本运行正常后再进行其他版本的Pod的更新。
发布方式
header、cookie、weigth 其中header和weiht中的最多
基于header(http包头)灰度
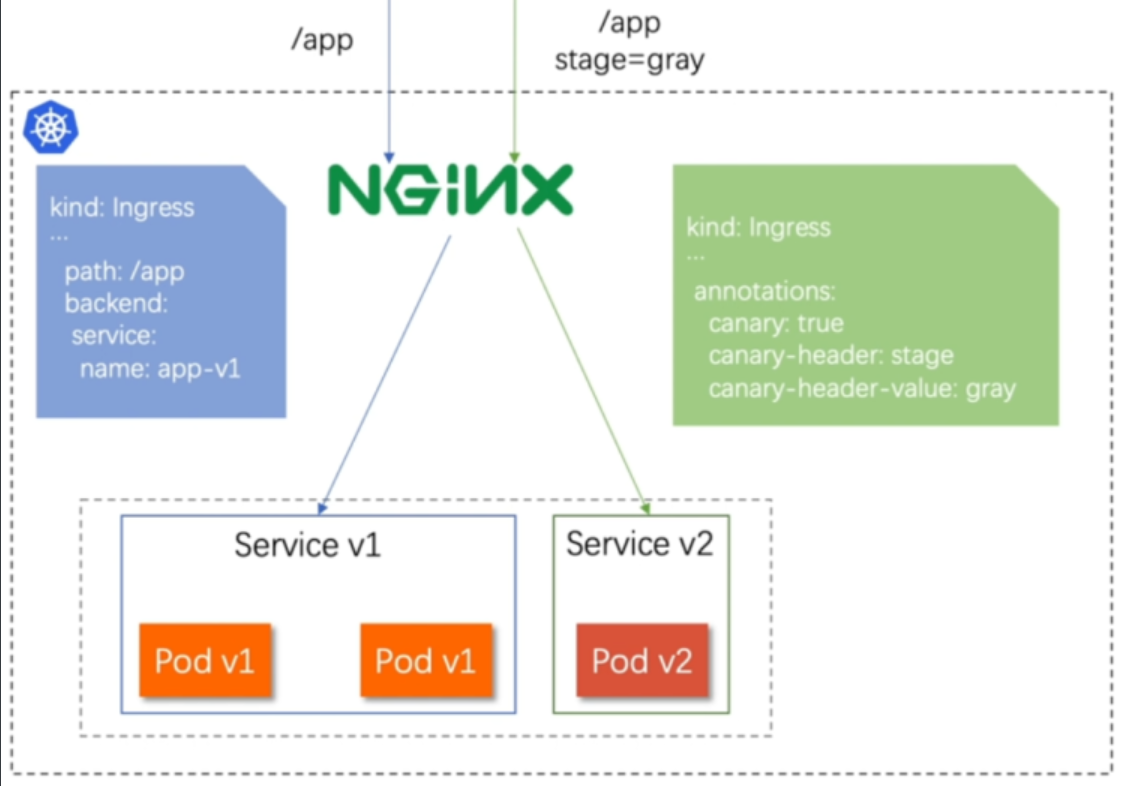
- 通过Annotaion扩展
- 创建灰度ingress,配置灰度头部key以及value
- 灰度流量验证完毕后,切换正式ingress到新版本
- 之前我们在做升级时可以通过控制器做滚动更新,默认25%利用header可以使升级更为平滑,通过key 和vule 测试新的业务体系是否有问题。
#建立版本1的ingress
[root@k8s-master app]# vim ingress7.yml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:annotations:name: myapp-v1-ingress
spec:ingressClassName: nginxrules:- host: myapp.dl.orghttp:paths:- backend:service:name: myapp-v1port:number: 80path: /pathType: Prefix[root@k8s-master app]# kubectl describe ingress myapp-v1-ingress
Name: myapp-v1-ingress
Labels: <none>
Namespace: default
Address: 192.168.60.100
Ingress Class: nginx
Default backend: <default>
Rules:Host Path Backends---- ---- --------myapp.dl.org/ myapp-v1:80 (10.244.2.31:80)
Annotations: <none>
Events:Type Reason Age From Message---- ------ ---- ---- -------Normal Sync 44s (x2 over 73s) nginx-ingress-controller Scheduled for sync#建立基于header的ingress
[root@k8s-master app]# vim ingress8.yml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:annotations:nginx.ingress.kubernetes.io/canary: "true"nginx.ingress.kubernetes.io/canary-by-header: “version”nginx.ingress.kubernetes.io/canary-by-header-value: ”2“name: myapp-v2-ingress
spec:ingressClassName: nginxrules:- host: myapp.dl.orghttp:paths:- backend:service:name: myapp-v2port:number: 80path: /pathType: Prefix
[root@k8s-master app]# kubectl apply -f ingress8.yml
ingress.networking.k8s.io/myapp-v2-ingress created
[root@k8s-master app]# kubectl describe ingress myapp-v2-ingress
Name: myapp-v2-ingress
Labels: <none>
Namespace: default
Address:
Ingress Class: nginx
Default backend: <default>
Rules:Host Path Backends---- ---- --------myapp.timinglee.org/ myapp-v2:80 (10.244.2.32:80)
Annotations: nginx.ingress.kubernetes.io/canary: truenginx.ingress.kubernetes.io/canary-by-header: versionnginx.ingress.kubernetes.io/canary-by-header-value: 2
Events:Type Reason Age From Message---- ------ ---- ---- -------Normal Sync 21s nginx-ingress-controller Scheduled for sync#测试:
[root@reg ~]# curl myapp.dl.org
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>
[root@reg ~]# curl -H "version: 2" myapp.dl.org
Hello MyApp | Version: v2 | <a href="hostname.html">Pod Name</a>
基于权重的灰度发布
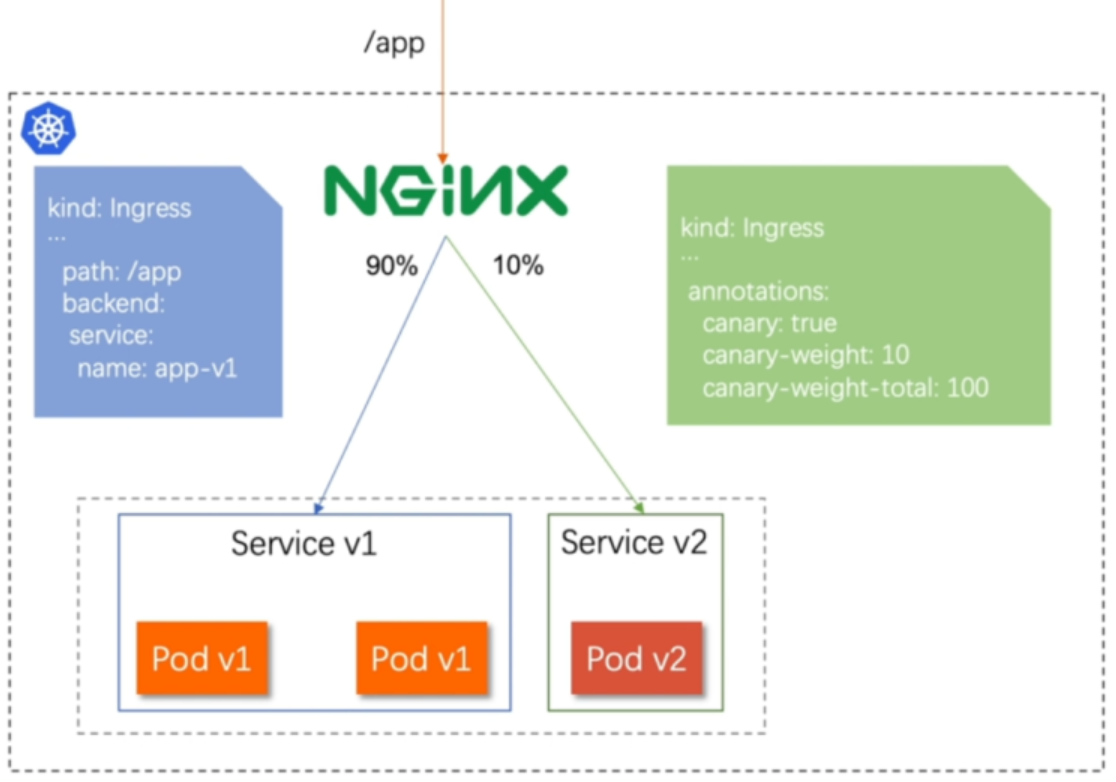
- 通过Annotaion拓展
- 创建灰度ingress,配置灰度权重以及总权重
- 灰度流量验证完毕后,切换正式ingress到新版本
示例
#基于权重的灰度发布
[root@k8s-master app]# vim ingress8.yml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:annotations:nginx.ingress.kubernetes.io/canary: "true"nginx.ingress.kubernetes.io/canary-weight: "10" #更改权重值nginx.ingress.kubernetes.io/canary-weight-total: "100"name: myapp-v2-ingress
spec:ingressClassName: nginxrules:- host: myapp.dl.orghttp:paths:- backend:service:name: myapp-v2port:number: 80path: /pathType: Prefix[root@k8s-master app]# kubectl apply -f ingress8.yml
ingress.networking.k8s.io/myapp-v2-ingress created#测试:
[root@reg ~]# vim check_ingress.sh
#!/bin/bash
v1=0
v2=0for (( i=0; i<100; i++))
doresponse=`curl -s myapp.dl.org |grep -c v1`v1=`expr $v1 + $response`v2=`expr $v2 + 1 - $response`done
echo "v1:$v1, v2:$v2"[root@reg ~]# sh check_ingress.sh
v1:90, v2:10#更改完毕权重后继续测试可观察变化
K8S存储
configmap
作用
通过解耦镜像与配置文件,实现镜像的可移植性与可复用性
传统方式中,配置硬编码在镜像中,修改配置往常需要重新构建镜像,耦合度较高,通过configmap存储配置,启动容器时挂载。配置变更时则不需要反复构建镜像。
- 数据类型:键值对
- 资源等级:命名空间级,只能在同一个命名空间中使用,跨命名空间需通过其他方式(挂载卷共享等…)
- 大小限制:单条data值不超过1M,超出会直接建立失败。一个configmap大小建议不超过10M(非硬性限制,实践10M以下最佳)
场景
- 填充环境变量值
- 设置容器命令行参数
- 填充卷的配置
创建
1.字面值创建
[root@master ~]# kubectl create cm configmap-1 --from-literal key1=value1 --from-literal key2=value2
configmap/configmap-1 created
[root@master ~]# kubectl describe cm configmap-1
Name: configmap-1
Namespace: default
Labels: <none>
Annotations: <none>Data
====
key1:
----
value1
key2:
----
value2BinaryData
====Events: <none>2.通过文件建立
将单个文件的内容作为cm的一个键值对(键为文件名,值为文件内容)。
#配置文件
[root@master cm]# cat nginx.conf
server {listen 80;server_name _;root /usr/share/nginx/html;index index.html;
}#创建
[root@master cm]# kubectl create cm cm-nginx --from-file nginx.conf
configmap/cm-nginx created
[root@master cm]# kubectl describe cm cm-nginx
Name: cm-nginx
Namespace: default
Labels: <none>
Annotations: <none>Data
====
nginx.conf:
----
server {listen 80;server_name _;root /usr/share/nginx/html;index index.html;
}BinaryData
====Events: <none>
3.通过目录创建
会将目录中的所有文件转化为cm的键值对
mkdir cmdirecho 111 > cmdir/file1
echo 222 > cmdir/file2#创建
[root@master cm]# kubectl create cm cm-dir --from-file cmdir/
configmap/cm-dir created
[root@master cm]# kubectl describe cm cm-dir
Name: cm-dir
Namespace: default
Labels: <none>
Annotations: <none>Data
====
file1:
----
111file2:
----
222BinaryData
====Events: <none>4.通过yaml文件创建
#快速生成模板
kubectl create cm cm-4 --from-literal username=user --dry-run=client -o yaml > cm.yml
#编辑模板
[root@master cm]# cat cm.yml
apiVersion: v1
data:nginx.conf: | `|`用于定义 ConfigMap、Secret 中的多行配置文件server {listen 80;server_name _;root /usr/share/nginx/html;index index.html;}hosts: |12345
kind: ConfigMap
metadata:creationTimestamp: nullname: cm-4#应用
[root@master cm]# kubectl apply -f cm.yml
configmap/cm-4 created[root@master cm]# kubectl describe cm cm-4
Name: cm-4
Namespace: default
Labels: <none>
Annotations: <none>Data
====
hosts:
----
1
2
3
4
5nginx.conf:
----
server {listen 80;server_name _;root /usr/share/nginx/html;index index.html;
}BinaryData
====Events: <none>应用
1.填充变量
#映射为指定变量
#创建cm
[root@master cm]# kubectl create cm test-1 --from-literal test1=a --from-literal test2=b
configmap/test-1 created#创建pod
[root@master cm]# cat testpod.yml
apiVersion: v1
kind: Pod
metadata:labels:run: testpodname: testpod
spec:restartPolicy: Nevercontainers:- image: busyboxplus:latestname: testpodcommand:- /bin/sh- -c- env #显示系统变量env:- name: key1valueFrom:configMapKeyRef:name: test-1 # 引用的 ConfigMap 名称 key: test1 # 引用 ConfigMap 中的 key(test1)- name: key2valueFrom:configMapKeyRef:name: test-1key: test2[root@master cm]# kubectl apply -f testpod.yml
pod/testpod created
[root@master cm]# kubectl logs testpod
...
