c++基础知识入门
目录
c++第一个程序
命名空间(namespace)
背景:
namespace的定义
using namespace 简化
命名空间嵌套
注意:
:: 作用:
无名命名空间
命名空间使用
c++输入&输出
缺省参数
核心:
缺省参数必须从右向左连续设置
缺省参数不能在声明和定义中重复指定
错误示范:
缺省参数的默认值必须是常量表达式
错误示范:
应用:
简化函数调用
兼容旧接口
注意:
函数重载
构成重载的条件
参数类型不同
参数个数不同
参数顺序不同
不能构成重载的情况
仅返回值类型不同
参数名
默认参数不同
引用的认识
核心特性:
必须初始化
一旦绑定,不可更改
与原变量共享内存
引用的使用
作为函数参数
优势:
作为函数返回值
注意:
常量引用
引用与指针区别:
注意事项:
const 引用
只读性
绑定到const变量
绑定到临时值
绑定到不同类型值(隐式转换)
核心引用场景:
作为函数参数(最常用)
安全高效地传递大型对象
存储临时结果
*
误区:
inline
声明方式:
核心作用:
使用规则和特性
1.inline 是 “建议” 而非 “命令”
2. 内联函数需在调用前定义
3. 避免内联过多导致代码膨胀
以下情况不适合使用 inline:
宏与inline
核心差异 1:参数求值方式(最关键)
示例:参数含副作用(如自增、自减、函数调用)
(1)宏的执行过程:文本替换 + 多次求值
(2)inline 函数的执行过程:参数先求值一次
二、核心差异 2:类型安全
示例:传入错误类型
三、核心差异 3:语法边界问题
示例:宏的语法边界漏洞
nullptr
优势:
c++第一个程序
#include<iostream>
using namespace std;
int main()
{cout << "first one!" << endl;return 0;
}
命名空间(namespace)
背景:
namespace的定义
#include <cassert>
#include <cstdlib>
// 假设 STDataType 是 int,这里用命名空间封装栈相关逻辑
namespace StackNamespace {typedef int STDataType;typedef struct ST {STDataType* arr;int top;int capacity;} ST;void STInit(ST* ps) {assert(ps);ps->arr = (STDataType*)malloc(4 * sizeof(STDataType));ps->top = 0;ps->capacity = 4;}
}int main() {StackNamespace::ST st;StackNamespace::STInit(&st);// ... 后续操作return 0;
}作用:把栈的结构体、函数都放进 StackNamespace,避免和其他库 / 代码的同名标识符冲突。
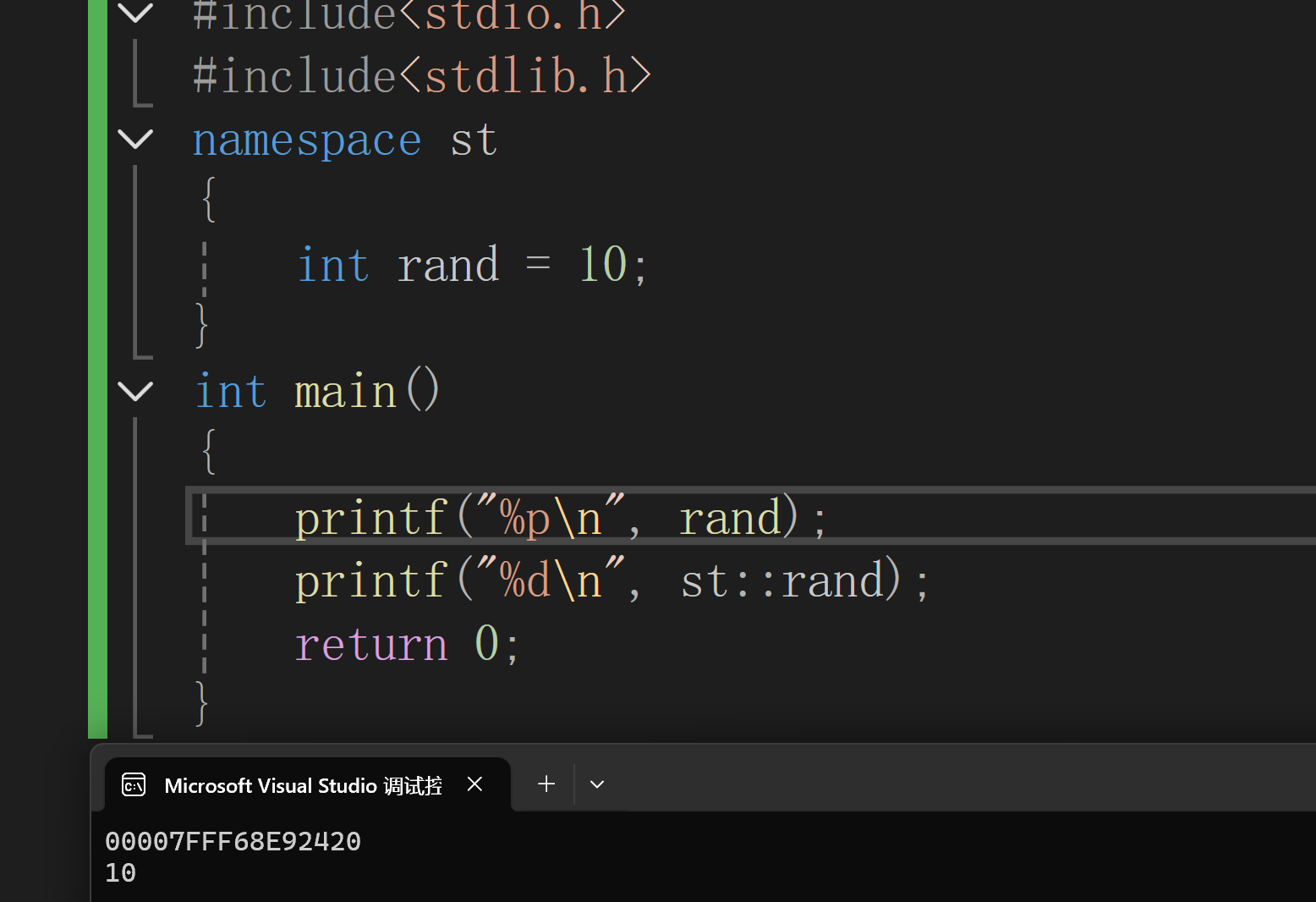
第一个默认访问的是全局变量中的rand指针变量;而第二个则是命名空间st中的rand
using namespace 简化
如果觉得每次写ST:: 麻烦,可局部 / 全局引入:
int main() {using namespace S; ST st;STInit(&st);return 0;
}局部引入,当前作用域可直接用 ST、STInit
全局 using namespace(比如写在文件开头)可能引发命名冲突,大型项目 / 库中慎用。
命名空间嵌套
namespace Project {namespace DataStruct {namespace Stack {typedef int STDataType;// ... 栈的定义、函数}}
