使用dumpbin指令分析Windows下的PE文件(伍)
目录
1.前言
2.Windows下的PE文件的来源
3.PE文件和COFF文件的关系
4.PE与ELF文件的区别和共同点
5.使用dumpbin指令分析Windows下的PE文件
6.解析PE文件中的".drectve"段
7.解析PE文件中的".debug"段
8.解析PE文件中的符号表
前言
在文章《使用binutils工具分析目标文件(贰)》中,我们知道了不同系统中的目标文件主要是靠目标文件中的魔数来区分,而且假如我们在Windows中使用readelf指令分析一个目标文件(该文件由Windows生成),则会提示Not an ELF file - it has the wrong magic bytes at the start。对此本篇博客则主要讲解使用dumpbin命令分析Windows生成的obj目标文件。
Windows下的PE文件的来源
PE(Portable Executable)文件格式由微软于1993年为Windows NT操作系统设计,旨在为不同硬件架构(如x86、ARM)提供统一的可执行文件结构,同时兼容早期MS-DOS系统。其核心设计基于COFF(Common Object File Format)规范——后者源自Unix System V的通用目标文件格式。微软在COFF基础上扩展了Windows专属功能,如导入表、资源管理和安全机制(如数字签名),并保留了DOS兼容层(MZ头),使PE文件在DOS环境下可显示提示信息而非直接崩溃(提示信息为:This program cannot be run in DOS)。