key1=a
key2=b#将cm中的值全部映射为变量
cat testpod.yml
apiVersion: v1
kind: Pod
metadata:labels:run: testpodname: testpod
spec:restartPolicy: Nevercontainers:- image: busyboxplus:latestname: testpodcommand:- /bin/sh- -c- envenvFrom: - configMapRef:name: test-1[root@master cm]# kubectl logs testpod
...
test1=a
test2=b#命令行中使用
[root@master cm]# kubectl logs testpod
a b
[root@master cm]# cat testpod.yml
apiVersion: v1
kind: Pod
metadata:labels:run: testpodname: testpod
spec:restartPolicy: Nevercontainers:- image: busyboxplus:latestname: testpodcommand:- /bin/sh- -c- echo ${test1} ${test2} envFrom: - configMapRef:name: test-1[root@master cm]# kubectl apply -f testpod.yml
pod/testpod created
[root@master cm]# kubectl logs testpod
a b
2.数据卷挂载
#创建cm
[root@master cm]# kubectl create cm test-2 --from-file nginx.conf
configmap/test-2 created[root@master cm]# cat testpod.yml
apiVersion: v1
kind: Pod
metadata:labels:run: testpodname: testpod
spec:restartPolicy: Nevercontainers:- image: busyboxplus:latestname: testpodcommand:- /bin/sh- -c- cat /mnt/nginx.confvolumeMounts: #调用策略- name: nginx-conf #卷名称 名称中不可包含 .mountPath: /mntvolumes: #声明卷位置- name: nginx-conf #卷名称 卷名称上下保持一致configMap: name: test-2
[root@master cm]# kubectl apply -f testpod.yml
pod/testpod created#效果
[root@master cm]# kubectl logs testpod
server {listen 80;server_name _;root /usr/share/nginx/html;index index.html;
}3.填充配置文件
kubectl create cm test-2 --from-file nginx.conf
[root@master cm]# kubectl describe cm test-2
Name: test-2
Namespace: default
Labels: <none>
Annotations: <none>Data
====
nginx.conf:
----
server {listen 8080;server_name _;root /usr/share/nginx/html;index index.html;
}
BinaryData
====
Events: <none>#生成控制器模板
kubectl create deployment test-nginx --image nginx:latest --dry-run=client -o yaml > nginx.yml[root@master cm]# cat nginx.yml
apiVersion: apps/v1
kind: Deployment
metadata:labels:app: test-nginxname: test-nginx
spec:replicas: 1selector:matchLabels:app: test-nginxtemplate:metadata:labels:app: test-nginxspec:containers:- image: nginx:latestname: nginxvolumeMounts:- name: nginx-confmountPath: /etc/nginx/conf.dvolumes:- name: nginx-confconfigMap:name: test-2[root@master cm]# kubectl apply -f nginx.yml
deployment.apps/test-nginx created
[root@master cm]# kubectl get pods test-nginx-5bb48dd447-rmchj -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
test-nginx-5bb48dd447-rmchj 1/1 Running 0 11m 10.244.1.22 k8s-1 <none> <none>
[root@master cm]# curl 10.244.1.22:8080
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
...4.热更新
[root@master cm]# kubectl edit cm test-2
configmap/test-2 edited# Please edit the object below. Lines beginning with a '#' will be ignored,
# and an empty file will abort the edit. If an error occurs while saving this file will be
# reopened with the relevant failures.
#
apiVersion: v1
data:nginx.conf: |server {listen 8888; #修改端口为8888server_name _;root /usr/share/nginx/html;index index.html;}
kind: ConfigMap
metadata:creationTimestamp: "2025-08-16T13:43:16Z"name: test-2namespace: defaultresourceVersion: "244314"uid: 12d4a994-8f0a-43e6-a085-6f1d3df97c4d#查看nginx配置文件
[root@master cm]# kubectl exec pods/test-nginx-54fd88ff84-vmtcv -- cat /etc/nginx/conf.d/nginx.conf
server {listen 8888;server_name _;root /usr/share/nginx/html;index index.html;
}#重载配置
[root@master cm]# kubectl exec pods/test-nginx-54fd88ff84-vmtcv -- nginx -s reload
2025/08/16 14:31:55 [notice] 36#36: signal process started[root@master cm]# curl 10.244.2.18:8888
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
...secrets配置管理
-
Secret 对象类型用来保存敏感信息,例如密码、OAuth 令牌和 ssh key。
-
敏感信息放在 secret 中比放在 Pod 的定义或者容器镜像中来说更加安全和灵活
-
Pod 可以用两种方式使用 secret:
-
作为 volume 中的文件被挂载到 pod 中的一个或者多个容器里。
-
当 kubelet 为 pod 拉取镜像时使用。
-
-
Secret的类型:
-
Service Account:Kubernetes 自动创建包含访问 API 凭据的 secret,并自动修改 pod 以使用此类型的 secret。
-
Opaque:使用base64编码存储信息,可以通过base64 --decode解码获得原始数据,因此安全性弱。
-
kubernetes.io/dockerconfigjson:用于存储docker registry的认证信息
-
secrets的创建
在创建secrets时我们可以用命令的方法或者yaml文件的方法
从文件创建
[root@k8s-master secrets]# echo -n timinglee > username.txt
[root@k8s-master secrets]# echo -n lee > password.txt
root@k8s-master secrets]# kubectl create secret generic userlist --from-file username.txt --from-file password.txt
secret/userlist created
[root@k8s-master secrets]# kubectl get secrets userlist -o yaml
apiVersion: v1
data:password.txt: bGVlusername.txt: dGltaW5nbGVl
kind: Secret
metadata:creationTimestamp: "2024-09-07T07:30:42Z"name: userlistnamespace: defaultresourceVersion: "177216"uid: 9d76250c-c16b-4520-b6f2-cc6a8ad25594
type: Opaque编写yaml文件
[root@k8s-master secrets]# echo -n timinglee | base64
dGltaW5nbGVl
[root@k8s-master secrets]# echo -n lee | base64
bGVl[root@k8s-master secrets]# kubectl create secret generic userlist --dry-run=client -o yaml > userlist.yml[root@k8s-master secrets]# vim userlist.yml
apiVersion: v1
kind: Secret
metadata:creationTimestamp: nullname: userlist
type: Opaque
data:username: dGltaW5nbGVlpassword: bGVl[root@k8s-master secrets]# kubectl apply -f userlist.yml
secret/userlist created[root@k8s-master secrets]# kubectl describe secrets userlist
Name: userlist
Namespace: default
Labels: <none>
Annotations: <none>Type: OpaqueData
====
password: 3 bytes
username: 9 byte
Secret的使用方法
将Secret挂载到Volume中
[root@k8s-master secrets]# kubectl run nginx --image nginx --dry-run=client -o yaml > pod1.yaml#向固定路径映射
[root@k8s-master secrets]# vim pod1.yaml
apiVersion: v1
kind: Pod
metadata:labels:run: nginxname: nginx
spec:containers:- image: nginxname: nginxvolumeMounts:- name: secretsmountPath: /secretreadOnly: truevolumes:- name: secretssecret:secretName: userlist[root@k8s-master secrets]# kubectl apply -f pod1.yaml
pod/nginx created[root@k8s-master secrets]# kubectl exec pods/nginx -it -- /bin/bash
root@nginx:/# cat /secret/
cat: /secret/: Is a directory
root@nginx:/# cd /secret/
root@nginx:/secret# ls
password username
root@nginx:/secret# cat password
leeroot@nginx:/secret# cat username
timingleeroot@nginx:/secret#
向指定路径映射 secret 密钥
#向指定路径映射
[root@k8s-master secrets]# vim pod2.yaml
apiVersion: v1
kind: Pod
metadata:labels:run: nginx1name: nginx1
spec:containers:- image: nginxname: nginx1volumeMounts:- name: secretsmountPath: /secretreadOnly: truevolumes:- name: secretssecret:secretName: userlistitems:- key: usernamepath: my-users/username[root@k8s-master secrets]# kubectl apply -f pod2.yaml
pod/nginx1 created
[root@k8s-master secrets]# kubectl exec pods/nginx1 -it -- /bin/bash
root@nginx1:/# cd secret/
root@nginx1:/secret# ls
my-users
root@nginx1:/secret# cd my-users
root@nginx1:/secret/my-users# ls
username
root@nginx1:/secret/my-users# cat username
将Secret设置为环境变量
[root@k8s-master secrets]# vim pod3.yaml
apiVersion: v1
kind: Pod
metadata:labels:run: busyboxname: busybox
spec:containers:- image: busyboxname: busyboxcommand:- /bin/sh- -c- envenv:- name: USERNAMEvalueFrom:secretKeyRef:name: userlistkey: username- name: PASSvalueFrom:secretKeyRef:name: userlistkey: passwordrestartPolicy: Never[root@k8s-master secrets]# kubectl apply -f pod3.yaml
pod/busybox created
[root@k8s-master secrets]# kubectl logs pods/busybox
KUBERNETES_SERVICE_PORT=443
KUBERNETES_PORT=tcp://10.96.0.1:443
HOSTNAME=busybox
MYAPP_V1_SERVICE_HOST=10.104.84.65
MYAPP_V2_SERVICE_HOST=10.105.246.219
SHLVL=1
HOME=/root
MYAPP_V1_SERVICE_PORT=80
MYAPP_V1_PORT=tcp://10.104.84.65:80
MYAPP_V2_SERVICE_PORT=80
MYAPP_V2_PORT=tcp://10.105.246.219:80
MYAPP_V1_PORT_80_TCP_ADDR=10.104.84.65
USERNAME=timinglee
MYAPP_V2_PORT_80_TCP_ADDR=10.105.246.219
KUBERNETES_PORT_443_TCP_ADDR=10.96.0.1
MYAPP_V1_PORT_80_TCP_PORT=80
PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
MYAPP_V2_PORT_80_TCP_PORT=80
MYAPP_V1_PORT_80_TCP_PROTO=tcp
KUBERNETES_PORT_443_TCP_PORT=443
MYAPP_V2_PORT_80_TCP_PROTO=tcp
KUBERNETES_PORT_443_TCP_PROTO=tcp
MYAPP_V1_PORT_80_TCP=tcp://10.104.84.65:80
MYAPP_V2_PORT_80_TCP=tcp://10.105.246.219:80
PASS=lee
KUBERNETES_PORT_443_TCP=tcp://10.96.0.1:443
KUBERNETES_SERVICE_PORT_HTTPS=443
KUBERNETES_SERVICE_HOST=10.96.0.1
PWD=/
存储docker registry的认证信息
建立私有仓库并上传镜像
#登陆仓库
[root@k8s-master secrets]# docker login reg.dl.org
Authenticating with existing credentials...