}// 使用时:
Project::DataStruct::Stack::ST st;注意:
:: 作用:
- C++ 里
::是作用域解析符,C 本身无严格命名空间,但编译器(如 GCC)支持用::访问全局作用域(可简单理解为 “默认全局” )。 ::rand想访问标准库的全局rand函数(<stdlib.h>里的随机数函数)
无名命名空间
可以定义没有名字的命名空间,它的作用域仅限于当前源文件。无名命名空间中的成员相当于具有静态存储期和内部链接属性,在其他源文件中不可见。
namespace {int localVar = 20;void localFunc() {std::cout << "Local function" << std::endl;}
}在当前源文件中可以直接使用 localVar 和 localFunc(),而无需使用命名空间名。
命名空间使用
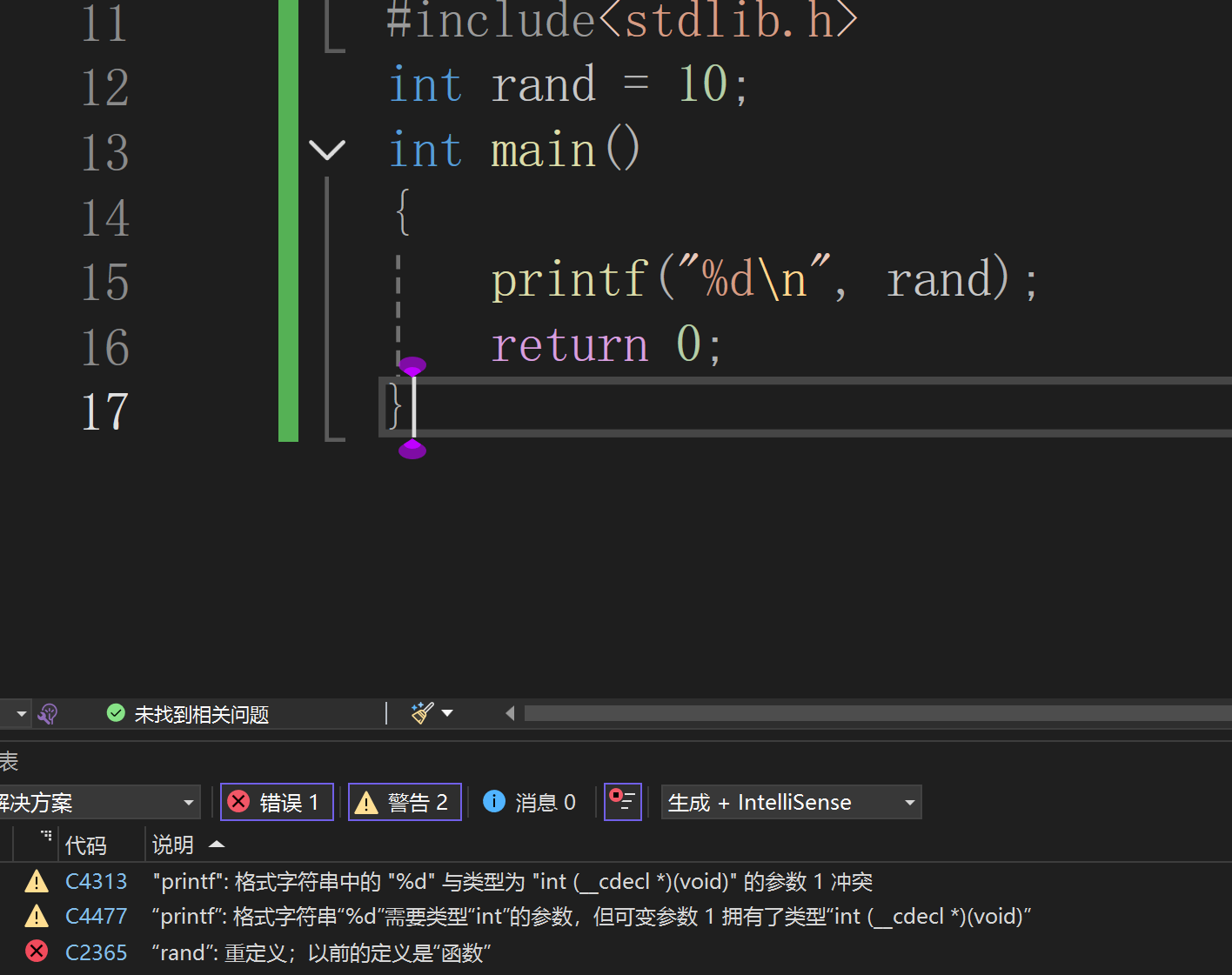
namespace st
{int a = 10;
}
using st::a;
int main()
{//printf("%d\n", st::a);printf("%d\n", a);return 0;
}
这便是展开某个成员。
c++输入&输出
<<(流插入):“写数据”,将数据输出到流(屏幕、文件),核心配合cout/cerr;>>(流提取):“读数据”,从流(键盘、文件)读取数据到变量,核心配合cin;
int a = 10;
double b = 3.14;
cout << "a = " << a << ", b = " << b; // 输出:a = 10, b = 3.14int x;
double y;
cout << "请输入整数和小数:";
cin >> x >> y; // 输入如 "5 2.7",则 x=5,y=2.7>> 会自动忽略输入中的空白字符(空格、换行、制表符 \t),因此可以分多行输入。
#include<iostream>
using namespace std;
int main()
{
// 在io需求⽐较⾼的地⽅,如部分⼤量输⼊的竞赛题中,加上以下3⾏代码
// 可以提⾼C++IO效率
ios_base::sync_with_stdio(false);
cin.tie(nullptr);
cout.tie(nullptr);
return 0;
}缺省参数
指在函数声明或定义时,为参数指定一个默认值。当调用函数时,如果没有提供该参数的值,编译器会自动使用这个默认值;如果提供了参数值,则使用用户指定的值。
用于提高函数调用的灵活性
// 函数声明时指定缺省参数
void printInfo(int age, string name = "匿名");// 函数定义(若已在声明中指定缺省参数,定义时不能重复指定)
void printInfo(int age, string name) {cout << "姓名:" << name << ",年龄:" << age << endl;
}printInfo(20); // 未提供name,使用默认值"匿名" → 输出:姓名:匿名,年龄:20printInfo(20, "张三"); // 提供name,使用"张三" → 输出:姓名:张三,年龄:20核心:
缺省参数必须从右向左连续设置
// 从右向左连续设置缺省参数
void func(int a, int b = 2, int c = 3) {} // 合法void func(int a = 1, int b, int c = 3) {}
// 非法:a有默认值,但其右侧的b没有缺省参数不能在声明和定义中重复指定
缺省参数只能在函数声明(通常在头文件)或定义中指定一次,避免二义性。
错误示范:
// 头文件中声明