PS:当Windows开始执行一个后缀名为"exe"的文件时,它会首先判断PE文件头在PE文件中的偏移地址,如果该地址为0则会启动一个DOS的子系统来运行它;如果地址不为0,那么则代表该"exe"文件是一个Windows中的PE可执行文件
PE文件和COFF文件的关系
PE是COFF的超集与扩展。COFF作为目标文件(.obj)的通用格式,定义了文件头、节表、符号表等基础结构,被PE直接沿用。但PE增加了关键增强:
1.头部扩展:添加DOS头(MZ头)支持旧系统兼容性,以及可选头(Optional Header)存储入口点、内存对齐等运行时元数据;
2.功能扩展:引入数据目录(Data Directories)管理导入表、导出表、资源表等Windows特有结构,支持动态链接库(DLL)和高级安全机制(如ASLR、DEP)
因此,COFF是编译阶段的中间格式(目标文件),而PE是链接后的最终可执行格式(.exe/.dll),两者在Windows工具链中形成继承关系
PE与ELF文件的区别和共同点
PE和ELF文件有以下的共同点:
1.均继承自COFF格式,采用分段存储(代码段.text、数据段.data、未初始化段.bss)和动态链接机制
2.均通过元数据结构(PE头/ELF头)描述文件属性,并支持符号表、重定位表等链接信息
PE和ELF文件的核心区别在于PE文件以DOS头起始,依赖导入表(.idata)静态解析DLL函数,一次性加载整个文件到固定内存地址(需重定位表.reloc支持ASLR),而ELF文件以魔数\x7FELF标识,通过全局偏移表(GOT)和过程链接表(PLT)实现延迟绑定,支持按需加载(懒加载)和原生地址随机化(ASLR)