WARNING! Your password will be stored unencrypted in /root/.docker/config.json.
Configure a credential helper to remove this warning. See
https://docs.docker.com/engine/reference/commandline/login/#credential-storesLogin Succeeded#上传镜像
[root@k8s-master secrets]# docker tag timinglee/game2048:latest reg.dl.org/library/game2048:latest
[root@k8s-master secrets]# docker push reg.dl.org/library/game2048:latest
The push refers to repository [reg.dl.org/library/game2048]
88fca8ae768a: Pushed
6d7504772167: Pushed
192e9fad2abc: Pushed
36e9226e74f8: Pushed
011b303988d2: Pushed
latest: digest: sha256:8a34fb9cb168c420604b6e5d32ca6d412cb0d533a826b313b190535c03fe9390 size: 1364
#建立用于docker认证的secret[root@k8s-master secrets]# kubectl create secret docker-registry docker-auth --docker-server reg.timinglee.org --docker-username admin --docker-password lee --docker-email timinglee@timinglee.org
secret/docker-auth created
[root@k8s-master secrets]# vim pod3.yml
apiVersion: v1
kind: Pod
metadata:labels:run: game2048name: game2048
spec:containers:- image: reg.timinglee.org/timinglee/game2048:latestname: game2048imagePullSecrets: #不设定docker认证时无法下载镜像- name: docker-auth[root@k8s-master secrets]# kubectl get pods
NAME READY STATUS RESTARTS AGE
game2048 1/1 Running 0 4svolumes配置管理
emptyDir卷
当Pod指定到某个节点上时,首先创建的是一个emptyDir卷,并且只要 Pod 在该节点上运行,卷就一直存在。卷最初是空的。 尽管 Pod 中的容器挂载 emptyDir 卷的路径可能相同也可能不同,但是这些容器都可以读写 emptyDir 卷中相同的文件。 当 Pod 因为某些原因被从节点上删除时,emptyDir 卷中的数据也会永久删除
emptyDir 的使用场景:
-
缓存空间,例如基于磁盘的归并排序。
-
耗时较长的计算任务提供检查点,以便任务能方便地从崩溃前状态恢复执行。
-
在 Web 服务器容器服务数据时,保存内容管理器容器获取的文件。
示例:
[root@k8s-master volumes]# vim pod1.yml
apiVersion: v1
kind: Pod
metadata:name: vol1
spec:containers:- image: busyboxplus:latestname: vm1command:- /bin/sh- -c- sleep 30000000volumeMounts:- mountPath: /cachename: cache-vol- image: nginx:latestname: vm2volumeMounts:- mountPath: /usr/share/nginx/htmlname: cache-volvolumes:- name: cache-volemptyDir:medium: MemorysizeLimit: 100Mi[root@k8s-master volumes]# kubectl apply -f pod1.yml#查看pod中卷的使用情况
[root@k8s-master volumes]# kubectl describe pods vol1#测试效果[root@k8s-master volumes]# kubectl exec -it pods/vol1 -c vm1 -- /bin/sh
/ # cd /cache/
/cache # ls
/cache # curl localhost
<html>
<head><title>403 Forbidden</title></head>
<body>
<center><h1>403 Forbidden</h1></center>
<hr><center>nginx/1.27.1</center>
</body>
</html>
/cache # echo timinglee > index.html
/cache # curl localhost
timinglee
/cache # dd if=/dev/zero of=bigfile bs=1M count=101
dd: writing 'bigfile': No space left on device
101+0 records in
99+1 records outhostpath卷
功能:
hostPath 卷能将主机节点文件系统上的文件或目录挂载到您的 Pod 中,不会因为pod关闭而被删除
hostPath 的一些用法
-
运行一个需要访问 Docker 引擎内部机制的容器,挂载 /var/lib/docker 路径。
-
在容器中运行 cAdvisor(监控) 时,以 hostPath 方式挂载 /sys。
-
允许 Pod 指定给定的 hostPath 在运行 Pod 之前是否应该存在,是否应该创建以及应该以什么方式存在
hostPath的安全隐患
- 具有相同配置(例如从 podTemplate 创建)的多个 Pod 会由于节点上文件的不同而在不同节点上有不同的行为。
- 当 Kubernetes 按照计划添加资源感知的调度时,这类调度机制将无法考虑由 hostPath 使用的资源。
- 基础主机上创建的文件或目录只能由 root 用户写入。您需要在 特权容器 中以 root 身份运行进程,或者修改主机上的文件权限以便容器能够写入 hostPath 卷。
示例:
[root@k8s-master volumes]# vim pod2.yml
apiVersion: v1
kind: Pod
metadata:name: vol1
spec:containers:- image: nginx:latestname: vm1volumeMounts:- mountPath: /usr/share/nginx/htmlname: cache-volvolumes:- name: cache-volhostPath:path: /datatype: DirectoryOrCreate #当/data目录不存在时自动建立#测试:
[root@k8s-master volumes]# kubectl apply -f pod2.yml
pod/vol1 created
[root@k8s-master volumes]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
vol1 1/1 Running 0 10s 10.244.2.48 k8s-node2 <none> <none>[root@k8s-master volumes]# curl 10.244.2.48
<html>
<head><title>403 Forbidden</title></head>
<body>
<center><h1>403 Forbidden</h1></center>
<hr><center>nginx/1.27.1</center>
</body>
</html>[root@k8s-node2 ~]# echo timinglee > /data/index.html
[root@k8s-master volumes]# curl 10.244.2.48
timinglee#当pod被删除后hostPath不会被清理
[root@k8s-master volumes]# kubectl delete -f pod2.yml
pod "vol1" deleted
[root@k8s-node2 ~]# ls /data/
index.html
nfs卷
NFS 卷允许将一个现有的 NFS 服务器上的目录挂载到 Kubernetes 中的 Pod 中。这对于在多个 Pod 之间共享数据或持久化存储数据非常有用
例如,如果有多个容器需要访问相同的数据集,或者需要将容器中的数据持久保存到外部存储,NFS 卷可以提供一种方便的解决方案。
部署一台nfs共享主机并在所有k8s节点中安装nfs-utils
#部署nfs主机
[root@reg ~]# dnf install nfs-utils -y
[root@reg ~]# systemctl enable --now nfs-server.service[root@reg ~]# vim /etc/exports
/nfsdata *(rw,sync,no_root_squash)[root@reg ~]# exportfs -rv
exporting *:/nfsdata[root@reg ~]# showmount -e
Export list for reg.timinglee.org:
/nfsdata *#在k8s所有节点中安装nfs-utils
[root@k8s-master & node1 & node2 ~]# dnf install nfs-utils -y
部署nfs卷
[root@k8s-master volumes]# vim pod3.yml
apiVersion: v1
kind: Pod
metadata:name: vol1
spec:containers:- image: nginx:latestname: vm1volumeMounts:- mountPath: /usr/share/nginx/htmlname: cache-volvolumes:- name: cache-volnfs:server: 172.25.254.250path: /nfsdata[root@k8s-master volumes]# kubectl apply -f pod3.yml
pod/vol1 created#测试
[root@k8s-master volumes]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
vol1 1/1 Running 0 100s 10.244.2.50 k8s-node2 <none> <none>
[root@k8s-master volumes]# curl 10.244.2.50
<html>
<head><title>403 Forbidden</title></head>
<body>
<center><h1>403 Forbidden</h1></center>
<hr><center>nginx/1.27.1</center>
</body>
</html>##在nfs主机中
[root@reg ~]# echo timinglee > /nfsdata/index.html
[root@k8s-master volumes]# curl 10.244.2.50
timinglee
PersistentVolume持久卷
PersistentVolume(持久卷,简称PV)
-
pv是集群内由管理员提供的网络存储的一部分。
-
PV也是集群中的一种资源。是一种volume插件,
-
但是它的生命周期却是和使用它的Pod相互独立的。
-
PV这个API对象,捕获了诸如NFS、ISCSI、或其他云存储系统的实现细节
-
pv有两种提供方式:静态和动态
-
静态PV:集群管理员创建多个PV,它们携带着真实存储的详细信息,它们存在于Kubernetes API中,并可用于存储使用
-
动态PV:当管理员创建的静态PV都不匹配用户的PVC时,集群可能会尝试专门地供给volume给PVC。这种供给基于StorageClass
-
PersistentVolumeClaim(持久卷声明,简称PVC)
-
是用户的一种存储请求
-
它和Pod类似,Pod消耗Node资源,而PVC消耗PV资源
-
Pod能够请求特定的资源(如CPU和内存)。PVC能够请求指定的大小和访问的模式持久卷配置
-
PVC与PV的绑定是一对一的映射。没找到匹配的PV,那么PVC会无限期得处于unbound未绑定状态
volumes访问模式
-
ReadWriteOnce – 该volume只能被单个节点以读写的方式映射
-
ReadOnlyMany – 该volume可以被多个节点以只读方式映射
-
ReadWriteMany – 该volume可以被多个节点以读写的方式映射
-
在命令行中,访问模式可以简写为:
-
RWO - ReadWriteOnce
-
ROX - ReadOnlyMany
-
RWX – ReadWriteMany
-
-
volumes回收策略
-
Retain:保留,需要手动回收
-
Recycle:回收,自动删除卷中数据(在当前版本中已经废弃)
-
Delete:删除,相关联的存储资产,如AWS EBS,GCE PD,Azure Disk,or OpenStack Cinder卷都会被删除
注意:
只有NFS和HostPath支持回收利用
AWS EBS,GCE PD,Azure Disk,or OpenStack Cinder卷支持删除操作。
volumes状态说明
-
Available 卷是一个空闲资源,尚未绑定到任何申领
-
Bound 该卷已经绑定到某申领
-
Released 所绑定的申领已被删除,但是关联存储资源尚未被集群回收
-
Failed 卷的自动回收操作失败
静态pv实例:
#在nfs主机中建立实验目录
[root@reg ~]# mkdir /nfsdata/pv{1..3}#编写创建pv的yml文件,pv是集群资源,不在任何namespace中
[root@k8s-master pvc]# vim pv.yml
apiVersion: v1
kind: PersistentVolume
metadata:name: pv1
spec:capacity:storage: 5GivolumeMode: FilesystemaccessModes:- ReadWriteOncepersistentVolumeReclaimPolicy: RetainstorageClassName: nfsnfs:path: /nfsdata/pv1server: 172.25.254.250---
apiVersion: v1
kind: PersistentVolume
metadata:name: pv2
spec:capacity:storage: 15GivolumeMode: FilesystemaccessModes:- ReadWriteManypersistentVolumeReclaimPolicy: RetainstorageClassName: nfsnfs:path: /nfsdata/pv2server: 172.25.254.250
---
apiVersion: v1
kind: PersistentVolume
metadata:name: pv3
spec:capacity:storage: 25GivolumeMode: FilesystemaccessModes:- ReadOnlyManypersistentVolumeReclaimPolicy: RetainstorageClassName: nfsnfs:path: /nfsdata/pv3server: 172.25.254.250[root@k8s-master pvc]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS VOLUMEATTRIBUTESCLASS REASON AGE
pv1 5Gi RWO Retain Available nfs <unset> 4m50s
pv2 15Gi RWX Retain Available nfs <unset> 4m50s
pv3 25Gi ROX Retain Available nfs <unset> 4m50s#建立pvc,pvc是pv使用的申请,需要保证和pod在一个namesapce中
[root@k8s-master pvc]# vim pvc.ym
apiVersion: v1
kind: PersistentVolumeClaim
metadata:name: pvc1
spec:storageClassName: nfsaccessModes:- ReadWriteOnceresources:requests:storage: 1Gi---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:name: pvc2
spec:storageClassName: nfsaccessModes:- ReadWriteManyresources:requests:storage: 10Gi---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:name: pvc3
spec:storageClassName: nfsaccessModes:- ReadOnlyManyresources:requests:storage: 15Gi
[root@k8s-master pvc]# kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS VOLUMEATTRIBUTESCLASS AGE
pvc1 Bound pv1 5Gi RWO nfs <unset> 5s
pvc2 Bound pv2 15Gi RWX nfs <unset> 4s
pvc3 Bound pv3 25Gi ROX nfs <unset> 4s#在其他namespace中无法应用
[root@k8s-master pvc]# kubectl -n kube-system get pvc
No resources found in kube-system namespace.