void func(int a = 1);// 源文件中定义(重复指定缺省参数,编译报错)
void func(int a = 1) {} 缺省参数的默认值必须是常量表达式
默认值可以是字面量、const 变量、枚举值等编译期可确定的值,不能是普通变量。
错误示范:
int num = 10;
void func(int a = num) {}
// 非法(普通变量不能作为默认值)正确示范:
const int DEFAULT_NUM = 10;
void func(int a = DEFAULT_NUM) {}
// 合法(const变量)应用:
简化函数调用
例如:计算两个数的和,默认第二个数为 0
int add(int a, int b = 0) {return a + b;
}// 调用
add(5); // 等价于add(5, 0) → 结果5
add(5, 3); // 结果8兼容旧接口
当需要为函数新增参数时,给新参数设置缺省值可以保证旧的调用代码仍然有效。
// 旧版本函数
void log(string msg) { /* ... */ }// 新版本新增"级别"参数,设为默认值"INFO"
void log(string msg, string level = "INFO") { /* ... */ }// 旧代码仍可调用(自动使用默认级别)
log("系统启动"); // 等价于log("系统启动", "INFO")注意:
若存在重载函数,需避免调用时产生二义性。
void func(int a) {}
void func(int a, int b = 1) {}// 调用时编译器无法确定调用哪个函数,报错
func(10); 函数重载
构成重载的条件
- 函数名完全相同;
- 参数列表不同(以下至少满足一项):
- 参数个数不同;
- 参数类型不同;
- 参数顺序不同(仅当类型不同时有效)。
参数类型不同
//参数类型不同
void swap(int* p1, int* p2)
{}// B
void swap(double* p1, double* p2)
{}void swap(char* p1, char* p2)
{}参数个数不同
// 2、参数个数不同void f(){cout << "f()" << endl;}void f(int a){cout << "f(int a)" << endl;}参数顺序不同
// 3、参数类型顺序不同
void f(int a, char b)
{cout << "f(int a,char b)" << endl;
}void f(char b, int a)
{cout << "f(char b, int a)" << endl;
}调用时,编译器会根据实参的类型、个数、顺序匹配最贴切的函数
不能构成重载的情况
仅返回值类型不同
int add(int a, int b) { return a + b; }
double add(int a, int b) { return a + b; } // 错误:仅返回值不同,不构成重载参数名
void func(int a) {}
void func(int b) {} // 错误:仅参数名不同,不构成重载默认参数不同
void func(int a = 10) {}
void func(int a = 20) {} // 错误:仅默认值不同,不构成重载这个带有缺省参数,导致无法识别,报错
using namespace std;void f(){cout << "f()" << endl;}void f(int a=10){cout << "f(int a)" << endl;}int main(){f(10);//f();return 0;}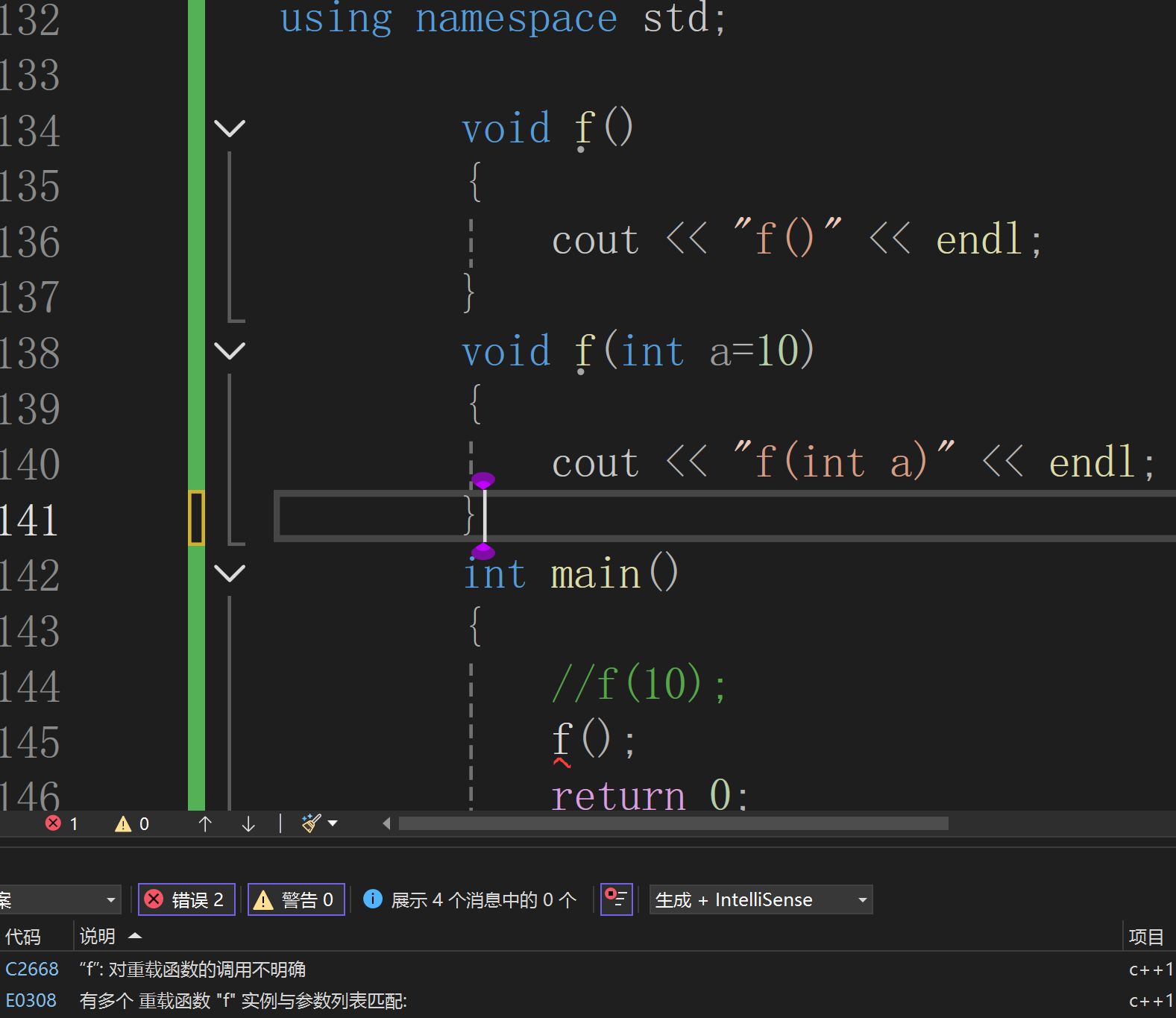
引用的认识