使用dumpbin指令分析Windows下的PE文件
在使用dumpbin指令之前,我们大多数电脑都没有对dumpbin指令进行一个配置,这里博主将先告诉读者如何配置dumpbin指令。在我们下过VisualStudio的电脑上使用Everything工具来查找dumpbin(Everything工具下载链接如下)
Everything![]() https://www.voidtools.com/zh-cn/ 如图,这是使用Everything检索到的dumpbin的信息,我们需要把检索到的dumpbin设置到电脑的path路径下:
https://www.voidtools.com/zh-cn/ 如图,这是使用Everything检索到的dumpbin的信息,我们需要把检索到的dumpbin设置到电脑的path路径下:
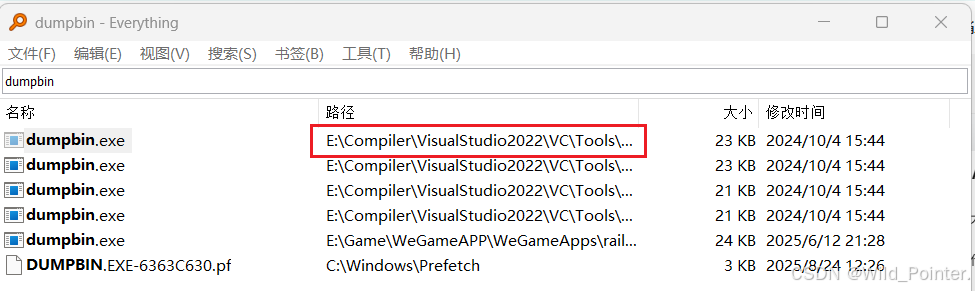
图1.使用Everything检索dumpbin
当我们把路径设置到path后,即可直接在cmd窗口使用dumpbin指令。此处使用的测试代码位于《使用binutils工具分析目标文件(壹)》中的样例代码。使用的dumpbin指令如下:
dumpbin /ALL xxx.obj 在使用dumpbin指令后,我们可以得到如图的输出信息:
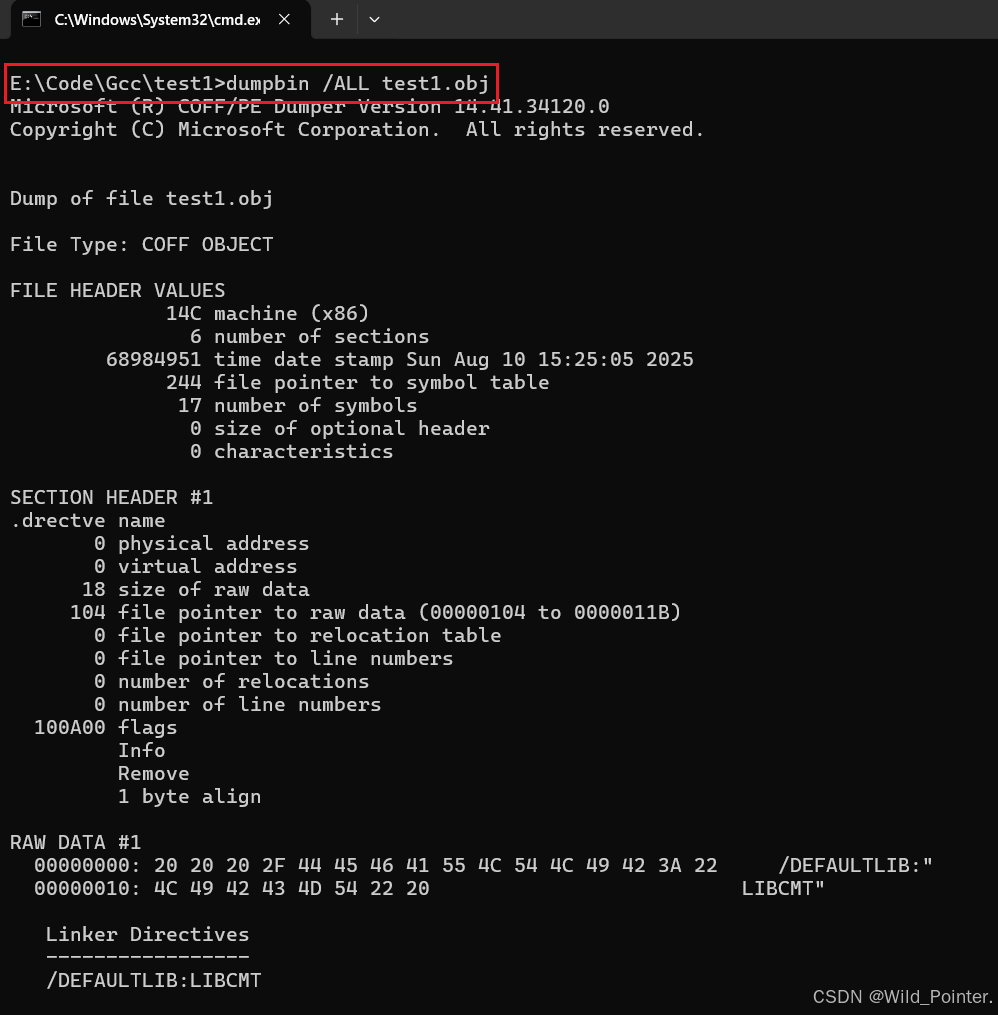
图2.dumpbin输出的信息
PS:由于在《使用binutils工具分析目标文件(壹)》,《使用binutils工具分析目标文件(贰)》和《使用binutils工具解析目标文件符号表(叁)》中已经对Linux中的ELF文件进行解析,而ELF文件和PE文件大体结构是相似的,所以后续只针对不同的地方进行解析