在pod中使用pvc
[root@k8s-master pvc]# vim pod.yml
apiVersion: v1
kind: Pod
metadata:name: timinglee
spec:containers:- image: nginxname: nginxvolumeMounts:- mountPath: /usr/share/nginx/htmlname: vol1volumes:- name: vol1persistentVolumeClaim:claimName: pvc1[root@k8s-master pvc]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
timinglee 1/1 Running 0 83s 10.244.2.54 k8s-node2 <none> <none>
[root@k8s-master pvc]# kubectl exec -it pods/timinglee -- /bin/bash
root@timinglee:/# curl localhost
<html>
<head><title>403 Forbidden</title></head>
<body>
<center><h1>403 Forbidden</h1></center>
<hr><center>nginx/1.27.1</center>
</body>
</html>
root@timinglee:/# cd /usr/share/nginx/
root@timinglee:/usr/share/nginx# ls
html
root@timinglee:/usr/share/nginx# cd html/
root@timinglee:/usr/share/nginx/html# ls[root@reg ~]# echo timinglee > /data/pv1/index.html[root@k8s-master pvc]# kubectl exec -it pods/timinglee -- /bin/bash
root@timinglee:/# cd /usr/share/nginx/html/
root@timinglee:/usr/share/nginx/html# ls
index.html
存储类storageclass
StorageClass提供了一种描述存储类(class)的方法,不同的class可能会映射到不同的服务质量等级和备份策略或其他策略等。
每个 StorageClass 都包含 provisioner、parameters 和 reclaimPolicy 字段, 这些字段会在StorageClass需要动态分配 PersistentVolume 时会使用到
StorageClass的属性
属性说明:https://kubernetes.io/zh/docs/concepts/storage/storage-classes/
Provisioner(存储分配器):用来决定使用哪个卷插件分配 PV,该字段必须指定。可以指定内部分配器,也可以指定外部分配器。外部分配器的代码地址为: kubernetes-incubator/external-storage,其中包括NFS和Ceph等。
Reclaim Policy(回收策略):通过reclaimPolicy字段指定创建的Persistent Volume的回收策略,回收策略包括:Delete 或者 Retain,没有指定默认为Delete。
存储分配器NFS Client Provisioner
源码地址:https://github.com/kubernetes-sigs/nfs-subdir-external-provisioner
-
NFS Client Provisioner是一个automatic provisioner,使用NFS作为存储,自动创建PV和对应的PVC,本身不提供NFS存储,需要外部先有一套NFS存储服务。
-
PV以 namespace−{namespace}-namespace−{pvcName}-${pvName}的命名格式提供(在NFS服务器上)
-
PV回收的时候以 archieved-namespace−{namespace}-namespace−{pvcName}-${pvName} 的命名格式(在NFS服务器上)
部署NFS Client Provisioner
创建sa并授权
[root@k8s-master storageclass]# vim rbac.yml
apiVersion: v1
kind: Namespace
metadata:name: nfs-client-provisioner
---
apiVersion: v1
kind: ServiceAccount
metadata:name: nfs-client-provisionernamespace: nfs-client-provisioner
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:name: nfs-client-provisioner-runner
rules:- apiGroups: [""]resources: ["nodes"]verbs: ["get", "list", "watch"]- apiGroups: [""]resources: ["persistentvolumes"]verbs: ["get", "list", "watch", "create", "delete"]- apiGroups: [""]resources: ["persistentvolumeclaims"]verbs: ["get", "list", "watch", "update"]- apiGroups: ["storage.k8s.io"]resources: ["storageclasses"]verbs: ["get", "list", "watch"]- apiGroups: [""]resources: ["events"]verbs: ["create", "update", "patch"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:name: run-nfs-client-provisioner
subjects:- kind: ServiceAccountname: nfs-client-provisionernamespace: nfs-client-provisioner
roleRef:kind: ClusterRolename: nfs-client-provisioner-runnerapiGroup: rbac.authorization.k8s.io
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:name: leader-locking-nfs-client-provisionernamespace: nfs-client-provisioner
rules:- apiGroups: [""]resources: ["endpoints"]verbs: ["get", "list", "watch", "create", "update", "patch"]
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:name: leader-locking-nfs-client-provisionernamespace: nfs-client-provisioner
subjects:- kind: ServiceAccountname: nfs-client-provisionernamespace: nfs-client-provisioner
roleRef:kind: Rolename: leader-locking-nfs-client-provisionerapiGroup: rbac.authorization.k8s.io#查看rbac信息
[root@k8s-master storageclass]# kubectl apply -f rbac.yml
namespace/nfs-client-provisioner created
serviceaccount/nfs-client-provisioner created
clusterrole.rbac.authorization.k8s.io/nfs-client-provisioner-runner created
clusterrolebinding.rbac.authorization.k8s.io/run-nfs-client-provisioner created
role.rbac.authorization.k8s.io/leader-locking-nfs-client-provisioner created
rolebinding.rbac.authorization.k8s.io/leader-locking-nfs-client-provisioner created
[root@k8s-master storageclass]# kubectl -n nfs-client-provisioner get sa
NAME SECRETS AGE
default 0 14s
nfs-client-provisioner 0 14s
部署应用
[root@k8s-master storageclass]# vim deployment.yml
apiVersion: apps/v1
kind: Deployment
metadata:name: nfs-client-provisionerlabels:app: nfs-client-provisionernamespace: nfs-client-provisioner
spec:replicas: 1strategy:type: Recreateselector:matchLabels:app: nfs-client-provisionertemplate:metadata:labels:app: nfs-client-provisionerspec:serviceAccountName: nfs-client-provisionercontainers:- name: nfs-client-provisionerimage: sig-storage/nfs-subdir-external-provisioner:v4.0.2volumeMounts:- name: nfs-client-rootmountPath: /persistentvolumesenv:- name: PROVISIONER_NAMEvalue: k8s-sigs.io/nfs-subdir-external-provisioner- name: NFS_SERVERvalue: 172.25.254.250- name: NFS_PATHvalue: /nfsdatavolumes:- name: nfs-client-rootnfs:server: 172.25.254.250path: /nfsdata[root@k8s-master storageclass]# kubectl -n nfs-client-provisioner get deployments.apps nfs-client-provisioner
NAME READY UP-TO-DATE AVAILABLE AGE
nfs-client-provisioner 1/1 1 1 86s
创建存储类
[root@k8s-master storageclass]# vim class.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:name: nfs-client
provisioner: k8s-sigs.io/nfs-subdir-external-provisioner
parameters:archiveOnDelete: "false"[root@k8s-master storageclass]# kubectl apply -f class.yaml
storageclass.storage.k8s.io/nfs-client created
[root@k8s-master storageclass]# kubectl get storageclasses.storage.k8s.io
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
nfs-client k8s-sigs.io/nfs-subdir-external-provisioner Delete Immediate false 9s
创建pvc
[root@k8s-master storageclass]# vim pvc.yml
kind: PersistentVolumeClaim
apiVersion: v1
metadata:name: test-claim
spec:storageClassName: nfs-clientaccessModes:- ReadWriteManyresources:requests:storage: 1G
[root@k8s-master storageclass]# kubectl apply -f pvc.yml
persistentvolumeclaim/test-claim created[root@k8s-master storageclass]# kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS VOLUMEATTRIBUTESCLASS AGE
test-claim Bound pvc-7782a006-381a-440a-addb-e9d659b8fe0b 1Gi RWX nfs-client <unset> 21m创建测试pod
[root@k8s-master storageclass]# vim pod.yml
kind: Pod
apiVersion: v1
metadata:name: test-pod
spec:containers:- name: test-podimage: busyboxcommand:- "/bin/sh"args:- "-c"- "touch /mnt/SUCCESS && exit 0 || exit 1"volumeMounts:- name: nfs-pvcmountPath: "/mnt"restartPolicy: "Never"volumes:- name: nfs-pvcpersistentVolumeClaim:claimName: test-claim[root@k8s-master storageclass]# kubectl apply -f pod.yml[root@reg ~]# ls /data/default-test-claim-pvc-b1aef9cc-4be9-4d2a-8c5e-0fe7716247e2/
SUCCESS
设置默认存储类
-
在未设定默认存储类时pvc必须指定使用类的名称
-
在设定存储类后创建pvc时可以不用指定storageClassName
#一次性指定多个pvc
[root@k8s-master pvc]# vim pvc.yml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:name: pvc1
spec:storageClassName: nfs-clientaccessModes:- ReadWriteOnceresources:requests:storage: 1Gi---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:name: pvc2
spec:storageClassName: nfs-clientaccessModes:- ReadWriteManyresources:requests:storage: 10Gi---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:name: pvc3
spec:storageClassName: nfs-clientaccessModes:- ReadOnlyManyresources:requests:storage: 15Giroot@k8s-master pvc]# kubectl apply -f pvc.yml