是一种特殊的变量类型,它为已存在的变量创建一个 “别名”(Alias)。通过引用,我们可以间接访问目标变量,且操作引用与操作原变量完全等效。
#include<iostream>using namespace std;int main(){int a = 0;// 引⽤:b和c是a的别名
int& b = a;int& c = a;// 也可以给别名b取别名,d相当于还是a的别名int& d = b;++d;// 这⾥取地址我们看到是⼀样的cout << &a << endl;cout << &b << endl;cout << &c << endl;cout << &d << endl;return 0;}核心特性:
必须初始化
引用声明时必须绑定到一个已存在的变量,不能单独存在。
int &b; // 错误:引用必须初始化一旦绑定,不可更改
引用一旦与某个变量绑定,就不能再改为指向其他变量。
int a = 10, c = 20;
int &b = a; // b是a的引用
b = c; // 这是给a赋值(a变为20),而非更改引用指向与原变量共享内存
引用本身不占用额外内存(编译器可能优化为指针实现,但语义不同),它与原变量代表同一块内存空间。
引用的使用
作为函数参数
引用作为参数时,函数内部对引用的操作会直接影响外部实参,实现 “传址调用” 的效果,但语法比指针更简洁。
// 引用参数版本
void swap(int &x, int &y) {int temp = x;x = y;y = temp;
}int main() {int a = 10, b = 20;swap(a, b); // 直接传变量,无需取地址cout << a << ", " << b; // 输出:20, 10(a和b的值已交换)return 0;
}优势:
- 避免值传递时的内存拷贝(尤其对大型对象,能提高效率)。
- 语法比指针更直观,无需解引用(
*)操作。
作为函数返回值
函数可以返回引用,此时返回的是变量本身(而非副本),可用于链式赋值等场景。
int arr[5] = {1, 2, 3, 4, 5};// 返回数组元素的引用
int &getElement(int index) {return arr[index]; // 注意:不能返回局部变量的引用(局部变量会销毁)
}int main() {getElement(2) = 100; // 通过返回的引用修改数组元素cout << arr[2]; // 输出:100return 0;
}注意:
- 不能返回函数内部局部变量的引用(局部变量在函数结束后销毁,引用会变为 “悬空引用”)。
- 返回引用时,函数返回值可以作为左值(如示例中的赋值操作)。
常量引用
常量引用(const 类型 &)用于限制通过引用修改原变量,同时支持绑定到临时值或不同类型的变量(需可隐式转换)。
int a = 10;
const int &b = a; // b是a的常量引用
// b = 20; // 错误:不能通过常量引用修改原变量
a = 20; // 允许:原变量可以直接修改,b的值也会变为20// 常量引用可以绑定到临时值
const int &c = 100; // 合法(临时值100被分配到常量区,生命周期延长)// 常量引用可以绑定到不同类型(需可转换)
double d = 3.14;
const int &e = d; // 合法(d被隐式转换为int临时值,e绑定到该临时值)- 函数参数为常量引用时,既能避免拷贝,又能防止函数内部修改实参(如
void print(const string &s))。 - 接收临时值或不同类型的变量(如上述示例)。
引用与指针区别:
| 特性 | 引用(Reference) | 指针(Pointer) |
|---|---|---|
| 初始化 | 必须初始化,且绑定后不可更改 | 可初始化也可不初始化,可随时指向其他变量 |