解析PE文件中的".drectve"段
对于PE文件中的".drectve"段,该段的主要内容是编译器传递给链接器的指令,即编译器希望告诉链接器应该如何链接这个目标文件。在输出的信息中含有LIBCMT,该信息代表输出的Obj文件需要使用LIBCMT这个库,而LIBCMT代表的就是VC的静态链接的多线程C库。
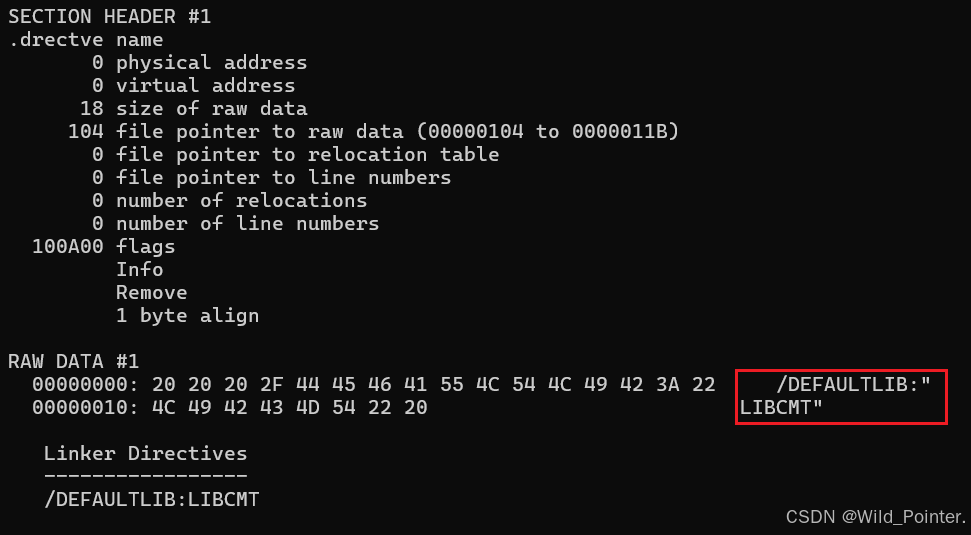
图3.PE文件中的drectve段
解析PE文件中的".debug"段
在COFF文件中所有以".debug"开始的段都包含着调试信息,PE文件也是如此。例如".debg$S"表示包含的是符号相关的调试信息段;".debug$P"表示包含预编译文件相关的调试信息段;".debug$T"则表示包含类型相关的调试信息段。而在我们使用dumpbin命令输出的PE文件信息只含有.debg$S段,则表示只有调试时相关的信息。具体如下图:
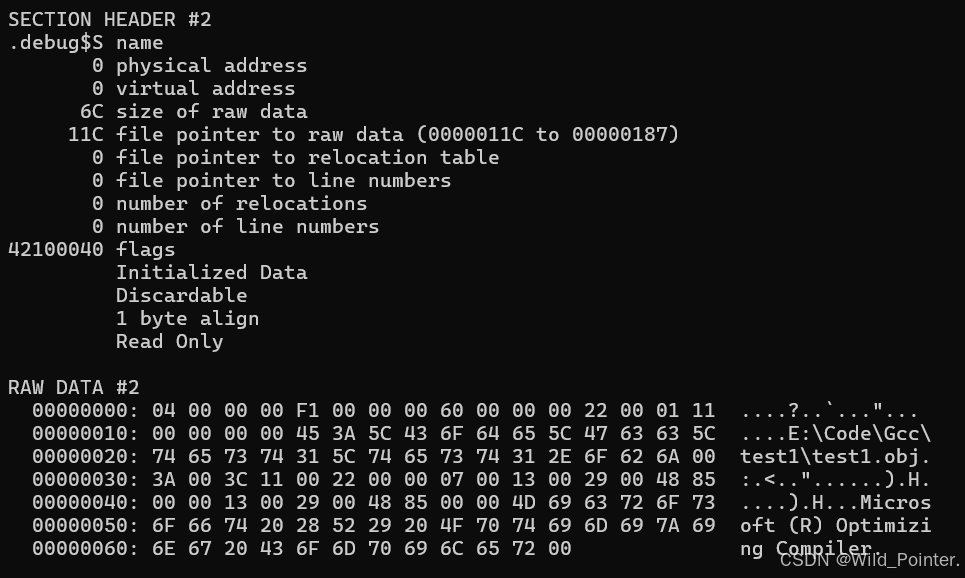
图4.PE文件中的debug段
解析PE文件中的符号表
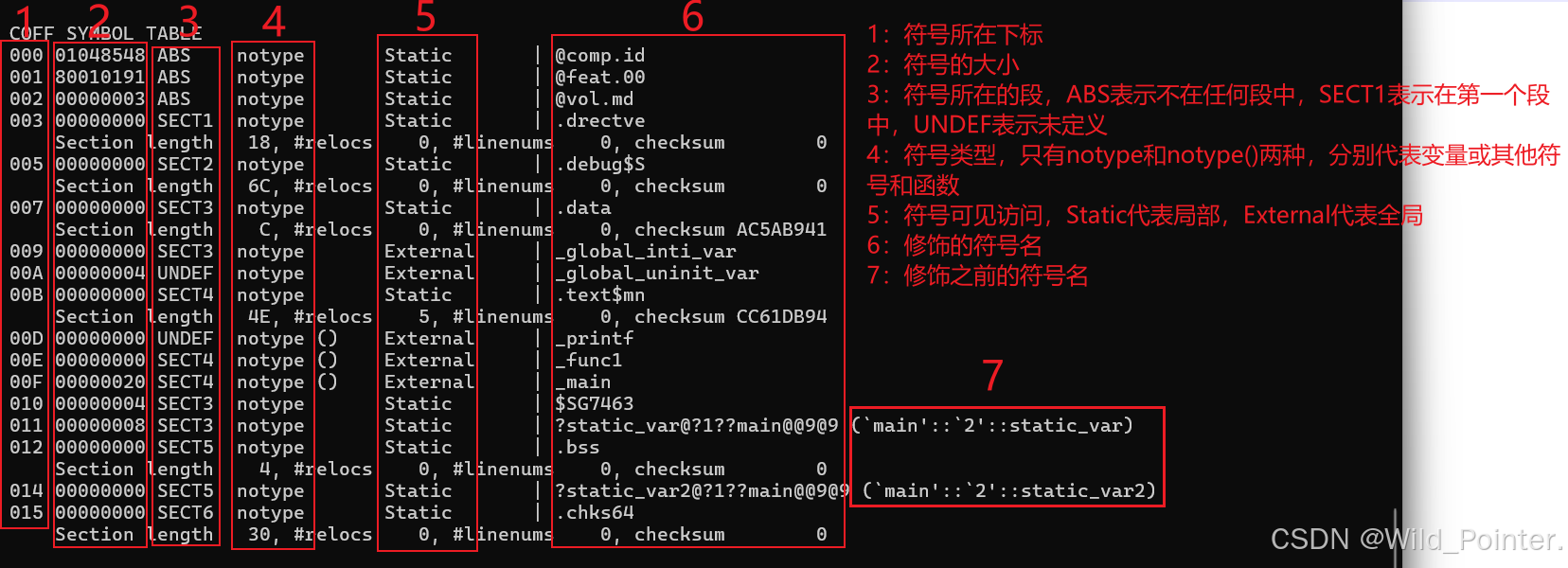
对于PE文件中的符号表,图5已经将各个列所含的意思表达出来了。对此从符号表输出的信息中,我们发现_global_init_vat属于SECT3段也就是.data段,而符号表第六列中的$SG7463则表示程序中的"%d\n"字符串常量,因为程序中要使用该字符串常量,而该字符串常量并没有名字,所以由编译器自动为其生成了一个名字。