persistentvolumeclaim/pvc1 created
persistentvolumeclaim/pvc2 created
persistentvolumeclaim/pvc3 created
[root@k8s-master pvc]# kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS VOLUMEATTRIBUTESCLASS AGE
pvc1 Bound pvc-25a3c8c5-2797-4240-9270-5c51caa211b8 1Gi RWO nfs-client <unset> 4s
pvc2 Bound pvc-c7f34d1c-c8d3-4e7f-b255-e29297865353 10Gi RWX nfs-client <unset> 4s
pvc3 Bound pvc-5f1086ad-2999-487d-88d2-7104e3e9b221 15Gi ROX nfs-client <unset> 4s
test-claim Bound pvc-b1aef9cc-4be9-4d2a-8c5e-0fe7716247e2 1Gi RWX nfs-client <unset> 9m9s设定默认存储类
[root@k8s-master storageclass]# kubectl edit sc nfs-client
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:annotations:kubectl.kubernetes.io/last-applied-configuration: |{"apiVersion":"storage.k8s.io/v1","kind":"StorageClass","metadata":{"annotations":{},"name":"nfs-client"},"parameters":{"archiveOnDelete":"false"},"provisioner":"k8s-sigs.io/nfs-subdir-external-provisioner"}storageclass.kubernetes.io/is-default-class: "true" #设定默认存储类creationTimestamp: "2024-09-07T13:49:10Z"name: nfs-clientresourceVersion: "218198"uid: 9eb1e144-3051-4f16-bdec-30c472358028
parameters:archiveOnDelete: "false"
provisioner: k8s-sigs.io/nfs-subdir-external-provisioner
reclaimPolicy: Delete
volumeBindingMode: Immediate#测试,未指定storageClassName参数
[root@k8s-master storageclass]# vim pvc.yml
kind: PersistentVolumeClaim
apiVersion: v1
metadata:name: test-claim
spec:accessModes:- ReadWriteManyresources:requests:storage: 1Gi[root@k8s-master storageclass]# kubectl apply -f pvc.yml
persistentvolumeclaim/test-claim created
[root@k8s-master storageclass]# kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS VOLUMEATTRIBUTESCLASS AGE
test-claim Bound pvc-b96c6983-5a4f-440d-99ec-45c99637f9b5 1Gi RWX nfs-client <unset> 7sk8s网络通信
1.1 k8s通信整体架构
- k8s通过CNI接口接入其他插件来实现网络通讯。目前比较流行的插件有flannel,calico等
- CNI插件存放位置:# cat /etc/cni/net.d/10-flannel.conflist
- 插件使用的解决方案如下
- 虚拟网桥,虚拟网卡,多个容器共用一个虚拟网卡进行通信。
- 多路复用:MacVLAN,多个容器共用一个物理网卡进行通信。
- 硬件交换:SR-LOV,一个物理网卡可以虚拟出多个接口,这个性能最好。
- 容器间通信:
- 同一个pod内的多个容器间的通信,通过lo即可实现pod之间的通信
- 同一节点的pod之间通过cni网桥转发数据包。
- 不同节点的pod之间的通信需要网络插件支持
- pod和service通信: 通过iptables或ipvs实现通信,ipvs取代不了iptables,因为ipvs只能做负载均衡,而做不了nat转换
- pod和外网通信:iptables的MASQUERADE
- Service与集群外部客户端的通信;(ingress、nodeport、loadbalancer)
1.2 flannel网络插件
插件组成:
| 插件 | 功能 |
|---|---|
| VXLAN | 即Virtual Extensible LAN(虚拟可扩展局域网),是Linux本身支持的一网种网络虚拟化技术。VXLAN可以完全在内核态实现封装和解封装工作,从而通过“隧道”机制,构建出覆盖网络(Overlay Network) |
| VTEP | VXLAN Tunnel End Point(虚拟隧道端点),在Flannel中 VNI的默认值是1,这也是为什么宿主机的VTEP设备都叫flannel.1的原因 |
| Cni0 | 网桥设备,每创建一个pod都会创建一对 veth pair。其中一端是pod中的eth0,另一端是Cni0网桥中的端口(网卡) |
| Flannel.1 | TUN设备(虚拟网卡),用来进行 vxlan 报文的处理(封包和解包)。不同node之间的pod数据流量都从overlay设备以隧道的形式发送到对端 |
| Flanneld | flannel在每个主机中运行flanneld作为agent,它会为所在主机从集群的网络地址空间中,获取一个小的网段subnet,本主机内所有容器的IP地址都将从中分配。同时Flanneld监听K8s集群数据库,为flannel.1设备提供封装数据时必要的mac、ip等网络数据信息 |
1.2.1 flannel跨主机通信原理
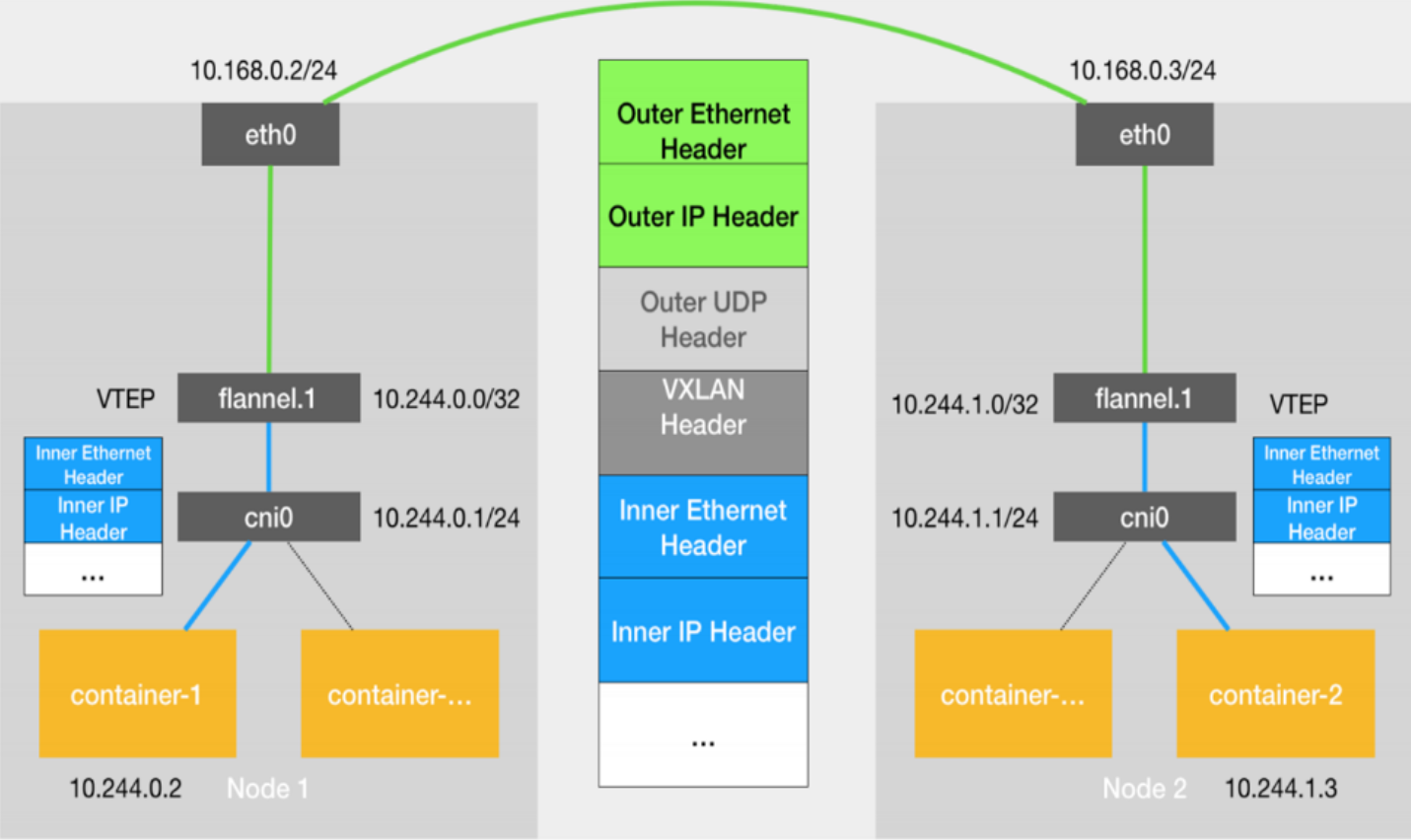
- 当容器发送IP包,通过veth pair 发往cni网桥,再路由到本机的flannel.1设备进行处理。
- VTEP设备之间通过二层数据帧进行通信,源VTEP设备收到原始IP包后,在上面加上一个目的MAC地址,封装成一个内部数据帧,发送给目的VTEP设备。
- 内部数据桢,并不能在宿主机的二层网络传输,Linux内核还需要把它进一步封装成为宿主机的一个普通的数据帧,承载着内部数据帧通过宿主机的eth0进行传输。
- Linux会在内部数据帧前面,加上一个VXLAN头,VXLAN头里有一个重要的标志叫VNI,它是VTEP识别某个数据桢是不是应该归自己处理的重要标识。
- flannel.1设备只知道另一端flannel.1设备的MAC地址,却不知道对应的宿主机地址是什么。在linux内核里面,网络设备进行转发的依据,来自FDB的转发数据库,这个flannel.1网桥对应的FDB信息,是由flanneld进程维护的。
- linux内核在IP包前面再加上二层数据帧头,把目标节点的MAC地址填进去,MAC地址从宿主机的ARP表获取。
- 此时flannel.1设备就可以把这个数据帧从eth0发出去,再经过宿主机网络来到目标节点的eth0设备。目标主机内核网络栈会发现这个数据帧有VXLAN Header,并且VNI为1,Linux内核会对它进行拆包,拿到内部数据帧,根据VNI的值,交给本机flannel.1设备处理,flannel.1拆包,根据路由表发往cni网桥,最后到达目标容器。
#默认网络通信路由
[root@k8s-master ~]# ip r
default via 172.25.254.2 dev eth0 proto static metric 100
10.244.0.0/24 dev cni0 proto kernel scope link src 10.244.0.1
10.244.1.0/24 via 10.244.1.0 dev flannel.1 onlink
10.244.2.0/24 via 10.244.2.0 dev flannel.1 onlink
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1 linkdown
172.25.254.0/24 dev eth0 proto kernel scope link src 172.25.254.100 metric 100#桥接转发数据库
[root@k8s-master ~]# bridge fdb
01:00:5e:00:00:01 dev eth0 self permanent
33:33:00:00:00:01 dev eth0 self permanent
01:00:5e:00:00:fb dev eth0 self permanent
33:33:ff:65:cb:fa dev eth0 self permanent
33:33:00:00:00:fb dev eth0 self permanent
33:33:00:00:00:01 dev docker0 self permanent
01:00:5e:00:00:6a dev docker0 self permanent
33:33:00:00:00:6a dev docker0 self permanent
01:00:5e:00:00:01 dev docker0 self permanent
01:00:5e:00:00:fb dev docker0 self permanent
02:42:76:94:aa:bc dev docker0 vlan 1 master docker0 permanent
02:42:76:94:aa:bc dev docker0 master docker0 permanent
33:33:00:00:00:01 dev kube-ipvs0 self permanent
82:14:17:b1:1d:d0 dev flannel.1 dst 172.25.254.20 self permanent
22:7f:e7:fd:33:77 dev flannel.1 dst 172.25.254.10 self permanent
33:33:00:00:00:01 dev cni0 self permanent
01:00:5e:00:00:6a dev cni0 self permanent
33:33:00:00:00:6a dev cni0 self permanent
01:00:5e:00:00:01 dev cni0 self permanent
33:33:ff:aa:13:2f dev cni0 self permanent
01:00:5e:00:00:fb dev cni0 self permanent
33:33:00:00:00:fb dev cni0 self permanent
0e:49:e3:aa:13:2f dev cni0 vlan 1 master cni0 permanent
0e:49:e3:aa:13:2f dev cni0 master cni0 permanent
7a:1c:2d:5d:0e:9e dev vethf29f1523 master cni0
5e:4e:96:a0:eb:db dev vethf29f1523 vlan 1 master cni0 permanent
5e:4e:96:a0:eb:db dev vethf29f1523 master cni0 permanent
33:33:00:00:00:01 dev vethf29f1523 self permanent
01:00:5e:00:00:01 dev vethf29f1523 self permanent
33:33:ff:a0:eb:db dev vethf29f1523 self permanent
33:33:00:00:00:fb dev vethf29f1523 self permanent
b2:f9:14:9f:71:29 dev veth18ece01e master cni0
3a:05:06:21:bf:7f dev veth18ece01e vlan 1 master cni0 permanent
3a:05:06:21:bf:7f dev veth18ece01e master cni0 permanent
33:33:00:00:00:01 dev veth18ece01e self permanent
01:00:5e:00:00:01 dev veth18ece01e self permanent
33:33:ff:21:bf:7f dev veth18ece01e self permanent
33:33:00:00:00:fb dev veth18ece01e self permanent#arp列表
[root@k8s-master ~]# arp -n
Address HWtype HWaddress Flags Mask Iface
10.244.0.2 ether 7a:1c:2d:5d:0e:9e C cni0
172.25.254.1 ether 00:50:56:c0:00:08 C eth0
10.244.2.0 ether 82:14:17:b1:1d:d0 CM flannel.1
10.244.1.0 ether 22:7f:e7:fd:33:77 CM flannel.1
172.25.254.20 ether 00:0c:29:6a:a8:61 C eth0
172.25.254.10 ether 00:0c:29:ea:52:cb C eth0
10.244.0.3 ether b2:f9:14:9f:71:29 C cni0
172.25.254.2 ether 00:50:56:fc:e0:b9 C eth01.2.2 flannel支持的后端模式
| 网络模式 | 功能 |
|---|---|
| vxlan | 报文封装,默认模式 |
| Directrouting | 直接路由,跨网段使用vxlan,同网段使用host-gw模式 |
| host-gw | 主机网关,性能好,但只能在二层网络中,不支持跨网络 如果有成千上万的Pod,容易产生广播风暴,不推荐 |
| UDP | 性能差,不推荐 |
更改flannel的默认模式
[root@k8s-master ~]# kubectl -n kube-flannel edit cm kube-flannel-cfg
apiVersion: v1
data:cni-conf.json: |{"name": "cbr0","cniVersion": "0.3.1","plugins": [{"type": "flannel","delegate": {"hairpinMode": true,"isDefaultGateway": true}},{"type": "portmap","capabilities": {"portMappings": true}}]}net-conf.json: |{"Network": "10.244.0.0/16","EnableNFTables": false,"Backend": {"Type": "host-gw" #更改内容}}
#重启pod
[root@k8s-master ~]# kubectl -n kube-flannel delete pod --all
pod "kube-flannel-ds-bk8wp" deleted
pod "kube-flannel-ds-mmftf" deleted
pod "kube-flannel-ds-tmfdn" deleted[root@k8s-master ~]# ip r
default via 172.25.254.2 dev eth0 proto static metric 100