| 空值 | 没有空引用(必须绑定有效变量) | 有空指针(nullptr) |
| 解引用 | 无需显式解引用,直接使用 | 需要用 * 解引用 |
| 地址操作 | 取引用的地址即原变量的地址 | 取指针的地址是指针本身的地址 |
| 自增 / 自减 | 操作原变量(如 b++ 等价于 a++) | 操作指针指向的地址(如 p++ 指向相邻内存) |
注意事项:
避免返回局部变量的引用
局部变量在函数结束后会被销毁,返回其引用会导致 “悬空引用”(访问已释放的内存),行为未定义。
int &badFunc() {int x = 10;return x; // 错误:返回局部变量的引用
}引用作为参数时的权限控制
若函数无需修改实参,尽量使用常量引用(const &),避免意外修改,同时支持更多类型的实参(如临时值)。
const 引用
只读性
int a = 10;
const int &b = a; // b是a的const引用// b = 20; // 错误:const引用不允许修改目标变量
a = 20; // 合法:可以直接修改原变量,b的值会同步变为20绑定到const变量
const int a = 10; // a是const变量,本身不可修改
// int &b = a; // 错误:普通引用不能绑定到const变量
const int &b = a; // 合法:const引用可以绑定到const变量绑定到临时值
// int &a = 100; // 错误:普通引用不能绑定到临时值(100是临时值)
const int &a = 100; // 合法:const引用绑定到临时值100// 绑定到表达式结果(临时值)
int x = 5, y = 3;
const int &sum = x + y; // 合法:sum绑定到x+y的结果(8),生命周期与sum一致绑定到不同类型值(隐式转换)
当类型不同但可隐式转换时,const 引用会先创建一个临时变量存储转换后的值,再绑定到该临时变量;而普通引用不允许这种操作:
double d = 3.14;// int &a = d; // 错误:普通引用不能绑定到不同类型的变量
const int &a = d; // 合法:d先转换为int临时值(3),a绑定到该临时值注意:此时修改原变量 d 不会影响 a,因为 a 实际绑定的是临时变量(值为 3),而非 d 本身。
核心引用场景:
作为函数参数(最常用)
将函数参数声明为 const 引用,有三大优势:
- 避免拷贝:对于大型对象(如自定义类、字符串),传递引用可避免值传递时的内存拷贝,提高效率;
- 保证安全:防止函数内部意外修改实参(通过引用);
- 兼容性强:可接收更多类型的实参(非 const 变量、const 变量、临时值、不同类型可转换的值)。
安全高效地传递大型对象
#include <string>
using namespace std;// 用const引用接收字符串,避免拷贝且防止修改
void printString(const string &s) {// s += "world"; // 错误:不能通过const引用修改实参cout << s << endl;
}int main() {string str = "hello";printString(str); // 传递非const变量printString("hello"); // 传递临时值(字符串字面量)printString(str + " world"); // 传递表达式结果(临时值)return 0;
}存储临时结果
int calculate(int a, int b) {return a * b + a + b;
}int main() {// 用const引用保存函数返回的临时结果const int &result = calculate(3, 4); // 结果为3*4+3+4=19cout << result << endl; // 合法:可正常访问临时结果return 0;
}*
int& SLAt(SL& sl, int i)
{assert(i < sl.size); // 断言:确保索引i在有效范围内return sl.a[i]; // 返回顺序表中第i个元素的引用
}-
函数声明
int& SLAt(SL& sl, int i):- 返回值
int&:表示函数返回一个int类型的引用(即返回顺序表中元素的别名)。 - 参数
SL& sl:接收一个SL类型的引用(顺序表对象),避免值传递的拷贝开销。 - 参数
int i:要访问的元素索引。
- 返回值
-
断言
assert(i < sl.size):- 用于检查索引
i是否合法(小于顺序表的当前元素个数size)。 - 若
i >= sl.size,程序会终止并提示错误(仅在调试模式有效)。
- 用于检查索引
-
返回值
return sl.a[i]:sl.a表示顺序表的底层数组(假设SL结构体中用a存储数据)。- 返回数组中第
i个元素的引用,意味着可以通过函数返回值直接修改该元素。
误区:
-
const 引用与 “常量” 的关系
const 引用只是 “不能通过引用修改目标”,不代表目标本身是常量。若目标是普通变量,仍可直接修改int a = 10; const int &b = a; a = 20; // 合法,此时b的值也会变为20 -
绑定不同类型时的 “隔离性”
当 const 引用绑定到不同类型的值时(如 double→int),引用实际指向的是临时变量,因此原变量的修改不会影响引用:double d = 3.14; const int &a = d; // a绑定到临时变量(3) d = 5.67; // 修改原变量 cout << a; // 输出3(临时变量未变) -
const 引用的底层实现
编译器通常会将 const 引用实现为指针(尤其当绑定临时值或不同类型时),但语法上完全屏蔽了指针的操作细节,更安全直观。
inline
在 C++ 中,inline(内联)是一个关键字,用于建议编译器将函数调用替换为函数体本身,从而消除函数调用的开销(如栈帧的创建与销毁、参数传递等),提高程序运行效率。
声明方式:
// 内联函数定义
inline int add(int a, int b) {return a + b;
}核心作用:
函数调用通常会有一定的性能开销(如跳转、栈操作等)。对于代码量少、调用频繁的函数(如简单的数学运算、访问器方法),inline 可以让编译器在调用处直接插入函数体,避免这些开销。
例如,调用 add(3, 5) 时,编译器可能直接替换为 3 + 5,而非执行一次完整的函数调用。
使用规则和特性
1.inline 是 “建议” 而非 “命令”
编译器可以忽略 inline 关键字:
- 若函数体过大(如包含循环、递归),编译器可能拒绝内联(内联会导致代码膨胀)。
- 不同编译器有不同的内联策略,无法保证一定生效。
2. 内联函数需在调用前定义
内联函数的完整定义必须在调用它的每个源文件中可见(通常放在头文件中),否则编译器无法在调用处插入函数体。
// inline_demo.h
#ifndef INLINE_DEMO_H
#define INLINE_DEMO_Hinline int add(int a, int b) {return a + b;
}#endif
❌ 错误做法(仅声明在头文件,定义在源文件):
// 头文件中仅声明
inline int add(int a, int b); // 不完整,调用处无法内联// 源文件中定义
int add(int a, int b) { return a + b; }