10.244.0.0/24 dev cni0 proto kernel scope link src 10.244.0.1
10.244.1.0/24 via 172.25.254.10 dev eth0
10.244.2.0/24 via 172.25.254.20 dev eth0
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1 linkdown
172.25.254.0/24 dev eth0 proto kernel scope link src 172.25.254.100 metric 100
1.3 calico网络插件
官网:
https://docs.projectcalico.org/getting-started/kubernetes/self-managed-onprem/onpremises
1.3.1 calico简介:
- 纯三层的转发,中间没有任何的NAT和overlay,转发效率最好。
- Calico 仅依赖三层路由可达。Calico 较少的依赖性使它能适配所有 VM、Container、白盒或者混合环境场景。
1.3.2 calico网络架构
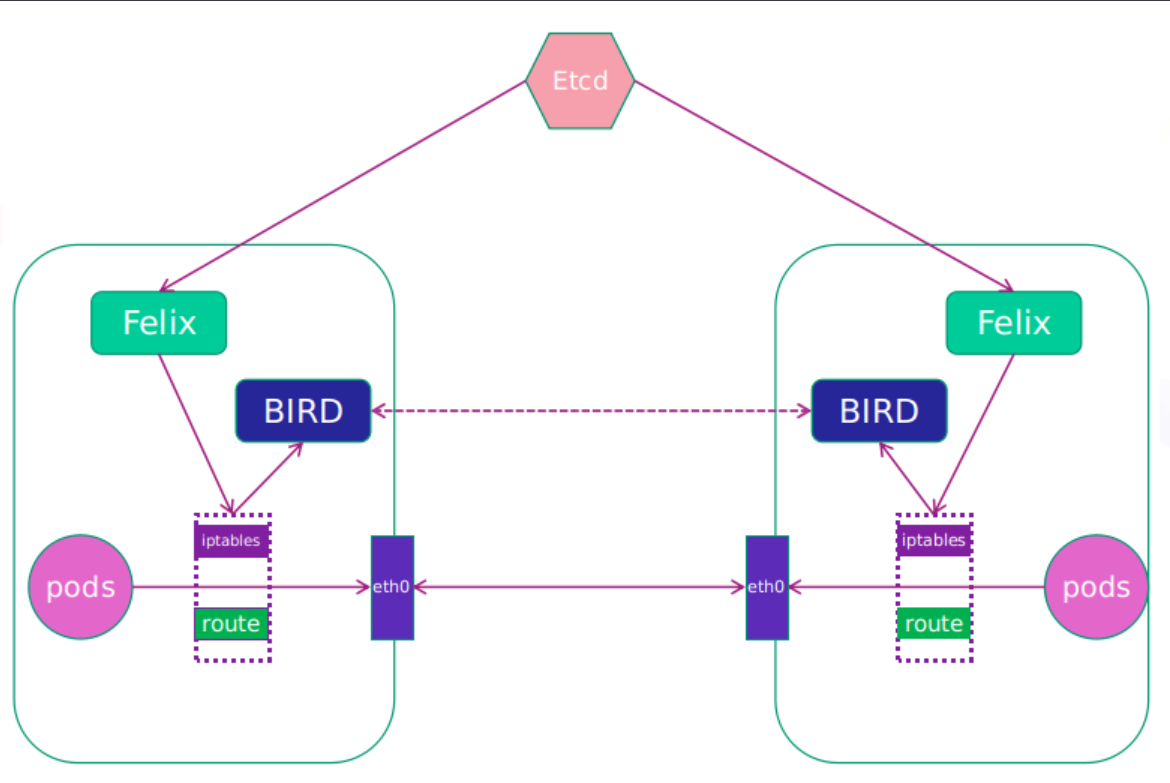
- Felix:监听ECTD中心的存储获取事件,用户创建pod后,Felix负责将其网卡、IP、MAC都设置好,然后在内核的路由表里面写一条,注明这个IP应该到这张网卡。同样如果用户制定了隔离策略,Felix同样会将该策略创建到ACL中,以实现隔离。
- BIRD:一个标准的路由程序,它会从内核里面获取哪一些IP的路由发生了变化,然后通过标准BGP的路由协议扩散到整个其他的宿主机上,让外界都知道这个IP在这里,路由的时候到这里
1.3.3 部署calico
删除flannel插件
[root@k8s-master ~]# kubectl delete -f kube-flannel.yml
删除所有节点上flannel配置文件,避免冲突
[root@k8s-master & node1-2 ~]# rm -rf /etc/cni/net.d/10-flannel.conflist
下载部署文件
[root@k8s-master calico]# curl https://raw.githubusercontent.com/projectcalico/calico/v3.28.1/manifests/calico-typha.yaml -o calico.yaml
下载镜像上传至仓库:
[root@k8s-master ~]# docker pull docker.io/calico/cni:v3.28.1
[root@k8s-master ~]# docker pull docker.io/calico/node:v3.28.1
[root@k8s-master ~]# docker pull docker.io/calico/kube-controllers:v3.28.1
[root@k8s-master ~]# docker pull docker.io/calico/typha:v3.28.1
更改yml设置
[root@k8s-master calico]# vim calico.yaml
4835 image: calico/cni:v3.28.1
4835 image: calico/cni:v3.28.1
4906 image: calico/node:v3.28.1
4932 image: calico/node:v3.28.1
5160 image: calico/kube-controllers:v3.28.1
5249 - image: calico/typha:v3.28.14970 - name: CALICO_IPV4POOL_IPIP
4971 value: "Never"4999 - name: CALICO_IPV4POOL_CIDR
5000 value: "10.244.0.0/16"
5001 - name: CALICO_AUTODETECTION_METHOD
5002 value: "interface=eth0"[root@k8s-master calico]# kubectl apply -f calico.yaml
[root@k8s-master calico]# kubectl -n kube-system get pods
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-6849cb478c-g5h5p 1/1 Running 0 75s
calico-node-dzzjp 1/1 Running 0 75s
calico-node-ltz7n 1/1 Running 0 75s
calico-node-wzdnq 1/1 Running 0 75s
calico-typha-fff9df85f-vm5ks 1/1 Running 0 75s
coredns-647dc95897-nchjr 1/1 Running 1 (139m ago) 4d7h
coredns-647dc95897-wjbg2 1/1 Running 1 (139m ago) 4d7h
etcd-k8s-master 1/1 Running 1 (139m ago) 4d7h
kube-apiserver-k8s-master 1/1 Running 1 (139m ago) 3d10h
kube-controller-manager-k8s-master 1/1 Running 3 (139m ago) 4d7h
kube-proxy-9g5z2 1/1 Running 1 (139m ago) 3d10h
kube-proxy-cd5wk 1/1 Running 1 (139m ago) 3d10h
kube-proxy-mvq4c 1/1 Running 1 (139m ago) 3d10h
kube-scheduler-k8s-master 1/1 Running 3 (139m ago) 4d7h测试:
[root@k8s-master calico]# kubectl run web --image myapp:v1
pod/web created
[root@k8s-master calico]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web 1/1 Running 0 5s 10.244.169.129 k8s-node2 <none> <none>
[root@k8s-master calico]# curl 10.244.169.129
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>k8s调度(Scheduling)
2.1 调度在Kubernetes中的作用
- 调度是指将未调度的Pod自动分配到集群中的节点的过程
- 调度器通过 kubernetes 的 watch 机制来发现集群中新创建且尚未被调度到 Node 上的 Pod
- 调度器会将发现的每一个未调度的 Pod 调度到一个合适的 Node 上来运行
2.2 调度原理:
- 创建Pod
- 用户通过Kubernetes API创建Pod对象,并在其中指定Pod的资源需求、容器镜像等信息。
- 调度器监视Pod
- Kubernetes调度器监视集群中的未调度Pod对象,并为其选择最佳的节点。
- 选择节点
- 调度器通过算法选择最佳的节点,并将Pod绑定到该节点上。调度器选择节点的依据包括节点的资源使用情况、Pod的资源需求、亲和性和反亲和性等。
- 绑定Pod到节点
- 调度器将Pod和节点之间的绑定信息保存在etcd数据库中,以便节点可以获取Pod的调度信息。
- 节点启动Pod
- 节点定期检查etcd数据库中的Pod调度信息,并启动相应的Pod。如果节点故障或资源不足,调度器会重新调度Pod,并将其绑定到其他节点上运行。
2.3 调度器种类
- 默认调度器(Default Scheduler):
- 是Kubernetes中的默认调度器,负责对新创建的Pod进行调度,并将Pod调度到合适的节点上。
- 自定义调度器(Custom Scheduler):
- 是一种自定义的调度器实现,可以根据实际需求来定义调度策略和规则,以实现更灵活和多样化的调度功能。
- 扩展调度器(Extended Scheduler):
- 是一种支持调度器扩展器的调度器实现,可以通过调度器扩展器来添加自定义的调度规则和策略,以实现更灵活和多样化的调度功能。
- kube-scheduler是kubernetes中的默认调度器,在kubernetes运行后会自动在控制节点运行
2.4 常用调度方法
2.4.1 nodename
- nodeName 是节点选择约束的最简单方法,但一般不推荐
- 如果 nodeName 在 PodSpec 中指定了,则它优先于其他的节点选择方法
- 使用 nodeName 来选择节点的一些限制
- 如果指定的节点不存在。
- 如果指定的节点没有资源来容纳 pod,则pod 调度失败。
- 云环境中的节点名称并非总是可预测或稳定的
实例:
#建立pod文件
[[root@k8s-master scheduler]# kubectl run testpod --image myapp:v1 --dry-run=client -o yaml > pod1.yml#设置调度
[root@k8s-master scheduler]# vim pod1.yml
apiVersion: v1
kind: Pod
metadata:labels:run: testpodname: testpod
spec:nodeName: k8s-node2containers:- image: myapp:v1name: testpod#建立pod
[root@k8s-master scheduler]# kubectl apply -f pod1.yml
pod/testpod created[root@k8s-master scheduler]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
testpod 1/1 Running 0 18s 10.244.169.130 k8s-node2 <none> <none>[!NOTE]
nodeName: k8s3 #找不到节点pod会出现pending,优先级最高,其他调度方式无效
2.4.2 Nodeselector(通过标签控制节点)
-
nodeSelector 是节点选择约束的最简单推荐形式
-
给选择的节点添加标签:
kubectl label nodes k8s-node1 lab=lee -
可以给多个节点设定相同标签
示例:
#查看节点标签
[root@k8s-master scheduler]# kubectl get nodes --show-labels
NAME STATUS ROLES AGE VERSION LABELS
k8s-master Ready control-plane 5d3h v1.30.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-master,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node.kubernetes.io/exclude-from-external-load-balancers=
k8s-node1 Ready <none> 5d3h v1.30.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-node1,kubernetes.io/os=linux
k8s-node2 Ready <none> 5d3h v1.30.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-node2,kubernetes.io/os=linux#设定节点标签
[root@k8s-master scheduler]# kubectl label nodes k8s-node1 lab=timinglee
node/k8s-node1 labeled
[root@k8s-master scheduler]# kubectl get nodes k8s-node1 --show-labels
NAME STATUS ROLES AGE VERSION LABELS
k8s-node1 Ready <none> 5d3h v1.30.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-node1,kubernetes.io/os=linux,lab=timinglee#调度设置
[root@k8s-master scheduler]# vim pod2.yml
apiVersion: v1
kind: Pod
metadata:labels:run: testpodname: testpod
spec:nodeSelector:lab: timingleecontainers:- image: myapp:v1name: testpod[root@k8s-master scheduler]# kubectl apply -f pod2.yml
pod/testpod created
[root@k8s-master scheduler]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
testpod 1/1 Running 0 4s 10.244.36.65 k8s-node1 <none> <none>
[!NOTE]
节点标签可以给N个节点加
2.5 affinity(亲和性)
官方文档 :
https://kubernetes.io/zh/docs/concepts/scheduling-eviction/assign-pod-node
2.5.1 亲和与反亲和
- nodeSelector 提供了一种非常简单的方法来将 pod 约束到具有特定标签的节点上。亲和/反亲和功能极大地扩展了你可以表达约束的类型。
- 使用节点上的 pod 的标签来约束,而不是使用节点本身的标签,来允许哪些 pod 可以或者不可以被放置在一起。
2.5.2 nodeAffinity节点亲和
- 那个节点服务指定条件就在那个节点运行
- requiredDuringSchedulingIgnoredDuringExecution 必须满足,但不会影响已经调度
- preferredDuringSchedulingIgnoredDuringExecution 倾向满足,在无法满足情况下也会调度pod
- IgnoreDuringExecution 表示如果在Pod运行期间Node的标签发生变化,导致亲和性策略不能满足,则继续运行当前的Pod。
- nodeaffinity还支持多种规则匹配条件的配置如
| 匹配规则 | 功能 |
|---|---|
| ln | label 的值在列表内 |
| Notln | label 的值不在列表内 |
| Gt | label 的值大于设置的值,不支持Pod亲和性 |
| Lt | label 的值小于设置的值,不支持pod亲和性 |
| Exists | 设置的label 存在 |
| DoesNotExist | 设置的 label 不存在 |
nodeAffinity示例
#示例1
[root@k8s-master scheduler]# vim pod3.yml
apiVersion: v1
kind: Pod
metadata:name: node-affinity
spec:containers:- name: nginximage: nginxaffinity:nodeAffinity:requiredDuringSchedulingIgnoredDuringExecution:nodeSelectorTerms:- matchExpressions:- key: diskoperator: In | NotIn #两个结果相反values:- ssd2.5.3 Podaffinity(pod的亲和)
- 那个节点有符合条件的POD就在那个节点运行
- podAffinity 主要解决POD可以和哪些POD部署在同一个节点中的问题
- podAntiAffinity主要解决POD不能和哪些POD部署在同一个节点中的问题。它们处理的是Kubernetes集群内部POD和POD之间的关系。
- Pod 间亲和与反亲和在与更高级别的集合(例如 ReplicaSets,StatefulSets,Deployments 等)一起使用时,
- Pod 间亲和与反亲和需要大量的处理,这可能会显著减慢大规模集群中的调度。
Podaffinity示例
[root@k8s-master scheduler]# vim example4.yml
apiVersion: apps/v1
kind: Deployment
metadata:name: nginx-deploymentlabels:app: nginx
spec:replicas: 3selector:matchLabels:app: nginxtemplate:metadata:labels:app: nginxspec:containers:- name: nginximage: nginxaffinity:podAffinity:requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:matchExpressions:- key: appoperator: Invalues:- nginxtopologyKey: "kubernetes.io/hostname"[root@k8s-master scheduler]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deployment-658496fff-d58bk 1/1 Running 0 39s 10.244.169.133 k8s-node2 <none> <none>
nginx-deployment-658496fff-g25nq 1/1 Running 0 39s 10.244.169.134 k8s-node2 <none> <none>
nginx-deployment-658496fff-vnlxz 1/1 Running 0 39s 10.244.169.135 k8s-node2 <none> <none>
2.5.4 Podantiaffinity(pod反亲和)
Podantiaffinity示例
[root@k8s-master scheduler]# vim example5.yml
apiVersion: apps/v1
kind: Deployment
metadata:name: nginx-deploymentlabels:app: nginx
spec:replicas: 3selector:matchLabels:app: nginxtemplate:metadata:labels:app: nginxspec:containers:- name: nginximage: nginxaffinity:podAntiAffinity: #反亲和requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:matchExpressions:- key: appoperator: Invalues:- nginxtopologyKey: "kubernetes.io/hostname"[root@k8s-master scheduler]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deployment-5f5fc7b8b9-hs9kz 1/1 Running 0 6s 10.244.169.136 k8s-node2 <none> <none>
nginx-deployment-5f5fc7b8b9-ktzsh 0/1 Pending 0 6s <none> <none> <none> <none>
nginx-deployment-5f5fc7b8b9-txdt9 1/1 Running 0 6s 10.244.36.67 k8s-node1 <none> <none>2.6 Taints(污点模式,禁止调度)
- Taints(污点)是Node的一个属性,设置了Taints后,默认Kubernetes是不会将Pod调度到这个Node上
- Kubernetes如果为Pod设置Tolerations(容忍),只要Pod能够容忍Node上的污点,那么Kubernetes就会忽略Node上的污点,就能够(不是必须)把Pod调度过去
- 可以使用命令 kubectl taint 给节点增加一个 taint:
$ kubectl taint nodes <nodename> key=string:effect #命令执行方法
$ kubectl taint nodes node1 key=value:NoSchedule #创建
$ kubectl describe nodes server1 | grep Taints #查询
$ kubectl taint nodes node1 key- #删除
其中[effect] 可取值:
| effect值 | 解释 |
|---|---|
| NoSchedule | POD 不会被调度到标记为 taints 节点 |
| PreferNoSchedule | NoSchedule 的软策略版本,尽量不调度到此节点 |
| NoExecute | 如该节点内正在运行的 POD 没有对应 Tolerate 设置,会直接被逐出 |
Taints示例
#建立控制器并运行
[root@k8s-master scheduler]# vim example6.yml
apiVersion: apps/v1
kind: Deployment
metadata:labels:app: webname: web
spec:replicas: 2selector:matchLabels:app: webtemplate:metadata:labels:app: webspec:containers:- image: nginxname: nginx[root@k8s-master scheduler]# kubectl apply -f example6.yml
deployment.apps/web createdroot@k8s-master scheduler]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-7c56dcdb9b-9wwdg 1/1 Running 0 25s 10.244.36.68 k8s-node1 <none> <none>
web-7c56dcdb9b-qsx6w 1/1 Running 0 25s 10.244.169.137 k8s-node2 <none> <none>#设定污点为NoSchedule
[root@k8s-master scheduler]# kubectl taint node k8s-node1 name=lee:NoSchedule
node/k8s-node1 tainted
[root@k8s-master scheduler]# kubectl describe nodes k8s-node1 | grep Tain
Taints: name=lee:NoSchedule#控制器增加pod
[root@k8s-master scheduler]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-7c56dcdb9b-4l759 1/1 Running 0 6s 10.244.169.140 k8s-node2 <none> <none>
web-7c56dcdb9b-9wwdg 1/1 Running 0 6m35s 10.244.36.68 k8s-node1 <none> <none>
web-7c56dcdb9b-bqd75 1/1 Running 0 6s 10.244.169.141 k8s-node2 <none> <none>
web-7c56dcdb9b-m8kx8 1/1 Running 0 6s 10.244.169.138 k8s-node2 <none> <none>
web-7c56dcdb9b-qsx6w 1/1 Running 0 6m35s 10.244.169.137 k8s-node2 <none> <none>
web-7c56dcdb9b-rhft4 1/1 Running 0 6s 10.244.169.139 k8s-node2 <none> <none>#设定污点为NoExecute
[root@k8s-master scheduler]# kubectl taint node k8s-node1 name=lee:NoExecute
node/k8s-node1 tainted
[root@k8s-master scheduler]# kubectl describe nodes k8s-node1 | grep Tain
Taints: name=lee:NoExecute[root@k8s-master scheduler]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-7c56dcdb9b-4l759 1/1 Running 0 108s 10.244.169.140 k8s-node2 <none> <none>
web-7c56dcdb9b-bqd75 1/1 Running 0 108s 10.244.169.141 k8s-node2 <none> <none>
web-7c56dcdb9b-m8kx8 1/1 Running 0 108s 10.244.169.138 k8s-node2 <none> <none>
web-7c56dcdb9b-mhkhl 0/1 ContainerCreating 0 14s <none> k8s-node2 <none> <none>
web-7c56dcdb9b-qsx6w 1/1 Running 0 8m17s 10.244.169.137 k8s-node2 <none> <none>
web-7c56dcdb9b-rhft4 1/1 Running 0 108s 10.244.169.139 k8s-node2 <none> <none>#删除污点
[root@k8s-master scheduler]# kubectl taint node k8s-node1 name-
node/k8s-node1 untainted
[root@k8s-master scheduler]#
[root@k8s-master scheduler]# kubectl describe nodes k8s-node1 | grep Tain
Taints: <none>tolerations(污点容忍)
- tolerations中定义的key、value、effect,要与node上设置的taint保持一直:
- 如果 operator 是 Equal ,则key与value之间的关系必须相等。
- 如果 operator 是 Exists ,value可以省略
- 如果不指定operator属性,则默认值为Equal。
- 还有两个特殊值:
- 当不指定key,再配合Exists 就能匹配所有的key与value ,可以容忍所有污点。
- 当不指定effect ,则匹配所有的effect
污点容忍示例:
#设定节点污点
[root@k8s-master scheduler]# kubectl taint node k8s-node1 name=lee:NoExecute
node/k8s-node1 tainted
[root@k8s-master scheduler]# kubectl taint node k8s-node2 nodetype=bad:NoSchedule
node/k8s-node2 tainted[root@k8s-master scheduler]# vim example7.yml
apiVersion: apps/v1
kind: Deployment
metadata:labels:app: webname: web
spec:replicas: 6selector:matchLabels:app: webtemplate:metadata:labels:app: webspec:containers:- image: nginxname: nginxtolerations: #容忍所有污点- operator: Existstolerations: #容忍effect为Noschedule的污点- operator: Existseffect: NoScheduletolerations: #容忍指定kv的NoSchedule污点- key: nodetypevalue: badeffect: NoSchedule
认证(在k8s中建立认证用户)
创建UserAccount
#建立证书
[root@k8s-master auth]# cd /etc/kubernetes/pki/
[root@k8s-master pki]# openssl genrsa -out timinglee.key 2048
[root@k8s-master pki]# openssl req -new -key timinglee.key -out timinglee.csr -subj "/CN=timinglee"
[root@k8s-master pki]# openssl x509 -req -in timinglee.csr -CA ca.crt -CAkey ca.key -CAcreateserial -out timinglee.crt -days 365
Certificate request self-signature ok[root@k8s-master pki]# openssl x509 -in timinglee.crt -text -noout
Certificate:Data:Version: 1 (0x0)Serial Number:76:06:6c:a7:36:53:b9:3f:5a:6a:93:3a:f2:e8:82:96:27:57:8e:58Signature Algorithm: sha256WithRSAEncryptionIssuer: CN = kubernetesValidityNot Before: Sep 8 15:59:55 2024 GMTNot After : Sep 8 15:59:55 2025 GMTSubject: CN = timingleeSubject Public Key Info:Public Key Algorithm: rsaEncryptionPublic-Key: (2048 bit)Modulus:00:a6:6d:be:5d:7f:4c:bf:36:96:dc:4e:1b:24:64:f7:4b:57:d3:45:ad:e8:b5:07:e7:78:2b:9e:6e:53:2f:16:ff:00:f4:c8:41:2c:89:3d:86:7c:1b:16:08:2e:2c:bc:2c:1e:df:60:f0:80:60:f9:79:49:91:1d:9f:47:16:9a:d1:86:c7:4f:02:55:27:12:93:b7:f4:07:fe:13:64:fd:78:32:8d:12:d5:c2:0f:be:67:65:f2:56:e4:d1:f6:fe:f6:d5:7c:2d:1d:c8:90:2a:ac:3f:62:85:9f:4a:9d:85:73:33:26:5d:0f:4a:a9:14:12:d4:fb:b3:b9:73:d0:a3:be:58:41:cb:a0:62:3e:1b:44:ef:61:b5:7f:4a:92:5b:e3:71:77:99:b4:ea:4d:27:80:14:e9:95:4c:d5:62:56:d6:54:7b:f7:c2:ea:0e:47:b2:19:75:59:22:00:bd:ea:83:6b:cd:12:46:7a:4a:79:83:ee:bc:59:6f:af:8e:1a:fd:aa:b4:bd:84:4d:76:38:e3:1d:ea:56:b5:1e:07:f5:39:ef:56:57:a2:3d:91:c0:3f:38:ce:36:5d:c7:fe:5e:0f:53:75:5a:f0:6e:37:71:4b:90:03:2f:2e:11:bb:a1:a1:5b:dc:89:b8:19:79:0a:ee:e9:b5:30:7d:16:44:4a:53Exponent: 65537 (0x10001)Signature Algorithm: sha256WithRSAEncryptionSignature Value:62:db:0b:58:a9:59:57:91:7e:de:9e:bb:20:2f:24:fe:b7:7f:33:aa:d5:74:0e:f9:96:ce:1b:a9:65:08:7f:22:6b:45:ee:58:68:d8:26:44:33:5e:45:e1:82:b2:5c:99:41:6b:1e:fa:e8:1a:a2:f1:8f:44:22:e1:d6:58:5f:4c:28:3d:e0:78:21:ea:aa:85:08:a5:c8:b3:34:19:d3:c7:e2:fe:a2:a4:f5:68:18:53:5f:ff:7d:35:22:3c:97:3d:4e:ad:62:5f:bb:4d:88:fb:67:f4:d5:2d:81:c8:2c:6c:5e:0e:e2:2c:f5:e9:07:34:16:01:e2:bf:1f:cd:6a:66:db:b6:7b:92:df:13:a1:d0:58:d8:4d:68:96:66:e3:00:6e:ce:11:99:36:9c:b3:b5:81:bf:d1:5b:d7:f2:08:5e:7d:ea:97:fe:b3:80:d6:27:1c:89:e6:f2:f3:03:fc:dc:de:83:5e:24:af:46:a6:2a:8e:b1:34:67:51:2b:19:eb:4c:78:12:ac:00:4e:58:5e:fd:6b:4c:ce:73:dd:b3:91:73:4a:d6:6f:2c:86:25:f0:6a:fb:96:66:b3:39:a4:b0:d9:46:c2:fc:6b:06:b2:90:9c:13:e1:02:8b:6f:6e:ab:cf:e3:21:7e:a9:76:c1:38:15:eb:e6:2d:a5:6f:e5:ab#建立k8s中的用户