3. 避免内联过多导致代码膨胀
内联会将函数体复制到每个调用处,若函数被频繁调用且代码量较大,会导致可执行文件体积增大(代码膨胀),反而可能降低效率(如增加内存缓存压力)。
以下情况不适合使用 inline:
- 复杂函数:包含循环、分支(如
if-else、switch)、递归的函数(编译器通常会忽略内联请求)。 - 调用次数极少的函数:内联带来的收益不足以抵消代码膨胀的代价。
- 需要取地址的函数:若程序中需要获取函数指针(如
auto func = &add;),编译器可能无法内联该函数(函数地址的存在意味着函数体未被完全替换)。
| 对比维度 | 宏(#define) | inline 函数 |
|---|---|---|
| 本质 | 文本替换(预处理阶段) | 真正的函数(编译阶段,可能被内联) |
| 参数求值 | 多次求值(依赖展开位置,可能有副作用) | 只求值一次(无副作用,结果确定) |
| 类型安全 | 无类型检查(运行时可能报错) | 强类型检查(编译阶段发现错误) |
| 语法边界 | 无边界(易因优先级 / 嵌套出问题) | 有明确函数体边界(语法逻辑可控) |
| 调试支持 | 无法调试(替换后代码无宏痕迹) | 可正常调试(与普通函数一致) |
宏与inline
核心差异 1:参数求值方式(最关键)
宏的本质是文本替换,参数会在替换后的代码中「直接展开」,可能被多次求值;而 inline 函数是「真正的函数」,参数会在函数调用前只求值一次,再将结果传入函数体。
add(x++, x++) 例子中,inline 函数的结果符合预期,但宏的结果其实是「未定义行为」(依赖编译器求值顺序),并非所有情况都能得到正确结果。我们用更直观的例子对比:
示例:参数含副作用(如自增、自减、函数调用)
假设我们有一个计算「参数加倍后求和」的逻辑,分别用宏和 inline 函数实现:
(1)宏的执行过程:文本替换 + 多次求值
宏 DOUBLE_ADD(x++, x++) 会被编译器直接替换为文本:
((x++)*2 + (x++)*2)
#include <iostream>
using namespace std;// 1. 宏定义:文本替换
#define DOUBLE_ADD(a, b) ((a)*2 + (b)*2)// 2. inline函数:真正的函数调用
inline int doubleAdd(int a, int b) {return a*2 + b*2;
}int main() {int x = 1;// 用宏计算:参数x++会被展开后多次求值int macroRes = DOUBLE_ADD(x++, x++); // 用inline函数计算:参数x++先求值一次,结果传入int inlineRes = doubleAdd(++x, ++x); cout << "宏结果:" << macroRes << endl; // 结果?cout << "inline结果:" << inlineRes << endl; // 结果?return 0;
}此时 x++ 被执行了 2 次(第一次计算 (x++)*2 时 x=1,第二次计算 (x++)*2 时 x=2),最终:
(1*2) + (2*2) = 2 + 4 = 6,且 x 最终变为 3。
但注意:C++ 标准并未规定「函数参数的求值顺序」,如果编译器先计算右侧的 x++,结果会变成 (2*2)+(1*2)=8——宏的结果是未定义的,完全依赖编译器实现。
(2)inline 函数的执行过程:参数先求值一次
inline 函数 doubleAdd(++x, ++x) 会先执行参数求值(只执行一次):
- 假设编译器按「从左到右」求值(无论顺序如何,每个参数只算一次):
左侧++x使 x=4(因为之前宏执行后 x=3),右侧++x使 x=5,然后将4和5传入函数体。 - 函数体计算:
4*2 +5*2 = 8+10=18,x 最终为 5。
关键是:每个参数(++x)只求值一次,结果是确定的,不存在未定义行为 —— 这是 inline 函数与宏的核心区别。
二、核心差异 2:类型安全
宏是「无类型」的文本替换,不会检查参数类型;而 inline 函数是强类型的,会严格检查参数类型是否匹配,避免类型错误。
示例:传入错误类型
// 宏:接收字符串也能“替换”,但运行时会报错
#define ADD(a, b) ((a)+(b))
// inline函数:只接收int,传入其他类型编译报错
inline int add(int a, int b) { return a + b; }int main() {// 宏:传入字符串,编译不报错(文本替换为 "123"+"456")// 但运行时会崩溃(字符串不能直接用+拼接)ADD("123", "456"); // inline函数:传入字符串,编译直接报错(类型不匹配)// add("123", "456"); // 错误:无法将const char*转换为intreturn 0;
}宏的「无类型」特性会把错误隐藏到运行时,而 inline 函数的类型检查能在编译阶段就发现问题,安全性远高于宏。
三、核心差异 3:语法边界问题
宏的文本替换没有「函数体边界」,如果宏定义包含多行代码或复杂逻辑,容易因优先级、括号缺失导致逻辑错误;而 inline 函数有明确的函数体边界,语法逻辑完全符合 C++ 规则。
示例:宏的语法边界漏洞
假设我们用宏实现「如果 a>b,返回 a,否则返回 b」的逻辑:
// 错误的宏定义:缺少大括号,导致else与外层if绑定
#define MAX(a, b) if(a > b) return a; else return b;inline int max(int a, int b) {if(a > b) return a; else return b;
}void test(int x, int y) {// 用宏:如果x<10,执行MAX(x,y),否则打印0if(x < 10)MAX(x, y); // 宏展开为:if(x>y) return x; else return y;elsecout << 0; // 错误:else与MAX内部的if绑定,导致语法错误
}宏展开后,else 会错误地与 MAX 内部的 if 绑定,而非外层的 if(x<10),导致编译报错;而 inline 函数有明确的函数体边界,不会出现这种问题。
即使给宏加括号,也无法解决所有边界问题(如嵌套条件、循环等),而 inline 函数的语法逻辑完全可控
nullptr
nullptr 是一个关键字,用于表示空指针常量,专门用来替代 C 语言和早期 C++ 中使用的 NULL,解决了 NULL 带来的类型歧义问题。
#include <iostream>
using namespace std;// 函数重载:一个接收指针,一个接收整数
void func(int x) {cout << "调用了int版本:" << x << endl;
}void func(char* p) {cout << "调用了指针版本:" << (void*)p << endl;
}int main() {func(NULL); // 问题:调用哪个版本?return 0;
}- 若
NULL定义为0,则func(NULL)会调用func(int)(而非预期的指针版本),导致逻辑错误; - 这就是
NULL的缺陷:它的类型是int(或void*,但隐式转换可能引发问题),无法明确表示 “空指针” 的语义。
优势:
- 类型明确(
nullptr_t),专门用于表示空指针; - 避免函数重载时的匹配错误;
- 可安全赋值给任何指针类型,但不能转换为整数,语义更清晰。