[root@k8s-master pki]# kubectl config set-credentials timinglee --client-certificate /etc/kubernetes/pki/timinglee.crt --client-key /etc/kubernetes/pki/timinglee.key --embed-certs=true
User "timinglee" set.[root@k8s-master pki]# kubectl config view
apiVersion: v1
clusters:
- cluster:certificate-authority-data: DATA+OMITTEDserver: https://172.25.254.100:6443name: kubernetes
contexts:
- context:cluster: kubernetesuser: kubernetes-adminname: kubernetes-admin@kubernetes
current-context: kubernetes-admin@kubernetes
kind: Config
preferences: {}
users:
- name: kubernetes-adminuser:client-certificate-data: DATA+OMITTEDclient-key-data: DATA+OMITTED
- name: timingleeuser:client-certificate-data: DATA+OMITTEDclient-key-data: DATA+OMITTED#为用户创建集群的安全上下文
root@k8s-master pki]# kubectl config set-context timinglee@kubernetes --cluster kubernetes --user timinglee
Context "timinglee@kubernetes" created.#切换用户,用户在集群中只有用户身份没有授权
[root@k8s-master ~]# kubectl config use-context timinglee@kubernetes
Switched to context "timinglee@kubernetes".
[root@k8s-master ~]# kubectl get pods
Error from server (Forbidden): pods is forbidden: User "timinglee" cannot list resource "pods" in API group "" in the namespace "default"#切换会集群管理
[root@k8s-master ~]# kubectl config use-context kubernetes-admin@kubernetes
Switched to context "kubernetes-admin@kubernetes".#如果需要删除用户
[root@k8s-master pki]# kubectl config delete-user timinglee
deleted user timinglee from /etc/kubernetes/admin.conf
RBAC(Role Based Access Control)
基于角色访问控制授权:
-
允许管理员通过Kubernetes API动态配置授权策略。RBAC就是用户通过角色与权限进行关联。
-
RBAC只有授权,没有拒绝授权,所以只需要定义允许该用户做什么即可
-
RBAC的三个基本概念
-
Subject:被作用者,它表示k8s中的三类主体, user, group, serviceAccount
-
Role:角色,它其实是一组规则,定义了一组对 Kubernetes API 对象的操作权限。
-
RoleBinding:定义了“被作用者”和“角色”的绑定关系
-
-
RBAC包括四种类型:Role、ClusterRole、RoleBinding、ClusterRoleBinding
-
Role 和 ClusterRole
-
Role是一系列的权限的集合,Role只能授予单个namespace 中资源的访问权限。
-
ClusterRole 跟 Role 类似,但是可以在集群中全局使用。
-
Kubernetes 还提供了四个预先定义好的 ClusterRole 来供用户直接使用
-
cluster-amdin、admin、edit、view
-
role授权实施
#生成role的yaml文件
[root@k8s-master rbac]# kubectl create role myrole --dry-run=client --verb=get --resource pods -o yaml > myrole.yml#更改文件内容
[root@k8s-master rbac]# vim myrole.yml
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:creationTimestamp: nullname: myrole
rules:
- apiGroups:- ""resources:- podsverbs:- get- watch- list- create- update- path- delete#创建role
[root@k8s-master rbac]# kubectl apply -f myrole.yml
[root@k8s-master rbac]# kubectl describe role myrole
Name: myrole
Labels: <none>
Annotations: <none>
PolicyRule:Resources Non-Resource URLs Resource Names Verbs--------- ----------------- -------------- -----pods [] [] [get watch list create update path delete]
#建立角色绑定
[root@k8s-master rbac]# kubectl create rolebinding timinglee --role myrole --namespace default --user timinglee --dry-run=client -o yaml > rolebinding-myrole.yml[root@k8s-master rbac]# vim rolebinding-myrole.yml
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:name: timingleenamespace: default #角色绑定必须指定namespace
roleRef:apiGroup: rbac.authorization.k8s.iokind: Rolename: myrole
subjects:
- apiGroup: rbac.authorization.k8s.iokind: Username: timinglee[root@k8s-master rbac]# kubectl apply -f rolebinding-myrole.yml
rolebinding.rbac.authorization.k8s.io/timinglee created
[root@k8s-master rbac]# kubectl get rolebindings.rbac.authorization.k8s.io timinglee
NAME ROLE AGE
timinglee Role/myrole 9s
#切换用户测试授权
[root@k8s-master rbac]# kubectl config use-context timinglee@kubernetes
Switched to context "timinglee@kubernetes".[root@k8s-master rbac]# kubectl get pods
No resources found in default namespace.
[root@k8s-master rbac]# kubectl get svc #只针对pod进行了授权,所以svc依然不能操作
Error from server (Forbidden): services is forbidden: User "timinglee" cannot list resource "services" in API group "" in the namespace "default"#切换回管理员
[root@k8s-master rbac]# kubectl config use-context kubernetes-admin@kubernetes
Switched to context "kubernetes-admin@kubernetes".
clusterrole授权实施
#建立集群角色
[root@k8s-master rbac]# kubectl create clusterrole myclusterrole --resource=deployment --verb get --dry-run=client -o yaml > myclusterrole.yml
[root@k8s-master rbac]# vim myclusterrole.yml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:name: myclusterrole
rules:
- apiGroups:- appsresources:- deploymentsverbs:- get- list- watch- create- update- path- delete
- apiGroups:- ""resources:- podsverbs:- get- list- watch- create- update- path- delete[root@k8s-master rbac]# kubectl describe clusterrole myclusterrole
Name: myclusterrole
Labels: <none>
Annotations: <none>
PolicyRule:Resources Non-Resource URLs Resource Names Verbs--------- ----------------- -------------- -----deployments.apps [] [] [get list watch create update path delete]pods.apps [] [] [get list watch create update path delete]#建立集群角色绑定
[root@k8s-master rbac]# kubectl create clusterrolebinding clusterrolebind-myclusterrole --clusterrole myclusterrole --user timinglee --dry-run=client -o yaml > clusterrolebind-myclusterrole.yml
[root@k8s-master rbac]# vim clusterrolebind-myclusterrole.yml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:name: clusterrolebind-myclusterrole
roleRef:apiGroup: rbac.authorization.k8s.iokind: ClusterRolename: myclusterrole
subjects:
- apiGroup: rbac.authorization.k8s.iokind: Username: timinglee[root@k8s-master rbac]# kubectl describe clusterrolebindings.rbac.authorization.k8s.io clusterrolebind-myclusterrole
Name: clusterrolebind-myclusterrole
Labels: <none>
Annotations: <none>
Role:Kind: ClusterRoleName: myclusterrole
Subjects:Kind Name Namespace---- ---- ---------User timinglee#测试:
[root@k8s-master rbac]# kubectl get pods -A
[root@k8s-master rbac]# kubectl get deployments.apps -A
[root@k8s-master rbac]# kubectl get svc -A
Error from server (Forbidden): services is forbidden: User "timinglee" cannot list resource "services" in API group "" at the cluster scope
服务账户的自动化
服务账户准入控制器(Service account admission controller)
-
如果该 pod 没有 ServiceAccount 设置,将其 ServiceAccount 设为 default。
-
保证 pod 所关联的 ServiceAccount 存在,否则拒绝该 pod。
-
如果 pod 不包含 ImagePullSecrets 设置,那么 将 ServiceAccount 中的 ImagePullSecrets 信息添加到 pod 中。
-
将一个包含用于 API 访问的 token 的 volume 添加到 pod 中。
-
将挂载于 /var/run/secrets/kubernetes.io/serviceaccount 的 volumeSource 添加到 pod 下的每个容器中。
服务账户控制器(Service account controller)
服务账户管理器管理各命名空间下的服务账户,并且保证每个活跃的命名空间下存在一个名为 “default” 的服务账户